【完整源码+数据集+部署教程】苹果实例分割检测系统源码和数据集:改进yolo11-AggregatedAtt
背景意义
研究背景与意义
随着农业现代化的推进,果品的质量和产量成为了研究的重点。苹果作为全球重要的水果之一,其种植和管理对农业经济具有重要影响。然而,苹果在生长过程中常常受到多种因素的影响,包括病虫害、气候变化以及管理不当等,这些因素可能导致果实的损失和品质下降。因此,开发一种高效的苹果实例分割检测系统,不仅能够提高果园管理的智能化水平,还能为果农提供科学的决策依据。
近年来,计算机视觉技术的快速发展为农业领域带来了新的机遇。尤其是实例分割技术的进步,使得我们能够对果园中的苹果进行精确的检测和分类。YOLO(You Only Look Once)系列模型因其高效的实时检测能力而受到广泛关注。YOLOv11作为该系列的最新版本,具备更强的特征提取能力和更高的检测精度,适合用于复杂环境下的实例分割任务。
本研究旨在基于改进的YOLOv11模型,构建一个针对苹果的实例分割检测系统。我们使用的“apple multiclass inst_seg”数据集包含1100张经过精细标注的苹果图像,涵盖了五个类别:Free、Heavily、Obst_apple、Obst_obst和Partially。这些类别的设置不仅反映了苹果的生长状态,也为模型的训练提供了丰富的样本。通过对这些图像的分析和处理,我们期望能够提升模型在不同环境下的适应性和准确性。
此外,本研究的成果将为果农提供一种高效的工具,帮助他们实时监测果园的健康状况,及时发现潜在问题,从而采取相应的管理措施。通过实现智能化的果园管理,不仅可以提高苹果的产量和质量,还能推动农业的可持续发展。因此,基于改进YOLOv11的苹果实例分割检测系统的研究具有重要的理论价值和实际意义。
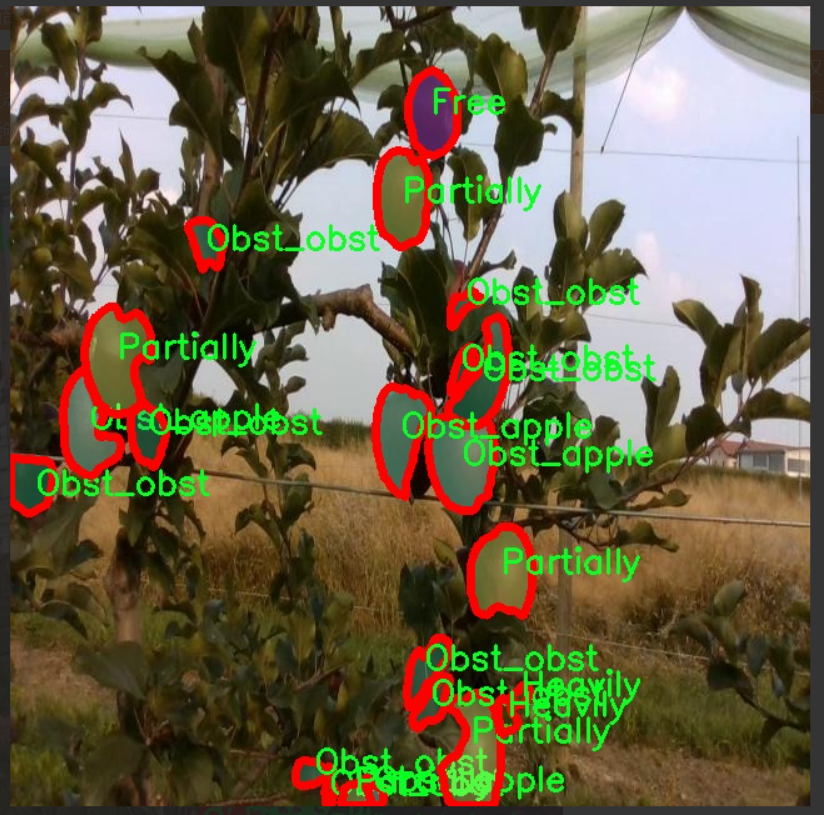
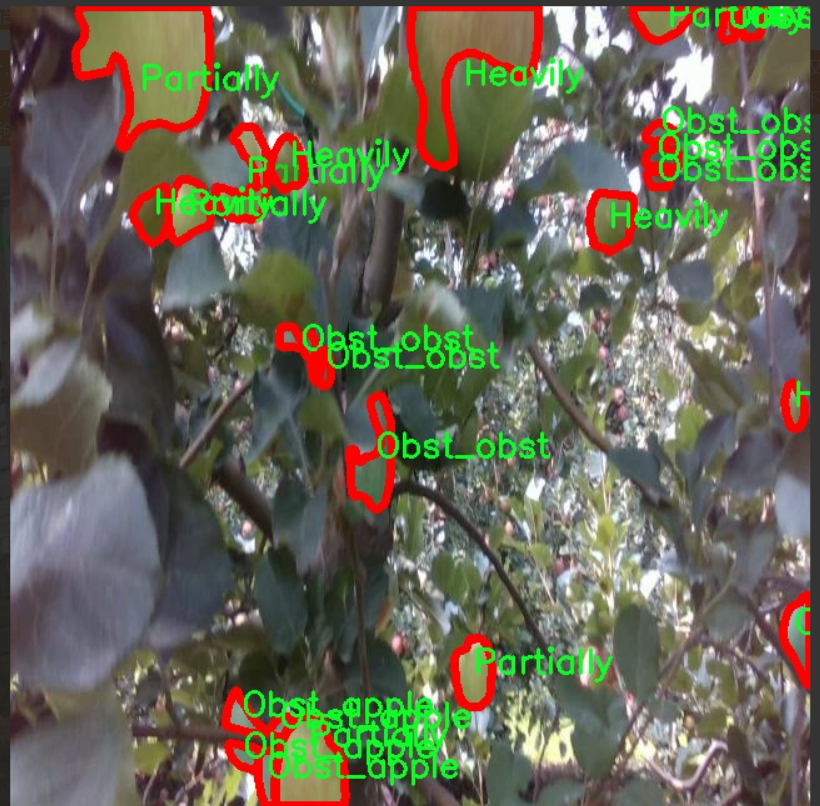
图片效果
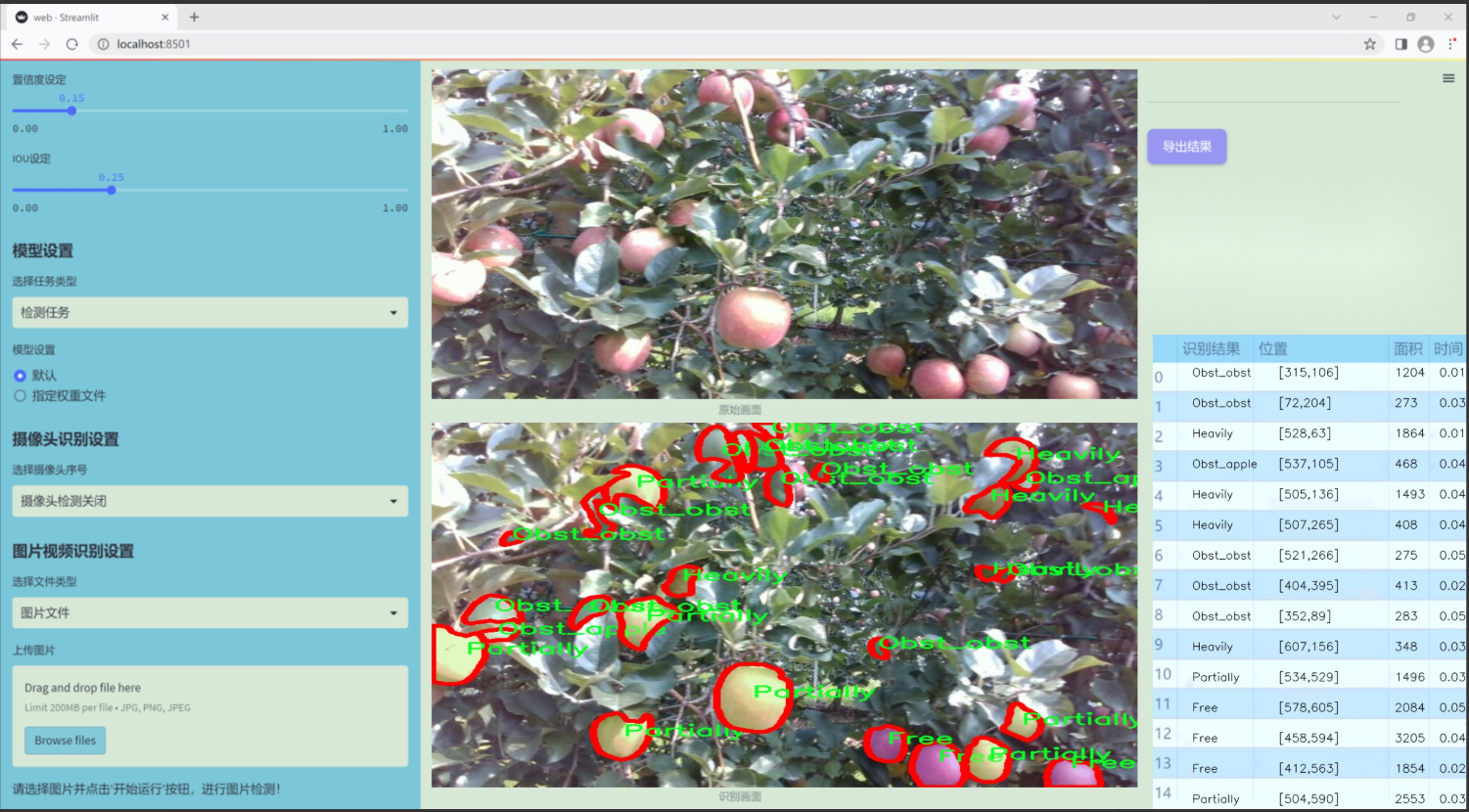
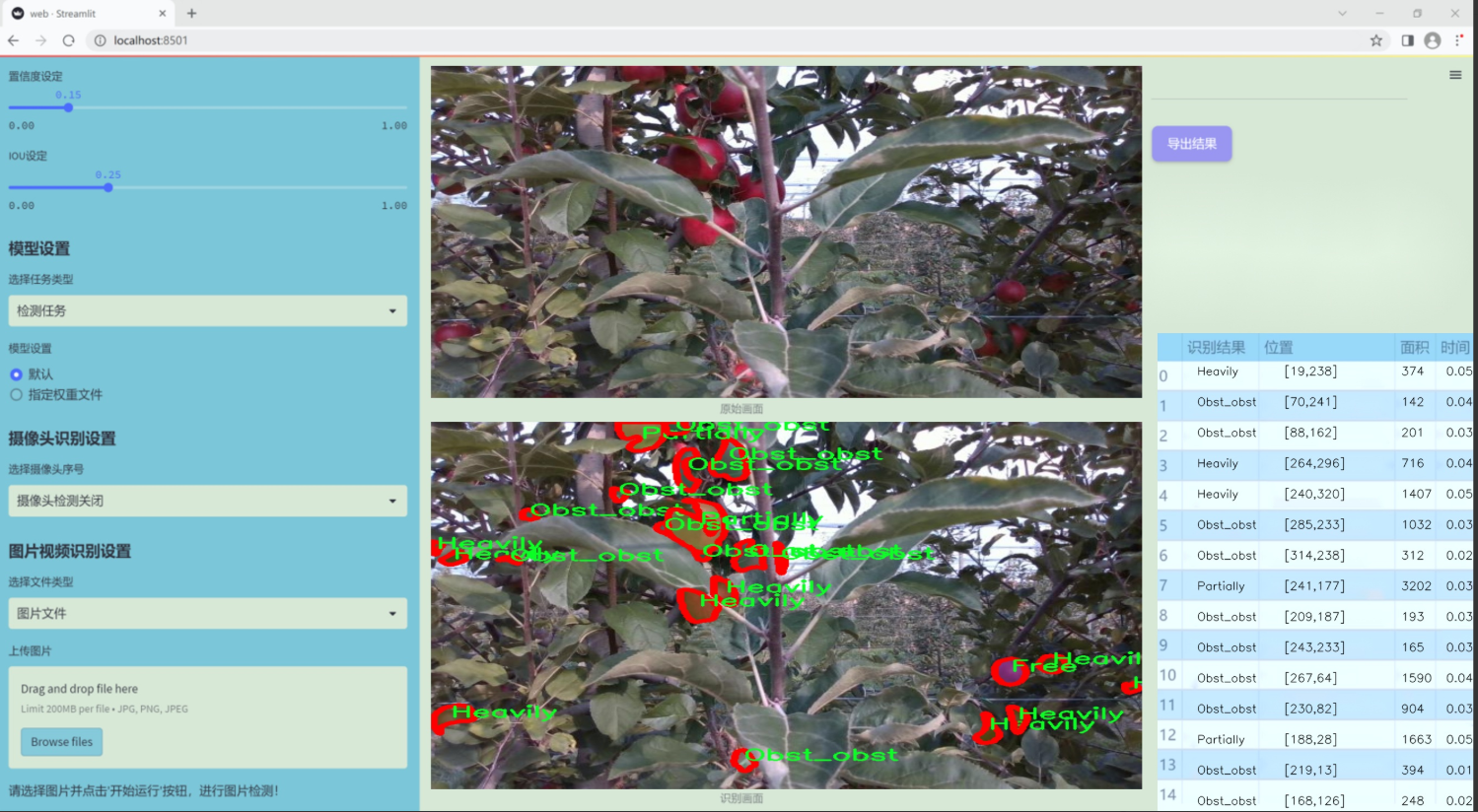
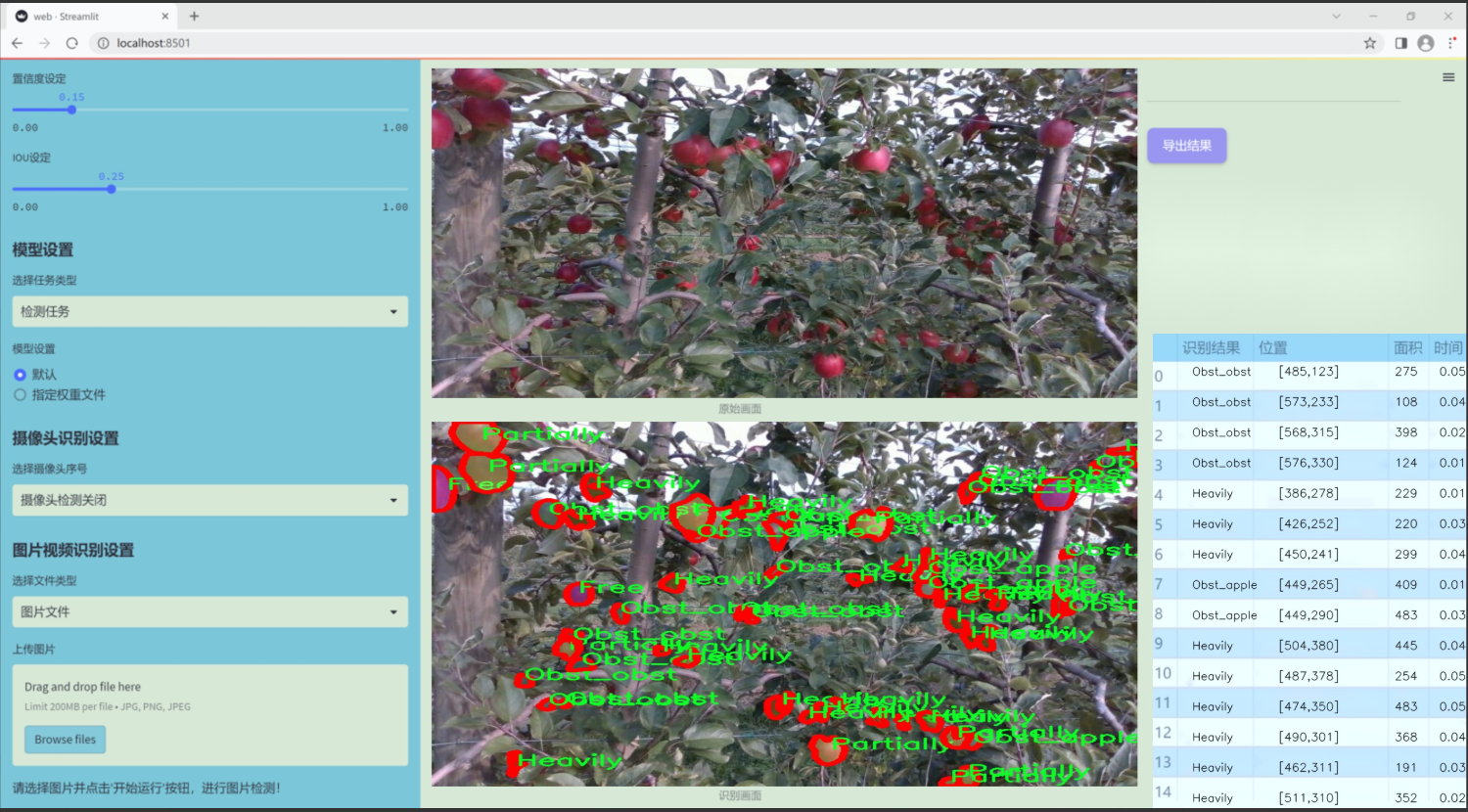
数据集信息
本项目数据集信息介绍
