【大语言模型 44】创造力评估:开放域生成质量测试
【大语言模型 44】创造力评估:开放域生成质量测试
关键词:创造力评估、开放域生成、质量测试、创意性指标、多样性评估、一致性平衡、风格控制、内容质量、人类创造力对比、生成评估框架、创新性测试、文本生成质量
摘要:本文深入探讨大语言模型创造力评估的理论基础与实践方法。文章系统分析创意性评估指标的设计原理,详细介绍多样性与一致性平衡的技术实现,深入探索风格控制与内容质量的评估策略。通过人类创造力对比实验,构建全面的开放域生成质量测试框架。结合理论阐述与代码实践,为研究者和工程师提供科学的创造力评估工具,助力大语言模型创新能力的准确测量与持续提升。
文章目录
- 【大语言模型 44】创造力评估:开放域生成质量测试
- 1. 引言:创造力的本质与评估挑战
- 1.1 创造力的多维定义
- 1.2 开放域生成的独特挑战
- 2. 创造力评估框架设计
- 2.1 多维度评估体系
- 2.1.1 创新性维度评估
- 2.1.2 质量维度评估
- 2.2 创造力评估算法实现
- 3. 多样性与一致性平衡技术
- 3.1 多样性评估的深度分析
- 3.1.1 多样性的多层次理解
- 3.1.2 多样性测量算法
- 3.2 一致性保持策略
- 3.2.1 风格一致性控制
- 3.2.2 主题一致性维护
- 4. 风格控制与内容质量评估
- 4.1 风格控制技术深度解析
- 4.1.1 风格特征提取与建模
- 4.2 内容质量综合评估
- 4.2.1 质量评估的多维框架
- 5. 人类创造力对比实验设计
- 5.1 实验框架设计
- 5.2 对比实验实现
- 6. 实践应用与案例分析
- 6.1 创造力评估在实际场景中的应用
- 6.2 综合评估系统实现
- 7. 总结与展望
- 7.1 创造力评估的重要意义
- 7.2 当前挑战与局限性
- 7.3 未来发展方向
- 7.4 结语
1. 引言:创造力的本质与评估挑战
创造力是人类智能的最高表现形式之一,也是大语言模型能力评估中最具挑战性的维度。当我们谈论机器的创造力时,实际上是在探讨一个深刻的哲学问题:什么是真正的创造?机器能否具备与人类相似的创新能力?
1.1 创造力的多维定义
创造力不是一个简单的概念,它包含多个相互关联的维度。就像一颗钻石有多个切面,每个切面都反射出不同的光芒,创造力也需要从多个角度来理解和评估。
创造力的核心要素:
- 新颖性(Novelty):产生前所未有的想法或作品
- 有用性(Usefulness):创造的内容具有实际价值或意义
- 适当性(Appropriateness):符合特定情境和约束条件
- 意外性(Surprise):超出预期的创新表现
创造力的层次结构:
- 模仿性创造:在现有框架内的变化和组合
- 适应性创造:对现有概念的改进和优化
- 突破性创造:打破传统框架的革命性创新
- 变革性创造:重新定义领域边界的根本性变革
1.2 开放域生成的独特挑战
开放域生成是指在没有严格约束条件下的自由创作,这为创造力评估带来了前所未有的挑战。
评估难点分析:
- 主观性强:创造力评判往往带有强烈的主观色彩
- 标准模糊:缺乏统一的评估标准和基准
- 上下文依赖:创造力的价值高度依赖于具体情境
- 动态变化:创造力标准随时间和文化而变化
技术挑战:
- 多样性测量:如何量化生成内容的多样性
- 质量保证:如何在追求创新的同时保证质量
- 一致性维持:如何在多样化中保持风格一致性
- 可解释性:如何解释创造力评估的结果
2. 创造力评估框架设计
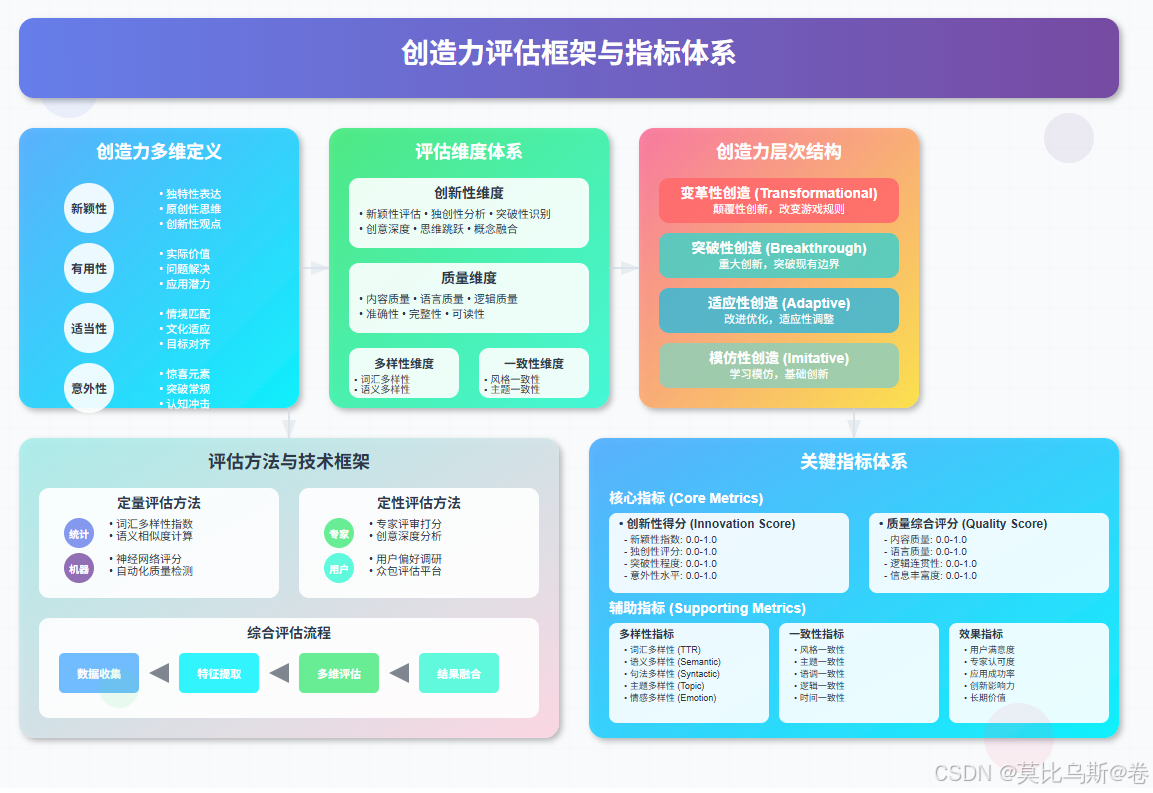
构建科学的创造力评估框架需要综合考虑多个维度和层次。就像建造一座大厦需要坚实的地基和清晰的蓝图,创造力评估也需要理论基础和实践指导。
2.1 多维度评估体系
2.1.1 创新性维度评估
新颖性测量:
- 词汇新颖性:使用罕见词汇和新颖表达的程度
- 概念新颖性:提出新概念或新观点的能力
- 结构新颖性:采用创新叙述结构或表达方式
- 跨域新颖性:跨领域知识融合的创新程度
独创性评估:
- 相似度分析:与训练数据和已有作品的相似程度
- 重复度检测:内容重复和模式化程度
- 原创性指标:基于信息论的原创性量化
- 创新距离:与现有作品在特征空间中的距离
2.1.2 质量维度评估
内容质量:
- 逻辑连贯性:内容的逻辑结构和推理合理性
- 信息丰富度:包含信息的数量和深度
- 表达准确性:语言表达的准确性和规范性
- 主题相关性:与给定主题的相关程度
语言质量:
- 语法正确性:语法规则的遵循程度
- 词汇丰富性:词汇使用的多样性和准确性
- 修辞效果:修辞手法的运用和效果
- 风格一致性:整体风格的统一性
2.2 创造力评估算法实现
import numpy as np
import torch
from transformers import AutoTokenizer, AutoModel
from sklearn.metrics.pairwise import cosine_similarity
from collections import Counter
import re
from typing import List, Dict, Tuple, Any
import mathclass CreativityEvaluator:"""创造力评估器:综合评估文本生成的创造力水平"""def __init__(self, model_name: str = "bert-base-uncased"):self.tokenizer = AutoTokenizer.from_pretrained(model_name)self.model = AutoModel.from_pretrained(model_name)self.model.eval()# 评估权重配置self.weights = {'novelty': 0.3,'quality': 0.25,'diversity': 0.2,'coherence': 0.15,'surprise': 0.1}def evaluate_creativity(self, generated_texts: List[str], reference_corpus: List[str] = None,prompt: str = None) -> Dict[str, float]:"""综合评估创造力水平Args:generated_texts: 生成的文本列表reference_corpus: 参考语料库prompt: 生成提示Returns:评估结果字典"""results = {}# 1. 新颖性评估results['novelty'] = self._evaluate_novelty(generated_texts, reference_corpus)# 2. 质量评估results['quality'] = self._evaluate_quality(generated_texts)# 3. 多样性评估results['diversity'] = self._evaluate_diversity(generated_texts)# 4. 连贯性评估results['coherence'] = self._evaluate_coherence(generated_texts, prompt)# 5. 意外性评估results['surprise'] = self._evaluate_surprise(generated_texts)# 6. 综合创造力得分results['overall_creativity'] = self._calculate_overall_score(results)return resultsdef _evaluate_novelty(self, generated_texts: List[str], reference_corpus: List[str] = None) -> float:"""评估新颖性:基于与参考语料的相似度"""if not reference_corpus:# 使用自相似度作为新颖性指标return self._calculate_self_novelty(generated_texts)novelty_scores = []for text in generated_texts:# 计算与参考语料的最大相似度max_similarity = 0.0text_embedding = self._get_text_embedding(text)for ref_text in reference_corpus:ref_embedding = self._get_text_embedding(ref_text)similarity = cosine_similarity(text_embedding.reshape(1, -1),ref_embedding.reshape(1, -1))[0][0]max_similarity = max(max_similarity, similarity)# 新颖性 = 1 - 最大相似度novelty_scores.append(1.0 - max_similarity)return np.mean(novelty_scores)def _calculate_self_novelty(self, texts: List[str]) -> float:"""计算文本间的自新颖性"""if len(texts) < 2:return 1.0embeddings = [self._get_text_embedding(text) for text in texts]similarities = []for i in range(len(embeddings)):for j in range(i + 1, len(embeddings)):sim = cosine_similarity(embeddings[i].reshape(1, -1),embeddings[j].reshape(1, -1))[0][0]similarities.append(sim)# 平均相似度越低,新颖性越高avg_similarity = np.mean(similarities)return 1.0 - avg_similaritydef _evaluate_quality(self, texts: List[str]) -> float:"""评估内容质量:基于多个质量指标"""quality_scores = []for text in texts:# 1. 语法正确性(简化版)grammar_score = self._assess_grammar_quality(text)# 2. 词汇丰富性lexical_score = self._assess_lexical_diversity(text)# 3. 内容连贯性coherence_score = self._assess_text_coherence(text)# 4. 信息密度information_score = self._assess_information_density(text)# 综合质量得分quality = (grammar_score * 0.3 + lexical_score * 0.25 + coherence_score * 0.25 + information_score * 0.2)quality_scores.append(quality)return np.mean(quality_scores)def _assess_grammar_quality(self, text: str) -> float:"""评估语法质量(简化版)"""# 基于句子完整性和标点使用的简单评估sentences = re.split(r'[.!?]+', text)complete_sentences = 0for sentence in sentences:sentence = sentence.strip()if len(sentence) > 5 and ' ' in sentence:complete_sentences += 1if len(sentences) == 0:return 0.0return complete_sentences / len(sentences)def _assess_lexical_diversity(self, text: str) -> float:"""评估词汇多样性"""words = re.findall(r'\b\w+\b', text.lower())if len(words) == 0:return 0.0unique_words = len(set(words))total_words = len(words)# TTR (Type-Token Ratio)ttr = unique_words / total_words# 调整TTR以考虑文本长度adjusted_ttr = ttr * math.log(total_words + 1)return min(adjusted_ttr, 1.0)def _assess_text_coherence(self, text: str) -> float:"""评估文本连贯性"""sentences = re.split(r'[.!?]