AI工具深度测评与选型指南 - AI工具测评框架及方法论
目录
- 引言:AI工具爆发期的机遇与挑战
- 一、从AI模型到AI工具:核心认知与生态解析
- 1.1 DeepSeek:快速出圈的国产大模型代表
- 1.2 大模型的核心能力与类型划分
- 1.2.1 大模型的三层能力与“双系统”类比
- 1.2.2 生成模型与推理模型的核心差异
- 1.3 AI工具与AI模型的本质差异
- 1.4 AI工具的分类框架与行业价值
- 1.4.1 AI工具的双重分类框架
- 1.4.2 AI工具的行业价值
- 二、AI工具测评框架与方法论:科学选型的关键
- 2.1 为何需要系统评估AI工具?
- 2.1.1 工具爆发带来的四大困境
- 2.1.2 系统评估的三大核心价值
- 2.2 12个核心测评维度:全面覆盖工具价值
- 2.3 6大测评方法:落地评估的实操路径
- 1. 实测案例分析
- 2. 用户反馈收集与分析
- 3. 结构化评分体系
- 4. 启发式评估与专家评审
- 5. A/B测试与对比分析
- 6. 真实场景数据集测评
- 2.4 场景化权重设置:匹配不同用户需求
- 三、总结:让AI工具选型从“经验驱动”到“数据驱动”
引言:AI工具爆发期的机遇与挑战
当下,生成式AI已进入实际应用爆发期,从ChatGPT到DeepSeek的快速迭代,标志着AI工具正成为重塑生产力的核心引擎。据麦肯锡全球调查显示,2024年企业生成式AI采用率达65%,72%的受访企业已部署AI技术,AI工具对工作方式与组织竞争力的影响愈发关键。
然而,AI工具市场呈现“数量爆炸、功能重叠、效果存疑、成本黑洞”的困境,加之用户对AI模型与工具的认知混淆,亟需一套系统化的认知框架与测评方法。本文基于北京大学AI肖睿团队的研究,从“AI模型-AI工具”的底层逻辑切入,拆解工具生态,并提供可落地的测评方法论,助力用户精准选型。
一、从AI模型到AI工具:核心认知与生态解析
1.1 DeepSeek:快速出圈的国产大模型代表
DeepSeek作为中国AI 2.0(大模型)时代“七小龙”之一,其快速出圈成为行业焦点,核心信息如下:
- 公司背景:2023年5月成立北京公司,7月成立杭州公司,由幻方量化孵化,团队160人分布于北京、杭州;国内大模型“六小虎”为智谱AI、百川智能、月之暗面、阶跃星辰、MiniMax、零一万物。
- 发展历程:
- 2024年1月:发布首版大模型DeepSeek LLM;
- 2024年9月:上线DeepSeek V2.5并开源模型权重;
