【CMake】变量作用域2——函数作用域
目录
一.函数作用域
1.1.function()
1.2.示例
1.2.1.关于参数的特殊变量
1.2.2.调用方式示例
1.2.3.变量作用域举例
1.2.4.SET的PARENT_SCOPE
1.3.策略在 Function 作用域中的关键行为
1.3.1.function()内的策略作用域
1.3.2.在function()里面构建一个独立的策略作用域
一.函数作用域
1.1.function()
function()
开始记录一个函数,以便后续作为命令来调用。
function(<name> [<arg1> ...])
<commands>
endfunction()定义一个名为 <name> 的函数,该函数接受名为 <arg1>, ... 的参数。函数定义中的 <commands> 会被记录起来,直到该函数被调用时才会执行。
出于历史遗留原因,endfunction() 命令允许一个可选的 <name> 参数。如果使用了该参数,它必须与开头 function 命令的参数完全一致。
函数会开启一个新的作用域:详情请参阅 set(var PARENT_SCOPE)的文档。
关于策略(policies)在函数内部的行为,请参见 cmake_policy() 命令的文档。
关于 CMake 函数(function)和宏(macro)之间的区别,请参见 macro() 命令的文档。
调用 (Invocation)
函数的调用是大小写不敏感的。一个定义为:
function(foo)<commands>
endfunction()的函数可以通过以下任何一种方式调用:
foo()
Foo()
FOO()
cmake_language(CALL foo)等等。但强烈建议保持与函数定义中所选大小写的一致性。通常,函数使用全小写的名称。
在 3.18 版本中加入:也可以使用 cmake_language(CALL ...) 命令来调用函数。
参数 (Arguments)
当函数被调用时,首先会通过将形式参数(${arg1}, ...)替换为传递进来的实际参数,来修改记录好的 <commands>,然后将它们作为普通命令执行。
除了引用形式参数之外,您还可以引用以下变量:
-
ARGC:该变量将被设置为传递给函数的参数数量。 -
ARGV0,ARGV1,ARGV2, ...:这些变量将包含传递进来的参数的实际值。
这便于创建带有可选参数的函数。
此外:
-
ARGV:持有传递给函数的所有参数的列表。 -
ARN:持有最后一个预期参数之后的参数列表。
注意:引用超出 ARGC 范围的 ARGV# 参数(例如,只有 2 个参数却引用 ${ARGV2})是未定义行为。确保 ARGC 大于 # 是检查是否确实将 ARGV# 作为额外参数传递给函数的唯一方法。
1.2.示例
1.2.1.关于参数的特殊变量
我们来详细讲解一下 CMake 函数中处理参数的这些特殊变量。
想象一下你定义了这样一个函数:
function(my_function arg1 arg2)# ... 函数体内的命令 ...
endfunction()当你调用它时:my_function(Hello World 42 "Extra String"),函数内部会自动创建以下变量来帮助你处理这些传入的参数。
核心变量详解
-
ARGC(Argument Count)-
含义:表示实际传递给函数的所有参数的总个数。
-
在上面的例子中:我们传入了 4 个参数 (
Hello,World,42,Extra String),所以ARGC的值是4。 -
用途:这是你判断调用者到底传了多少个参数的最直接依据。
-
-
ARGV0,ARGV1,ARGV2, ...ARGVN-
含义:这是一个变量序列,每个变量对应一个位置上的参数值。
ARGV0对应第一个参数,ARGV1对应第二个,以此类推。 -
在上面的例子中:
-
ARGV0=Hello -
ARGV1=World -
ARGV2=42 -
ARGV3=Extra String
-
-
用途:当你需要按数字位置访问特定参数时非常有用,尤其是在循环中或处理未知数量的参数时。
-
-
ARGV(Argument Values)-
含义:这是一个列表,包含了传递给函数的所有参数。
-
在上面的例子中:
ARGV的值是Hello;World;42;Extra String(一个CMake列表)。 -
用途:你可以使用所有列表操作命令(如
list(LENGTH),list(GET),list(APPEND)等)来处理ARGV,这为批量处理参数提供了极大的灵活性。
-
-
ARGN(Argument N... 即额外的参数)-
含义:这是一个非常重要的变量。它包含了所有在形式参数(即
arg1,arg2)之后传入的额外参数。 -
形式参数 vs 实际参数:函数定义
(arg1 arg2)中的arg1和arg2是形式参数,它们期望接收两个参数。但我们调用时传入了 4 个,多出的 2 个就是“额外”的。 -
在上面的例子中:
-
形式参数
arg1和arg2分别被赋值为Hello和World。 -
剩下的两个参数 (
42和Extra String) 则被放入ARGN变量中。所以ARGN的值是42;Extra String。
-
-
用途:这是实现可变参数函数或可选参数的关键。你的函数可以只定义几个必需参数,然后通过检查
ARGN来处理任何数量的可选参数。
-
关于“未定义行为”和如何安全使用的详细说明
警告的核心意思是:不要访问不存在的参数。
-
为什么会发生?
在例子中,ARGC是 4,这意味着有效的参数索引是0, 1, 2, 3(编程中通常从0开始计数)。如果你尝试访问ARGV4,ARGV5...,这些参数根本不存在。 -
“未定义行为”意味着什么?
这表示 CMake 对此没有做出规定。结果可能是:-
得到一个空字符串。
-
得到一个之前的内存垃圾值。
-
在某些情况下导致错误或不可预测的脚本行为。
你的 CMake 脚本会变得非常不稳定和难以调试。
-
-
如何安全地检查和使用?
