stack queue的实现 deque的底层结构 priority_queue的实现
stack and queue
栈和队列之前用c的方式已经实现过了 而且这里的stack和queue的接口就这些 在之前学习string vector 及list的使用及底层实现之后 这里很容易就知道这些接口是干嘛的
所以这里的使用上其实不需要额外再去探究什么了
但是这里的底层还是有必要来实现一下的 因为在stl中的stack及queue不是和之前一样如下面这样的方式实现的

stl中的stack和queue不是和vector及list一样是容器 而是容器适配器

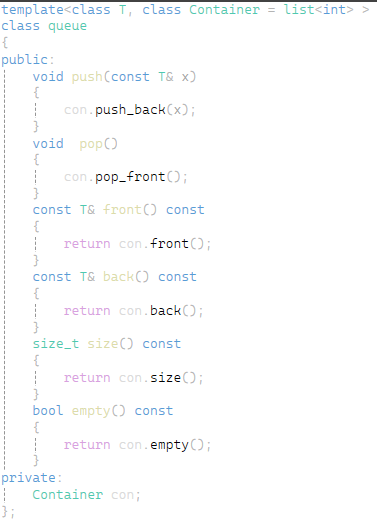
stl中是如下图这样的方式来实现stack及queue的(这里的Container缺省值实际是deque<T> 这里先用vector来理解) 这里的成员变量从之前的指针直接变为一个容器 默认为vector容器 然后想实现栈的功能直接赋用容器的成员函数就可以了
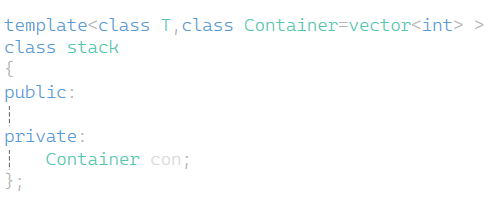
这里以最后的位置为栈顶 从栈顶入数据栈顶出数据 对于push和pop直接调用成员变量的容器con的尾插尾删就可以了 top只需要返回最后一个位置 size和empty也直接调用容器里的来实现

就直接可以正常使用了 没有传模版第二个参数 容器默认为vector<T> 这个栈就是用vector实现的
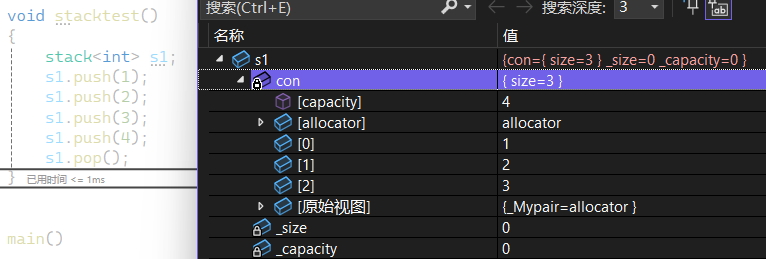
如果显示传第二个参数为链表 那这个栈就是通过链表实现的
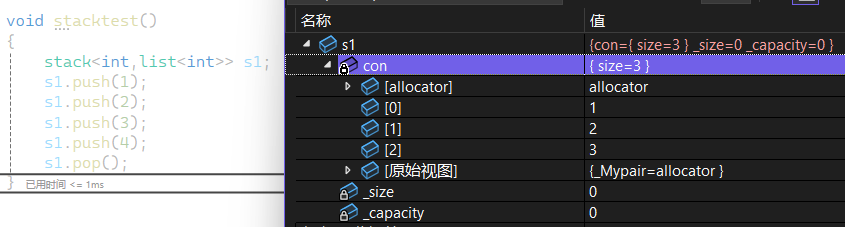
这里连 构造 析构和拷贝构造都不需要写 因为对于自定义类型的对象会自动调用他们的构造和析构函数 这里就会调用对应容器里面的构造和析构函数
对于queue和stack基本上没有区别 这里Container默认为list<T> 队列是从队尾入数据队头删数据 这里以尾部为队尾 对于插入要调用尾插 对于删除要调用头删 但是对于vector不支持头增和头删(要挪动数据 时间复杂度高) 所以不用vector来实现队列
当然如果非用vector实现队列也可以用erase(begin())的方式就是头删了 但是还是效率低下
但是stl中stack和queue第二个模版参数实际上都是用depue<T>来实现的