本项目所使用的数据集旨在支持改进YOLOv11的苹果实例分割检测系统,专注于“apple multiclass inst_seg”这一主题。该数据集包含五个主要类别,分别为“Free”、“Heavily”、“Obst_apple”、“Obst_obst”和“Partially”。这些类别涵盖了苹果在不同生长阶段和不同环境条件下的状态,能够为模型提供丰富的训练样本,提升其在实际应用中的检测能力。
在数据集的构建过程中,我们特别注重样本的多样性和代表性,以确保模型能够在各种情况下进行有效的实例分割。类别“Free”代表无障碍的苹果,适用于检测健康生长的果实;“Heavily”则指代果实生长繁茂的情况,可能存在过度拥挤的现象;“Obst_apple”类别则标识那些被其他苹果遮挡的果实,挑战模型在复杂场景中的识别能力;“Obst_obst”则涉及到苹果被其他物体(如树叶、枝条等)遮挡的情况,进一步增加了检测的难度;最后,“Partially”类别则描述了部分可见的苹果,要求模型能够推断出被遮挡部分的存在。
通过对这些类别的细致划分,我们希望能够提升YOLOv11在苹果实例分割任务中的准确性和鲁棒性。数据集的多样性不仅有助于训练模型识别不同状态的苹果,还能提高其在实际农业场景中的应用潜力,促进智能农业的发展。随着数据集的不断扩展和优化,我们期待能够为农业领域提供更为精准的技术支持,助力果农提高产量和质量。



核心代码
以下是代码中最核心的部分,包含了YOLOv8的检测头实现,并对其进行了详细的中文注释:
import torch
import torch.nn as nn
import torch.nn.functional as F
from …modules import Conv, DFL, make_anchors, dist2bbox
class Detect_DyHead(nn.Module):
“”“YOLOv8检测头,使用动态头进行目标检测。”“”
def __init__(self, nc=80, hidc=256, block_num=2, ch=()):"""初始化检测头。参数:nc (int): 类别数量。hidc (int): 隐藏层通道数。block_num (int): 动态头块的数量。ch (tuple): 输入通道数。"""super().