唯一正确的方法是在访问ARGV#之前,先用ARGC进行检查。
示例
项目结构
test/
└── CMakeLists.txt
CMakeLists.txt
cmake_minimum_required(VERSION 3.18)
project(FunctionDemo)function(print_args x y)message("参数 x = ${x}")message("参数 y = ${y}")message("参数总数 ARGC = ${ARGC}")message("所有参数 ARGV = ${ARGV}")message("多余的参数 ARGN = ${ARGN}")message("ARGV0 = ${ARGV0}")message("ARGV1 = ${ARGV1}")
endfunction()# 调用函数,传入 4 个参数
print_args(apple banana cherry date)
其实我们可以执行下面这个来一键搭建出这个目录结构
mkdir -p test && cat > test/CMakeLists.txt <<'EOF'
cmake_minimum_required(VERSION 3.18)
project(FunctionDemo)function(print_args x y)message("参数 x = ${x}")message("参数 y = ${y}")message("参数总数 ARGC = ${ARGC}")message("所有参数 ARGV = ${ARGV}")message("多余的参数 ARGN = ${ARGN}")message("ARGV0 = ${ARGV0}")message("ARGV1 = ${ARGV1}")
endfunction()# 调用函数,传入 4 个参数
print_args(apple banana cherry date)
EOF

接下来我们就来构建一下项目
mkdir build && cd build && cmake ..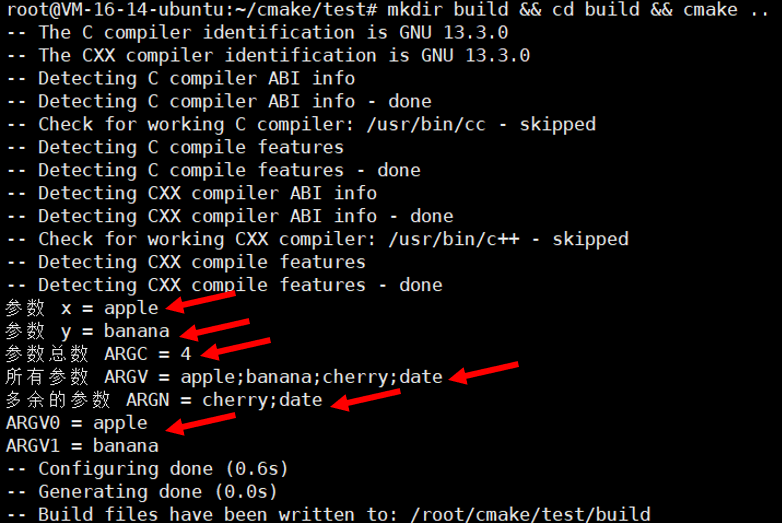
我们发现
1. ARGC (Argument Count)
-
含义:表示实际传递给函数的所有参数的总个数。
-
在这个例子中:您传入了 4 个参数 (
apple,banana,cherry,date),所以ARGC的值是4。 -
用途:这是函数内部判断调用者到底传了多少个参数的最直接依据。例如,可以用
if(${ARGC} GREATER 2)来判断是否提供了额外的参数。
2. ARGV0, ARGV1, ARGV2, ... ARGVN
-
含义:这是一个变量序列,每个变量对应一个位置上的参数值。
ARGV0对应第一个参数,ARGV1对应第二个,以此类推。 -
在这个例子中:
-
ARGV0=apple(第一个参数) -
ARGV1=banana(第二个参数) -
ARGV2=cherry(第三个参数) -
ARGV3=date(第四个参数)
-
-
用途:当您需要按数字位置访问特定参数时非常有用。例如,如果您想跳过前两个参数,直接处理后面的,就可以使用
ARGV2,ARGV3等。
3. ARGV (Argument Values)
-
含义:这是一个列表,包含了传递给函数的所有参数。
-
在这个例子中:
ARGV的值是apple;banana;cherry;date(一个由分号分隔的 CMake 列表)。 -
用途:您可以使用所有 CMake 列表操作命令(如
list(LENGTH ARGV num),list(GET ARGV 2 third_item),list(APPEND ARGV new_item)等)来处理ARGV,这为批量处理参数提供了极大的灵活性。
4. ARGN (Argument N... 即额外的参数)
-
含义:这是一个非常重要的变量。它包含了所有在形式参数(即
x,y)之后传入的额外参数。 -
形式参数 vs 实际参数:函数定义
(x y)中的x和y是形式参数,它们期望接收两个参数。但您调用时传入了 4 个,多出的 2 个就是“额外”的。 -
在这个例子中:
-
形式参数
x被赋值为第一个实际参数apple。 -
形式参数
y被赋值为第二个实际参数banana。 -
剩下的两个参数 (
cherry和date) 则被放入ARGN变量中。所以ARGN的值是cherry;date。
-
-
用途:这是实现可变参数函数或可选参数的关键。您的函数可以只定义几个必需参数(
x和y),然后通过检查和处理ARGN来接收任何数量的额外参数。例如,可以把ARGN中的所有参数当作需要编译的源文件列表。
1.2.2.调用方式示例
在 CMake 里,函数的调用方式其实挺灵活的。
除了最常见的
print_args(apple banana cherry date)
你还可以用以下几种方式:
1. 大小写无关调用
CMake 函数调用不区分大小写,所以这些都等价:
print_args(apple banana cherry date)
PRINT_ARGS(apple banana cherry date)
Print_Args(apple banana cherry date)
2.
