【机器学习】HanLP+Weka+Java算法模型
一、核心功能与技术栈概述
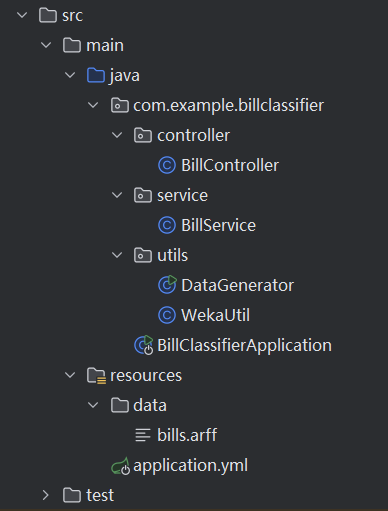
此服务通过 Spring Boot 构建 RESTful 接口,结合 HanLP 进行中文分词,通过自定义数据生成工具类>>构建训练数据集,利用 Weka 机器学习库的随机森林算法,最终训练出高效的机器学习模型,可通过 Vue 前端页面接口调用,实现对饮食类账单数据的类型预测并显示。
核心技术栈:
- 框架:Spring Boot
- 机器学习:Weka(随机森林算法、数据预处理)
- 中文处理:HanLP(中文分词)
- 数据生成:自定义工具类(构建带标签的训练数据)
系统整体结构:
二、随机森林算法与Weka工具库
Weka是免费开源且集成多种机器学习算法的平台,可应用于数据挖掘、预测等方面,其拥有众多常用算法的实现,除了有一个十分方便的图形界面外,也有完全使用编程方式的操作。它可以完成如数据清洗、分类、回归、聚类和特征选择等的功能。其最大的优点就是为使用者提供了模块化的算法组合方式;通过ARFF文件可以方便地处理各种数据;
在Weka中对随机森林算法做出了改进:首先是通过多线程同时产生多颗决策树,提高了多核CPU性能。其次是利用拆分数据节点时按照特征重要性调整个别特征选择概率的方法,提高了预测准确性;然后是采用分批加载方法应对超出内存容量的数据量;最后,训练过程中自动计算OOB误差用于实时查看模型情况,并且增加查看特征重要性以及查看单棵模型结构等功能,使模型更加易于理解。这一系列的改进使得模型在面对如高维数据、不均衡数据等复杂问题时的解决能力增强。
在SpringBoot项目中使用Weka需要在Maven里面添加3.8.6这样的版本依赖,在SpringBoot中可以利用自己的模块化特性进行编程。原理是用WekaFilteredClassifier读取ARFF格式的数据去训练自己的模型并提供接口调用,用SpringBoot来管理依赖以及通过Instances类实现对数据的清洗操作,既借助了Weka的强大算法能力又实现了SpringBoot的优点。

三、实现步骤
(1)引入相关依赖
随机森林算法和HanLP分词方法,由maven仓库提供的Weka依赖和分词方法依赖,引入获取相应的jar包:
<!-- HanLP汉语言处理库,用于自然语言处理 -->
<dependency><groupId>com.hankcs</groupId><artifactId>hanlp</artifactId><version>portable-1.7.7</version>
</dependency>
<!-- Weka机器学习库,用于数据分析和预测 -->
<dependency><groupId>nz.ac.waikato.cms.weka</groupId><artifactId>weka-stable</artifactId><version>3.8.6</version>
</dependency>(2)模拟数据生成
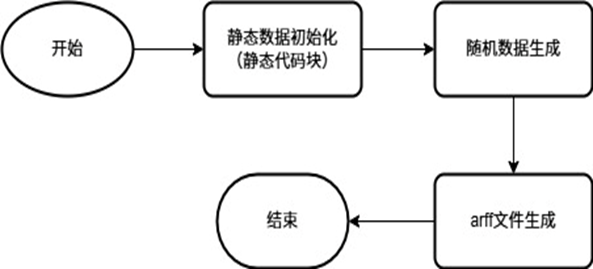
步骤 1:定义核心数据集合(静态成员变量)
首先通过静态变量定义 5 类核心数据集合,用于存储食品分类的基础数据,所有集合均为类级别的静态变量,确保程序启动时仅初始化一次,避免重复创建。