+', text)if len(sentences) < 2:return 1.0coherence_scores = []for i in range(len(sentences) - 1):sent1 = sentences[i].strip()sent2 = sentences[i + 1].strip()if sent1 and sent2:emb1 = self._get_text_embedding(sent1)emb2 = self._get_text_embedding(sent2)similarity = cosine_similarity(emb1.reshape(1, -1),emb2.reshape(1, -1))[0][0]coherence_scores.append(similarity)return np.mean(coherence_scores) if coherence_scores else 0.0def _assess_information_density(self, text: str) -> float:"""评估信息密度"""words = re.findall(r'\b\w+\b', text.lower())if len(words) == 0:return 0.0# 计算词频分布的熵word_counts = Counter(words)total_words = len(words)entropy = 0.0for count in word_counts.values():prob = count / total_wordsentropy -= prob * math.log2(prob)# 归一化熵值max_entropy = math.log2(len(word_counts))normalized_entropy = entropy / max_entropy if max_entropy > 0 else 0.0return normalized_entropydef _evaluate_diversity(self, texts: List[str]) -> float:"""评估生成文本的多样性"""if len(texts) < 2:return 1.0# 1. 语义多样性semantic_diversity = self._calculate_semantic_diversity(texts)# 2. 词汇多样性lexical_diversity = self._calculate_lexical_diversity(texts)# 3. 结构多样性structural_diversity = self._calculate_structural_diversity(texts)# 综合多样性得分diversity = (semantic_diversity * 0.4 + lexical_diversity * 0.3 + structural_diversity * 0.3)return diversitydef _calculate_semantic_diversity(self, texts: List[str]) -> float:"""计算语义多样性"""embeddings = [self._get_text_embedding(text) for text in texts]# 计算所有文本对的相似度similarities = []for i in range(len(embeddings)):for j in range(i + 1, len(embeddings)):sim = cosine_similarity(embeddings[i].reshape(1, -1),embeddings[j].reshape(1, -1))[0][0]similarities.append(sim)# 多样性 = 1 - 平均相似度avg_similarity = np.mean(similarities)return 1.0 - avg_similaritydef _calculate_lexical_diversity(self, texts: List[str]) -> float:"""计算词汇多样性"""all_words = set()total_words = 0for text in texts:words = re.findall(r'\b\w+\b', text.lower())all_words.update(words)total_words += len(words)if total_words == 0:return 0.0# 词汇多样性 = 唯一词汇数 / 总词汇数return len(all_words) / total_wordsdef _calculate_structural_diversity(self, texts: List[str]) -> float:"""计算结构多样性"""structures = []for text in texts:# 简化的结构特征:句子长度分布sentences = re.split(r'[.!?]+', text)sentence_lengths = [len(s.split()) for s in sentences if s.strip()]if sentence_lengths:avg_length = np.mean(sentence_lengths)std_length = np.std(sentence_lengths)structures.append((avg_length, std_length))if len(structures) < 2:return 1.0# 计算结构特征的方差avg_lengths = [s[0] for s in structures]std_lengths = [s[1] for s in structures]diversity = (np.std(avg_lengths) + np.std(std_lengths)) / 2return min(diversity / 10.0, 1.0) # 归一化def _evaluate_coherence(self, texts: List[str], prompt: str = None) -> float:"""评估与提示的连贯性"""if not prompt:# 评估内部连贯性return np.mean([self._assess_text_coherence(text) for text in texts])coherence_scores = []prompt_embedding = self._get_text_embedding(prompt)for text in texts:text_embedding = self._get_text_embedding(text)similarity = cosine_similarity(prompt_embedding.reshape(1, -1),text_embedding.reshape(1, -1))[0][0]coherence_scores.append(similarity)return np.mean(coherence_scores)def _evaluate_surprise(self, texts: List[str]) -> float:"""评估意外性:基于预测难度"""surprise_scores = []for text in texts:# 计算文本的困惑度作为意外性指标perplexity = self._calculate_perplexity(text)# 将困惑度转换为0-1范围的意外性得分surprise = min(math.log(perplexity) / 10.0, 1.0)surprise_scores.append(surprise)return np.mean(surprise_scores)def _calculate_perplexity(self, text: str) -> float:"""计算文本困惑度(简化版)"""words = re.findall(r'\b\w+\b', text.lower())if len(words) == 0:return 1.0# 基于词频的简化困惑度计算word_counts = Counter(words)total_words = len(words)log_prob_sum = 0.0for word, count in word_counts.items():prob = count / total_wordslog_prob_sum += count * math.log(prob)perplexity = math.exp(-log_prob_sum / total_words)return perplexitydef _get_text_embedding(self, text: str) -> np.ndarray:"""获取文本的向量表示"""inputs = self.tokenizer(text, return_tensors="pt", truncation=True, max_length=512)with torch.no_grad():outputs = self.model(**inputs)# 使用[CLS]标记的表示作为文本嵌入embedding = outputs.last_hidden_state[:, 0, :].numpy().flatten()return embeddingdef _calculate_overall_score(self, results: Dict[str, float]) -> float:"""计算综合创造力得分"""overall_score = 0.0for dimension, weight in self.weights.items():if dimension in results:overall_score += results[dimension] * weightreturn overall_score# 使用示例
if __name__ == "__main__":# 创建评估器evaluator = CreativityEvaluator()# 示例生成文本generated_texts = ["在遥远的星球上,有一种会唱歌的水晶,它们的歌声能够治愈心灵的创伤。","时间是一条河流,而我们都是河中的鱼,游向未知的海洋。","她的笑容像春天的第一缕阳光,温暖而充满希望。"]# 评估创造力results = evaluator.evaluate_creativity(generated_texts)print("创造力评估结果:")for dimension, score in results.items():print(f"{dimension}: {score:.3f}")
3. 多样性与一致性平衡技术
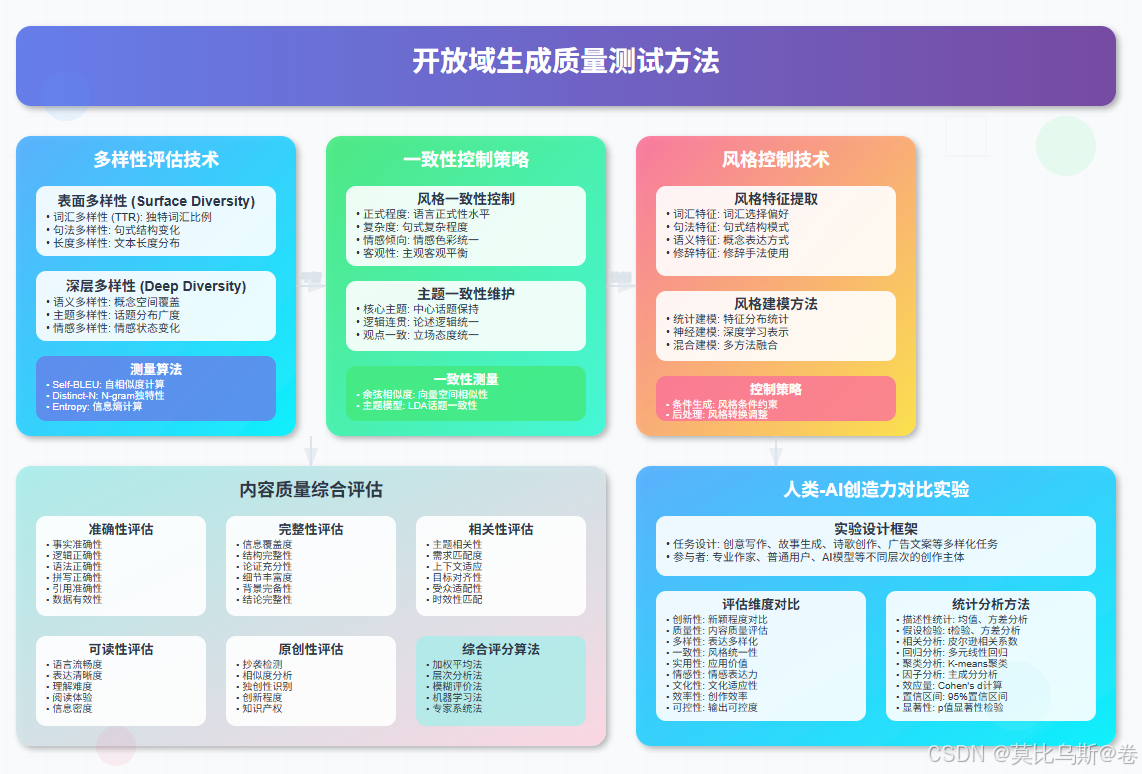
在创造力评估中,多样性与一致性的平衡是一个核心挑战。就像音乐中的和谐与变化,既要有丰富的变化来保持趣味性,又要有统一的主题来维持连贯性。
3.1 多样性评估的深度分析
3.1.1 多样性的多层次理解
表面多样性:
- 词汇多样性:使用不同词汇的程度
- 句式多样性:句子结构的变化程度
- 长度多样性:文本长度的分布情况
- 风格多样性:表达风格的差异程度
深层多样性:
- 语义多样性:表达含义的丰富程度
- 主题多样性:涉及主题的广泛程度
- 视角多样性:观察角度的多元化
- 情感多样性:情感表达的丰富性
3.1.2 多样性测量算法
class DiversityAnalyzer:"""多样性分析器:全面评估生成内容的多样性"""def __init__(self):self.diversity_metrics = {'lexical': self._calculate_lexical_diversity,'semantic': self._calculate_semantic_diversity,'syntactic': self._calculate_syntactic_diversity,'thematic': self._calculate_thematic_diversity,'emotional': self._calculate_emotional_diversity}def analyze_diversity(self, texts: List[str]) -> Dict[str, float]:"""综合分析多样性"""results = {}for metric_name, metric_func in self.diversity_metrics.items():results[metric_name] = metric_func(texts)# 计算综合多样性得分results['overall_diversity'] = np.mean(list(results.values()))return resultsdef _calculate_lexical_diversity(self, texts: List[str]) -> float:"""计算词汇多样性"""all_words = []for text in texts:words = re.findall(r'\b\w+\b', text.lower())all_words.extend(words)if not all_words:return 0.0unique_words = len(set(all_words))total_words = len(all_words)# 使用修正的TTRmattr = unique_words / math.sqrt(2 * total_words)return min(mattr, 1.0)def _calculate_semantic_diversity(self, texts: List[str]) -> float:"""计算语义多样性"""if len(texts) < 2:return 1.0# 使用词向量计算语义相似度embeddings = [self._get_sentence_embedding(text) for text in texts]similarities = []for i in range(len(embeddings)):for j in range(i + 1, len(embeddings)):sim = cosine_similarity(embeddings[i].reshape(1, -1),embeddings[j].reshape(1, -1))[0][0]similarities.append(sim)# 语义多样性 = 1 - 平均相似度return 1.0 - np.mean(similarities)def _calculate_syntactic_diversity(self, texts: List[str]) -> float:"""计算句法多样性"""sentence_patterns = []for text in texts:sentences = re.split(r'[.!?]