cmake_language(CALL ...)调用
CMake 3.18+ 提供了通用调用接口,可以这样写:
cmake_language(CALL print_args apple banana cherry date)
这种方式更“元编程”,因为你可以把函数名存在一个变量里再调用,例如:
set(func_name print_args)
cmake_language(CALL ${func_name} foo bar)
3. 通过变量展开参数
你可以先把参数存到一个列表变量,再展开调用:
set(my_args apple banana cherry date)
print_args(${my_args})
注意:${my_args} 会在调用时被展开成 apple banana cherry date。
4. 空调用(无参数)
如果你定义了函数但不传参:
print_args()
那么函数里:
-
ARGC = 0 -
ARGV = "" -
形式参数未定义
5. 传入带分号的列表
CMake 把分号当作列表分隔符,所以你可以这样:
print_args("a;b;c" d)
实际上传入的参数是 a;b;c(一个整体字符串) 和 d。
注意:除了上面这些,其实还是有其他的调用方法的,但是我不想再多说了,大家自己去了解一下吧
示例
项目结构
test/
└── CMakeLists.txt
CMakeLists.txt
cmake_minimum_required(VERSION 3.18)
project(FunctionCallDemo)# 定义一个非常简单的函数
function(show_args)message("参数个数 = ${ARGC}")message("所有参数 = ${ARGV}")message("---------- 分割线 ----------")
endfunction()# --- 调用方式演示 ---# 1. 普通调用
show_args(apple banana cherry)# 2. 大小写无关
SHOW_ARGS(apple banana)# 3. 使用 cmake_language(CALL)
cmake_language(CALL show_args foo bar baz)# 4. 使用变量展开
set(my_args x y z)
show_args(${my_args})# 5. 空调用
show_args()# 6. 传入带分号的列表(整体字符串)
show_args("a;b;c" d)
其实我们可以执行下面这个来一键搭建出这个目录结构
mkdir -p test && cat > test/CMakeLists.txt <<'EOF'
cmake_minimum_required(VERSION 3.18)
project(FunctionCallDemo)# 定义一个非常简单的函数
function(show_args)message("参数个数 = ${ARGC}")message("所有参数 = ${ARGV}")message("---------- 分割线 ----------")
endfunction()# --- 调用方式演示 ---# 1. 普通调用
show_args(apple banana cherry)# 2. 大小写无关
SHOW_ARGS(apple banana)# 3. 使用 cmake_language(CALL)
cmake_language(CALL show_args foo bar baz)# 4. 使用变量展开
set(my_args x y z)
show_args(${my_args})# 5. 空调用
show_args()# 6. 传入带分号的列表(整体字符串)
show_args("a;b;c" d)
EOF
接下来我们就来构建一下项目
mkdir build && cd build && cmake ..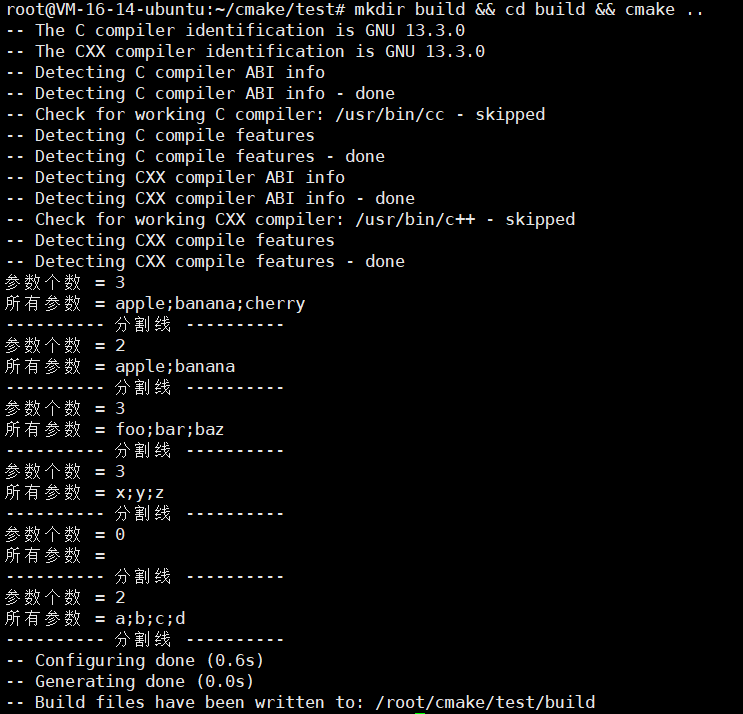
大家一一去比对一下,发现都是没有问题的!!!
1.2.3.变量作用域举例
在 CMake 中,每当调用一个 function(),它都会创建一个新的、独立的作用域。你可以把这个新作用域想象成函数自己的一块私有白板。这块白板和函数外部的白板(父作用域)是分开的。这个机制对变量的可见性和修改方式有至关重要的影响,具体表现为三条规则:
规则一:外部变量在函数内部“只读”可见
当进入函数时,CMake 会将当前父作用域中的所有变量复制一份到函数的新作用域中。这意味着,在函数内部,你可以读取函数外部定义的所有变量。
重要提示:这种可见性是单向的、只读的。你看到的其实是外部变量的一个副本,而不是原始变量本身。
规则二:函数内部对变量的修改是局部的
这是最关键也最容易混淆的一点。
你在函数内部使用 set() 或 unset() 对任何变量(无论这个变量最初是来自外部还是你在函数内部新建的)所做的任何操作,都只会在函数自身的这块私有白板上进行。
-
修改外部已存在的变量:你修改的只是它的副本。函数外部的原始变量纹丝不动,保持不变。
-
创建新变量:你只是在函数的私有白板上创建了一个新变量。
无论哪种情况,当函数执行完毕退出时,它这块私有白板会被整个销毁。你在上面做的所有修改和创建的所有新变量,都会随之一起消失,不会对函数外部的白板(父作用域)产生任何影响。
示例1——访问外部变量
项目结构
test/
└── CMakeLists.txt
CMakeLists.txt
cmake_minimum_required(VERSION 3.18)
