【MLLM】从BLIP3o到BLIP3o-NEXT:统一生成与理解
note
- BLIP3-o采用「先理解后生成」训练策略,实现了图像理解与生成的有效统一,并基于GPT-4o构建了BLIP3o-60k数据集。
- BLIP3-o是一个全开源统一多模态模型,结合自回归与扩散架构,采用「先理解后生成」策略,创新地使用CLIP特征与Flow Matching训练,显著提升生成图像质量与多样性。BLIP3-o不仅在多个评测中表现领先,也正拓展至图像编辑和视觉对话等多模态任务。
- 应用场景:图像编辑(如「给照片中的狗戴墨镜」);视觉对话(根据图片内容回答问题);逐步推理(如解数学题时生成辅助图表)。
文章目录
- note
- 一、从BLIP3o到BLIP3o-NEXT
- 二、模型架构
- 1、模型设计
- 2、BLIP3-o方案
- 3、模型训练
- 三、统一多模态下的训练策略
- 四、模型评测
- 相关问题
- Reference
一、从BLIP3o到BLIP3o-NEXT
BLIP3o-NEXT architecture with discrete image token supervision. The autoregressive model generates discrete image tokens, and their hidden representations serve as conditions for the diffusion model. We jointly optimize both CrossEntropy and Flow-Matching objective during training.
代码:https://github.com/JiuhaiChen/BLIP3o
论文地址:https://arxiv.org/abs/2505.09568
模型链接:https://huggingface.co/BLIP3o/BLIP3o-Model
优化数据:https://huggingface.co/datasets/BLIP3o/BLIP3o-60k
体验网站:https://blip3o.salesforceresearch.ai
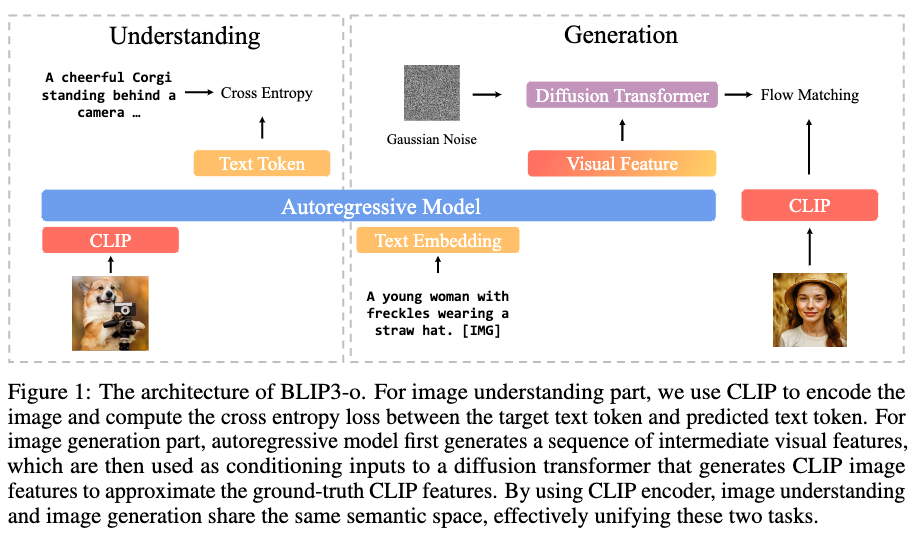
BLIP3-o的架构包括两部分:
理解部分:使用CLIP对图像进行编码;
生成部分:自回归模型生成中间视觉特征,作为DiT的输入,采用CLIP+Flow Matching策略生成图像特征。
传统技术痛点:
- 多数模型要么擅长理解图片(如CLIP),要么擅长生成图片(如Stable Diffusion),难以统一;、
- 生成图片多样性不足(同一提示词总画相似的图)。
二、模型架构
1、模型设计
1.模型亮点:像人类一样「先看懂再画图」
- 双模块设计:
- 理解模块:用CLIP图像编码器提取图片的语义特征(类似人类观察后理解画面内容);
- 生成模块:通过自回归模型+扩散模型(DiT)生成图像,类似画家根据理解创作新作品。
- 训练黑科技:
- 采用 Flow Matching 替代传统MSE损失,让生成的图片更自然多样(同一描述可画出不同风格的图)。
- 两阶段训练:先专注教模型「看懂图」,再教它「画图」,避免两者互相干扰。
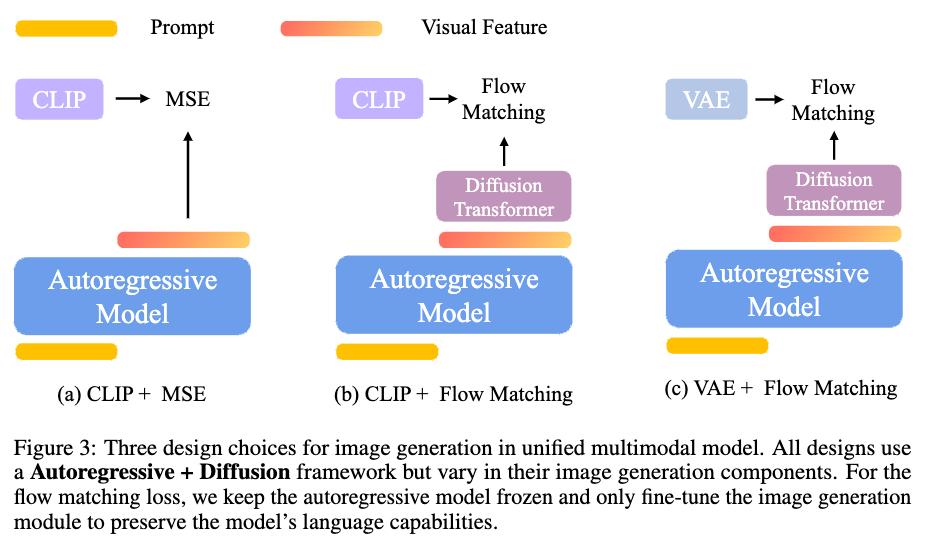
2、BLIP3-o方案
- 用 CLIP语义特征 作为「翻译官」,桥接理解与生成模块;
- 通过 Flow Matching 引入随机性,让同一提示生成不同风格的图(如「城堡」可画成童话风或写实风)。
3、模型训练
研究团队开发了两种不同大小的模型:一个是在专有数据上训练的8B参数模型,另一个是仅使用开源数据的4B参数模型。研究团队跳过了图像理解训练阶段,直接在Qwen 2.5 VL上构建研究团队的图像生成模块。在8B模型中,研究团队冻结了Qwen2.5-VL-7B-Instruct主干,并训练DiT,总共 1.4B 可训练参数。4B模型采用了相同的图像生成架构,但使用Qwen2.5-VL-3B-Instruct作为主干。研究团队利用Lumina-Next模型的架构来构建研究团队的DiT。Lumina-Next模型基于改进的Next-DiT架构,这是一种可扩展且高效的扩散Transformer,专为文本到图像和一般的多模态生成而设计。
三、统一多模态下的训练策略
使用CLIP + Flow Matching进行图像生成模块的开发。由于图像理解也在CLIP的嵌入空间中运行,在相同的语义空间内对齐这两个任务,从而实现它们的统一。
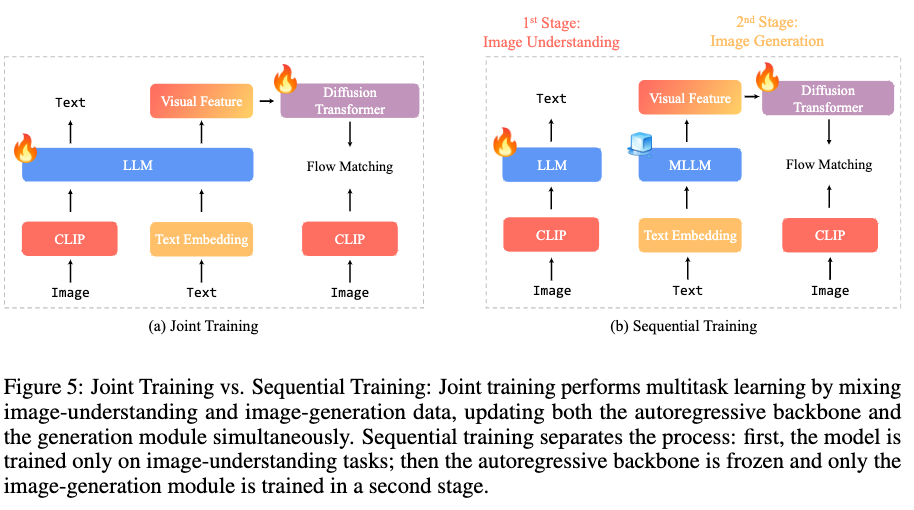