private static final String[] PARENT_TYPES = {"主食", "肉类", "蔬菜", "水果", "饮品"};// 定义每个父类的具体子类型 Map集合 键为父类型,值为子类型数组private static final Map<String, String[]> SUB_TYPES_BY_PARENT = new HashMap<>();// 定义每个父类对应的营养成分、食用方式、存储条件、交易地点private static final Map<String, String[]> NUTRITION_BY_PARENT = new HashMap<>(); // 营养成分private static final Map<String, String[]> EATING_METHOD_BY_PARENT = new HashMap<>(); // 食用方式private static final Map<String, String[]> STORAGE_CONDITION_BY_PARENT = new HashMap<>(); // 存储条件private static final Map<String, String[]> TRANSACTION_LOCATION_BY_PARENT = new HashMap<>(); // 交易地点各集合的具体用途如下表所示:
| 集合名称 | 数据类型 | 核心用途 | 示例数据 |
|---|---|---|---|
PARENT_TYPES | String[] | 定义食品的 5 个顶级分类(父类型),是所有数据分类的基础 | {"主食", "肉类", "蔬菜", "水果", "饮品"} |
SUB_TYPES_BY_PARENT | Map<String, String[]> | 建立 “父类型→子类型” 的映射,确保子类型与父类型严格对应 | 键:"主食";值:{"米饭", "面条", "馒头"...} |
NUTRITION_BY_PARENT | Map<String, String[]> | 建立 “父类型→营养成分” 的映射,确保营养属性符合父类食品特征 | 键:"肉类";值:{"胆固醇", "蛋白质", "脂肪"} |
EATING_METHOD_BY_PARENT | Map<String, String[]> | 建立 “父类型→食用方式” 的映射,定义对应食品的常见食用方法 | 键:"水果";值:{"剥皮", "切块", "直接吃"...} |
STORAGE_CONDITION_BY_PARENT | Map<String, String[]> | 建立 “父类型→存储条件” 的映射,定义对应食品的合理存储方式 | 键:"蔬菜";值:{"冷藏5天", "避光", "保鲜"...} |
TRANSACTION_LOCATION_BY_PARENT | Map<String, String[]> | 建立 “父类型→交易地点” 的映射,定义对应食品的常见购买场景 | 键:"饮品";值:{"超市", "便利店", "自动售货机"...} |
步骤 2:静态代码块初始化集合数据
通过静态代码块(static {})为上述集合赋值,这是 Java 中 “类加载时初始化静态变量” 的常用方式,确保程序运行前所有基础数据已准备就绪。
static {// 扩展子类型SUB_TYPES_BY_PARENT.put("主食", new String[]{"米饭", "面条", "馒头", "包子", "饺子", "饼", "粥", "面包", "蛋糕", "煎饼","炒饭", "盖浇饭", "拉面", "刀削面", "馄饨", "汤圆", "粽子", "月饼", "糕点", "寿司","主食", "米", "米粉", "河粉", "意面", "通心粉", "炒面", "烩面", "凉面", "米线"
});......初始化逻辑示例(以 “主食” 为例):
- 给
SUB_TYPES_BY_PARENT的 “主食” 键赋值,添加米饭、面条等 70 + 个子类型; - 给
NUTRITION_BY_PARENT的 “主食” 键赋值,添加 “高纤维”“碳水化合物” 等符合主食特征的营养成分; - 同理完成 “肉类”“蔬菜” 等其他 4 个父类型的所有映射集合赋值。
