linux中的awk使用详解
文章目录
- 前言
- 一、概述
- 二、工作原理
- 三、工作流程
- 3.1 运行模式
- 3.2 执行流程
- 四、基本语法
- 4.1 命令格式
- 4.2 常用内置变量
- 五、实战案例
- 5.1 基础文本处理
- 5.2 模式匹配
- 5.3 使用 BEGIN 和 END
- 5.3.1 直接数学运算
- 5.4 模糊匹配
- 5.5 逻辑运算与条件判断
- 5.6 使用awk的内置变量
- 5.7 在awk中使用if进行逻辑控制
- 5.8 通过管道、双引号调用shell 命令
- 5.9 数组与循环
- 5.9.1 核心概念:AWK 数组是**关联数组**
- 5.9.2 基本语法
- 5.9.3 关键特性与用法
- 5.9.3.1 遍历数组
- 5.9.3.2 检查键是否存在以及检查数组是否为空
- 5.9.3.3 删除数组元素
- 5.9.3.4 多维数组(模拟)
- 5.9.4 经典实用示例
- 5.9.4.1 示例 1:统计词频
- 5.9.4.2 示例 2:处理 /etc/passwd 文件
- 5.9.4.3 示例 3:倒置数组(键值互换)
- 5.9.4.3 总结与注意事项
- 5.10实战脚本示例
- 5.10.1 查看内存百分比
- 5.10.1.1 从`/proc/meminfo`获取参数实现内存百分比计算
- 5.10.2 同一ip多次失败访问预警
- 5.10.3 统计在线用户
- 5.10.4 查看cpu使用率
- 总结
前言
AWK 是一种强大的文本处理工具,诞生于 20 世纪 70 年代的贝尔实验室,由 Alfred Aho、Peter Weinberger 和 Brian Kernighan 三位创始人共同开发,其名称取自三人姓氏的首字母。AWK 专门用于文本扫描、过滤、统计和格式化输出,支持从标准输入、管道或文件中读取数据。在 Linux 系统中,常用的版本是 GAWK(GNU AWK),它是 AWK 的自由软件版本,完全兼容 AWK 和 NAWK。
本文将系统介绍 AWK 的基本概念、工作原理、语法结构、常用变量和实战案例,帮助读者全面掌握 AWK 的使用方法。
一、概述
AWK 是一种处理文本文件的编程语言,也是一个强大的文本分析工具。它逐行读取输入数据,按字段进行处理,支持模式匹配、变量操作、数学运算和流程控制,广泛应用于日志分析、数据提取和报表生成等场景。
二、工作原理
AWK 逐行读取文本,默认以空格或制表符作为字段分隔符,将每行拆分成多个字段,并存入内置变量(如 $1、$2 等)。每读取一行,AWK 会检查是否匹配指定的模式,若匹配则执行相应的动作。若不指定模式,则默认处理所有行。
三、工作流程
3.1 运行模式
任何 awk 语句都是由模式和动作组成,一个 awk 可以有多个语句。模式决定动作语句的触发条件和触发时间。
AWK 程序由三部分组成:
BEGIN块:在处理输入前执行一次,常用于初始化变量或打印表头。pattern { action }块:对每一行进行模式匹配,若匹配则执行动作。END块:在处理完所有输入后执行一次,常用于汇总结果。
3.2 执行流程
- 执行
BEGIN块中的命令。 - 逐行读取输入数据。
- 对每一行执行匹配的模式和动作。
- 重复步骤 2 和 3,直到所有行处理完毕。
- 执行
END块中的命令。
四、基本语法
4.1 命令格式
awk [选项] '模式 { 动作 }' 文件1 文件2 ...
awk -f 脚本文件 文件1 文件2 ...
4.2 常用内置变量
AWK 支持两种不同类型的变量:内建变量(可直接使用),自定义变量awk 内置变量(预定义变量)
| 变量名 | 说明 |
|---|---|
FS | 输入字段分隔符,默认为空格或制表符 |
OFS | 输出字段分隔符,默认为空格 |
RS | 输入行分隔符,默认为换行符 |
ORS | 输出行分隔符,默认为换行符 |
NF | 当前行的字段数 |
NR | 当前行号 |
FNR | 当前文件的行号(多文件时独立计数) |
$0 | 当前行的完整内容 |
$n | 当前行的第 n 个字段 |
FILENAME | 当前输入文件名 |
五、实战案例
5.1 基础文本处理
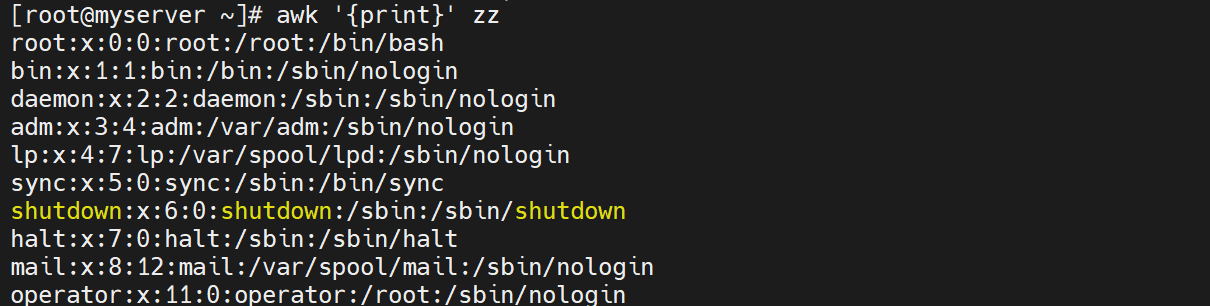
# 打印文件所有行
awk '{print}' zz
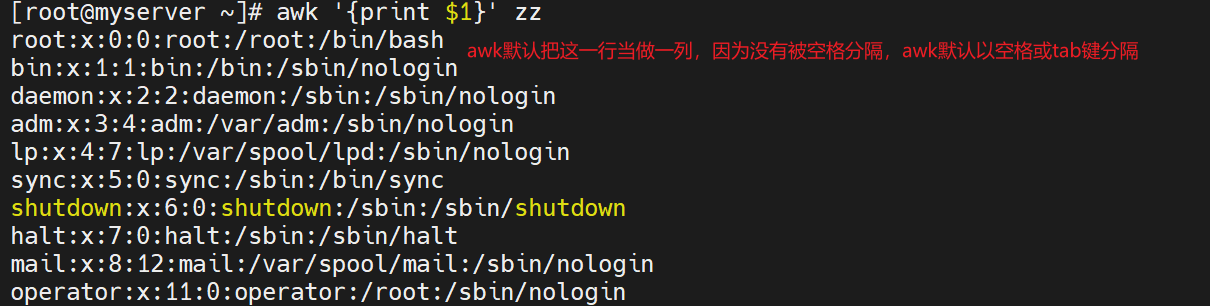
# 打印第一列
awk '{print $1}' zz #因没有定义分隔符,按默认分隔符空格进行分段
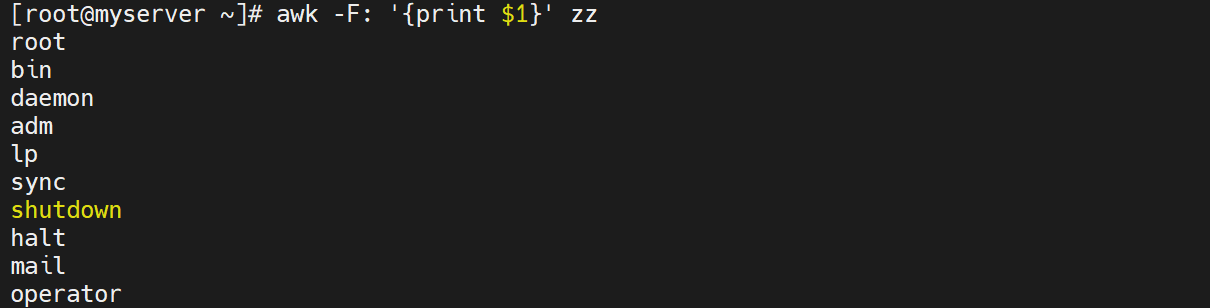
# 指定冒号为分隔符,打印第五列
awk -F: '{print $5}' zz
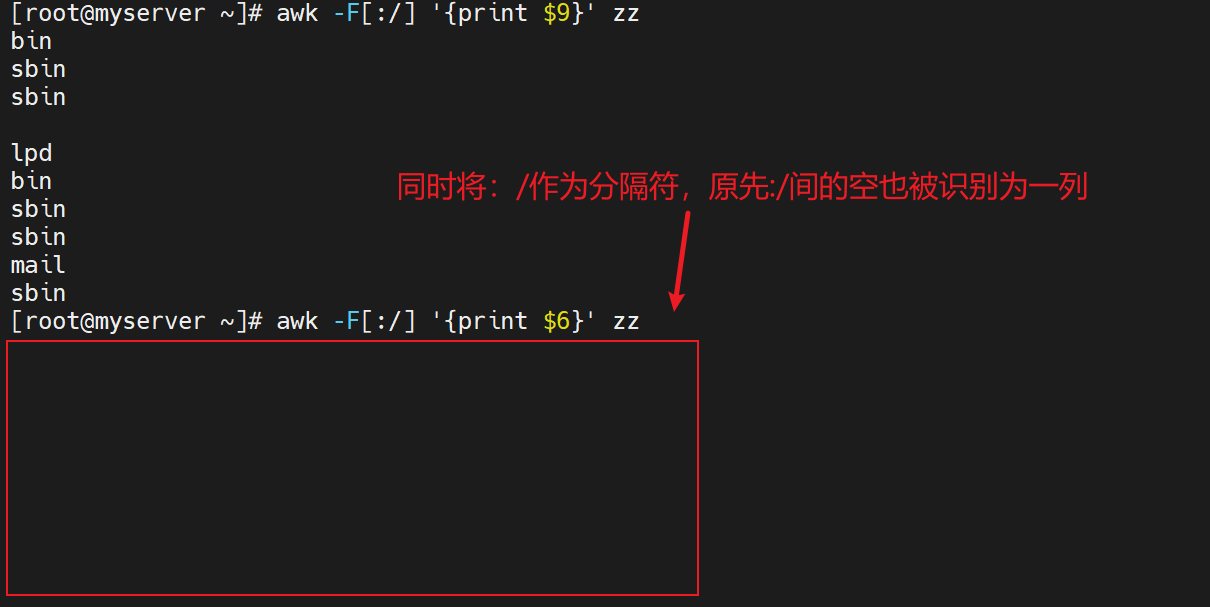
#定义多个分隔符,只要看到其中一个都算作分隔符
awk -F[:/] '{print $9}' zz
#显示一个空格,空格需要用双引号引起来,如果不用引号默认以变量看待,如果是常量就需要双引号引起来awk '{print $1""$2}' zz #逗号有空格效果awk '{print $1,$2}' zz #用制表符作为分隔符输出awk -F: '{print $1"\t"$2}' zz
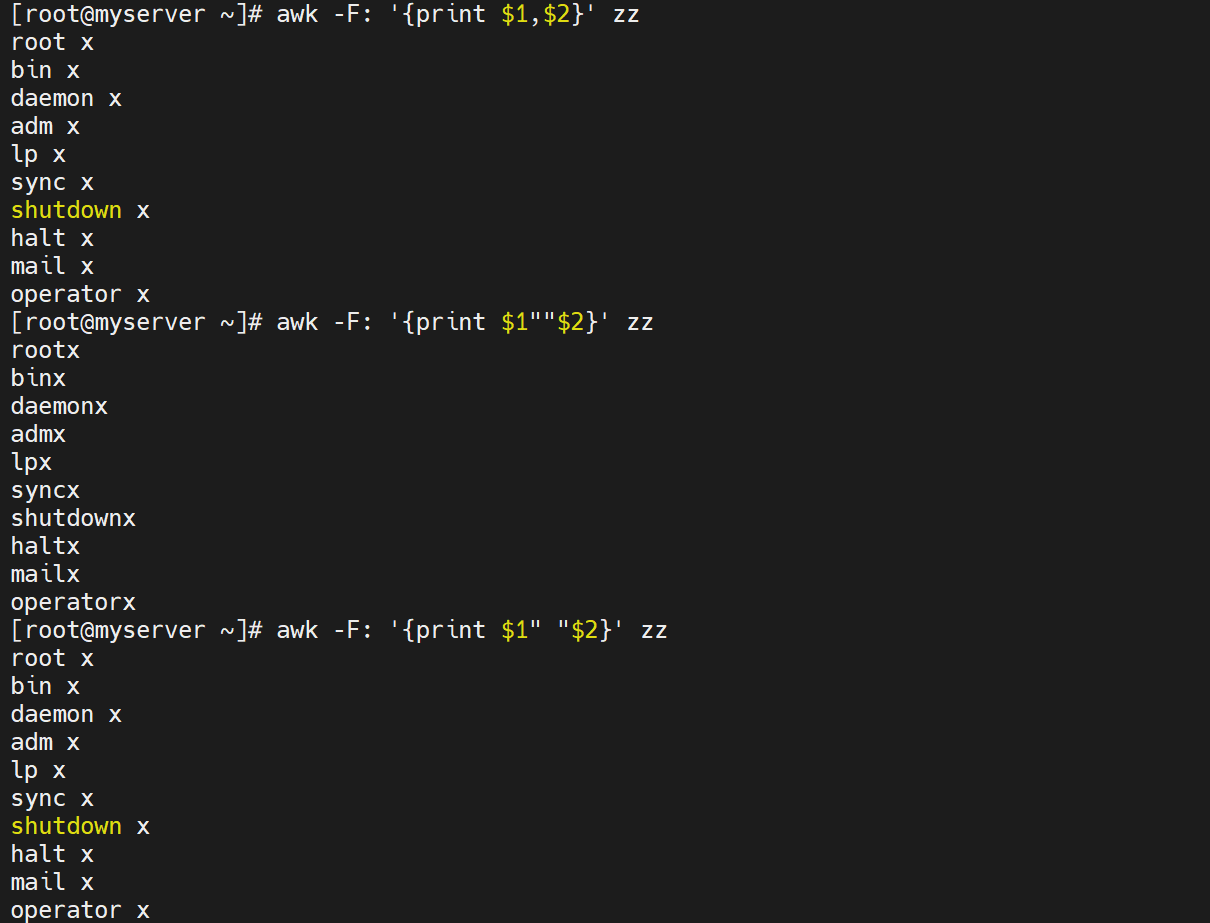
# 打印行号和整行内容
awk '{print NR, $0}' zz
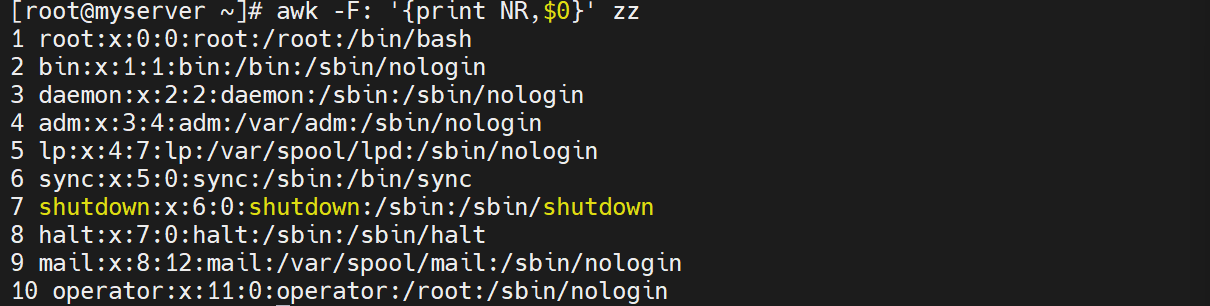
5.2 模式匹配
# 打印包含 "root" 的行
awk -F: '/root/{print $0}' zz
# 打印包含 "root" 的行的第一列
awk -F: '/root/{print $1}' pass.txt