__init__()self.nc = nc # 类别数量self.nl = len(ch) # 检测层的数量self.reg_max = 16 # DFL通道数self.no = nc + self.reg_max * 4 # 每个锚点的输出数量self.stride = torch.zeros(self.nl) # 构建时计算的步幅c2, c3 = max((16, ch[0] // 4, self.reg_max * 4)), max(ch[0], self.nc) # 通道数# 定义卷积层self.conv = nn.ModuleList(nn.Sequential(Conv(x, hidc, 1)) for x in ch)self.dyhead = nn.Sequential(*[DyHeadBlock(hidc) for _ in range(block_num)]) # 动态头块self.cv2 = nn.ModuleList(nn.Sequential(Conv(hidc, c2, 3), Conv(c2, c2, 3), nn.Conv2d(c2, 4 * self.reg_max, 1)) for _ in ch)self.cv3 = nn.ModuleList(nn.Sequential(nn.Sequential(DWConv(hidc, x, 3), Conv(x, c3, 1)),nn.Sequential(DWConv(c3, c3, 3), Conv(c3, c3, 1)),nn.Conv2d(c3, self.nc, 1),)for x in ch)self.dfl = DFL(self.reg_max) if self.reg_max > 1 else nn.Identity() # DFL层def forward(self, x):"""前向传播,返回预测的边界框和类别概率。"""for i in range(self.nl):x[i] = self.conv[i](x[i]) # 通过卷积层处理输入x = self.dyhead(x) # 通过动态头处理特征shape = x[0].shape # 获取输出形状 BCHWfor i in range(self.nl):# 将cv2和cv3的输出拼接x[i] = torch.cat((self.cv2[i](x[i]), self.cv3[i](x[i])), 1)if self.training:return x # 训练模式下返回处理后的特征elif self.shape != shape:# 动态锚点生成self.anchors, self.strides = (x.transpose(0, 1) for x in make_anchors(x, self.stride, 