RecSys:用户行为序列建模以及DIN、SIM模型
引言
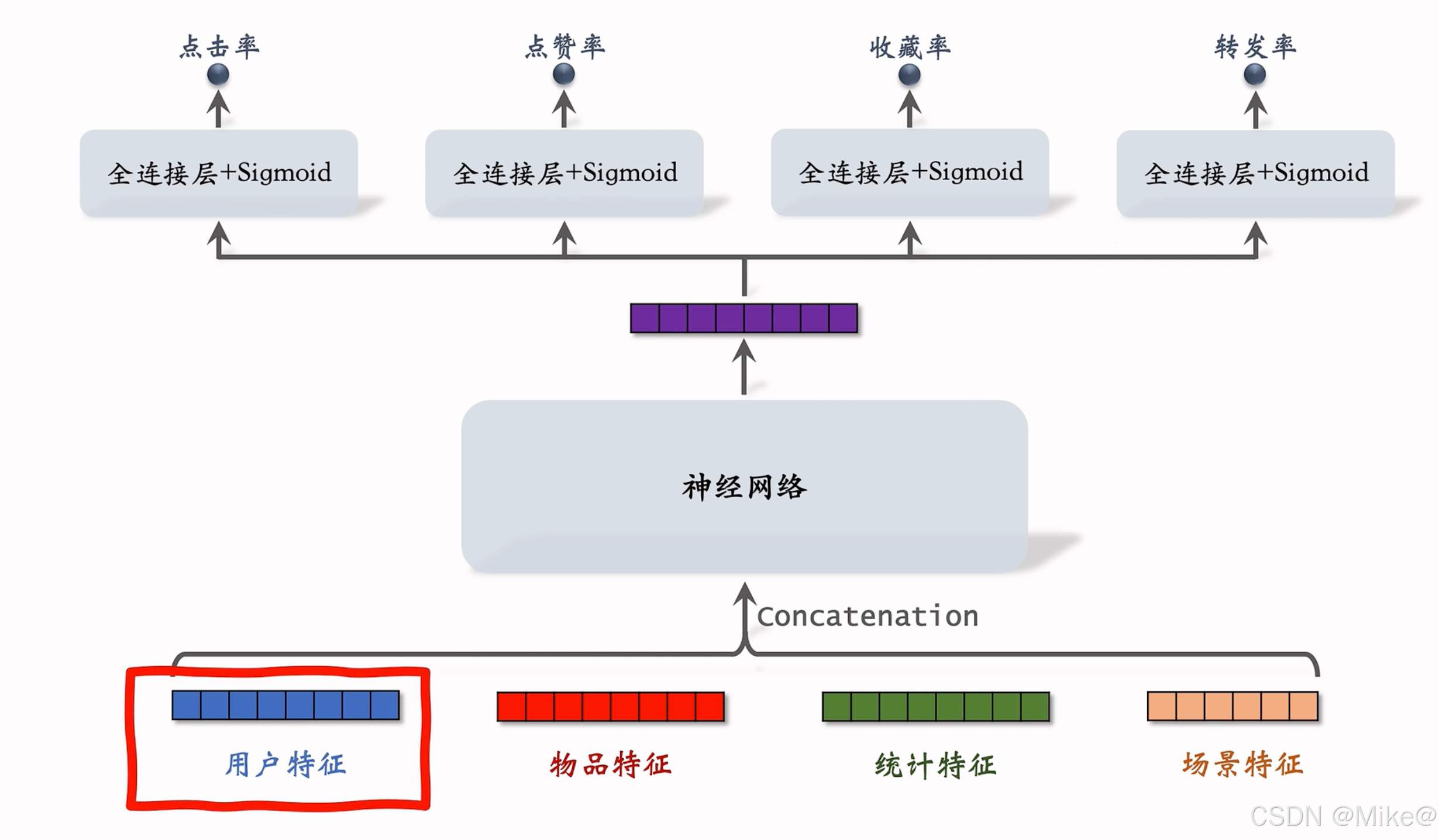
在推荐系统中,用户历史行为序列是极其重要的信息源。用户最近的点击、点赞、收藏、转发等行为能够有效反映其即时兴趣,无论是在召回、粗排还是精排阶段,合理利用这些行为序列都能显著提升推荐效果。本文将系统介绍用户行为序列建模的几种经典方法:简单平均法、DIN模型(深度兴趣网络)以及SIM模型(基于搜索的用户兴趣建模)。
1. 简单平均法(Last-N Average)
基本思想
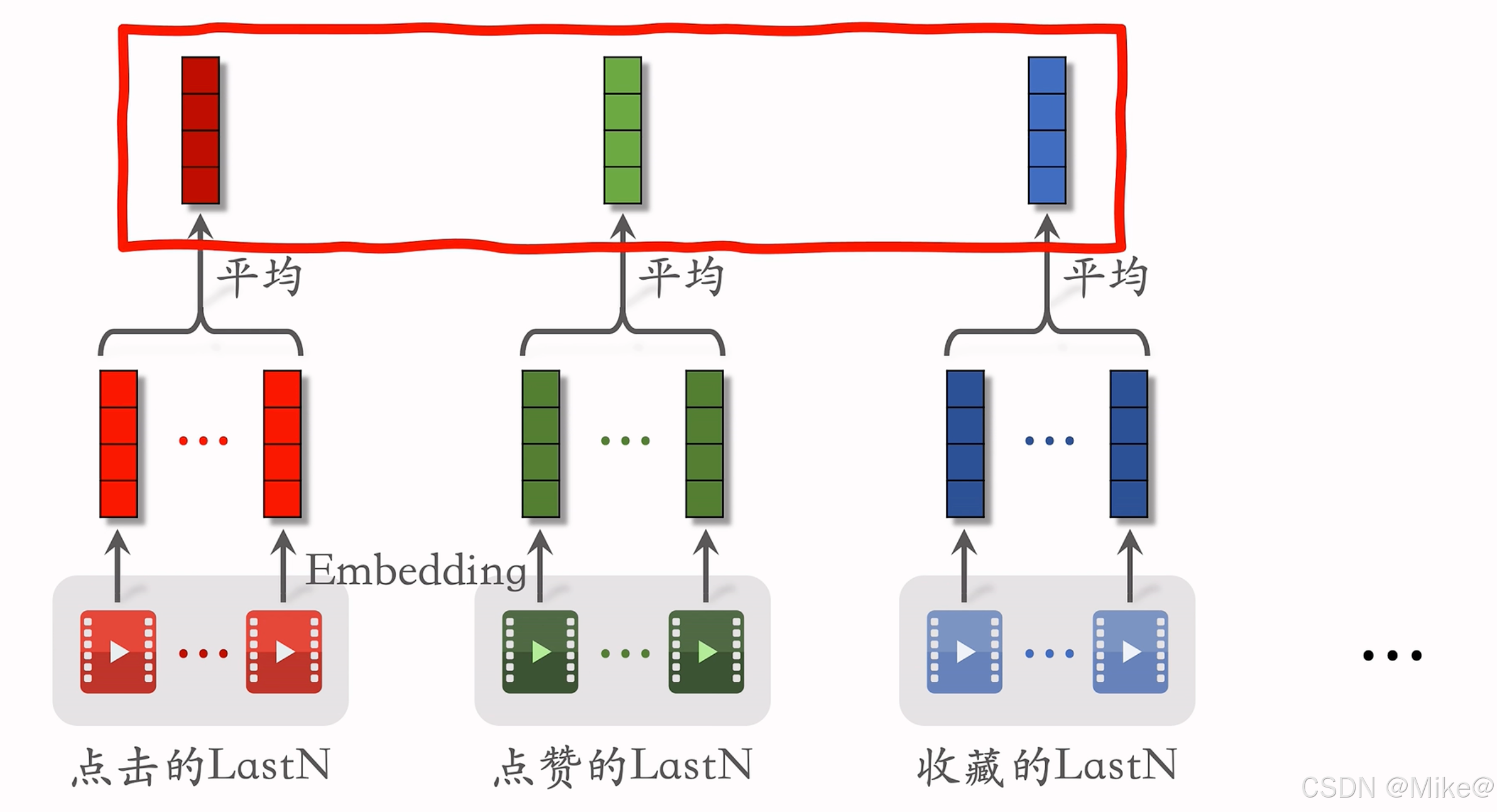
Last-N 特征是指用户最近的 nnn 次交互(如点击、点赞等)的物品 ID。