C++学习记录(6)string部分操作的模拟实现
前言
string部分操作的模拟实现并不是说觉得自己无所不能,可以自己创造一个string类代替库里面的string类,至少目前连C++基本语法都没有学完肯定是没有办法的。
模拟实现的重点在于运用前面我们讲的C++入门、类与对象、内存管理等内容辅助实现string类,并且通过模拟实现加深对string类的理解,使使用的时候更加得心应手。
一、string类构造和析构的模拟实现
1.string类的成员变量
创建一个类首先就得做到明确它的对象,我们在使用string类的时候反复说过,底层可以当作一个存放char类型的顺序表而管理。
所以string类的成员变量:
namespace xx
{class string{private:char* _str;size_t _size;size_t _capacity;};
}标准的顺序表参数,一个指针,一个有效数据个数,一个容量。
另外,我们平常自己简单写测试代码的时候经常性的做出using namespace std;的行为,这种行为早已说过,其实是不安全的,毕竟命名空间的存在就是为了防止冲突,所以为了防范,我们自己写一个命名空间包起来,这样就不会与标准库里的string类冲突。
C++入门大讲特讲命名空间还是有点用的。
2.string类的构造函数
有了成员变量,构造析构就该上了。
构造函数我们再三强调,是用来给成员变量初始化的,根据我们顺序表时期的经验,相信这种构造很容易就写出来了:
![]()
![]()
![]()
我们模拟实现这三种构造函数。
①默认构造函数
默认构造就好像我们以前写的Init方法一样:
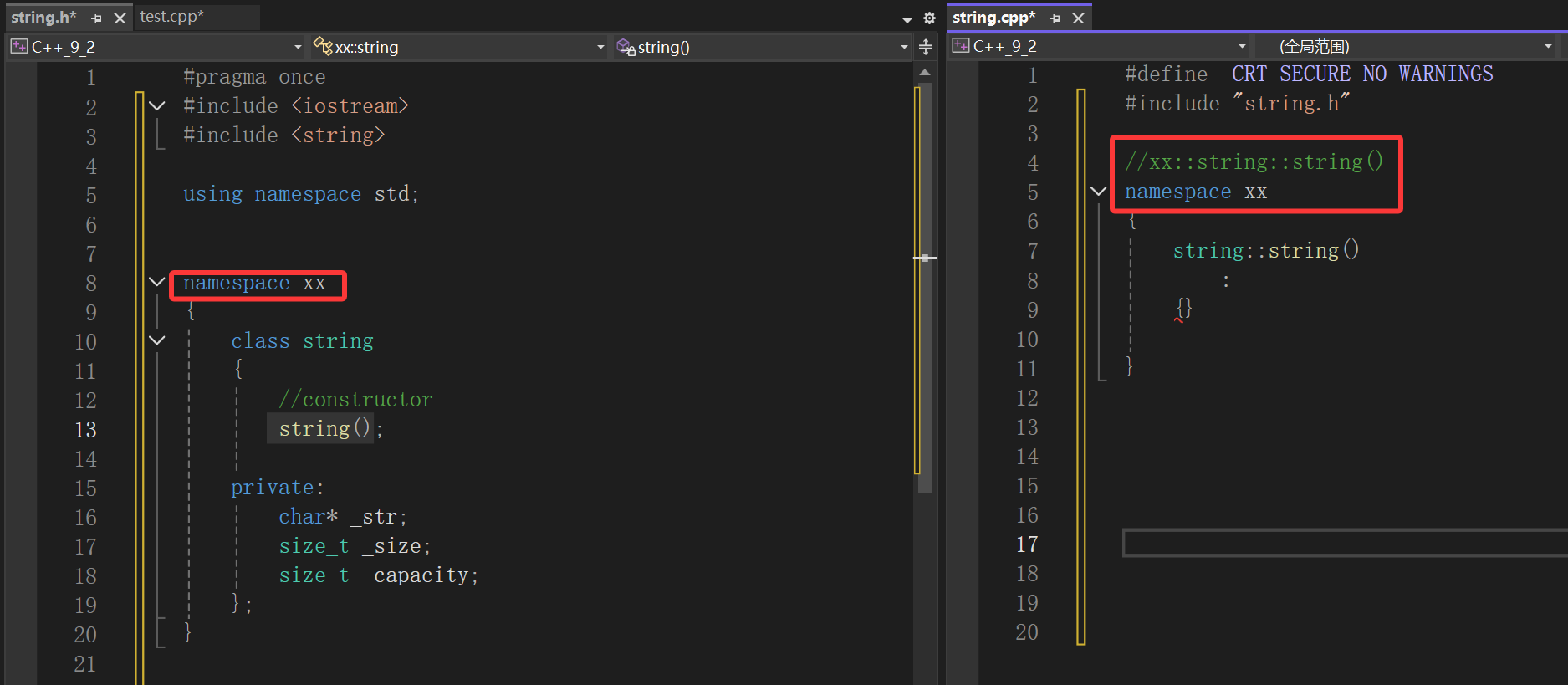
模拟实现还是分头文件和实现文件,也就是.h和.cpp,而跨文件由于命名空间包裹,即使包了头文件其实还是穿不透命名空间那层膜,所以要不然指明命名空间域再指明类域,要不然就像我下面写的一样,再用同名命名空间包裹起来,这里用到的是编译器会将不同文件中同名的命名空间认为是同一个命名空间,不会冲突。
这样以后再写只用注明类域就行了。
这段代码暂时没有啥疑问。
c_str
继续讲解之前写一个c_str函数,因为如果我们想完成打印操作,那么我们需要<<运算符重载,目前我们暂时不讲这个重载,所以如果想打印那就以c-string的方式来打印:
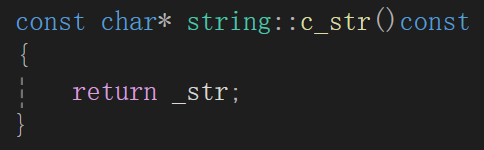
c_str这个函数我们如果想要弄成c语言字符串形式,那么就返回const char*,因为首先C的常量串就是const char*形式的,再来,我们总不希望这样一个函数返回的值最终可以在类外部直接修改_str或_str指向的值。
函数名后的const是用来修饰this指针的,我们必须加const修饰就是防止这种直接调内部成员变量的函数对this指向的_str、_size、_capacity进行修改,所以加上const更加保险。
另外,如果我们加上const那我们不仅可以用非常量对象调用此函数也可以用常量对象调用此函数。
有了c_str以后我们就可以打印string对象(即转出来个const char*打印)。
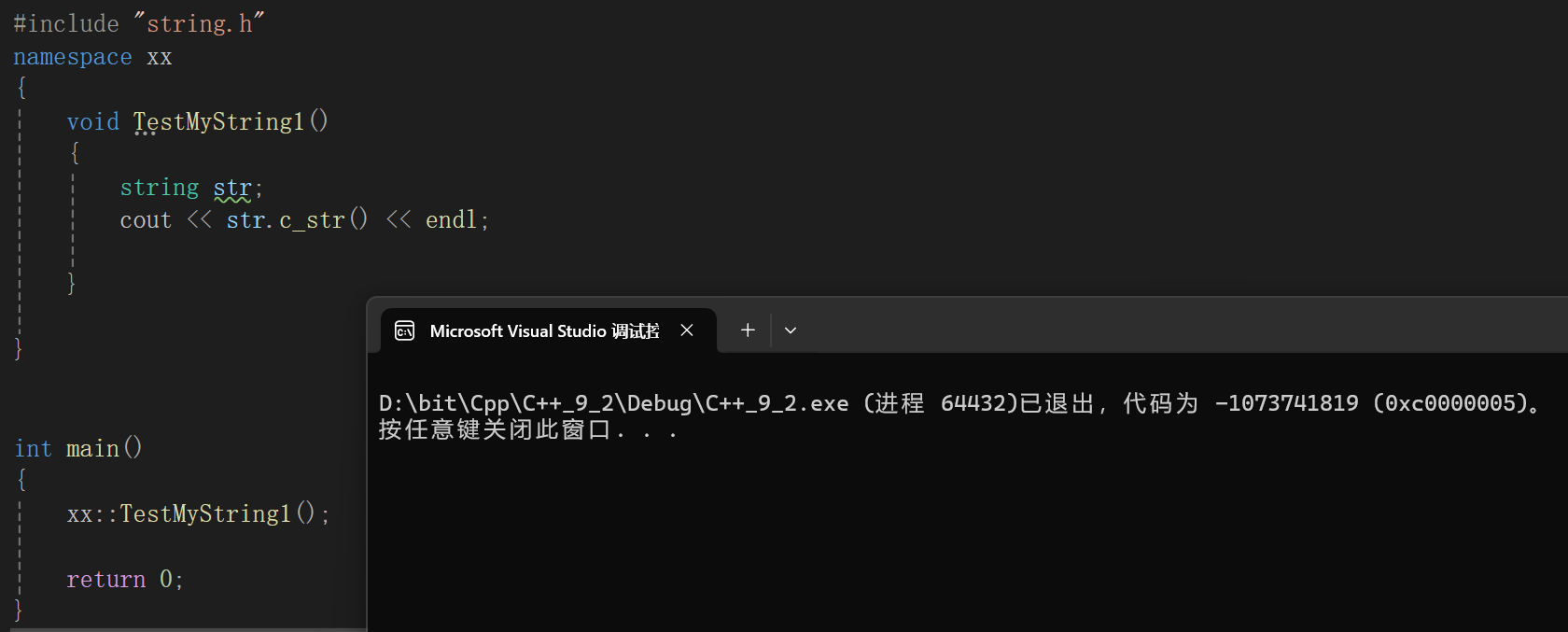
程序直接崩了,这就是为什么我说默认构造的初始化为什么说暂时没有问题,c_str就那么一点逻辑,没错,那就只能是构造出问题了。
其实原因也好说,c_str返回的是const char*的指针,这玩意可老特殊了,如果你用printf("%s")后面传个const char*的指针,是不是直接就读出来字符串了,碰见\0停止。
用cout一个道理,也会输出字符串。
但是底层的角度,怎么样才能根据指针去读出来字符串,怎么样才知道自己读到\0没有,很简单,指针解引用嘛。
所以出问题就出在了:

空指针的解引用可没有被检查出来,一旦运行,系统不崩才不正常。
所以我们数据结构那一套已经不管用了,毕竟如果用库里面的string:
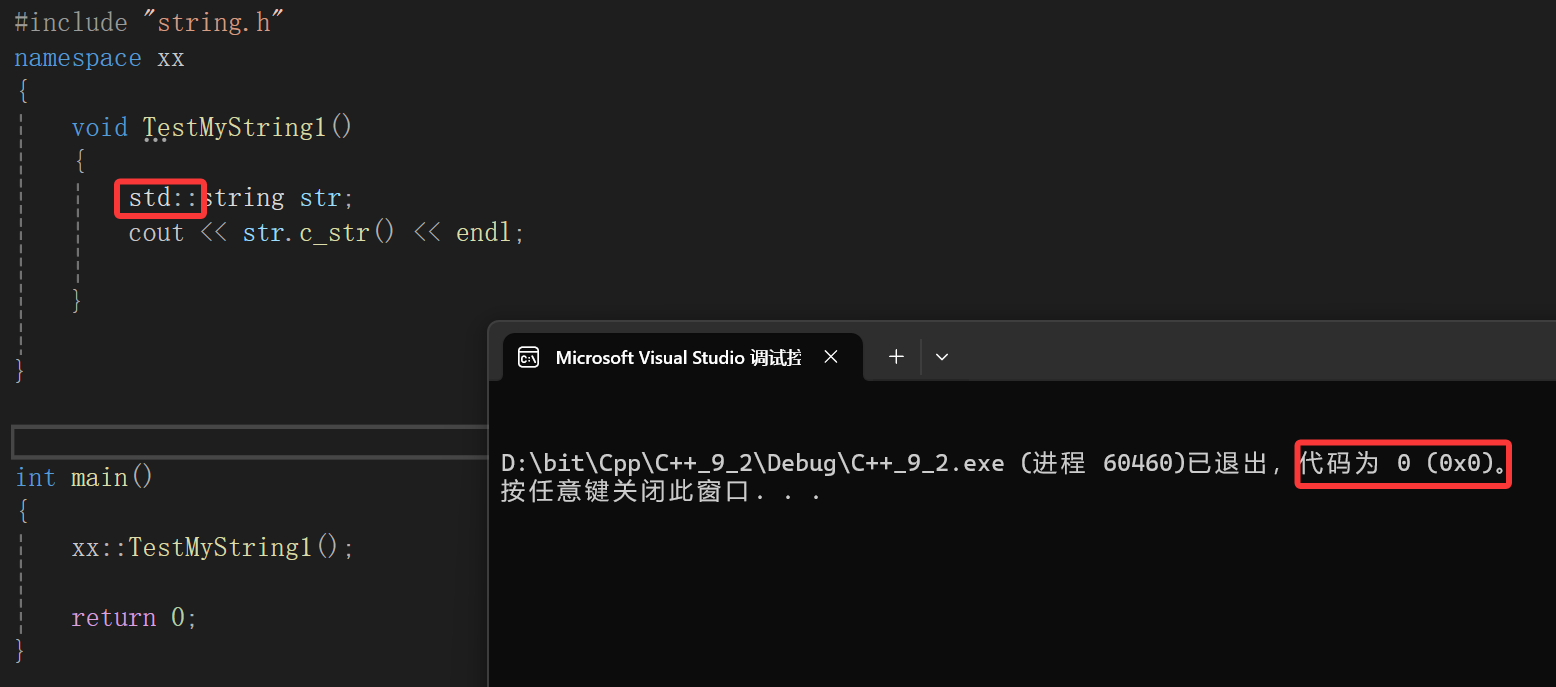
其实是没问题的,首先说明std::不仅有穿透命名空间的膜去访问的作用,还有指定类域的作用。
而一旦用标准库的string去创建对象,其实连c_str都是标准库的,毕竟str是标准库里的string的实例化对象,所以一旦调成员函数就调的是标准库的。
从这个例子我们见识到了通过类访问操作符可以无缝转换不同命名空间下的内容。
所以重中之重是让现在的默认构造具有像库里面一样的效果,那么这个时候_str搞成nullptr的初始化就泡汤了。
直接给出:
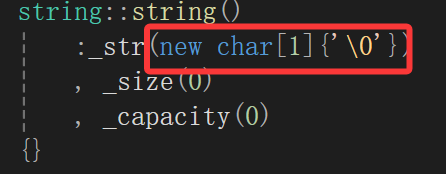
干脆用\0来初始化,在使用时已经说了,编写STL库的先辈没并没有将字符串末尾的\0作为有效字符算入_size和_capacity里,所以其它成员变量的初始化不变。
这个时候再测试一下:
至于为什么这里的str要用new char[]而不是new char()来初始化,继续往下看。
②const char* s初始化的构造函数
实现传参的构造,就实现这个常量字符串初始化的函数,比如string str("hello world"),其实这种形式的传参我们经常写。

如果这么写,犯的错误是什么,首先最显而易见的就是把const char*的值赋给了char* 的str,string的_str肯定是必须支持可修改的,所以参数类型不能变,这么写肯定不合适;再来,你这么做其实就是我们之前说的浅拷贝:
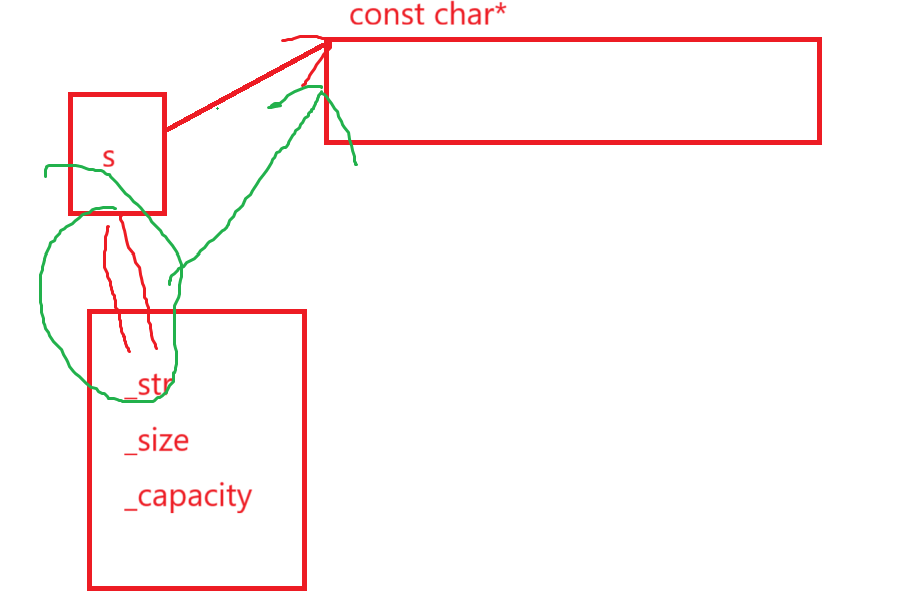
这怎么能被允许呢,堆区的内存会被手动回收的,到时候delete[]_str,不炸了嘛,那s指针还调个屁啊,这是一般浅拷贝经常发生的问题,当然,这里连赋值都做不到,倒也不用担心浅拷贝深拷贝的问题了。
所以这就是为什么讲完函数体初始化,又讲了个初始化列表初始化,最后也并没有一棒子打死,而是良禽择木而栖,选择最合适的方法,甚至是初始化列表和函数体结合起来使用。因为虽然建议使用初始化列表,因为每一个都会走初始化列表,但是像我们上面写出来的构造很明显不能这么做。
所以干脆初始化列表仅开辟空间,因为要深拷贝,只能先开辟空间,再拷贝:

对此作几点说明:
首先,strlen我们知道是计算字符串的长度,因为底层是以碰见\0就停止计数,不含\0,所以strlen的大小刚好符合_size和_capacity的要求,但是对于_str来说,肯定是要多加一个来存放\0的。
其次,strcpy复制的时候如果不复制\0,dest的位置可不一定给咱们准备\0,所以strcpy基本原理大概是这样的:
char* My_strcpy(char* dest,const char* src)
{
char* ret = dest;
while (*dest++ = *src++)
{
;
}
*dest = '\0';
return dest;
}
也就是自己在末尾补一个\0。
故而函数体内的strcpy其实也是合理的。
不足之处,这段代码调用的strcpy是不可避免的,但是strlen的调用其实有点冗余了,毕竟strlen底层需要把整个字符串遍历一下,三次strlen的结果都是一样的,所以可能有人很轻松的就想到:

这段代码看着真不错啊,这样就只调用一次strlen,而后就是用_size去赋值了。
如果这么写代码,你就又错了,为什么呢?
很简单,我讲初始化列表的时候说的什么,走初始化列表的顺序是按照声明的顺序来的,声明的顺序大概是:

这样就会导致初始化的时候其实不合理,以为先初始化_str,借助于_size的大小确定内存大小,那不炸了嘛,_size还没初始化,还是随机值呢:

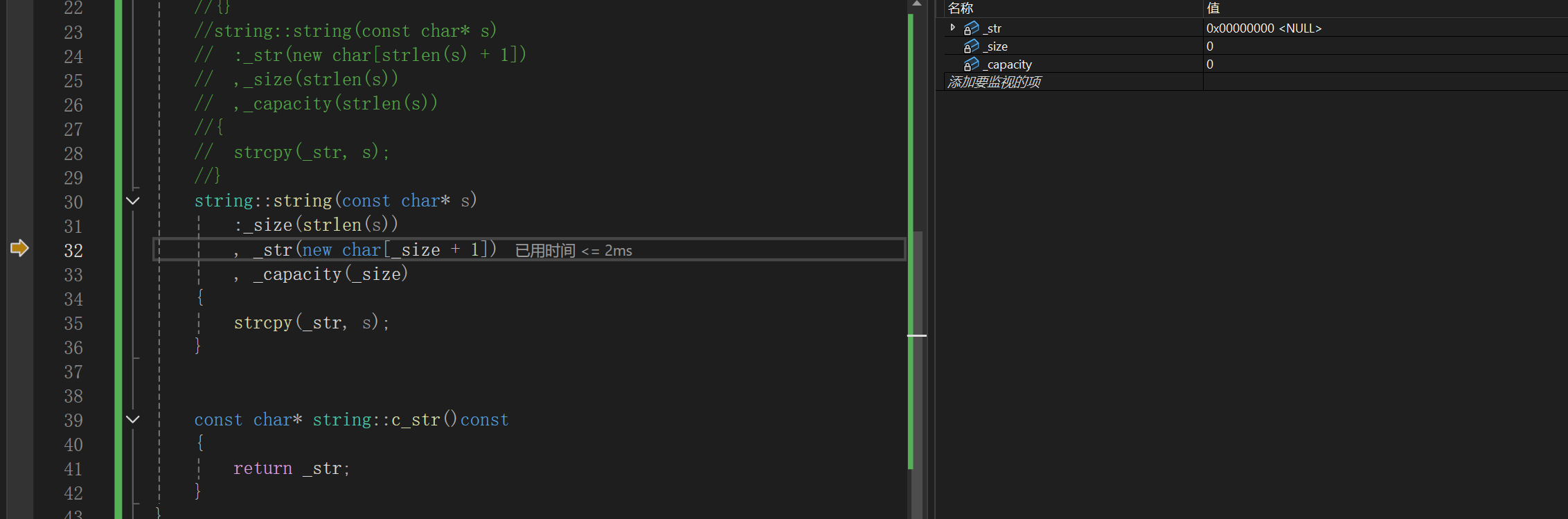

这是调试可以看到的,很明显,_str开辟的内存不符合要求,但是:
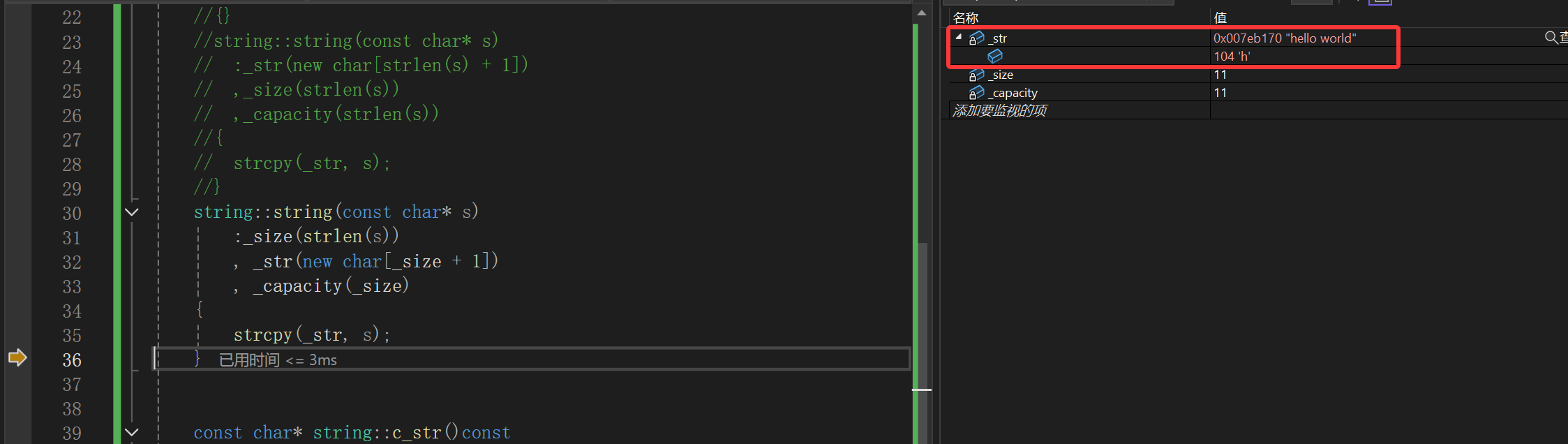
strcpy太强势了,直接根据指针起始地址全部拷贝过去了,这不直接越界了嘛,但是如果程序员不知道的话,其实最后结果:

输出的hello world,一看最后返回值蒙了,很明显代码有问题。
于是吸取教训以后,既然你是根据声明的顺序来初始化的,那我就让你声明的顺序和初始化列表的顺序一致:

没毛病倒是没毛病了,但是这里其实还是有隐含的问题。
如果进到项目组里面,好几个人完成一个项目,互相写的代码大概能看个七七八八的。
假如有一天来了个实习生,实习生一看:

这多难受啊,顺手给你:

然后同样的代码一弄肯定就又炸了。
声明顺序和初始化顺序高度耦合,这段代码其实不是一段好代码。
所以也不能改变声明的顺序了,就保持我们惯用的顺序,玩个小花招:

没人说_str和_capacity必须在初始化列表初始化吧,必须在初始化列表初始化的是引用,const对象,没有默认构造的自定义类型的对象,这里哪有这样的三种,所以完全可以函数体内初始化嘛。
这就是我说的要择木而栖,你不能说反正都要走初始化列表,我为了省事强行憋出来,那不坏了嘛。该用初始化列表就用初始化列表,该用函数体就用函数体。
当然,最终版本写成有缺省值的:

如果声明和定义分离那就在声明位置给出缺省值,这样我们的默认构造其实也可以下班了:
string::string(const char* s):_size(strlen(s)){_str = new char[_size + 1];_capacity = _size;strcpy(_str, s);}3.string类的析构函数
string::~string()
{delete[]_str;_str = nullptr;_size = _capacity = 0;
}不多说,该释放释放,该置空置空。
二、string类访问的模拟实现
1.operator[]重载
类似于数组的形式访问是我们常用的访问方法
库里面给出来的大概就一个意思,const对象的匹配const成员函数,非const对象匹配非const成员函数。
char& string::operator[](size_t pos){return _str[pos];}const char& string::operator[](size_t pos) const{return _str[pos];}代码其实很简单的逻辑,给的下标那你就根据底层的char*找去。
只不过在我们真正常使用的时候必须让pos是个有效值,不能越界:
char& string::operator[](size_t pos)
{assert(pos < _size);return _str[pos];
}const char& string::operator[](size_t pos) const
{assert(pos < _size);return _str[pos];
}所以加一层assert。
2.迭代器和范围for
讲的时候我们是先讲的迭代器,再讲的范围for,已经知道,底层范围for其实会转换成迭代器,所以写好迭代器,范围for自然就实现了。
string类的迭代器怎么实现呢?
起个迭代器的名字可真是高级的一匹啊,感觉都不简单,其实我们如果模拟实现的话,可以用最简单的方式:

看见这两行有没有脑袋轰的一下炸开了,很明显可以看出来,原来两种迭代器可以简简单单的用指针,只不过包装成迭代器使用,真是草台班子啊。
但是还是强调,迭代器不一定是指针,我们string类迭代器就当成指针用没啥毛病,假如你现在底层是个单链表,如果仍旧以此为迭代器,我请问你typedef SLT* iterator以后,你iterator++可以遍历吗,iterator--更是不可能,可以知道迭代器的设计跟底层数据结构的设计有关,绝对不能一刀切。
知道了这层包装以后相信迭代器就非常简单了,当然,这里暂时只实现普通迭代器和const迭代器。
string::iterator string::begin()
{return _str;
}
string::iterator string::end()
{return _str + _size;
}string::const_iterator string::begin()const
{return _str;
}
string::const_iterator string::end()const
{return _str + _size;
}强调一下几点:
- 做声明和定义分离,很明显
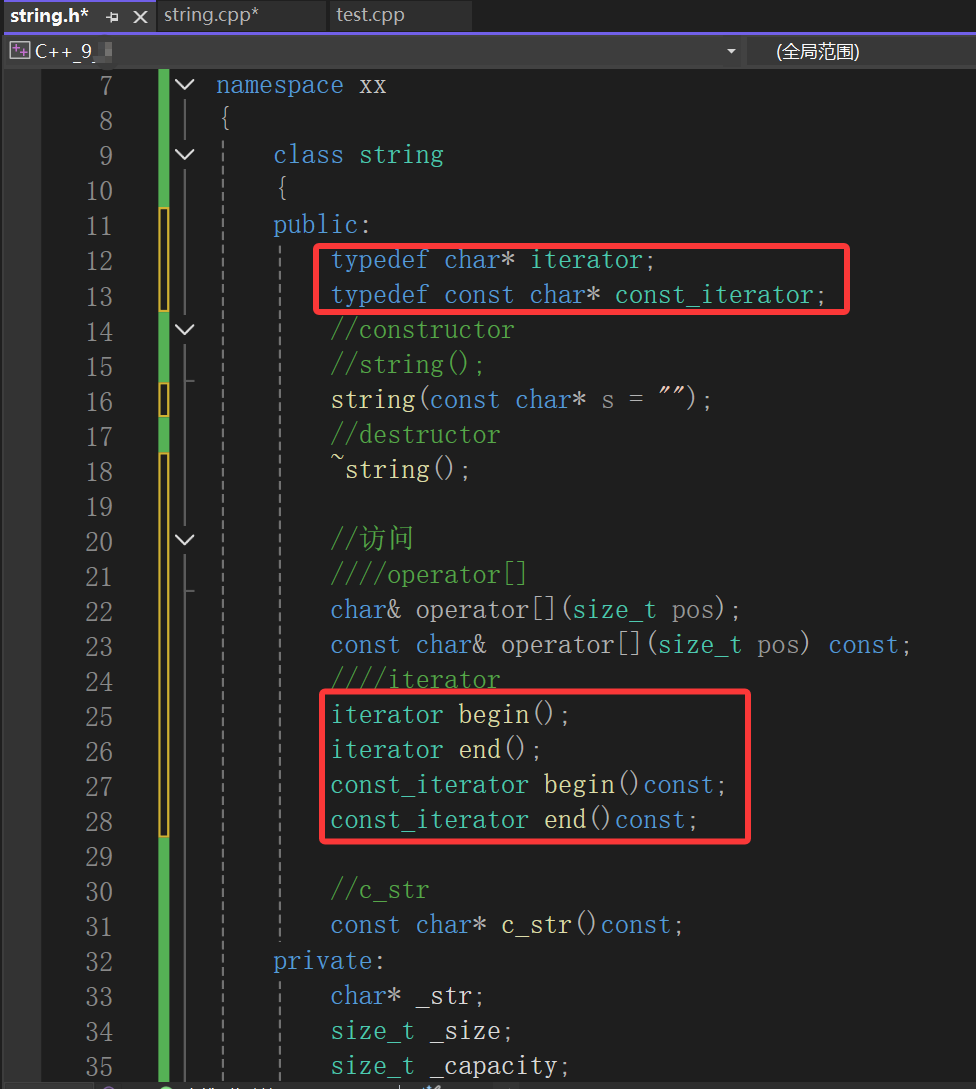
需要不仅begin函数需要注明类域,以求相当于在类内创建函数以及访问类内的成员变量;而且typedef也需要注明类域,命名空间内可没有iterator和const_iterator,必须再突破个类域访问。 - const_iterator相信看到typedef能够更深一步理解,什么叫const不修饰迭代器,因为迭代迭代,它指向的内容肯定是可变的,如果是const iterator那就失去了迭代性,所以是const_iterator,即指向的内容不能变。
至于反向迭代器和const反向迭代器暂时不去实现。
测试:
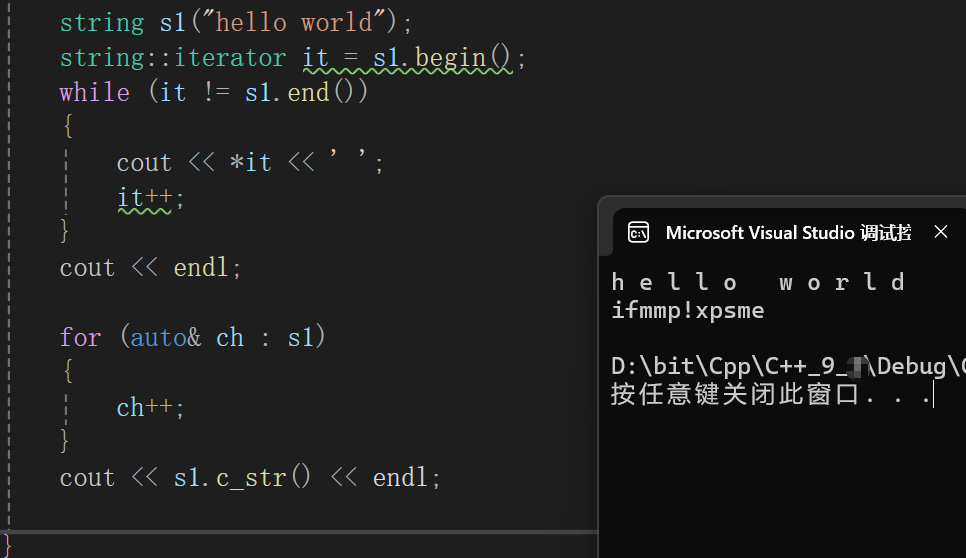
迭代器一完成,范围for也就成了。
三、string类的增删查改
1.push_back

string类的push_back就是插一个字符。
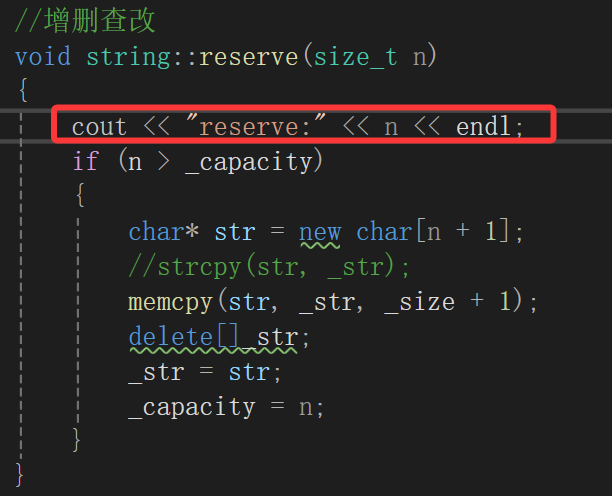
如果想要插入,首先应该保证内存空间是够的,所以第一步就是扩容,故而先搞个reserve函数:
reserve
reserve的难点就在于我们C++可没有C语言一样的realloc,虽然可以兼容,但是为了和构造和析构函数接口完全一样,我们也用new,而new是用来申请空间的,如果这样的话,只能异地扩容了。
void string::reserve(size_t n){if (n > _capacity){char* str = new char[n + 1];strcpy(str, _str);delete[]_str;_str = str;_capacity = n;}}需要注意的点,reserve函数在库中传比_capacity大的值可以扩容,传比_capacity小的,如果还大于_size的话,某些编译器就会去缩容,我们这里不实现缩容。
还是需要注意_str的大小永远多一个char去存\0。
有了reserve以后先判断是否需要扩容,并完成扩容代码后再进行尾插:
void string::push_back(char c){//扩容if (_size >= _capacity){size_t newcapacity = _capacity == 0 ? 4 : 2 * _capacity;reserve(newcapacity);}//尾插_str[_size++] = c;_str[_size] = '\0';}扩容后比较重要的就是往_size位置尾插并往原_size + 1位置插入\0,因为尾插的时候把\0覆盖了。

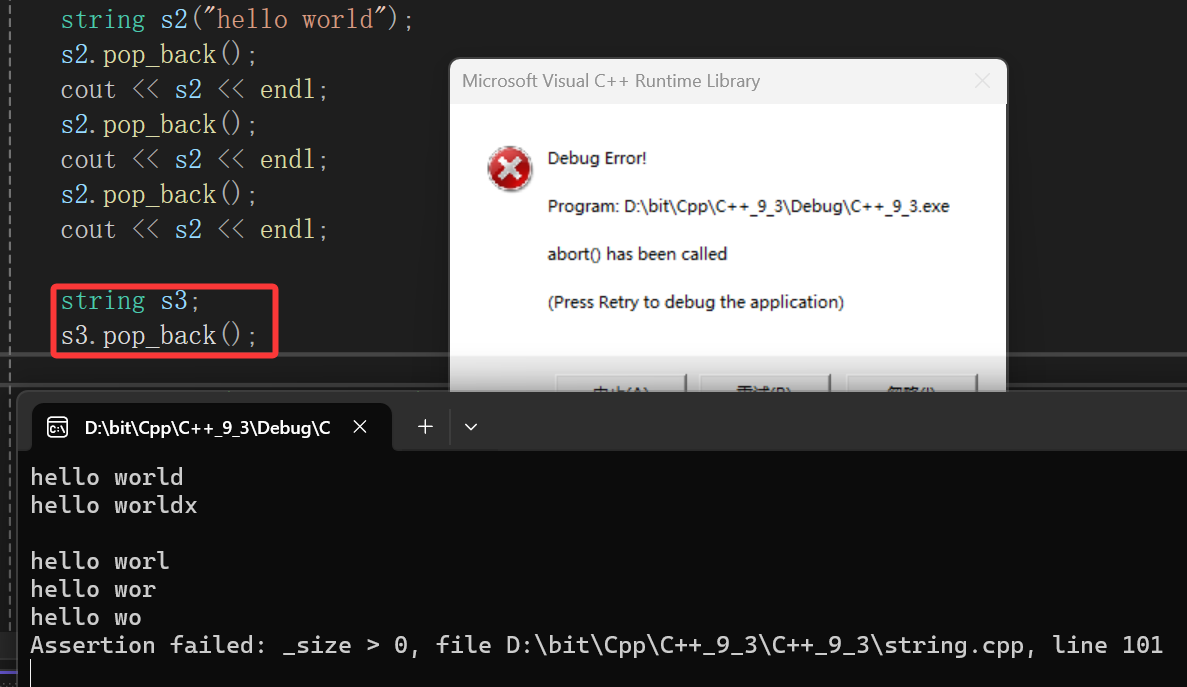
2.pop_back
尾删就非常简单了,我们顺序表的尾删怎么写的?_size--,只不过这里存的是字符串,你--以后还必须在字符串末尾搞个\0,不过也不难:
void string::pop_back(){assert(_size > 0);_str[--_size] = '\0';}