0.5))self.shape = shape# 将所有输出拼接为一个张量x_cat = torch.cat([xi.view(shape[0], self.no, -1) for xi in x], 2)box, cls = x_cat.split((self.reg_max * 4, self.nc), 1) # 分割边界框和类别概率dbox = dist2bbox(self.dfl(box), self.anchors.unsqueeze(0), xywh=True, dim=1) * self.strides # 解码边界框y = torch.cat((dbox, cls.sigmoid()), 1) # 返回边界框和经过sigmoid处理的类别概率return ydef bias_init(self):"""初始化检测头的偏置,要求步幅可用。"""for a, b, s in zip(self.cv2, self.cv3, self.stride):a[-1].bias.data[:] = 1.0 # 边界框偏置初始化为1b[-1].bias.data[:self.nc] = math.log(5 / self.nc / (640 / s) ** 2) # 类别偏置初始化
代码核心部分说明:
Detect_DyHead类:这是YOLOv8的检测头实现,使用动态头(DyHead)来进行目标检测。
初始化方法:设置类别数量、通道数、卷积层、动态头块等参数。
前向传播方法:处理输入特征,通过卷积层和动态头进行特征提取,生成边界框和类别概率。
偏置初始化方法:用于初始化检测头的偏置,以提高模型的收敛速度。
以上代码是YOLOv8目标检测模型的核心部分,包含了模型的基本结构和前向传播逻辑。
这个文件 head.py 定义了多个用于目标检测和分割的模型头部,主要是基于 YOLOv8 的架构。文件中包含了多个类,每个类实现了不同的检测或分割功能,主要用于处理图像中的物体检测、关键点检测和分割任务。
首先,文件导入了一些必要的库,包括 PyTorch 和相关的神经网络模块。这些模块提供了构建深度学习模型所需的基本功能。
接下来,文件定义了多个检测头类。每个类通常会继承自 nn.Module,并实现以下主要功能:
初始化方法 (init):在初始化中,定义了网络的结构,包括卷积层、激活函数、正则化层等。还设置了一些超参数,如类别数量、隐藏通道数、输出数量等。
