C++基础——模板进阶
ʕ • ᴥ • ʔ
づ♡ど
🎉 欢迎点赞支持🎉

个人主页:励志不掉头发的内向程序员;
专栏主页:C++语言;
文章目录
前言
一、非类型模板参数
二、模板的特化
2.1、概念
2.2、函数模板特化
2.3、类模板特化
(1)、全特化
(2)、偏特化
三、模板分离编译
3.1、什么是分离编译
3.2、模板的分离编译
3.3、解决方法
四、模板总结
总结
前言
我们之前就学习过了我们的模板初阶的内容,帮助我们开启了我们泛型之旅,随着我们的学习了这么多的容器,以及它们的模拟实现,我们已经有足够的能力来去尝试学习它的进阶了。大家赶紧带上小板凳,一起来学习吧。

一、非类型模板参数
模板参数分为类类型模板参数与非类型模板参数。
类型形参即:出现在模板参数列表中,跟在 class 或者 typename 之类的参数类型名称。
非类型形参:就是用一个常量作为类(函数)模板的一个参数,在类(函数)模板中可将该参数当成常量来使用。
// 定义一个模板类型的静态数组
template<class T, size_t N = 10>
class array
{
public:T& operator[](size_t index) { return _array[index]; }const T& operator[](size_t index)const { return _array[index]; }size_t size()const { return _size; }bool empty()const { return 0 == _size; }
private:T _array[N];size_t _size;
};
我们 size_t N = 10 便是我们非类型模板参数。当然,它也可以独立存在,而非跟着类类型模板参数一起存在。
template <size_t N>
class Stack
{
private:int _a[N];int _top;
};当然,我们之前也有一个类似这样子的功能,那就是宏。非类型模板参数与宏相比,宏是写死的,但是非类型模板参数是可以根据用户的不同需求去传不同值而改变的。
int main()
{// 传 5 个数据Stack<5> s1;// 传 10 个数据Stack<10> s2;return 0;
}它的底层适合我们模板是一样的,本质就是编译器替我们生成了两个类去实现我们的需求。
当然我们非类型模板参数的限制也是相当多的:
- 浮点数、类对象以及字符串是不允许作为非类型模板参数的(换句话说就是只用于整型)。而到 C++20 后才多支持了一个 double。
- 非类型的模板参数必须在编译期就能确认结果。