project(FunctionUnsetDemo)set(VAR1 "outer1") # 定义外部变量 VAR1
set(VAR2 "outer2") # 定义外部变量 VAR2function(test_scope)message("函数开始时: VAR1='${VAR1}', VAR2='${VAR2}'")set(VAR1 "inner1") # 修改 VAR1(仅函数作用域有效)set(NEW_VAR "new") # 新建一个变量(仅函数作用域可见)unset(VAR2) # 仅在函数作用域内取消定义 VAR2message("函数内部: VAR1='${VAR1}', VAR2='${VAR2}', NEW_VAR='${NEW_VAR}'")
endfunction()message("调用函数前: VAR1='${VAR1}', VAR2='${VAR2}'")
test_scope()
message("调用函数后: VAR1='${VAR1}', VAR2='${VAR2}', NEW_VAR='${NEW_VAR}'")
其实我们可以执行下面这个来一键搭建出这个目录结构
mkdir -p test && cat > test/CMakeLists.txt <<'EOF'
cmake_minimum_required(VERSION 3.18)
project(FunctionUnsetDemo)set(VAR1 "outer1") # 定义外部变量 VAR1
set(VAR2 "outer2") # 定义外部变量 VAR2function(test_scope)message("函数开始时: VAR1='${VAR1}', VAR2='${VAR2}'")set(VAR1 "inner1") # 修改 VAR1(仅函数作用域有效)set(NEW_VAR "new") # 新建一个变量(仅函数作用域可见)unset(VAR2) # 仅在函数作用域内取消定义 VAR2message("函数内部: VAR1='${VAR1}', VAR2='${VAR2}', NEW_VAR='${NEW_VAR}'")
endfunction()message("调用函数前: VAR1='${VAR1}', VAR2='${VAR2}'")
test_scope()
message("调用函数后: VAR1='${VAR1}', VAR2='${VAR2}', NEW_VAR='${NEW_VAR}'")
EOF
接下来我们就来构建一下项目
mkdir build && cd build && cmake ..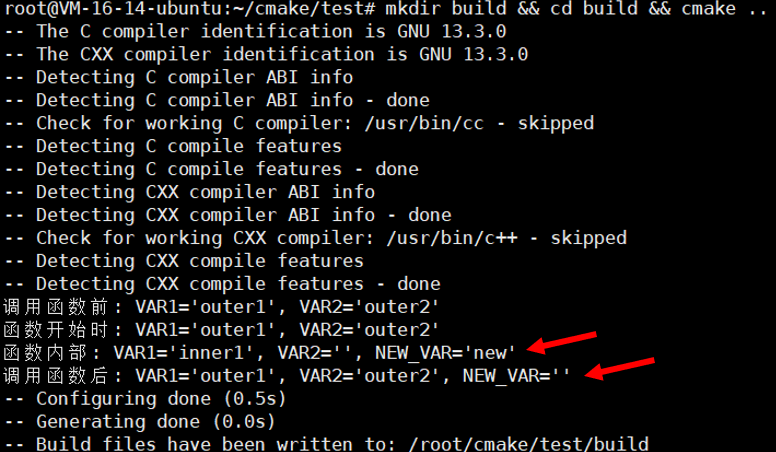
大家一一去比对一下,发现和我们的猜想都是没有问题的!!!
函数内部对外部同名变量进行的修改,是不会影响到外部同名变量的
1.2.4.SET的PARENT_SCOPE
规则三:如何影响外部?必须使用
PARENT_SCOPE
至于这个PARENT_SCOPE,大家可以去这里好好看看:【CMake】变量作用域1——块作用域-CSDN博客
如果你确实需要在函数内部修改一个变量,并让这个修改在函数外部(即调用它的父作用域)生效,CMake 提供了唯一的机制:set(... PARENT_SCOPE) 或 unset(... PARENT_SCOPE)。
-
set(var value PARENT_SCOPE):这条命令的意思是,“请不要在我当前函数的作用域里设置var,请去我的父作用域(即调用我的地方)设置或修改这个变量。” -
工作方式:它直接跳过了函数的本地作用域,去修改父作用域中的变量。它不会改变函数内部当前作用域中同名变量的值。
特别注意:由于 PARENT_SCOPE 是直接修改父级,所以你必须确保父作用域中已经存在这个变量吗?不,不一定。如果父作用域中不存在,set(... PARENT_SCOPE) 会在父作用域中创建它;如果已存在,则修改它。
话不多说,我们直接看例子
示例1
项目结构
test/
└── CMakeLists.txt
CMakeLists.txt
cmake_minimum_required(VERSION 3.18)
project(FunctionUnsetParentDemo)set(VAR1 "outer1") # 定义外部变量 VAR1
set(VAR2 "outer2") # 定义外部变量 VAR2function(test_scope)message("函数开始时: VAR1='${VAR1}', VAR2='${VAR2}'")set(VAR1 "inner1" PARENT_SCOPE) # 修改 VAR1,并传递到父作用域set(NEW_VAR "new" PARENT_SCOPE) # 新建变量并写入父作用域unset(VAR2 PARENT_SCOPE) # 在父作用域彻底清除 VAR2message("函数内部: VAR1='${VAR1}', VAR2='${VAR2}', NEW_VAR='${NEW_VAR}'")
endfunction()message("调用函数前: VAR1='${VAR1}', VAR2='${VAR2}'")
test_scope()
message("调用函数后: VAR1='${VAR1}', VAR2='${VAR2}', NEW_VAR='${NEW_VAR}'")
其实我们可以执行下面这个来一键搭建出这个目录结构
mkdir -p test && cat > test/CMakeLists.txt <<'EOF'
cmake_minimum_required(VERSION 3.18)
project(FunctionUnsetParentDemo)set(VAR1 "outer1") # 定义外部变量 VAR1