步骤 3:实现 “随机数据生成” 方法(generateData)
public static List<String[]> generateData(int numRecords) {List<String[]> data = new ArrayList<>(); // List数组用于存储生成的数据Random random = new Random(); // 创建一个随机数生成器for (int i = 0; i < numRecords; i++) {String parentType = PARENT_TYPES[random.nextInt(PARENT_TYPES.length)];String subType = SUB_TYPES_BY_PARENT.get(parentType)[random.nextInt(SUB_TYPES_BY_PARENT.get(parentType).length)];String nutrition = NUTRITION_BY_PARENT.get(parentType)[random.nextInt(NUTRITION_BY_PARENT.get(parentType).length)];String eatingMethod = EATING_METHOD_BY_PARENT.get(parentType)[random.nextInt(EATING_METHOD_BY_PARENT.get(parentType).length)];String storageCondition = STORAGE_CONDITION_BY_PARENT.get(parentType)[random.nextInt(STORAGE_CONDITION_BY_PARENT.get(parentType).length)];String transactionLocation = TRANSACTION_LOCATION_BY_PARENT.get(parentType)[random.nextInt(TRANSACTION_LOCATION_BY_PARENT.get(parentType).length)];// 添加一些随机噪声if (random.nextDouble() < 0.01) { // 1% 的概率添加噪声subType = "未知类型";nutrition = "未知营养";eatingMethod = "未知方法";storageCondition = "未知条件";transactionLocation = "未知地点";}String[] record = {subType,nutrition,eatingMethod,storageCondition,transactionLocation,parentType};data.add(record);}return data;}该方法接收 “生成记录数” 参数,返回包含随机食品数据的List<String[]>,是数据生成的核心逻辑,步骤如下:
- 创建
Random对象用于生成随机数,创建List<String[]>用于存储最终数据; - 循环
numRecords次(生成指定数量的记录):- 随机选择父类型:从
PARENT_TYPES数组中随机选一个父类型(如 “肉类”); - 匹配子属性:根据选中的父类型,从对应的映射集合中随机选子属性(如从
SUB_TYPES_BY_PARENT选 “牛肉”,从NUTRITION_BY_PARENT选 “蛋白质”); - 添加噪声数据:以 1% 的概率将子属性替换为 “未知类型”“未知营养” 等,模拟真实数据中的异常值;
- 封装记录:将 “子类型、营养成分、食用方式、存储条件、交易地点、父类型” 封装为
String[],添加到List中;
- 随机选择父类型:从