#显示行号
awk -F: '{print NR}' zz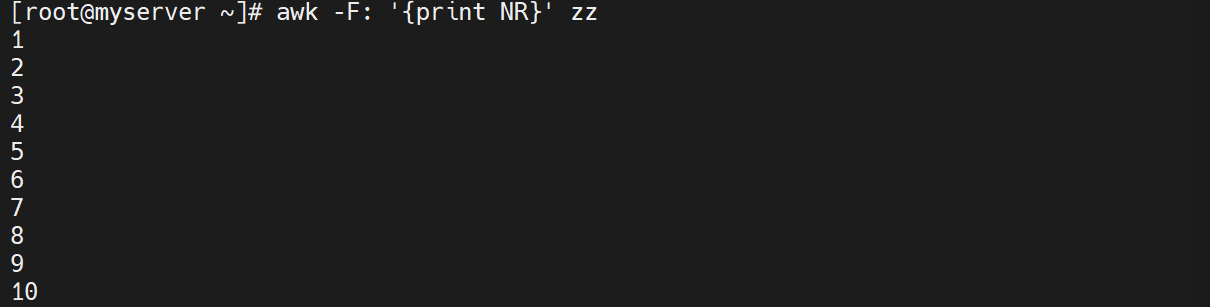
#打印总行数
awk 'END{print NR}' zz
#打印文件最后一行
awk 'END{print $0}' zz