其实也不难理解,非类型模板参数的主要作用就是用来定义一些大小、长度等,支持其他的非类型模板参数其实用处也不是很大。
我们非类型模板参数也是可以给缺省值的。
template <size_t N = 10>
class Stack
{
private:int _a[N];int _top;
};
但是如果我们想要调用缺省参数,有的人可能认为类型就是直接写个类型名即可。
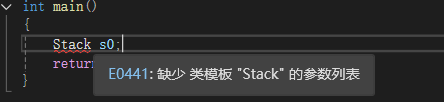
但其实不然,哪怕我们没有任何参数在模板中,我们也得把 < > 给带上,所以正确的写法应该是。
int main()
{Stack<> s0;return 0;
}其实我们不加 < > 的写法在 C++20 后也是可以的。
二、模板的特化
2.1、概念
通常情况下,使用模板可以实现一些与类型无关的代码,但对于一些特殊类型的可能会得到一些错误的结果,需要特殊处理。
// 函数模板 -- 参数匹配
template<class T>
bool Less(T left, T right)
{return left < right;
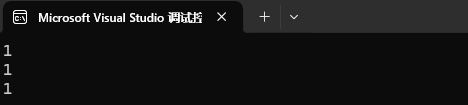
}int main()
{cout << Less(1, 2) << endl; // 可以比较,结果正确Date d1(2022, 7, 7);Date d2(2022, 7, 8);cout << Less(d1, d2) << endl; // 可以比较,结果正确Date* p1 = &d1;Date* p2 = &d2;cout << Less(p1, p2) << endl; // 可以比较,结果错误return 0;
}我们可以看到我们前面两个都是给仿函数传递正确类型后就能正确比较。但是如果像第三个我们想要对它们指向的类型比较,编译器就不能很好的理解,从而错误的判断成我们是想进行指针比较。所以结果就是错误的。
一会儿是 true。
一会儿是 false。
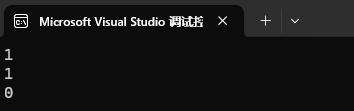
此时就应该使用模板的特化来控制住我们的结果。
2.2、函数模板特化
函数模板的特化步骤:
- 必须要先有一个基础的函数模板。
- 关键字 template 后面接一对空的尖括号 <>。
- 函数名后跟一对尖括号,尖括号中指定需要特化的类型。
- 函数形参表:必须要和模板函数的基础参数类型完全相同,如果不同编译器可能会报一些奇怪的错误。
// 函数模板 -- 参数匹配
template<class T>
bool Less(T left, T right)
{return left < right;
}// 对Less函数模板进行特化
template<>
bool Less<Date*>(Date* left, Date* right)
{return *left < *right;
}此时就有了特化,我们对 Data* 进行特殊处理,当编译器碰到了 Date* 类型的比较,就会去走特化版本,而其他类型还是走我们原本的函数模板。
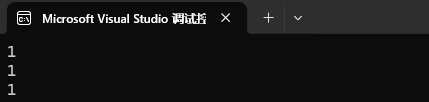
此时结果就不会发生改变了,一直是正确的结果了。
当然,在这里我并不建议写函数模板,因为函数模板其实用的不好还是蛮恶心的。
正常来说我们一般写函数模板都应该是这么写的。
template<class T>
bool Less(const T& left, const T& right)
{return left < right;
}但是当我们这么写的时候,我们刚才写的函数模板就不支持了。有人可能会动脑筋觉得把我们的特化也按照一样的方式改改就可以了。
template<>
bool Less<Date*>(const Date*& left, const Date*& right)
{return *left < *right;
}
实际上这样还是会报错,这个原因是因为 const,我们原来函数模板的 const 修饰的是 left。而我们特化出来的 const 是在 * 前,所以修饰的是 *left。所以正确写法其实是。
template<>
bool Less<Date*>(Date* const & left, Date* const & right)
{return *left < *right;
}看起来就很恶心,我们其实有一个十分简单的办法,那就是函数重载一个普通函数即可。
bool Less(Date* left, Date* right)
{return *left < *right;
}我们之前也说过,我们的编译器非常懒,所以当它发现了有完全匹配的类型就不会再去生成我们的模板了,所以当我们自己写一个普通函数,就可以避免上面的问题。当然,普通函数和模板函数相比,编译器优先匹配普通的。普通函数和特化函数相比也是如此。
2.3、类模板特化
(1)、全特化
全特化即是将模板参数列表中所有的参数都确定化。
// 类模板 -- 参数匹配
template <class T1, class T2>
class Data
{
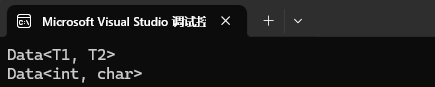
public:Data() { cout << "Data<T1, T2>" << endl; }
private:T1 _d1;T2 _d2;
};// 对Data类模板进行全特化
template <>
class Data <int, char>
{
public:Data() { cout << "Data<int, char>" << endl; }
};类的特化不要忘记 template <>,还有它要特化的类型和函数一样是写在类名定义的后面的。
int main()
{Data<int, int> d1;Data<int, char> d2;return 0;
}我们全特化得每一个模板参数都匹配上我们特化的参数类型才会走特化的类。
(2)、偏特化
偏特化是指任何针对模板参数进一步进行条件限制设计的特化版本。
// 类模板 -- 参数匹配
template <class T1, class T2>
class Data
{
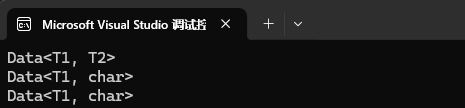
public:Data() { cout << "Data<T1, T2>" << endl; }
private:T1 _d1;T2 _d2;
};// 对Data类模板进行偏特化
template <class T1>
class Data <T1, char>
{
public:Data() { cout << "Data<T1, char>" << endl; }
};int main()
{Data<int, int> d1;Data<double, char> d2;Data<char, char> d3;return 0;
}与全特化不同,偏特化只要满足我们指定的那个参数的类型,其他的参数是什么类型都无所谓,编译器就会去走偏特化。
当然,在假如有个类调用,既满足全特化,又满足偏特化,编译器会调用谁呢?
int main()
{Data<int, char> d0;return 0;
}这个调用既满足全特化的 <int, char>,有满足偏特化的 <T1, char>。