- 返回存储所有随机记录的
List。
步骤 4:实现 “ARFF 文件生成” 方法(generateArffFile)
ARFF(Attribute-Relation File Format)是机器学习工具 WEKA 的标准数据格式,该方法将随机数据导出为 ARFF 文件,步骤如下:
- 调用
generateData获取随机数据列表; - 使用
FileWriter创建文件输出流(try-with-resources 语法自动关闭流,避免资源泄漏); - 写入 ARFF 文件头:
@relation bills:定义数据集名称为 “bills”;@attribute:定义每个属性的名称和取值范围(如@attribute subType {米饭,面条,馒头...}),取值范围通过遍历对应集合的所有元素生成(并添加 “未知” 类);@data:标记数据开始部分;
- 写入数据:遍历
List中的每条记录,将数组元素用逗号连接,按行写入文件; - 关闭流(try-with-resources 自动完成)。
步骤 5:主方法(main)测试
main方法是程序的入口,直接调用generateArffFile,指定 ARFF 文件的输出路径(src/main/resources/data/bills.arff)和生成记录数(8000 条),运行后即可在指定路径生成包含 8000 条食品数据的 ARFF 文件。若文件写入失败(如路径不存在),则打印异常堆栈信息。
最终数据生成在bills.arrf文件中:

(3)数据集预处理
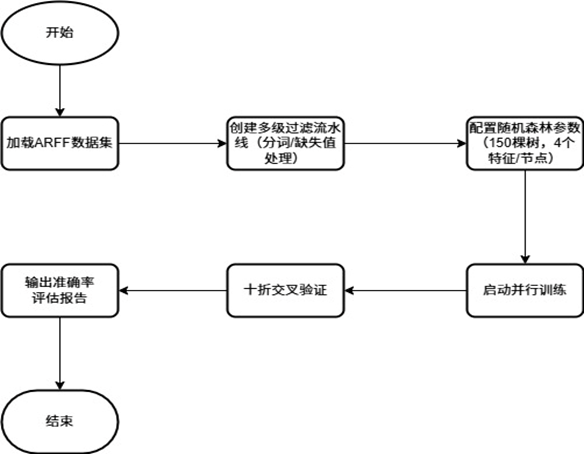
1.中文分词与特征提取
使用HanLP分词。用Weka工具中自带的StringToWordVector功能将字符串中拆分出的单词转换成数字。这里我们用TF-IDF计算方式来选取出现频率最高的1500个词语作为主要特征,并且对每一词计算IDF权重;将所有字母变为小写;将常见词去掉。这样才能让一些较有代表性的词汇更加凸显,让计算机更容易辨别文本数据的关键信息。
private static String segmentWords(String text) {List<Term> termList = HanLP.segment(text); // 使用HanLP进行中文分词处理List<String> wordList = termList.stream() // 将Term对象转化为词.map(term -> term.word).collect(Collectors.toList());String segmentedValue = String.join(" ", wordList); // 将词序列转化为字符串return segmentedValue; // 返回分词后的字符串
}StringToWordVector过滤器的实现代码:/*通过Weka的StringToWordVector过滤器生成TF-IDF向量,
设置1500个高频词保留、启用IDF权重转换和小写规范化*/
StringToWordVector wordVector = new StringToWordVector();
wordVector.setAttributeIndices("first-last");
wordVector.setWordsToKeep(1500); //降维处理,提升模型泛化能力
wordVector.setIDFTransform(true); //削弱常见词影响,突出特征词
wordVector.setLowerCaseTokens(true);//消除大小写差异带来的特征分裂3.2.2 缺失值与噪声处理利用ReplaceMissingValues过滤器自动补充缺失值,因为这样能避免模型由于数据缺失而出现偏差。