前向传播方法 (forward):这个方法定义了数据如何通过网络流动。输入的特征图经过卷积、激活和其他操作后,生成预测的边界框和类别概率。根据训练和推理模式,前向传播的逻辑可能会有所不同。
锚框和步幅的计算:在推理过程中,动态生成锚框和步幅,以适应输入特征图的形状。这些锚框用于后续的边界框解码。
解码方法 (decode_bboxes):将网络输出的边界框参数转换为实际的边界框坐标。这一过程通常涉及到对输出进行逆变换,以便得到在原始图像上的位置。
偏置初始化 (bias_init):初始化网络中的偏置项,以帮助模型更快地收敛。
文件中定义的类包括但不限于:
Detect_DyHead:实现了动态头部的检测模型。
Detect_AFPN_P345 和 Detect_AFPN_P2345:实现了基于自适应特征金字塔网络(AFPN)的检测模型。
Detect_Efficient:实现了高效的检测头。
Detect_LSCD 和 Detect_LSCSBD:实现了轻量级共享卷积检测头。
Detect_TADDH:实现了任务动态对齐检测头。
Segment_Efficient、Segment_LSCD、Segment_LADH 等:实现了不同的分割头,处理图像分割任务。
此外,文件还定义了一些用于特定任务的类,如 Pose_LSCD 和 OBB_LSCD,分别用于关键点检测和旋转边界框检测。
总体而言,这个文件是 YOLOv8 模型实现的一部分,提供了多种灵活的检测和分割头部,可以根据不同的任务需求进行选择和组合。每个类的设计都考虑到了模型的可扩展性和高效性,以便在实际应用中能够快速适应不同的场景和数据集。
10.4 rep_block.py
以下是经过简化和注释的核心代码部分,主要集中在 DiverseBranchBlock 类及其相关函数上:
import torch
import torch.nn as nn
import torch.nn.functional as F
def transI_fusebn(kernel, bn):
“”"
将卷积核和批归一化层的参数融合,返回融合后的卷积核和偏置。
“”"
gamma = bn.weight # 获取批归一化的缩放因子
std = (bn.running_var + bn.eps).sqrt() # 计算标准差
# 融合卷积核和批归一化参数
return kernel * ((gamma / std).reshape(-1, 1, 1, 1)), bn.bias - bn.running_mean * gamma / std