很显然,既然能够不用费力,那肯定是怎么轻松怎么来啦。编译器会选择全特化。
我们的偏特化除了上面那样,还有一种玩法。
template <class T1, class T2>
class Data <T1*, T2*>
{
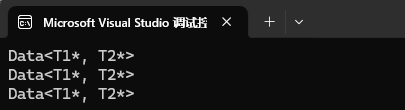
public:Data() { cout << "Data<T1*, T2*>" << endl; }
};这个偏特化比较特殊,就是如果传递的类型是指针就会调用这个特化。
int main()
{Data<int*, char*> d1;Data<double*, char*> d2;Data<float*, long*> d3;return 0;
}是什么类型都不重要,只要是指针就会走这个特化。
我们偏特化成引用也是可以的。
我们函数模板的特化有恶心的地方,那我们类模板特化肯定也是少不了的。
template <class T1, class T2>
class Data <T1*, T2*>
{
public:Data() {cout << "Data<T1*, T2*>" << endl;T1 x;T2 y;// typeid() 是用来打印变量类型的函数cout << typeid(x).name() << " " << typeid(y).name() << endl;}
};我们的指针变量在传递过去时,我们的变量类型其实是会发生改变的。
int main()
{Data<int*, int*> d1;Data<int**, int**> d2;return 0;
}
我们传递过去的一级指针会变成原类型,而传递二级指针会变成一级指针。我们的引用也是一样的,传递到偏特化时,我们的模板参数就变成了原本类型。
template <class T1, class T2>
class Data <T1&, T2*>
{
public:Data() {cout << "Data<T1&, T2*>" << endl;T1 x;T2 y;// typeid() 是用来打印变量类型的函数cout << typeid(x).name() << " " << typeid(y).name() << endl;}
};
int main()
{Data<int&, int*> d2;return 0;
}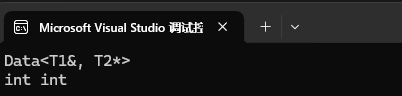
所以当我们在特化中要使用到这些类型时,要记住它已经不是我们想要的那个类型了。它这里这样设计的目的就是为了让你既能使用引用和指针,也可以使用原来的类型。
三、模板分离编译
3.1、什么是分离编译
一个程序(项目)由若干个源文件共同实现,而每个源文件单独编译生成目标文件,最后将所有目标文件链接起来形成单一的可执行文件的过程称为分离编译模式。
3.2、模板的分离编译
我们最基础的项目一般至少都会有 3 个文件。
我们在不同的文件中实现不同功能的代码。
// Func.h
#include <iostream>
using namespace std;template<class T>
T Add(const T& left, const T& right);void func(const int& left, const int& right);// Func.cpp
#include "Func.h"template<class T>
T Add(const T& left, const T& right)
{cout << "T Add(const T& left, const T& right)" << endl;return left + right;
}void func(const int& left, const int& right)
{cout << "void func(const int& left, const int& right)" << endl;
}// test.cpp
#include "Func.h"int main()
{Add(1, 2);Add(1.0, 2.0);return 0;
}我们在运行上面的代码时会发生一个链接错误。

这个错误只有模板会出现,普通函数不会出现这个问题。
int main()
{func(1, 2);return 0;
}
编译分为好几个过程:
- 首先最重要的事情就是预处理,再次时编译器进行头文件展开/宏替换/条件编译/去掉注释。此时 .h 后缀的文件给展开了,.cpp 后缀的文件生成了 Func.i 和 test.i 文件。
- 第二步就会进行编译,此时我们编译器检查语法,生成汇编代码,不合规的语法就会报错。此时文件就从 Func.i/test.i 变成 Func.s/test.s 了。
- 第三步就是汇编,这一步的核心就是把我们汇编代码转换成二进制机器码。此时文件就从 Func.s/test.s 变成 Func.o/test.o 了。
- 我们刚才的错误出现在最后一步的链接,链接的主要作用是把目标文件合并在一起,生成可执行程序,并且把需要的函数地址链接上,生成 xxx.exe 文件。
我们在编译时由于模板和普通函数都有声明,所以我们编译器就会让它们通过。但是运行时却发现我们的模板函数找不到了,而普通函数是可以正常找到的,所以模板函数就会报错。我们普通函数在编译的时候就编译成了一串指令,等到运行时找到这串之类即可运行,但是我们模板却不行,因为它没有实例化,没有实例化就不会生成对应的指令。

3.3、解决方法
我们知道了是因为没有实例化导致我们编译时无法形成指令而链接时失败,所以我们只要显示实例化就可以解决。
// Func.cpp
#include "Func.h"template<class T>
T Add(const T& left, const T& right)
{cout << "T Add(const T& left, const T& right)" << endl;return left + right;
}void func(const int& left, const int& right)
{cout << "void func(const int& left, const int& right)" << endl;
}// 显示实例化,和特化进行区分,没有 <>
template
int Add(const int& left, const int& right);template
double Add(const double& left, const double& right);// test.cpp
#include "Func.h"int main()
{Add(1, 2);Add(1.0, 2.0);return 0;
}
但是这样做非常挫,相当于没写模板。
所以我们理想的解决办法就是直接在 .h 文件中定义
// Func.h
#include <iostream>
using namespace std;template<class T>
T Add(const T& left, const T& right)
{cout << "T Add(const T& left, const T& right)" << endl;return left + right;
}

四、模板总结
优点:
- 模板复用了代码,节省资源,更快的迭代开发,C++的标准模板库(STL)因此而产生。
- 增强了代码的灵活性。
缺点:
- 模板会导致代码膨胀问题,也会导致编译时间变长。
- 出现模板编译错误时,错误信息非常凌乱,不易定位错误。
总结
以上便是我们模板的全部内容,我们现在应该对模板的领悟又上升了一个台阶了。同时我们应该也能够对我们编译器的行为有所了解了。我们下一章节将讲解继承,知识点还是蛮多的,大家加油吸收,我们下期再见。
🎇坚持到这里已经很厉害啦,辛苦啦🎇
ʕ • ᴥ • ʔ
づ♡ど