对这些物品 ID 进行嵌入(Embedding),得到 nnn 个向量,然后对这些向量取平均,将得到的均值向量作为用户的一种特征表示。该方法计算简单,易于实现,可广泛应用于召回双塔模型、粗排三塔模型以及精排模型中。
数学表达如下:
设用户最近 nnn 次交互的物品嵌入向量为 v1,v2,…,vn\mathbf{v}_1, \mathbf{v}_2, \dots, \mathbf{v}_nv1,v2,…,vn,则用户特征向量 u\mathbf{u}u 为:
u=1n∑i=1nvi\mathbf{u} = \frac{1}{n} \sum_{i=1}^{n} \mathbf{v}_i u=n1i=1∑nvi
实践经验
除了使用物品 ID 嵌入外,还可以结合类目等特征进行嵌入拼接,这样通常比仅使用 ID 嵌入效果更好。不过,取平均是一种较为基础的操作,目前更主流的方法是使用注意力机制,尽管这会带来更大的计算开销。
注:不同公司的系统基础设施水平存在差异,实践中需根据实际情况选择适合的方案。
2. DIN模型:引入注意力机制
动机
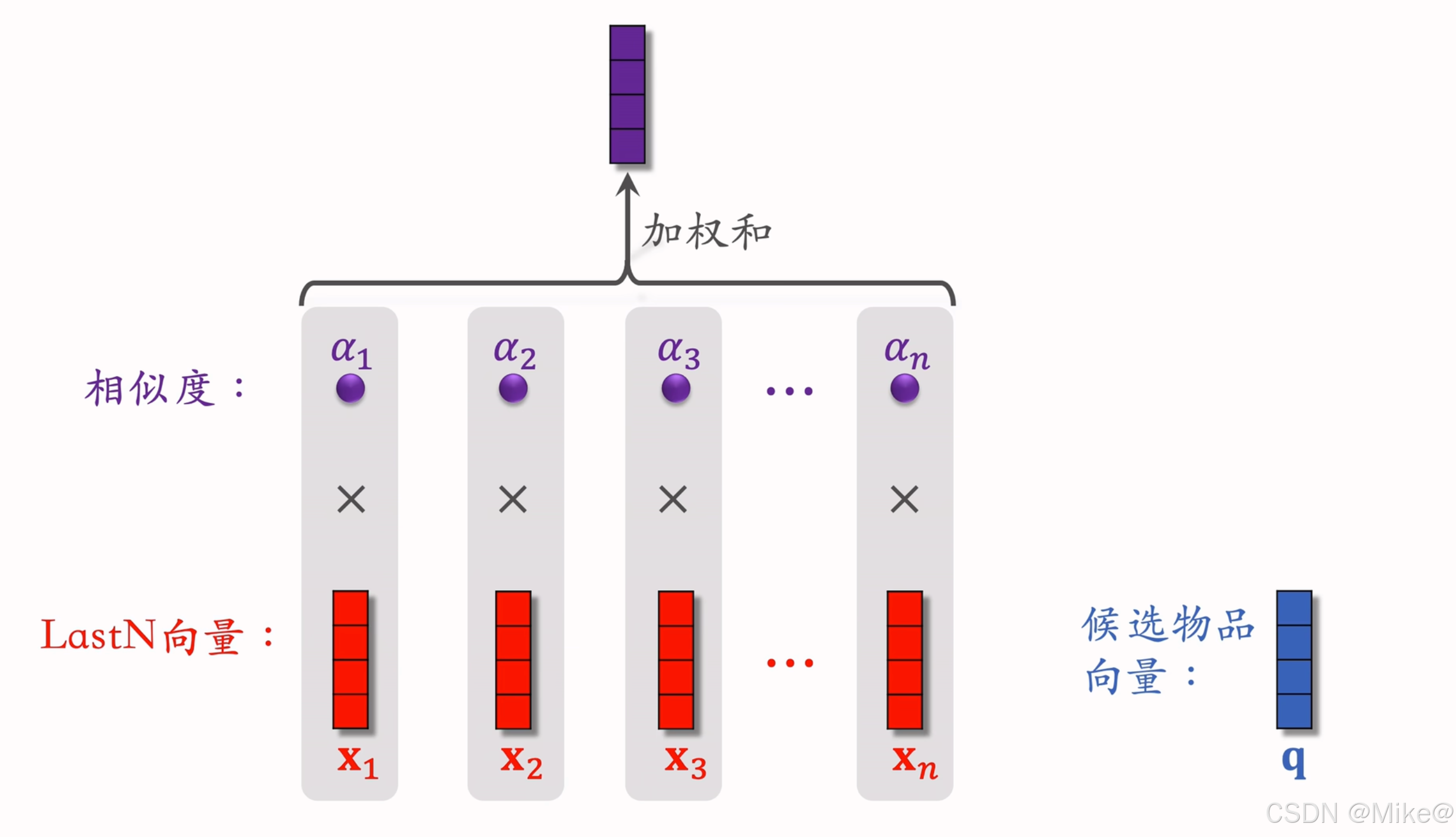
简单平均法对所有历史行为一视同仁,忽略了用户兴趣的动态变化。DIN(Deep Interest Network)通过引入注意力机制,对用户历史行为进行加权平均,权重由候选物品与历史行为的相似度决定。
模型结构
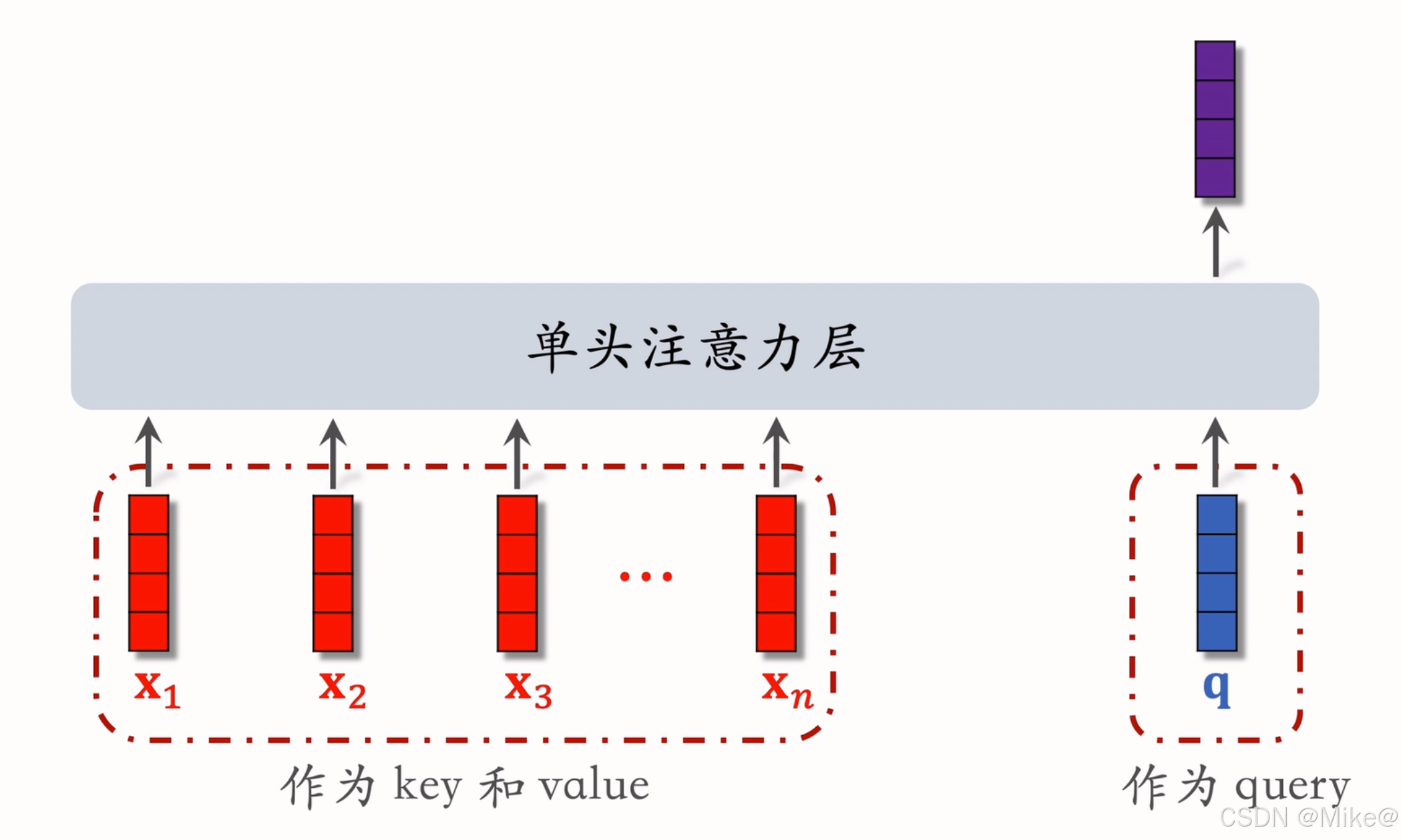
对于每个候选物品,计算其与用户 Last-N 个历史行为物品的相似度(记为 aia_iai,i=1,…,ni=1,\dots,ni=1,…,n),以这些相似度为权重,对历史行为物品的嵌入向量进行加权求和,得到用户兴趣表示。
数学表达如下:
u=∑i=1nai⋅vi\mathbf{u} = \sum_{i=1}^{n} a_i \cdot \mathbf{v}_i u=i=1∑nai⋅vi
其中 aia_iai 是候选物品与第 iii 个历史物品的相似度,可以通过内积、余弦相似度或更复杂的网络计算。
其实本质上是注意力机制
适用范围
- 适用于精排模型。
- 不适用于双塔或三塔模型,因为注意力机制需要同时看到用户历史行为和候选物品,而双塔模型在用户塔中无法获取候选物品信息。
参考文献:Zhou et al. Deep Interest Network for Click-Through Rate Prediction. In KDD, 2018.