- 2024年12月:推出对标GPT-4o的DeepSeek V3;
- 2025年1月:发布对标GPT-o1的推理模型DeepSeek R1,上线20天日活达2000万;
- 2025年1月26日:因“颠覆大模型商业模式”的讨论引发英伟达股价波动,从美国出圈至中国,并上升至中美竞争高度。
- 模型家族:涵盖通用模型(V3、V2)、代码模型(CoderV2、Coder)、多模态模型(VL)、数学模型(Math)、推理模型(R1),需注意:市场上部分“DeepSeek-R1-Distill”模型实为基于Qwen/Llama的蒸馏模型,非原生DeepSeek模型。
1.2 大模型的核心能力与类型划分
1.2.1 大模型的三层能力与“双系统”类比
大模型能力可通过“快思考(系统1)-慢思考(系统2)”类比理解:
- 快思考(生成模型主导):对应“直觉系统”,无意识且快速,依赖记忆与经验,适用于文本生成、创意写作、多轮对话等通用场景,代表模型为GPT-4o、DeepSeek V3;
- 慢思考(推理模型主导):对应“理性系统”,需集中注意力分析,适用于数学计算、逻辑拆解、代码生成等复杂任务,代表模型为GPT-o1、DeepSeek R1。
1.2.2 生成模型与推理模型的核心差异
| 比较项 | 生成模型(GPT-4.1、DeepSeek-V3) | 推理模型(GPT-o3、DeepSeek-R1) |
|---|---|---|
| 模型定位 | 通用自然语言处理,多模态能力突出 | 复杂推理与逻辑能力,专注专业领域任务 |
| 推理能力 | 日常任务均衡,复杂逻辑准确率低 | 复杂推理卓越,数学/代码任务表现优异 |
| 多模态支持 | 支持文本、图像、音视频输入 | 仅支持文本输入,未来或扩展多模态 |
| 应用场景 | 大众市场(对话、内容生成、跨语言交流) | 专业场景(数学竞赛、编程、科学研究、方案撰写) |
| 用户交互体验 | 实时流畅,界面友好,无需专业知识 | 展示链式思考过程,交互节奏慢,定制性高 |
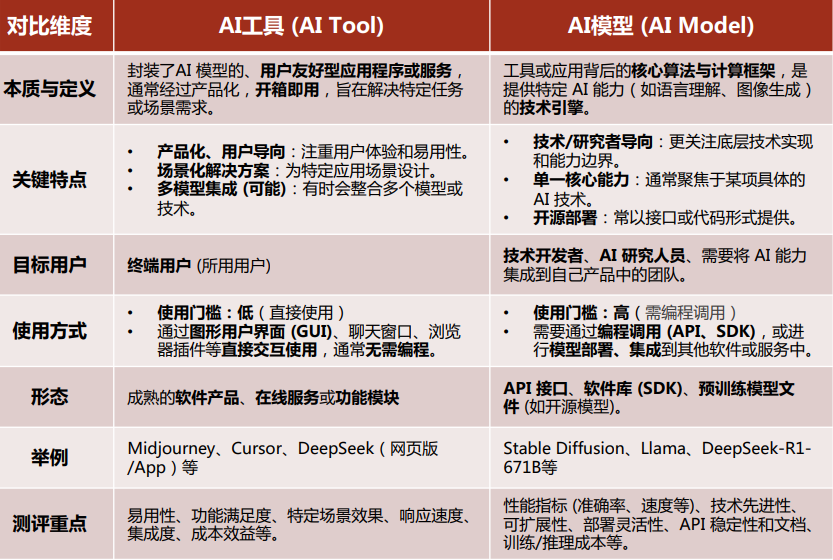
1.3 AI工具与AI模型的本质差异
AI模型是“发动机”,AI工具是“整车”,二者核心区别如下:
1.4 AI工具的分类框架与行业价值
1.4.1 AI工具的双重分类框架
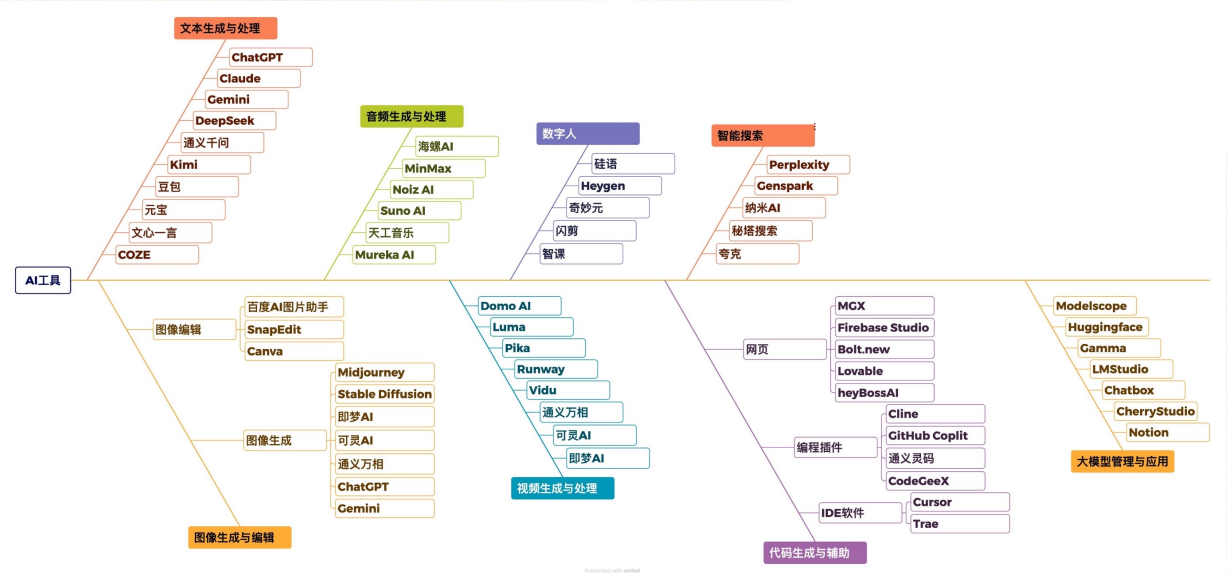
- 按核心功能划分:
- 文本处理:ChatGPT、Claude、Kimi、豆包、文心一言;