没啥毛病。
接下来就是看看assert管不管用:
完活。
3.append
还是实现插入常量字符串的版本。
稍微瞅一眼库里面的参数和返回值:
![]()
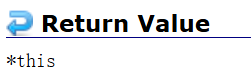
其实append这个函数返回值写个void倒也无可厚非,但是可能会有:
string s2 = s1.append()这样的场景出现,所以最后返回*this的引用了,大概率还是用来赋值,只不过传引用可以避免拷贝。
拷贝思路
至于实现思路其实很简单:
要不然调strcat,要不然调strcpy,去实现尾插。
不过这里用strcpy更好,原因:
从底层来讲,strcat需要先遍历目标位置的字符串,直至找到\0才会停止一次循环,开始循环拷贝来源位置的字符串直至\0;
而我们string类不仅有_str,还有_size,我们可以直接知道\0的位置(_str + _size),也就可以不找\0只拷贝。
扩容思路
拷贝倒是结束了,你可不能光插啊,最少得保证容量够吧,容量是相对于谁的呢?
_size+strlen(s)这是我们最少要开辟的大小。
所以可不能直接傻傻的:
//扩容
if (_size >= _capacity)
{
size_t newcapacity = _capacity == 0 ? 4 : 2 * _capacity;
reserve(newcapacity);
}
最少得_size + strlen(s)去和_capacity比较,所以扩容就搞成这样:

二倍扩容够用就二倍扩容,二倍扩容不够用那就你要多大我开多大吧。
至于尾插就简单了。
string& string::append(const char* s){//扩容size_t length = strlen(s);if (length + _size >= _capacity){size_t newcapacity = length + _size > 2 * _capacity ? length + _size : 2 * _capacity;reserve(newcapacity);}strcpy(_str + _size, s);_size += length;return *this;}测试代码:
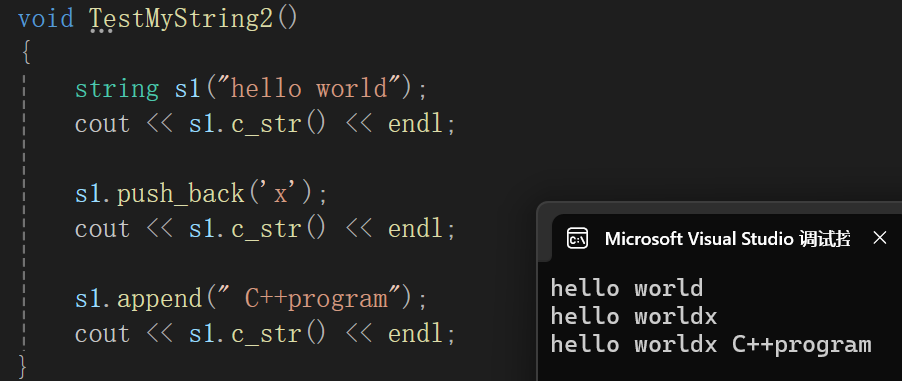
4.operator+=重载
这个还真不用多讲,基于push_back和append,我们轻轻松松就能做到这种重载:
string& string::operator+=(char c){push_back(c);return *this;}string& string::operator+=(const char* s){append(s);return *this;}不过确实+=更加生动形象的体现字符串追加。
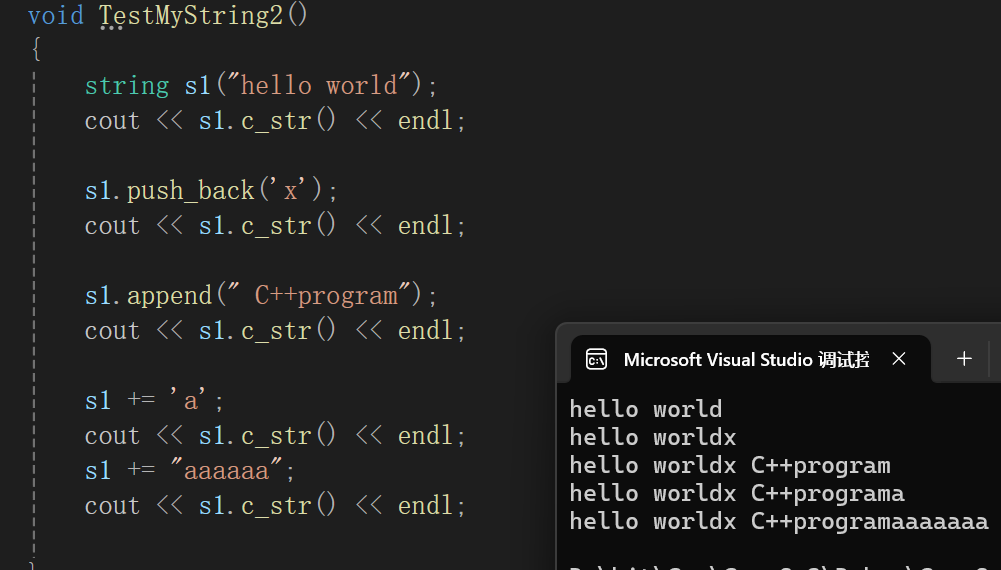
5.<<流插入操作符重载
①完善<<
既然到了C++,我们肯定是不希望还跟C语言一样去打印,那就离不开重载<<。
在Date类中我们实现过流插入重载,重点就是非成员函数(因为要想让cout做第一个参数,符合流插入的习惯);返回cout以便可以同一行连续输出数据。
简单写就是这样:
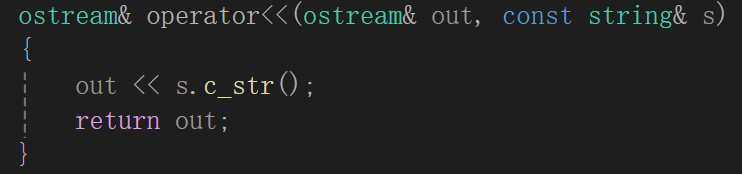
ostream& operator<<(ostream& out, const string& s){out << s.c_str();return out;}注意到其实这么写我们并没有申请为友元函数,因为这里如果设为友元函数就是为了方便我们能够访问内部的成员变量,而c_str这个成员函数暂时看起来能够满足我们的要求,所以并不是所有的流插入函数都需要写为友元函数。
浅拷贝深拷贝问题再现
当然,其实我一开始写的不是这段代码,我写的是这样的:
ostream& operator<<(ostream& out, string s)
{out << s.c_str();return out;
}我自己看了半天代码调试了半天代码,一直出错,给我干成sb了我都不知道哪里错了。
这里就又犯了浅拷贝的问题。
我们第二个参数写的是string s,等于说是传值传参,传值传参需要拷贝,自定义类型就会去调用其对应的拷贝构造,可是我们写了这么多函数,哪里实现拷贝构造了吗,其实根本没有,那编译器就会自动调用默认拷贝构造,说是默认拷贝构造,这里编译器干的活就是搬运工,还不是传统意义上的搬运工,还是复制粘贴的拷贝,也就造成:
理想状态下拷贝了一份给s,但是事实上直接让s指向s1那块空间了,而在<<重载中:
出了局部域肯定要销毁s:

那后面就遭老罪了,因为后面我们还要:
push_back的个数刚好够(_size == _capacity)调用reserve,reserve里有delete []_str。

这就是我们前面说的对一块空间多次释放,那这程序不炸谁炸。
我当时找半天没找出来出啥事了,果然先辈总结的错误都不是白来的,都是血与泪的教训啊。
可能这个时候就有人注意到了,为什么我说的是暂时呢:
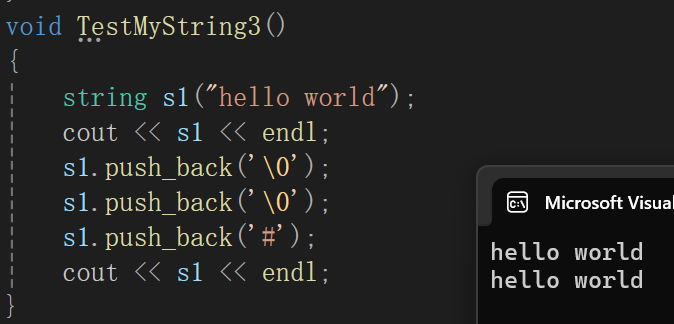
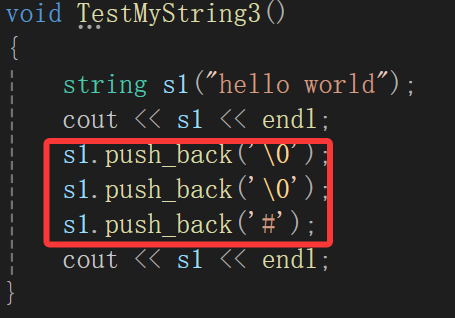
不妨来看这样一个极端案例,你\0不打印出来我就不说了,为啥#也没了,真是欺人太甚。
不妨调试看看:
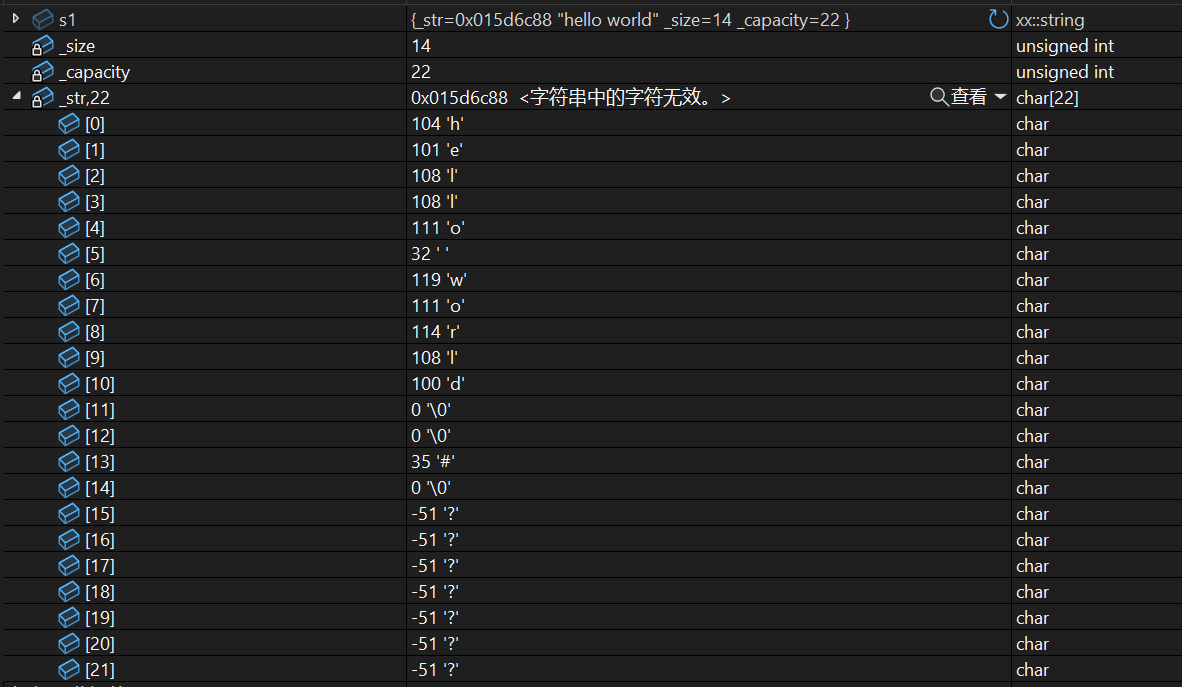
我们push_back实际上暂时没啥问题,毕竟确实插入了。

其实问题就很明显了,那就是以const char*的形式输出,读到\0就停止了,那肯定输出不到#,我们这个<<重载写的就失败了,毕竟:
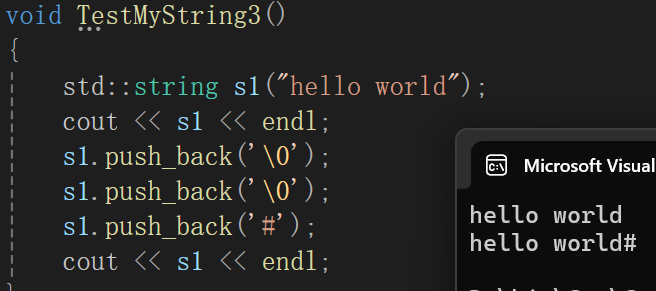
库里面的可没啥问题,虽然\0不显示,但是#人家总归给你打印出来了,其实要实现也是非常简单:
ostream& operator<<(ostream& out, const string& s){/*out << s.c_str();*/for (auto ch : s){out << ch;}return out;}直接逐个输出就完了,这里用的是什么,是迭代器。当然用下标其实也可以,一直输出到_size-1位置即可:
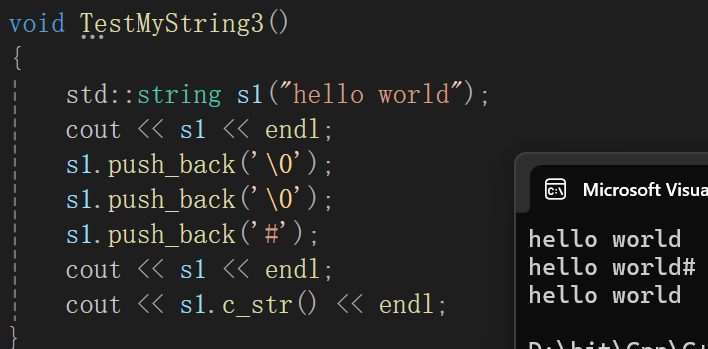
也从侧面印证了,c_str与正常s的不同之处。
这也就是为啥说现在模拟实现最多就是增加对string类的理解,你看你写过流插入重载,一会因为参数浅拷贝出事,一会因为偷懒不能将所有有效字符输出,所以一般情况下库里面的还是老老实实的用,真的有能力的了,再完善STL去。
---------------------------------------------------------------------------------------------------------------------------------
②借助<<输出并完善push_back、reserve等
好的,现在流插入修好了,但是:
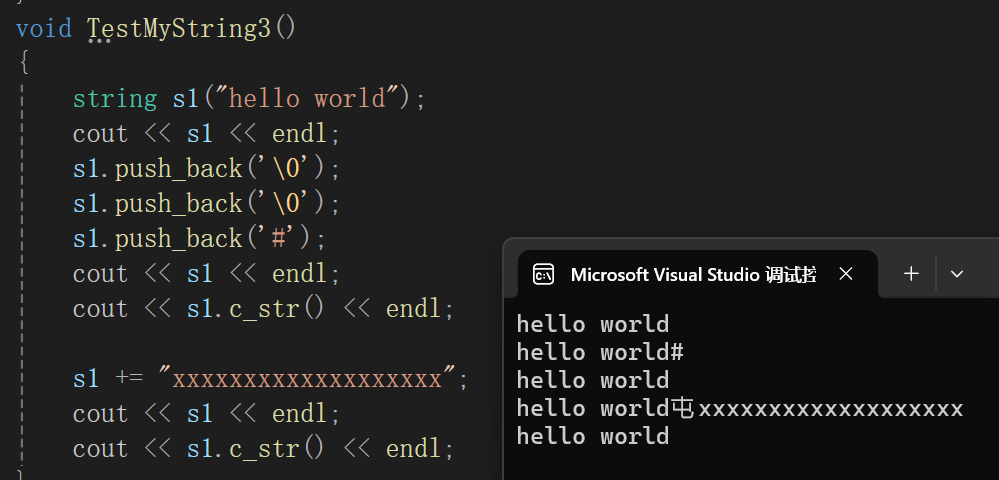
暗流涌动啊,又干出来个屯,真是气笑了,继续调试检查为什么,很明显断点打到s1 +=那一行,毕竟从那里以后打印的数据出问题了:
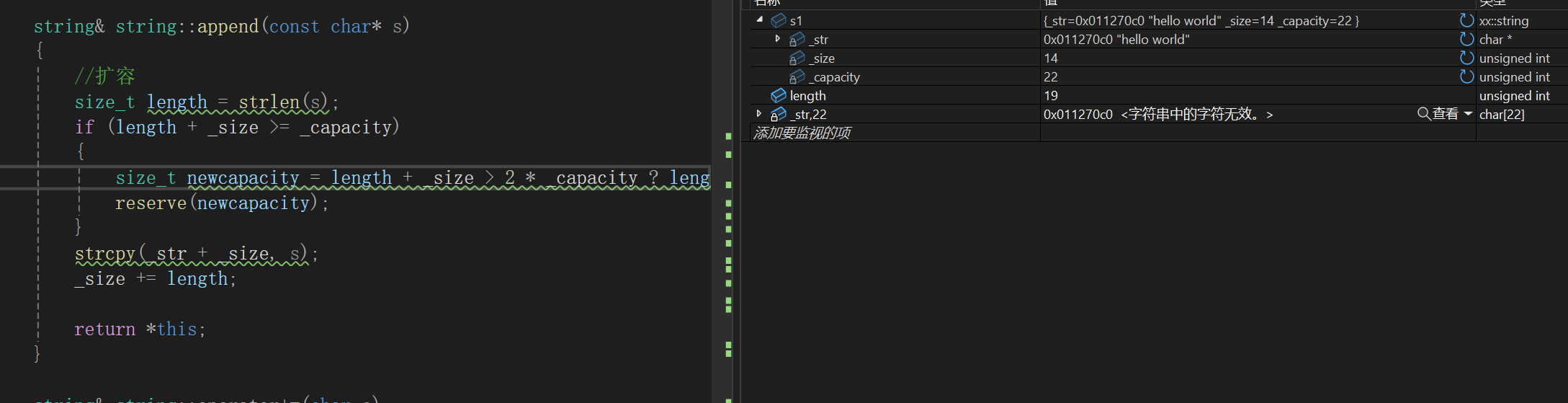
+=我们底层其实也就是让它去调append,而上来就得检查用不用扩容,19 + 14 = 43,2*22 = 44,二倍扩刚好够用。
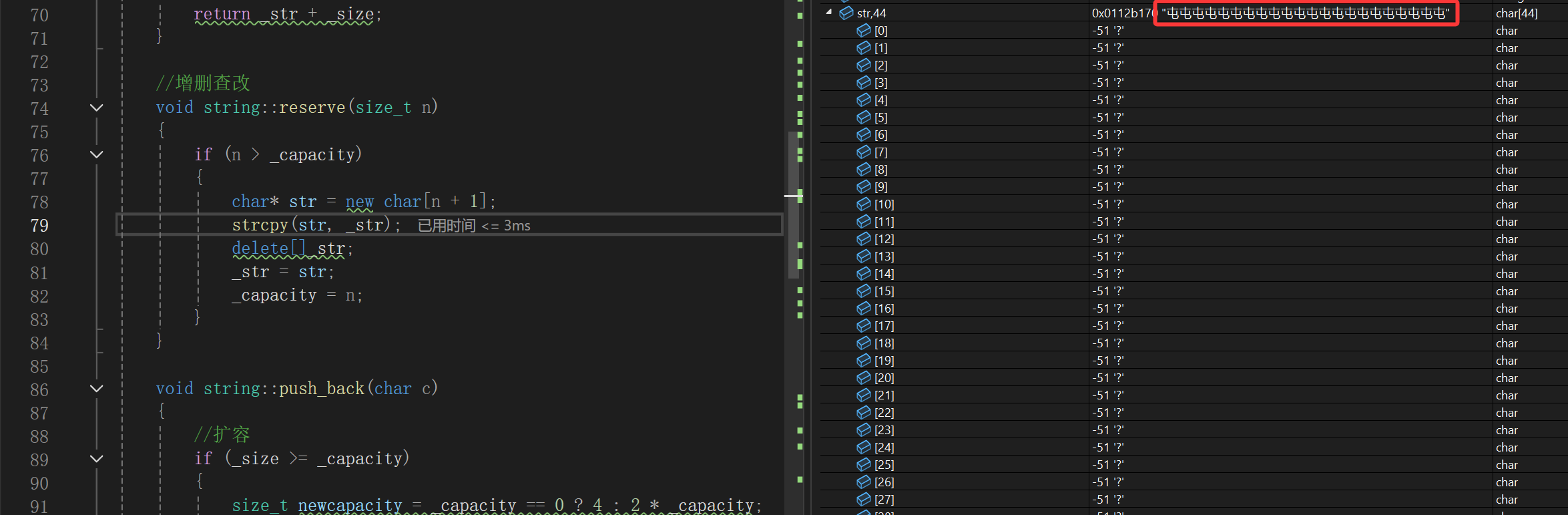
reserve里new了以后发现一个巧合的现象,我们在最终输出里有屯,这里随机值也是屯,那么说明我们输出的就是随机值了,为什么出现这种情况呢?
继续往下看:
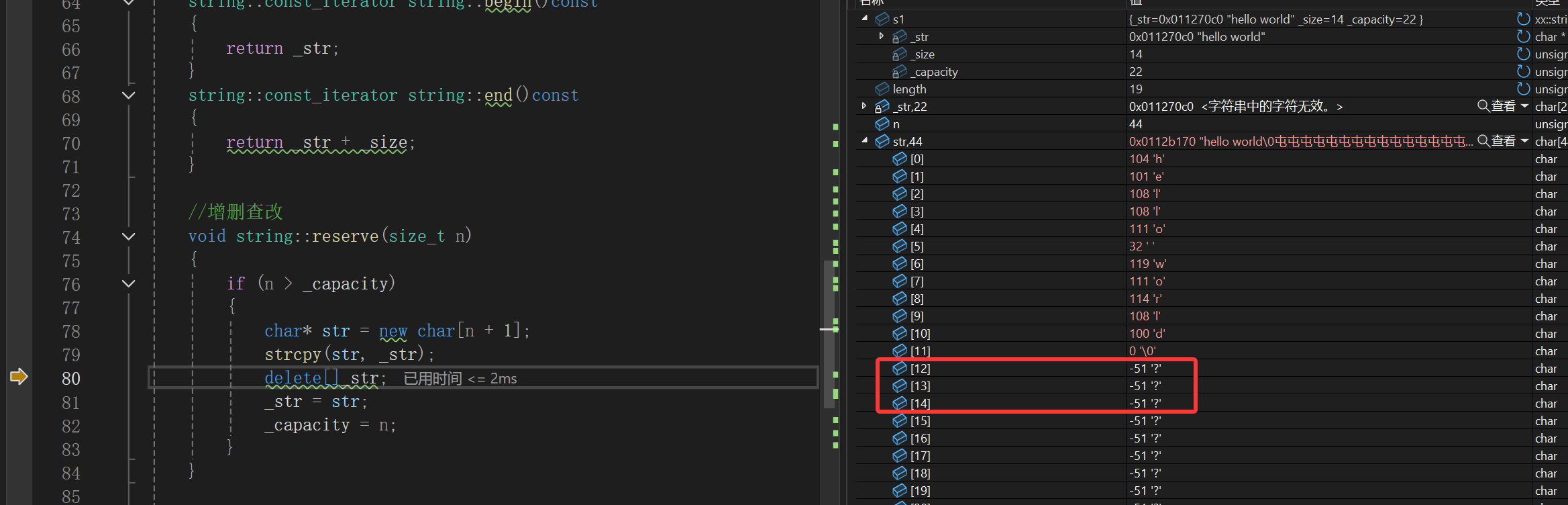
我们string里面按理来说是一个hello world和\0 \0 以及#,硬说的话还有个结尾的\0,但是我们这里最后只有一个\0,也就是少了一个\0、一个#和一个\0。
那就是strcpy的问题,不过想想strcpy的底层,大概率strcpy碰到\0就会停止,毕竟这是C的接口,C碰见\0不就是字符串结束嘛,再拷贝就越界了,很明显string对象里也可能有效字符有\0,所以strcpy在这里是不合适的。