那么为什么都用deque来实现呢 deque又是什么 接下来对deque的底层做一下了解之后就知道这里为什么用deque了
先简单说一下 虽然看着deque和queue名字好像差不多 但其实它和queue没什么关系 deque是由vector和list缝合而成的
之前学习知道 vector不支持头插尾插 list不支持用下标访问的方式 其实都可以实现出来没有实现就是因为时间复杂度高效率上的问题
vector和list各自的优缺点
vector优点
1.空间上是连续的 下标访问很快 支持下标访问的方试
2.空间上是连续的 缓存利用率高( 简单解释下 cpu处理数据会先在缓存中找 没有的话会先把要处理的放到缓存中 这个过程会把其附近的部分也直接一起放到缓存中 之后先在缓存中找的时候就大概率直接找到(缓存命中..好像是叫这个) )
缺点
1.开空间时候 如果一次开的少需要频繁扩容 就会有消耗 如果开的多又会造成空间的浪费
2.因为空间是连续的 如果头插头删中间及之前的时候 需要挪动后面的所有数据 所以也会造成之后的迭代器失效的问题 只有尾插尾删比较靠后的数据处理时候比较快
list优点
1.按需申请释放空间 不会造成浪费 也不需要扩容
2.不管在哪一个位置插入数据或者删除数据 只需要处理该位置的空间问题及邻近位置的指向问题 所以容易位置插入删除都比较快
缺点
1.空间不连续 不支持下标访问的方式
2.空间不连续 缓存利用率低
总结vector及list的优缺点我们发现他们的优缺点主要取决于他们的结构
而deque既支持头插头删也支持下标访问 那么deque的结构是怎么实现的 为什么它会都支持了呢
deque的底层了解
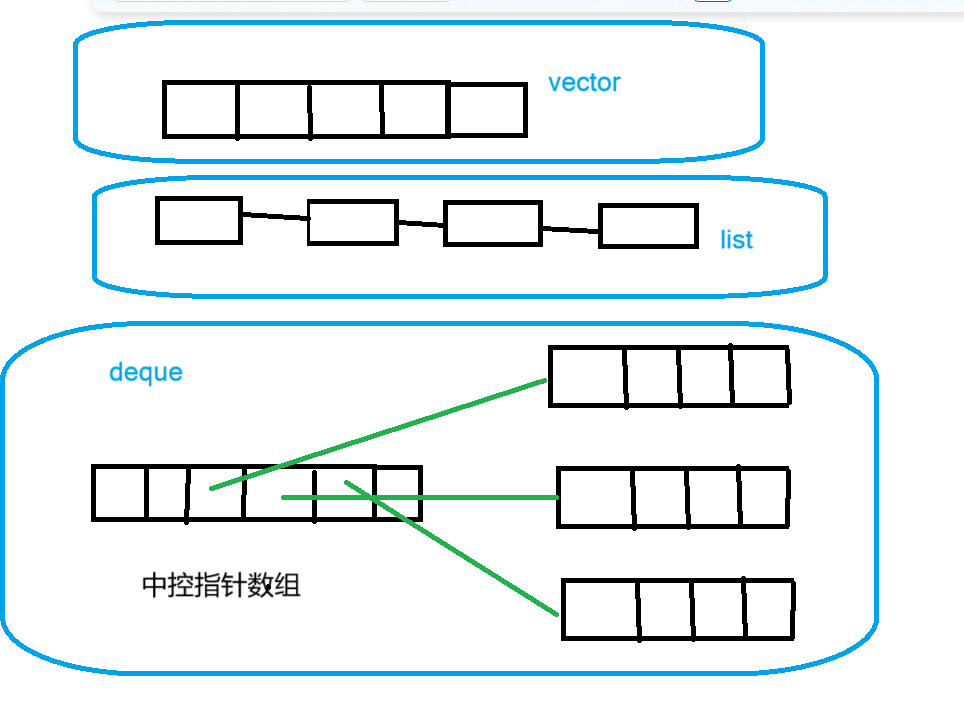