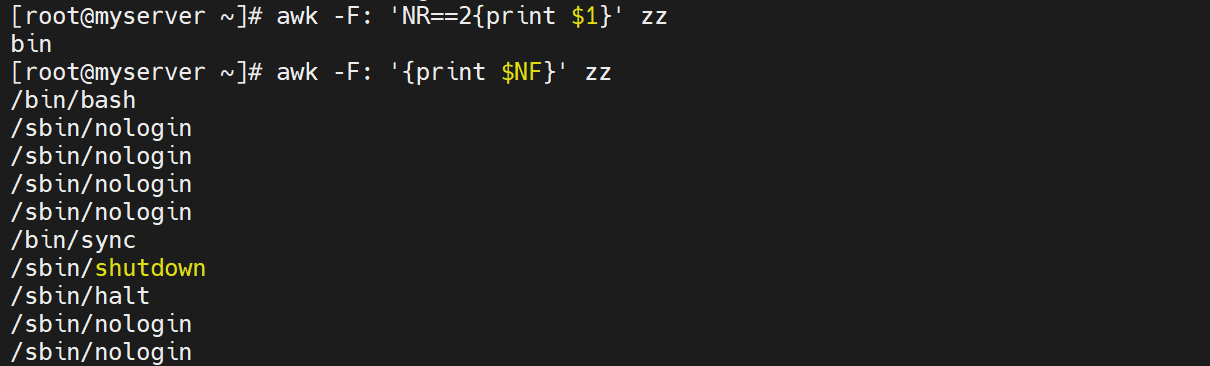
#打印第二行的第一列
awk -F: 'NR==2{print $1}'
#打印最后一列
awk -F: '{print $NF}' zz
#打印第二行,不加print也一样,默认就是打印
awk 'NR==2' zz
awk 'NR==2{print}' zz