- 图像生成/编辑:Midjourney、Stable Diffusion、Canva、百度AI图片助手;
- 音视频处理:Suno AI、Heygen、闪剪、Runway;
- 代码辅助:GitHub Copilot、CodeGeeX、Cursor、DeepSeek Coder;
- 智能搜索:Perplexity、秘塔搜索、夸克AI。
- 按应用领域划分:办公协同、内容创作、研发设计、教育培训等。
1.4.2 AI工具的行业价值
- 效率革命:每日AI生成图像达3400万张,71%社交媒体图像来自AI,内容生产效率提升40%;
- 决策优化:AI处理复杂数据集,减少认知负担,挖掘隐藏业务趋势,降低决策偏差;
- 创新加速:新材料研发周期从10年缩短至1-2年,可再生能源产出提升15-30%,医疗AI市场价值达387亿美元(2023年翻倍)。
二、AI工具测评框架与方法论:科学选型的关键
2.1 为何需要系统评估AI工具?
2.1.1 工具爆发带来的四大困境
- 数量爆炸:2024年全球新增AI工具呈指数级增长;
- 功能重叠:同类工具差异度不足30%,选型难度大;
- 效果存疑:开发周期短,用户反馈“未达预期”;
- 成本黑洞:无规划采购导致技术预算浪费。
2.1.2 系统评估的三大核心价值
- 风险控制:规避数据泄露、供应商绑定风险;
- 资源优化:缩短选型周期,精准匹配需求以节省成本;
- 效能保障:提升功能达标率,间接提高员工工作效率。
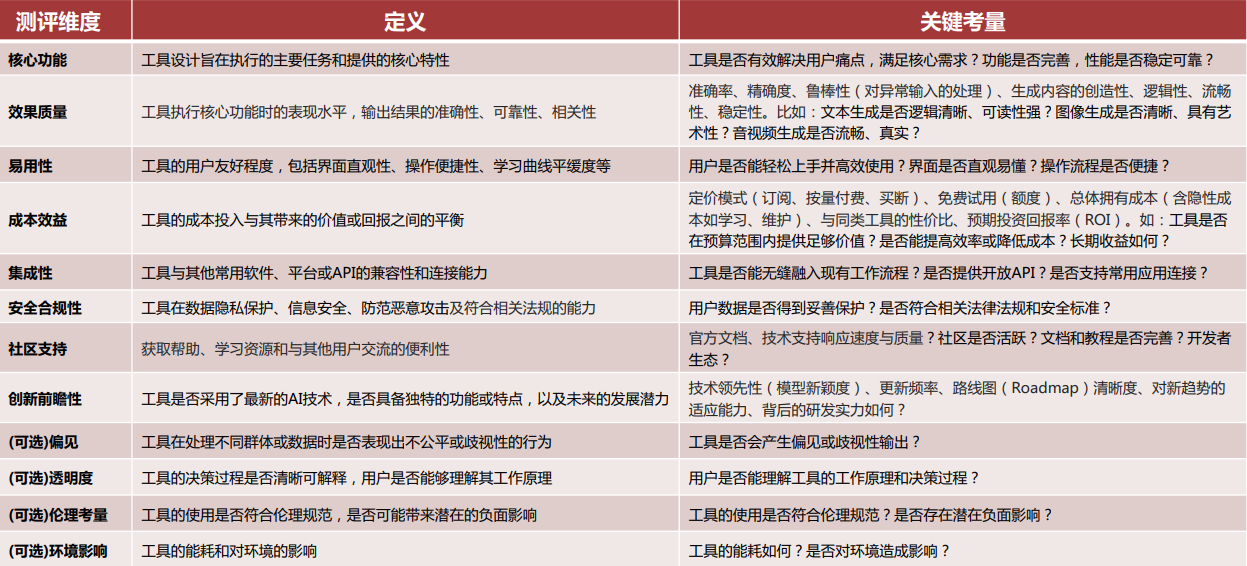
2.2 12个核心测评维度:全面覆盖工具价值
测评维度分为“核心维度(8个)”与“可选维度(4个)”,具体定义与关键考量如下:
2.3 6大测评方法:落地评估的实操路径
1. 实测案例分析
- 核心逻辑:“实践是检验真理的唯一标准”,设计贴近业务的测试任务(如文本摘要、图像生成);
- 关键步骤:定义场景→建立基准测试(量化指标如生成耗时、准确率)→与预期/人工/其他工具对比。
2. 用户反馈收集与分析
- 方法:查阅专业评测网站、应用商店评论、社交媒体口碑,或开展小范围用户访谈;
- 分析要点:关注共性问题与高频赞扬点,区分用户群体(开发者/普通用户),交叉验证信息真实性。
3. 结构化评分体系
- 方法:为每个维度设定评分标准(1-10分/优中差),结合实测与反馈打分,加权计算总分;
- 优势:减少主观偏差,实现数据驱动的横向对比。
4. 启发式评估与专家评审