def conv_bn(in_channels, out_channels, kernel_size, stride=1, padding=0, dilation=1, groups=1):
“”"
创建一个卷积层和批归一化层的组合。
“”"
conv_layer = nn.Conv2d(in_channels=in_channels, out_channels=out_channels, kernel_size=kernel_size,
stride=stride, padding=padding, dilation=dilation, groups=groups,
bias=False) # 不使用偏置
bn_layer = nn.BatchNorm2d(num_features=out_channels, affine=True) # 批归一化层
return nn.Sequential(conv_layer, bn_layer) # 返回组合的层
class DiverseBranchBlock(nn.Module):
def init(self, in_channels, out_channels, kernel_size, stride=1, padding=None, dilation=1, groups=1):
“”"
初始化DiverseBranchBlock,包含多个分支的卷积结构。
“”"
super(DiverseBranchBlock, self).init()
self.kernel_size = kernel_size
self.in_channels = in_channels
self.out_channels = out_channels
self.groups = groups
if padding is None:padding = kernel_size // 2 # 默认填充为卷积核的一半# 原始卷积和批归一化self.dbb_origin = conv_bn(in_channels=in_channels, out_channels=out_channels, kernel_size=kernel_size,stride=stride, padding=padding, dilation=dilation, groups=groups)# 平均池化分支self.dbb_avg = nn.Sequential(nn.Conv2d(in_channels=in_channels, out_channels=out_channels, kernel_size=1, stride=1, padding=0, groups=groups, bias=False),nn.BatchNorm2d(out_channels),nn.AvgPool2d(kernel_size=kernel_size, stride=stride, padding=0))# 1x1卷积分支self.dbb_1x1_kxk = nn.Sequential(nn.Conv2d(in_channels=in_channels, out_channels=out_channels, kernel_size=1, stride=stride, padding=0, groups=groups, bias=False),nn.BatchNorm2d(out_channels))def forward(self, inputs):"""前向传播,计算输出。"""out = self.dbb_origin(inputs) # 通过原始卷积分支out += self.dbb_avg(inputs) # 加上平均池化分支out += self.dbb_1x1_kxk(inputs) # 加上1x1卷积分支return out # 返回最终输出def get_equivalent_kernel_bias(self):"""获取等效的卷积核和偏置,用于推理时的参数融合。"""k_origin, b_origin = transI_fusebn(self.dbb_origin[0].weight, self.dbb_origin[1]) # 融合原始卷积k_avg, b_avg = transI_fusebn(self.dbb_avg[0].weight, self.dbb_avg[1]) # 融合平均池化卷积k_1x1, b_1x1 = transI_fusebn(self.dbb_1x1_kxk[0].weight, self.dbb_1x1_kxk[1]) # 融合1x1卷积# 返回所有分支的卷积核和偏置的和return k_origin + k_avg + k_1x1, b_origin + b_avg + b_1x1
代码注释说明:
transI_fusebn: 该函数用于将卷积层和批归一化层的参数融合,返回融合后的卷积核和偏置。
conv_bn: 该函数创建一个包含卷积层和批归一化层的组合,方便后续使用。