# 打印第三列等于 0 的行
awk -F: '$3 == 0' zz

# 打印行号小于 5 的行
awk 'NR < 5' zz

#不将字符串用双引号框起来会无法进行判断
awk -F: '$1==root' /etc/passwd
#精确匹配一定是root
awk -F: '$1=="root"' /etc/passwd

awk -F: '$3>=1000' /etc/passwd

5.3 使用 BEGIN 和 END
- BEGIN一般用来做初始化操作,仅在读取数据记录之前执行一次
- END一般用来做汇总操作,仅在读取完数据记录之后执行一次
awk -F: 'BEGIN{x=0};/\/bin\/bash$/{x++;print x,$1};END{print "bash的目录为/bin/bash的用户共"x"个"}' /etc/passwd

5.3.1 直接数学运算
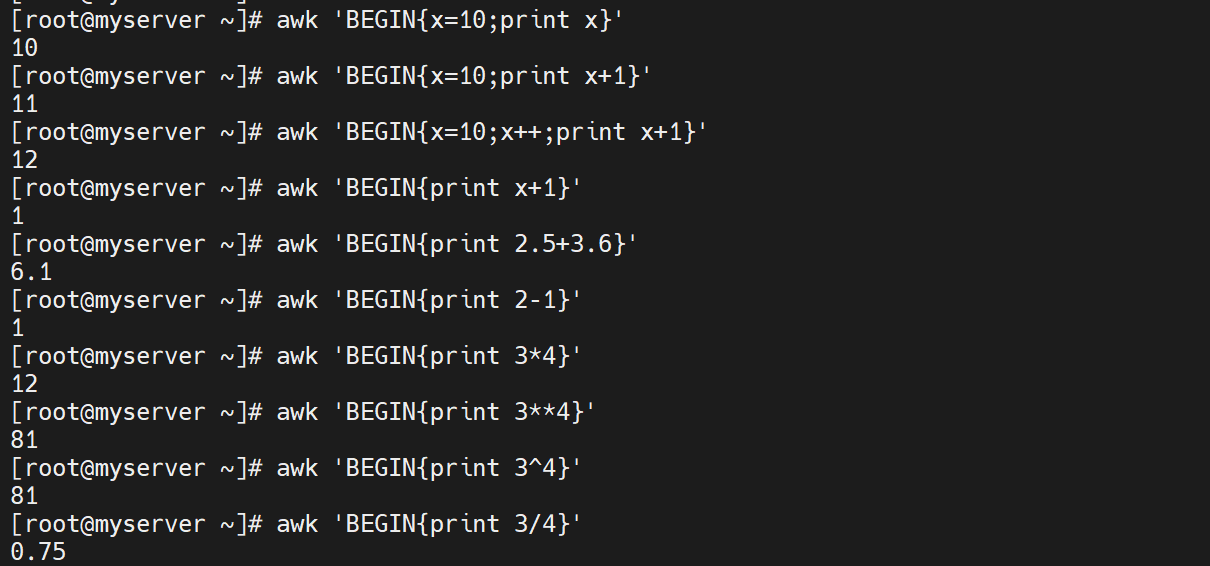
awk 'BEGIN{x=10;print x}' #赋值变量
awk 'BEGIN{x=10;print x+1}' #变量运算
awk 'BEGIN{x=10;x++;print x}' #变量自增
awk 'BEGIN{print x+1}' #直接输出变量不定义变量,默认为0
awk 'BEGIN{print 2.5+3.5}' #小数计算
awk 'BEGIN{print 2-1}' #减
awk 'BEGIN{print 3*4}' #乘
awk 'BEGIN{print 3**2}' #开平方
awk 'BEGIN{print 2^3}' #指数幂
awk 'BEGIN{print 1/2}' #除法
5.4 模糊匹配
# 打印第一列包含 "root" 的行,模糊匹配
awk -F: '$1 ~ /root/' zz
# 打印第一列包括ro的所有行
awk -F: '$1~/ro/' zz
# 打印第七列不是nologin的所有行中的第一列和第七列
awk -F: '$7!~/nologin$/{print $1,$7}' zz



