MySQL复制技术的发展历程

在互联网应用不断发展的二十多年里,MySQL 一直是最广泛使用的开源关系型数据库之一。它凭借开源、轻量、灵活的优势,支撑了无数网站、移动应用和企业系统。支撑 MySQL 长期发展的关键之一,就是 复制(Replication)技术。
复制机制不仅用于 读写分离,还广泛应用于 高可用、容灾备份、分布式架构。本文将详细回顾 MySQL 复制技术的发展历程,结合实际生产应用分析其意义,并对安全性进行客观星级评比。
一、单机时代与最初的主从复制(基于语句的复制)
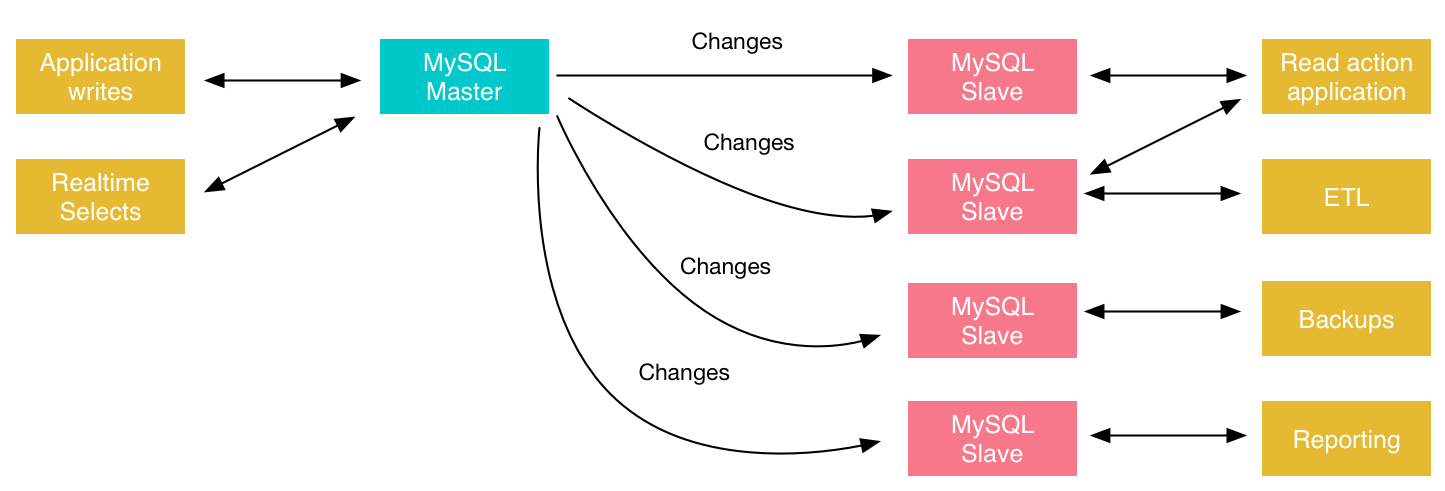
技术背景
在 2000 年前后,互联网业务还处于起步阶段,大多数系统访问量有限,一台 MySQL 单机即可满足。但随着门户网站、早期电商的兴起,读请求和写请求的压力不断上升,单机架构逐渐捉襟见肘。
技术实现
MySQL 在3.23(2001 年)首次引入了 主从复制(Master-Slave Replication),工作流程如下:
主库将所有写入操作记录到 二进制日志(binlog)。
从库的 IO 线程从主库拉取 binlog,写入 中继日志(relay log)。
从库的 SQL 线程顺序执行 relay log 中的语句,重放主库操作。
默认复制模式为 基于语句的复制(Statement-Based Replication, SBR),即直接把 SQL 语句写入 binlog 并在从库执行。
应用场景
读多写少的 新闻门户、社区论坛:读请求走从库,写请求走主库。
早期电商的 商品浏览和 库存更新场景:大多数读流量分摊到多个从库。
意义
以极低的成本实现了 水平扩展(增加从库即可分担读压力)。
奠定了互联网应用架构中 读写分离 的雏形。
不足
对非确定性语句(如
NOW()、RAND())存在 重放歧义,导致主从数据不一致。主从延迟在高并发场景下仍可能积累。