set(VAR2 "outer2") # 定义外部变量 VAR2function(test_scope)message("函数开始时: VAR1='${VAR1}', VAR2='${VAR2}'")set(VAR1 "inner1" PARENT_SCOPE) # 修改 VAR1,并传递到父作用域set(NEW_VAR "new" PARENT_SCOPE) # 新建变量并写入父作用域unset(VAR2 PARENT_SCOPE) # 在父作用域彻底清除 VAR2message("函数内部: VAR1='${VAR1}', VAR2='${VAR2}', NEW_VAR='${NEW_VAR}'")
endfunction()message("调用函数前: VAR1='${VAR1}', VAR2='${VAR2}'")
test_scope()
message("调用函数后: VAR1='${VAR1}', VAR2='${VAR2}', NEW_VAR='${NEW_VAR}'")
EOF
接下来我们就来构建一下项目
mkdir build && cd build && cmake ..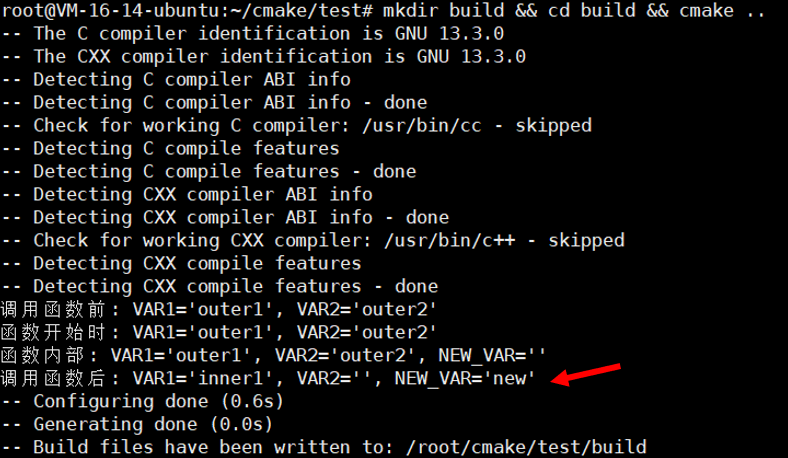
我们看到调用函数之后,真的影响到了外部变量,但是我们仔细观察的话,就会发现一个奇怪的地方。大家看下面
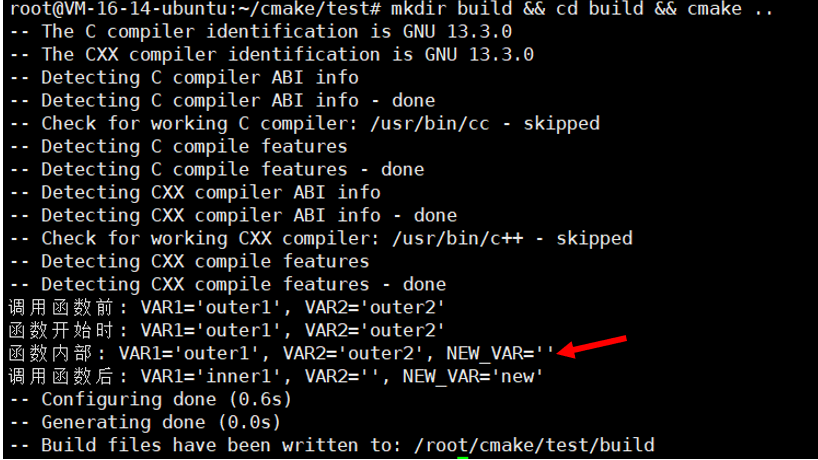
大家可能好奇啊?
为什么函数内部: VAR1='outer1', VAR2='outer2', NEW_VAR=''这一行居然是修改之前的状态?我明明是在修改了这些变量之后才去打印这一句的啊?
这里其实蕴含了一个机制
补充知识
当 CMake 的执行流程遇到一个函数调用时,它会启动一个精心设计的过程来管理变量和作用域。这个过程是理解 CMake 行为的关键。
第一步:调用时刻的准备工作
在控制权即将从“父作用域”(调用函数的地方)转移到“函数作用域”(函数体内的代码)的那一瞬间,CMake 会进行以下操作:
-
创建空的本地变量表:CMake 首先在内存中为本次特定的函数调用分配一个全新的、空的变量表。你可以将其视为一个专属于这次函数执行的私有数据库。这个表与任何其他作用域的表都是完全隔离的。
-
捕获父作用域状态:CMake 会立即对父作用域的变量表进行一次“快照”。这个快照记录了在函数调用语句被执行的那个时间点上,父作用域中所有已定义变量的完整状态,包括:
-
所有使用
set()或option()定义的普通变量。 -
所有使用
list()命令修改过的列表变量。 -
环境变量(如
$ENV{PATH})。 -
所有内置的CMake变量(如
CMAKE_SOURCE_DIR,PROJECT_NAME等)。
-
-
复制快照到本地表:CMake 将上一步快照中的所有条目,逐变量、逐值地复制到刚刚创建的空白本地变量表中。这个复制是深拷贝(对于列表变量,是复制整个列表,而不是引用)。
重要细节:
-
时机至关重要:这个复制过程发生在函数体内的任何一条代码执行之前。这意味着,即使父作用域中某个变量在函数调用语句之后被改变,也不会影响已经传入函数内部的副本。
-
全面复制:它复制的是整个变量环境,而不仅仅是函数明面上用到的参数。你可以在函数内部访问到父作用域的所有变量。
第二步:在函数作用域内执行
现在,函数体内的代码开始一行一行地执行。所有的变量操作都基于它自己的那份本地变量表。
-
变量查找(Read Access):
-
当代码中遇到
${SOME_VAR}时,CMake 的解析器会严格地在函数的本地变量表中查找名为SOME_VAR的条目。 -
因为它拥有父作用域变量的完整副本,所以它能成功找到并读出值。
-
它绝不会自动地、穿透性地去父作用域的原变量表中查找。如果某个变量在本地表中不存在(即它既不是从父作用域复制来的,也不是在函数内部创建的),那么
${SOME_VAR}的值将为空。
-
-
变量修改(Write Access - 无 PARENT_SCOPE):
-
当使用
set(SOME_VAR "New Value")或list(APPEND SOME_LIST "New Item")时,CMake 会执行以下操作:
a. 首先在本地变量表中查找SOME_VAR。
b. 如果找到,则修改该条目的值。
c. 如果没找到,则在本地变量表中创建一个名为SOME_VAR的新条目,并为其赋值。 -
关键:无论哪种情况,操作的对象都是本地变量表。父作用域的变量表完全不受影响,仿佛这两个表存在于不同的宇宙中。
-
-
与父作用域通信(Write Access - 使用 PARENT_SCOPE):
-
set(SOME_VAR "New Value" PARENT_SCOPE)是一个明确的指令,它改变了set命令的行为目标。 -
当 CMake 遇到这个命令时,它不会去触碰本地变量表中的
SOME_VAR条目。 -
Instead,它会沿着作用域链向上,找到父作用域的变量表,然后对那张表进行操作:
a. 在父作用域的变量表中查找SOME_VAR。
b. 如果找到,则修改其值。
c. 如果没找到,则在父作用域的变量表中创建一个新的SOME_VAR条目。 -
至关重要的后果:由于此操作跳过了本地表,所以本地表中
SOME_VAR的值保持不变。这就是为什么在函数内部执行了set(VAR ... PARENT_SCOPE)之后,紧接着用message(${VAR})打印,看到的依然是旧值(即最初从父作用域复制来的值,或之前在本地设置的值)。
-
所以,讲到这里大家应该明白了吧!!!
