激活函数:神经网络的“灵魂开关”
在人工智能与深度学习蓬勃发展的今天,神经网络已成为推动技术进步的核心引擎。当我们揭开神经网络神秘的面纱,会发现其中一个看似简单却至关重要的组件——激活函数(Activation Function)。它被誉为神经网络的“灵魂开关”,决定了神经元是否应该被激活,并将输入信号转换为输出信号。没有它,再深层的神经网络也只是一堆线性回归模型的堆叠,无法理解世界的复杂与非线性。
一、为什么需要激活函数?
要理解激活函数的重要性,我们首先要回答一个问题:如果没有激活函数会怎样?
一个神经元的基本计算是:对所有输入进行加权求和,再加上一个偏置项(输出 = Σ(权重 * 输入) + 偏置)。如果不在这个结果后面添加激活函数,那么每个神经元的输出就仅仅是输入的线性组合。
线性模型的局限:无论你堆叠多少层这样的线性变换,其最终效果等价于一个单一的线性变换。这意味着网络无法学习到复杂、非线性的数据 patterns,比如识别一张图片是猫还是狗,或者理解一句话的情感。
引入非线性:激活函数的作用就是在这个线性计算之后,施加一个非线性变换。正是这种非线性,使得神经网络能够无限逼近任何复杂的函数,从而成为强大的通用函数逼近器(Universal Function Approximator),能够处理图像、语音、自然语言等高度复杂的任务。
简而言之,激活函数为神经网络提供了非线性建模能力,是其能够“深度学习”的基石。
二、常见的激活函数家族
多年来,研究人员提出了多种激活函数,各有其特点和适用场景。以下是一些最具代表性的成员:
1. Sigmoid(S型函数)
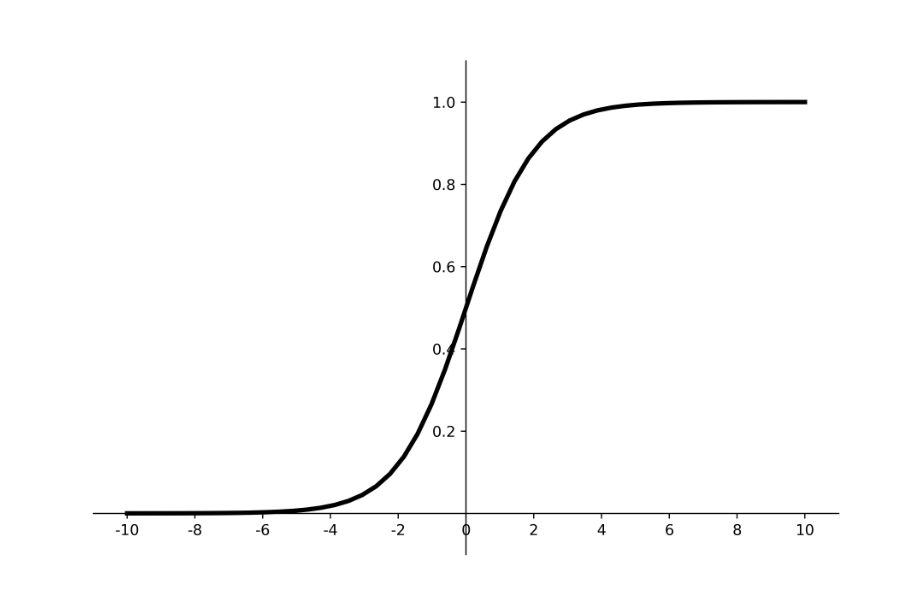
公式:
f(x) = 1 / (1 + e^(-x))输出范围:(0, 1)
特点:它能够将任何实数“挤压”到(0,1)之间,非常适合作为输出层激活函数用于二分类问题(输出可以理解为概率)。
缺点:
梯度消失:当输入值非常大或非常小时,函数的梯度会接近于0。在反向传播过程中,梯度会逐层相乘,导致靠前的网络层梯度几乎不变,权重无法有效更新(即梯度消失问题)。
非零中心:其输出恒大于0,这会导致梯度更新时出现“之”字形下降,降低训练效率。
计算耗时:涉及指数运算。
2. Tanh(双曲正切函数)
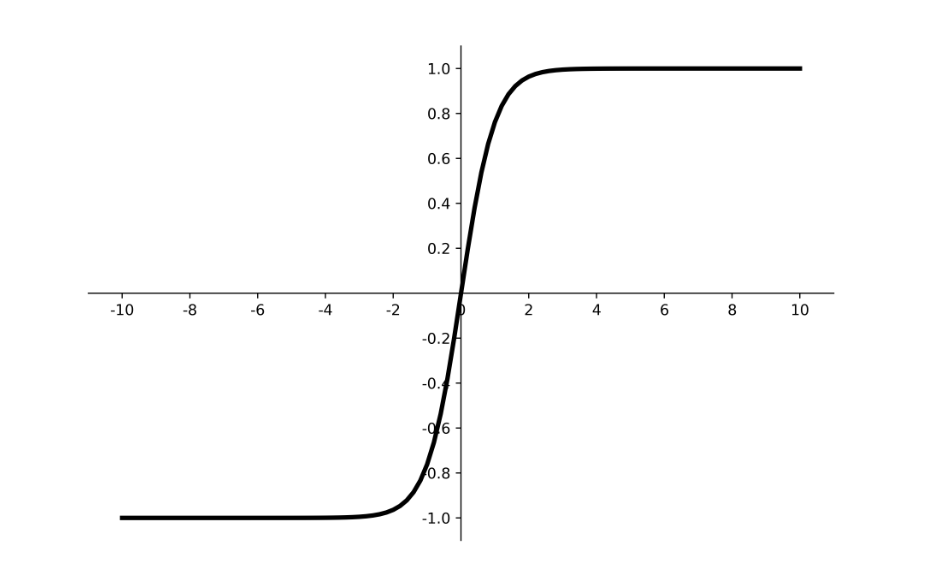
公式:
f(x) = (e^x - e^(-x)) / (e^x + e^(-x))输出范围:(-1, 1)
特点:它像是Sigmoid的“升级版”,同样具有“挤压”效果,但其输出是零中心的(均值为0),这大大改善了Sigmoid非零中心带来的问题,收敛速度通常更快。
缺点:梯度消失问题依然存在。
3. ReLU(整流线性单元) - 当前的主流选择
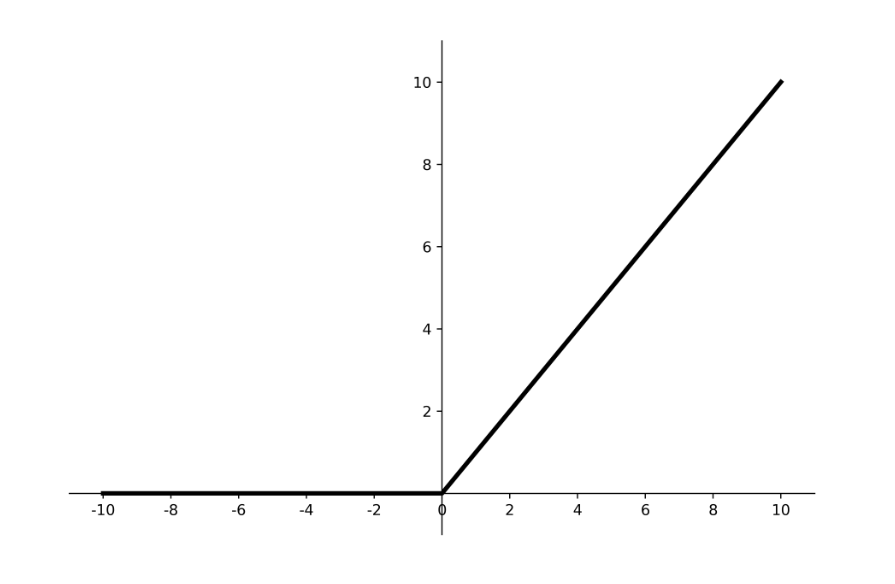
公式:
f(x) = max(0, x)输出范围:[0, +∞)
优点:
计算极其高效:只需一个阈值判断,没有复杂运算。
缓解梯度消失:在正区间(x>0)梯度恒为1,有效缓解了梯度消失问题,使得深层网络的训练成为可能。
缺点:
Dying ReLU(死ReLU)问题:当输入为负时,梯度完全为0。这意味着一旦神经元输出为负,它可能永远无法被再次激活,相应的权重也无法更新。
非零中心。
4. ReLU的改进者们
为了克服ReLU的缺点,研究者们提出了多种变体:
Leaky ReLU:为负输入区域提供了一个很小的斜率(如0.01x),而不是直接设为0。
f(x) = max(αx, x)(α是一个小的正常数)。这确保了负输入区域也有梯度,避免了神经元“死亡”。Parametric ReLU (PReLU):将Leaky ReLU中的斜率α作为一个可学习的参数,让网络自己决定最合适的斜率。
Exponential Linear Unit (ELU):在负输入区域使用一个指数曲线,试图使输出的均值更接近0,同时缓解死ReLU问题。通常比ReLU表现更好,但计算量稍大。
5. Swish(谷歌大脑推出)
公式:
f(x) = x * sigmoid(x)特点:这是一个平滑、非单调的函数(在负区间先小幅下降再上升)。在实践中,Swish常常表现出比ReLU更优的性能,尤其是在更深的网络中。它提供了小幅的负值输出,既保持了ReLU的优点,又避免了死区问题,同时其平滑性有利于优化过程。
三、如何选择合适的激活函数?
虽然没有放之四海而皆准的法则,但以下经验可供参考:
默认首选:ReLU及其变体(如Leaky ReLU、PReLU)是绝大多数隐藏层的首选,尤其是在CNN和MLP中,因为它们简单且高效。
分类输出层:Sigmoid用于二分类,Softmax(可视为Sigmoid的多分类扩展)用于多分类。
回归输出层:通常不使用激活函数(线性激活),以获得任意范围的输出值。
RNN网络:Tanh仍然常见,因其输出有正有负,有助于调节信息流。
追求最佳性能:可以尝试Swish或ELU,尽管它们计算成本稍高,但可能在特定任务上带来提升。
切勿使用:Sigmoid和Tanh应避免在深层网络的隐藏层中使用,主要是因为梯度消失问题。
四、总结与展望
激活函数虽小,却是神经网络不可或缺的核心部件。从Sigmoid/Tanh到ReLU,再到Swish,其演进史是深度学习不断突破自身瓶颈、追求更优性能的缩影。
未来的研究趋势可能集中在:
自适应激活函数:像PReLU和Swish那样,让函数的关键参数能够根据数据或任务自行学习调整。
搜索最优激活函数:利用神经架构搜索(NAS)技术,自动为特定数据集和网络结构发现更高效的激活函数。
理解激活函数的工作原理和特性,是理解和设计高效神经网络的关键一步。它就像是为线性计算的“骨架”赋予了非线性的“血肉与灵魂”,最终让机器拥有了学习万事万物的能力。