【左程云算法06】链表入门练习合集
算法讲解009【入门】单双链表及其反转-堆栈诠释
算法讲解010【入门】链表入门题目-合并两个有序链表
算法讲解011【入门】链表入门题目-两个链表相加
算法讲解012【入门】链表入门题目-划分链表
视频链接
目录
单双链表及其反转-堆栈诠释编辑
1)按值传递、按引用传递
代码与内存分析
Case 1: 基本数据类型
Case 2: 自定义对象类型
Case 3: 数组类型
结论
2)单链表、双链表的定义
单(向)链表 (Singly Linked List)
双(向)链表 (Doubly Linked List)
3) 根据反转功能,彻底从系统角度解释链表是如何调整的
核心思路:迭代反转
代码与内存逐行解析
初始状态 (循环前)
第一轮循环 (处理节点1)
第二轮循环 (处理节点2)
第三轮循环 (处理节点3)
循环结束
返回结果
链表入门题目-合并两个有序链表
核心思想与图解
代码实现与逐行解析
1. 边界条件处理
2. 初始化
3. 主循环
4. 连接剩余部分
5. 返回头节点
链表入门题目-两个链表相加
编辑
核心思想与图解
代码实现与逐行解析
变量初始化
创新的 for 循环结构
循环体内部
收尾工作
链表入门题目-划分链表
核心思想与图解
代码实现与逐行解析
1. 初始化 (步骤1)
2. 遍历与拆分 (步骤2)
3. 拼接 (步骤3)
单双链表及其反转-堆栈诠释
1)按值传递、按引用传递
标准答案:Java 永远是“按值传递” (Pass by Value)。
这个结论常常会引起混淆,所以我们需要通过代码和内存图来精确理解它的含义:
-
传递基本数据类型时:传递的是值的副本。
-
传递对象类型时:传递的是引用的副本(可以理解为内存地址的副本)。
代码与内存分析
public class ListReverse {// --- 用于演示的自定义类 ---public static class Number {public int val;public Number(int v) { this.val = v; }}// --- Case 1: 基本数据类型 ---public static void f(int a) {a = 0; // 试图修改a}// --- Case 2: 对象类型 ---public static void g1(Number b) {b = null; // 试图将引用置空}public static void g2(Number b) {b.val = 6; // 试图通过引用修改对象内部的值}// --- Case 3: 数组类型(也是对象) ---public static void g3(int[] c) {c = null; // 试图将引用置空}public static void g4(int[] c) {c[0] = 100; // 试图通过引用修改数组内容}public static void main(String[] args) {// ... (调用代码)}
}Case 1: 基本数据类型
// main函数中
int a = 10;
f(a);
System.out.println(a); // 输出结果?-
分析:当调用 f(a) 时,Java 复制了 a 的值(也就是10),并将这个副本传递给了 f 方法。f 方法内部的所有操作,都是针对这个副本进行的。main 函数中的原始 a 变量丝毫不会受到影响。
-
结果:10
Case 2: 自定义对象类型
// main函数中
Number b = new Number(5); // b 是一个引用,指向堆中值为5的Number对象
g1(b);
System.out.println(b.val); // 输出结果?g2(b);
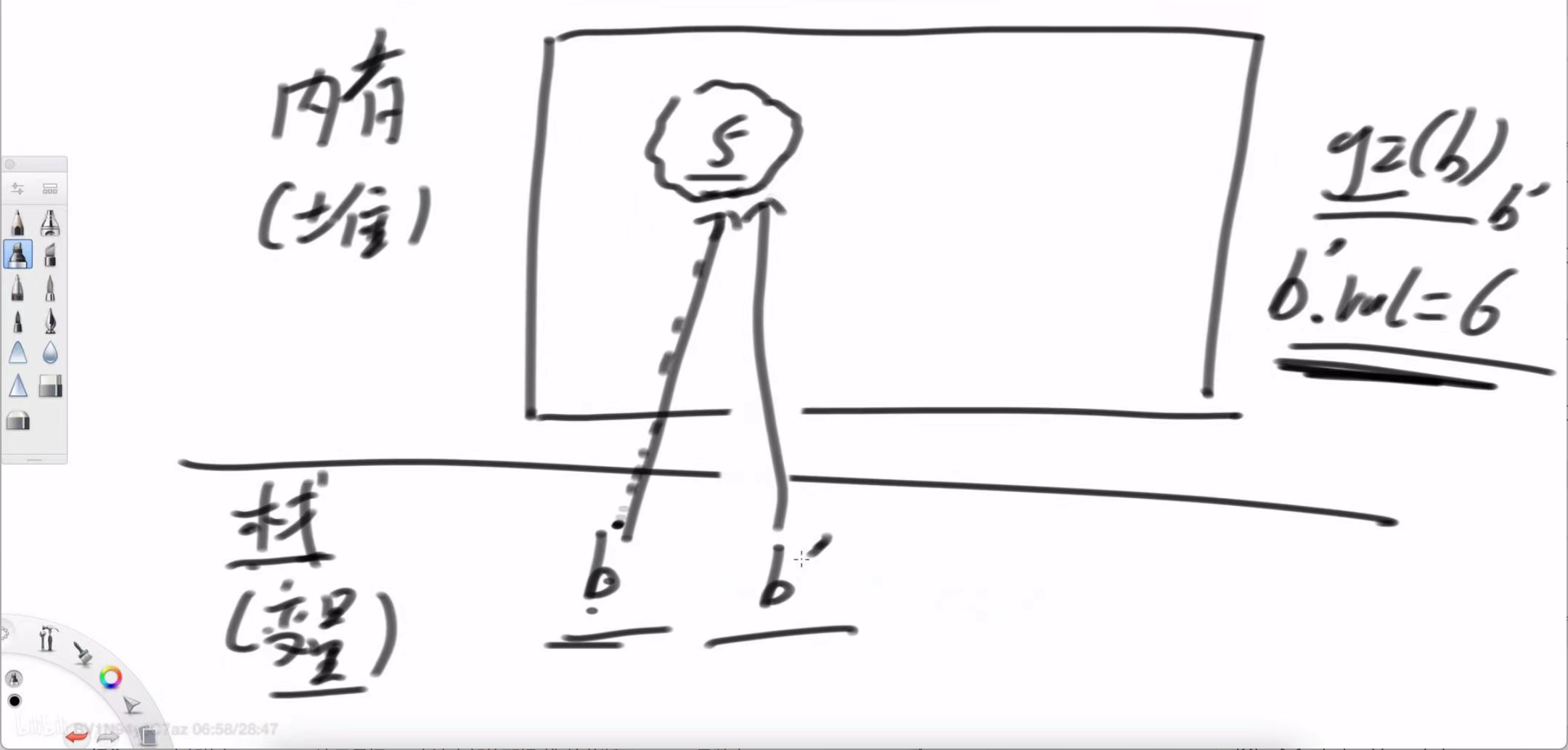
System.out.println(b.val); // 输出结果?这里是理解的关键。变量 b 存储在栈 (Stack) 中,它是一个引用,像一根线,指向堆 (Heap) 内存中实际的 Number 对象。
-