5.5 逻辑运算与条件判断
- 条件判断
使用==、!=、<=、>=、<、>等符号 - 逻辑运算
使用&&、||符号 &&要求所有条件都为真时才为真,否则为假。||只要有一个条件为真就为真,全为假时才为假。
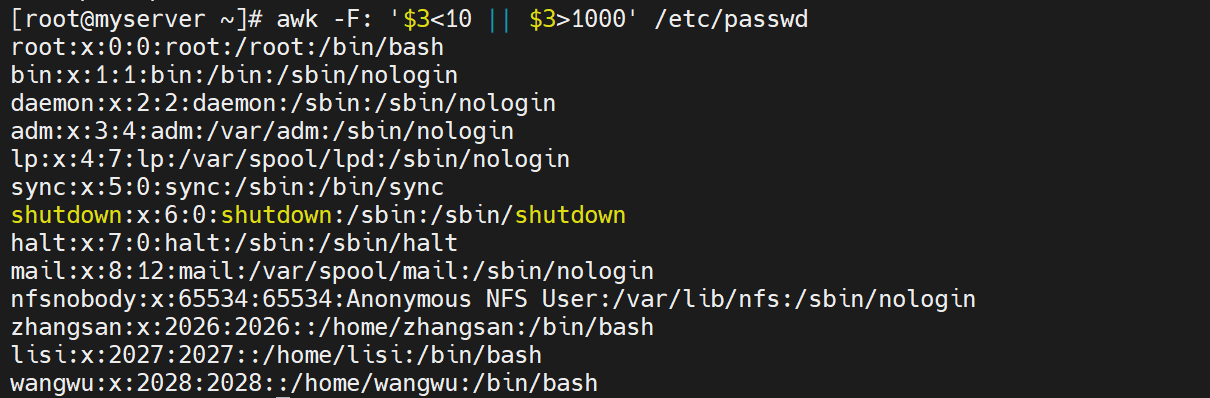
# 打印第三列小于10或大于等于1000的行
awk -F: '$3 < 10 || $3 >= 1000' /etc/passwd
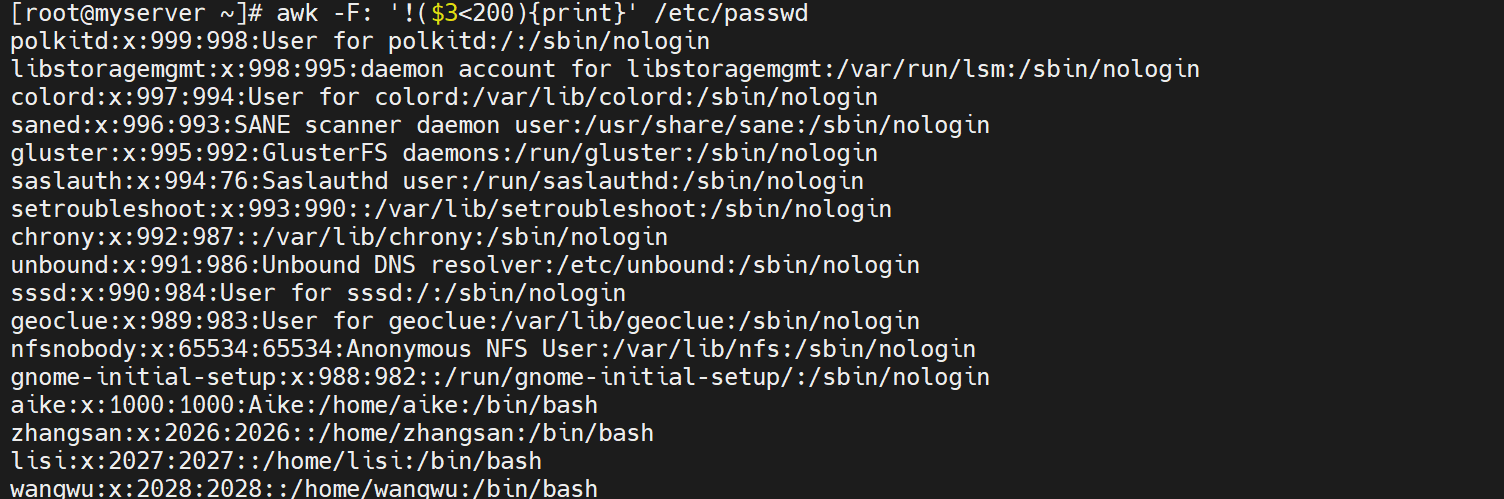
awk -F: '!($3<200){print}' /etc/passwd
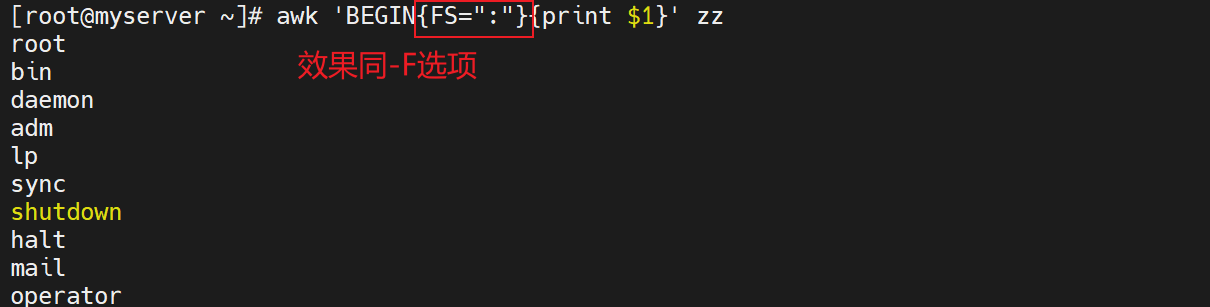
5.6 使用awk的内置变量
awk 'BEGIN{FS=":"}{print $1}' zz
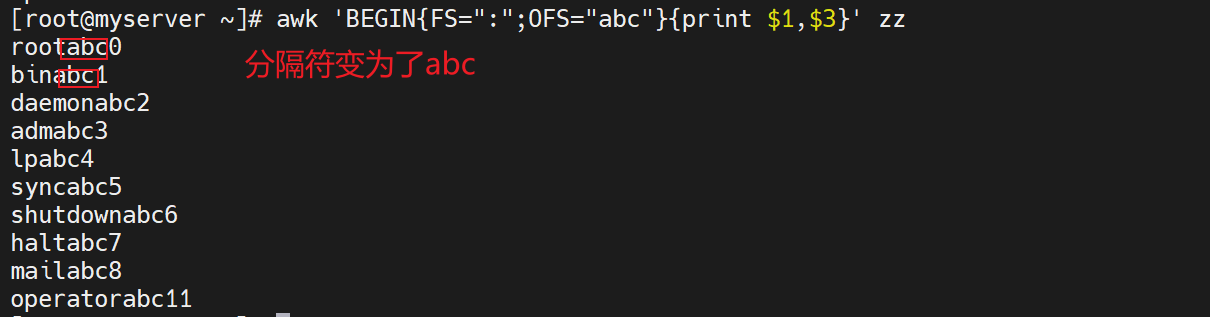
awk 'BEGIN{FS=":";OFS="abc"}{print $1,$3}' zz
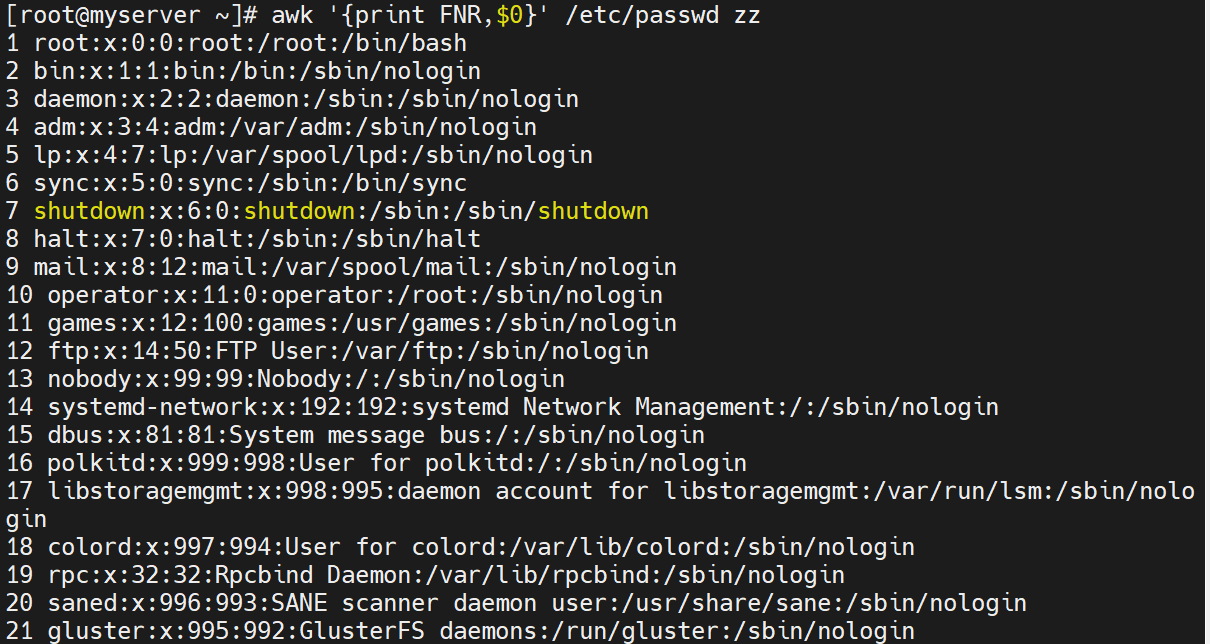
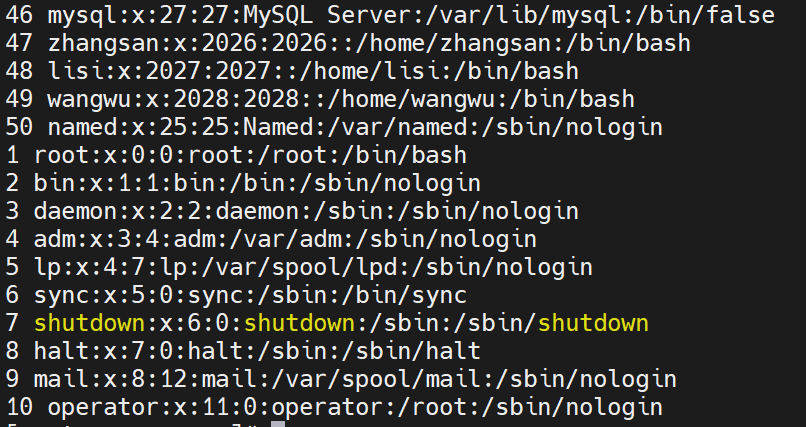
awk '{print FNR,$0}' /etc/passwd zz
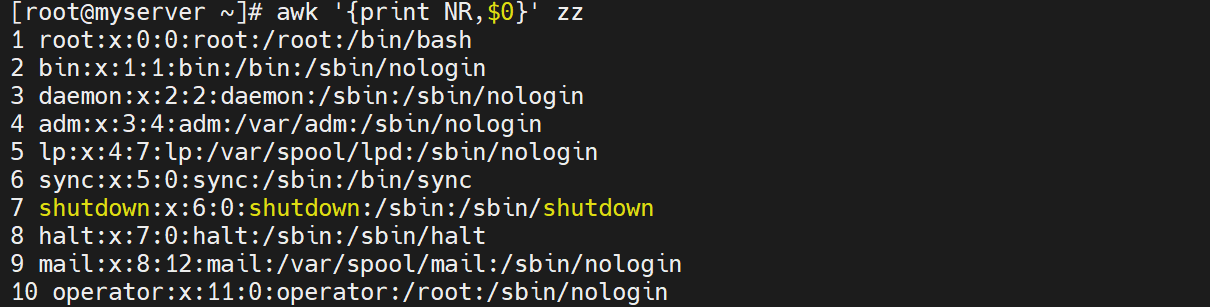
awk '{print NR,$0}' zz
awk 'BEGIN{ORS=" "}{print NR,$0}' zz