+', text)for sentence in sentences:if sentence.strip():pattern = self._extract_sentence_pattern(sentence)sentence_patterns.append(pattern)if not sentence_patterns:return 0.0unique_patterns = len(set(sentence_patterns))total_patterns = len(sentence_patterns)return unique_patterns / total_patternsdef _extract_sentence_pattern(self, sentence: str) -> str:"""提取句子模式(简化版)"""words = sentence.strip().split()if not words:return ""# 简化的句子模式:基于词性和长度pattern = f"L{len(words)}"# 添加标点符号信息if sentence.strip().endswith('?'):pattern += "_Q"elif sentence.strip().endswith('!'):pattern += "_E"else:pattern += "_S"return patterndef _calculate_thematic_diversity(self, texts: List[str]) -> float:"""计算主题多样性"""# 使用关键词提取来估计主题多样性all_keywords = set()text_keywords = []for text in texts:keywords = self._extract_keywords(text)text_keywords.append(keywords)all_keywords.update(keywords)if not all_keywords:return 0.0# 计算主题覆盖度coverage_scores = []for keywords in text_keywords:coverage = len(keywords) / len(all_keywords) if all_keywords else 0coverage_scores.append(coverage)# 主题多样性基于覆盖度的标准差return np.std(coverage_scores) if coverage_scores else 0.0def _extract_keywords(self, text: str, top_k: int = 5) -> List[str]:"""提取关键词(简化版)"""words = re.findall(r'\b\w+\b', text.lower())# 过滤停用词(简化版)stop_words = {'the', 'a', 'an', 'and', 'or', 'but', 'in', 'on', 'at', 'to', 'for', 'of', 'with', 'by', 'is', 'are', 'was', 'were'}filtered_words = [w for w in words if w not in stop_words and len(w) > 2]# 计算词频word_counts = Counter(filtered_words)# 返回最频繁的词作为关键词return [word for word, count in word_counts.most_common(top_k)]def _calculate_emotional_diversity(self, texts: List[str]) -> float:"""计算情感多样性"""emotions = []for text in texts:emotion_score = self._analyze_emotion(text)emotions.append(emotion_score)if not emotions:return 0.0# 情感多样性基于情感得分的标准差return np.std(emotions)def _analyze_emotion(self, text: str) -> float:"""分析文本情感(简化版)"""# 简化的情感词典positive_words = {'happy', 'joy', 'love', 'wonderful', 'amazing', 'beautiful', 'great', 'excellent', 'fantastic'}negative_words = {'sad', 'angry', 'hate', 'terrible', 'awful', 'horrible', 'bad', 'worst', 'disgusting'}words = re.findall(r'\b\w+\b', text.lower())positive_count = sum(1 for word in words if word in positive_words)negative_count = sum(1 for word in words if word in negative_words)if positive_count + negative_count == 0:return 0.0 # 中性# 情感极性得分emotion_score = (positive_count - negative_count) / len(words)return emotion_scoredef _get_sentence_embedding(self, text: str) -> np.ndarray:"""获取句子嵌入(简化版)"""# 这里应该使用预训练的句子嵌入模型# 为了简化,使用词向量的平均值words = re.findall(r'\b\w+\b', text.lower())# 简化的词向量(随机生成,实际应用中应使用预训练向量)embedding_dim = 300word_embeddings = []for word in words:# 基于词的哈希值生成伪向量np.random.seed(hash(word) % 2**32)embedding = np.random.randn(embedding_dim)word_embeddings.append(embedding)if not word_embeddings:return np.zeros(embedding_dim)# 返回平均词向量return np.mean(word_embeddings, axis=0)# 使用示例
if __name__ == "__main__":analyzer = DiversityAnalyzer()sample_texts = ["今天天气真好,阳光明媚,适合出去散步。","昨晚的雨下得很大,现在空气格外清新。","她喜欢在图书馆里安静地读书,享受知识的乐趣。"]diversity_results = analyzer.analyze_diversity(sample_texts)print("多样性分析结果:")for metric, score in diversity_results.items():print(f"{metric}: {score:.3f}")
3.2 一致性保持策略
3.2.1 风格一致性控制
风格一致性是指在保持创造性的同时,维持整体表达风格的统一性。这就像一个作家的作品,虽然内容各异,但总能让读者感受到独特的个人风格。
风格要素分析:
- 语言风格:正式vs非正式、学术vs通俗
- 情感基调:积极vs消极、客观vs主观
- 表达方式:直接vs含蓄、简洁vs详细
- 修辞特征:比喻、排比、反问等修辞手法的使用
一致性控制方法:
- 风格向量约束:在生成过程中加入风格向量约束
- 对抗性训练:使用判别器识别风格不一致的内容
- 模板引导:通过模板结构保持格式一致性
- 后处理调整:生成后进行风格统一化处理
3.2.2 主题一致性维护
class ConsistencyController:"""一致性控制器:确保生成内容的风格和主题一致性"""def __init__(self):self.style_features = {'formality': self._measure_formality,'complexity': self._measure_complexity,'sentiment': self._measure_sentiment,'objectivity': self._measure_objectivity}def evaluate_consistency(self, texts: List[str]) -> Dict[str, float]:"""评估文本一致性"""if len(texts) < 2:return {'overall_consistency': 1.0}consistency_scores = {}# 评估各个维度的一致性for feature_name, feature_func in self.style_features.items():scores = [feature_func(text) for text in texts]consistency = 1.0 - np.std(scores) # 标准差越小,一致性越高consistency_scores[f'{feature_name}_consistency'] = max(0.0, consistency)# 计算综合一致性consistency_scores['overall_consistency'] = np.mean(list(consistency_scores.values()))return consistency_scoresdef _measure_formality(self, text: str) -> float:"""测量文本正式程度"""formal_indicators = {'contractions': ["n't", "'re", "'ve", "'ll", "'d"],'informal_words': ['gonna', 'wanna', 'yeah', 'ok', 'cool'],'formal_words': ['therefore', 'furthermore', 'consequently', 'nevertheless', 'moreover']}text_lower = text.lower()# 计算非正式指标informal_count = 0for contraction in formal_indicators['contractions']:informal_count += text_lower.count(contraction)for word in formal_indicators['informal_words']:informal_count += text_lower.count(word)# 计算正式指标formal_count = 0for word in formal_indicators['formal_words']:formal_count += text_lower.count(word)# 正式程度得分total_words = len(text.split())if total_words == 0:return 0.5formality_score = (formal_count - informal_count) / total_wordsreturn max(0.0, min(1.0, formality_score + 0.5)) # 归一化到[0,1]def _measure_complexity(self, text: str) -> float:"""测量文本复杂度"""sentences = re.split(r'[.!?]+', text)if not sentences:return 0.0# 平均句子长度avg_sentence_length = np.mean([len(s.split()) for s in sentences if s.strip()])# 词汇复杂度(平均词长)words = re.findall(r'\b\w+\b', text)avg_word_length = np.mean([len(word) for word in words]) if words else 0# 复杂度得分complexity = (avg_sentence_length / 20.0 + avg_word_length / 10.0) / 2return min(1.0, complexity)def _measure_sentiment(self, text: str) -> float:"""测量文本情感倾向"""# 简化的情感分析positive_words = ['good', 'great', 'excellent', 'wonderful', 'amazing', 'beautiful', 'love', 'like', 'happy', 'joy']negative_words = ['bad', 'terrible', 'awful', 'horrible', 'hate', 'dislike', 'sad', 'angry', 'disappointed', 'frustrated']words = re.findall(r'\b\w+\b', text.lower())positive_count = sum(1 for word in words if word in positive_words)negative_count = sum(1 for word in words if word in negative_words)if positive_count + negative_count == 0:return 0.5 # 中性sentiment_score = positive_count / (positive_count + negative_count)return sentiment_scoredef _measure_objectivity(self, text: str) -> float:"""测量文本客观性"""subjective_indicators = ['i