调用 g1(b):
-
传递:Java 复制了 b 的引用(地址值),并将这个地址副本传递给了 g1。现在 main 中的 b 和 g1 中的 b 这两根“线”都指向同一个堆中的 Number(5) 对象。
-
操作:g1 内部执行 b = null,这只是把 g1 方法内部的那根“线”给剪断了。main 函数中的那根“线” b 依然牢牢地指向 Number(5) 对象。
-
结果:5
-
-
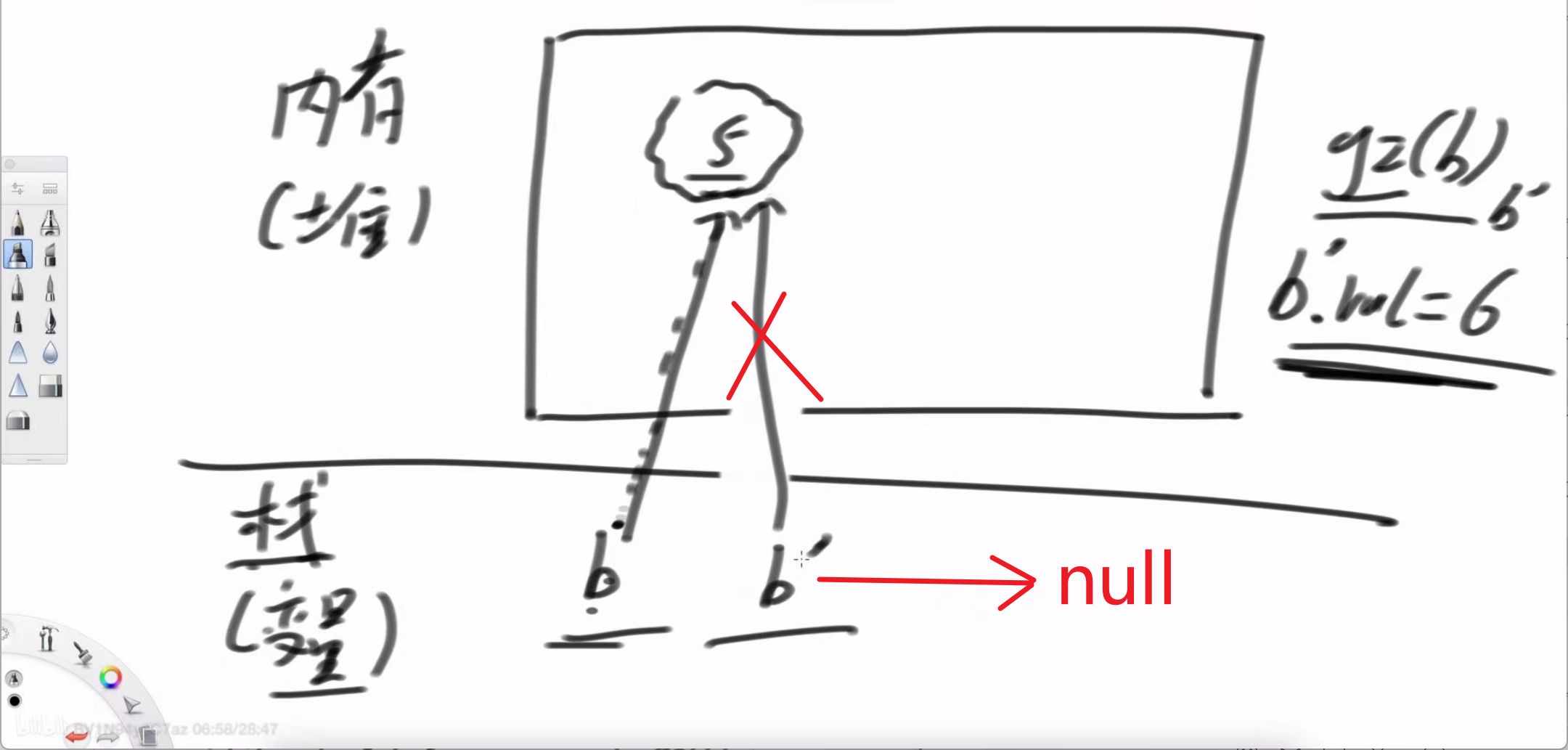
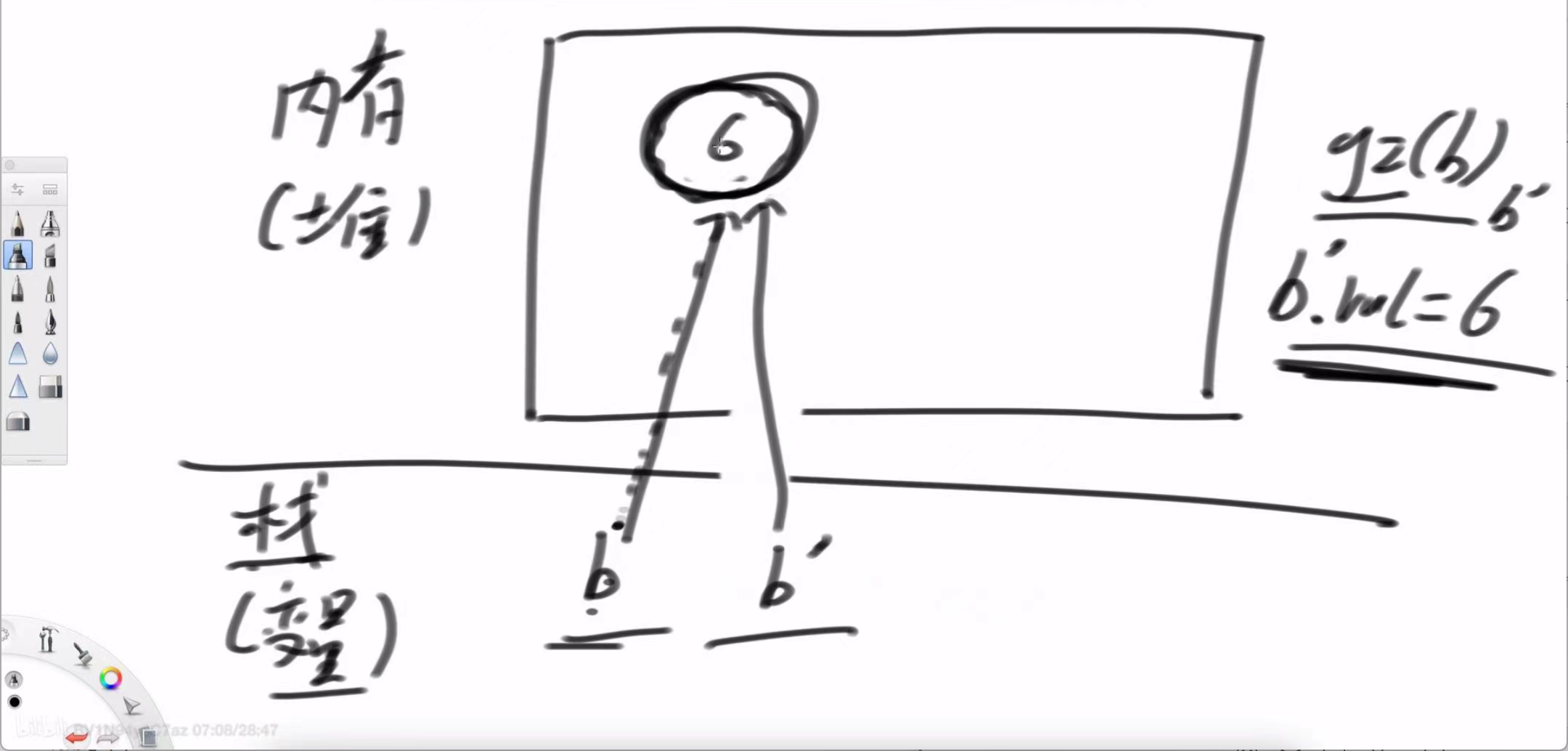
调用 g2(b):
-
传递:同样,g2 获得了指向 Number(5) 对象的地址副本。
-
操作:g2 内部执行 b.val = 6。它顺着自己手里的这根“线”,找到了堆中的 Number 对象,并把对象内部的 val 值从 5 修改为了 6。
-
内存变化:堆中的同一个对象被修改了。
-
结果:main 函数中的 b 依然指向这个被修改过的对象,所以输出 6。
-
-
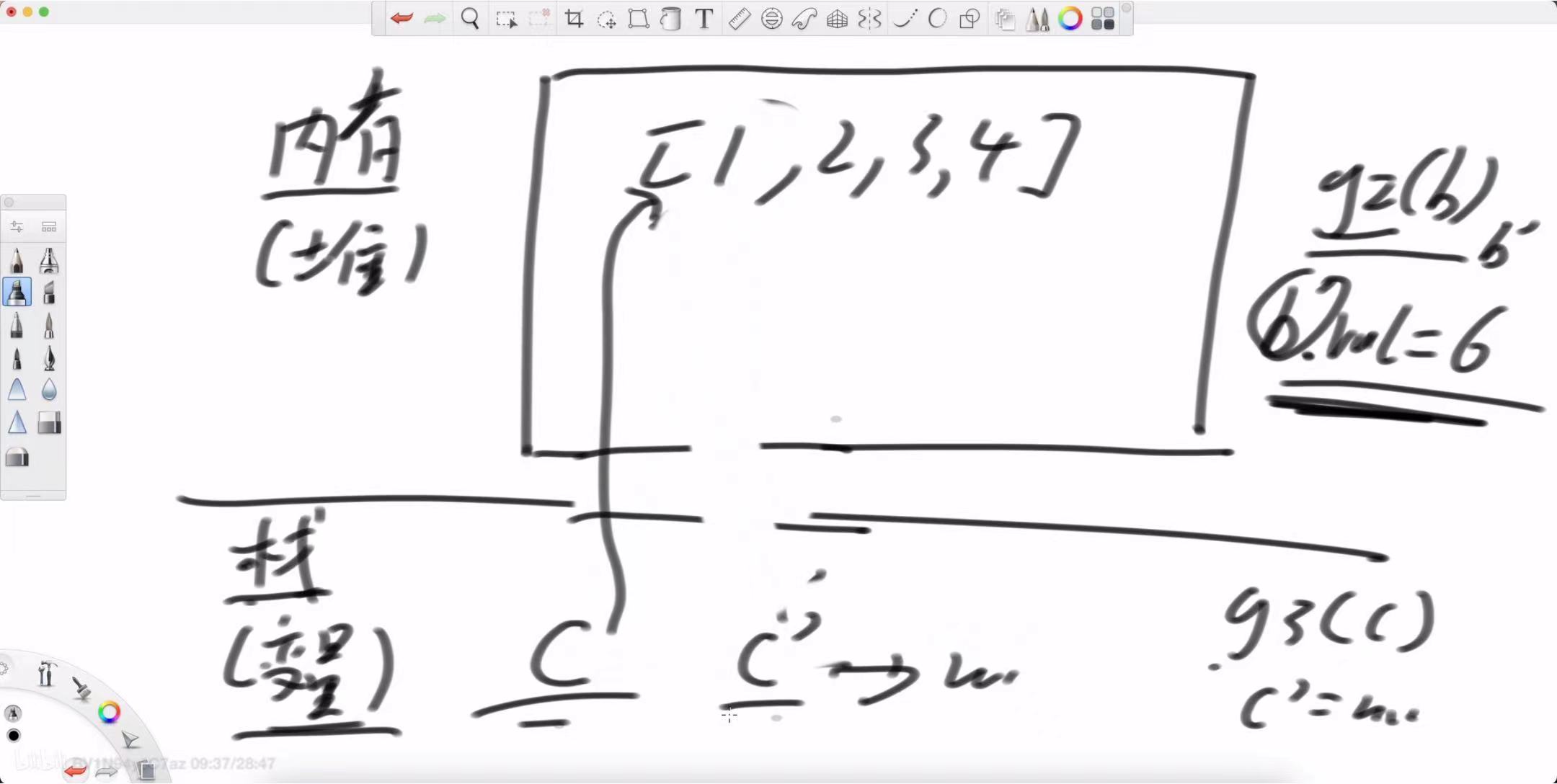
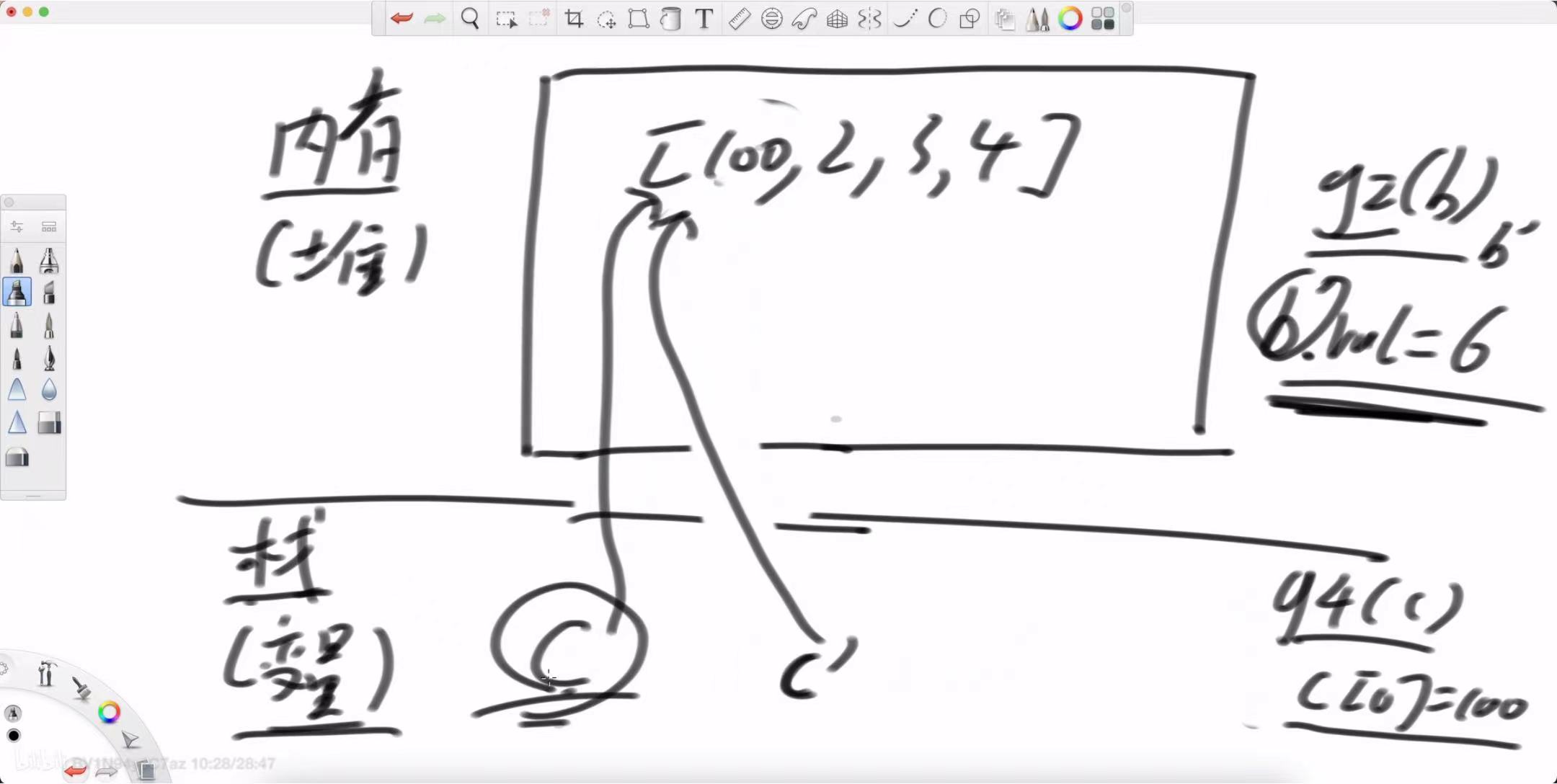
Case 3: 数组类型
数组在 Java 中也是对象,所以它的行为和 Case 2 完全一致。
// main函数中
int[] c = {1, 2, 3, 4}; // c 是一个引用,指向堆中的数组对象
g3(c);
System.out.println(c[0]); // 输出结果?g4(c);
System.out.println(c[0]); // 输出结果?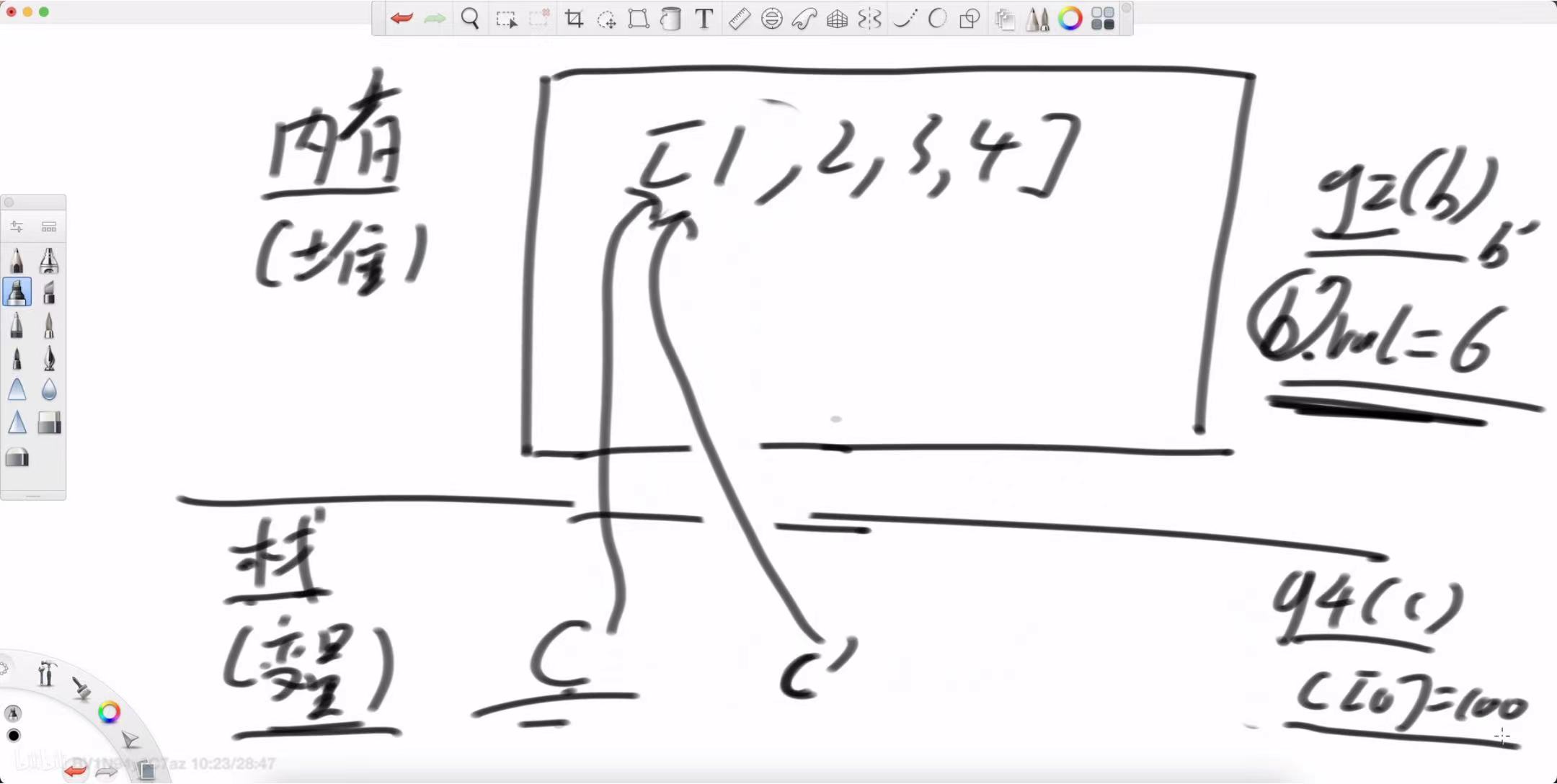
-
调用 g3(c):将 c 这个引用置为 null,同样只影响 g3 内部的副本,main 中的 c 不变。结果:1
-
调用 g4(c):通过引用的副本找到了堆上的数组对象,并修改了它的第一个元素。结果:100
结论
-
函数无法改变基本数据类型实参的值。
-
函数无法让对象类型的实参引用一个新的对象。(如 g1 和 g3)
-
函数可以通过引用副本,来修改实参指向的对象的内部状态。(如 g2 和 g4)
这个结论是进行一切链表操作(节点交换、指针反转)的基石。只有深刻理解了这一点,我们才能在后续的链表反转中游刃有余。
2)单链表、双链表的定义
单(向)链表 (Singly Linked List)
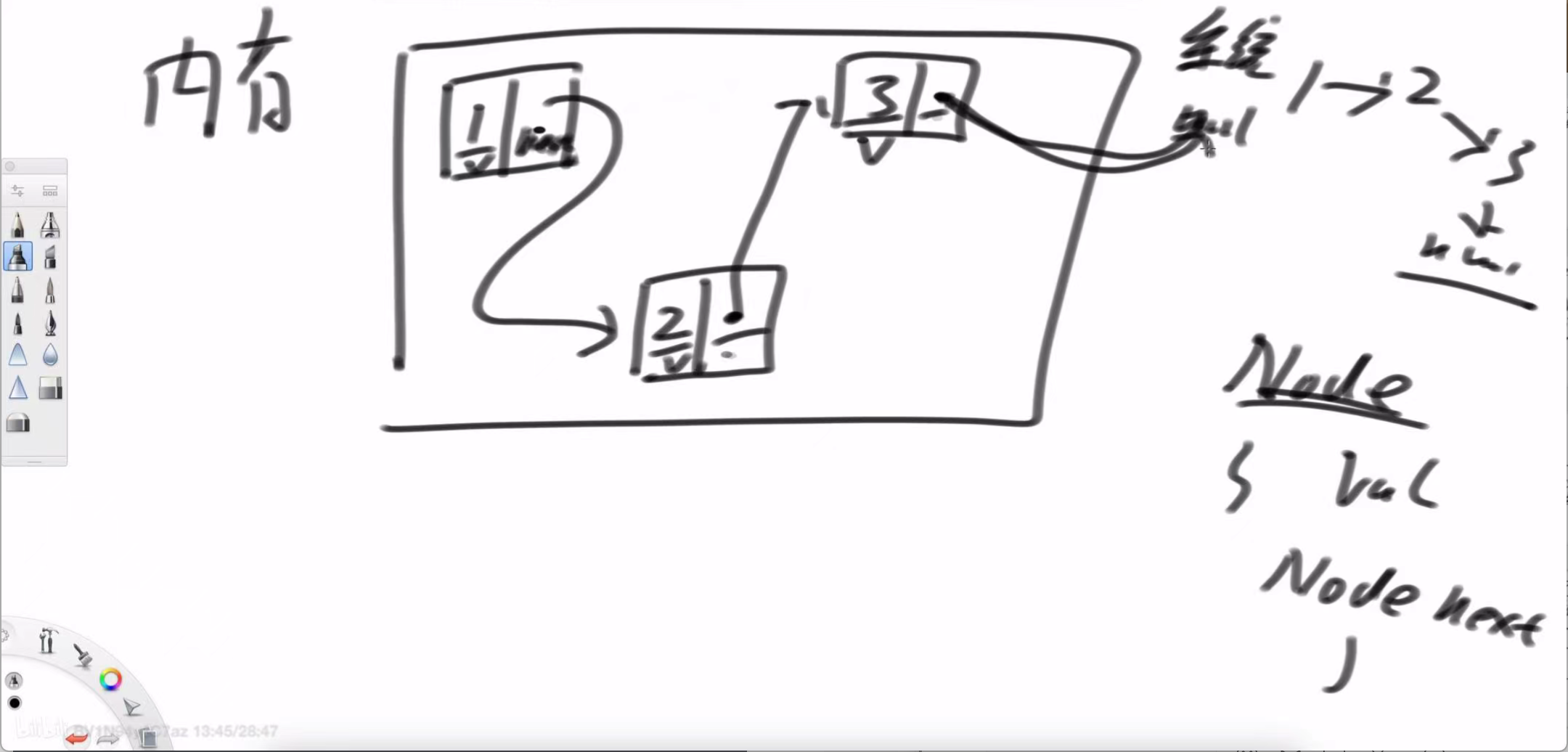
上图就是单链表在内存中的真实面貌:
-
离散存储:与数组不同,链表的每个节点(Node)在内存中是零散分布的,它们不要求地址连续。
-
指针连接:节点之间的逻辑顺序,完全依靠每个节点内部的一个**指针(或引用)**来维系。
单链表节点的构成:
根据左老师的板书,一个标准的单链表节点 Node 包含两个核心部分:
-
val:节点自身存储的值。
-
Node next:一个指向下一个节点的引用。
单向链表意思就是能指向下一个节点
当 next 引用指向 null 时,就代表这是链表的最后一个节点。通过从头节点(head)开始,顺着 next 引用不断地“跳转”,我们就能遍历整个链表,形成 1 -> 2 -> 3 -> null 这样的逻辑序列。
Java 代码定义:
public class SinglyNode {public int val; // 节点值public SinglyNode next; // 指向下一个节点的引用public SinglyNode(int val) {this.val = val;}
}双(向)链表 (Doubly Linked List)
双链表是在单链表的基础上,为了实现更灵活的操作而进行的扩展。
-
双向连接:它与单链表最大的区别在于,每个节点不仅知道自己的“下一个”是谁,还知道自己的“上一个”是谁。
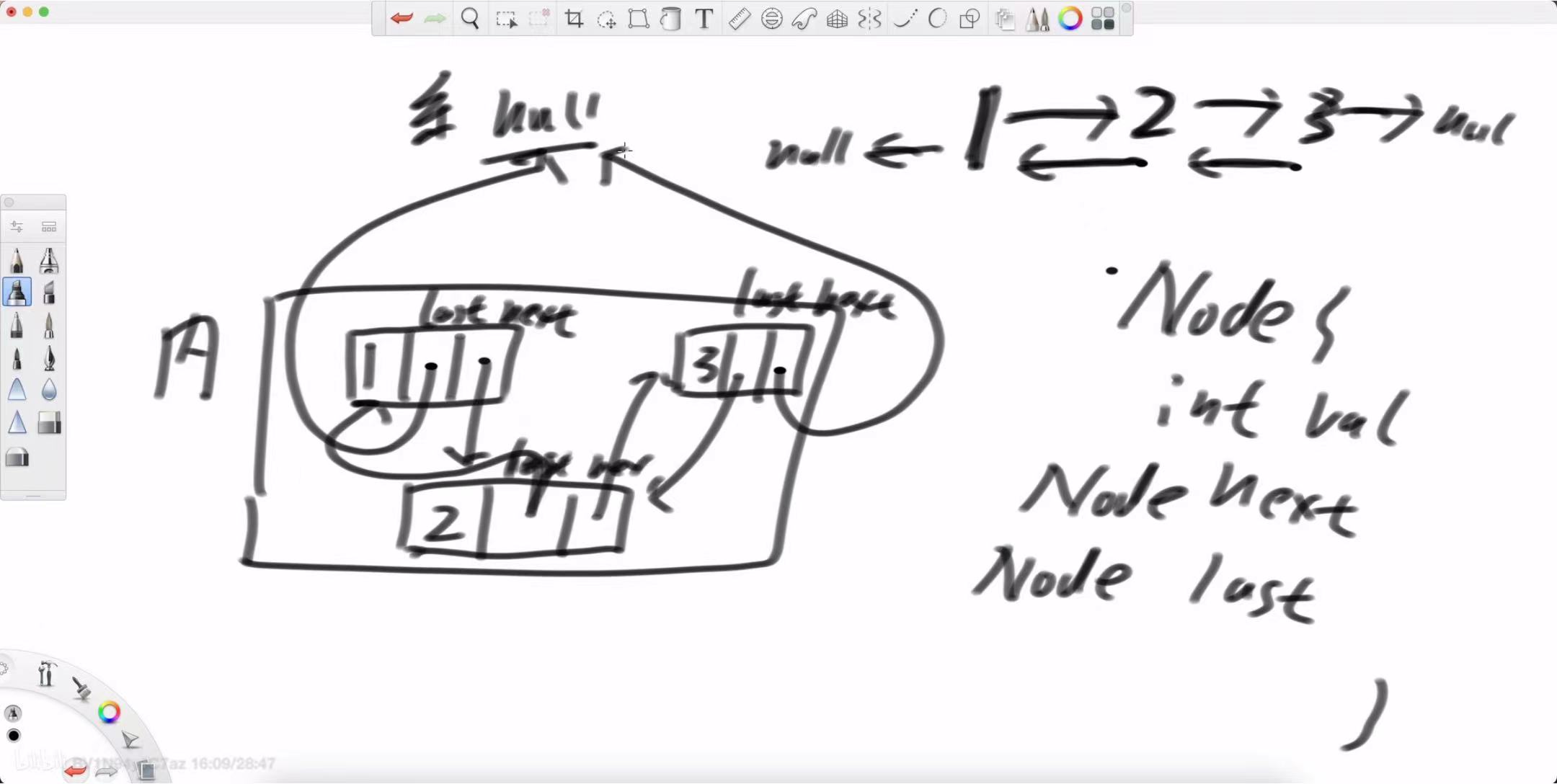
双链表节点的构成:
一个标准的双链表节点 Node 包含三个核心部分:
-
int val:节点自身存储的值。
-
Node next:一个指向下一个节点的引用。
-
Node last(或 prev):一个指向上一个节点的引用。
这种结构使得链表的遍历可以是双向的,即 null <- 1 <-> 2 <-> 3 -> null。
-
头节点:它的 last(或 prev)引用指向 null。
-
尾节点:它的 next 引用指向 null。
Java 代码定义:
public class DoublyNode {public int val; // 节点值public DoublyNode next; // 指向下一个节点的引用public DoublyNode last; // 指向上一个节点的引用public DoublyNode(int val) {this.val = val;}
}3) 根据反转功能,彻底从系统角度解释链表是如何调整的
206. 反转链表 - 力扣(LeetCode)
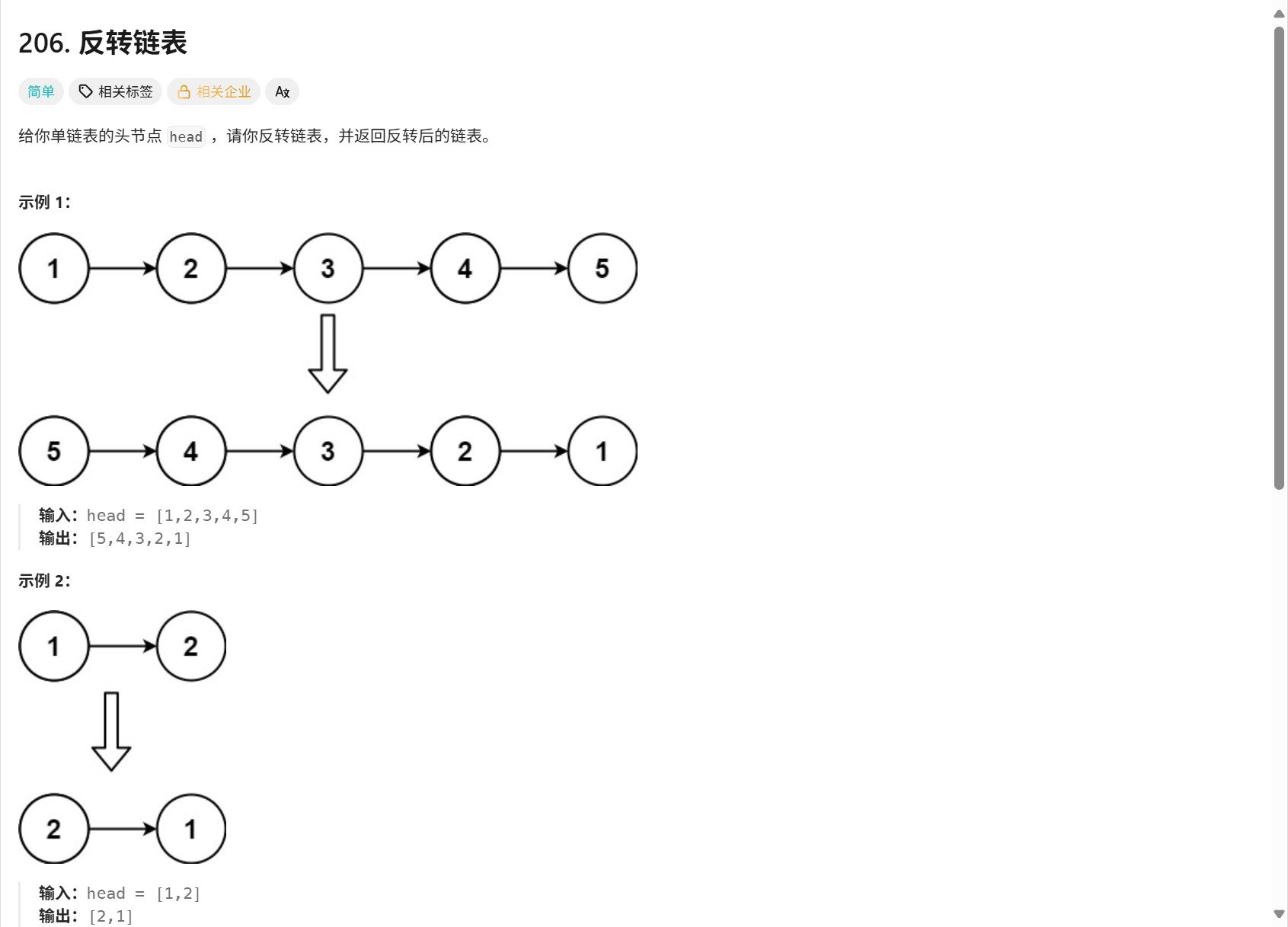
我们的目标是将一个 1 -> 2 -> 3 -> null 的链表,在内存中原地调整为 null <- 1 <- 2 <- 3,并返回新的头节点 3。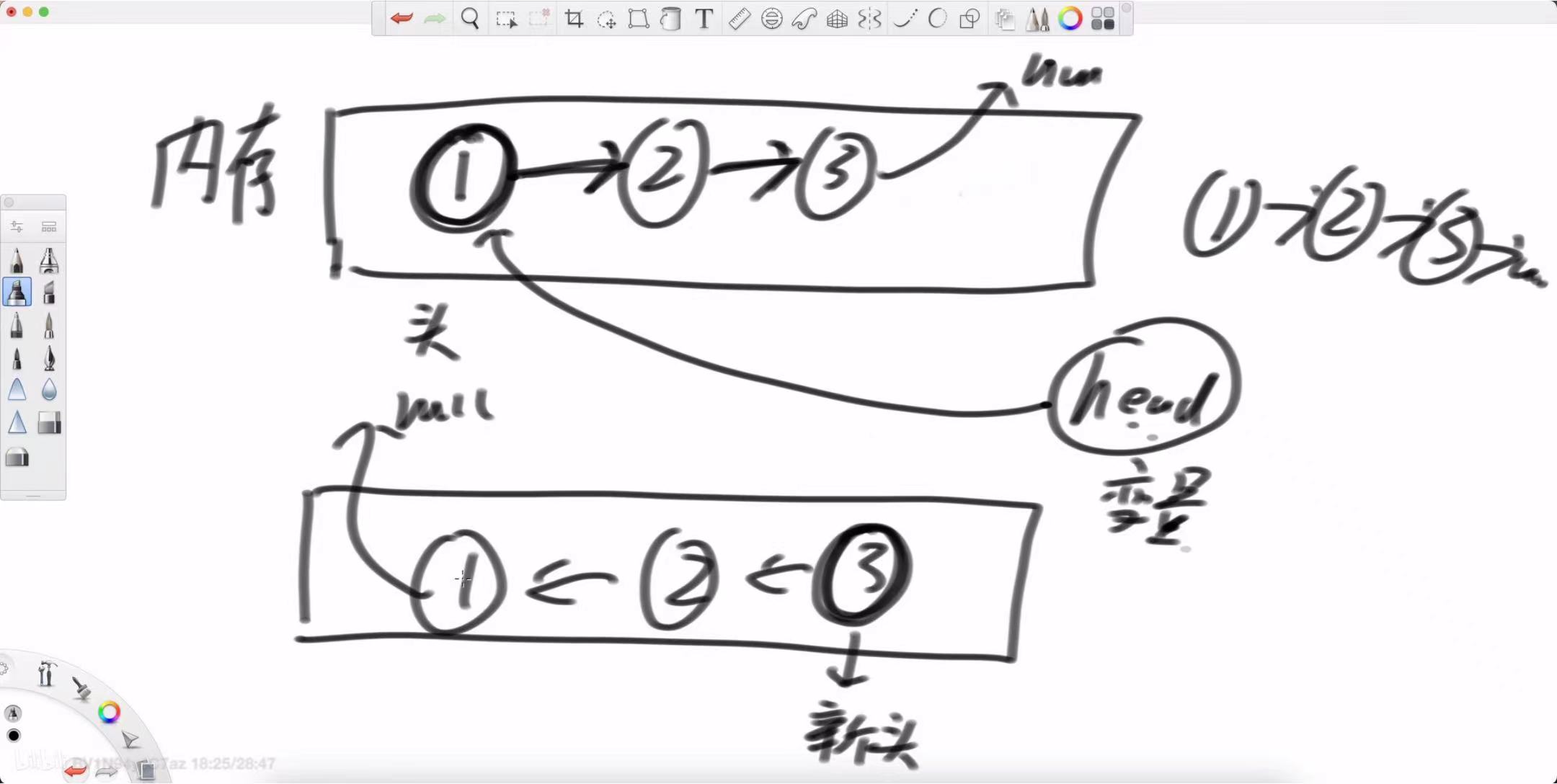
核心思路:迭代反转
我们将遍历整个链表,对于每一个当前节点,我们要做的核心操作就是将它的 next 指针反向。这个过程不能一蹴而就,因为它会“断开”我们与后续节点的连接。因此,我们需要借助额外的引用变量来“保护”现场,一步步地挪动指针。
左老师在白板上为我们画出了三个至关重要的引用变量,它们位于栈内存中,负责在循环的每一步中,指挥堆内存里的节点如何“掉头”:
-
pre (previous): 指向上一个已经处理好的节点。在反转后的链表中,它将是当前节点的 next。初始时,头节点的前一个节点是 null,所以 pre 初始化为 null。
-
head (current): 指向我们当前正在处理的节点。
-
next: 临时存放当前节点的下一个节点。这是至关重要的一步,因为我们一旦修改了 head.next,就会丢失与原始链表后续部分的连接,所以必须提前把它保存下来。
代码与内存逐行解析
让我们将代码与左老师的白板推演结合起来,一步步看懂内存中到底发生了什么。
// LeetCode链接: https://leetcode.cn/problems/reverse-linked-list/
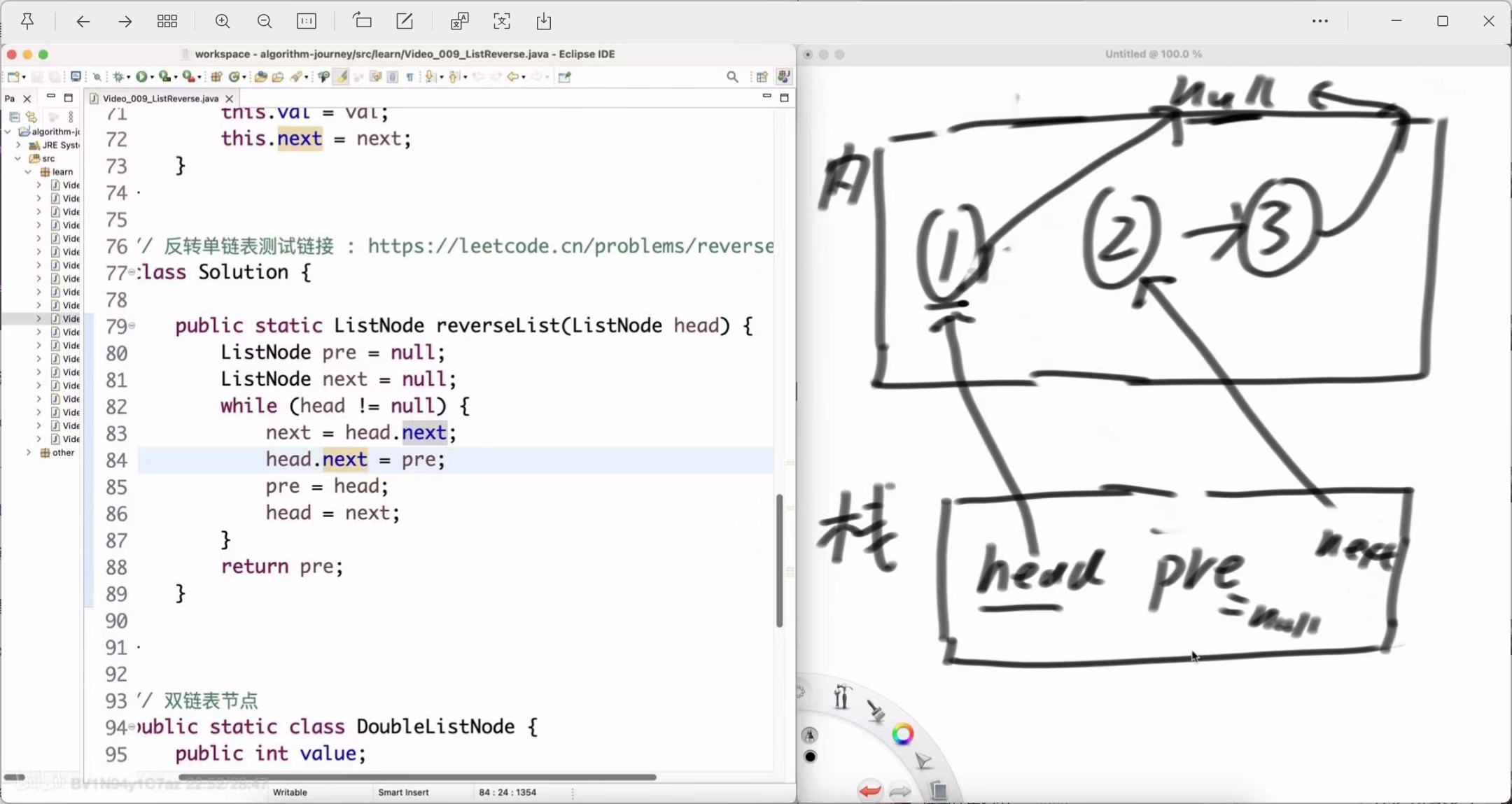
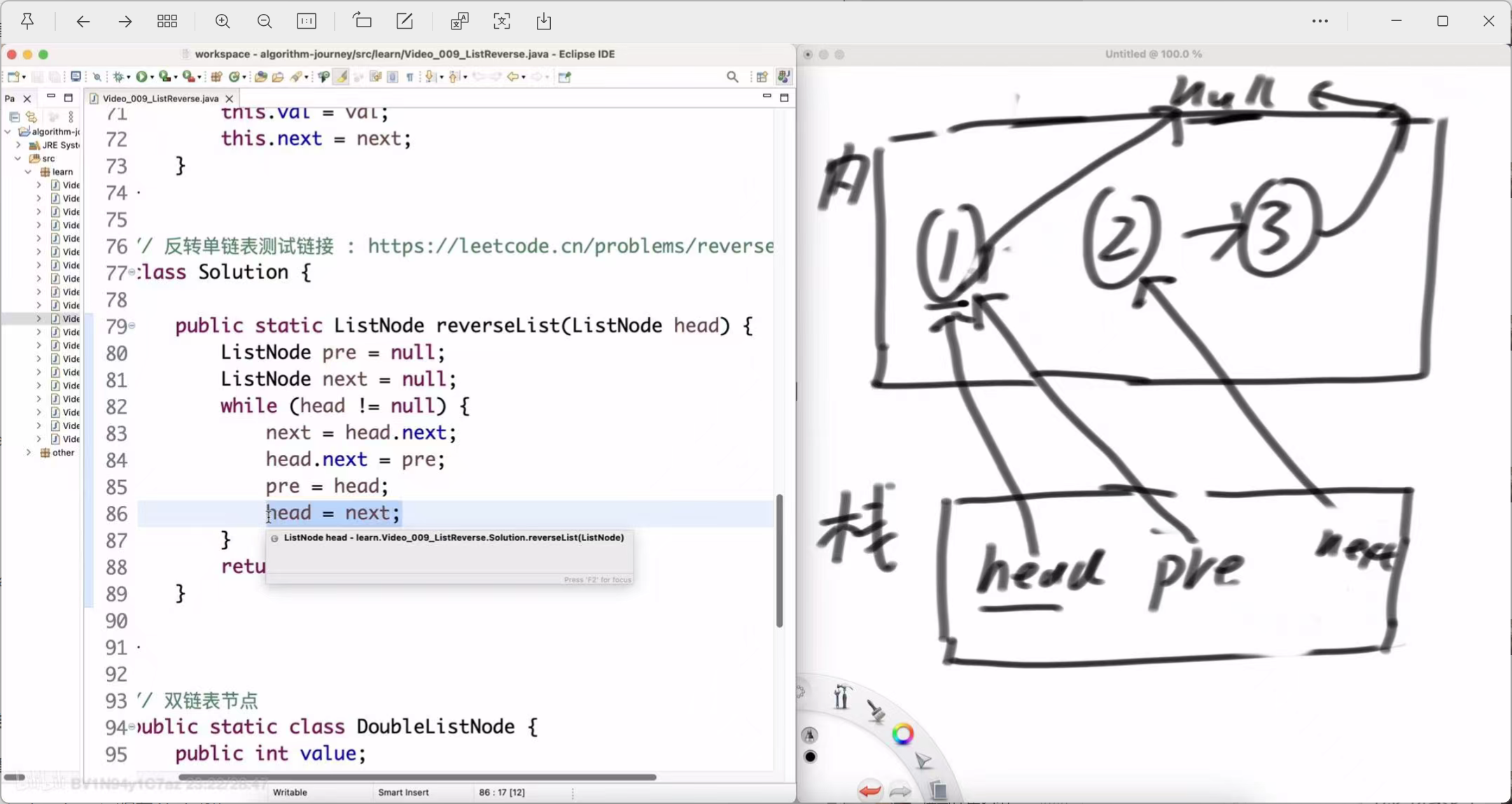
public static ListNode reverseList(ListNode head) {ListNode pre = null;ListNode next = null;while (head != null) {next = head.next; // 1. 保存下一个节点head.next = pre; // 2. 指针反转pre = head; // 3. pre 指针后移head = next; // 4. head 指针后移}return pre; // 循环结束后,pre就是新的头节点
}初始状态 (循环前)
-
head -> Node(1)
-
pre -> null
-
next -> null
-
内存:1 -> 2 -> 3 -> null
第一轮循环 (处理节点1)
-
next = head.next;
-
操作:保存节点1的下一个节点,即节点2。
-
状态:next -> Node(2)
-
-
head.next = pre;
-
操作:核心反转!将节点1的 next 指针从指向节点2,改为指向 pre (当前是null)。
-
状态:Node(1).next -> null。此时,原始的 1 -> 2 链接断开。
-
-
pre = head;
-
操作:pre 指针后移,指向我们刚刚处理完的节点1。
-
状态:pre -> Node(1)