3. SIM模型:处理长期行为序列
动机
DIN 模型的计算复杂度与行为序列长度 nnn 成正比,因此通常只能处理几百个最近的行为,难以利用更长期的用户历史。SIM(Search-based Interest Modeling)模型通过两阶段搜索机制,在保留长期兴趣的同时控制计算量。
主要目的是保留用户的长期兴趣
- DIN 注意力层的计算量 ∝\propto∝ n(用户行为序列的长度)
- 只能记录最近几百个物品,否则计算量太大
- 缺点:关注短期兴趣,遗忘长期兴趣
增加用户行为序列可以显著推荐系统的各项指标,但是让行为序列变长是不划算,
-
目标:保留用户长期行为序列(n很大),而且计算量不会过大。
-
DIN对LastN向量做加权平均,权重是相似度
-
如果LastN物品与候选物品差异很大,则权重接近零
-
快速排除掉与候选物品无关的LastN物品,降低注意力层的计算量
SIM模型
工业界公认SIM模型是有效的
- 保留用户长期行为记录,n的大小可以是几千
- 对于每个候选物品,在用户LastN记录中做快速查找,找到k个相似物品,比如k = 100.
- 把LastN变成TopK,然后输入到注意力层
- SIM模型减少计算量(从n降低到K)
两阶段机制
第一阶段:搜索(Search)
从用户长期行为序列(例如几千个历史物品)中快速检索出与候选物品最相关的 kkk 个物品(例如 k=100k=100k=100)。具体方法有两种:
- Hard Search:根据候选物品的类目,筛选出同类目的历史物品。实现简单,无需训练。
- Soft Search:将物品表示为嵌入向量,通过最近邻搜索(如 KNN)找出与候选物品最相似的 kkk 个历史物品。效果更好,但对工程基础设施要求较高。
第二阶段:注意力聚合
将筛选出的 kkk 个物品输入注意力层(类似 DIN),计算加权和作为用户兴趣表示。