二、行级复制(Row-Based Replication, RBR)
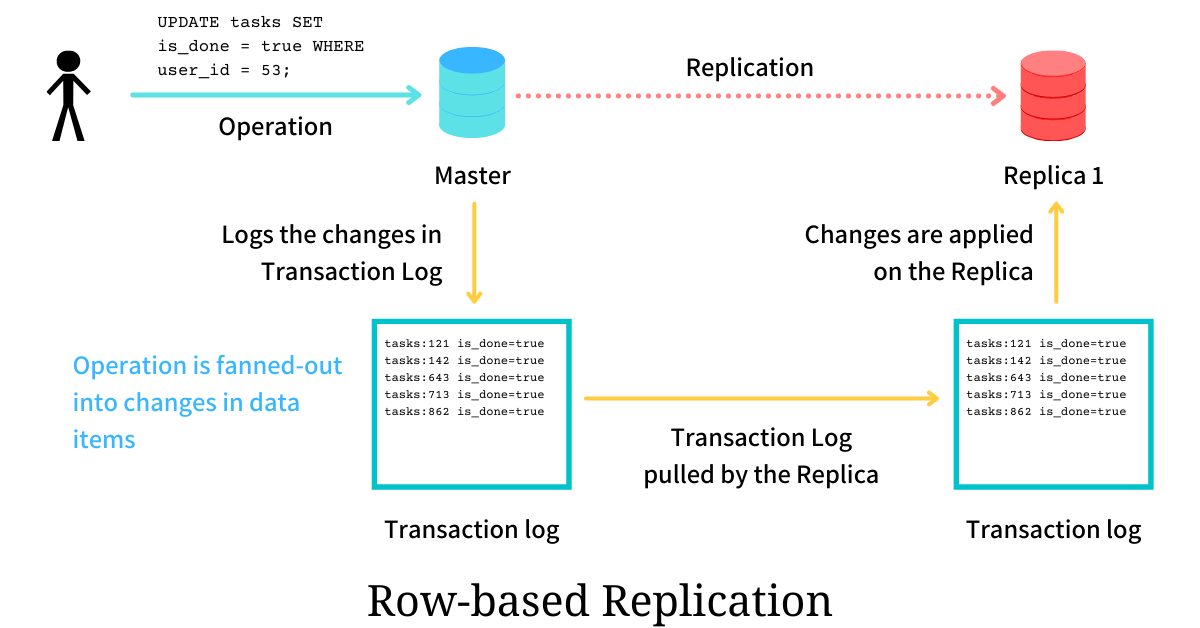
技术背景
随着业务复杂化,SBR 的数据一致性问题暴露越来越多,尤其在金融、电商支付等场景下,任何数据不一致都可能导致严重事故。
技术实现
MySQL 5.1(2008 年)**引入 RBR,binlog 不再记录 SQL,而是记录 行数据的变更结果:
SBR:记录语句
UPDATE user SET balance=balance+100 WHERE id=1;RBR:记录变更行
id=1,旧值=500,新值=600
应用场景
支付、金融:账户余额必须绝对一致。
库存管理:电商大促期间,库存扣减的准确性直接影响发货与售后。
意义
有效解决了 SBR 的一致性问题,实现了 强一致复制。
支持更复杂的语句,业务对数据准确性更有保障。
不足
binlog 体积更大,存储与传输开销增加。
对大批量更新,RBR 性能可能显著下降。
三、混合复制(Mixed-Based Replication, MBR)
技术背景
单纯使用 RBR,日志量过大,性能不佳;单纯使用 SBR,又有一致性隐患。于是 MySQL 在 5.1 中同时推出 混合复制模式(MBR)。
技术实现
普通的确定性语句 → 使用 SBR,提高性能。
非确定性、存在歧义的语句 → 使用 RBR,保证一致性。
应用场景
电商网站:商品浏览、大批量商品更新场景用 SBR;库存扣减、订单支付用 RBR。
内容分发平台:大规模数据同步时更灵活。
意义
在 效率与一致性之间找到平衡,适合大部分互联网中型业务。
不足
自动选择机制并不总是“最优”,有时仍需人工配置。
四、并行复制(Parallel Replication)
技术背景
随着互联网进入 移动互联网和大数据时代(2010s),主库 QPS 可达数万,但从库单线程回放却跟不上,导致 主从延迟数十秒甚至数分钟,无法满足实时性需求。