-
-
head = next;
-
操作:head 指针后移,指向我们之前保存好的下一个节点2,准备开始下一轮循环。
-
状态:head -> Node(2)
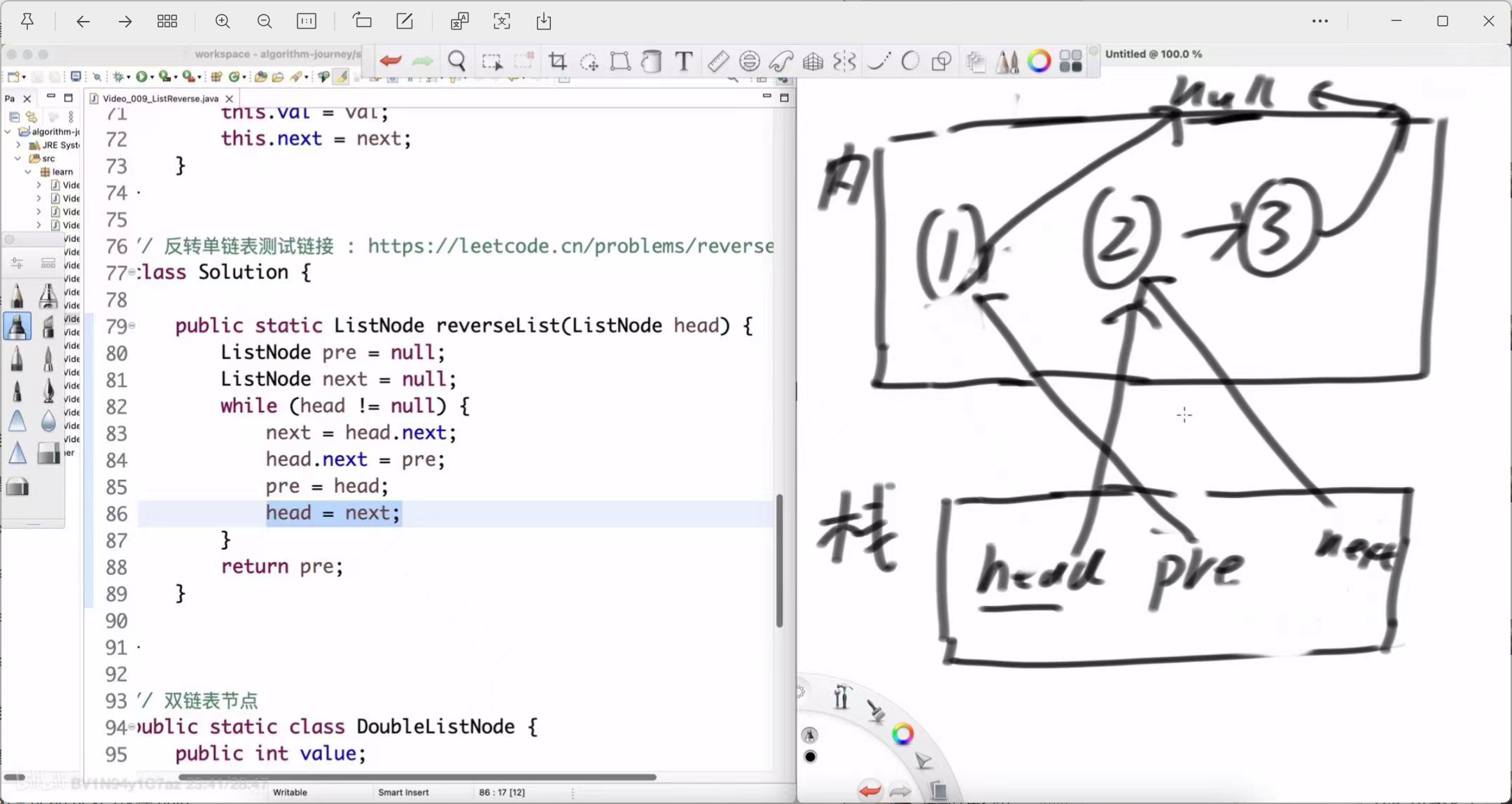
-
第一轮结束后:pre 指向1,head 指向2。反转好的部分是 1 -> null。
第二轮循环 (处理节点2)
-
next = head.next; (保存 Node(3))
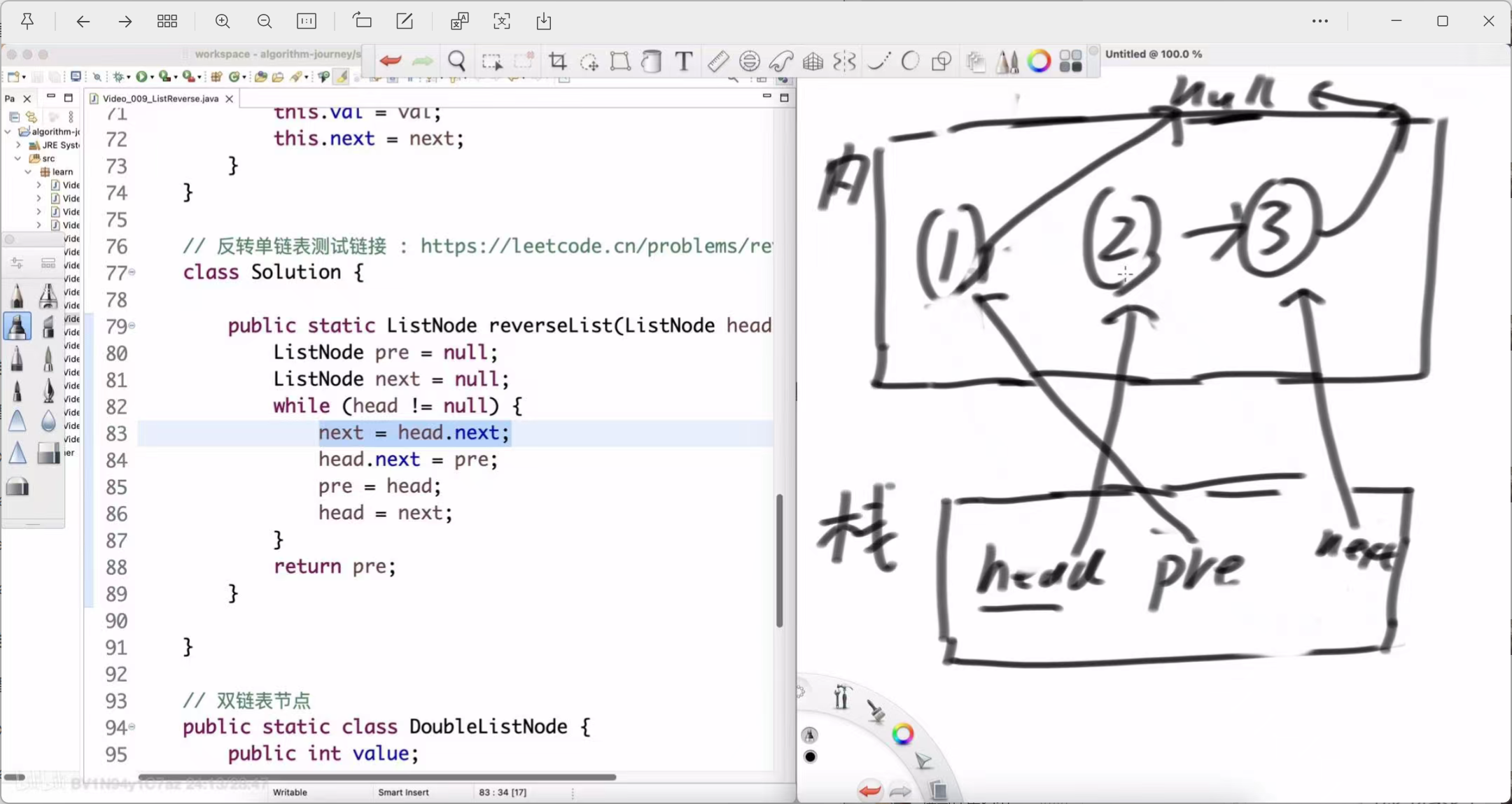
-
head.next = pre; (节点2的 next 指向节点1)
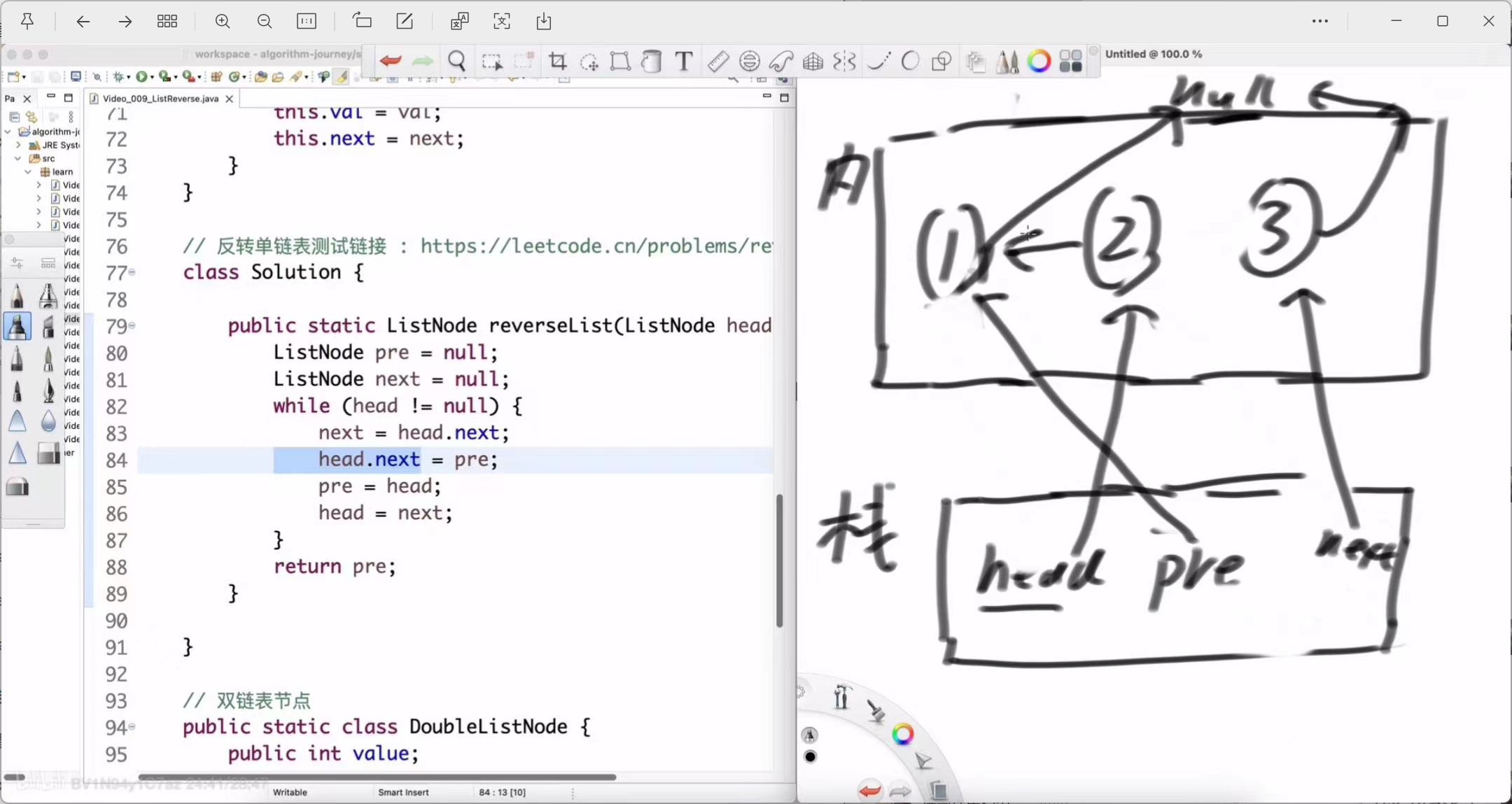
-
pre = head; (pre 移动到节点2)
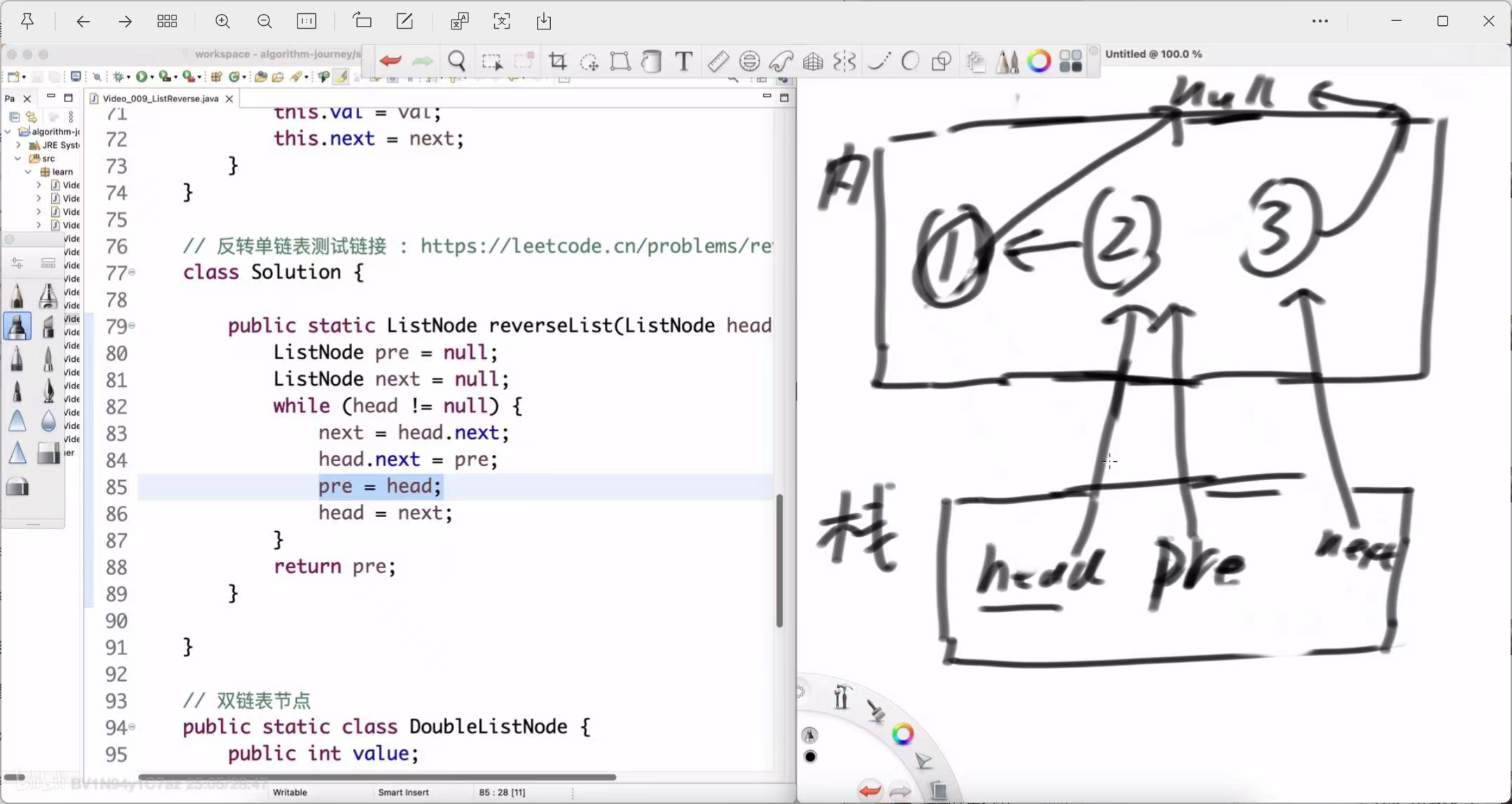
-
head = next; (head 移动到节点3)
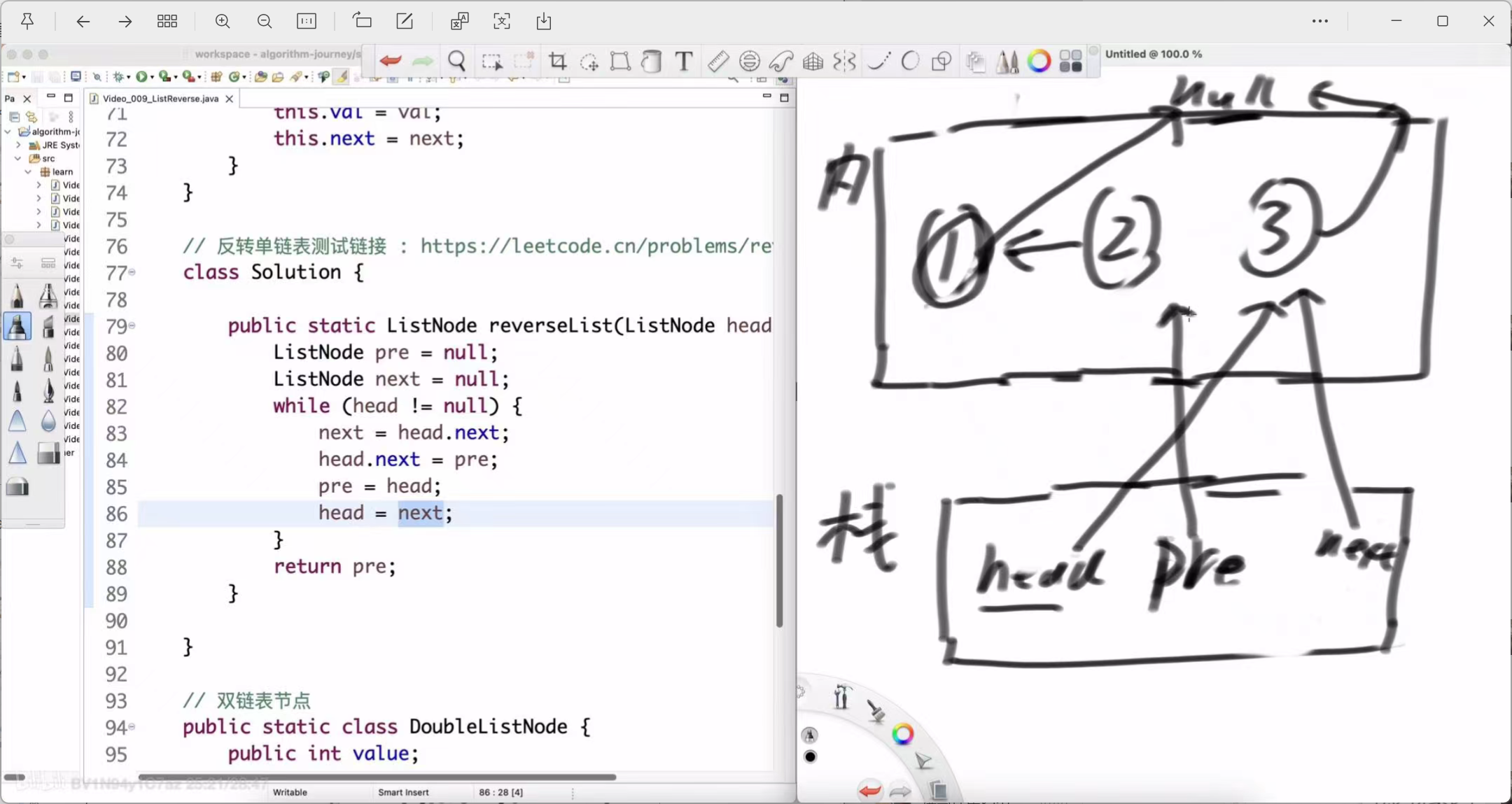
第二轮结束后:pre 指向2,head 指向3。反转好的部分是 2 -> 1 -> null。
第三轮循环 (处理节点3)
-
next = head.next; (保存 null)
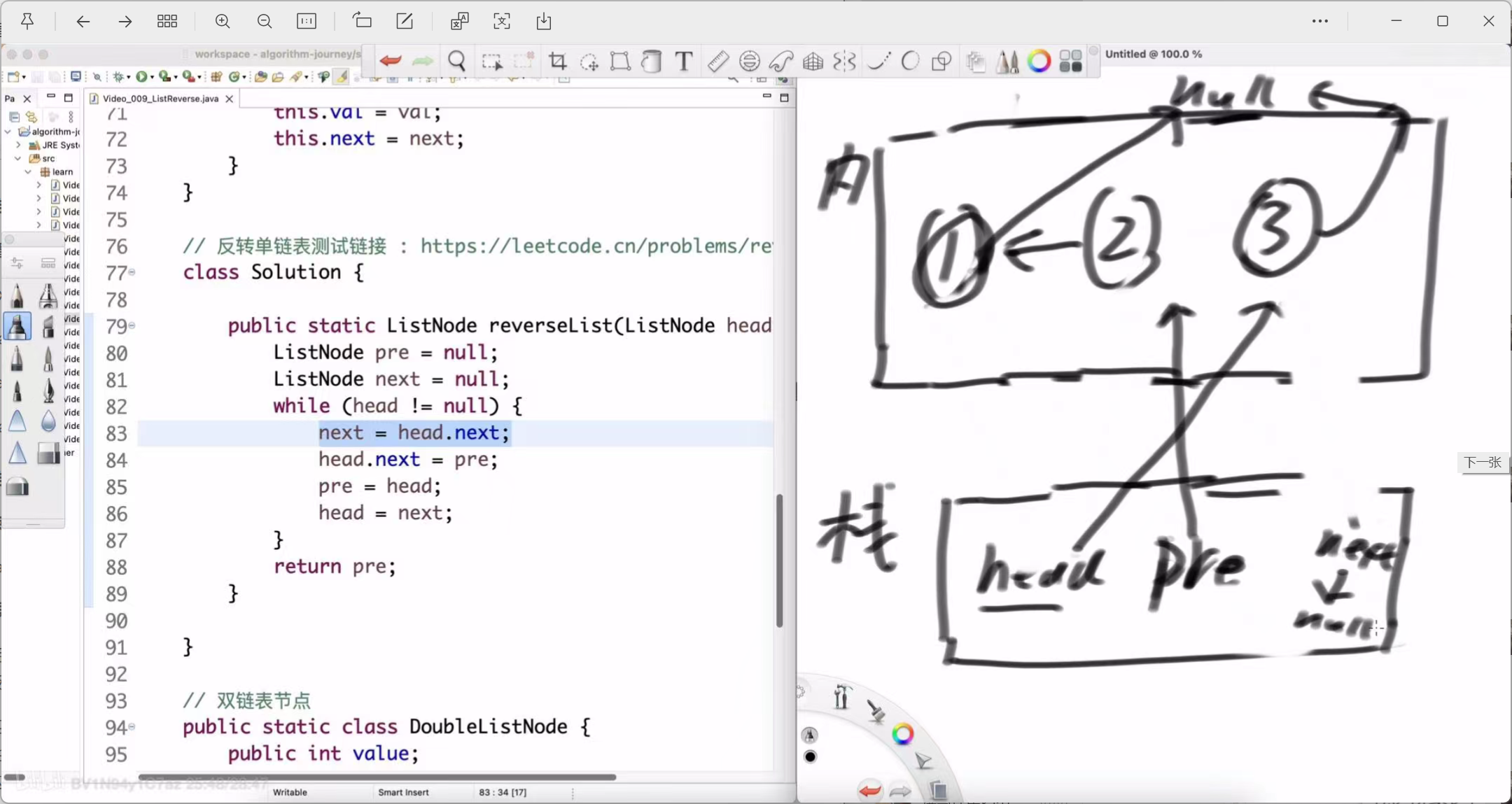
-
head.next = pre; (节点3的 next 指向节点2)
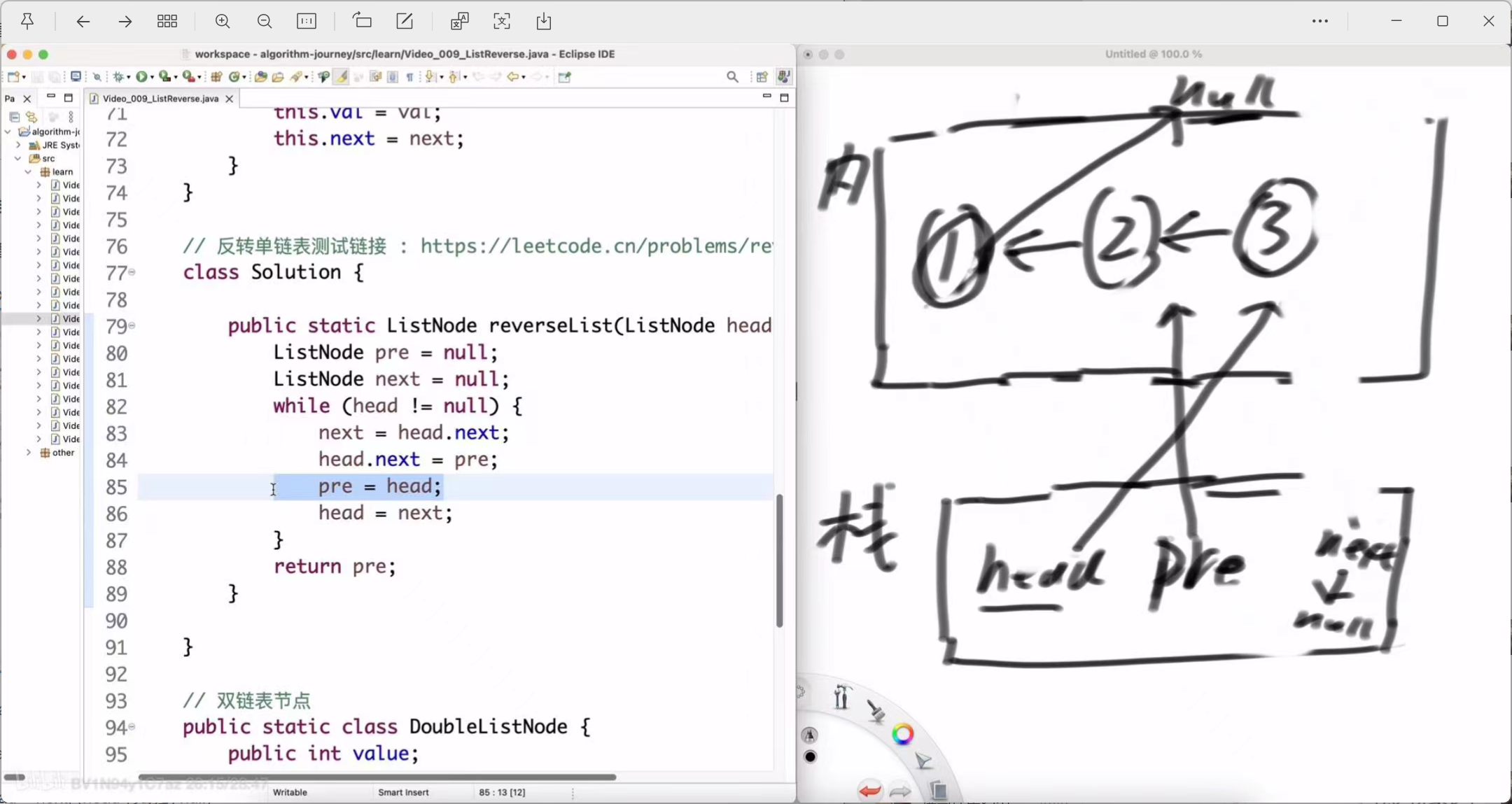
-
pre = head; (pre 移动到节点3)
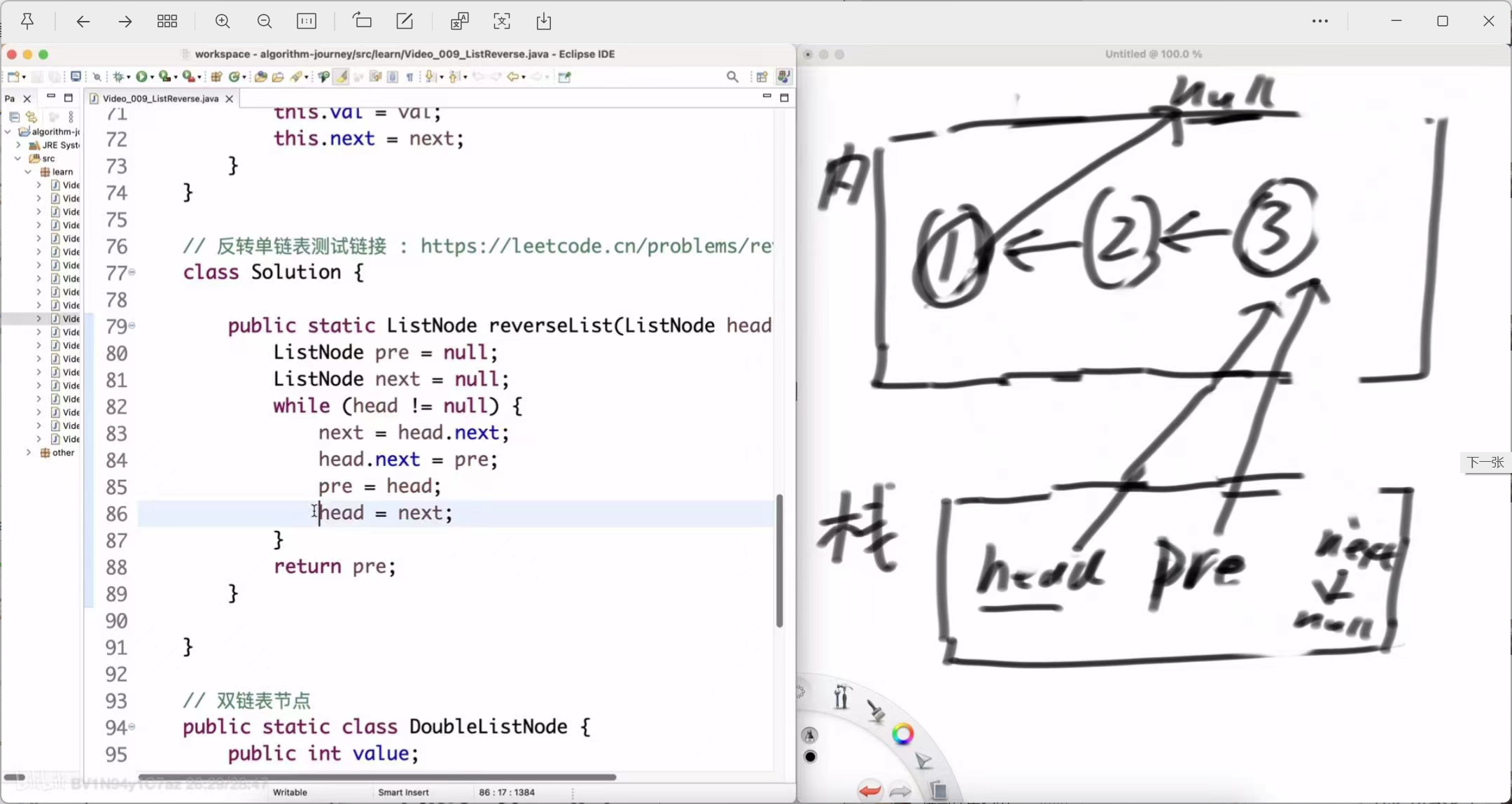
-
head = next; (head 移动到 null)
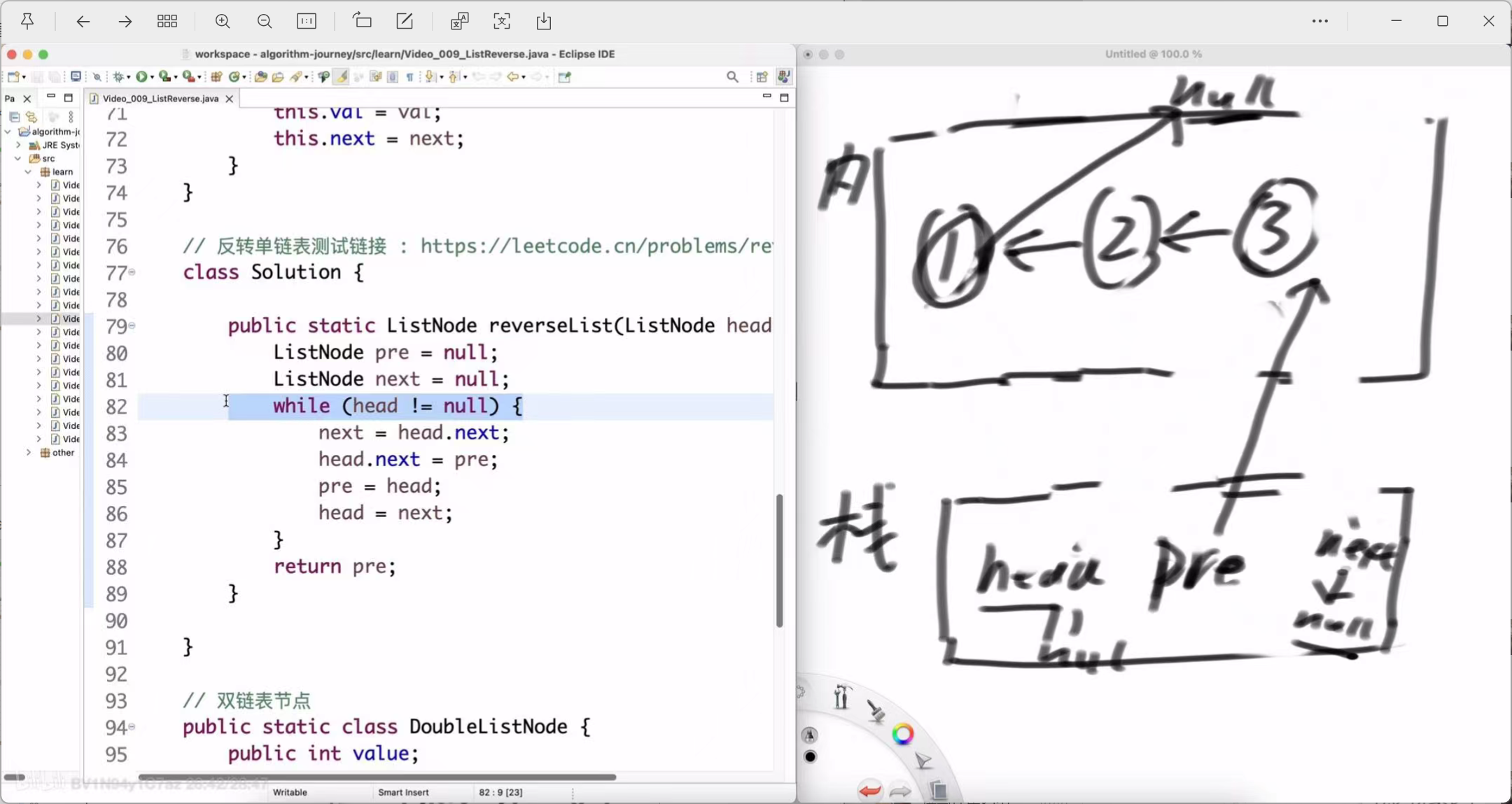
第三轮结束后:pre 指向3,head 指向 null。反转好的部分是 3 -> 2 -> 1 -> null。
循环结束
此时 head 已经为 null,while 循环条件不满足,循环终止。
返回结果
函数最后 return pre;。为什么要返回 pre?因为当循环结束时,head 已经走到了 null,而 pre 正好停留在反转前链表的最后一个节点,也就是我们反转后链表的新头节点——节点3。
通过这四步精妙的指针操作,我们就在 O(N) 的时间复杂度和 O(1) 的空间复杂度下,完成了单链表的原地反转。这个过程完美地诠释了如何通过栈上的几个引用变量,去“编排”和“调度”堆内存中数据结构的形态。
链表入门题目-合并两个有序链表
21. 合并两个有序链表 - 力扣(LeetCode)
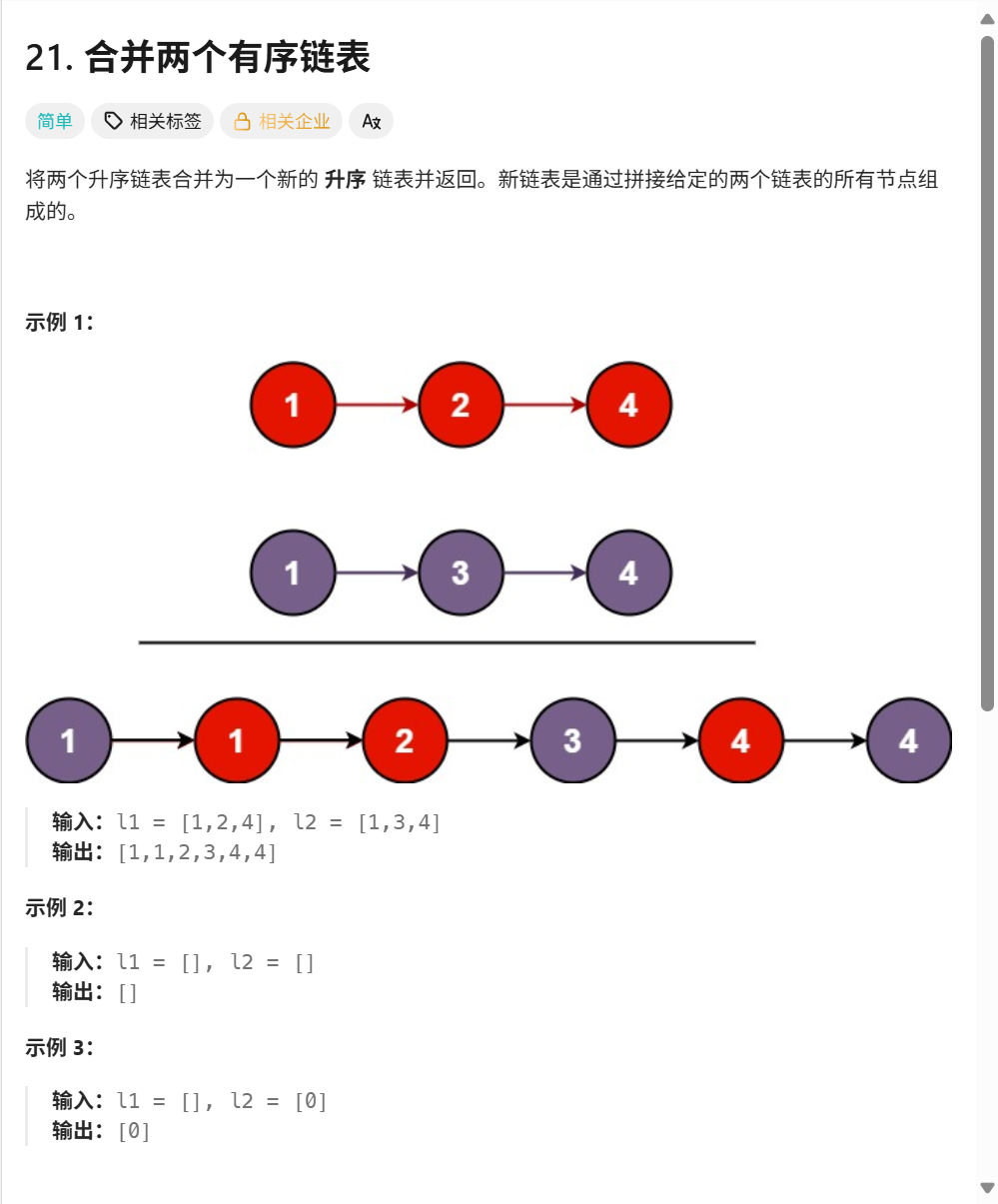

在掌握了链表的基本操作和反转之后,我们来挑战一个在面试中出镜率极高的问题:合并两个有序链表。这个问题同样是检验 coding 基本功的绝佳考题。
题目要求:将两个升序链表合并为一个新的升序链表并返回。新链表是通过拼接给定的两个链表的所有节点组成的。
核心思想与图解
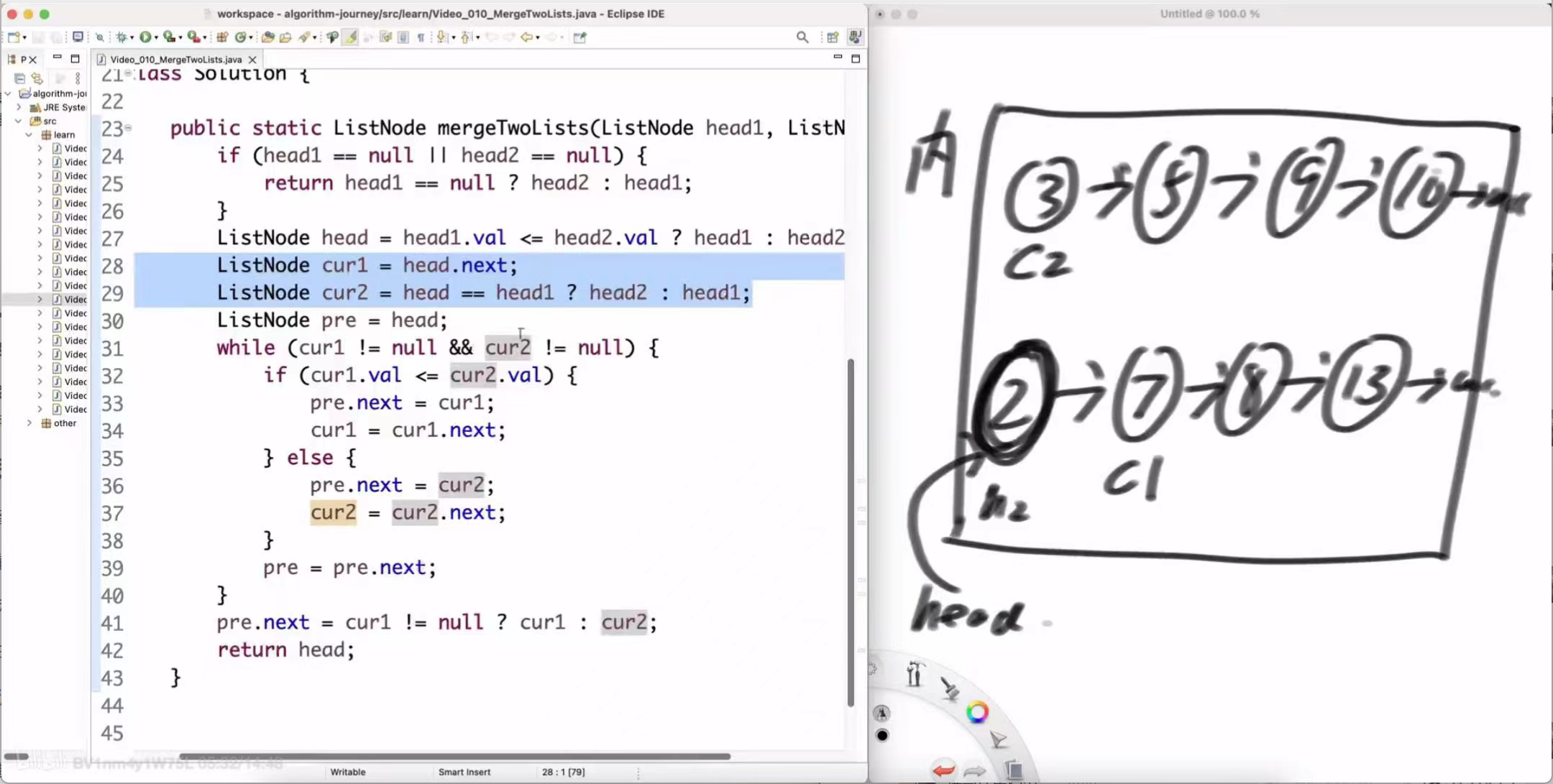
算法的整体思路非常直观,类似于归并排序中的“合并”步骤:
-
比较两个链表的头节点,值较小的那个作为合并后链表的头节点。
-
用两个指针 cur1 和 cur2 分别指向两个链表的当前待比较节点。
-
同时,需要一个 pre 指针,始终指向合并后链表的尾节点。
-
在循环中,不断比较 cur1 和 cur2 的值,将较小的那个节点连接到 pre 的后面,然后移动 pre 和被选中的那个指针。
-
当其中一个链表遍历结束后,将另一个链表剩下的部分直接拼接到 pre 的后面即可。
代码实现与逐行解析
我们将结合代码和白板图,深入理解指针在内存中是如何移动和拼接的。
// 测评链接: https://leetcode.cn/problems/merge-two-sorted-lists/
