SMARTGRAPHQA —— 基于多模态大模型的PDF 转 Markdown方法和基于大模型格式校正方法
一个基于 Python 的工具,利用多模态大模型(MLLM)将 PDF 文档转换为结构清晰、格式准确的 Markdown 文件。支持图像提取、Base64 编码、分段保存和可选的内容校正功能,适用于长文档的高精度转换。
代码连接:点击这里
📌 主要功能
- ✅ PDF 转图像:使用
PyMuPDF(fitz)将每页 PDF 高清渲染为图像。 - ✅ 图像转 Markdown:通过多模态大模型(如 Qwen-VL)识别图像内容并生成结构化 Markdown。
- ✅ 断点续存机制:每处理 N 页自动保存一次,防止程序中断导致前功尽弃。
- ✅ 图像导出选项:可选择将 PDF 页面保存为 JPG 图像用于调试或归档。
- ✅ Markdown 内容校正:支持使用上下文信息对生成内容进行修订,提升连贯性与格式一致性。
- ✅ 灵活提示词配置:可通过模板或自定义 prompt 控制模型行为。
- ✅ 指定页码范围:支持只处理 PDF 的某一部分页面。
- ✅ 双模式修订:可选择使用 MLLM 多模态模型或纯语言模型(LLM)进行内容修订。
效果图
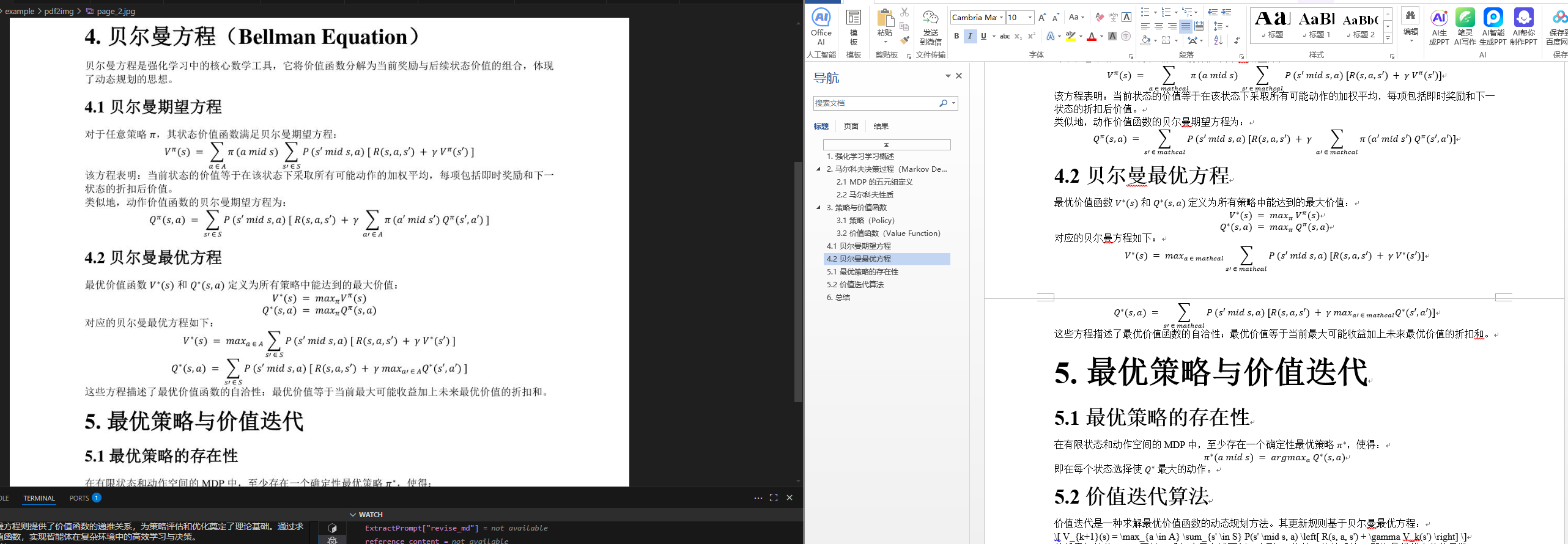
🧰 项目结构
确保项目结构如下:
SmartGraphQA/
├── Models/
│ ├── vision_models.py # 多模态模型封装
│ └── LLM_Models.py # 语言模型封装
├── ExtraTools/
│ └── extractDocument/
│ ├── extractPrompt.py # 提示词模板
│ └── Pdf2Img2Md.py # 本工具主文件
🚀 使用示例
from ExtraTools.extractDocument.PDFToMarkdownConverter import PDFToMarkdownConverterpdf_file = "xxx.pdf"
output_folder