先简单了解一下deque的结构
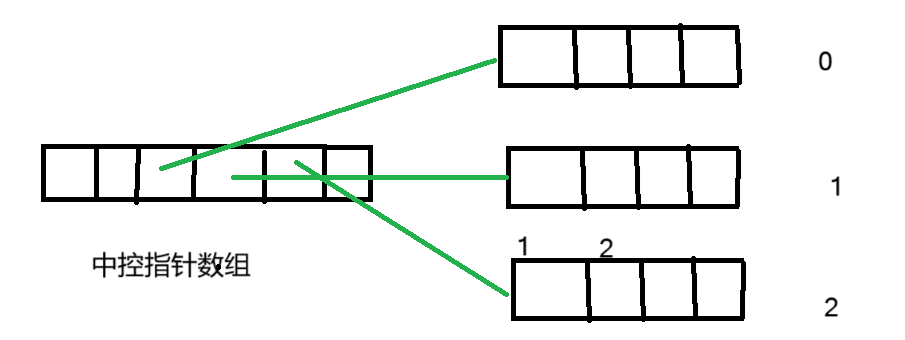
deque有一块块的数组 这些数组物理空间上不是连续的 然后有一个中控指针数组的东西 里面存的是指针 它最中间位置里面的指针指向第一个数组 下一个位置的指针指向第二个数组的 以此类推 那么为什么要以中间开始呢这个在后面再解释
deque有了这样一块块的数组
如下图 以每一块数组有四个空间为例 如果我们想找到第六个元素如何找到呢
6/4=1 6%4=2 那么就是在第一个数组(这从0开始) 第二个位置
简单先了解deque的大概结构之后 那么是怎么找到一个个数组的 在里面又是怎么实现那些各个接口的功能的就需要再细致理解一下迭代器
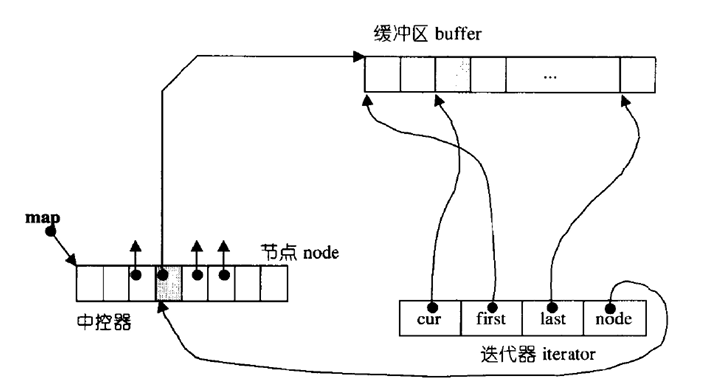
如下 迭代器里面有四个指针 first和last分别指向当前数组的的第一个位置后最后一个元素的后一个位置 cur指向当前元素的位置用于遍历数组 还有一个node是二级指针
之前不是提到一个中控指针数组就是下图的中控器 它里面某一个位置存着当前迭代器指向的数组的地址 是一个一级指针 而node这个二级指针就是指向这个指针 可以用于找到下一个数组
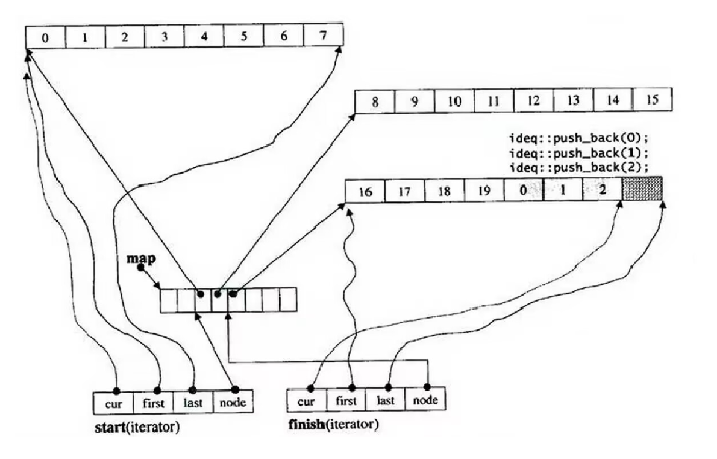
在理解了上面的之后 deque里面有start和finish两个迭代器 start里面的first last和cur指向第一个数组相应的位置 finish的first last和cur指向最后一个数组相应的位置 node就指向中控指针数组里面对应的指针
这里就简单说一下 ++ 及尾插头插吧
如果要实现之前的迭代器方式打印 如下面这样 那么就需要重载++