awk 'BEGIN{RS=" "}{print NR,$0}' zz
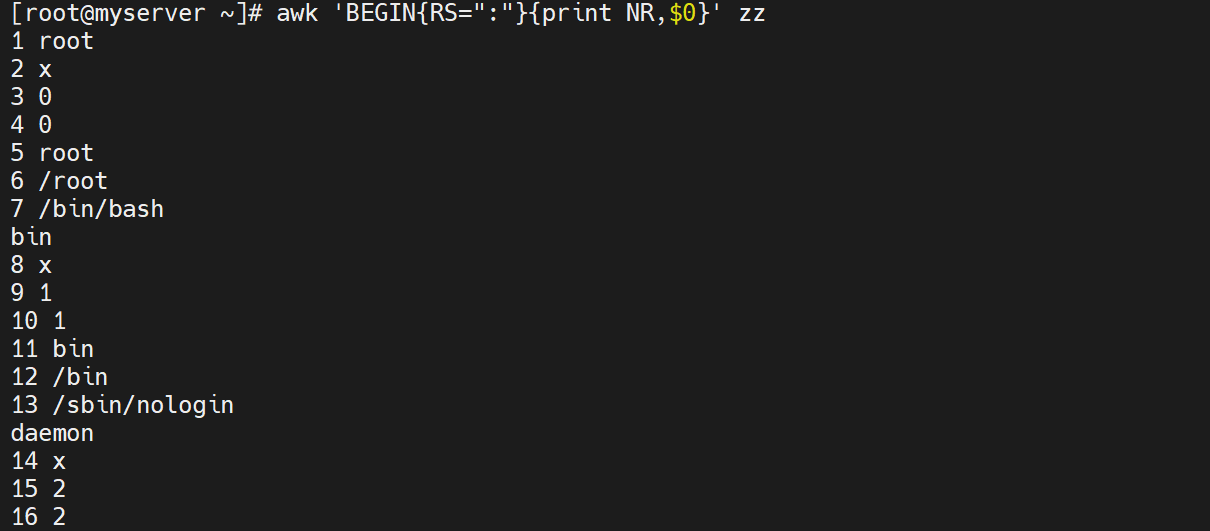
5.7 在awk中使用if进行逻辑控制
在awk也可以使用if、while、for等判断控制方法
# 使用 if 语句判断并打印
awk -F: '{if($3 < 10) print $3; else print $1}' /etc/passwd
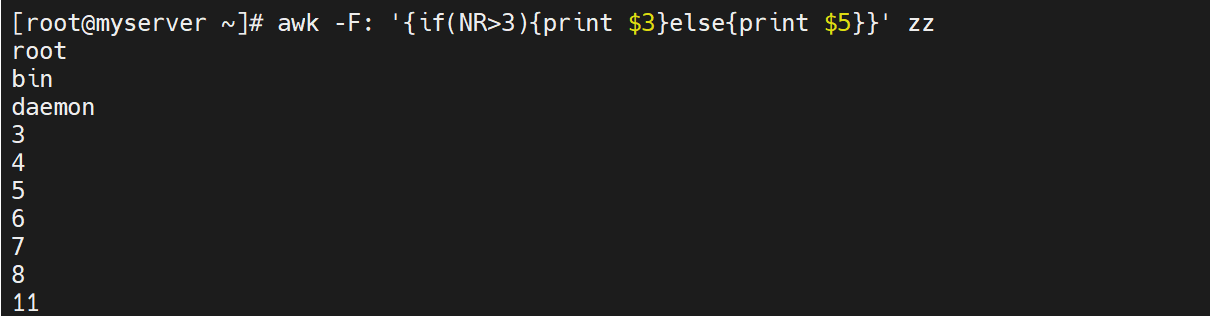
5.8 通过管道、双引号调用shell 命令
# 统计使用 bash 的用户数
awk -F: '/bash$/{print | "wc -l"}' /etc/passwd

