【论文阅读】Sparse4D v3:Advancing End-to-End 3D Detection and Tracking
标题:Sparse4D v3:Advancing End-to-End 3D Detection and Tracking
作者:Xuewu Lin, Zixiang Pei, Tianwei Lin, Lichao Huang, Zhizhong Su
motivation
作者觉得做自动驾驶,还需要跟踪。于是更深入的把3D-检测&跟踪用sparse的模式做好。 检测性能的进一步优化及端到端跟踪实现。
于是将目光聚焦到了两个问题上:
**收敛困难:**稀疏形式的感知算法,大多数都面临这个收敛困难的问题,收敛速度相对较慢、训练不稳定导致最终指标不高;在Sparse4D-V2 中,我们主要采用了额外的深度估计任务来帮助网络训练,但由于用上了额外的点云作为监督,这并不是一种理想的形式。
**端到端跟踪:**在实际业务系统中,在检测模块后,我们总是需要在加入跟踪模块获得目标轨迹。因此一个完善的稀疏动态感知框架应该同时具备端到端跟踪能力。
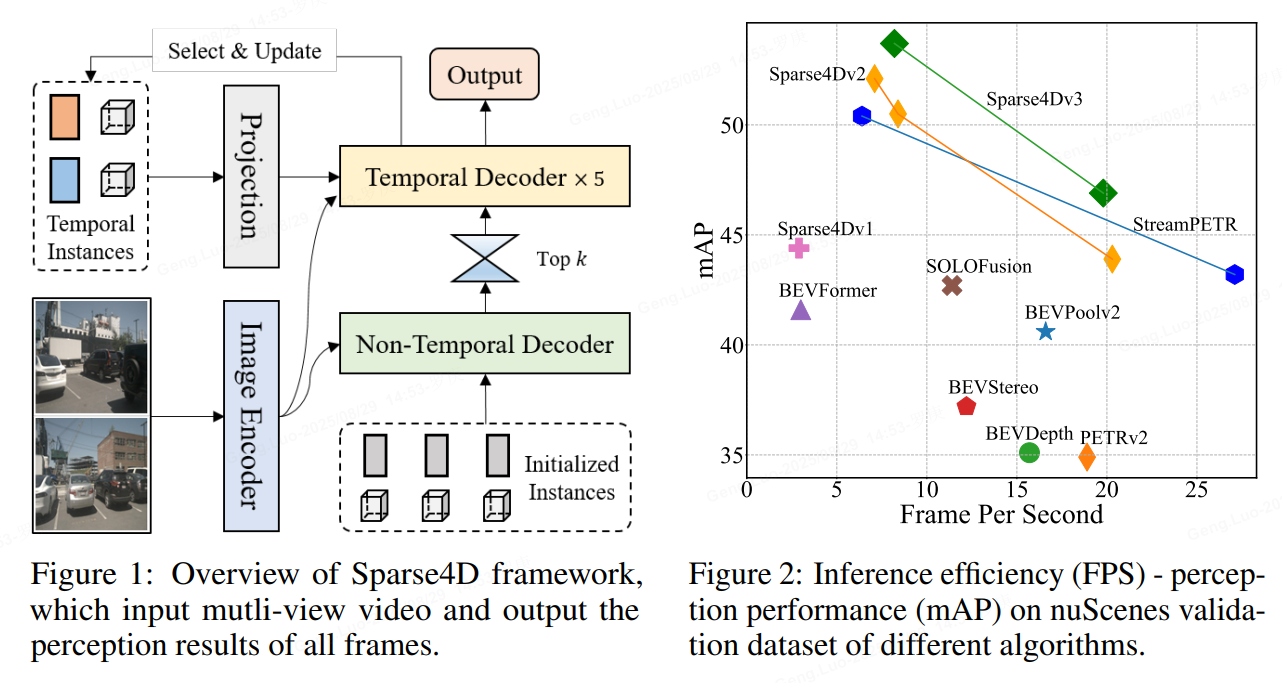
methods
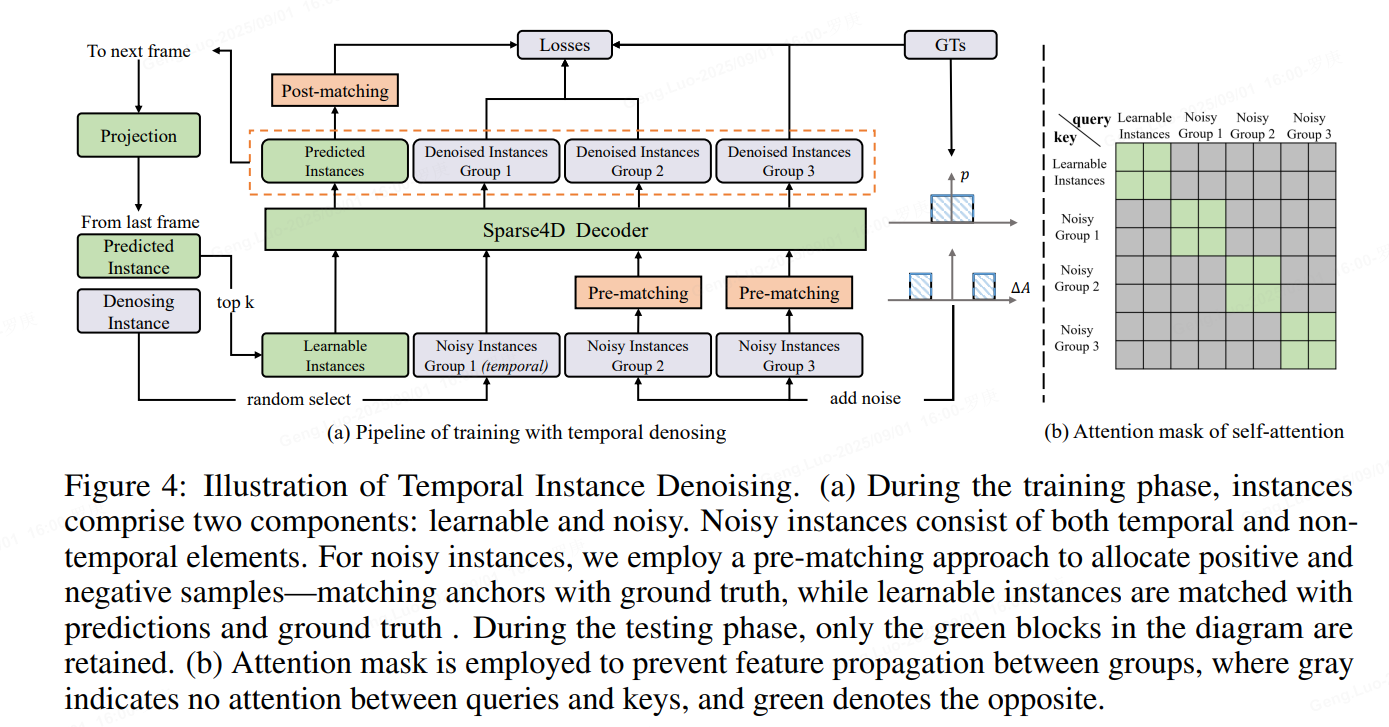
1、Temporal Instance Denoising
在训练过程中,初始化了两组锚点。
一组包括均匀分布在检测空间中的锚点,使用 k 均值方法初始化,这些锚点作为可学习参数。
另一组锚点是通过向地面实况 (GT) 添加噪声生成的,如公式如下所示,专门为 3D 检测任务量身定制。对GT加上小规模噪声来生成noisy instance,用decoder来进行去噪,这样可以较好的控制instance和gt之间的偏差范围,decoder 层之间匹配关系稳定,让训练更加鲁棒,且大幅增加正样本的数量,让模型收敛更充分,以得到更好的结果。具体来说,我们设置两个分布来生产噪声Delat_A,用于模拟产生正样本和负样本,对于3D检测任务加噪公式如下