DiverseBranchBlock: 这是一个神经网络模块,包含多个分支(原始卷积、平均池化和1x1卷积),用于实现多样化的特征提取。
forward: 定义了前向传播的过程,计算输入的输出。
get_equivalent_kernel_bias: 该函数用于获取等效的卷积核和偏置,以便在推理时使用。
通过这些注释,代码的核心逻辑和功能得以清晰展现。
这个程序文件 rep_block.py 是一个用于构建深度学习模型中多分支卷积块的实现,主要依赖于 PyTorch 框架。文件中定义了多个类和函数,用于实现不同类型的卷积操作和相应的批归一化(Batch Normalization)处理。
首先,文件中引入了必要的库,包括 torch 和 torch.nn,这些是构建神经网络的基础库。接着,定义了一些用于卷积和批归一化的辅助函数,例如 transI_fusebn 用于将卷积核和批归一化的参数融合,transII_addbranch 用于将多个卷积核和偏置相加,transIII_1x1_kxk 用于处理不同类型的卷积核组合等。
接下来,定义了多个类,主要包括 DiverseBranchBlock、WideDiverseBranchBlock 和 DeepDiverseBranchBlock,这些类实现了不同的多分支卷积块。每个类的构造函数中都可以接收多个参数,如输入通道数、输出通道数、卷积核大小、步幅、填充等。
在 DiverseBranchBlock 类中,构造函数中根据输入参数初始化了多个卷积层和批归一化层,并根据需要创建了不同的分支(如平均池化分支、1x1 卷积分支等)。该类还实现了 forward 方法,定义了前向传播的计算过程。
WideDiverseBranchBlock 类在此基础上增加了对水平和垂直卷积的支持,允许在前向传播中同时使用不同方向的卷积核,以增强特征提取能力。
DeepDiverseBranchBlock 类则进一步扩展了功能,允许使用更深的网络结构,同时保持多分支的特性。
每个类都实现了 switch_to_deploy 方法,用于在推理阶段将模型转换为更高效的形式,减少计算开销。此外,还有一些初始化方法,如 init_gamma 和 single_init,用于初始化模型参数。
总的来说,这个文件提供了一种灵活的方式来构建复杂的卷积神经网络结构,支持多种卷积操作和参数融合,适用于需要高效特征提取的深度学习任务。
源码文件

源码获取
欢迎大家点赞、收藏、关注、评论啦 、查看👇🏻获取联系方式