think', 'i believe', 'in my opinion', 'i feel', 'personally', 'i suppose']objective_indicators = ['according to', 'research shows', 'data indicates', 'studies suggest', 'evidence demonstrates']text_lower = text.lower()subjective_count = sum(text_lower.count(indicator) for indicator in subjective_indicators)objective_count = sum(text_lower.count(indicator) for indicator in objective_indicators)total_indicators = subjective_count + objective_countif total_indicators == 0:return 0.5 # 中性objectivity_score = objective_count / total_indicatorsreturn objectivity_scoredef balance_diversity_consistency(self, texts: List[str], diversity_weight: float = 0.6,consistency_weight: float = 0.4) -> float:"""平衡多样性和一致性"""# 计算多样性得分analyzer = DiversityAnalyzer()diversity_results = analyzer.analyze_diversity(texts)diversity_score = diversity_results['overall_diversity']# 计算一致性得分consistency_results = self.evaluate_consistency(texts)consistency_score = consistency_results['overall_consistency']# 加权平衡得分balance_score = (diversity_score * diversity_weight + consistency_score * consistency_weight)return balance_score# 使用示例
if __name__ == "__main__":controller = ConsistencyController()sample_texts = ["根据最新的研究数据显示,人工智能技术在医疗领域的应用前景广阔。","我认为AI在医疗方面真的很有潜力,特别是在诊断方面。","医疗AI的发展确实令人兴奋,但我们也需要考虑伦理问题。"]consistency_results = controller.evaluate_consistency(sample_texts)balance_score = controller.balance_diversity_consistency(sample_texts)print("一致性评估结果:")for metric, score in consistency_results.items():print(f"{metric}: {score:.3f}")print(f"\n多样性-一致性平衡得分: {balance_score:.3f}")
4. 风格控制与内容质量评估
风格控制与内容质量评估是创造力评估的两个关键维度。风格控制确保生成内容符合特定的表达要求,而内容质量评估则保证创造性不以牺牲质量为代价。
4.1 风格控制技术深度解析
4.1.1 风格特征提取与建模
风格是文本的"指纹",每种风格都有其独特的特征组合。就像画家的笔触,虽然画的内容不同,但总能让人识别出是谁的作品。
风格特征体系:
- 词汇特征:词汇选择偏好、专业术语使用
- 句法特征:句子结构、从句使用频率
- 修辞特征:比喻、排比、设问等修辞手法
- 语篇特征:段落组织、逻辑连接方式
class StyleController:"""风格控制器:实现精确的文本风格控制和评估"""def __init__(self):self.style_dimensions = {'formality': {'formal': 1.0, 'informal': 0.0},'complexity': {'complex': 1.0, 'simple': 0.0},'emotion': {'emotional': 1.0, 'neutral': 0.0},'creativity': {'creative': 1.0, 'conventional': 0.0}}# 风格特征权重self.feature_weights = {'lexical': 0.3,'syntactic': 0.25,'semantic': 0.25,'rhetorical': 0.2}def extract_style_features(self, text: str) -> Dict[str, float]:"""提取文本的风格特征"""features = {}# 1. 词汇特征features.update(self._extract_lexical_features(text))# 2. 句法特征features.update(self._extract_syntactic_features(text))# 3. 语义特征features.update(self._extract_semantic_features(text))# 4. 修辞特征features.update(self._extract_rhetorical_features(text))return featuresdef _extract_lexical_features(self, text: str) -> Dict[str, float]:"""提取词汇特征"""words = re.findall(r'\b\w+\b', text.lower())if not words:return {'avg_word_length': 0, 'lexical_diversity': 0, 'rare_word_ratio': 0}# 平均词长avg_word_length = np.mean([len(word) for word in words])# 词汇多样性unique_words = len(set(words))lexical_diversity = unique_words / len(words)# 罕见词比例(长度>6的词)rare_words = [word for word in words if len(word) > 6]rare_word_ratio = len(rare_words) / len(words)return {'avg_word_length': avg_word_length / 10.0, # 归一化'lexical_diversity': lexical_diversity,'rare_word_ratio': rare_word_ratio}def _extract_syntactic_features(self, text: str) -> Dict[str, float]:"""提取句法特征"""sentences = re.split(r'[.!?]+', text)sentences = [s.strip() for s in sentences if s.strip()]if not sentences:return {'avg_sentence_length': 0, 'sentence_variety': 0, 'complex_sentence_ratio': 0}# 平均句长sentence_lengths = [len(s.split()) for s in sentences]avg_sentence_length = np.mean(sentence_lengths)# 句长变化度sentence_variety = np.std(sentence_lengths) / (avg_sentence_length + 1)# 复杂句比例(包含逗号的句子)complex_sentences = [s for s in sentences if ',' in s]complex_sentence_ratio = len(complex_sentences) / len(sentences)return {'avg_sentence_length': min(avg_sentence_length / 20.0, 1.0),'sentence_variety': min(sentence_variety, 1.0),'complex_sentence_ratio': complex_sentence_ratio}def _extract_semantic_features(self, text: str) -> Dict[str, float]:"""提取语义特征"""# 抽象词汇比例abstract_words = ['concept', 'idea', 'theory', 'principle', 'philosophy', 'emotion', 'feeling', 'thought', 'belief', 'value']concrete_words = ['table', 'chair', 'book', 'car', 'house', 'tree', 'water', 'food', 'money', 'computer']words = re.findall(r'\b\w+\b', text.lower())abstract_count = sum(1 for word in words if word in abstract_words)concrete_count = sum(1 for word in words if word in concrete_words)total_semantic_words = abstract_count + concrete_countif total_semantic_words == 0:abstraction_level = 0.5else:abstraction_level = abstract_count / total_semantic_words# 情感强度emotion_words = ['love', 'hate', 'amazing', 'terrible', 'wonderful', 'awful', 'fantastic', 'horrible', 'brilliant', 'disgusting']emotion_count = sum(1 for word in words if word in emotion_words)emotion_intensity = emotion_count / len(words) if words else 0return {'abstraction_level': abstraction_level,'emotion_intensity': min(emotion_intensity * 10, 1.0)}def _extract_rhetorical_features(self, text: str) -> Dict[str, float]:"""提取修辞特征"""# 问句比例sentences = re.split(r'[.!?]+', text)question_count = len([s for s in sentences if '?' in s])question_ratio = question_count / len(sentences) if sentences else 0# 感叹句比例exclamation_count = len([s for s in sentences if '!' in s])exclamation_ratio = exclamation_count / len(sentences) if sentences else 0# 比喻词汇metaphor_words = ['like', 'as', '似乎', '如同', '仿佛', '好像']metaphor_count = sum(text.lower().count(word) for word in metaphor_words)metaphor_density = metaphor_count / len(text.split()) if text.split() else 0return {'question_ratio': question_ratio,'exclamation_ratio': exclamation_ratio,'metaphor_density': min(metaphor_density * 5, 1.0)}def calculate_style_similarity(self, text1: str, text2: str) -> float:"""计算两个文本的风格相似度"""features1 = self.extract_style_features(text1)features2 = self.extract_style_features(text2)# 计算特征向量的余弦相似度common_features = set(features1.keys()) & set(features2.keys())if not common_features:return 0.0vec1 = np.array([features1[f] for f in common_features])vec2 = np.array([features2[f] for f in common_features])# 余弦相似度similarity = cosine_similarity(vec1.reshape(1, -1), vec2.reshape(1, -1))[0][0]return similaritydef evaluate_style_consistency(self, texts: List[str]) -> float:"""评估多个文本的风格一致性"""if len(texts) < 2:return 1.0similarities = []for i in range(len(texts)):for j in range(i + 1, len(texts)):sim = self.calculate_style_similarity(texts[i], texts[j])similarities.append(sim)return np.mean(similarities)def control_style_generation(self, base_text: str, target_style: Dict[str, float],adjustment_strength: float = 0.5) -> str:"""风格控制生成(简化版)"""current_features = self.extract_style_features(base_text)# 分析需要调整的方向adjustments = []for style_dim, target_value in target_style.items():if style_dim in current_features:current_value = current_features[style_dim]diff = target_value - current_valueif abs(diff) > 0.1: # 需要调整adjustments.append((style_dim, diff))# 应用风格调整(这里是简化的示例)adjusted_text = base_textfor style_dim, diff in adjustments:adjusted_text = self._apply_style_adjustment(adjusted_text, style_dim, diff, adjustment_strength)return adjusted_textdef _apply_style_adjustment(self, text: str, style_dim: str, diff: float, strength: float) -> str:"""应用风格调整(简化版实现)"""# 这里是简化的风格调整实现# 实际应用中需要更复杂的NLG技术if style_dim == 'formality' and diff > 0:# 增加正式性:替换缩写词text = re.sub(r"can't", "cannot", text)text = re.sub(r"won't", "will not", text)text = re.sub(r"don't", "do not", text)elif style_dim == 'complexity' and diff > 0:# 增加复杂性:添加修饰词text = re.sub(r'\b(good)\b', 'excellent', text)text = re.sub(r'\b(big)\b', 'substantial', text)elif style_dim == 'emotion_intensity' and diff > 0:# 增加情感强度:添加感叹号text = re.sub(r'\.$', '!', text)return text# 使用示例
if __name__ == "__main__":controller = StyleController()sample_text = "This is a good example of text analysis. It works well."# 提取风格特征features = controller.extract_style_features(sample_text)print("风格特征:")for feature, value in features.items():print(f"{feature}: {value:.3f}")# 风格控制生成target_style = {'formality': 0.8,'complexity': 0.7,'emotion_intensity': 0.6}adjusted_text = controller.control_style_generation(sample_text, target_style)print(f"\n原文: {sample_text}")print(f"调整后: {adjusted_text}")
4.2 内容质量综合评估
4.2.1 质量评估的多维框架
内容质量不是单一指标,而是多个维度的综合体现。就像评价一道菜的好坏,需要考虑色香味俱全,内容质量也需要从多个角度进行评估。
质量维度体系:
- 准确性(Accuracy):信息的正确性和可靠性
- 完整性(Completeness):内容的全面性和深度
- 相关性(Relevance):与主题的关联程度
- 可读性(Readability):表达的清晰度和易理解性
- 原创性(Originality):内容的独特性和创新性
class ContentQualityEvaluator:"""内容质量评估器:全面评估生成内容的质量水平"""def __init__(self):self.quality_dimensions = {'accuracy': 0.25,'completeness': 0.2,'relevance': 0.2,'readability': 0.2,'originality': 0.15}# 质量阈值self.quality_thresholds = {'excellent': 0.8,'good': 0.6,'fair': 0.4,'poor': 0.2}def evaluate_content_quality(self, text: str, reference_texts: List[str] = None,topic: str = None) -> Dict[str, Any]:"""综合评估内容质量"""results = {}# 1. 准确性评估results['accuracy'] = self._evaluate_accuracy(text, reference_texts)# 2. 完整性评估results['completeness'] = self._evaluate_completeness(text, topic)# 3. 相关性评估results['relevance'] = self._evaluate_relevance(text, topic)# 4. 可读性评估results['readability'] = self._evaluate_readability(text)# 5. 原创性评估results['originality'] = self._evaluate_originality(text, reference_texts)# 6. 综合质量得分results['overall_quality'] = self._calculate_overall_quality(results)# 7. 质量等级results['quality_level'] = self._determine_quality_level(results['overall_quality'])return resultsdef _evaluate_accuracy(self, text: str, reference_texts: List[str] = None) -> float:"""评估内容准确性"""# 简化的准确性评估accuracy_indicators = {'factual_words': ['research', 'study', 'data', 'evidence', 'fact'],'uncertain_words': ['maybe', 'perhaps', 'possibly', 'might', 'could'],'absolute_words': ['always', 'never', 'all', 'none', 'every']}words = re.findall(r'\b\w+\b', text.lower())factual_count = sum(1 for word in words if word in accuracy_indicators['factual_words'])uncertain_count = sum(1 for word in words if word in accuracy_indicators['uncertain_words'])absolute_count = sum(1 for word in words if word in accuracy_indicators['absolute_words'])# 准确性得分:事实性词汇增加得分,绝对性词汇减少得分if len(words) == 0:return 0.5accuracy_score = (factual_count * 0.1 - absolute_count * 0.05) / len(words)return max(0.0, min(1.0, accuracy_score + 0.7)) # 基础分0.7def _evaluate_completeness(self, text: str, topic: str = None) -> float:"""评估内容完整性"""# 基于文本长度和结构完整性sentences = re.split(r'[.!?]+', text)sentences = [s.strip() for s in sentences if s.strip()]# 长度完整性word_count = len(text.split())length_score = min(word_count / 100.0, 1.0) # 100词为满分# 结构完整性structure_score = 0.0if len(sentences) >= 3: # 至少3个句子structure_score += 0.3if any('?' in s for s in sentences): # 包含问句structure_score += 0.2if len(set(re.findall(r'\b\w+\b', text.lower()))) > 20: # 词汇丰富structure_score += 0.3if text.count(',') >= 2: # 包含复杂句structure_score += 0.2completeness = (length_score * 0.6 + structure_score * 0.4)return min(completeness, 1.0)def _evaluate_relevance(self, text: str, topic: str = None) -> float:"""评估内容相关性"""if not topic:return 0.8 # 无主题时给予默认分数# 提取主题关键词topic_words = set(re.findall(r'\b\w+\b', topic.lower()))text_words = set(re.findall(r'\b\w+\b', text.lower()))# 计算词汇重叠度overlap = len(topic_words & text_words)relevance_score = overlap / len(topic_words) if topic_words else 0.0return min(relevance_score * 2, 1.0) # 放大相关性得分def _evaluate_readability(self, text: str) -> float:"""评估可读性"""sentences = re.split(r'[.!?]+', text)sentences = [s.strip() for s in sentences if s.strip()]if not sentences:return 0.0# 平均句长(理想范围:10-20词)sentence_lengths = [len(s.split()) for s in sentences]avg_sentence_length = np.mean(sentence_lengths)# 句长得分if 10 <= avg_sentence_length <= 20:length_score = 1.0else:length_score = max(0.0, 1.0 - abs(avg_sentence_length - 15) / 15)# 词汇难度(基于平均词长)words = re.findall(r'\b\w+\b', text)avg_word_length = np.mean([len(word) for word in words]) if words else 0# 理想词长:4-6字符if 4 <= avg_word_length <= 6:word_score = 1.0else:word_score = max(0.0, 1.0 - abs(avg_word_length - 5) / 5)# 标点符号使用punctuation_score = min(text.count(',') / len(sentences), 1.0) if sentences else 0readability = (length_score * 0.4 + word_score * 0.4 + punctuation_score * 0.2)return readabilitydef _evaluate_originality(self, text: str, reference_texts: List[str] = None) -> float:"""评估原创性"""if not reference_texts:# 基于内部多样性评估原创性return self._calculate_internal_originality(text)# 与参考文本的相似度max_similarity = 0.0text_words = set(re.findall(r'\b\w+\b', text.lower()))for ref_text in reference_texts:ref_words = set(re.findall(r'\b\w+\b', ref_text.lower()))if text_words and ref_words:similarity = len(text_words & ref_words) / len(text_words | ref_words)max_similarity = max(max_similarity, similarity)# 原创性 = 1 - 最大相似度return 1.0 - max_similaritydef _calculate_internal_originality(self, text: str) -> float:"""计算内部原创性"""words = re.findall(r'\b\w+\b', text.lower())if len(words) < 10:return 0.5# 词汇多样性unique_words = len(set(words))diversity = unique_words / len(words)# 罕见词比例rare_words = [w for w in words if len(w) > 6]rare_ratio = len(rare_words) / len(words)# 创新表达(包含比喻等)creative_patterns = ['like', 'as if', '似乎', '仿佛', '如同']creative_count = sum(text.lower().count(pattern) for pattern in creative_patterns)creative_score = min(creative_count / len(words) * 10, 1.0)originality = (diversity * 0.5 + rare_ratio * 0.3 + creative_score * 0.2)return originalitydef _calculate_overall_quality(self, results: Dict[str, float]) -> float:"""计算综合质量得分"""overall_score = 0.0for dimension, weight in self.quality_dimensions.items():if dimension in results:overall_score += results[dimension] * weightreturn overall_scoredef _determine_quality_level(self, score: float) -> str:"""确定质量等级"""if score >= self.quality_thresholds['excellent']:return 'excellent'elif score >= self.quality_thresholds['good']:return 'good'elif score >= self.quality_thresholds['fair']:return 'fair'else:return 'poor'# 使用示例
if __name__ == "__main__":evaluator = ContentQualityEvaluator()sample_text = """人工智能技术的发展为医疗行业带来了革命性的变化。通过机器学习算法,医生可以更准确地诊断疾病,提高治疗效果。然而,我们也需要考虑数据隐私和算法偏见等伦理问题。"""quality_results = evaluator.evaluate_content_quality(sample_text, topic="人工智能在医疗中的应用")print("内容质量评估结果:")for dimension, score in quality_results.items():if isinstance(score, float):print(f"{dimension}: {score:.3f}")else:print(f"{dimension}: {score}")
5. 人类创造力对比实验设计
5.1 实验框架设计
人类创造力对比实验是评估AI创造力的重要基准。就像运动员需要与其他选手比赛来证明实力,AI的创造力也需要与人类创造力进行对比来验证其水平。
实验设计原则:
- 公平性:确保人类和AI在相同条件下进行创作
- 多样性:涵盖不同类型和难度的创作任务
- 客观性:建立客观的评估标准和流程
- 可重复性:实验结果应该可以重现和验证
实验流程设计:
- 任务设计:创建标准化的创作任务
- 参与者招募:选择合适的人类创作者
- 创作执行:在控制条件下进行创作
- 结果评估:使用多维度评估体系
- 数据分析:统计分析和结果解释
5.2 对比实验实现
class HumanAICreativityComparison:"""人类-AI创造力对比实验系统"""def __init__(self):self.creativity_evaluator = CreativityEvaluator()self.quality_evaluator = ContentQualityEvaluator()# 实验配置self.experiment_config = {'task_types': ['story_writing', 'poetry', 'dialogue', 'description'],'difficulty_levels': ['easy', 'medium', 'hard'],'time_limits': {'easy': 300, 'medium': 600, 'hard': 900}, # 秒'evaluation_criteria': ['creativity', 'quality', 'originality', 'coherence']}def design_creativity_tasks(self, task_type: str, difficulty: str) -> Dict[str, Any]:"""设计创造力测试任务"""tasks = {'story_writing': {'easy': {'prompt': '写一个关于友谊的短故事','constraints': ['200-300字', '包含对话', '积极结局'],'evaluation_focus': ['情节完整性', '人物塑造', '情感表达']},'medium': {'prompt': '创作一个科幻背景下的冒险故事','constraints': ['400-500字', '包含转折', '原创设定'],'evaluation_focus': ['创新性', '逻辑性', '想象力']},'hard': {'prompt': '写一个多线程叙事的悬疑故事','constraints': ['600-800字', '多重视角', '开放结局'],'evaluation_focus': ['结构复杂性', '悬念营造', '叙事技巧']}},'poetry': {'easy': {'prompt': '创作一首关于春天的诗歌','constraints': ['4-8行', '押韵', '意象丰富'],'evaluation_focus': ['韵律美感', '意象创新', '情感表达']},'medium': {'prompt': '写一首现代自由诗表达孤独感','constraints': ['12-20行', '不要求押韵', '抽象表达'],'evaluation_focus': ['情感深度', '语言创新', '意境营造']},'hard': {'prompt': '创作一首实验性诗歌探讨时间概念','constraints': ['形式创新', '哲学思辨', '语言实验'],'evaluation_focus': ['形式创新', '思想深度', '艺术性']}}}return tasks.get(task_type, {}).get(difficulty, {})def conduct_comparison_experiment(self, task_type: str, difficulty: str,human_responses: List[str],ai_responses: List[str]) -> Dict[str, Any]:"""执行对比实验"""task = self.design_creativity_tasks(task_type, difficulty)results = {'task_info': task,'human_results': self._evaluate_responses(human_responses, 'human'),'ai_results': self._evaluate_responses(ai_responses, 'ai'),'comparison': {}}# 对比分析results['comparison'] = self._compare_results(results['human_results'], results['ai_results'])return resultsdef _evaluate_responses(self, responses: List[str], source_type: str) -> Dict[str, Any]:"""评估回答质量"""creativity_scores = []quality_scores = []for response in responses:# 创造力评估creativity_result = self.creativity_evaluator.evaluate_creativity([response])creativity_scores.append(creativity_result['overall_creativity'])# 质量评估quality_result = self.quality_evaluator.evaluate_content_quality(response)quality_scores.append(quality_result['overall_quality'])return {'source_type': source_type,'response_count': len(responses),'creativity_scores': creativity_scores,'quality_scores': quality_scores,'avg_creativity': np.mean(creativity_scores),'avg_quality': np.mean(quality_scores),'std_creativity': np.std(creativity_scores),'std_quality': np.std(quality_scores)}def _compare_results(self, human_results: Dict, ai_results: Dict) -> Dict[str, Any]:"""对比人类和AI的结果"""comparison = {}# 平均分对比comparison['creativity_comparison'] = {'human_avg': human_results['avg_creativity'],'ai_avg': ai_results['avg_creativity'],'difference': human_results['avg_creativity'] - ai_results['avg_creativity'],'ai_advantage': ai_results['avg_creativity'] > human_results['avg_creativity']}comparison['quality_comparison'] = {'human_avg': human_results['avg_quality'],'ai_avg': ai_results['avg_quality'],'difference': human_results['avg_quality'] - ai_results['avg_quality'],'ai_advantage': ai_results['avg_quality'] > human_results['avg_quality']}# 一致性对比comparison['consistency_comparison'] = {'human_creativity_std': human_results['std_creativity'],'ai_creativity_std': ai_results['std_creativity'],'human_quality_std': human_results['std_quality'],'ai_quality_std': ai_results['std_quality'],'ai_more_consistent': (ai_results['std_creativity'] < human_results['std_creativity'] and ai_results['std_quality'] < human_results['std_quality'])}# 统计显著性检验(简化版)comparison['statistical_significance'] = self._test_significance(human_results, ai_results)return comparisondef _test_significance(self, human_results: Dict, ai_results: Dict) -> Dict[str, bool]:"""统计显著性检验(简化版)"""from scipy import stats# t检验creativity_t_stat, creativity_p_value = stats.ttest_ind(human_results['creativity_scores'],ai_results['creativity_scores'])quality_t_stat, quality_p_value = stats.ttest_ind(human_results['quality_scores'],ai_results['quality_scores'])return {'creativity_significant': creativity_p_value < 0.05,'quality_significant': quality_p_value < 0.05,'creativity_p_value': creativity_p_value,'quality_p_value': quality_p_value}def generate_experiment_report(self, results: Dict[str, Any]) -> str:"""生成实验报告"""report = f"""