下面为原码中 ++的重载实现
不管什么情况 先++cur让其指向下一个位置
此时分为两种情况第一种还不是当前数组的后一个位置即last 那么就不需要做额外处理 直到++到第二种情况等于当前数组最后一个元素的后一个位置last 那么此时就应该指向下一个数组的第一个位置了 通过下面的set_node(node+1)来实现
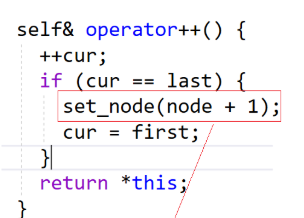
set_node传的实参node+1其实就是中控指针数组当前指向位置的后一个位置即下一个数组的地址
set_node如下图 那么这里的形参new_node 其实就是下一个数组的地址 在函数里面让node指向现在新数组的地址 然后对first及last进行处理 new_node是此时新数组的地址 在解引用之后就是这个新数组的第一个位置first指向这个位置 然后last在进行处理后就指向了当前数组最后一个元素的后一个位置了也
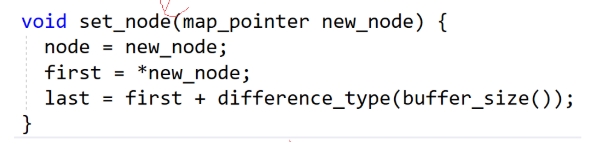
对于尾插是新开一块和之前一样固定大小的数组空间 然后其地址给了中控指针数组的下一个位置
对于头删一样的道理 不过新的数组地址是给了中控指针数组第一个存在地址数据的前一个位置
所以刚开始说的第一个数组的地址要存在中控指针数组中间的位置原因就是在这里 要预留空间存头增所开辟的数组地址 对于这个中控指针数组当它空间不够也会扩容
deque也支持重载[]然后就可以下标访问 重载[]其实是赋用了如下+=的逻辑
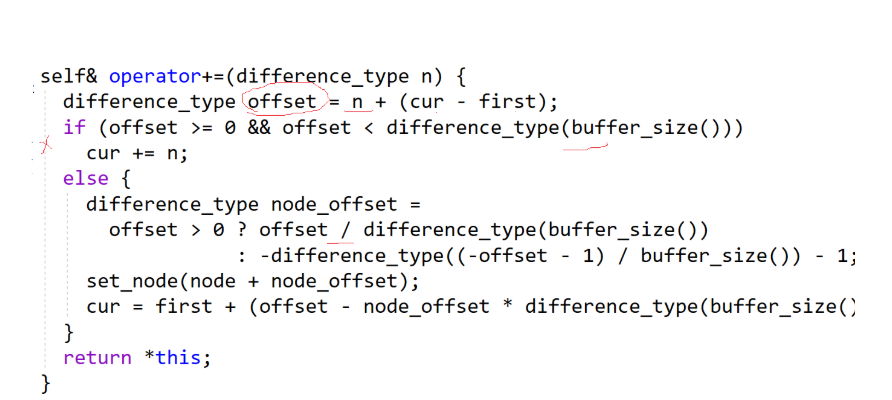
最后总结一下deque
1.deque的头插尾插效率高 比vector和list都好 (vector需要挪动数据 list只能一个一个空间来开辟deque能直接开一块 )
2.支持下标访问 但是不如vector的效率高
3.但是中间插入数据的时候 还是需要挪动很多数据(不能对里面某个数组进行扩容 否则会影响到其他接口 )
所以deque适合只对头尾操作 需要支持偶尔下标访问的结构
所以一开始的问题 stack和queue的第二个模版的默认缺省值为deque<T>就很合适 栈和队列只需要对头尾进行数据处理
priority_queue