技术实现
5.6(2013):库级并行复制,不同数据库的事务可并行执行。
5.7(2015):基于组提交的并行复制,同一库中不同事务可并行。
8.0(2018):基于 Write Set,利用事务写集合判断是否冲突,实现接近主库的并行度。
应用场景
电商大促:秒杀期间主库高并发写入,从库延迟必须缩小到毫秒级,才能快速切换。
金融系统:实时交易要求从库与主库几乎同步。
意义
极大缩短了主从延迟,使 高可用架构真正可用。
提升了 容灾切换 的可靠性。
不足
并行度受限于事务冲突,如果业务逻辑高度集中,效果有限。
五、全局事务 ID(GTID)与自动故障转移
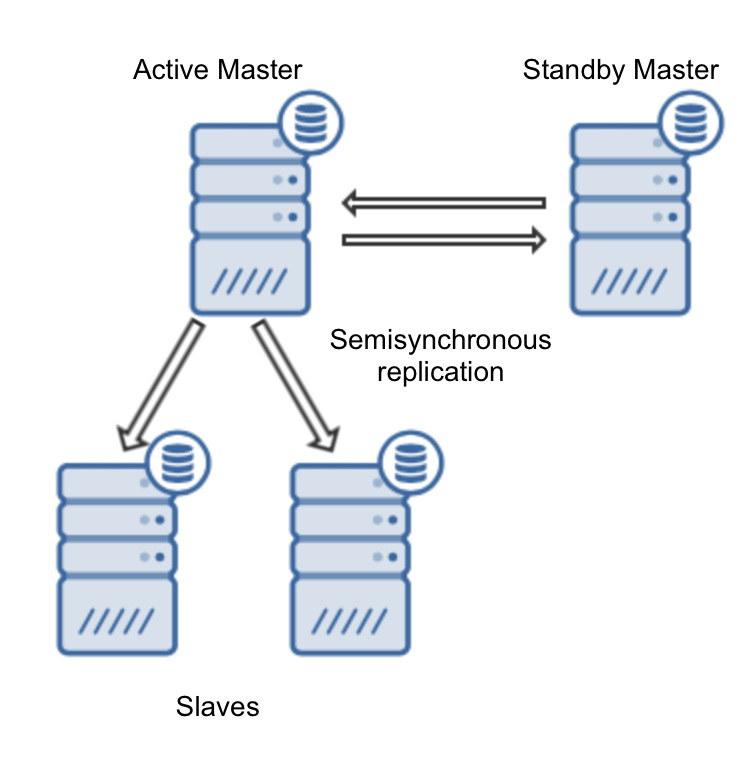
技术背景
在早期 MySQL 架构中,主从切换必须人工定位 binlog 文件名和位置,繁琐且容易出错,严重时会导致数据丢失。
技术实现
MySQL 5.6 引入 GTID(Global Transaction Identifier),每个事务生成唯一标识。
主从切换时,无需关心 binlog 文件位置,只需比对 GTID 集合。
自动化工具(如 MHA、Orchestrator)可据此快速完成切换。
应用场景
高可用架构:互联网金融、电商平台需要快速主从切换。
云数据库:自动化容灾切换的核心机制。
意义
显著降低了人工失误风险。
推动了 MySQL 自动化高可用 的发展。
不足
本身不提高一致性,仍依赖复制模式(SBR/RBR)。
六、组复制与 InnoDB Cluster
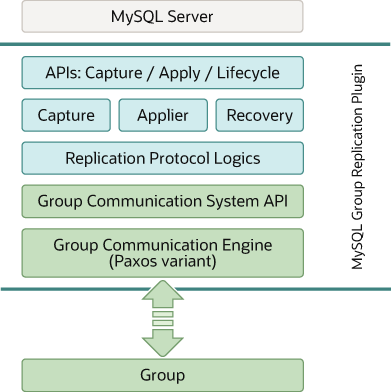
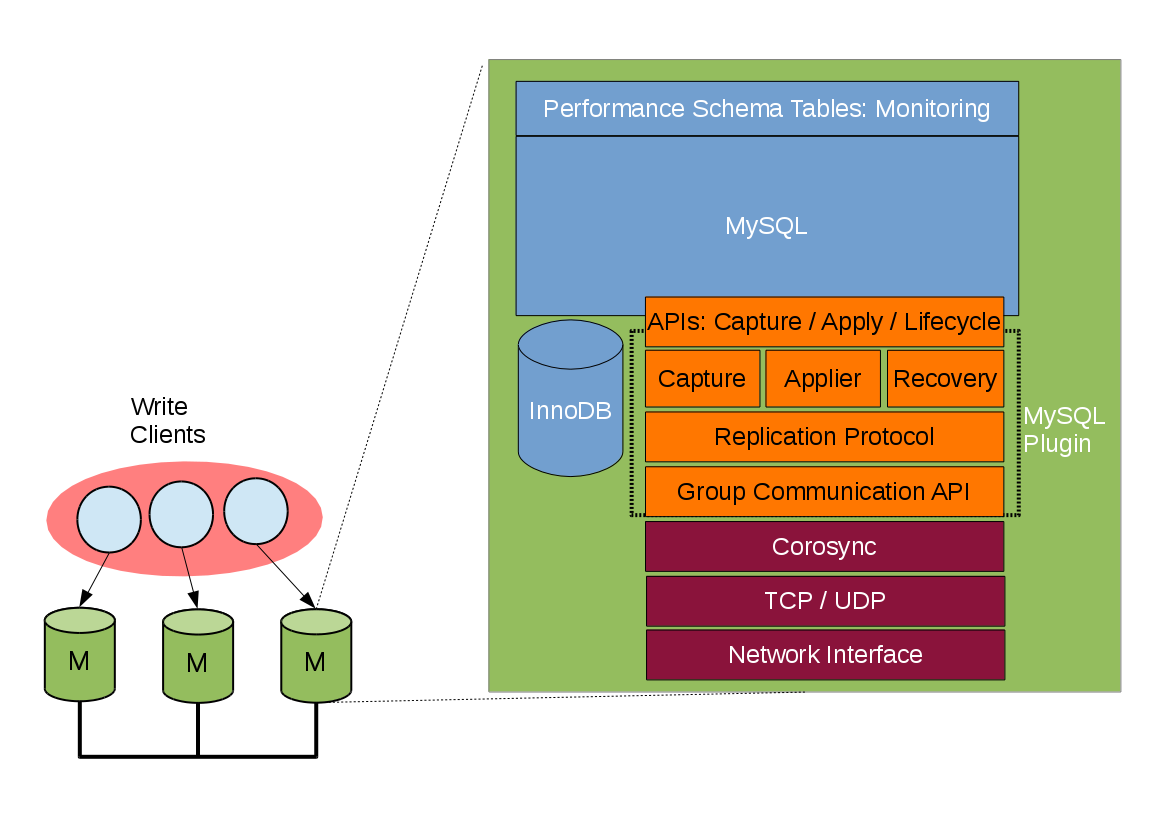
技术背景
进入 云计算时代(2016+),企业对数据库的需求已不只是扩展性,还需要 分布式一致性 和 自动高可用。