# 人类-AI创造力对比实验报告## 实验任务
- 任务类型: {results['task_info'].get('prompt', 'N/A')}
- 约束条件: {', '.join(results['task_info'].get('constraints', []))}## 实验结果### 创造力对比
- 人类平均分: {results['comparison']['creativity_comparison']['human_avg']:.3f}
- AI平均分: {results['comparison']['creativity_comparison']['ai_avg']:.3f}
- 差异: {results['comparison']['creativity_comparison']['difference']:.3f}
- AI优势: {results['comparison']['creativity_comparison']['ai_advantage']}### 质量对比
- 人类平均分: {results['comparison']['quality_comparison']['human_avg']:.3f}
- AI平均分: {results['comparison']['quality_comparison']['ai_avg']:.3f}
- 差异: {results['comparison']['quality_comparison']['difference']:.3f}
- AI优势: {results['comparison']['quality_comparison']['ai_advantage']}### 一致性分析
- AI更一致: {results['comparison']['consistency_comparison']['ai_more_consistent']}
- 人类创造力标准差: {results['comparison']['consistency_comparison']['human_creativity_std']:.3f}
- AI创造力标准差: {results['comparison']['consistency_comparison']['ai_creativity_std']:.3f}### 统计显著性
- 创造力差异显著: {results['comparison']['statistical_significance']['creativity_significant']}
- 质量差异显著: {results['comparison']['statistical_significance']['quality_significant']}"""return report# 使用示例
if __name__ == "__main__":comparator = HumanAICreativityComparison()# 模拟实验数据human_responses = ["春天来了,花儿开了,鸟儿唱着欢快的歌。小明和小红在公园里玩耍,他们的友谊像春天一样美好。","阳光透过树叶洒在地上,形成斑驳的光影。两个孩子手牵手走过小径,笑声回荡在空气中。"]ai_responses = ["在这个充满生机的季节里,友谊如同新绿的嫩芽,在温暖的阳光下茁壮成长。","春风轻抚,万物复苏。真挚的友情在这美好的时光中绽放,如同满园的花朵。"]# 执行对比实验experiment_results = comparator.conduct_comparison_experiment('story_writing', 'easy', human_responses, ai_responses)# 生成报告report = comparator.generate_experiment_report(experiment_results)print(report)
6. 实践应用与案例分析
6.1 创造力评估在实际场景中的应用
创造力评估不仅是学术研究的工具,更是实际应用中的重要指标。在不同的应用场景中,创造力评估发挥着关键作用。
应用场景分析:
-
内容创作平台:
- 自动写作助手:评估AI生成内容的创新性和质量
- 创意推荐系统:基于创造力指标推荐优质内容
- 内容审核系统:识别和过滤低质量或重复内容
-
教育培训领域:
- 写作能力评估:客观评价学生的创作水平
- 个性化教学:根据创造力水平调整教学策略
- 创意思维训练:设计针对性的创造力提升方案
-
商业营销应用:
- 广告创意评估:量化广告文案的创新程度
- 品牌内容生成:确保品牌内容的独特性和吸引力
- 市场调研分析:评估消费者反馈的创新见解
6.2 综合评估系统实现
class ComprehensiveCreativityAssessment:"""综合创造力评估系统:整合多种评估方法的完整解决方案"""def __init__(self):self.creativity_evaluator = CreativityEvaluator()self.quality_evaluator = ContentQualityEvaluator()self.style_controller = StyleController()self.diversity_analyzer = DiversityAnalyzer()self.consistency_controller = ConsistencyController()# 评估配置self.assessment_config = {'weights': {'creativity': 0.3,'quality': 0.25,'diversity': 0.2,'consistency': 0.15,'style_control': 0.1},'thresholds': {'excellent': 0.85,'good': 0.7,'satisfactory': 0.55,'needs_improvement': 0.4}}def comprehensive_assessment(self, texts: List[str],reference_corpus: List[str] = None,target_style: Dict[str, float] = None,topic: str = None) -> Dict[str, Any]:"""执行综合创造力评估"""assessment_results = {'input_info': {'text_count': len(texts),'avg_length': np.mean([len(text.split()) for text in texts]),'topic': topic,'has_reference': reference_corpus is not None},'detailed_scores': {},'summary': {},'recommendations': []}# 1. 创造力评估creativity_results = self.creativity_evaluator.evaluate_creativity(texts, reference_corpus)assessment_results['detailed_scores']['creativity'] = creativity_results# 2. 质量评估quality_scores = []for text in texts:quality_result = self.quality_evaluator.evaluate_content_quality(text, reference_corpus, topic)quality_scores.append(quality_result['overall_quality'])assessment_results['detailed_scores']['quality'] = {'individual_scores': quality_scores,'average_score': np.mean(quality_scores),'score_variance': np.var(quality_scores)}# 3. 多样性分析diversity_results = self.diversity_analyzer.analyze_diversity(texts)assessment_results['detailed_scores']['diversity'] = diversity_results# 4. 一致性评估consistency_results = self.consistency_controller.evaluate_consistency(texts)assessment_results['detailed_scores']['consistency'] = consistency_results# 5. 风格控制评估if target_style:style_scores = []for text in texts:current_style = self.style_controller.extract_style_features(text)style_alignment = self._calculate_style_alignment(current_style, target_style)style_scores.append(style_alignment)assessment_results['detailed_scores']['style_control'] = {'individual_scores': style_scores,'average_alignment': np.mean(style_scores)}# 6. 计算综合得分overall_score = self._calculate_comprehensive_score(assessment_results['detailed_scores'])# 7. 生成评估摘要assessment_results['summary'] = self._generate_assessment_summary(overall_score, assessment_results['detailed_scores'])# 8. 生成改进建议assessment_results['recommendations'] = self._generate_recommendations(assessment_results['detailed_scores'])return assessment_resultsdef _calculate_style_alignment(self, current_style: Dict[str, float], target_style: Dict[str, float]) -> float:"""计算风格对齐度"""alignment_scores = []for style_dim, target_value in target_style.items():if style_dim in current_style:current_value = current_style[style_dim]# 计算相似度(1 - 绝对差值)similarity = 1.0 - abs(target_value - current_value)alignment_scores.append(similarity)return np.mean(alignment_scores) if alignment_scores else 0.0def _calculate_comprehensive_score(self, detailed_scores: Dict[str, Any]) -> float:"""计算综合评估得分"""weighted_score = 0.0total_weight = 0.0# 创造力得分if 'creativity' in detailed_scores:creativity_score = detailed_scores['creativity'].get('overall_creativity', 0)weighted_score += creativity_score * self.assessment_config['weights']['creativity']total_weight += self.assessment_config['weights']['creativity']# 质量得分if 'quality' in detailed_scores:quality_score = detailed_scores['quality']['average_score']weighted_score += quality_score * self.assessment_config['weights']['quality']total_weight += self.assessment_config['weights']['quality']# 多样性得分if 'diversity' in detailed_scores:diversity_score = detailed_scores['diversity'].get('overall_diversity', 