回到append以后发现确实是这样的,有效字符\0和#并没有被拷贝,这样存的就是-51-51。
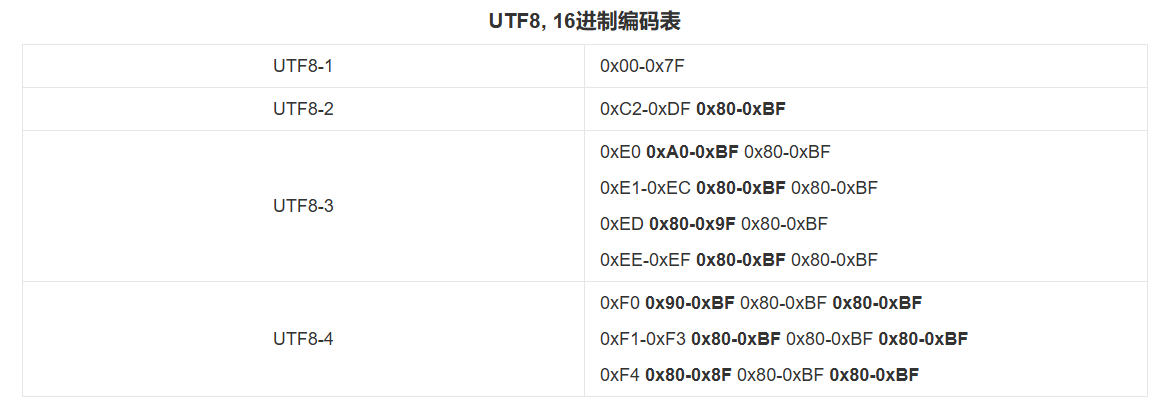
前面说过嘛,单个字节存英文字母,也就是用ASCII码存英文字母和字符等。如果是汉字的话就是多字节,这里编译器就将这里的随机值当成汉字来解析了,解析成了屯,其实在C语言阶段我们见过这样的值,当时有一次输出了烫烫烫,这个其实就是随机值。
调试了这么久知道哪里出问题了,就知道怎么改了,strcpy不合适,那就转用memcpy:

总结原因就是string字符串中可能存有字符串结束标志\0,这也就会干扰strcpy的完整执行,所以用memcpy,只需要将_str中_size + 1个字节的数据全部给str拷贝过去就行。
标准库里:
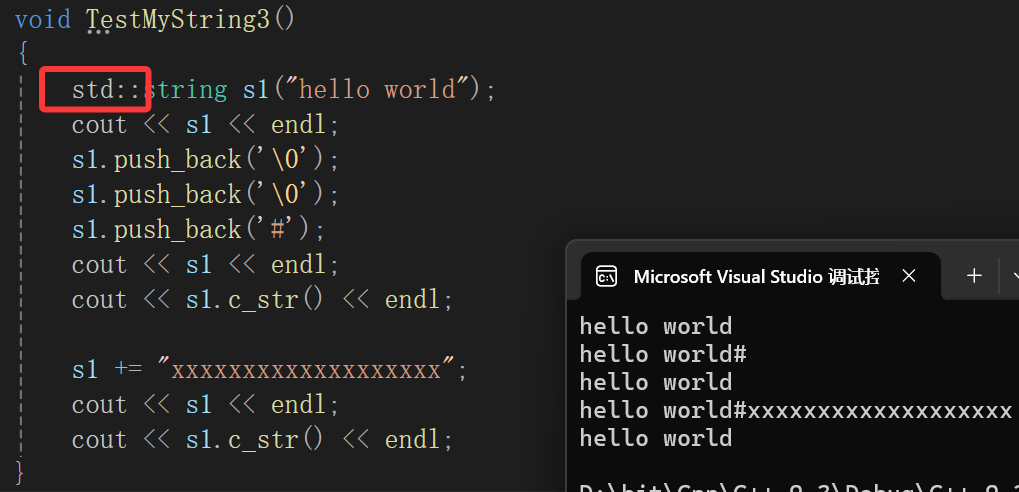
修改过后的:
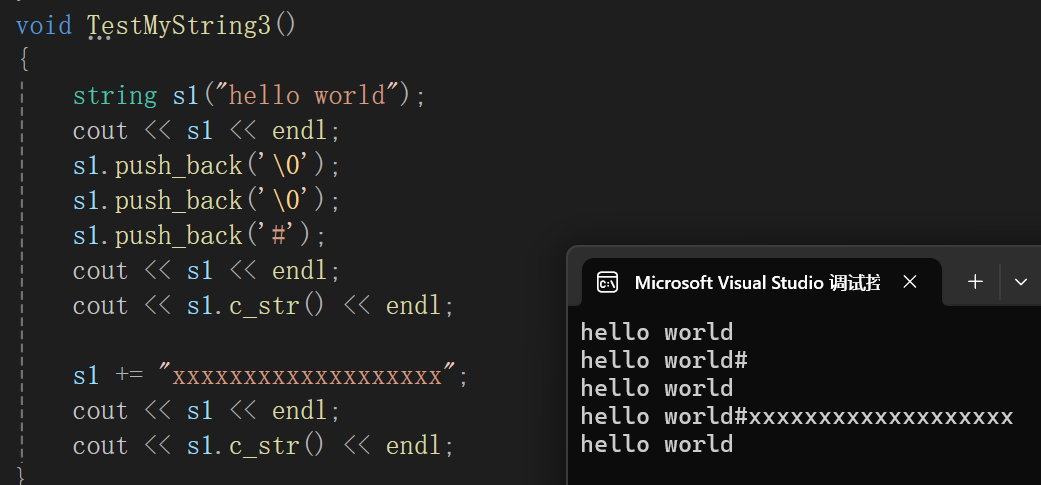
跟库里面的一个效果了已经。
现在就警醒我们了,对于string类对象的拷贝需要非常小心,我们上面的构造、操作都不少写strcpy,但是部分还是合理的:
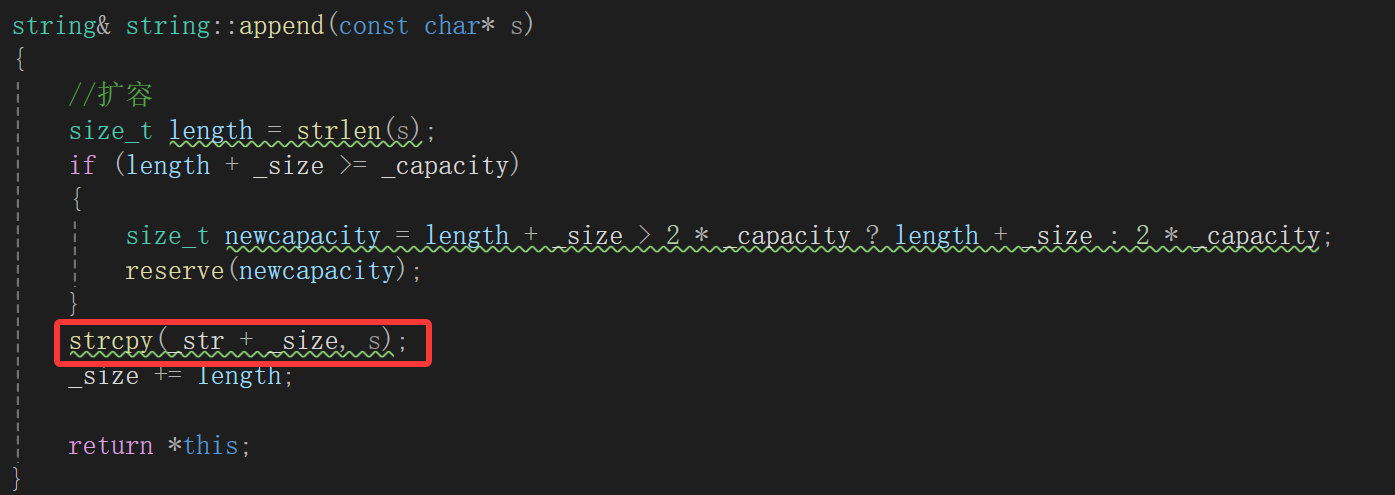
比如这里的s其实就是C形式的字符串,那它中间咋可能存\0,只有末尾有,所以这里可以用strcpy,这样的例子还有很多,但是为了方便记忆,干脆所有的strcpy都改成memcpy。
不限于:
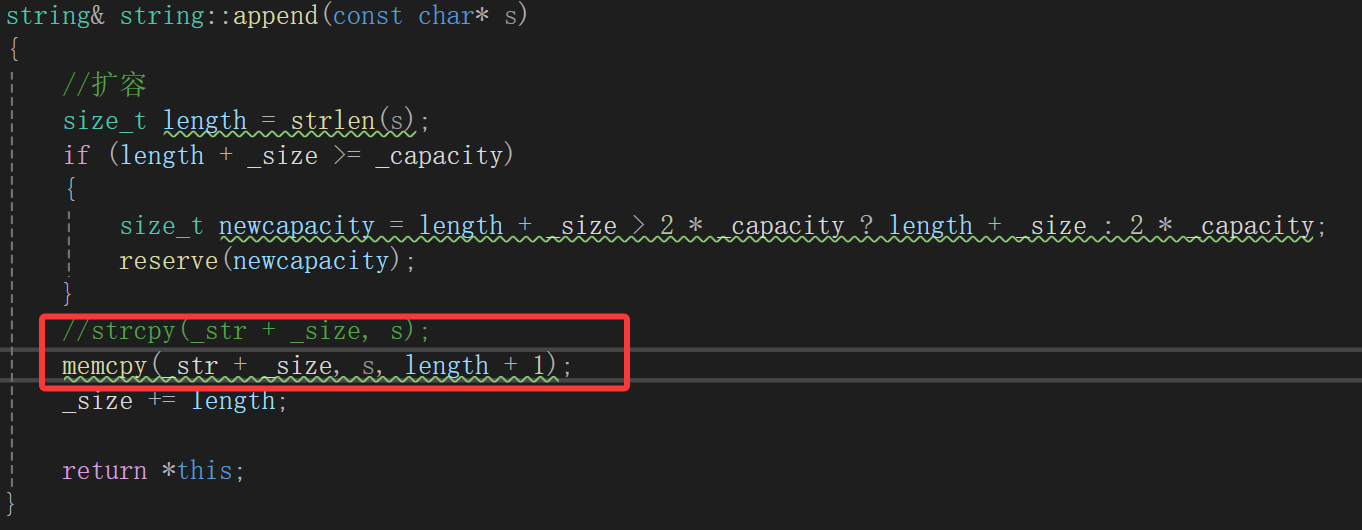
都得带着\0,千万不能忘。
但是凡事还有例外,如果同样的字符串,即使是用标准库的string,也会:
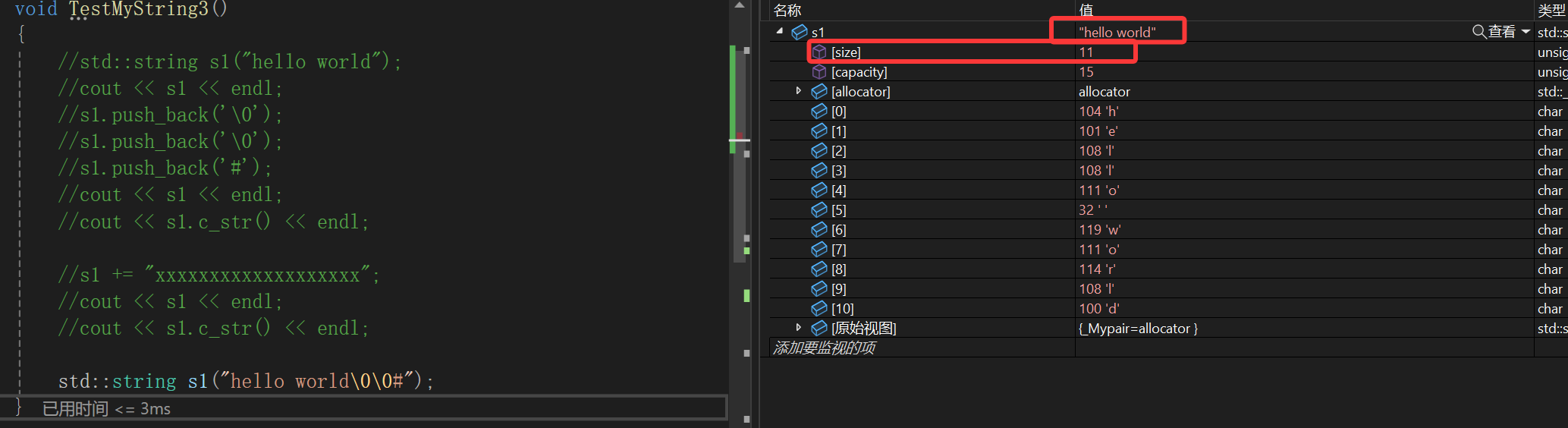
即使是库里面的类面对这种字符串也会依据const char*来初始化,这样读到\0就终止,后面的字符就不在读了。
这种行为和上面那种行为怎么理解呢?
其实string类就是用来存字符串的,而字符串中间其实是不能有\0的,所以构造的时候碰见\0就终止其实是没毛病的,_size是11不犯毛病;push_back一开始得reserve,重开空间那也肯定是有多少拷贝多少,因为底层是顺序表,所以如果push_back \0其实也得算成有效字符,只要push_back了,最后我的_size必定++,所以_size是14也没毛病。
嘿,合着你说了半天结果最后来了一句都对,是的,这两种处理方式是对的,不对的是程序员的行为,你知道\0是字符串结束的标志吧,你知道string应该存字符串吧,那么你俩都知道,你为啥还要往字符串后面push_back \0,你做的行为合理吗,纯纯找不自在。
我们这里严格拷贝就是考虑的底层结构,用const char*构造是当字符串用。
---------------------------------------------------------------------------------------------------------------------------------
可能我正写增删查改呢,突然搞个流插入重载,给人都看懵了,那是因为有的bug借助c_str打印根本看不出来,所以需要实现我们自己的<<来使用。
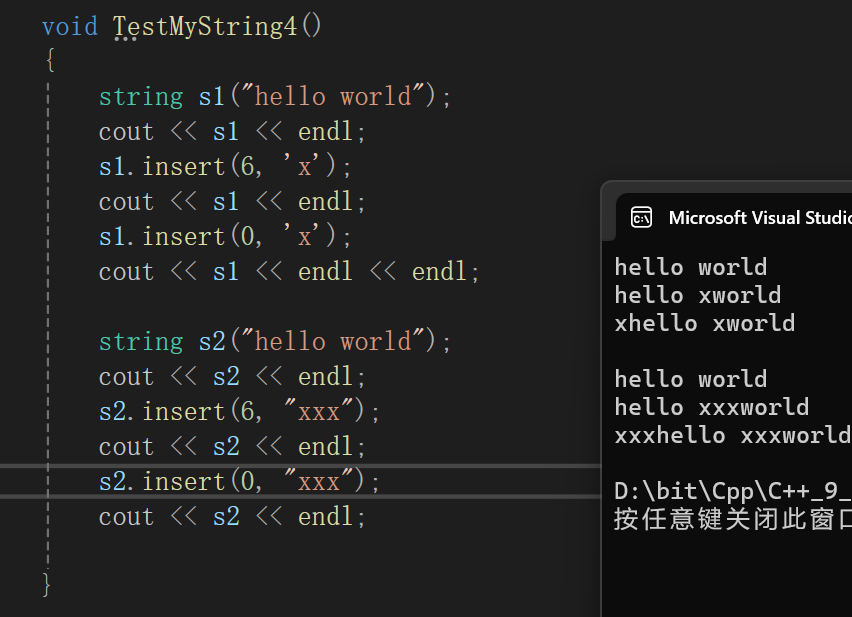
6.insert
![]()
![]()
简单写两种,第一个就不实现成n个c了,实现成一个c,主要是为了实现第二个之后体现我们从一个字符的任意位置的插入到任意位置的字符串的插入。
①insert char
insert的难点就是要根据pos和string类里的成员变量写一个循环来移动数据,干想其实我也不知道咋写代码,还是跟我们做OJ题一样,当个事办,画个图代值:
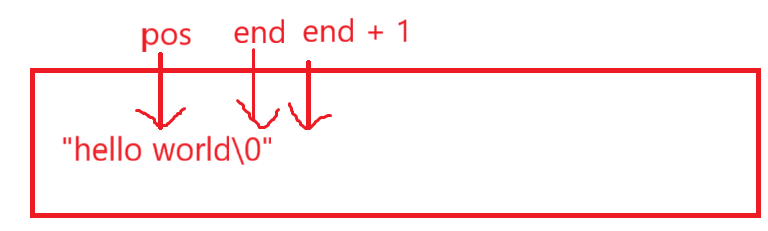
我的思路就是不断的把end位置的值赋给end + 1,然后终止循环的临界就是end == pos以后相当于把pos位置的也移走了,这个时候就可以_str[pos] = c去赋值了。
当然,写循环的时候只是将end == pos作为临界,写起来代码可不一定就写个这。
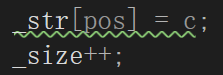
string& string::insert(size_t pos, char c){if (_size >= _capacity){size_t newcapacity = _capacity == 0 ? 4 :2 *_capacity;reserve(newcapacity);}size_t end = _size;while (end >= pos){_str[end + 1] = _str[end];end--;}_str[pos] = c;_size++;return *this;}
写一段测试代码:

暂时看起来没啥毛病。
试验一下极端情况:
咱存测试代码就那几行,不能一瞬间跑完说明已经出问题了,也就是这个极端情况出问题,画图先看看能不能找出来问题:
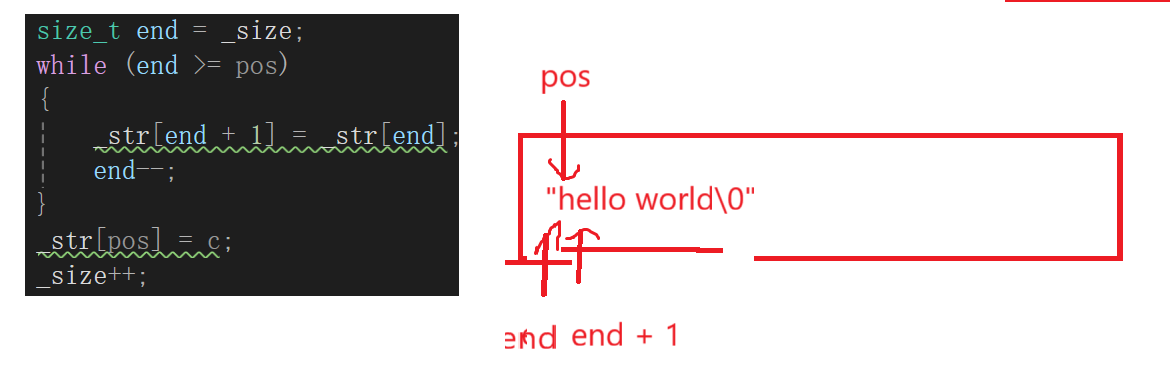
很明显,当end = 0的时候进循环是把h后移了,这个时候end--了,就成-1了,-1按说小于0啊,注意看,size_t类型我们见过一个npos,-1相当于整型最大值了,所以这里炸了。
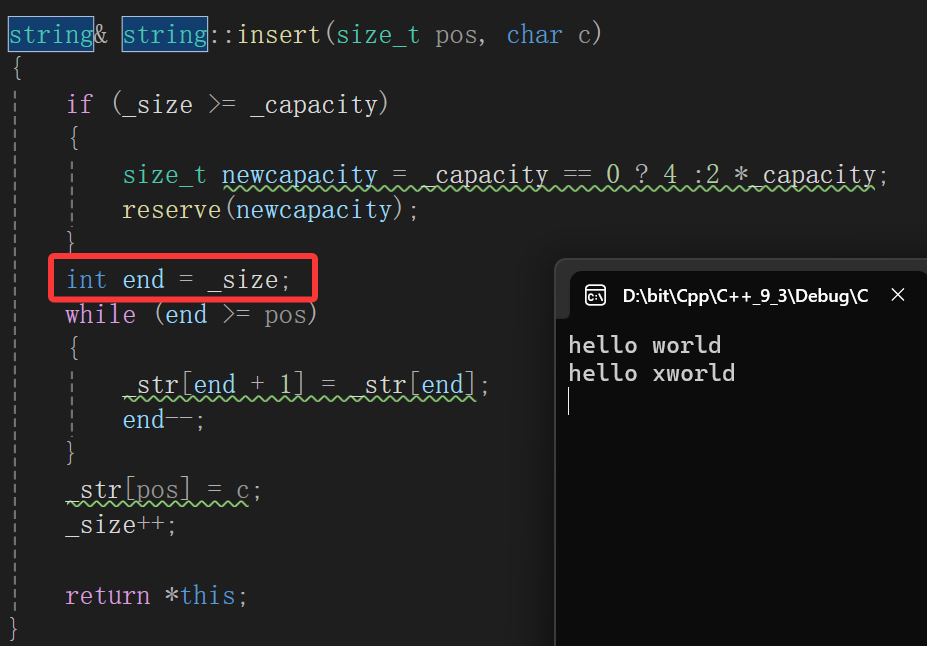
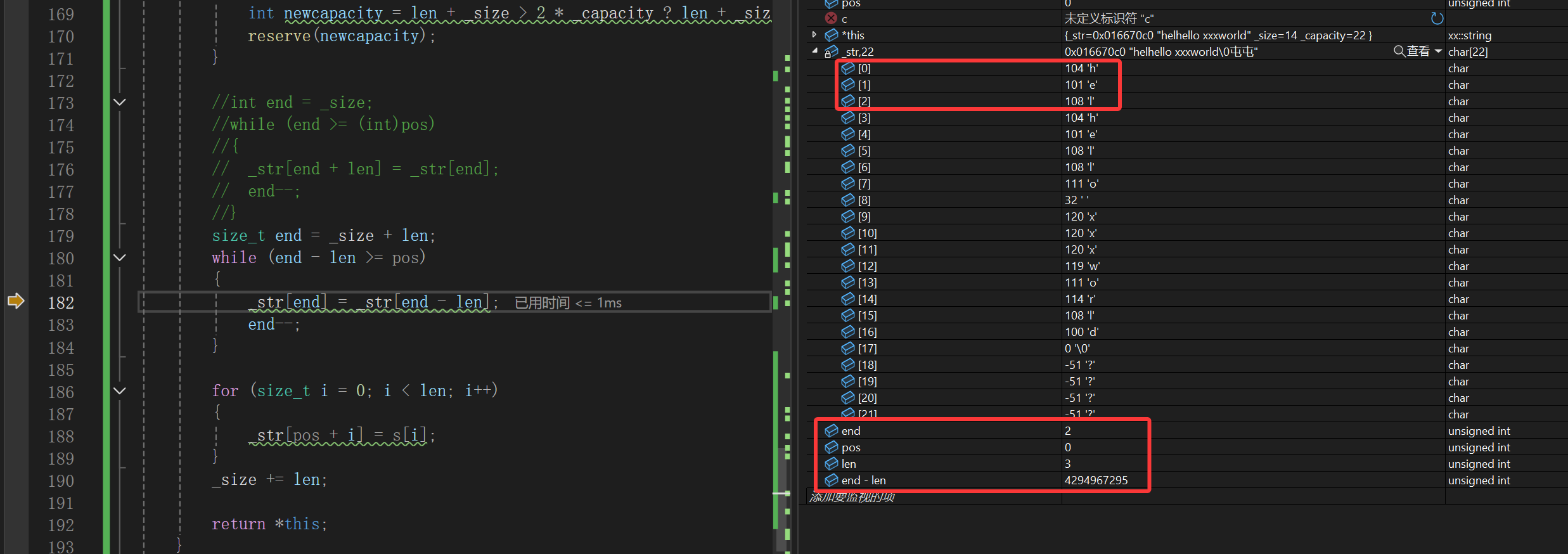
结果一改一运行又tm炸了,沃日哦。到底哪里搞错了,调试吧:

容量绝对够用,因为初始化string对象的时候是有多少字符创建多大空间+1,我们测试代码刚才刚测试过insert个字符,所以肯定是在那里就二倍扩容了,那就只能是我们下面的循环,也就是insert的核心代码出问题了。
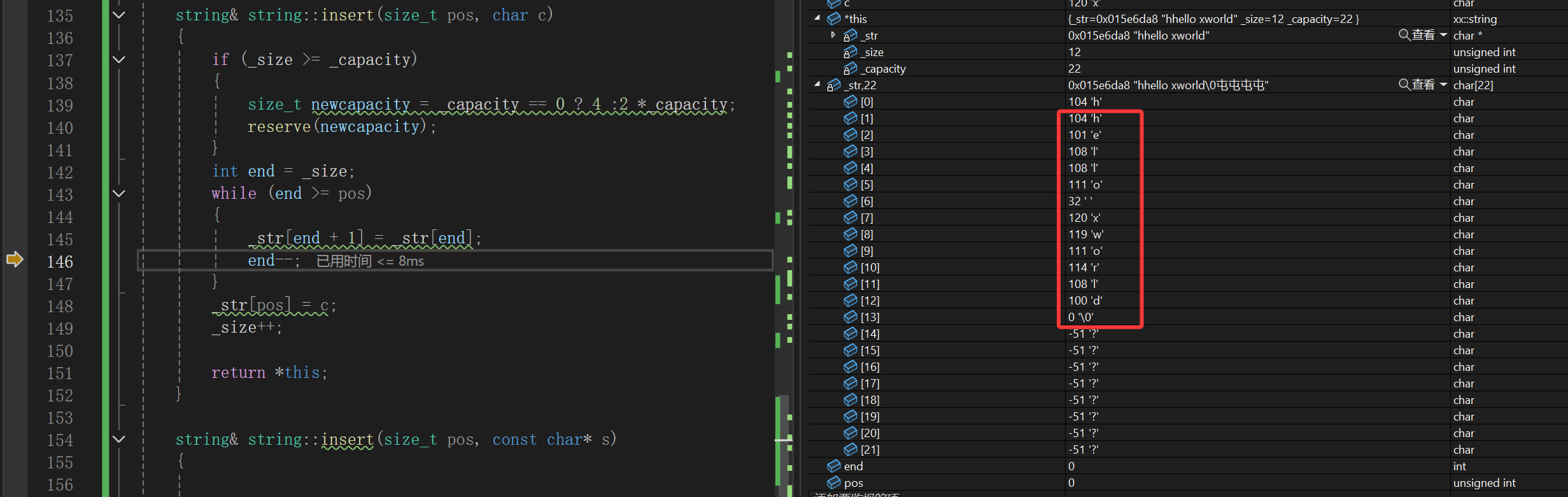
可以看到其实有效的基本都后移成功了,此时end还没有--,还是0,下一步:
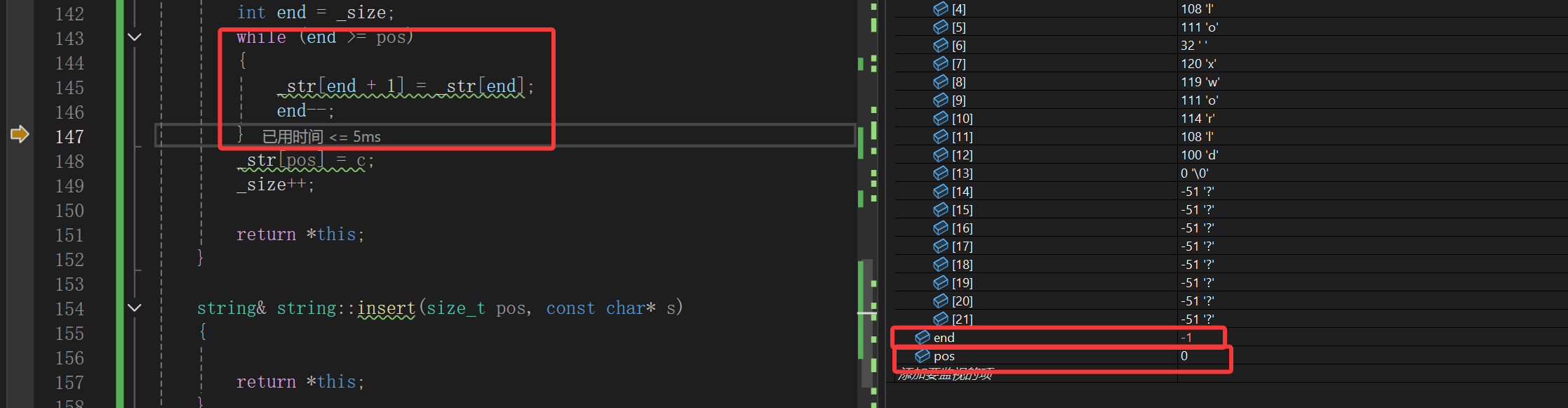
一看,end确实--了,那下一步就该退出循环了。结果:
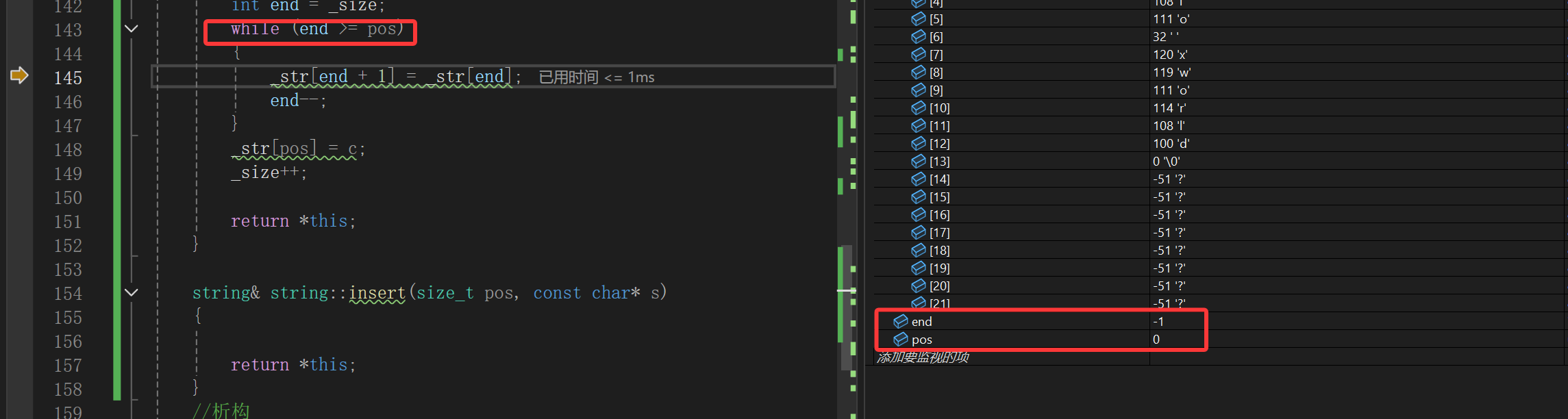
????
编译器抽风了吗,-1不比0小,搞什么飞机啊。

这段代码喂给ai以后给出了这样的解释。
我们以前了解的就是等级提升原则,什么叫等级提升呢?
这里等级的高低其实就是数据类型的大小,比如char和short,假如两个char = 127相加,为了能够不丢失数据,自动会将它们转换成int或者unsigned int计算。
这里就是另一个核心原则,无符号优先。什么叫无符号优先呢?
在32位操作系统下size_t就是4个字节,代表无符号整数,相当于unsigned int;在64位操作系统下size_t就是8个字节。
就说在32位操作系统下,int碰见unsigned int肯定就转换成unsigned int去参与计算了,这里我们的布尔表达式也算是计算了,只不过返回的是true/false。
更综合的理解就是在64位操作系统下同样的代码,大概率先等级提升到long,又因为size_t通常为unsigned long,所以又遵循无符号优先搞成unsigned long,同时运用两个规则。
这么理解的话其实又回到size_t的end这种情况了,永远无法到达的边界,就好像给了个while(true)去循环一样,程序当然就会一直跑下去了。
只能说把pos也弄成int了,但是注意,刚才忘写assert了,毕竟得保证传过来的下标有效性:
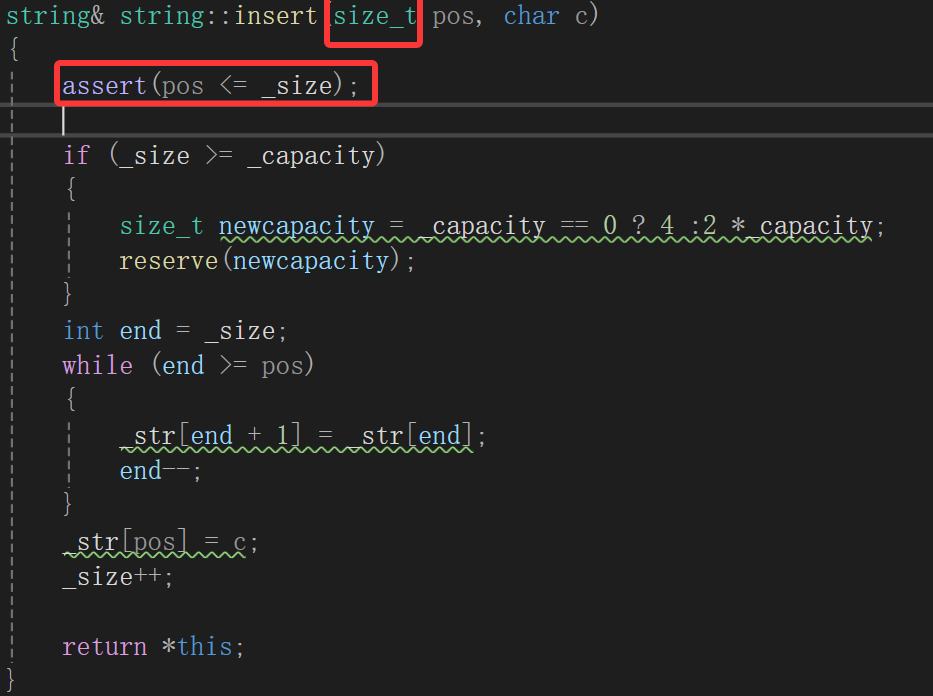
其实size_t的pos是合理的,如果用int还得再assert个pos >= 0,所以我们:
临时用一下。
最后代码为:
string& string::insert(size_t pos, char c){assert(pos <= _size);if (_size >= _capacity){size_t newcapacity = _capacity == 0 ? 4 :2 *_capacity;reserve(newcapacity);}int end = _size;while (end >= (int)pos){_str[end + 1] = _str[end];end--;}_str[pos] = c;_size++;return *this;}返回值倒是没有什么意义,对于insert一般而言,毕竟返回的也是它自己,还是说可能用来去赋值了,链式访问了,可能用得上。
另外一个版本:

我们做OJ题其实经常这么干,要不然用end和end - 1,要不然用end 和 end + 1。
这样的话其实想象一下,就算pos是0,只要当pos == end就直接跳出循环就行。
代码展示:
size_t end = _size + 1;while (end > pos){_str[end] = _str[end - 1];end--;}
就这里不一样,其实就是把循环的逻辑换了换。
②insert c-str
上来肯定还得先扩容,其实想了想,这个逻辑跟append那里的扩容一模一样,都是要往里面插字符串,所以扩容不多讲。
重点还是后移那块,依旧画图:
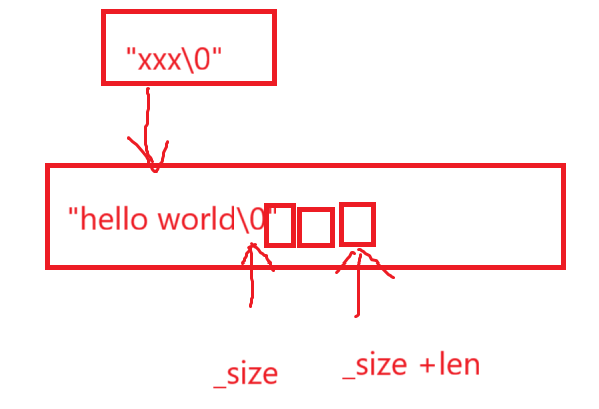
逻辑关系大概就是这样的,挪是比较费劲的,目标就是把包括pos后所有字符向后整体移动len次,当然,我们写代码找到目标位置直接赋值就行。
同insert char,我们第一种代码就写成:
string& string::insert(size_t pos, const char* s){assert(pos <= _size);size_t len = strlen(s);if (len + _size >= _capacity){int newcapacity = len + _size > 2 * _capacity ? len + _size : 2 * _capacity;reserve(newcapacity);}int end = _size;while (end >= (int)pos){_str[end + len] = _str[end];end--;}for (size_t i = 0; i < len; i++){_str[pos + i] = s[i];}_size += len;return *this;}
对着图一看就知道这里的end和pos的临界和上面第一种完全一样,所以除了内部逻辑都是照搬。
强调一点:

插入完不要忘记增加有效数据个数,我写的时候都忘了,还以为循环有问题了,结果发现确实好好的移动了,所以一下就意识过来了。
对照了对照上面,我忘了的原因大概率就是,上面插入一个我用的是:
这个肯定忘不了。
下面这段代码插入用的循环,注意力全在循环怎么写了,就忘了写有效数据个数改变了。
测试代码:
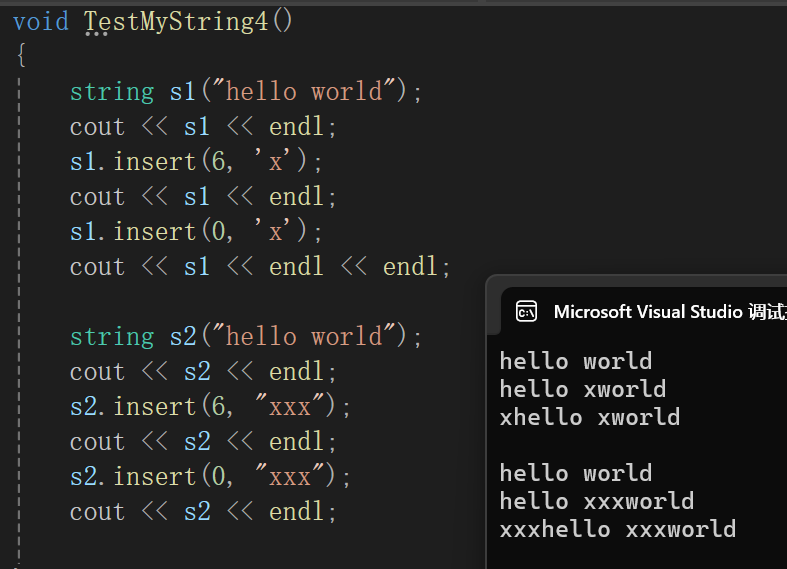
一般情况通过且头插通过。
第二种还是让end站后面来实现:
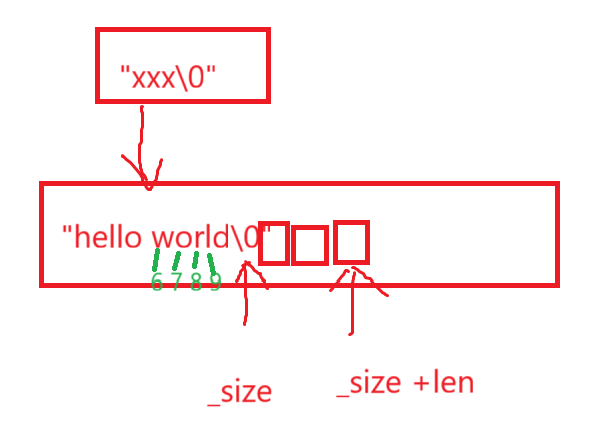
如果就按照这个pos的话,临界条件end指向的是9,而end - len指向的是6,很明显,这次还得进循环,这次循环的下一次才不进入循环。
尝试写一写:
string& string::insert(size_t pos, const char* s){assert(pos <= _size);size_t len = strlen(s);if (len + _size >= _capacity){int newcapacity = len + _size > 2 * _capacity ? len + _size : 2 * _capacity;reserve(newcapacity);}//int end = _size;//while (end >= (int)pos)//{// _str[end + len] = _str[end];// end--;//}size_t end = _size + len;while (end - len >= pos){_str[end] = _str[end - len];end--;}for (size_t i = 0; i < len; i++){_str[pos + i] = s[i];}_size += len;return *this;}经测试,极端代码也就是头插不管用,大概率还是循环的问题。
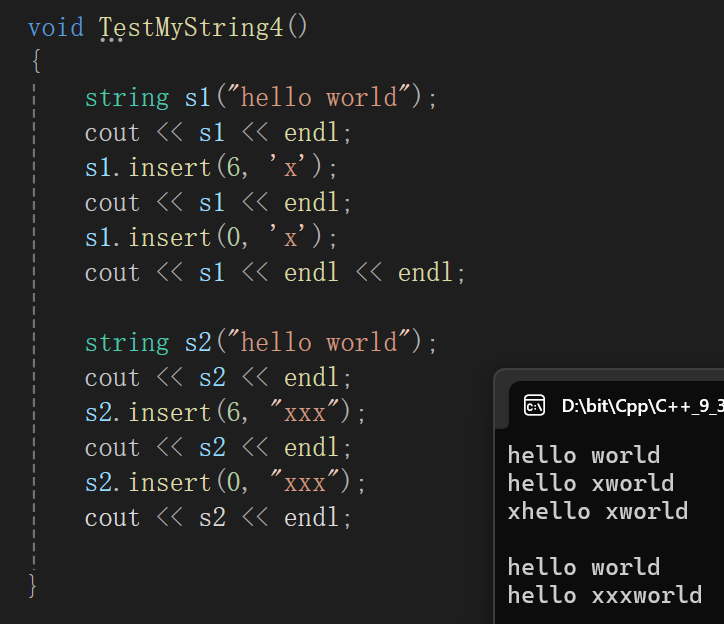
给这种情况下的代码画个图:
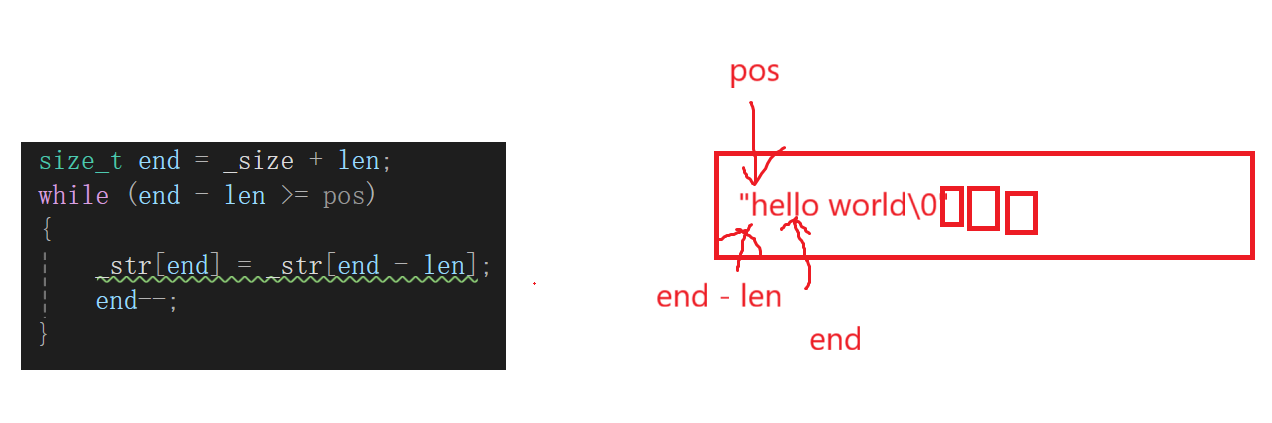
从这两张图都可以看出来又是size_t在作妖,最后一次end - len反倒成整型最大值了,如果还是用int呢:

直接就成了:
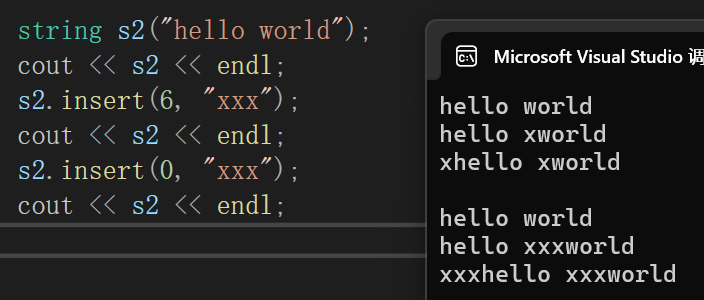
但是第二段代码我们不这么写,看看能不能只改条件不强转完成任务:

我们分析的条件是什么,临界是end - len == pos时候还得继续嘛,什么时候终止呢,end - len == pos - 1嘛,所以条件这么写:
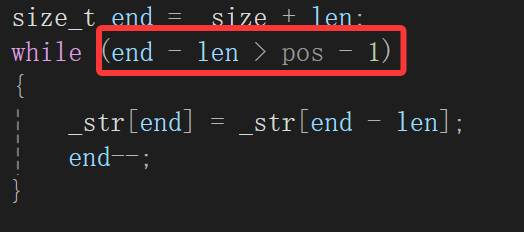

结果又搞错了,其实这个问题一眼就看出来了,pos如果传0,那么pos-1就又成整型最大值了,也就是说没有进入循环,直接拷贝了,这样的话你就会覆盖数据并且读随机值。
我们这么写最核心目的就是不要让size_t的值变到-1,而end最后停留在2,不会说存在这种情况,所以为了pos那边的值也不变到-1,干脆玩个左右两边同时加:
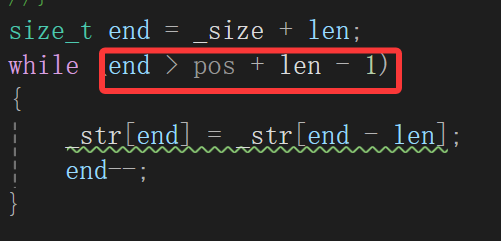
一测试:
真是颠沛流离啊。
特别是最后这一点,其实数学上看没啥毛病了,但是计算机的计算还有问题,令人汗颜啊。
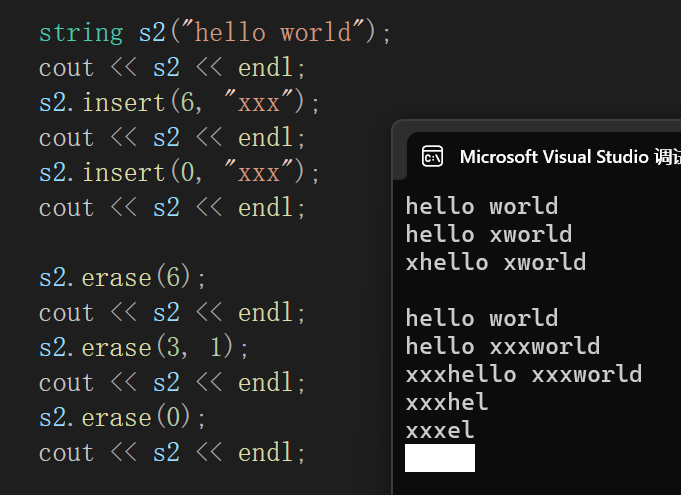
7.erase
![]()
就去实现库里面这个erase,哪个呢?
pos位置开始删除len个字符,如果不传pos默认从头开始,如果不传长度,默认从pos位置开始直接删完。
所以先不写erase的代码,我们先实现一个npos,其实也简单,也就是个size_t = -1:


在头文件中声明,在实现文件中定义并初始化。
我们也模仿类,声明成public的static const对象,当成类常量来用。

至于为什么类外必须不能加static其实我没看懂说了个啥,目前只能当成语法就是这么规定的来看了。
erase分为两种,一种是pos后的全部删除,(因为这种不用考虑那么多,所以单独拿出来);一种是pos后部分删除,这玩意可就得一点一点搬形成覆盖,而且要补个\0,最后size-len。
第一种情况随便找出来图就能看出来内部的逻辑。

_size = pos,并且将_size位置变为\0。
可不要想着把pos后的数据全部删了,C/C++都是不允许的,如果直接删完pos后的,就相当于顺序表的尾删,顺序表的尾删就是移_size。
第二种情况:

假设这里pos的三个不要了,你不要了以后还是说,不能真删数据,直接让后面的过来覆盖,这种情况直接调memmove就行,标准的memmov的场景。
找好下标就行:

string& string::erase(size_t pos, size_t len){assert(pos < _size);if (len == npos || len > _size - pos){_size = pos;_str[_size] = '\0';}else{memmove(_str + pos, _str + (pos + len), _size - (pos + len) + 1);_size -= len;}return *this;}看着代码没多少,实际上真是头脑风暴,特别是memmove,盯着例子算了两个指针,又算了到底拷贝多少。
一测试没问题:
8.find
![]()
![]()
依旧实现这两种,先实现查找字符的,再实现查找字符串的。
find的逻辑是从pos位置开始找,找的对象是第一个参数,最后返回第一个参数在字符串中第一次出现的下标。
①find char

随便画个图,很明显得从pos位置开始遍历,如果在循环内部找到目标的字符直接return下标,如果循环完,即循环到字符串末尾也没找到,直接return npos。

size_t string::find(char c, size_t pos)const{assert(pos < _size);for (size_t i = pos; i < _size; i++){if (_str[i] == c){return i;}}return npos;}代码逻辑很简单,就是写一个循环从pos位置遍历到字符串末尾,每次都去检查是否符合要求,如果到字符串末尾都没有找到,那就直接return npos。
测试代码:

②find c-str

其实可以直接调C库里面的strstr,也就是底层暴力直接查找。需要注意的是最后返回的是指针。
strstr的原理大概就是,从str1位置开始对比*str1和*str2,一旦找到相同的,就让*str1和*str2站下,再创建两个指针用循环看看是否遍历到str2的末尾都是相同的。
其实也就是外层while遍历str1和str2,内层找到相同的while一直对比到str2的末尾,如果相等直接返回现如今的str1的位置,如果存在不等就break继续移动str1和str2。
循环套循环是我们最不想见到的情况,不过这里套用倒是无可厚非,毕竟除了这个法子我好像也没啥其他的法子。
size_t string::find(const char* s, size_t pos)const{assert(pos < _size);const char* ret = strstr(_str + pos, s);if (ret == nullptr)return npos;elsereturn ret - _str;}
测试符合要求。

9.substr
拷出来一份子字符串
这个函数的模拟实现,函数的逻辑反倒是最简单的,麻烦事在于:
①拷贝构造
返回的是string类型,也就是说可能根据参数创建个字符串,最后返回,因为创建的这个字符串在函数内部属于局部变量嘛,出了作用域直接就销毁了,你总不能传引用返回指向一个局部变量吧,这玩意就像野指针一样的野引用。
那就传值返回,传值返回都需要拷贝一份临时变量,也就是创建一个临时字符串,我们上面可没有实现拷贝构造吧,没有实现的情况下,想想需要不需要写一个。
到时候返回的是一个局部变量ret的拷贝,ret有_str、_size、_capacity,有这么多成员变量重点就是_str,如果浅拷贝的话相当于到时候返回的是ret._str指向的空间,因为浅拷贝只会把ret._str存的地址拷贝走,但是出了函数ret就会销毁,那这个时候tmp._str也指向这部分,浅拷贝看来不够用(也就是编译器默认的复制粘贴的拷贝构造不够用)。
所以拷贝构造需要自己写一份:
string::string(const string& s){_size = s._size;_capacity = s._capacity;_str = new char[_capacity + 1];memcpy(_str, s._str, _size + 1);}②split_url函数
这玩意是啥呢,url就是我们通常说的网址,比如随便找两个:
我经常用的C++的库的:

ai的网址。
这些网址都是固定格式,大概是:
协议://主机名:端口号/路径?查询参数#片段标识
组成都是像树一样,一层一层的。
为什么在这里提出来这个玩意呢,后面自然会了解,现在提是为了这样一段代码:
void split_url(const string& url){size_t i1 = url.find(':');if (i1 != string::npos){string ret = url.substr(0, i1);cout << ret << endl;}size_t i2 = i1 + 3;size_t i3 = url.find('/', i2);if (i3 != string::npos){cout << url.substr(i2, i3 - i2) << endl;cout << url.substr(i3 + 1) << endl;}cout << endl;}
这段代码可以将你提供的网址(网址实质上其实就是属于string类嘛),利用string内部的find和substr函数,根据url的组成规则(目前不需要懂),输出得到的每段内容。
其实就是借用这样的函数来综合测试find和substr。
③模拟实现
测试代码找好了,返回值问题也考虑到了,现在就是写substr的内部逻辑了,其实也简单,毕竟从pos一直拷贝到len的长度就行,只不过如果太长特殊处理一下就行:
string string::substr(size_t pos, size_t len)const{assert(pos < _size);if (len == npos || len >= _size - pos){len = _size - pos;}string ret;ret.reserve(len);for (size_t i = 0; i < len; i++){ret += _str[pos + i];}return ret;}这段代码进去保证了len长度的合理性以后就创建了个局部变量接收会从s中拷贝的目标长度的字符串,并提前reserve,避免连续扩容。
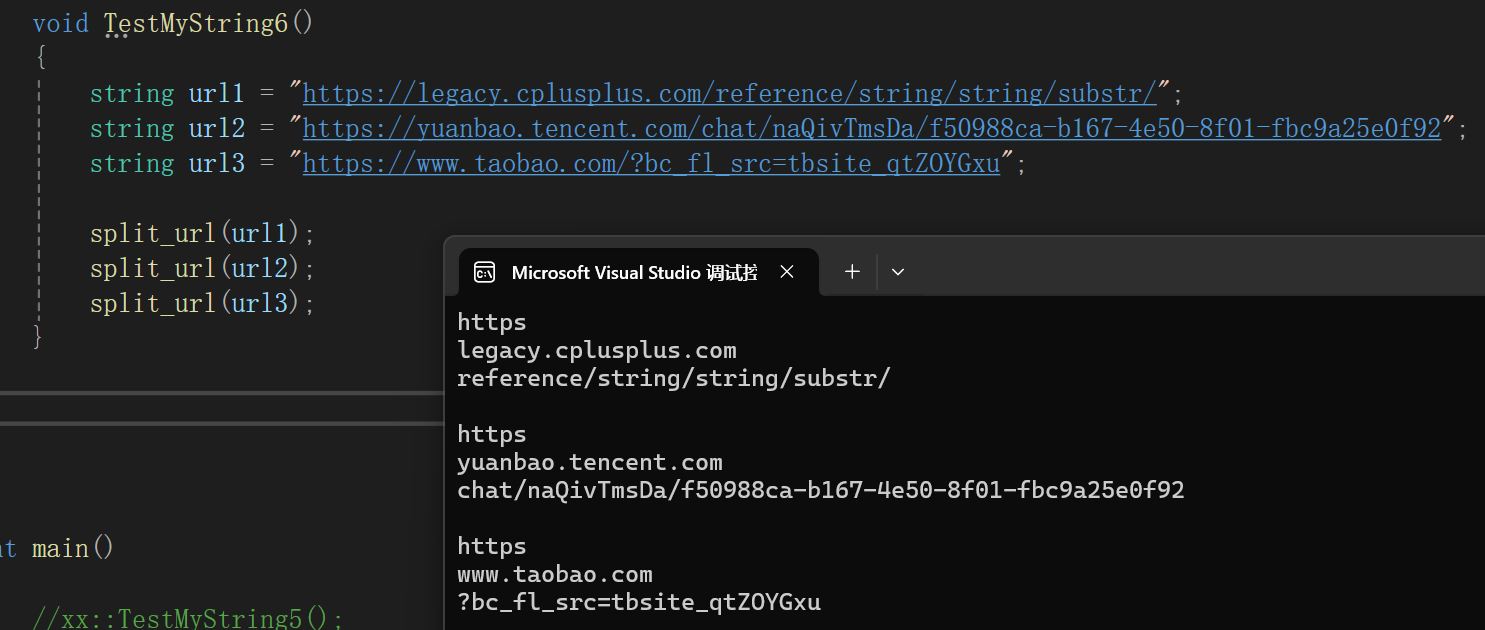
测试完没啥毛病。
四、string类的逻辑运算符重载
首先说明,我们不再像库里面一样搞个什么非成员函数,说过了,他也就是为了个const char*可以当第一个参数,不多展示了也就。
逻辑运算符的实现其实老简单了,我们Date类实现逻辑运算符严格来说其实就只实现了个<和==,其它的运算符全部都是对于<和==的一层或多层封装。
//relational operatorsbool string::operator==(const string& s)const{if (_size == s. _size){for (size_t i = 0; i < _size; i++){if (_str[i] != s._str[i]){return false;}}return true;}return false;}//注意比较的重点是ASCII码,可不是长度bool string::operator <(const string& s)const{size_t s1 = 0, s2 = 0;while (s1 < _size && s2 < s._size){if (_str[s1] > s._str[s2])return false;else if (_str[s1] < s._str[s2])return true;s1++;s2++;}//至少有一个遍历完了,前n个字符相同,谁长谁大if (_size < s._size)return true;elsereturn false;}bool string::operator<=(const string& s)const{return (*this < s) || (*this == s);}bool string::operator>(const string& s)const{return !(*this <= s);}bool string::operator>=(const string& s)const{return !(*this < s);}bool string::operator!=(const string& s)const{return !(*this == s);}
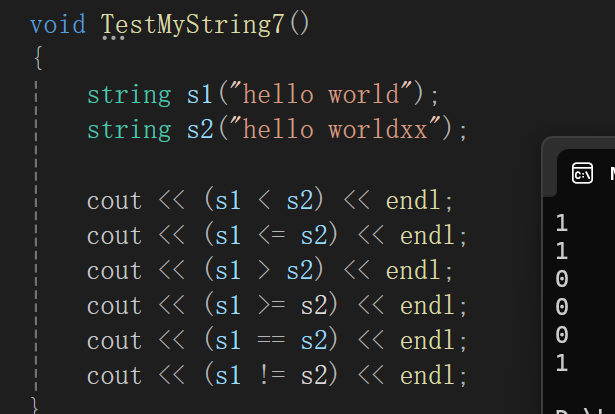
测试也没毛病。
五、补充模拟实现
1.流提取>>运算符重载

这种操作符库里面标准是这样的。
为什么在完成模拟实现之前先看看标准库里面的输入输出结果呢?
cin在底层读取的时候不管你手动输入的内容是什么它都将将其视为一个字符序列,只不过根据第二个参数的类型
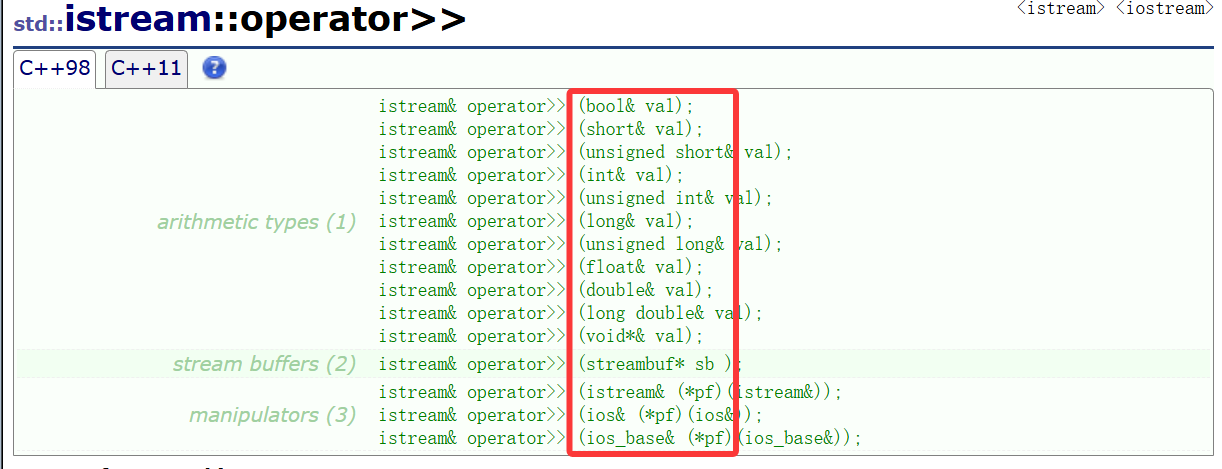
每种类型都写了运算符重载,在函数内部通过一系列操作向你的目标类型转换。
可以将cin想象成一个字符指针一样的东西,输入的内容都先被放到一个输入缓冲区的地方,然后cin作为字符指针就会一个字符一个字符的去里面读取,当然,终止的逻辑就得依赖函数内部实现了,毕竟不同类型的读取要求不一样。
按照对上述描述的理解有:
istream& operator>>(istream& in, string& s){char ch;cin >> ch;while (ch != ' ' && ch != '\n'){s += ch;cin >> ch;}return in;}
大概逻辑就是,既然你底层就是一个一个字符去读的,那我干脆也一个一个读,并且插入到字符串里(字符插入字符串倒是不麻烦,因为不需要类型转换),如果碰见空格和换行符其实大概率就是代表着一个对象读取的结束,到了另一个对象读取了,return in是为了支持连续读取。
但是一测试:
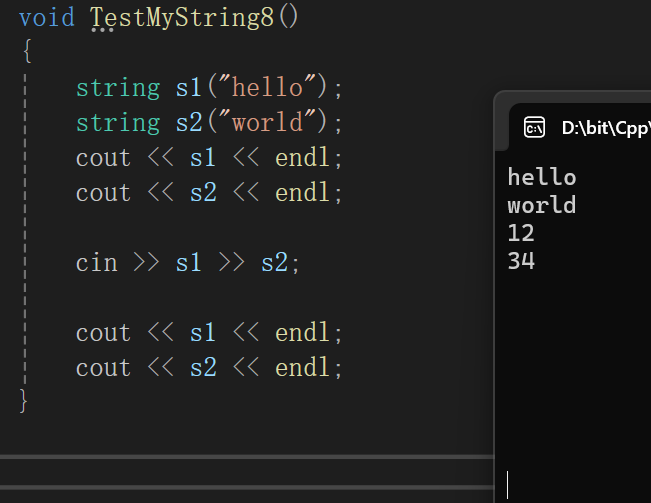
把回车敲烂了也是一直在读,我就不理解了?
直接调试看吧:
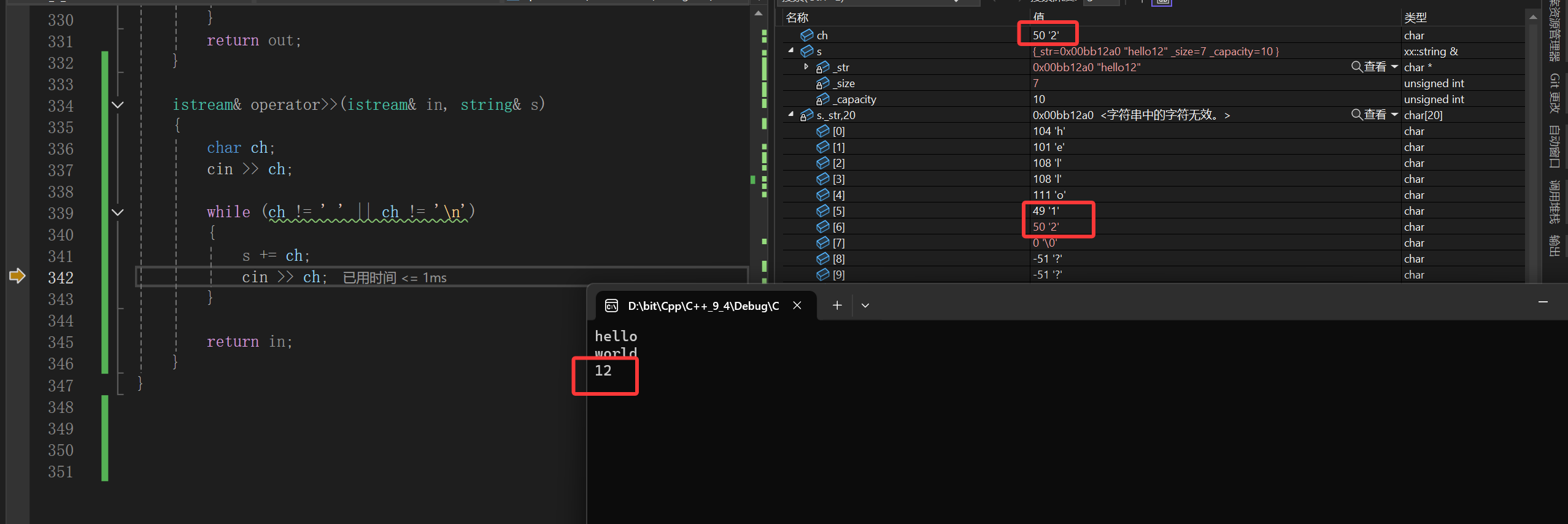
很明显读12都没啥毛病,这个时候我敲个回车:

按理来说你应该给我完成读取了,该结束循环了,但是:
再按F11强制跳到窗口,好像让我必须再输入值一样,反正回车都敲了,干脆把下一个对象的数据也敲出来:
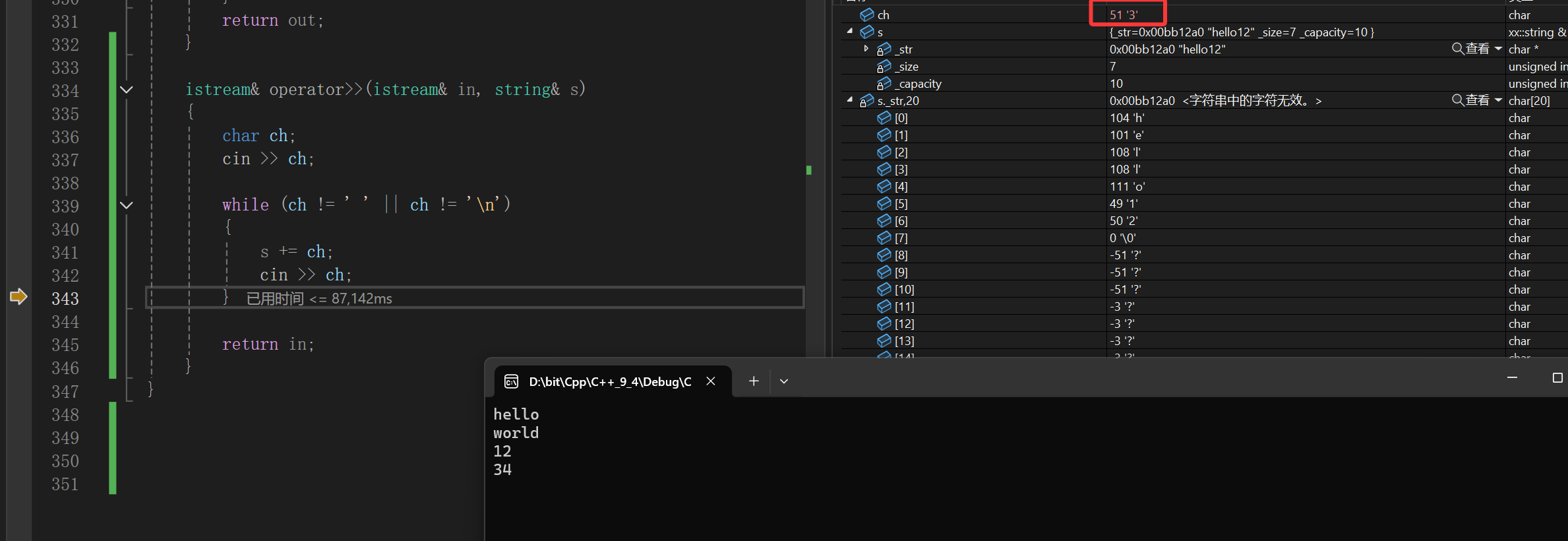
结果按理来说ch会读到'\n'然后直接停止循环,可是它却读出来个3,把回车直接给我跳过了,难道空格也是这样的吗,经调试是这样的。
为什么会变成这样子呢?
cin在使用流提取运算符>>进行读取时,默认自动跳过空格、制表符(tab)和回车('\n')这些空白字符,直到找到下一个非空白字符才开始读取。这是cin>>的默认行为
其实这个也合理,就好像我们之前fread函数最后要用FILE*的指针接收,每次读取以后,读取文件的指针也是自动后移的,因为读过的数据不能让用户重复读啊,不然永远到不了EOF。
这个道理也是一样的,明知道空白字符就是分割,我为了下一次的读取,当然就得自动跳过了。
这就苦了我们了,我们这样干的话直接搞得就永远跳不出循环了,你给多少数据它就能读多少,理论来说其实跟个无底洞一样。
所以为了能够读到空白字符,我们调用库里的:

get函数的特点是逐个的从缓冲区读字符,每读一个就从缓冲区中移除了,而后那个读取的指针自动后移。
借助不断使用get函数,读取数据并读空白字符终止循环。
另外为什么调第二个:


如果你传过来一个字符,那到时候我get读到的字符,我就会放到这个字符里。
所以修改后的代码:
istream& operator>>(istream& in, string& s){char ch;cin.get(ch);while (ch != ' ' && ch != '\n'){s += ch;cin.get(ch);}return in;}其实还是有点小问题:
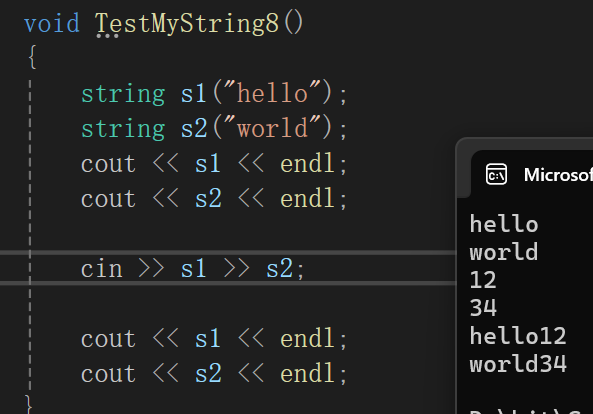
可以看到标准库将s1,s2作为接收数据的地方的时候,直接就把字符串清空了,所以干脆我们也玩个清空再插入。
string库里面确实有这个函数,不过毕竟逻辑没多难:

void string::clear(){_size = 0;_str[_size] = '\0';}还是那个道理,内存不清,只清有效数据个数,而顺序表实现这种操作其实就是改_size。
嘿嘿,直接成了,至少这个例子看起来跟库里面一模一样的。嘻嘻![]()
2.getline函数
实现了流提取和流插入,自然而然就得再搞个这个函数,前几天做OJ题的时候其实就见识过了,主要就是读到空格也不停止,直至碰见'\n'或者说指定的分界符才会停止。
其实想想,基本逻辑跟>>差不多,只不过分界符默认是'\n',或者传参指定的。
参考库里面的参数和返回值:
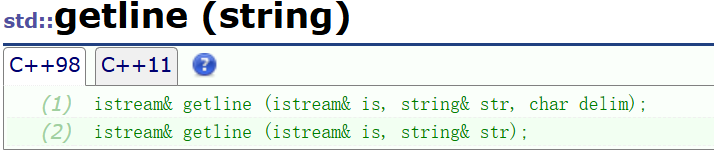
大致上就是这样的:
istream& getline(istream& in, string& s, char delim){s.clear();char ch;cin.get(ch);while (ch != delim){s += ch;cin.get(ch);}return in;}其实也就改了个while循环的条件,当然,声明部分:
![]()
缺省值毫无疑问就是\n。
3.>>重载和getline的问题与解决方案
可能这个时候就有人说,你找茬是吧,你让我根据空格和换行,或者说根据换行等字符停止读取了,还有啥问题。
内存开辟。
这两个函数里开辟了个char 的ch就不多说了,忽略不计了都,但是s += ch实际上是push_back的封装,而push_back前自然会检查内存够不够用,不够用得扩容,这里就涉及到内存开辟问题,比如:
先将reserve函数的调用显示出来:
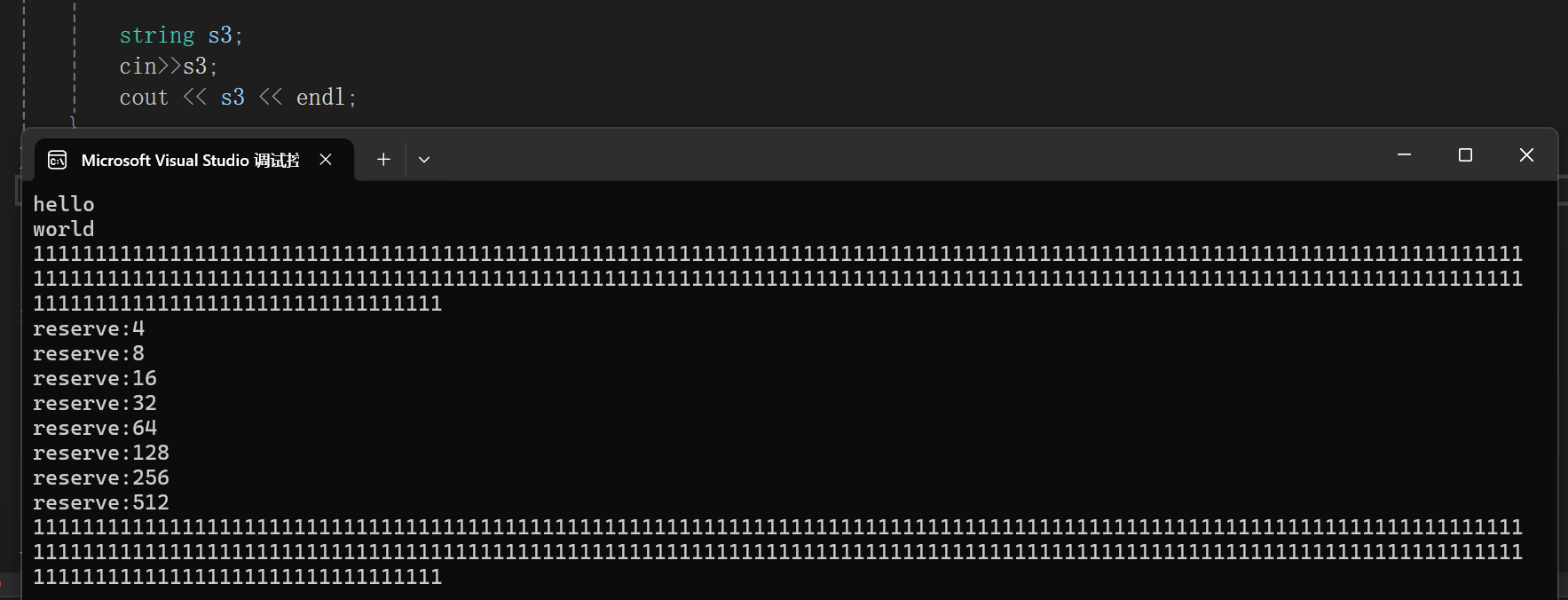
如果需要输入的字符串超级长,我们给的又是一个空串,一旦串非常长,那么内存空间的开辟就会非常频繁,为什么说不让频繁调用内存呢?
我们C++扩容的方法是什么:

直接new了,内存都是连续调用的,假如你申请了一块空间以后,不够用了,恰好后面的空间被用了,那你就得再去找符合大小的空间,就像这样:

如果把内存当成一个玉米的话,你一会咬一口上边,一会咬一口下边,一会咬一口中间,这会造成内存空间被申请的不连续,也就是常说的,反复申请会导致堆空间的碎片化。
所以开辟内存这个动作越少越好。
有的人可能就说,那我提前reserve呗,但是都说了是提前,千人千面,每个人需要输入的值是不等长的,你reserve的过大就是内存的浪费;reserve的过小其实跟没有提前reserve差不多,比如你就reserve个8,其实输入个356字符,那你reserve其实跟没有一样。
下面提供一个思路解决这个问题:
istream& operator>>(istream& in, string& s){s.clear();char ch = in.get();char buffer[128];size_t i = 0;while (ch != ' ' && ch != '\n'){if (i == 127){buffer[i] = '\0';i = 0;s += buffer;}else{buffer[i++] = ch;ch = in.get();}}if (i > 0){buffer[i] = '\0';s += buffer;}return in;}大概解释一下,创建一个字符数组,就好像我们给的缓冲区一样,不是直接暴力往字符串里加,如果buffer马上满了,为了能够当成const char*来利用+=,给最后一个值赋为'\0'。如果buffer还没满,那就不断插就行。
当然,跳出循环以后可能是buffer存了一些值了,把所有不是空白字符的字符读完了,结果碰见空白字符了,这个时候得清空buffer里的值,也就是再插到s里,这样就可以每127或者说,buffer的大小-1个字符大小去插入,这样大概率有多少开多少:

利用的是栈区的内存,因为栈区内存人如其名,就是像我们数据结构里的栈一样去管理内存,用多少开多少,一旦出了局部域就直接返还给操作系统,这样将数据暂存到栈区就避免了反复往字符串里存而导致的多次内存空间的开辟。
当然,buffer给的越大肯定将来申请空间大概率就是只申请一次,毕竟buffer不存满就不可能插,有可能到第一个空白字符的大小,比buffer小的多。
不过凡事有利有弊,当然不能往死里开辟buffer,你给几个亿说不定把栈区内存干干了都,重点是够用就行。
4.赋值运算符operator=重载
string& string::operator=(const string& s){if (*this != s){_size = s._size;_capacity = s._capacity;char* str = new char[_capacity + 1];memcpy(str, s._str, _size + 1);_str = str;}return *this;}老老实实赋值/复制就对了。
5.现代版拷贝构造和operator=重载
经典或者说传统的拷贝构造和=运算符重载都有:

自己开空间的操作。
现代版的拷贝构造和=重载当然不会说不需要你再申请空间了,只不过玩了一个小花招,把申请空间甚至是改_size等成员函数都封装起来了。
①现代版拷贝构造
void string::swap(string&s){std::swap(_str, s._str);std::swap(_size, s._size);std::swap(_capacity, s._capacity);}string::string(const string& s){string temp(s._str);swap(temp);cout << endl;}
简单来说就是根据s的_str去创建一个临时的string,也就是调用string的构造函数来代替我们自己开辟内存;然后让调用拷贝构造的string对象和temp互换即可,也就是拷贝构造的*this和temp互换。
画图再加深一下理解:

初始情况就是这样,s2还没进入拷贝构造初始化可以说就是个空壳子。
然后进去先创建个temp:
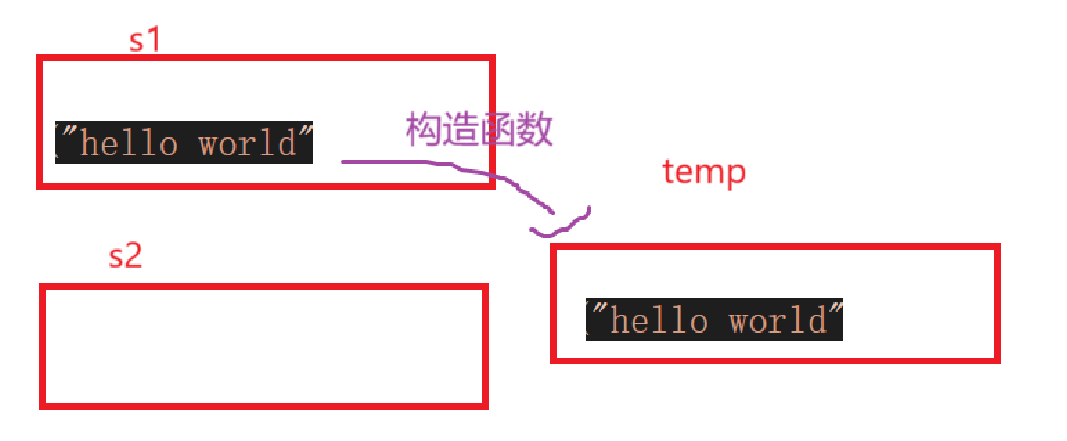
因为构造函数其实也是深拷贝嘛:

所以temp和s1指向的不是同一块内存空间,除了指针以外其他所有数据相同。
这个时候直接让s2殖民掠夺:

进行到这一步其实基本已经完成任务了。
不过还会隐式调用析构,去析构temp这个临时对象,这个对象的数据现在是s2的无用数据,所以随便扔,这样就完成了拷贝构造。
与传统对比:
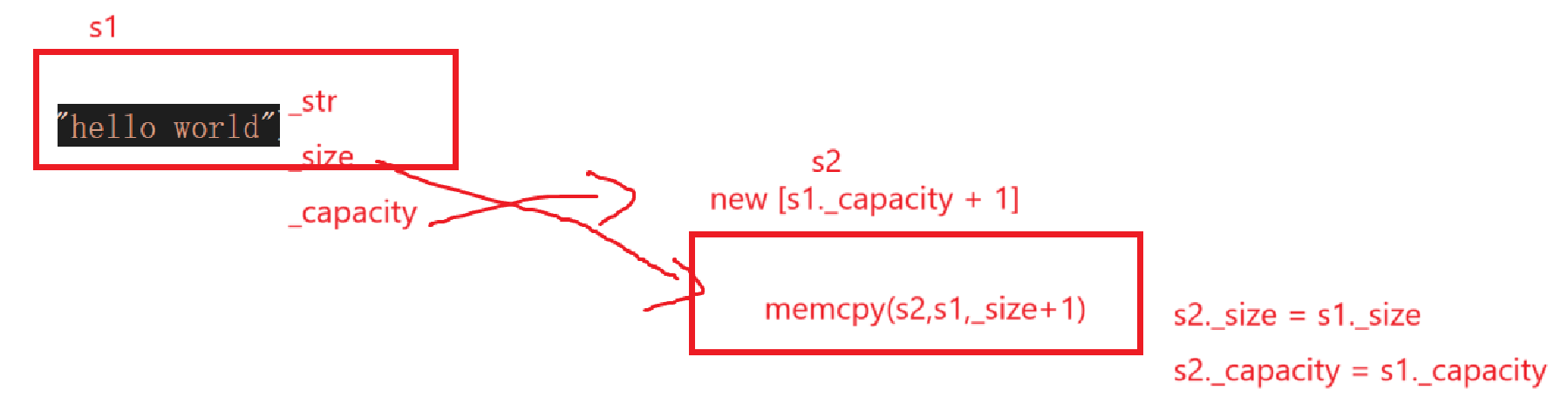
底层开空间赋值基本上可以说压根没变,变的就是我们写代码的代码量,而且这样一来如果一旦出错,只需要去找构造函数的问题。
②现代版operator=重载
思路超级像拷贝构造:
string& string::operator=(const string& s){if (*this != s){string temp(s);swap(temp);}return *this;}swap实际上有俩参数嘛,参数必须都是string类的,那我先拷贝构造出来一份s的临时拷贝temp,再让temp所有申请出来的数据跟*this互换。
比如:
相当于函数内部把s3内的空串替换为temp的拷贝了,temp拿着空串的数据随便析构。
当然还能再化简:
string& string::operator=(string temp){swap(temp);return *this;}
传值调用就会调用拷贝构造,相当于直接把拷贝构造哪一步又隐藏起来了,看起来就只有swap(temp)。
6.string类的swap算法

我们在实现现代版拷贝构造和=重载的时候其实是自己写的函数,而不是调用库里的swap,这是为什么呢?
拜读库的描述:

库里面的swap函数c(a)这句其实是调用的拷贝构造。
如果按照现代版拷贝构造,用我们自己写的swap直接就把底层的指向或者值换了;如果用库里面的swap事就大了,进去先拷贝构造创建个c,我们现代版的拷贝构造先借用构造复制倒是没事,第二步就是swap又要调拷贝构造,成循环了不是。
如果现代版=重载里只有swap用的是标准库模板生成的,那么想想啊。
- 传值调用一次拷贝构造
- 交换第一步c(a)一次拷贝构造
- 两个赋值运算符重载等于是2*2个拷贝构造
当然,可能存在编译器的优化,反正调用库里的swap模板函数就得浪费好多好多资源。
而且就算是传统版的拷贝构造和=重载,其实swap里的每一句都在经历深拷贝,这也就是说的现代版其实可以视为传统版的封装。
这就是为什么string类里其实自带swap算法:
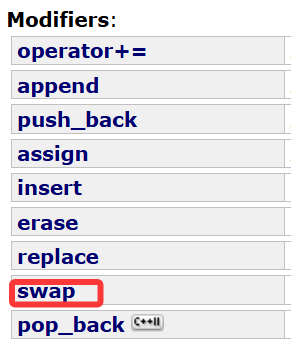

底层逻辑大致就是我们上面实现的那种,直接针对string类的每个成员变量互换。
这时候又有人问了,那么兄弟,为什么非成员函数里面还有一个swap:

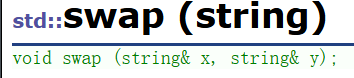
其实非成员的swap其实是成员swap的一种封装,类似于:
void string::swap(string&s){std::swap(_str, s._str);std::swap(_size, s._size);std::swap(_capacity, s._capacity);}void swap(string& s1, string& s2){s1.swap(s2);}
首先上面讲清了,绝对不能用库模板给的swap,因为涉及多次拷贝构造和赋值运算符重载;
然后就回到这里了,实现成成员函数的能够完成我们的要求这个是没啥毛病的。
但是如果不看标准库或者没有像我们这样来模拟实现的话,很容易就会去调用下面的swap,想的可能是直接用算法库里的swap,也就类似于:
swap(s1,s2);
其实没毛病,一般swap都是这么用的,所以就实现了下面的swap,这样的话与模板构成重载,在模板那块我们说过,有现成的有模板,而且实现的功能一样,我们用的就是现成的。
所以这就是为什么站在string角度来看有三个swap函数。
模板的不好用,多次深拷贝;
成员函数不符合我们使用习惯;
最终的非成员swap即符合我们的使用习惯又避免了深拷贝还起到了避免模板生成函数的作用。
六、强调
1.string库提供的字符串转其它类型/其他类型转字符串函数

这些实现没讲,模拟实现提一嘴吧,毕竟可能能够用得到的接口也算是。
目前仅作了解,知道有这样的接口,如果需要用的到,比如程序了OJ了,来查库即可。
2.VS下的string对象的优化

这样一段代码首先我们知道,sizeof只会去计算这个对象有多大,只跟成员变量有关系,所以两次sizeof的值是一样的,但是:

成员变量只有指针和两个size_t,在32位操作系统下都是4个字节按说不应该是给12个字节吗?
调试仔细看看:
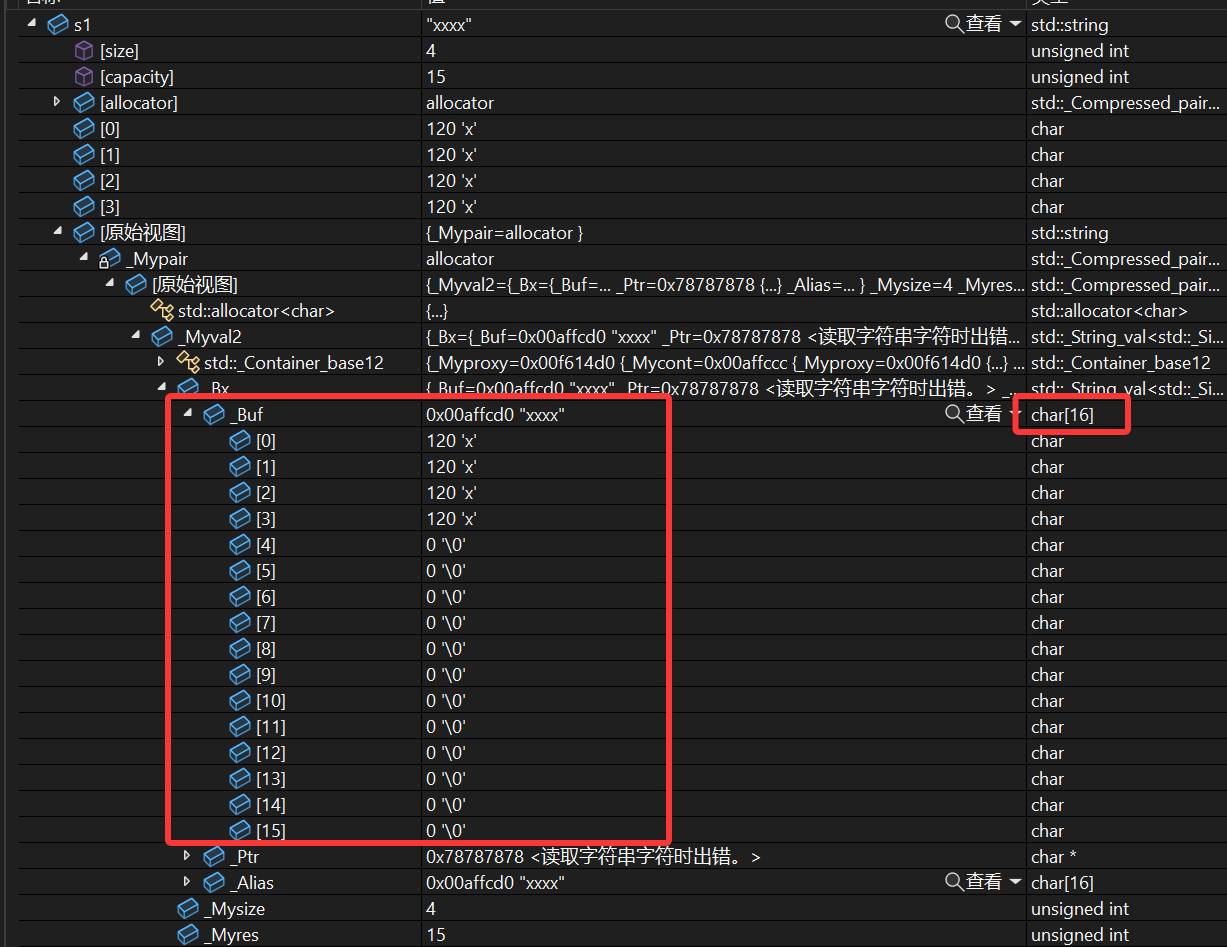
一直点点点,其实底层对于string类库里面,或者说VS对于库里面的string类多加处理了一个char buffer[16],因为有的字符串太短嘛,出于不想申请堆上的内存以及防止内存碎片化,于是在栈上申请了一个16个字节的数组,如果不超过16个字符,就存到buffer里,如果超过了再存到_str里,我们测试样例给的s2超过16个了,所以:
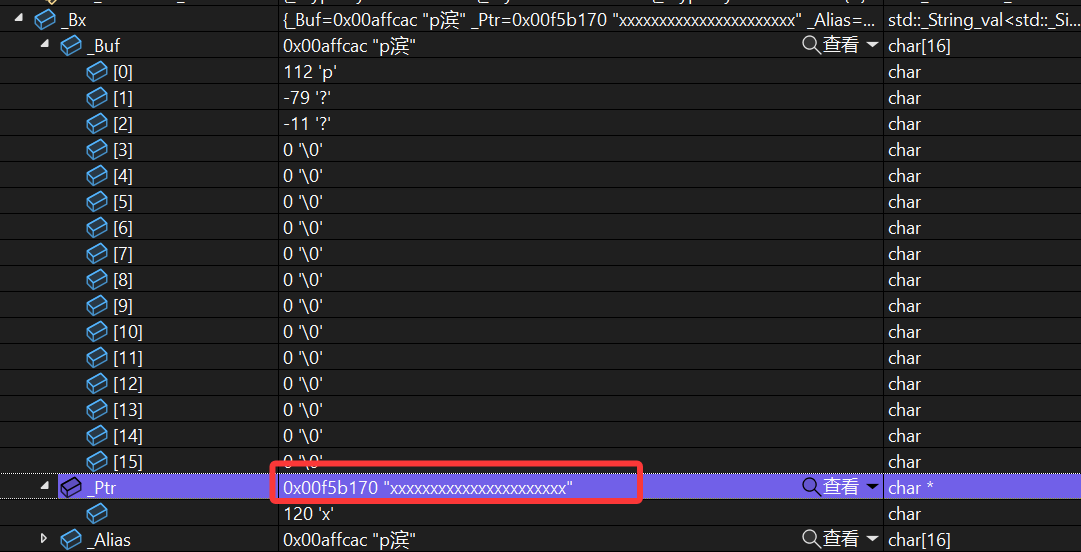
可以看出来区别。
这就是为什么sizeof出来28个字节,因为还加上了个数组(都是4的倍数,基本没有说为了内存对齐空出来的字节没有用,完全紧紧贴在一起了)。