public static ListNode mergeTwoLists(ListNode head1, ListNode head2) {// 1. 处理边界条件if (head1 == null || head2 == null) {return head1 == null ? head2 : head1;}// 2. 确定头节点,并初始化指针ListNode head = head1.val <= head2.val ? head1 : head2;ListNode cur1 = head.next;ListNode cur2 = head == head1 ? head2 : head1;ListNode pre = head;// 3. 主循环:合并公共部分while (cur1 != null && cur2 != null) {if (cur1.val <= cur2.val) {pre.next = cur1; // pre的下一个连上cur1cur1 = cur1.next; // cur1后移} else {pre.next = cur2; // pre的下一个连上cur2cur2 = cur2.next; // cur2后移}pre = pre.next; // pre后移到新链表的尾部}// 4. 连接剩余部分pre.next = cur1 != null ? cur1 : cur2;// 5. 返回头节点return head;
}1. 边界条件处理
if (head1 == null || head2 == null) {return head1 == null ? head2 : head1;
}如果任意一个链表为空,那么合并的结果就是另一个链表,直接返回即可。
2. 初始化
ListNode head = head1.val <= head2.val ? head1 : head2;
ListNode cur1 = head.next;
ListNode cur2 = head == head1 ? head2 : head1;
ListNode pre = head;这是算法的初始准备阶段,也是最需要细心的地方:
-
head:这是我们最终要返回的合并后链表的头。它被设定为 head1 和 head2 中值较小的那个。这个 head 变量一旦确定,就不再改变。
-
pre:尾指针。初始时,既然 head 已经是合并链表的第一个节点,那么 pre 自然也指向 head。
-
cur1 和 cur2:工作指针。它们需要指向两个链表下一个待比较的节点。
-
如果 head 来自 head1,那么 cur1 就应该是 head1.next,而 cur2 依然是 head2。
-
反之亦然。
-
这里的 cur1 = head.next; 和 cur2 = head == head1 ? head2 : head1; 是一个非常精巧的写法,实现了上述逻辑。
-
3. 主循环
while (cur1 != null && cur2 != null) {if (cur1.val <= cur2.val) {pre.next = cur1;cur1 = cur1.next;} else { // cur1.val > cur2.valpre.next = cur2;cur2 = cur2.next;}pre = pre.next;
}这是算法的核心,只要两个链表都还有剩余节点,就一直执行:
-
比较:比较 cur1 和 cur2 的值。
-
拼接:将值较小的那个节点(比如是 cur1)拼接到 pre 的后面 (pre.next = cur1;)。
-
移动工作指针:被选中的那个工作指针向后移动 (cur1 = cur1.next;)。
-
移动尾指针:pre 必须移动到刚刚拼接好的新尾部 (pre = pre.next;),为下一次拼接做准备。这一步至关重要,也最容易被遗忘。
4. 连接剩余部分
pre.next = cur1 != null ? cur1 : cur2;当 while 循环结束时,意味着 cur1 或 cur2 中至少有一个变成了 null。此时,另一个链表可能还有剩余的节点。因为原链表是有序的,所以这些剩余节点的值肯定都比已合并链表的所有节点的值要大。我们只需将 pre(当前合并链表的尾巴)的 next 指向这个剩余链表的头即可。