/*组合ReplaceMissingValues过滤器处理缺失值,形成多阶段预处理流水线*/
MultiFilter multiFilter = new MultiFilter();
Filter[] filters = new Filter[]{wordVector,new ReplaceMissingValues()
};
multiFilter.setFilters(filters);
multiFilter.setInputFormat(data);
filteredData = Filter.useFilter(data, multiFilter);(4)随机森林模型构建
a.模型配置与训练
在这个模块中使用随机森林算法:采用150颗决策树、每棵树在训练中随机抽取4个特征、同时设置树的最大深度为20层并且开启了特征重要性分析。
classifier = new RandomForest();
((RandomForest) classifier).setOptions(new String[]{"-I", "150", "-K", "4", "-depth", "20","-attribute-importance"
});随机森林的训练过程是通过多棵决策树的并行构建与集成实现,其核心步骤包括 Bootstrap 采样、特征子集随机选择、节点分裂优化及集成投票:
1.Bootstrap 采样与数据子集生成
首先,这里的每个树都是基于一组随机样本而进行训练的(同时也是可以有重复的)。其次,Weka工具类库的RandomForest模块在默认情况下会使用这个选项,而且同时会在每棵树上训练150棵树并会对每一棵树进行独立试验。
2.特征子集随机选择机制
每棵决策树在节点分裂时,从全部特征中随机选取K个候选特征(K由-K4指定),而非使用所有特征。特征子集大小K 的设定直接影响模型性能:
(1)如果K值较小,会增强树间的差异性并减少过拟合,但可能丢失重要特征。
(2)如果K值较大,将提高单棵树精度但会增加模型相关性,从而降低集成效果。
所以通过-K 4设置每棵树随机选择4个特征将会平衡特征多样性与模型稳定性。
3. 决策树节点分裂标准
节点分裂基于基尼不纯度(Gini Impurity) 最小化原则,计算方式为:
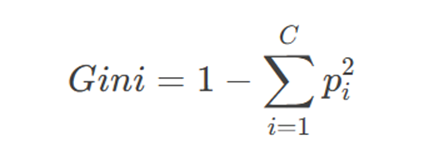
其中 C 为类别数,pi 为节点中第 i 类的样本比例。
分裂过程:
a.遍历当前节点的所有候选特征和候选阈值。
b.计算出各个候选分割的基尼不纯度,选择分裂后子节点不纯度之和最小的那个分割点。
c.根据题意递归地切分子节点,直至达到最大深度(-depth20)或当前节点划分后子样本数量小于阈值。
4.并行化训练与集成策略
并行化机制:利用多线程技术同时训练多棵决策树,极大的节省了训练的时间。
集成投票:经过决策树独立的预测后,将用多数投票(分类),或均值(回归)的方法来集成最后的结果。
5.特征重要性分析
通过-attribute-importance参数启用,特征重要性基于基尼不纯度减少量或袋外误差计算:
基尼重要性:统计某特征在所有树中作为分裂节点时基尼不纯度的总减少量,值越大表示特征越重要。
袋外重要性:通过随机置换某特征的取值,观察模型OOB误差的上升幅度,误差上升越大则特征越关键。
训练完成后,可通过 ((RandomForest) classifier).getAttributeImportances() 获取特征重要性排名,用于后续特征筛选或结果解释。
b. 动态参数调优与模型鲁棒性
因为中文文本有语义多样的特点,所以提出了基于编辑距离和类别权重的模糊匹配方法,因此提升了模型对于同义词和近义词的泛化能力。
values = attribute.enumerateValues(); // 获取属性值枚举