priority_queue和stack和queue 一样都是容器适配器 主要的接口其实就是top和pop
它的其实底层就是之前数据结构学习的堆的结构 top就是获取堆顶的数 pop也是删除堆顶的数

先插入一些数 此时里面已经是堆的结构了 默认建的是大堆 然后打印一个堆顶的元素之后删除堆顶的元素就会正常按照从大到小的顺序打印出来
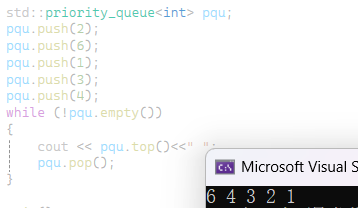
接下来实现priority_queue
和之前的栈和队列一样 如以下的结构 这里的容器默认为vector<T> (底层是堆 堆底层实际是顺序表不能用list)
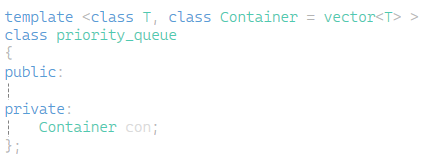
以下的功能很简单 size和empty直接调用容器自身的 top返回的就是堆顶也就是第一个位置的元素

而对于插入和删除也就是之前堆里面实现过的 这里就简单解释 在尾部插入一个元素之后 对其进行向上调整 让这个堆仍是大堆
删除是要删除堆顶的元素 但是如果直接删堆顶的话 会把堆的结构给破坏掉 所以采取的方式是先交换堆顶和最后一个元素的位置 然后进行尾删(也就是把开始堆顶的删除了) 然后让交换到堆顶的元素进行向下调整

下面为向上调整和向下调整


这样默认建的是大堆 如果要改成小堆只需要改变向上调整和向下调整里面的交换逻辑
但是如果别人来使用的话 怎么能直接选择要建的是大堆还是小堆呢
一种方法是再写一个类全部都一样只是里面向下调整和向上调整的交换逻辑不同 在使用的时候调用不同的类 但是这种方式需要重写一个类很麻烦
另一种方式伪代码的方式 这也是源代码里面使用到的方式
源代码
如下图 写了一个类Less 在里面重载了() 然后创建一个Less类的对象le
如果只看最后一行的cout<<le(a,b); 可能就以为这个le是一个函数 但是其实是类的一个对象
仿函数本质其实就是一个类的对象 通过在类里面重载了() 让这个类的对象能像函数一样使用

除了Less 在写一个Greater判断逻辑和Less相反
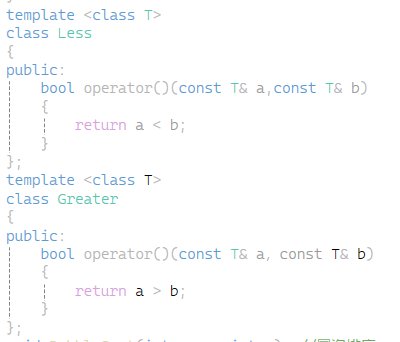
先结合冒泡排序来理解一下仿函数 如下图排序之后是从小打到排序 要改变成逆序只需要改变if判断的逻辑
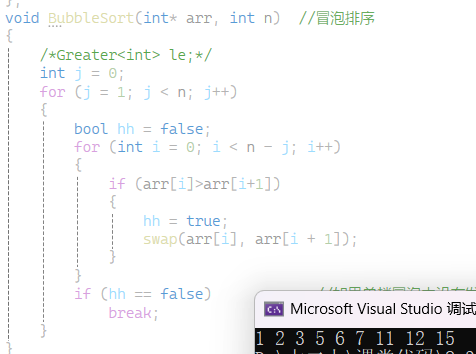
如果用Less类型的对象仿函数的方式 结果就是逆序
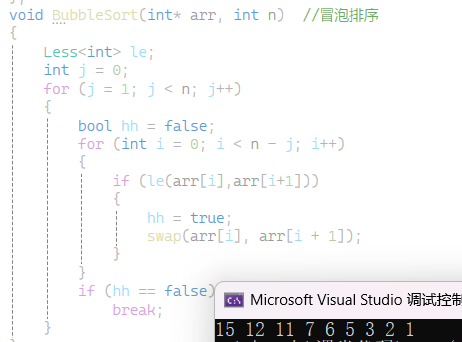
用Greater就是正序
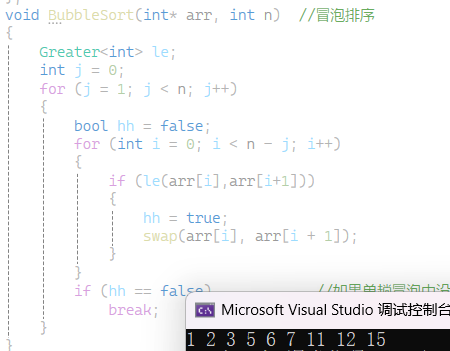
当然还取决于调用仿函数时候里面两个参数的位置 参数位置交换了 排序结果就会交换
有了这两个类之后 用仿函数再结合模版 我们就可以解决开始的问题
在类里面再多一个模版Comper 默认缺省值为Less类型的对象 其实可以直接用匿名对象方式 Less<T>
std中的Less是升序排序 Greater是降序 在实现时候在对应交换逻辑的地方通过参数位置实现我们期望的
既然默认Less 要和stl中一样 那其实就是Less时候要为升序 那我们就建大堆
下面为修改后的


这里的是正序排序是说建大堆后 通过进行堆顶和最后一个交换然后堆顶元素向下排序这样循环操作之后是正序