5. 返回头节点
return head;返回我们在第二步就保存好的、固定不变的头节点。
通过以上步骤,我们就在 O(M+N) 的时间复杂度和 O(1) 的空间复杂度下,完成了两个有序链表的合并。
链表入门题目-两个链表相加
leecode 2.两数相加
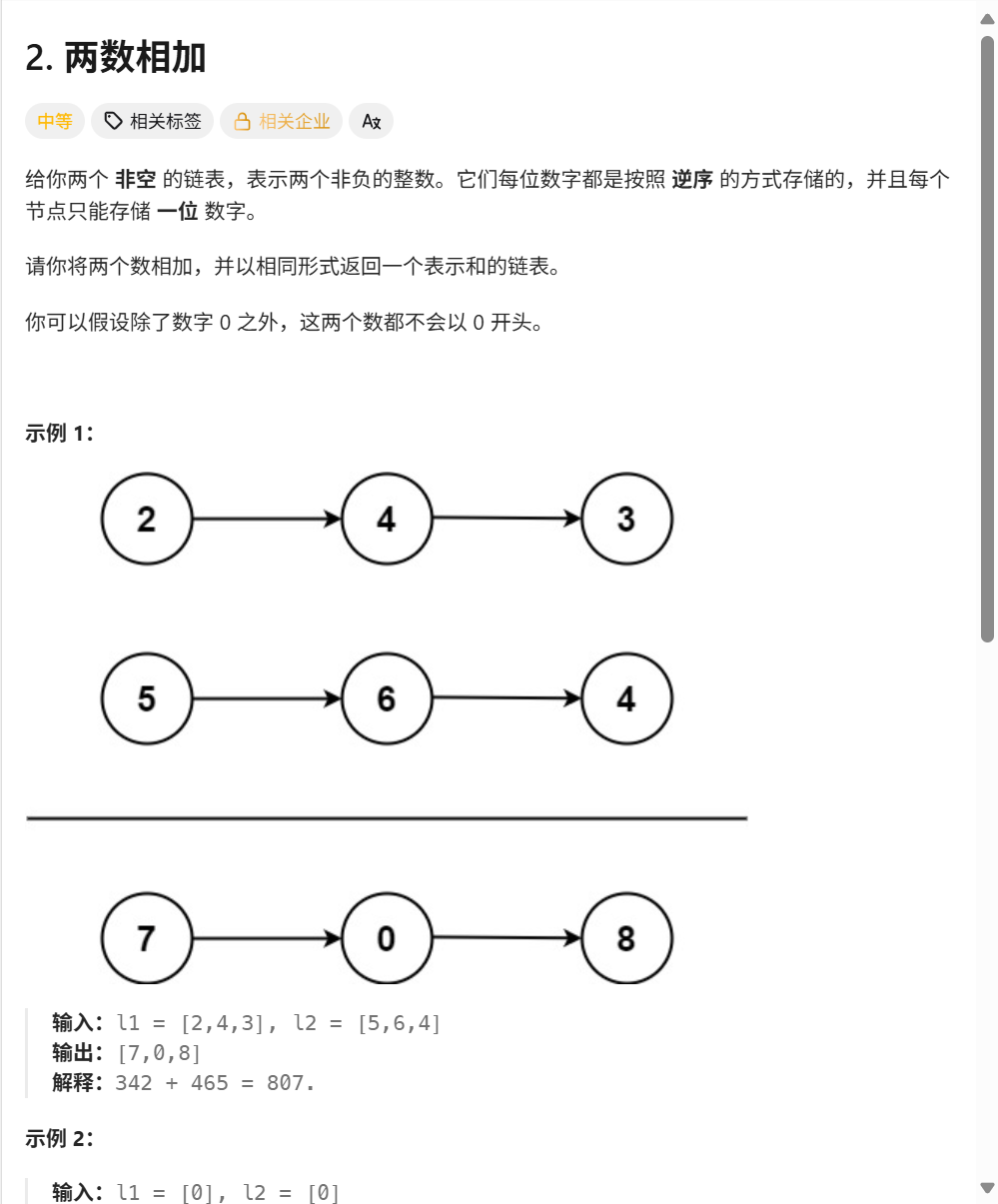
这是另一道经典的链表面试题,它将链表操作与基本的数学运算结合起来,同样是考察 coding 功底的利器。
题目要求:
给你两个 非空 的链表,表示两个非负的整数。它们每位数字都是按照 逆序 的方式存储的,并且每个节点只能存储 一位 数字。
请你将两个数相加,并以相同形式返回一个表示和的链表。
你可以假设除了数字 0 之外,这两个数都不会以 0 开头。
核心思想与图解
这个问题本质上就是模拟我们小学时列竖式做加法的过程。因为数字是逆序存储的,所以链表的头部恰好对应着整数的个位,这极大地简化了我们的计算,我们可以从头到尾遍历链表,就像从右到左计算竖式一样。
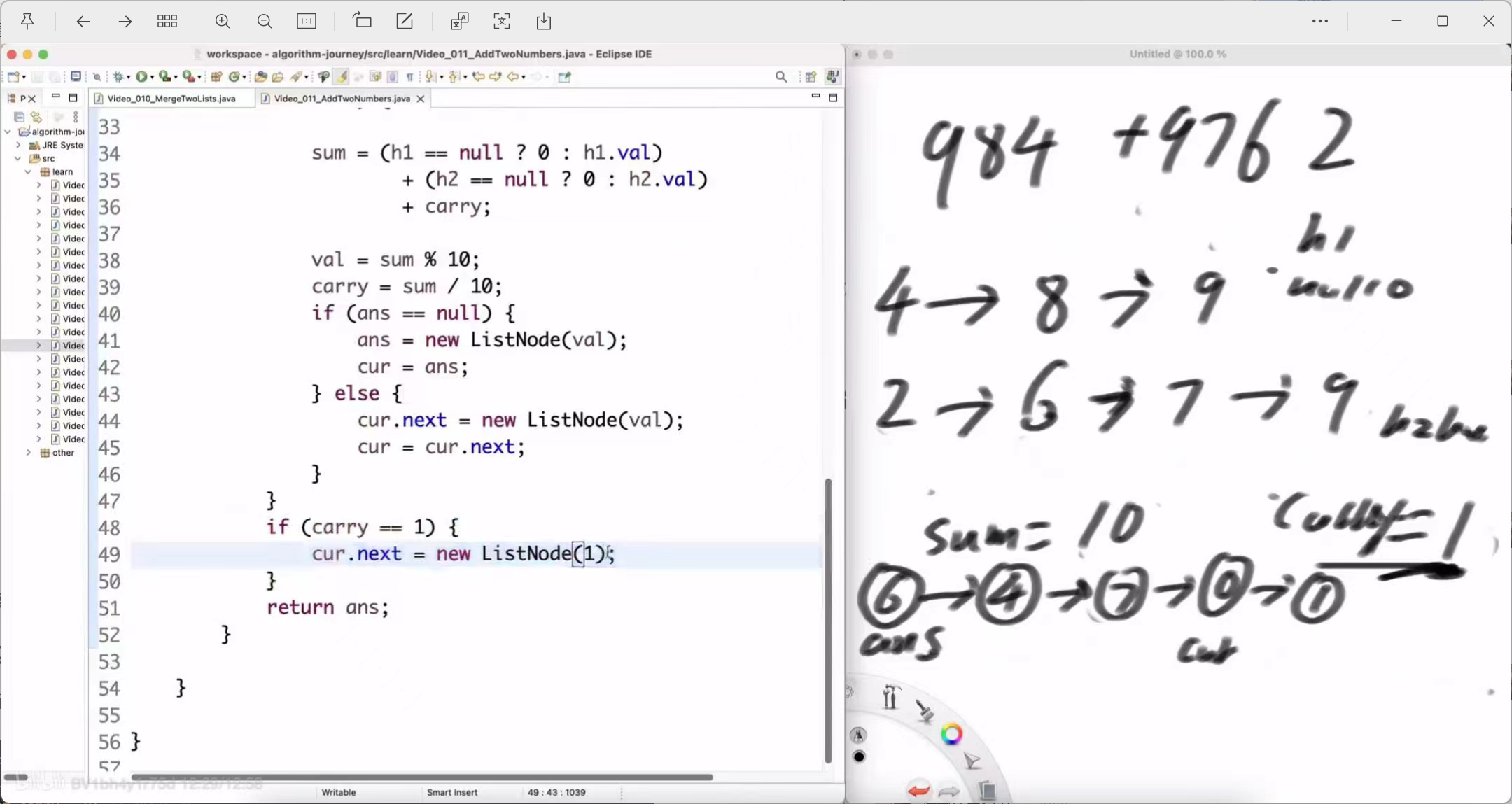
左老师在白板上为我们演示了这个过程: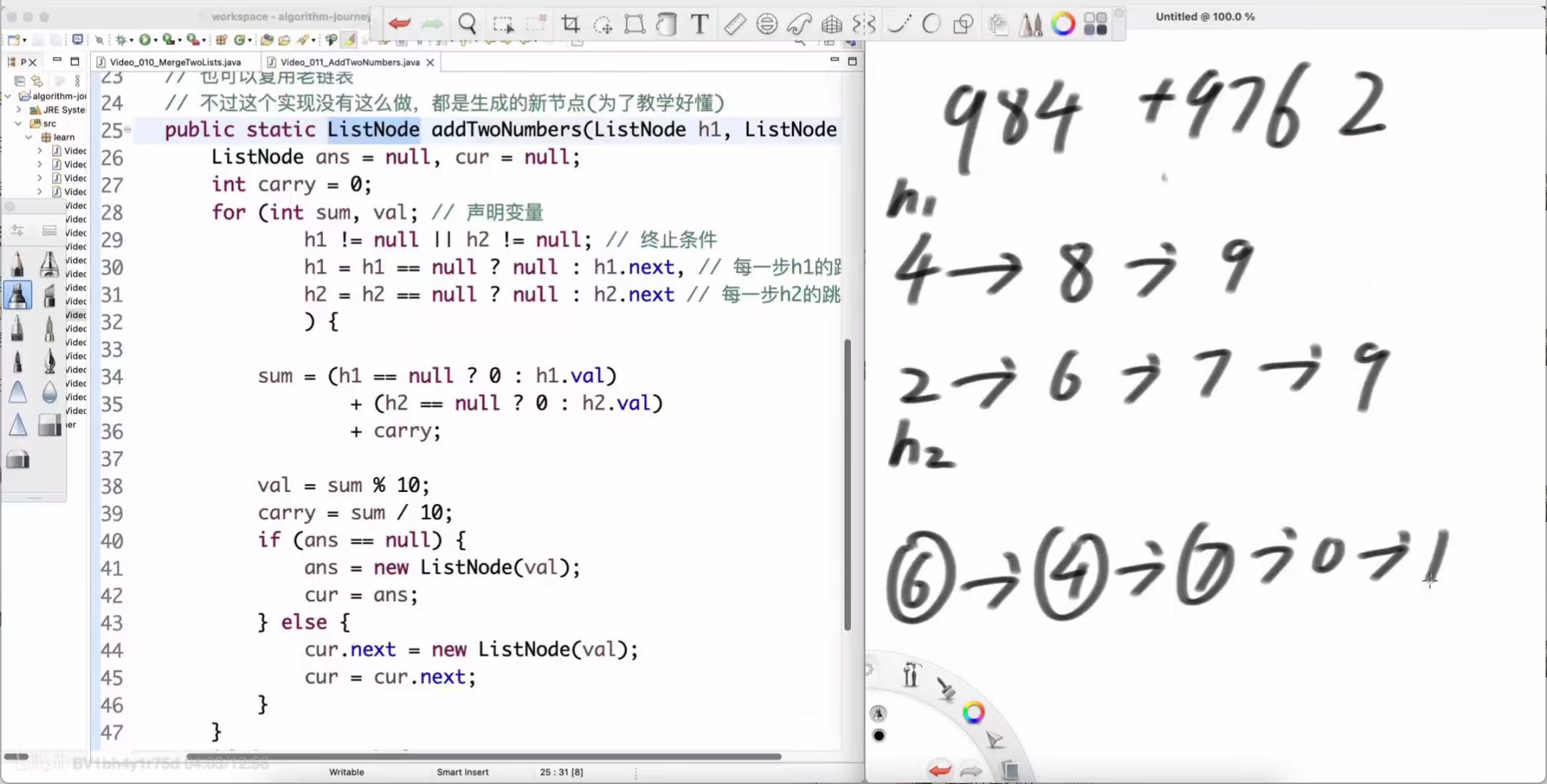
例:984 + 9762
-
在链表中的表示:
-
h1: 4 -> 8 -> 9 -> null
-
h2: 2 -> 6 -> 7 -> 9 -> null
-
-
计算过程:
-
个位:4 + 2 = 6。结果链表新节点为 6,进位为 0。
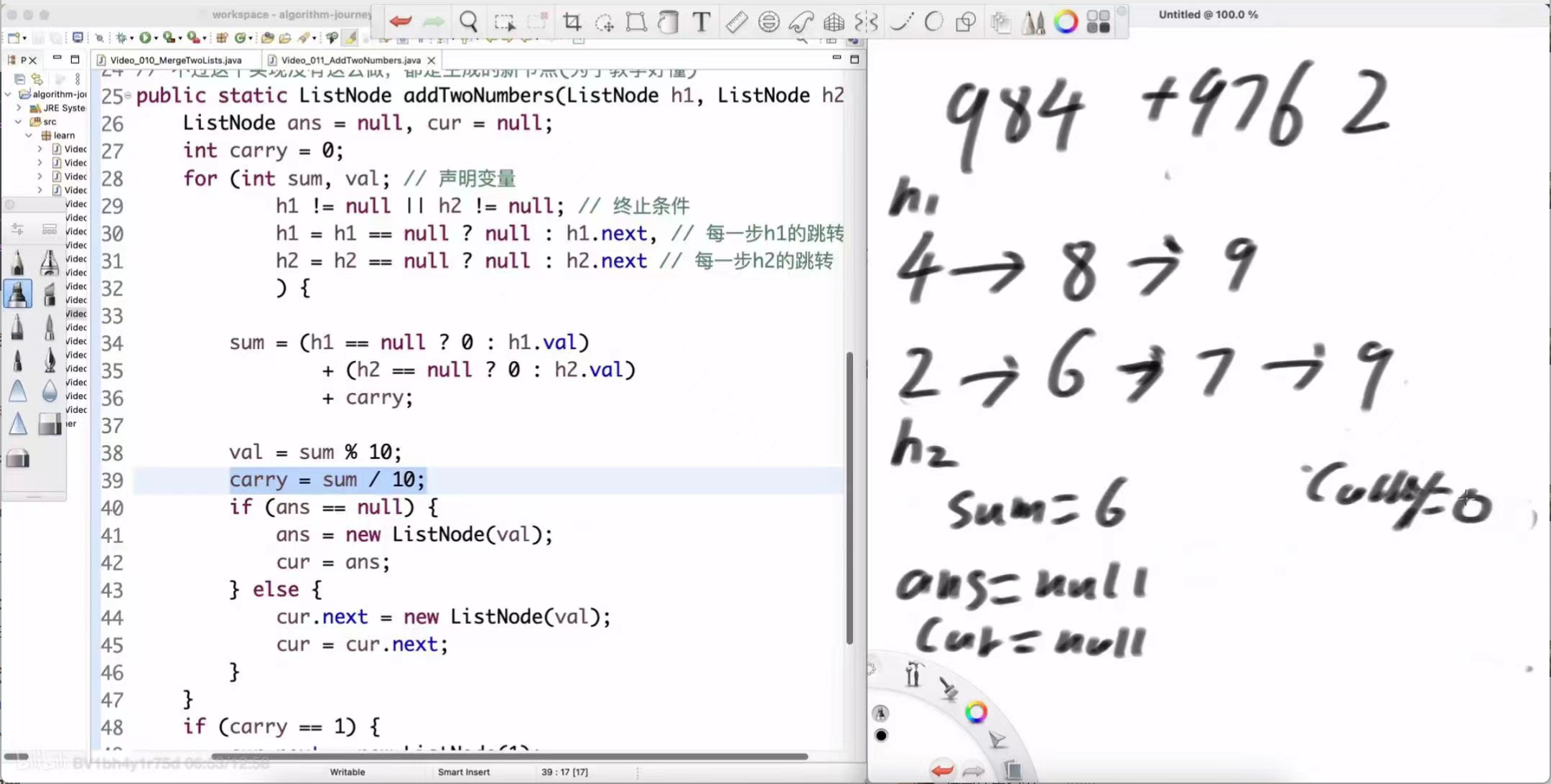
-
十位:8 + 6 + (进位0) = 14。结果链表新节点为 4,进位为 1。
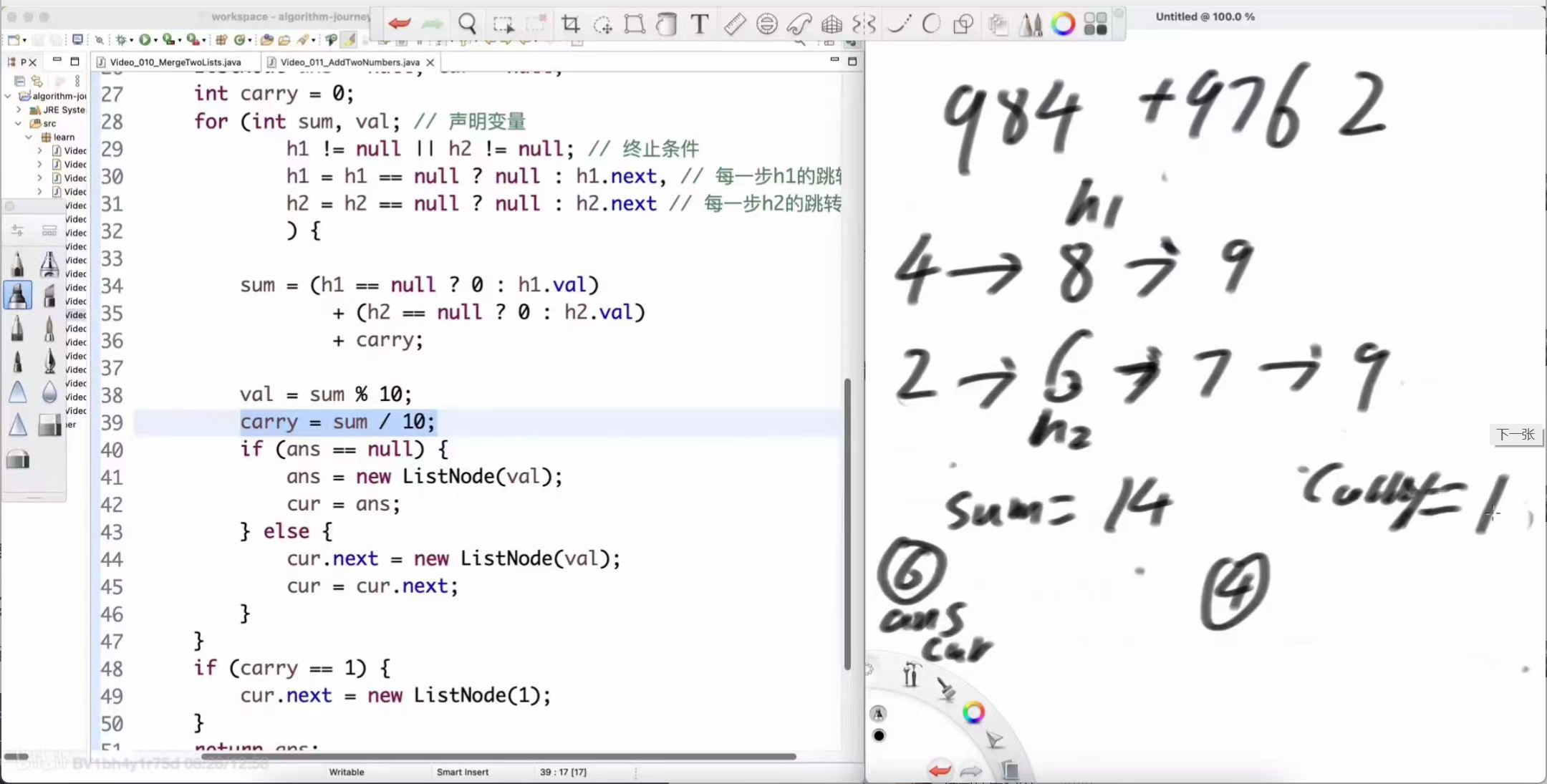
-
百位:9 + 7 + (进位1) = 17。结果链表新节点为 7,进位为 1。
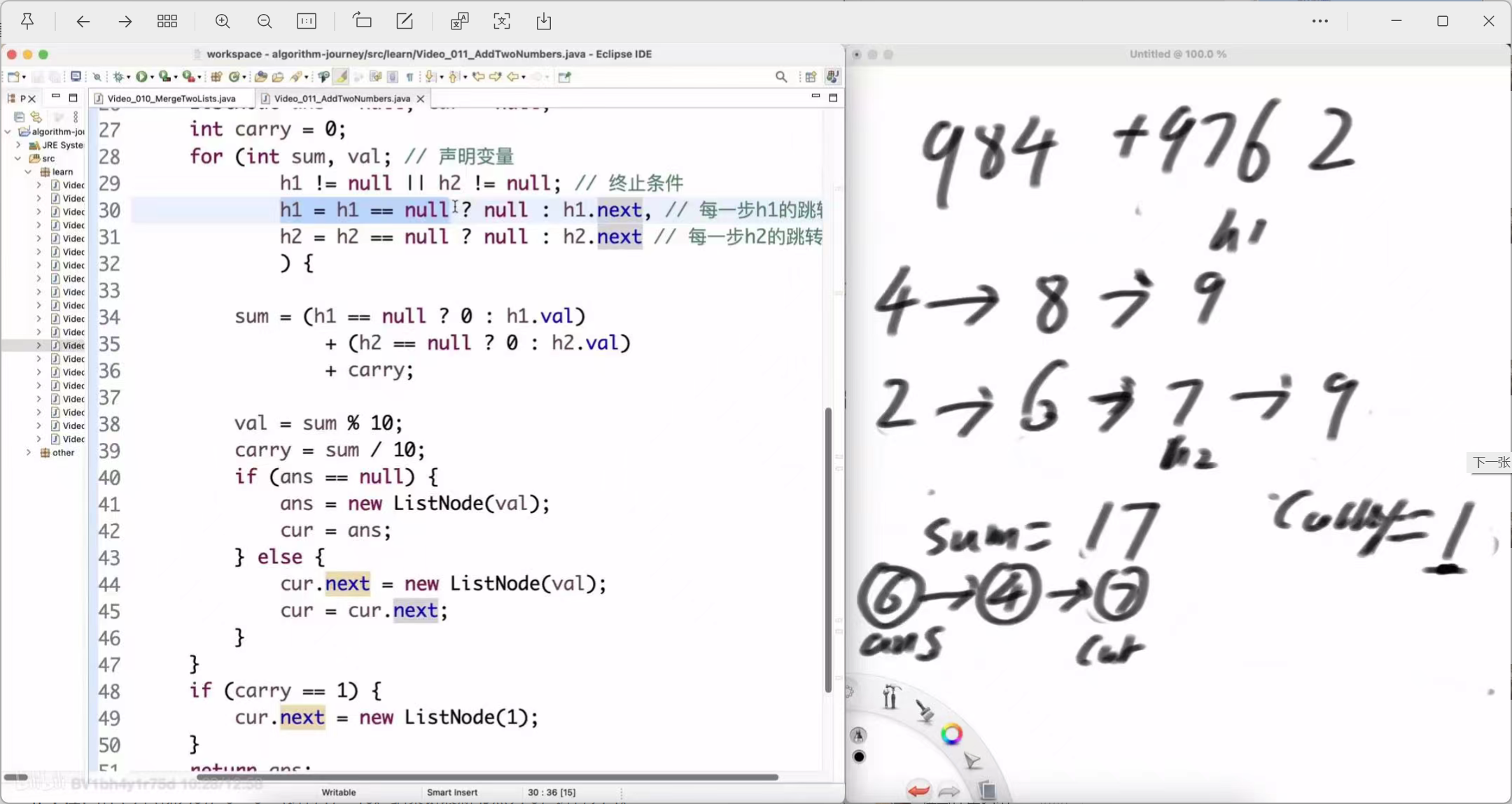
-
千位:h1 已空(视为0),0 + 9 + (进位1) = 10。结果链表新节点为 0,进位为 1。
-
万位:h1 和 h2 都已空,但还有进位 1。结果链表新节点为 1。
-
-
最终结果链表:6 -> 4 -> 7 -> 0 -> 1 -> null (代表整数 10746)
代码实现与逐行解析
我们来拆解左老师视频中的实现代码,这是一种非常简洁的写法。
public static ListNode addTwoNumbers(ListNode h1, ListNode h2) {ListNode ans = null, cur = null; // ans是结果头节点, cur是尾节点int carry = 0; // 进位信息// 循环条件:只要h1或h2不为空,就继续for (int sum, val; h1 != null || h2 != null; // 每次循环后,h1和h2都向后移动一位h1 = h1 == null ? null : h1.next,h2 = h2 == null ? null : h2.next) {// 1. 计算当前位的和sum = (h1 == null ? 0 : h1.val) + (h2 == null ? 0 : h2.val) + carry;// 2. 得到当前位的值 和 新的进位val = sum % 10;carry = sum / 10;// 3. 构建新节点并连接到结果链表上if (ans == null) {// 如果是第一个节点ans = new ListNode(val);cur = ans;} else {// 如果不是第一个节点cur.next = new ListNode(val);cur = cur.next;}}// 4. 处理最后的进位if (carry == 1) {cur.next = new ListNode(1);}// 5. 返回结果头节点return ans;