示例2
之前的例子里,set(VAR1 "outer1") 和 set(VAR2 "outer2") 在 调用函数之前 定义,所以函数内部看到的是外层的变量,并能通过 PARENT_SCOPE 修改或删除它们。
如果把这两句 放到函数调用之后,那么在调用函数时外层还没有 VAR1 和 VAR2,效果会很不一样。我们来写一个完整的例子:
项目结构
test/
└── CMakeLists.txt
CMakeLists.txt
cmake_minimum_required(VERSION 3.18)
project(FunctionUnsetParentDemo)function(test_scope)message("函数开始时: VAR1='${VAR1}', VAR2='${VAR2}'")set(VAR1 "inner1" PARENT_SCOPE) # 试图修改 VAR1(父作用域还不存在 VAR1,等同于新建)set(NEW_VAR "new" PARENT_SCOPE) # 新建变量并写入父作用域unset(VAR2 PARENT_SCOPE) # 试图删除 VAR2(父作用域还没有 VAR2,所以没效果)message("函数内部设置完变量后: VAR1='${VAR1}', VAR2='${VAR2}', NEW_VAR='${NEW_VAR}'")
endfunction()# 外层此时没有定义 VAR1 和 VAR2
message("调用函数前: VAR1='${VAR1}', VAR2='${VAR2}'")
test_scope()
message("调用函数后 (定义之前): VAR1='${VAR1}', VAR2='${VAR2}', NEW_VAR='${NEW_VAR}'")# 在函数调用之后再定义 VAR1 和 VAR2
set(VAR1 "outer1")
set(VAR2 "outer2")message("调用函数后 (定义之后): VAR1='${VAR1}', VAR2='${VAR2}', NEW_VAR='${NEW_VAR}'")其实我们可以执行下面这个来一键搭建出这个目录结构
mkdir -p test && cat > test/CMakeLists.txt <<'EOF'
cmake_minimum_required(VERSION 3.18)
project(FunctionUnsetParentDemo)function(test_scope)message("函数开始时: VAR1='${VAR1}', VAR2='${VAR2}'")set(VAR1 "inner1" PARENT_SCOPE) # 试图修改 VAR1(父作用域还不存在 VAR1,等同于新建)set(NEW_VAR "new" PARENT_SCOPE) # 新建变量并写入父作用域unset(VAR2 PARENT_SCOPE) # 试图删除 VAR2(父作用域还没有 VAR2,所以没效果)message("函数内部设置完变量后: VAR1='${VAR1}', VAR2='${VAR2}', NEW_VAR='${NEW_VAR}'")
endfunction()# 外层此时没有定义 VAR1 和 VAR2
message("调用函数前: VAR1='${VAR1}', VAR2='${VAR2}'")
test_scope()
message("调用函数后 (定义之前): VAR1='${VAR1}', VAR2='${VAR2}', NEW_VAR='${NEW_VAR}'")# 在函数调用之后再定义 VAR1 和 VAR2
set(VAR1 "outer1")
set(VAR2 "outer2")message("调用函数后 (定义之后): VAR1='${VAR1}', VAR2='${VAR2}', NEW_VAR='${NEW_VAR}'")
EOF
接下来我们就来构建一下项目
mkdir build && cd build && cmake ..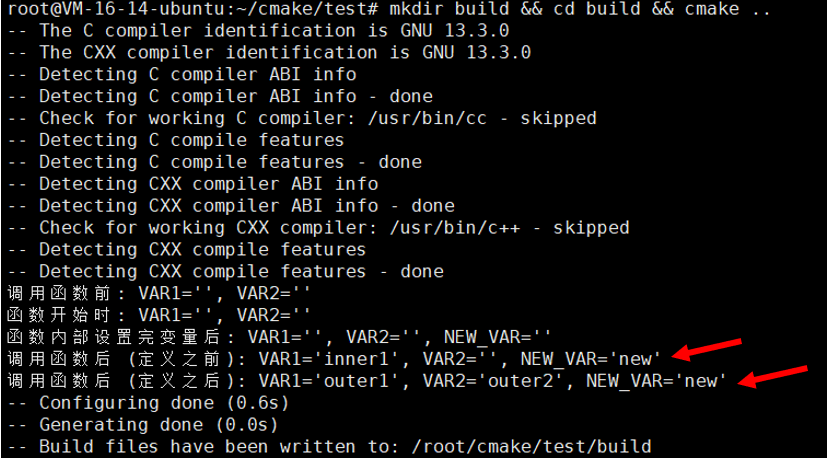
这就再度验证了我们的猜想!!!