(1)联合训练:联合训练图像理解和图像生成是最为常见做法,这些方法采用了不同的图像生成架构,但都通过混合用于图像生成和理解的数据来进行多任务学习。
(2)序列训练:与其同时训练图像理解和生成,研究团队采用两阶段方法。在第一阶段,研究团队仅训练图像理解模块。在第二阶段,研究团队冻结MLLM主干,并仅训练图像生成模块。
在联合训练设置中,尽管图像理解和生成任务可能互相受益,但两个关键因素影响它们的协同效应:总数据量和图像理解和生成数据之间的数据比例。相比之下,顺序训练提供了更大的灵活性:能够冻结自回归主干并保持图像理解能力。研究团队可以将所有训练能力专门用于图像生成,避免联合训练中的任何任务间影响。
研究团队最终选择顺序训练来构建研究团队的统一多模态模型。
四、模型评测
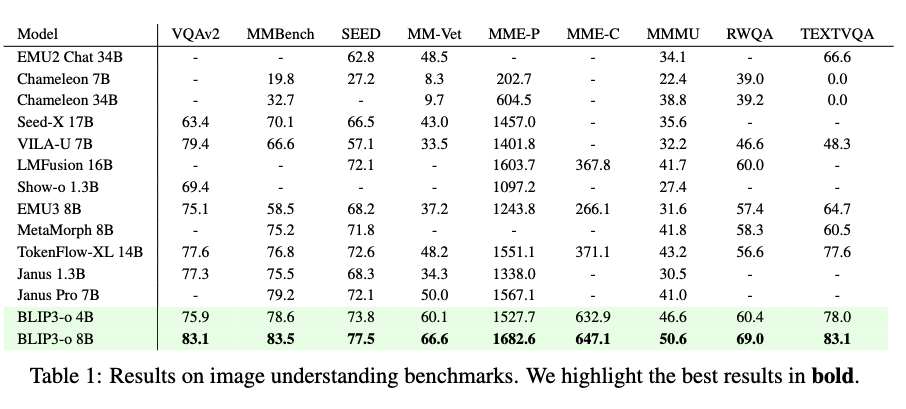
在图像理解任务中,研究团队在多个数据集上评估基准性能。如表1所示,研究团队的BLIP3-o 8B在大多数基准测试中达到了最佳性能。
在图像生成基准中,如表2所示,BLIP3-o 8B的GenEval得分为0.84,WISE得分为0.62,但在DPG-Bench上得分较低。
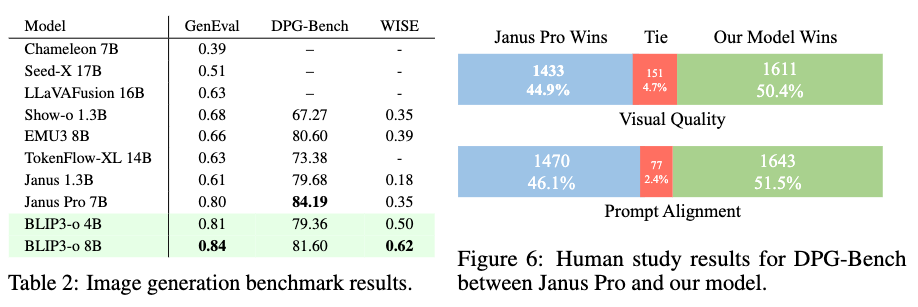
由于基于模型的DPG-Bench评估可能不可靠,研究团队在下一节通过继续研究补充这些结果。研究团队进行了一项人工评估,比较了BLIP3-o 8B和Janus Pro 7B在大约1,000个从DPG-Bench抽取的提示上的表现。
对于每个提示,标注者根据两个指标并排比较图像对:视觉质量:看图像是否更清晰、美观、布局好。提示对齐:看图像内容与文本描述是否更匹配。每个维度都进行了两轮评估,共约3,000次判断。结果显示,BLIP3-o在视觉质量和提示对齐上都显著优于Janus Pro,尽管后者在表2的DPG分数更高。两个维度的统计显著性分别为5.05e-06和1.16e-05,说明BLIP3-o的优势可信度非常高。
相关问题
1、对比分析离散与连续两类视觉生成建模方式的原理及优势
2、探讨不同视觉表征在多模态大模型中的特性与性能差异
3、如何利用强化学习方法有效提升视觉生成质量
Reference
[1] 谢赛宁SFR等新作,统一多模态BLIP3-o登场!先理解后生成,端掉VAE刷新SOTA