}变量初始化
-
ans = null, cur = null;: ans 用来保存最终结果链表的头,cur 则是移动的尾指针,负责拼接新节点。
-
int carry = 0;: 进位变量,初始为0。
创新的 for 循环结构
这里的 for 循环写得非常巧妙:
-
终止条件:h1 != null || h2 != null。只要两个链表中还有一个没有遍历完,循环就继续。这优雅地处理了两个链表长度不等的情况。
-
迭代步长:h1 = ..., h2 = ...。在每次循环体执行完毕后,将 h1 和 h2 向后移动。三元表达式 h1 == null ? null : h1.next 确保了当一个链表已经遍历完时,不会发生 NullPointerException。
循环体内部
-
计算 sum:
sum = (h1 == null ? 0 : h1.val) + (h2 == null ? 0 : h2.val) + carry;
这一行是核心。它将两个链表当前节点的值(如果节点为空则视为0)与上一位的进位相加。 -
计算 val 和 carry:
val = sum % 10; (取余数得到当前位)
carry = sum / 10; (取商得到新的进位) -
构建结果链表:
这段 if-else 逻辑的作用是创建新节点并将其正确地连接起来。-
if (ans == null):这个条件只在循环的第一次满足。它负责创建结果链表的头节点。
-
else: 在后续的循环中,cur.next = new ListNode(val); 将新节点挂在当前尾节点 cur 的后面,然后 cur = cur.next; 将尾指针后移。
-
收尾工作
if (carry == 1)
循环结束后,可能会留下一个最后的进位(例如 98 + 7 得到 105)。这条语句就是为了处理这种情况,如果最后还有一个进位1,就再追加一个值为1的新节点。
通过这种方式,我们模拟了加法运算的每一步,并同步构建出结果链表,最终返回其头节点 ans。
链表入门题目-划分链表
这是一个非常经典的链表问题,它要求我们将链表中的节点根据一个给定的值 x 分成两部分,同时还要保持节点在各自区域内的相对顺序不变。
题目要求:
给你一个链表的头节点 head 和一个特定值 x,请你对链表进行分隔,使得所有 小于 x 的节点都出现在 大于或等于 x 的节点之前。
你应当 保留 两个分区中每个节点的初始相对位置。
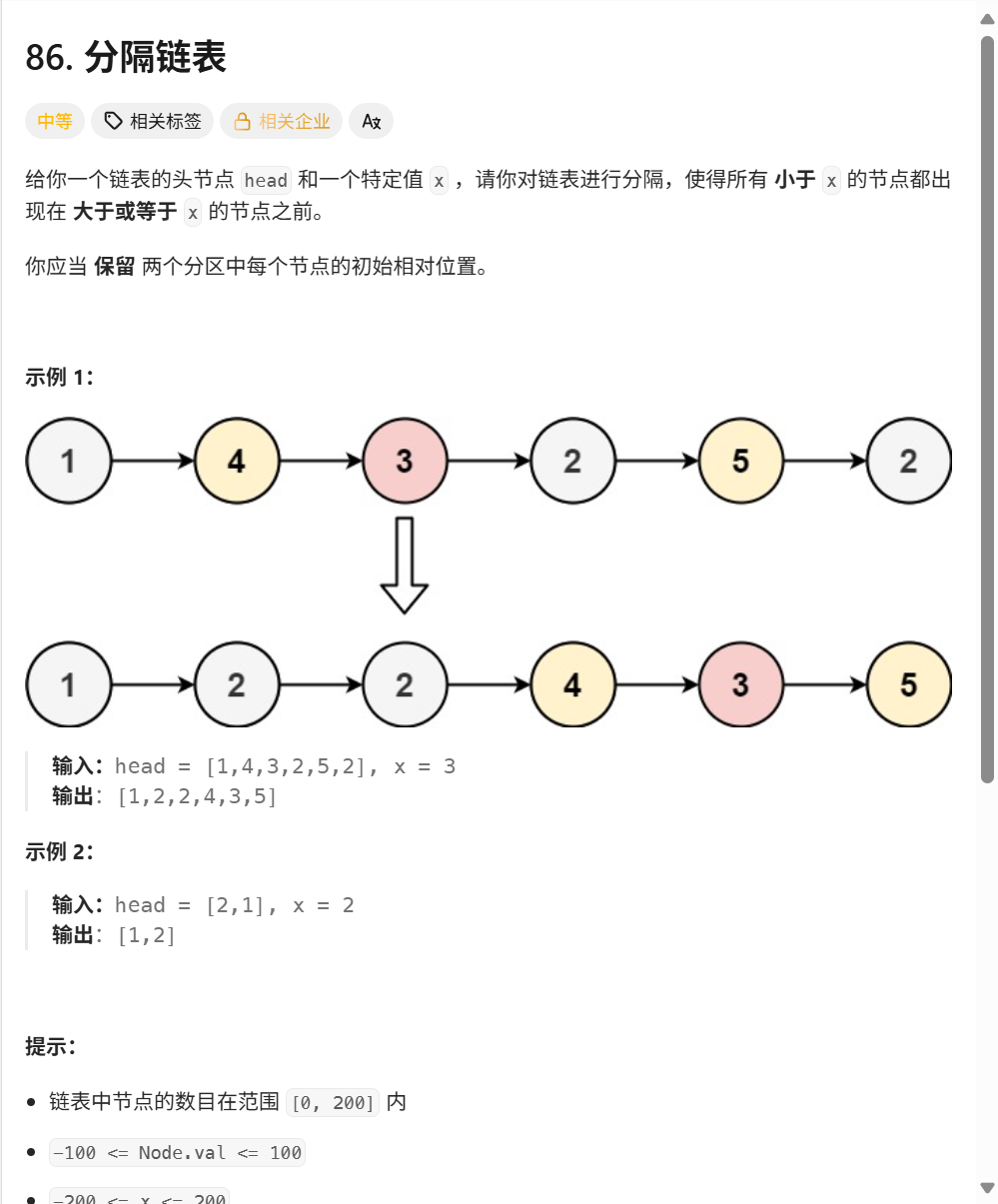
86. 分隔链表 - 力扣(LeetCode)
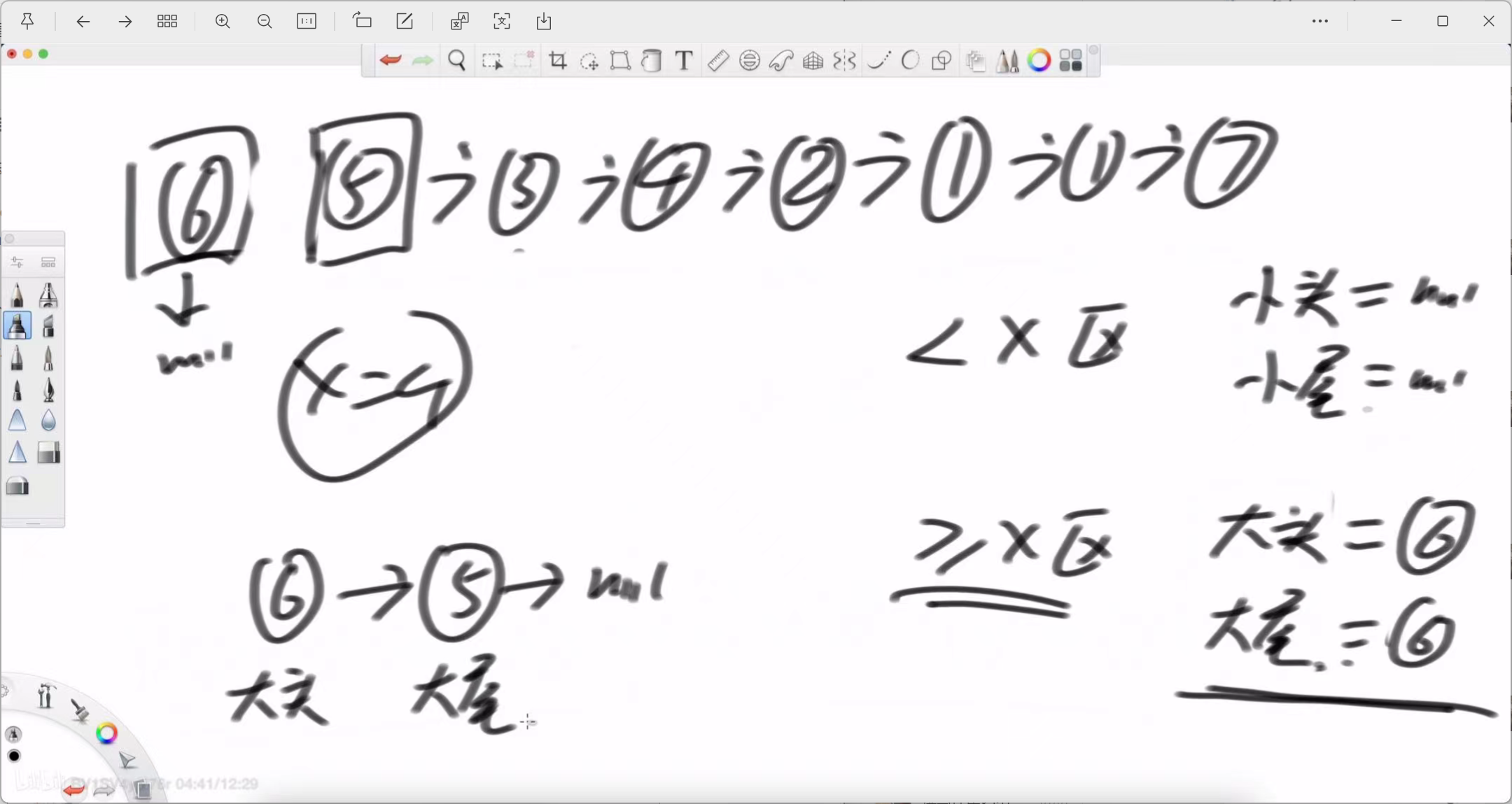
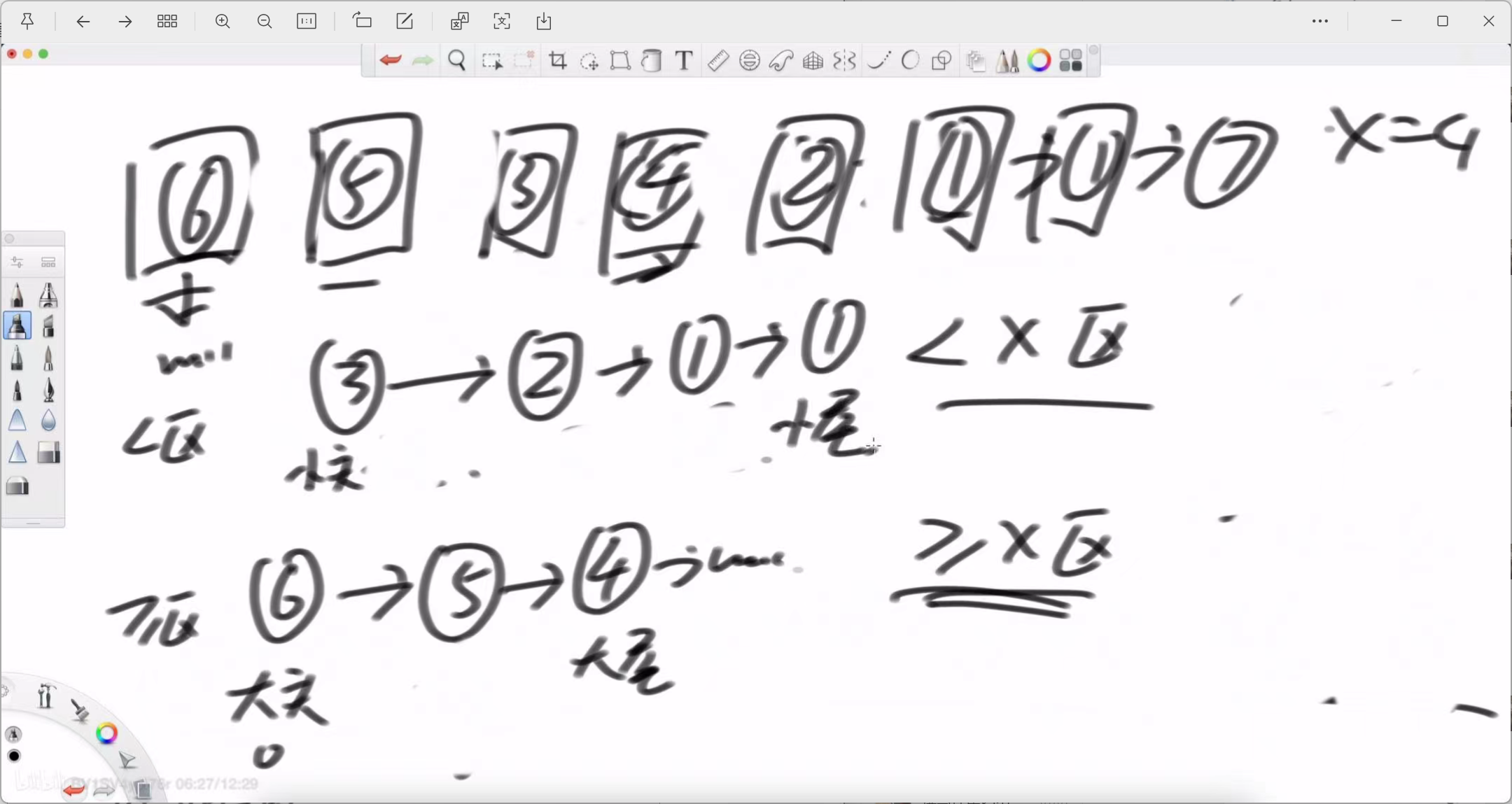
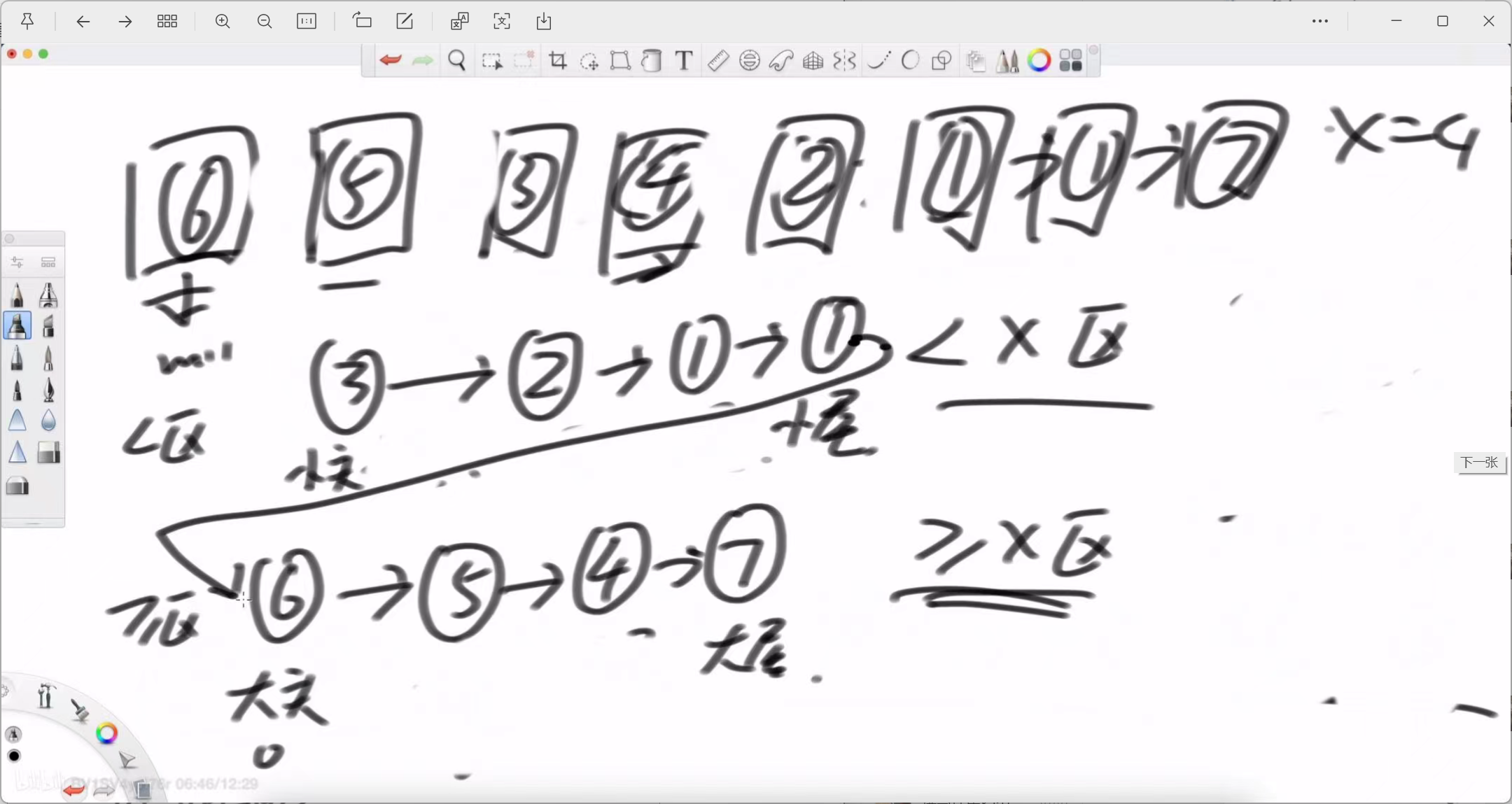
核心思想与图解
解决这个问题的最直观、最不容易出错的方法是:将原链表“拆分”成两个新的、独立的子链表,一个专门存放小于 x 的节点,另一个存放大于或等于 x 的节点。最后,再将这两个子链表拼接起来。
左老师在白板上生动地演示了这一过程:
-
准备区域:我们需要为两个子链表分别准备“头指针”和“尾指针”。
-
小于x区 (< x): 需要 leftHead (小头) 和 leftTail (小尾)。
-
大于等于x区 (>= x): 需要 rightHead (大头) 和 rightTail (大尾)。
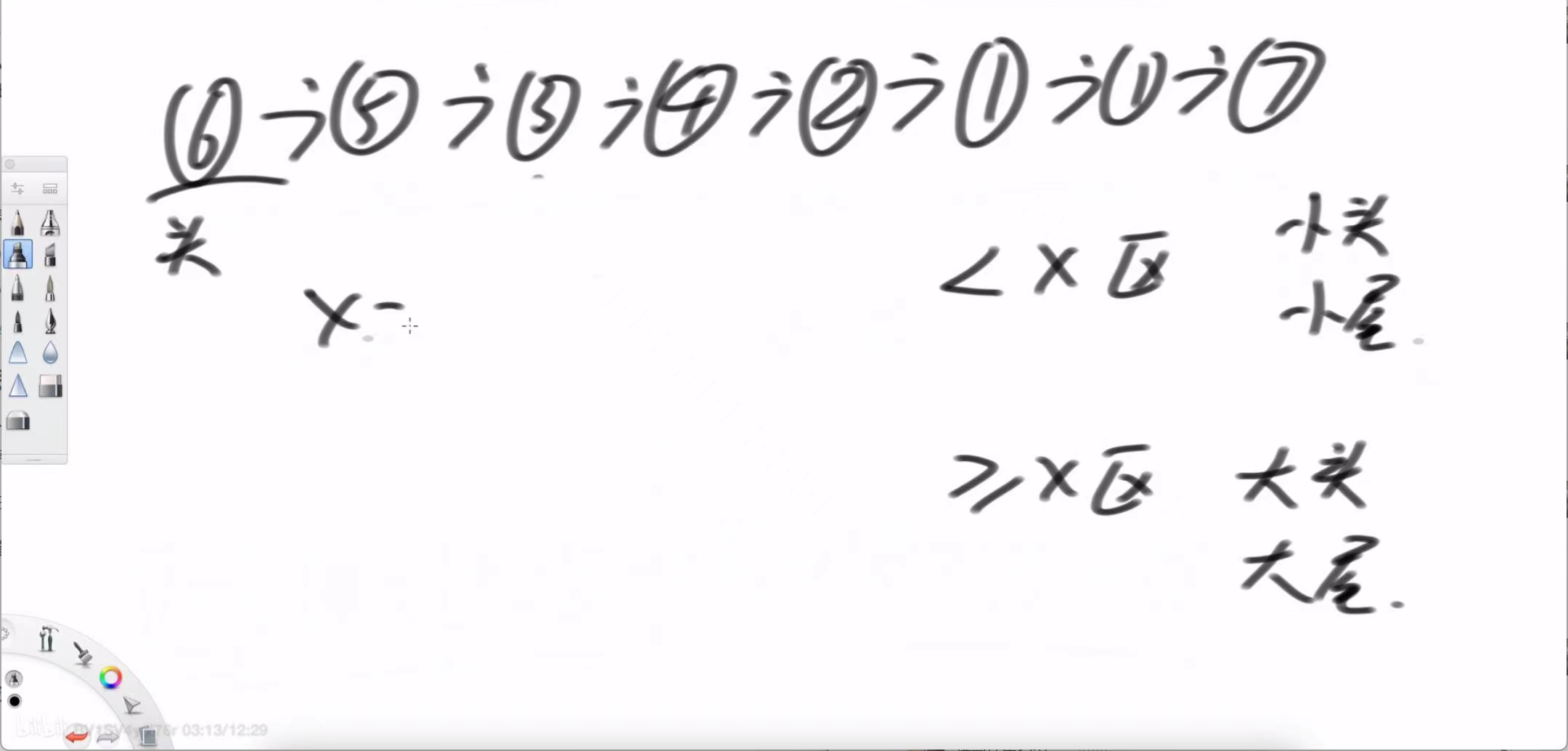
-
-
遍历拆分:
-
我们从头到尾遍历原始链表。
-
遇到一个节点,就判断它的值与 x 的关系。
-
如果节点值小于 x,就把它挂载到 leftTail 的后面,并更新 leftTail。
-
如果节点值大于或等于 x,就把它挂载到 rightTail 的后面,并更新 rightTail。
-
-
拼接:
-
当原始链表遍历完毕后,我们就得到了两个独立的、内部有序的子链表。
-