#显示查看PATH中的查找路径
echo $PATH | awk 'BEGIN{RS=":"}{print NR,$0}END{print NR}'

5.9 数组与循环
5.9.1 核心概念:AWK 数组是关联数组
AWK 中的数组与大多数编程语言中的数组(如 C 或 Java)有根本性的不同。它们不是通过数字索引(0, 1, 2, …)来访问的,而是通过字符串来索引的。这种数据结构在其他语言中通常被称为字典(Dictionary)、映射(Map) 或哈希表(Hash)。
这意味着你可以使用任何字符串作为数组的“下标”或“键(key)”。
5.9.2 基本语法
-
定义与赋值:无需预先声明大小或类型,直接赋值即可创建,index可以是任意字符串
# 基本赋值 array[index] = value# 示例 array["name"] = "Alice" array[1] = "Number One" # 注意:这里的 1 会被 AWK 理解为字符串 "1" array[var] = 42 # 使用变量 var 的值作为键 -
读取值:通过键名来访问对应的值。
print array["name"] # 输出:Alice print array[1] # 输出:Number One
5.9.3 关键特性与用法
5.9.3.1 遍历数组
这是使用 AWK 数组最常见的操作之一,使用特殊的 for...in 循环。
for (key in array) {print key, array[key] # 打印键和对应的值
}
# 定义数组并遍历
awk 'BEGIN{a['abc']=10; a['456']=20; for(i in a) print i, a[i]}'

重要提示:
for (key in array)循环中,键的遍历顺序是随机的,不保证与赋值的顺序相同。如果需要按特定顺序处理,需要自行对键进行排序。如上图所示,虽然先添加了a["abc"]但实际先打印的是a["456"]
5.9.3.2 检查键是否存在以及检查数组是否为空
使用 in 操作符来检查一个键是否存在于数组中。
if (key in array) {print "键" key "存在于arryay中,它的值为:”, array[key]
} else {print " 键"Key "不存在于arrat"中
}
awk 'BEGIN{a["abc"]=1;a["456"]=2; key="789";if( key in a ){print "键" key "存在于a中,它的值为:",a[key]}else{print "键" key "不存在于a中" }}'

注意:不能通过检查
array["key"]是否为空或 0 来判断,因为它的值可能就是空或 0。
#判断数组为空的方法为判断数组的长度
if (length(array) == 0) {print "数组为空"
} else {print "数组不为空,有", length(array), "个元素"
}
awk 'BEGIN{a["abc"]=1;a["456"]=2;if( length(a) == 0 ){ print "数组为空"}else{print "数组不为空,有", length(a), "个元素" }}'awk 'BEGIN{if( length(a) == 0 ){ print "数组为空"}else{print "数组不为空,有", length(a), "个元素" }}'

5.9.3.3 删除数组元素
使用 delete 语句来移除数组中的一个键值对。
delete array["name"] # 删除键为 "name" 的元素
如果要清空整个数组,可以遍历删除所有元素,或者直接使用 split() 函数重新赋值(一种常见技巧)。
# 方法一:遍历删除(安全)
for (key in array) {delete array[key]
}# 方法二:更快的清空方法
split("", array) # 将一个空字符串分割后存入 array,效果是清空 array
awk 'BEGIN{a["abc"]=1;a["456"]=2;delete a["456"];for(i in a) print i, a[i]}'
awk 'BEGIN{a["abc"]=1;a["456"]=2;split("", a);for(i in a) print i, a[i]}'