1.3.策略在 Function 作用域中的关键行为
1.3.1.function()内的策略作用域
注意这个和那个block()和endblock()对待策略的作用域不一样!!
我们可以去官网看看是怎么说它的:cmake_policy — CMake 4.1.1 Documentation
Commands created by the function() and macro() commands record policy settings when they are created and use the pre-record policies when they are invoked. If the function or macro implementation sets policies, the changes automatically propagate up through callers until they reach the closest nested policy stack entry.
中文翻译:
由
function()和macro()命令创建的函数和宏会在创建时记录策略设置,并在被调用时使用这些预先记录的策略。如果函数或宏的实现内部设置了策略,其更改会自动向上传播到调用方,直到到达最内层的嵌套策略栈条目。
我们来好好讲讲
在 CMake 中,由 function() 和 macro() 命令所定义的函数与宏,其策略作用域的行为是独特且需要特别注意的,这与 block(SCOPE_FOR POLICIES) 创建的显式作用域有根本不同。
核心机制:
-
定义时静态绑定(Statically Bound at Definition)
当使用function()或macro()进行定义时,CMake 会捕获当前作用域下所有策略的设置状态,并将其作为一个快照与这个函数或宏永久绑定。此快照定义了该函数/宏执行的“策略起点”。 -
调用时隔离执行(Isolated Execution upon Invocation)
无论后续在何处调用该函数或宏,其内部的代码逻辑都将严格遵循定义时所记录的策略快照,完全不受调用者当前策略环境的影响。这种机制确保了函数与宏的行为具有确定性和封装性,其执行结果不会因外部调用上下文的不同而改变。 -
内部更改的向上传播(Propagation of Internal Changes)
虽然入口策略是隔离的,但函数或宏内部仍然可以动态地使用cmake_policy(SET ...)等命令修改策略。
关键之处在于:这些在函数/宏内部发生的策略更改不会被限制在其局部作用域内。相反,这些修改会向上传播(Propagate Upwards),影响其调用者的策略环境。
这种传播会一直持续,直至遇到一个由cmake_policy(PUSH)或block(SCOPE_FOR POLICIES)所创建的策略栈屏障为止。
与 block() 的关键区别:
-
function()/macro():提供入口策略的隔离,但允许内部策略更改泄漏到外部。这是一种“半透明”的作用域。 -
block(SCOPE_FOR POLICIES) ... endblock():创建一个完全隔离且自包含的策略作用域。在block内部对策略的任何修改都会在endblock处被自动撤销,绝对不会对外部调用环境造成任何影响。这是一种“不透明”的、安全的作用域。
示例1
我们直接看例子
项目结构
test/
└── CMakeLists.txt
CMakeLists.txt
cmake_minimum_required(VERSION 3.5)
project(PolicyFunctionDemo)function(my_func)cmake_policy(GET CMP0048 state)message("函数开始时 CMP0048 = ${state}")cmake_policy(SET CMP0048 OLD)cmake_policy(GET CMP0048 state)message("函数内部修改 CMP0048 = ${state}")
endfunction()# 在顶层设置 CMP0048 策略为 NEW
cmake_policy(SET CMP0048 NEW)# 函数调用前
cmake_policy(GET CMP0048 state)
message("函数调用前 CMP0048 = ${state}")# 调用函数
my_func()# 函数返回后
cmake_policy(GET CMP0048 state)
message("函数返回后 CMP0048 = ${state}")
其实我们可以执行下面这个来一键搭建出这个目录结构
mkdir -p test && cat > test/CMakeLists.txt <<'EOF'
cmake_minimum_required(VERSION 3.5)
project(PolicyFunctionDemo)function(my_func)cmake_policy(GET CMP0048 state)message("函数开始时 CMP0048 = ${state}")cmake_policy(SET CMP0048 OLD)cmake_policy(GET CMP0048 state)message("函数内部修改 CMP0048 = ${state}")
endfunction()# 在顶层设置 CMP0048 策略为 NEW
cmake_policy(SET CMP0048 NEW)# 函数调用前
cmake_policy(GET CMP0048 state)
message("函数调用前 CMP0048 = ${state}")# 调用函数
my_func()# 函数返回后
cmake_policy(GET CMP0048 state)
message("函数返回后 CMP0048 = ${state}")
EOF
接下来我们就来构建一下项目
mkdir build && cd build && cmake ..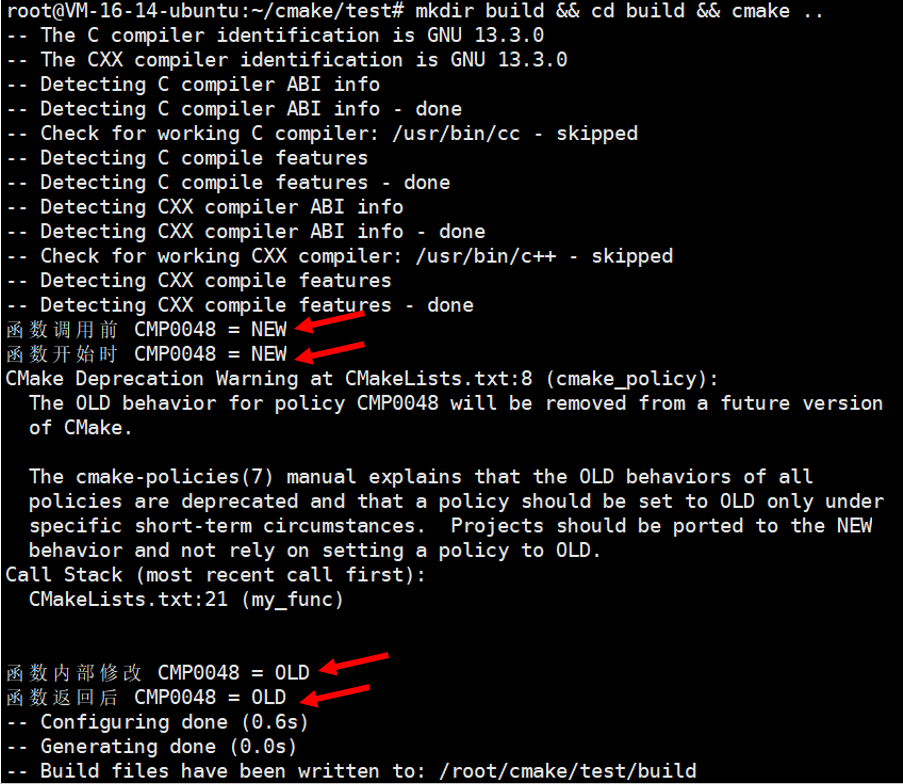
完全没有问题吧!!!