最后一步,将 leftTail (小于区的尾巴) 的 next 指针指向 rightHead (大于等于区的头),就完成了最终的拼接。
-
示例 (x=4):
代码实现与逐行解析
// 测评链接:https://leetcode.cn/problems/partition-list/
public static ListNode partition(ListNode head, int x) {// 1. 初始化六个指针ListNode leftHead = null; // <x 区域的头ListNode leftTail = null; // <x 区域的尾ListNode rightHead = null; // >=x 区域的头ListNode rightTail = null; // >=x 区域的尾ListNode next = null; // 保存下一个节点// 2. 遍历原链表进行拆分while (head != null) {next = head.next; // a. 保存下一个节点,防止失联head.next = null; // b. 断开当前节点与原链表的连接,非常重要!// c. 判断当前节点应放入哪个区域if (head.val < x) {// 放入 <x 区域if (leftHead == null) {leftHead = head;leftTail = head;} else {leftTail.next = head;leftTail = leftTail.next;}} else {// 放入 >=x 区域if (rightHead == null) {rightHead = head;rightTail = head;} else {rightTail.next = head;rightTail = rightTail.next;}}head = next; // d. 移动到下一个节点}// 3. 拼接两个区域if (leftHead == null) {// 如果 <x 区域为空,直接返回 >=x 区域的头return rightHead;}// 将 <x 区域的尾巴 连接到 >=x 区域的头leftTail.next = rightHead;return leftHead;
}1. 初始化 (步骤1)
我们定义了6个指针变量,全部初始化为 null。leftHead/leftTail 和 rightHead/rightTail 分别是两个新链表的头尾指针,而 next 用于在遍历时暂存 head 的后继节点。
2. 遍历与拆分 (步骤2)
这是算法的核心 while 循环。
-
a. next = head.next;: 在对 head 节点进行任何操作之前,必须先保存它后面的节点,否则一旦 head 被挂到新链表上,我们就找不到原始链表的后续部分了。
-
b. head.next = null;: 这是极其关键的一步!我们将当前节点 head 从原链中断开,把它变成一个独立的节点。这样做可以避免在新链表的尾部产生环或意外连接。
-
c. if-else 判断:
-
根据 head.val 与 x 的大小关系,决定是加入 left 区域还是 right 区域。
-
在每个区域内部,都用 if (xxHead == null) 来处理第一个被放入该区域的节点的特殊情况(头尾指针都指向它),用 else 处理后续节点的追加(只移动尾指针)。
-
-
d. head = next;: 将 head 指针移动到我们一开始保存的 next 节点,继续处理下一个。
3. 拼接 (步骤3)
循环结束后,我们得到了两个可能为空的链表。
-
if (leftHead == null): 这是一个边界情况。如果整个原始链表都没有小于 x 的节点,那么 left 区域就是空的,我们直接返回 right 区域的头即可。
-
leftTail.next = rightHead;: 这是最终的“缝合”操作,将小于区的链表尾部和大于等于区的链表头部连接起来。
-
return leftHead;: 返回小于区的头,也就是整个新链表的头。
通过这种“分而治之”再“合并”的思路,我们清晰且稳定地解决了链表划分问题。