技术实现
组复制(Group Replication, GR):基于 Paxos/Raft 协议,事务提交需获得多数节点确认。
InnoDB Cluster:官方高可用集群方案,集成组复制、MySQL Router、Shell 管理工具。
应用场景
金融支付系统:保障交易的强一致性和自动容灾。
电商大促:保证在节点宕机时快速恢复,业务不中断。
IoT/实时采集:海量并发写入场景下仍保证一致性。
意义
标志着 MySQL 从 单机复制 走向 分布式一致性集群。
为传统企业和云厂商提供了官方级高可用解决方案。
不足
架构和管理复杂度显著上升。
吞吐量相比异步复制有所牺牲。
七、安全性评比
不同复制技术在数据一致性、容错能力、防丢失风险上有明显差异:
| 技术阶段 | 安全性星级 | 评语 |
|---|---|---|
| 语句复制(SBR) | ★★☆☆☆ | 高效,但易出现不一致,适合安全性要求低的读写分离。 |
| 行级复制(RBR) | ★★★★☆ | 强一致性,金融/支付首选,但日志开销大。 |
| 混合复制(MBR) | ★★★☆☆ | 折中方案,整体安全性中等。 |
| 并行复制 | ★★★★☆ | 缩短延迟,降低风险,但仍依赖底层复制模式。 |
| GTID 复制 | ★★★★☆ | 简化主从切换,减少运维错误,提升安全性。 |
| 组复制 & InnoDB Cluster | ★★★★★ | 内置一致性协议,支持冲突检测与自动选主,是最高等级的安全方案。 |
八、总结
2000s:SBR → RBR —— 从低成本扩展到数据一致性保障
2010s:并行复制 + GTID —— 缓解延迟瓶颈,提升高可用性
2020s:组复制/InnoDB Cluster —— 迈向分布式强一致与自动容灾
可以说,MySQL 复制技术的发展史,就是互联网架构在 扩展性 — 一致性 — 高可用 三个维度不断进化的缩影。