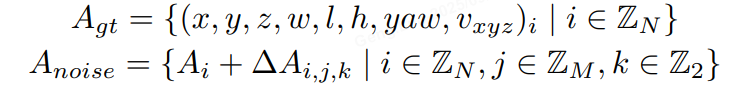
加上噪声的GT框需要重新和原始GT进行one2one匹配,确定正负样本,而并不是直接将加了较大扰动的GT作为负样本,这可以缓解一部分的分配歧义性。噪声GT需要转为instance的形式以输入进网络中,首先噪声GT可以直接作为anchor,把噪声GT编码成高维特征作为anchor embed,相应的instance feature直接以全0来初始化。
为了模拟时序特征传递的过程,让时序模型能得到denoisy任务更多的收益,将单帧denosing拓展为时序的形式。具体地,在每个训练step,随机选择部分noisy-instance组,将这些instance通过ego pose和velocity投影到当前帧,投影方式与learnable instance一致。
具体实现中,我们设置了5组noisy-instance,每组最大gt数量限制为32,因此会增加5322=320个额外的instance。时序部分,每次随机选择2组来投影到下一帧。每组instance使用attention mask完全隔开,与DINO中的实现不一样的是,我们让noisy-instance也无法和learnable instance进行特征交互.
2、Quality Estimation
Sparse4D输出的分类置信度并不适合用来判断框的准确程度,这主要是因为one2one 匈牙利匹配过程中,正样本离GT并不能保证一定比负样本更近,而且正样本的分类loss并不随着匹配距离而改变。而对比dense head,如CenterPoint或BEV3D,其分类label为heatmap,随着离gt距离增大,loss weight会发生变化。
因此,除了一个正负样本的分类置信度以外,还需要一个描述模型结果与GT匹配程度的置信度,也就是进行Quality Estimation。对于3D检测来说,我们定义了两个quality指标,centerness和yawness:
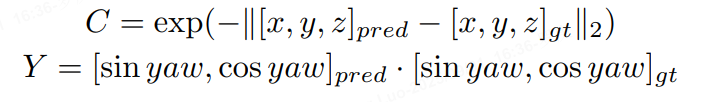