1.3.2.在function()里面构建一个独立的策略作用域
鉴于函数和宏内部策略更改会“泄漏”的特性,强烈建议在其内部使用 cmake_policy(PUSH) 和 cmake_policy(POP) 对,或者(在 CMake 3.25+ 版本中)更推荐使用 block(SCOPE_FOR POLICIES) ... endblock() 来显式地管理一个临时策略栈。
这样做可以确保函数/宏内部的策略调整被严格限制在临时栈帧内,当通过 POP 或退出 block 时,所有临时更改都会被自动回收,从而避免了意外污染调用者策略状态的风险,使代码更加健壮和可维护。
此外,官网还说
在 3.25 版本中添加:block(SCOPE_FOR POLICIES) 命令提供了一种更灵活、更安全的方式来管理策略栈。pop 操作在离开块作用域时会自动完成,因此无需在每次 return() 前调用 cmake_policy(POP)。
# 使用 cmake_policy() 管理栈
function(my_func)cmake_policy(PUSH)cmake_policy(SET ...)if (<cond1>)...cmake_policy(POP)return()elseif(<cond2>)...cmake_policy(POP)return()endif()...cmake_policy(POP)
endfunction()# 使用 block()/endblock() 管理栈
function(my_func)block(SCOPE_FOR POLICIES) # 块(作用域为策略)cmake_policy(SET ...)if (<cond1>)...return()elseif(<cond2>)...return()endif()...endblock() # 结束块
endfunction()由此,我们可以看一个例子
示例
项目结构
test/
└── CMakeLists.txt
CMakeLists.txt
cmake_minimum_required(VERSION 3.5)
project(PolicyFunctionDemo)function(my_func)cmake_policy(PUSH)cmake_policy(GET CMP0048 state)message("函数开始时 CMP0048 = ${state}")cmake_policy(SET CMP0048 OLD)cmake_policy(GET CMP0048 state)message("函数内部修改 CMP0048 = ${state}")cmake_policy(POP)
endfunction()# 在顶层设置 CMP0048 策略为 NEW
cmake_policy(SET CMP0048 NEW)# 函数调用前
cmake_policy(GET CMP0048 state)
message("函数调用前 CMP0048 = ${state}")# 调用函数
my_func()# 函数返回后
cmake_policy(GET CMP0048 state)
message("函数返回后 CMP0048 = ${state}")
其实我们可以执行下面这个来一键搭建出这个目录结构
mkdir -p test && cat > test/CMakeLists.txt <<'EOF'
cmake_minimum_required(VERSION 3.5)
project(PolicyFunctionDemo)function(my_func)cmake_policy(PUSH)cmake_policy(GET CMP0048 state)message("函数开始时 CMP0048 = ${state}")cmake_policy(SET CMP0048 OLD)cmake_policy(GET CMP0048 state)message("函数内部修改 CMP0048 = ${state}")cmake_policy(POP)
endfunction()# 在顶层设置 CMP0048 策略为 NEW
cmake_policy(SET CMP0048 NEW)# 函数调用前
cmake_policy(GET CMP0048 state)
message("函数调用前 CMP0048 = ${state}")# 调用函数
my_func()# 函数返回后
cmake_policy(GET CMP0048 state)
message("函数返回后 CMP0048 = ${state}")
EOF
接下来我们就来构建一下项目
mkdir build && cd build && cmake ..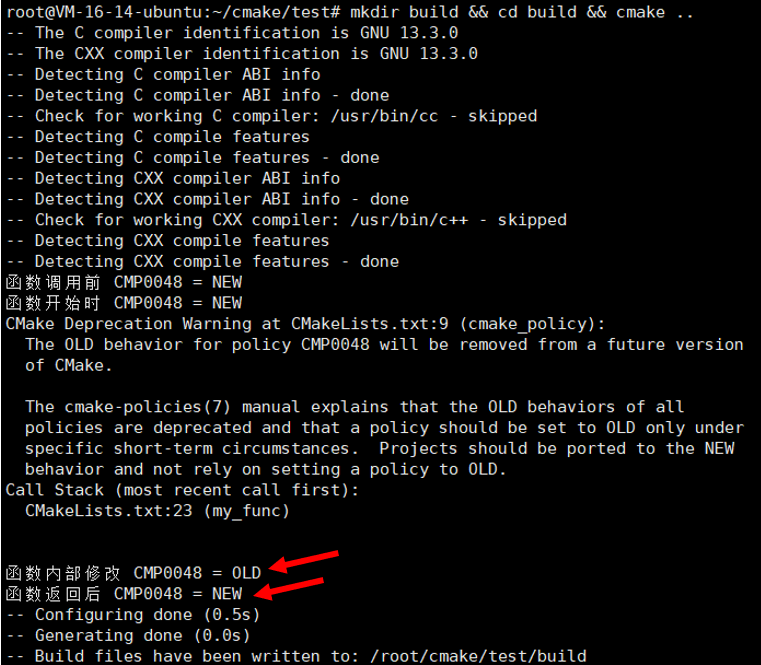
完全没有问题吧!!!