时间信息的利用
SIM 模型通常引入时间信息来增强长期行为序列的表征:
- 记录用户与每个历史物品交互的时刻距今的时间间隔 δ\deltaδ。
- 对 δ\deltaδ 进行离散化(如划分为 1天、7天、30天、1年等区间),并嵌入为向量 d\mathbf{d}d。
- 将物品嵌入 v\mathbf{v}v 与时间嵌入 d\mathbf{d}d 拼接,共同作为历史行为的表征。
x=[v;d]\mathbf{x} = [\mathbf{v}; \mathbf{d}] x=[v;d]
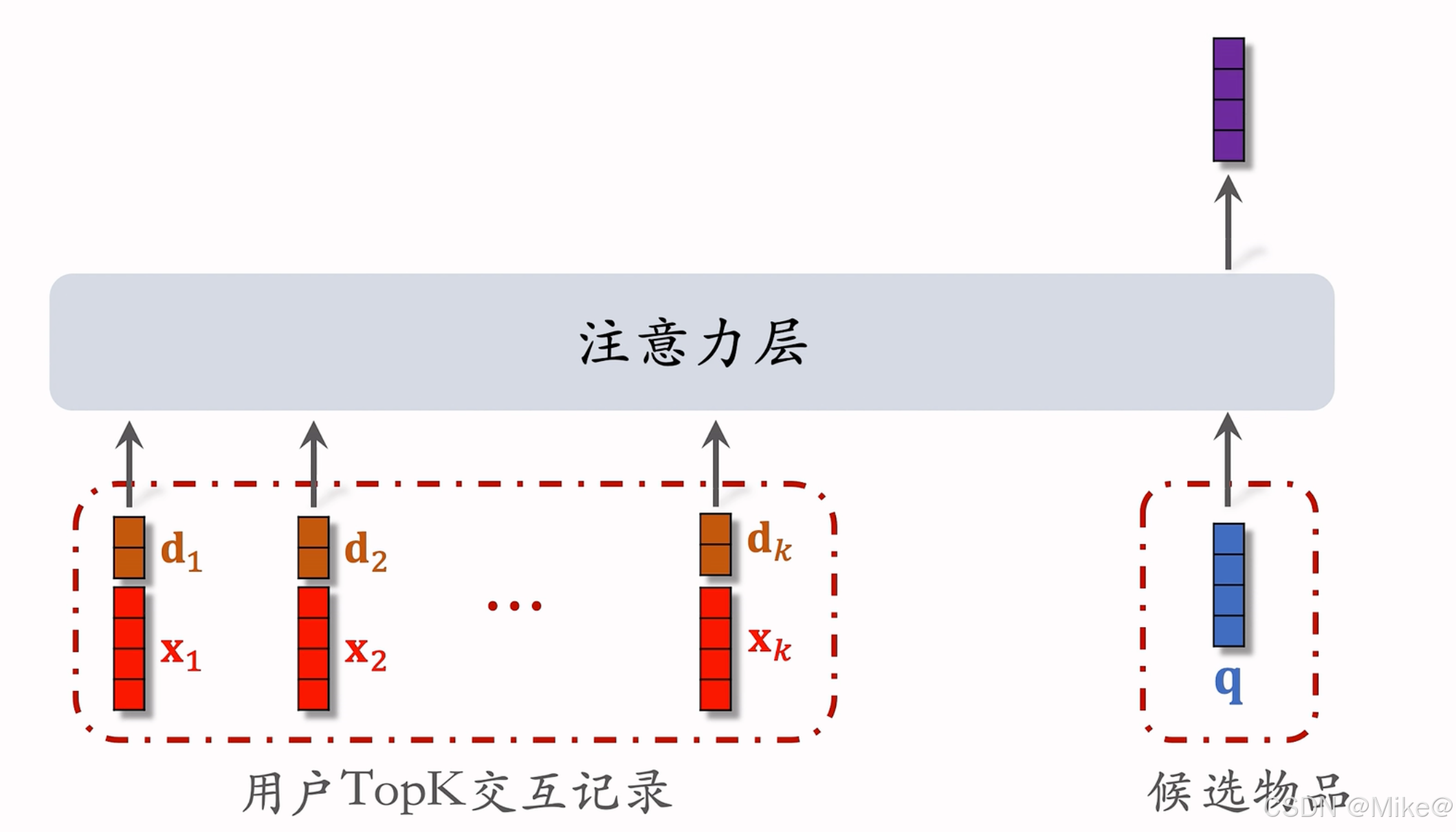
为什么SIM需要使用时间信息?
- DIN 仅处理短期行为,时间跨度小,时间因素影响不显著。
- SIM 处理长期行为,时间越久远的行为重要性通常越低,引入时间信息可以带来显著提升。
结论
- 长序列(长期兴趣)优于短序列(近期兴趣)。
- 注意力机制优于简单平均。
- Soft Search 优于 Hard Search,但取决于工程基础。
- 使用时间信息对效果有提升。
参考文献:Qi et al. Search-based User Interest Modeling with Lifelong Sequential Behavior Data for Click-Through Rate Prediction. In CIKM, 2020.
总结
用户行为序列建模是推荐系统的核心环节。从简单平均到注意力机制(DIN),再到基于搜索的长期兴趣建模(SIM),每一步演进都在更好地平衡效果与计算效率。实践中,需根据业务需求、数据规模和基础设施条件选择合适的方法,并灵活引入时间等辅助信息以进一步提升模型性能。
Reference
王树森 bilibili推荐系统