qt = qt.flatten(end_dim=1)[mask] #[n,2]
cns = qt[..., 0]
yns = qt[..., 1].sigmoid()
cns_target = torch.norm(reg_target[..., :3] - reg[..., :3], p=2, dim=-1)
cns_target = torch.exp(-cns_target)
cns_loss = self.loss_cns(cns, cns_target, avg_factor=num_pos)
output[f"loss_cns_{decoder_idx}"] = cns_loss
yns_target = (torch.nn.functional.cosine_similarity(reg_target[..., 6:8],reg[..., 6:8],dim=-1,) > 0
)
yns_target = yns_target.float()
yns_loss = self.loss_yns(yns, yns_target)
output[f"loss_yns_{decoder_idx}"] = yns_loss
对于centerness和yawness,我们分别用cross entropy loss和focal loss来进行训练
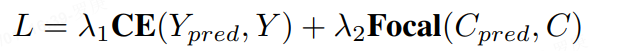
3、Decoupled Attention
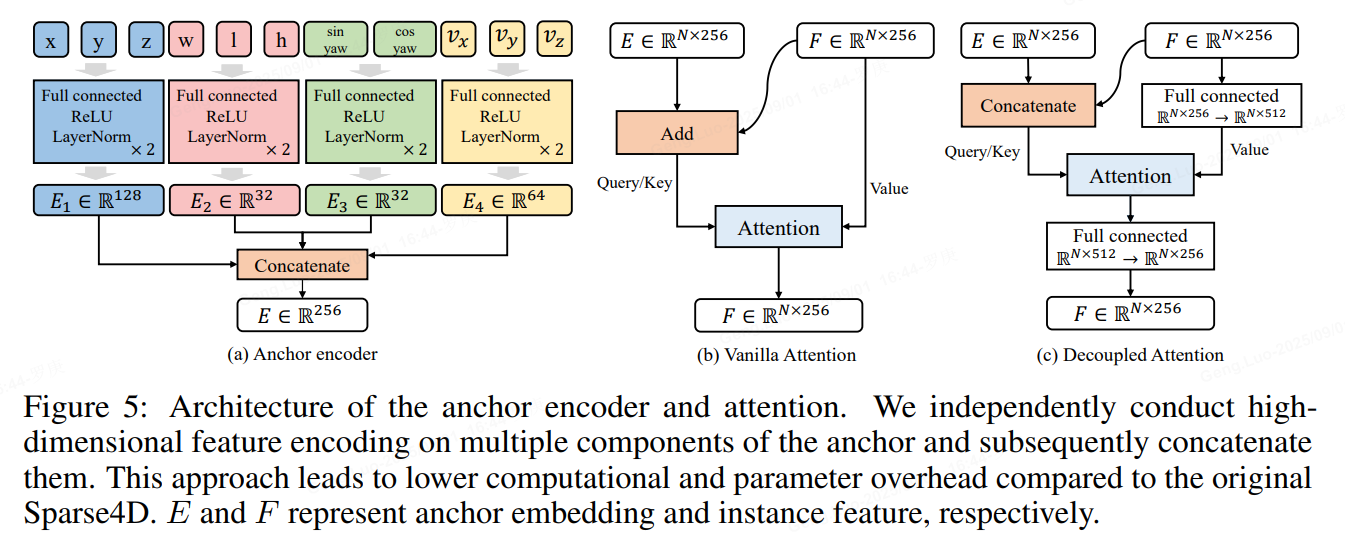
Sparse4D中有两个instance attention模块,1)instance self-attention和2)temporal instance cross-attention。在这两个attention模块中,将instance feature和anchor embed相加作为query与key,在计算attention weights时一定程度上会存在特征混淆的问题,如图下所示。