- 启发式评估:由5-8名可用性专家按预定义原则评估界面与交互设计;
- 专家评审:邀请领域专家评估功能、效果与潜在风险,适用于专业场景(如法律合同审阅工具)。
5. A/B测试与对比分析
- 方法:在相同任务下直接对比不同工具表现,基于测评维度系统分析差异;
- 价值:为“特定场景下选哪类工具”提供实证依据。
6. 真实场景数据集测评
- 步骤:领域专家设计批量测试问题→获取工具回复→设定专业维度与权重→人工打分计算总分;
- 适用场景:需高精准度的专业领域(如教育、医疗、法务)。
2.4 场景化权重设置:匹配不同用户需求
不同用户对维度的优先级差异显著,核心场景的权重设置参考如下:
| 测评维度 | 个人内容创作者(博主/设计师) | 小型企业(3-5人电商团队) | 大型企业(法务部门) | 科研机构(实验室) |
|---|---|---|---|---|
| 核心功能 | 中 | 高 | 高 | 高 |
| 效果质量 | 高(内容质量决定传播力) | 较高(需符合品牌调性) | 高(需精准提取条款) | 高(成果可靠性) |
| 易用性 | 较高(无技术支持) | 中(培训资源有限) | 中(专业用户可学习) | 中 |
| 成本效益 | 中(个人预算有限) | 高(需明确ROI) | 中(预算充足但需论证) | 低(优先功能) |
| 集成性 | 低(独立使用) | 中(需对接电商后台) | 较高(需集成文档系统) | 中(需对接科研软件) |
| 安全合规性 | 低(仅需账号安全) | 中(涉及用户数据) | 高(商业机密红线) | 中(需保护实验数据) |
| 社区支持 | 低 | 中(需快速解决问题) | 较高(需供应商保障) | 中(需技术支持) |
| 创新前瞻性 | 中(需创意辅助) | 中(需稳定而非前沿) | 中 | 较高(需探索未知) |
三、总结:让AI工具选型从“经验驱动”到“数据驱动”
AI工具已从“可选项”变为“必选项”,但市场的复杂性易导致选型失误。本文通过“AI模型-AI工具”的认知拆解,明确了DeepSeek等代表性模型的定位,区分了生成/推理模型的适用场景;同时,构建了“12维度+6方法+场景化权重”的测评框架,核心目标是:
- 消除信息不对称,为用户提供结构化认知;
- 降低试错成本,将选型从“凭经验”转向“靠数据”;
- 匹配需求与工具,让AI真正成为个人与组织的“效率引擎”。
未来,随着多模态、Agent等技术的发展,AI工具的测评框架需持续迭代,但“以需求为核心、以数据为依据”的原则将始终适用。