5.9.3.4 多维数组(模拟)
AWK 本身不支持真正的多维数组,但它提供了一个非常强大的特性来模拟它:你可以使用 SUBSEP 作为分隔符来组合键名。
内置变量 SUBSEP 默认值是 \034(一个不可打印的字符)。
# 模拟一个 2x2 的多维数组
array["1", "1"] = "Top-Left"
array["1", "2"] = "Top-Right"
array["2", "1"] = "Bottom-Left"
array["2", "2"] = "Bottom-Right"# 上面的赋值在内部等价于:
# array["1" SUBSEP "1"] = "Top-Left"
# array["1\0341"] = "Top-Left"# 访问元素
print array["1", "2"] # 输出:Top-Right# 遍历多维数组
for (key in array) {print "Key:”, key, "Value:”, array[key]
}
# 输出可能是:
# Key: 1□1 Value: Top-Left (□ 代表不可见的 SUBSEP)
# Key: 1□2 Value: Top-Right
# ...
5.9.4 经典实用示例
5.9.4.1 示例 1:统计词频
这是 AWK 数组的“杀手级”应用。
# 输入:text.txt
apple banana
apple orange banana
orange# AWK 命令
awk '
{for (i=1; i<=NF; i++) { # 遍历每一行的每个字段(单词)count[$i]++ # 以单词作为键,出现次数作为值,进行累加}
}
END {for (word in count) {print word, count[word]}
}' text.txt
输出(顺序可能随机):
apple 2
banana 2
orange 2
5.9.4.2 示例 2:处理 /etc/passwd 文件
# 将用户ID($3)作为键,用户名($1)作为值,存入数组
awk -F: '{ users[$3] = $1 } END { for (uid in users) print "UID:”, uid, "-> User:”, users[uid] }' /etc/passwd
5.9.4.3 示例 3:倒置数组(键值互换)
# 假设有一个原始数组 original
original["a"] = 10
original["b"] = 20# 创建倒置数组 inverted
for (key in original) {inverted[original[key]] = key
}# 现在 inverted[10] 的值是 "a",inverted[20] 的值是 "b"
# 统计 IP 出现次数
awk '{ip[$1]++} END{for(i in ip) print ip[i], i}' /var/log/httpd/access_log | sort -nr
5.9.4.3 总结与注意事项
| 特性 | 描述 |
|---|---|
| 类型 | 关联数组(字典/哈希表) |
| 索引 | 字符串(即使是数字也会被转为字符串处理) |
| 顺序 | 遍历顺序随机,不保证插入顺序 |
| 检查存在 | 使用 (key in array) |
| 删除元素 | 使用 delete array[key] |
| 多维数组 | 使用 array[i, j] 语法模拟,内部是 i SUBSEP j |
优势:
- 极其强大和灵活:文本处理、统计、数据关联的利器。
- 使用简单:无需声明,自动增长。
需要注意的点:
- 性能:对于海量数据(例如上百万个键),AWK 数组的性能可能不如专门的编程语言,但对于大多数日常的日志分析、文本处理任务来说绰绰有余。
- 顺序:如果需要按特定顺序输出,必须自己对键进行排序。可以在 AWK 内部实现一个排序算法,或者使用
asort()/asorti()函数(GNU AWK 支持),更常见的做法是将键输出并通过管道传递给系统命令sort。
5.10实战脚本示例
5.10.1 查看内存百分比
通过判断百分比是否到达阈值可以进行预警,如通过发送邮件等方式。
# 查看内存使用百分比
free -m | awk '/Mem:/{print "当前内存已经使用了"int((1-$7/$2)*100)"%"}'
从 Linux 内核 3.14 版本开始,free 命令引入了 available 列。这个值是一个估算,表示在不进行交换(swap)的情况下,可供新应用程序使用的内存大小。它考虑了 free 内存和大部>分可回收的 cache/buffer 内存。
因此,最准确的计算当前内存使用百分比的公式是:
内存使用率 = (1 - (available / total)) * 100%

5.10.1.1 从/proc/meminfo获取参数实现内存百分比计算
比起使用free -h获取内存参数,更推荐从/proc/meminfo中获得更真实的数据。
#!/bin/bash# 从 /proc/meminfo 读取关键值
mem_total=$(grep MemTotal /proc/meminfo | awk '{print $2}')
mem_available=$(grep MemAvailable /proc/meminfo | awk '{print $2}')# 计算使用率百分比
mem_used_percentage=$(echo "scale=2; (1 - $mem_available / $mem_total) * 100" | bc)echo "内存总大小: $(echo "scale=2; $mem_total / 1024" | bc) MB"
echo "可用内存: $(echo "scale=2; $mem_available / 1024" | bc) MB"
echo "当前内存使用率: $mem_used_percentage%"
为什么推荐 /proc/meminfo?
它是 free、top 等命令的数据来源,是“真相之源”。
输出格式稳定,不会因 free 命令版本不同而改变字段顺序。
MemAvailable 是内核直接提供的估算值,比用 (free + buff/cache) 的旧方法更智能、更准确。
也可以将这个变成脚本中的函数,提高复用性。
#!/bin/bash
mem_total=$(awk '/MemTotal/{print $2}' /proc/meminfo)
mem_available=$(awk '/MemAvailable/{print $2}' /proc/meminfo)getMem(){local mem_per=$(echo "scale=2;(1 - $mem_available / $mem_total) * 100" | bc)local mem_tatol_mb=$(echo "scale=2;$mem_total / 1024" | bc)local mem_ava_mb=$(echo "scale=2;$mem_available / 1024" | bc)echo "$mem_per $mem_tatol_mb $mem_ava_mb"
}
通过调用函数获取到内存的三个数值. ./mem_stats.sh | read mem_usage mem_total mem_ava
5.10.2 同一ip多次失败访问预警
#!/bin/bash
log="/var/log/secure"
result=$(awk '/Failed password/{ip[$11]++} END{for(i in ip) print i","ip[i]}' $log)for line in $result; doip=$(echo $line | cut -d, -f1)count=$(echo $line | cut -d, -f2)if [ $count -ge 3 ]; thenecho "警告!$ip 访问本机失败了 $count 次,请速处理!"fi
done
/var/log/secure是登录失败日志
5.10.3 统计在线用户
awk 'BEGIN {n=0 ; while ("w" | getline) n++ ; {print n-2}}'
#调用w命令,并用来统计在线用户数

5.10.4 查看cpu使用率
cpu_us=$(top -bn1 | awk '/Cpu/{print $2}')
cpu_sy=$(top -bn1 | awk '/Cpu/{print $4}')
cpu_sum=$(echo "$cpu_us+$cpu_sy" | bc)
echo $cpu_sum

总结
AWK 是一款功能强大的文本处理工具,具备以下特点:
- 灵活性强:支持字段分隔、模式匹配、变量操作、数学运算和流程控制。
- 适用场景广:可用于日志分析、数据提取、报表生成等。
- 与 Shell 结合紧密:可通过管道调用其他命令,增强处理能力。
与 grep 和 sed 相比,AWK 更擅长对结构化文本进行复杂处理和格式化输出。掌握 AWK 的使用,能极大提升在 Linux 环境下的文本处理效率。
最后,希望大家多多实践,夯实基础,聚沙成塔,与君共勉之!