为了解决这问题,作者对attention模块进行了简单的改进,将所有特征相加操作换成了拼接,提出了decoupled atttention module,结构如下图所示
def forward(self, box_3d: torch.Tensor) -> torch.Tensor:pos_feat = self.pos_fc(box_3d[..., 0:3])size_feat = self.size_fc(box_3d[..., 3:6])yaw_feat = self.yaw_fc(box_3d[..., 6:8])if self.vel_dims > 0:vel_feat = self.vel_fc(box_3d[..., 8 : 8 + self.vel_dims])output = self.cat.cat([pos_feat, size_feat, yaw_feat, vel_feat], dim=-1)else:output = self.cat.cat([pos_feat, size_feat, yaw_feat], dim=-1)return output4、Extend to Tracking
无需额外训练策略的端到端多目标跟踪能力。由于Sparse4D已经实现了目标检测的端到端(无需dense-to-sparse的解码),进一步考虑将端到端往检测的下游任务进行拓展,即多目标跟踪。发现当Sparse4D经过充分检测任务的训练之后,instance在时序上已经具备了目标一致性了,即同一个instance始终检测同一个目标。因此,无需对训练流程进行任何修改,只需要在infercence阶段对instance进行ID assign即可,infer pipeline如下所示。

对比如MOTR、TransTrack、TrackFormer等一系列端到端跟踪算法,实现方式具有以下两点不同: 1)训练阶段,无需进行任何tracking的约束;2)Temporal instance不需要卡高阈值,大部分temporal instance不表示一个历史帧的检测目标。