while (values.hasMoreElements()) { // 遍历所有可能的值String value = (String) values.nextElement(); // 获取属性值int baseDistance = levenshteinDistance(feature, value); // 计算编辑距离// 语义增强规则int weight = 0; // 初始权重if (isSameCategory(value, feature)) { // 同类加分weight += 50; // 同类加分}if (value.contains(feature) || feature.contains(value)) { // 包含关系weight += 30; // 包含关系加分}weightedDistances.put(value, baseDistance - weight); // 更新权重距离
}// 找到最优匹配
String bestMatch = null; // 初始最优匹配
int minWeightedDistance = Integer.MAX_VALUE; // 初始最小权重距离
for (Map.Entry<String, Integer> entry : weightedDistances.entrySet()) { // 遍历权重距离映射if (entry.getValue() < minWeightedDistance) { // 如果当前权重距离小于最小权重距离,更新最小权重距离和最优匹配minWeightedDistance = entry.getValue(); // 更新最小权重距离bestMatch = entry.getKey();}
}(5)参数分析与优化
本研究使用交叉验证调整重要参数:
/*并行构建多棵决策树
每棵树使用Bootstrap有放回采样和特征子集
最终通过投票机制集成结果*/
classifier.buildClassifier(filteredData);
/*通过10折交叉验证评估模型性能,使用Evaluation类输出准确率等指标*/
Evaluation eval = new Evaluation(filteredData);
eval.crossValidateModel(classifier, filteredData, 10, new Random(1));
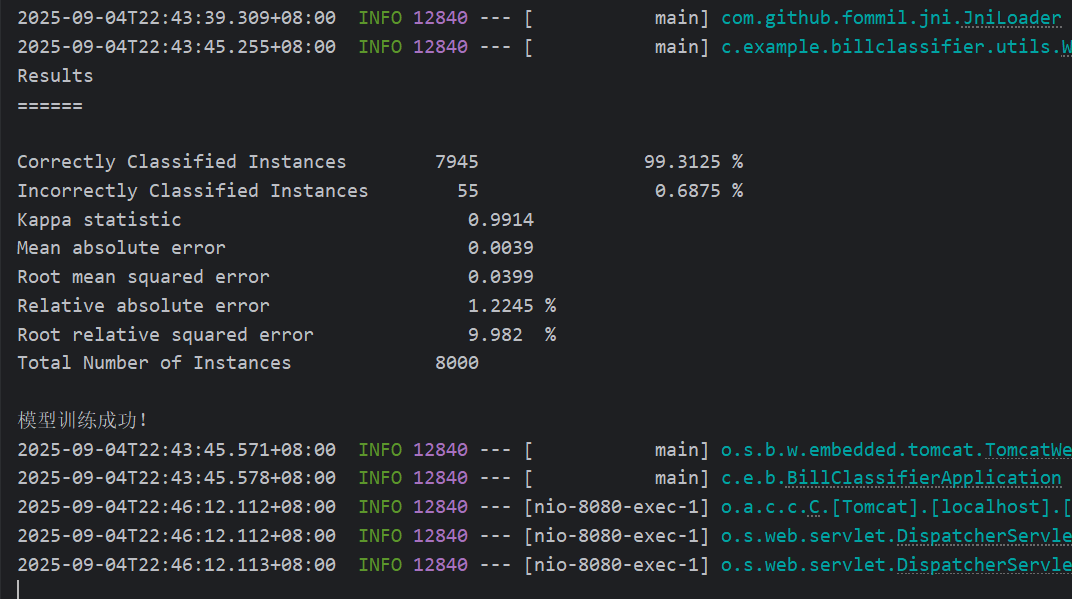
logger.info(eval.toSummaryString("\nResults\n======\n", false));四、控制器Controller层
@RestController
@RequestMapping("/bills")
@CrossOrigin(origins = "http://localhost:8088")
public class BillController {@Autowiredprivate BillService billService;@PostMapping("/predict")public Map<String, Double> predictBillCategory(@RequestBody String[] billData) {try {return billService.predictBillCategory(billData); // 调用服务层方法} catch (Exception e) {e.printStackTrace();
}五、运行结果
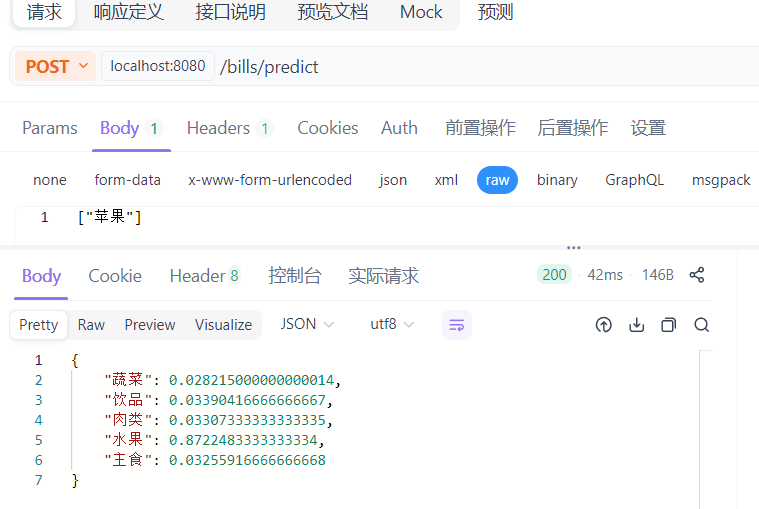
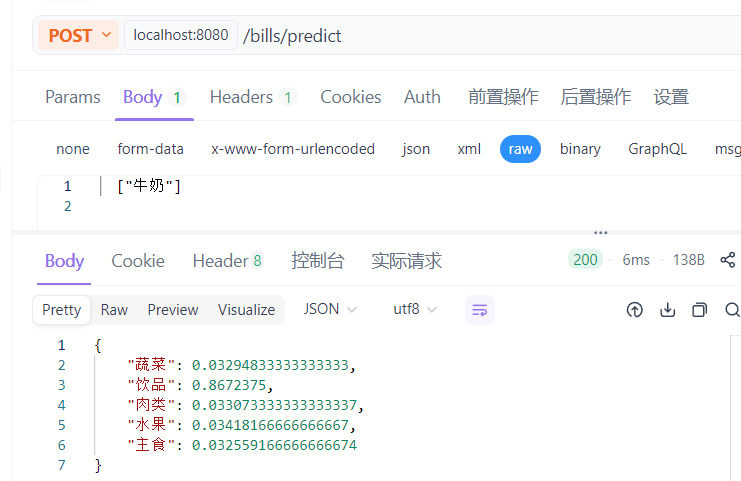
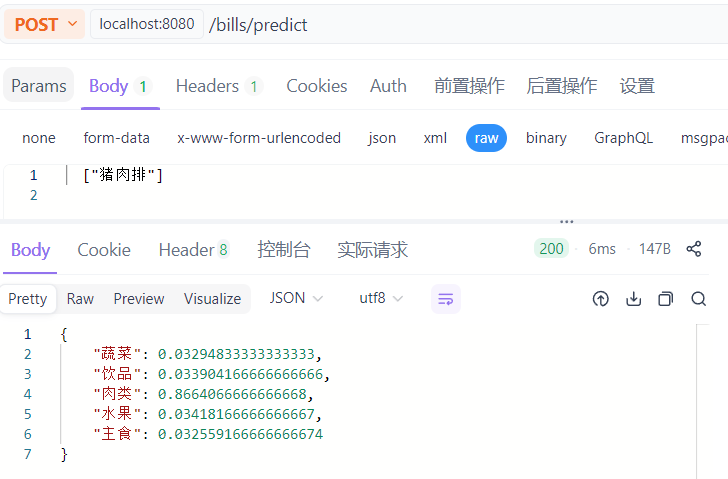
六、Apifox测试
七、控制台日志
