【AI论文】面向大语言模型(LLMs)的具身强化学习全景图:一项调研综述
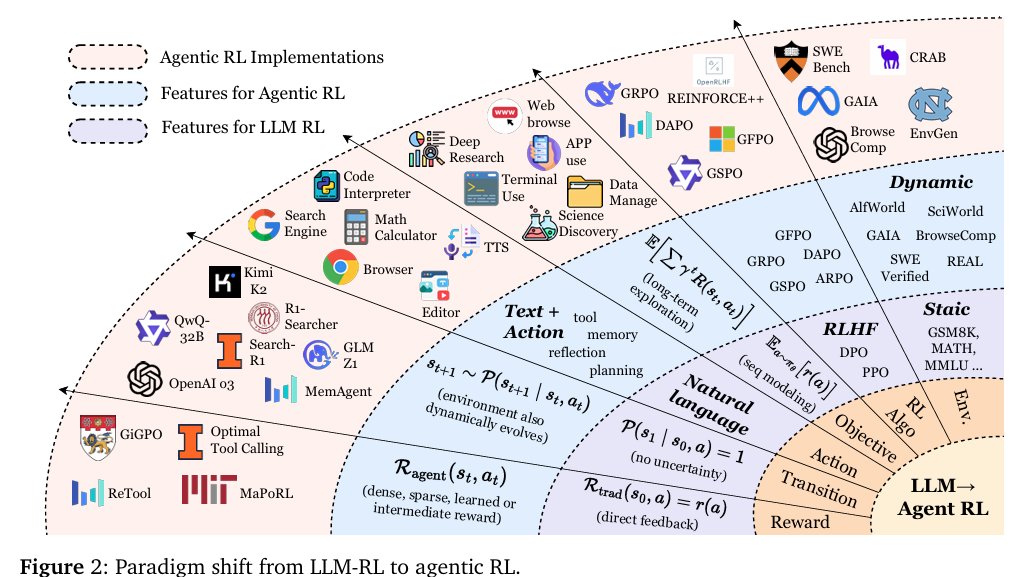
摘要:具身强化学习(Agentic Reinforcement Learning,Agentic RL)的兴起标志着一种范式转变,它从应用于大语言模型的传统强化学习(大语言模型强化学习,LLM RL)中脱颖而出,将大语言模型从被动的序列生成器重新定义为嵌入复杂动态世界中的自主决策智能体。本调研通过对比大语言模型强化学习中退化的单步马尔可夫决策过程(Markov Decision Processes,MDPs)与定义具身强化学习的时序扩展、部分可观测马尔可夫决策过程(Partially Observable Markov Decision Processes,POMDPs),使这一概念转变得以正式确立。在此基础上,我们提出了一个全面的双重分类体系:一个围绕核心具身能力展开,包括规划、工具使用、记忆、推理、自我提升和感知;另一个围绕这些能力在多样任务领域中的应用展开。我们研究的核心观点是,强化学习是将这些能力从静态的启发式模块转变为自适应、稳健的具身行为的关键机制。为支持和加速未来研究,我们将开源环境、基准测试和框架的概况整合成一本实用指南。本调研综合了五百余篇近期研究成果,描绘了这一快速发展领域的轮廓,并强调了塑造可扩展通用人工智能智能体发展所面临的机遇与挑战。Huggingface链接:Paper page,论文链接:2509.02547
研究背景和目的
研究背景:
近年来,大型语言模型(LLMs)的快速发展显著提升了自然语言处理(NLP)的能力,使得LLMs不仅能够生成流畅的文本,还能执行复杂的推理和决策任务。然而,传统的LLMs主要依赖于静态的启发式模块,缺乏在动态环境中自适应和鲁棒行为的能力。为了克服这一限制,强化学习(RL)作为一种关键机制被引入,用于将LLMs的这些能力转化为自适应、鲁棒的智能体行为。RL通过与环境的交互学习最优策略,使LLMs能够在动态环境中表现出色。
研究目的:
本研究旨在通过系统综述和实证分析,探讨强化学习如何赋能基于LLMs的智能体,使其能够在动态环境中展现出更强的自适应能力和鲁棒性。具体目标包括:
- 理论整合:从概念基础到实际实现,逐步构建对智能体强化学习(Agentic RL)的统一理解。
- 模块化能力分析:分类并详细分析智能体强化学习中的关键模块,如规划、推理、工具使用、记忆和自我改进等。
- 应用探索:探索智能体强化学习在不同领域的应用,包括搜索、GUI导航、代码生成、数学推理和多人系统等。
- 挑战与未来方向:讨论智能体强化学习面临的挑战,并提出未来的研究方向,以促进可扩展、自适应和可靠的智能体智能的发展。
研究方法
本研究采用了综合性的研究方法,包括文献综述、案例分析和实证研究,具体方法如下:
- 文献综述:
- 广泛搜集文献:通过学术数据库(如arXiv、Google Scholar等)搜索近五年内关于智能体强化学习、大型语言模型和强化学习结合的相关文献。
- 筛选与分类:根据研究主题和贡献,筛选出高质量的文献,并按照研究内容(如理论基础、模块化能力、应用领域等)进行分类。
- 深入分析:对分类后的文献进行深入分析,提取关键观点、方法、实验结果和结论。
- 案例分析:
- 选择典型案例:选取在智能体强化学习领域具有代表性的研究案例,如DeepSeek-R1、OpenAI o3等模型在动态环境中的应用。
- 详细剖析:对每个案例进行详细剖析,包括模型架构、训练方法、实验结果和应用场景等。
- 对比分析:对比不同案例之间的异同点,总结成功经验和存在的问题。
- 实证研究:
- 设计实验:基于文献综述和案例分析的结果,设计一系列实证研究,以验证强化学习对LLMs智能体在动态环境中的影响。