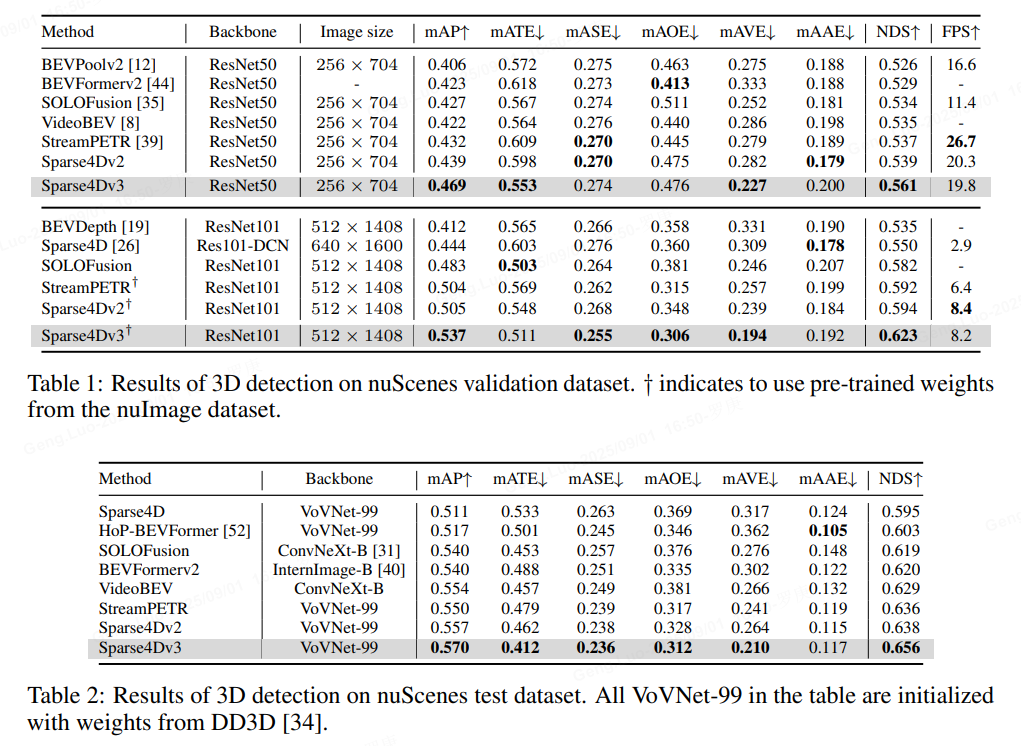
experiments
作者的总结与展望
总的来说,在长时序稀疏化3D 目标检测的一路探索中,主要有如下的收获:
显式的稀疏实例表示方式: 将待检测的instance 表示为3D anchor 和 instance feature,并不断进行迭代更新来获得检测结果是一种简洁、有效的方式。同时,这种方式也更容易进行时序的运动补偿;
高效的Deformable Aggregation 算子:提出了针对多视角/多尺度图像特征 + 多关键点的层级化特征采样与融合策略,并进行了大幅的效率优化,能高效获得高质量的特征表示。同时在稀疏化的形式下,decoder 部分的计算量和计算延时受输入图像分辨率的影响不大,能更好处理高分辨率输入;
Recurrent 的时序稀疏融合框架:基于稀疏实例的时序recurrent 融合框架,使得时序模型基本上具备与单帧模型相同的推理速度,同时在帧间只需要占用少量的带宽(比起bev 的时序方案)。这样轻量且有效的时序方案很适合在真实的车端场景处理多摄视频流数据。
端到端多目标跟踪:在无需对训练阶段进行任何修改的情况下,实现了从多视角视频到目标轨迹的端到端感知,进一步减小对后处理的依赖,算法结构和推理流程非常简洁;
卓越的感知性能:在稀疏感知框架下进行了一系列性能优化,在不增加推理计算量的前提下,让Sparse4D在检测和跟踪任务上都取得了SOTA的水平。
基于稀疏范式的感知算法仍然有很多未解决的问题,也具有很大的发展空间。首先,如何将Sparse的框架应用到更广泛的感知任务上是下一步需要探索的,例如道路元素的感知任务(HD map construction、 topology等)、预测规控任务(trajectory prediction、end-to-end planning等);其次,需要对稀疏感知算法进行更充足的验证,保证其具备量产能力,例如远距离检测效果、相机内外参泛化能力及多模态融合感知性能等。作者希望Sparse4D(v3)可以作为稀疏感知方向新的baseline,推动该领域的进步。
就是好好好!
【完结】