0)weighted_score += diversity_score * self.assessment_config['weights']['diversity']total_weight += self.assessment_config['weights']['diversity']# 一致性得分if 'consistency' in detailed_scores:consistency_score = detailed_scores['consistency'].get('overall_consistency', 0)weighted_score += consistency_score * self.assessment_config['weights']['consistency']total_weight += self.assessment_config['weights']['consistency']# 风格控制得分if 'style_control' in detailed_scores:style_score = detailed_scores['style_control']['average_alignment']weighted_score += style_score * self.assessment_config['weights']['style_control']total_weight += self.assessment_config['weights']['style_control']return weighted_score / total_weight if total_weight > 0 else 0.0def _generate_assessment_summary(self, overall_score: float, detailed_scores: Dict[str, Any]) -> Dict[str, Any]:"""生成评估摘要"""# 确定评估等级if overall_score >= self.assessment_config['thresholds']['excellent']:grade = 'excellent'description = '创造力表现卓越,内容质量优秀'elif overall_score >= self.assessment_config['thresholds']['good']:grade = 'good'description = '创造力表现良好,内容质量较高'elif overall_score >= self.assessment_config['thresholds']['satisfactory']:grade = 'satisfactory'description = '创造力表现一般,内容质量中等'else:grade = 'needs_improvement'description = '创造力有待提升,内容质量需要改进'# 识别优势和劣势strengths = []weaknesses = []for dimension, data in detailed_scores.items():if dimension == 'creativity':score = data.get('overall_creativity', 0)elif dimension == 'quality':score = data.get('average_score', 0)elif dimension == 'diversity':score = data.get('overall_diversity', 0)elif dimension == 'consistency':score = data.get('overall_consistency', 0)elif dimension == 'style_control':score = data.get('average_alignment', 0)else:continueif score >= 0.7:strengths.append(dimension)elif score < 0.5:weaknesses.append(dimension)return {'overall_score': overall_score,'grade': grade,'description': description,'strengths': strengths,'weaknesses': weaknesses}def _generate_recommendations(self, detailed_scores: Dict[str, Any]) -> List[str]:"""生成改进建议"""recommendations = []# 基于各维度得分生成建议if 'creativity' in detailed_scores:creativity_score = detailed_scores['creativity'].get('overall_creativity', 0)if creativity_score < 0.6:recommendations.append("建议增加内容的新颖性和原创性,尝试使用更多创新的表达方式和独特的观点。")if 'quality' in detailed_scores:quality_score = detailed_scores['quality']['average_score']if quality_score < 0.6:recommendations.append("建议提高内容质量,注意语法准确性、逻辑连贯性和信息丰富度。")if 'diversity' in detailed_scores:diversity_score = detailed_scores['diversity'].get('overall_diversity', 0)if diversity_score < 0.5:recommendations.append("建议增加内容多样性,使用更丰富的词汇和更多样的表达结构。")if 'consistency' in detailed_scores:consistency_score = detailed_scores['consistency'].get('overall_consistency', 0)if consistency_score < 0.6:recommendations.append("建议保持风格一致性,确保整体表达风格和语言特征的统一。")if not recommendations:recommendations.append("整体表现良好,继续保持当前的创作水平。")return recommendationsdef generate_detailed_report(self, assessment_results: Dict[str, Any]) -> str:"""生成详细评估报告"""report = f"""
# 创造力综合评估报告## 基本信息
- 评估文本数量: {assessment_results['input_info']['text_count']}
- 平均文本长度: {assessment_results['input_info']['avg_length']:.1f} 词
- 评估主题: {assessment_results['input_info']['topic'] or '无特定主题'}
- 参考语料: {'有' if assessment_results['input_info']['has_reference'] else '无'}## 评估结果摘要
- 综合得分: {assessment_results['summary']['overall_score']:.3f}
- 评估等级: {assessment_results['summary']['grade']}
- 总体描述: {assessment_results['summary']['description']}## 详细分析### 优势领域
{chr(10).join([f'- {strength}' for strength in assessment_results['summary']['strengths']])}### 待改进领域
{chr(10).join([f'- {weakness}' for weakness in assessment_results['summary']['weaknesses']])}## 改进建议
{chr(10).join([f'{i+1}. {rec}' for i, rec in enumerate(assessment_results['recommendations'])])}## 详细得分
"""# 添加详细得分信息for dimension, data in assessment_results['detailed_scores'].items():report += f"\n### {dimension.title()}\n"if dimension == 'creativity':report += f"- 整体创造力: {data.get('overall_creativity', 0):.3f}\n"report += f"- 新颖性: {data.get('novelty', 0):.3f}\n"report += f"- 多样性: {data.get('diversity', 0):.3f}\n"elif dimension == 'quality':report += f"- 平均质量: {data['average_score']:.3f}\n"report += f"- 质量方差: {data['score_variance']:.3f}\n"elif dimension == 'diversity':report += f"- 整体多样性: {data.get('overall_diversity', 0):.3f}\n"report += f"- 词汇多样性: {data.get('lexical', 0):.3f}\n"report += f"- 语义多样性: {data.get('semantic', 0):.3f}\n"return report# 使用示例
if __name__ == "__main__":# 创建综合评估系统assessment_system = ComprehensiveCreativityAssessment()# 示例文本sample_texts = ["人工智能正在改变我们的世界,它像一把双刃剑,既带来机遇也带来挑战。","在数字化时代,创新思维比以往任何时候都更加重要,我们需要培养适应变化的能力。","技术的发展速度令人惊叹,但我们不能忘记人文关怀的重要性。"]# 执行综合评估results = assessment_system.comprehensive_assessment(texts=sample_texts,topic="人工智能与社会发展")# 生成详细报告report = assessment_system.generate_detailed_report(results)print(report)
7. 总结与展望
7.1 创造力评估的重要意义
创造力评估作为大语言模型能力测试的重要组成部分,具有深远的理论意义和实践价值。通过本文的深入探讨,我们可以看到:
理论贡献:
- 评估框架完善:构建了多维度、多层次的创造力评估体系
- 方法论创新:提出了量化创造力的科学方法和技术路径
- 标准化推进:为创造力评估提供了可操作的标准和规范
实践价值:
- 模型优化指导:为大语言模型的创造力提升提供明确方向
- 应用场景拓展:支持创造力要求较高的实际应用场景
- 质量保证机制:确保AI生成内容的创新性和质量水平
7.2 当前挑战与局限性
尽管创造力评估技术取得了显著进展,但仍面临诸多挑战:
技术挑战:
- 主观性难题:创造力评判的主观性使得客观量化困难
- 上下文依赖:创造力的价值高度依赖于具体情境和文化背景
- 动态变化:创造力标准随时间和社会发展而变化
- 多模态融合:当前评估主要局限于文本,缺乏多模态整合
方法局限:
- 评估维度不全:现有方法可能遗漏某些重要的创造力维度
- 基准数据稀缺:高质量的创造力评估基准数据集相对匮乏
- 计算复杂度高:综合评估需要大量计算资源和时间
- 可解释性不足:评估结果的可解释性有待提升
7.3 未来发展方向
展望未来,创造力评估技术将在以下方向取得突破:
技术发展趋势:
-
多模态创造力评估:
- 整合文本、图像、音频等多种模态
- 开发跨模态创造力评估方法
- 构建多模态创造力基准数据集
-
动态适应性评估:
- 开发能够适应不同文化和时代背景的评估系统
- 实现评估标准的动态更新和调整
- 构建个性化的创造力评估框架
-
可解释性增强:
- 提供详细的评估过程解释
- 开发可视化的创造力分析工具
- 建立评估结果的因果关系分析
-
实时评估优化:
- 开发高效的实时创造力评估算法
- 实现评估过程的并行化和分布式处理
- 构建轻量级的移动端评估工具
应用前景展望:
-
教育领域革新:
- 个性化创造力培养方案
- 智能化写作指导系统
- 创新思维能力测评平台
-
内容产业升级:
- 智能内容创作助手
- 创意质量自动评估
- 版权原创性检测系统
-
科研创新支持:
- 学术论文创新性评估
- 研究方向推荐系统
- 跨学科创新发现工具
7.4 结语
创造力评估是人工智能发展的重要里程碑,它不仅推动了技术的进步,更深刻地影响着我们对智能本质的理解。随着大语言模型能力的不断提升,创造力评估将成为衡量AI真正智能水平的关键指标。
通过本文的系统阐述,我们构建了完整的创造力评估理论框架,提供了实用的技术实现方案,并展望了未来的发展方向。这些工作为研究者和工程师提供了宝贵的参考,有助于推动创造力评估技术的持续发展和广泛应用。
在未来的研究中,我们需要继续深化对创造力本质的理解,完善评估方法和技术,拓展应用场景和领域。只有这样,我们才能真正实现AI创造力的科学评估,为人工智能的健康发展提供有力支撑。
创造力是人类智慧的结晶,也是AI追求的目标。通过不断完善创造力评估技术,我们正在为构建更加智能、更加创新的AI系统铺平道路。这不仅是技术的进步,更是人类对智能本质探索的重要一步。