- 数据收集与分析:通过实验收集数据,并使用统计分析方法(如t检验、方差分析等)分析实验结果,验证假设。
- 结果讨论:根据实验结果,讨论强化学习对LLMs智能体性能提升的具体作用机制,以及不同参数设置对实验结果的影响。
研究结果
理论整合:
本研究成功构建了对智能体强化学习的统一理解框架,明确了强化学习在将LLMs的静态能力转化为动态环境中的自适应行为中的关键作用。通过文献综述,揭示了智能体强化学习与传统强化学习在任务结构、决策粒度和底层假设上的根本区别。
模块化能力分析:
- 规划能力:强化学习显著提升了LLMs在复杂任务中的规划能力,使智能体能够制定多步决策轨迹,实现长期目标。例如,在代码生成任务中,智能体能够通过强化学习优化代码迭代过程,提高代码的正确性和效率。
- 工具使用:强化学习使智能体能够根据任务需求自适应地调用外部工具,如API和计算器等。通过工具集成推理(TIR),智能体能够在认知循环中深度嵌入工具使用,提升任务执行的灵活性和准确性。
- 记忆管理:强化学习在记忆管理中发挥了重要作用,通过优化检索行为、调整记忆编码和检索策略,提高了智能体的记忆效率和准确性。例如,Memory-R1框架通过PPO或GRPO算法训练记忆管理器,实现了对记忆池的有效控制。
- 自我改进:强化学习促进了智能体的自我反思和持续改进能力。通过引入迭代自我训练机制,智能体能够在没有人类干预的情况下,通过自我生成反馈循环实现性能的不断提升。
应用探索:
- 搜索与信息检索:强化学习优化了查询生成和多步推理过程,提高了智能体在复杂搜索任务中的表现。例如,DeepRetrieval框架通过GRPO算法训练查询生成策略,显著提升了搜索结果的相关性和准确性。
- GUI导航:强化学习使智能体能够在GUI环境中执行多步交互任务,通过试错学习最优操作序列。例如,UI-Venus框架通过RFT算法微调智能体,实现了在UI界面上的高效导航。
- 代码生成与软件工程:强化学习在代码生成和软件工程领域展现了巨大潜力,通过执行反馈引导策略更新,提高了代码的正确性和可维护性。例如,CURE框架通过联合训练代码生成器和单元测试器,显著提升了代码的健壮性和泛化能力。
研究局限
尽管本研究在智能体强化学习领域取得了显著进展,但仍存在以下局限:
- 数据稀缺性:在某些特定领域(如专业数学推理),高质量的训练数据稀缺,限制了强化学习算法的性能提升。
- 计算资源需求:强化学习训练过程需要大量计算资源,尤其是在处理复杂任务和大规模模型时,计算成本高昂。
- 泛化能力:尽管强化学习在特定任务中表现优异,但智能体的泛化能力仍有待提高,尤其是在面对未见过的任务和环境时。
- 可解释性:强化学习模型往往被视为“黑箱”,其决策过程缺乏透明度,影响了模型的可信度和可靠性。
未来研究方向
针对上述局限,未来研究可从以下几个方面展开:
- 数据增强与合成:开发数据增强和合成技术,缓解数据稀缺问题。例如,利用生成对抗网络(GANs)生成合成数据,或通过迁移学习利用相关领域的数据。
- 高效强化学习算法:研究更高效的强化学习算法,降低计算资源需求。例如,开发基于模型的强化学习算法,减少与环境的实际交互次数。
- 泛化能力提升:探索提高智能体泛化能力的方法,如元学习、多任务学习等。通过在不同任务和环境中训练智能体,增强其适应新任务和环境的能力。
- 可解释性研究:加强强化学习模型的可解释性研究,提高模型的透明度和可信度。例如,开发可视化工具展示模型的决策过程,或设计可解释性强的模型结构。
- 动态环境构建:构建更复杂、更动态的交互环境,模拟真实世界中的多样性和不确定性。通过自动化奖励函数设计,降低人工标注成本,提高训练效率。
总之,本研究通过系统综述和实证分析,深入探讨了强化学习在赋能基于LLMs的智能体方面的作用。未来研究应继续关注数据增强、高效算法、泛化能力、可解释性和动态环境构建等方面,以推动智能体强化学习领域的进一步发展。