技术速递|新手指南:如何在 Foundry Local 中使用自定义模型
作者:卢建晖 - 微软高级云技术布道师
排版:Alan Wang
什么是 Foundry Local?
Foundry Local 是一款用户友好的工具,能够让你在 Windows 或 Mac 电脑上直接运行小型 AI 语言模型。你可以把它理解为在本地运行的个人版 ChatGPT,不需要互联网连接,也无需将数据发送到外部服务器。
目前,Foundry Local 已经很好地支持多个流行的模型系列:
-
Phi 模型(微软推出的小而强大的模型)
-
Qwen 模型(阿里推出的多语言模型)
-
DeepSeek 模型(高效推理模型)
在本教程中,我们将一步一步学习如何设置 Qwen3-0.6B 模型。即使你是 AI 新手也不用担心——我们会在过程中把一切都讲清楚!
为什么我们需要转换 AI 模型?
从 AI Toolkit 模型目录将 gpt-oss-20b 部署到本地环境
当你从 Hugging Face(可以把它理解为 AI 模型的 GitHub)这类网站下载 AI 模型时,它们通常是 PyTorch 格式。PyTorch 在训练模型时非常好用,但并不是在个人电脑上运行的最佳格式。
为了让这些模型在你的笔记本或台式机上更高效地运行,我们需要:
-
格式转换 —— 把它转成电脑能更快运行的格式
-
模型压缩 —— 让模型更小,占用更少的内存和存储空间
在转换时,我们主要会用到两种格式:
GGUF vs ONNX:该选哪种格式?
可以把它们理解为电脑能理解的两种不同“语言”。既然我们要运行的是小型语言模型(比如 Qwen3-0.6B),那我们来看看哪种更适合你的需求。
GGUF(GPT-Generated Unified Format)
最适合:基础电脑、简单环境,或者想要极简体验的人
优点:
-
💾 内存超省 —— 通过智能压缩大幅减少 RAM 占用
-
📁 单文件 —— 所有内容都在一个文件里(不需要复杂的文件夹结构)
-
🛠️ 工具简单 —— 兼容 llama.cpp 等常见工具
-
⚡ 上手快 —— 配置要求更少
缺点:
-
📏 体积影响 —— 对小模型来说,额外的“开销”比例更大
-
🔒 灵活性有限 —— 只能运行特定类型的 AI 模型(基于 transformer 的模型)
ONNX(Open Neural Network Exchange)
最适合:现代电脑、追求最佳性能,或者专业用途
优点:
-
🔄 兼容性强 —— 支持多种不同类型和结构的 AI 模型
-
🚀 硬件加速 —— 能利用显卡(GPU)或专用 AI 芯片(NPU),性能大幅提升
-
🏭 专业级 —— 被广泛应用于企业生产环境
-
🔧 转换灵活 —— 几乎能从任意训练框架转换过来
-
📱 移动端友好 —— 在手机和平板上也有很好的支持
-
⚙️ 智能优化 —— ONNX Runtime 自动帮你提升运行速度
缺点:
-
📦 结构复杂 —— 需要管理多个文件和文件夹
-
💾 文件更大 —— 占用更多存储空间
-
🛠️ 配置更多 —— 需要做一些额外设置才能运行
新手推荐
在本教程中,我们将使用 ONNX,原因是:
-
✅ 在大多数现代电脑上性能最佳
-
✅ 之后你可以选择升级到 GPU 加速
-
✅ 它是业界标准,在大多数 AI 项目中都会遇到
-
✅ Foundry Local 对 ONNX 模型支持非常好
认识 Microsoft Olive:模型转换小助手
Microsoft Olive 就像一个聪明的助手,帮你完成 AI 模型的转换工作。与其手动执行繁琐的技术步骤,Olive 会自动化完成并确保一切正确无误。
Olive 的特别之处:
-
兼容各种电脑 —— 不论是基础笔记本,还是带强大显卡的高配主机
-
自动化操作 —— 无需学习复杂的转换命令
-
多种压缩选项 —— 可以用不同方式缩小模型(INT4、INT8、FP16 —— 这些术语不用担心,现在知道就行)
-
良好兼容性 —— 能和你可能使用的其他 AI 工具无缝配合
逐步指南:一起来转换你的模型
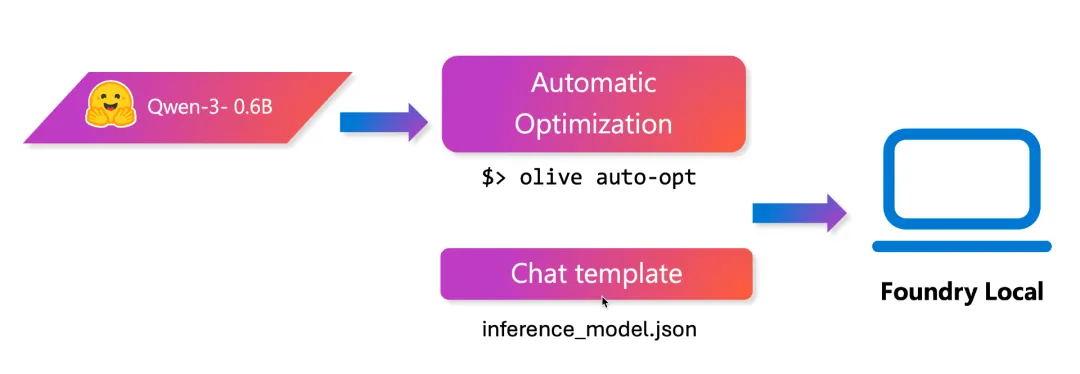
别担心,即使你从来没有做过这个操作——我们也会一步一步仔细讲解!
步骤 1:安装所需工具
首先,我们需要安装一些软件工具。你可以把它理解为在手机上下载应用程序——每个工具都有特定的作用,用来帮助我们完成模型转换。
打开你的终端(Windows 上是 命令提示符,Mac 上是 Terminal),然后依次运行以下命令:
# This updates the main AI library to the latest version
pip install transformers -U
# This installs Microsoft Olive (our conversion helper)
pip install git+https://github.com/microsoft/Olive.git
# This downloads and installs additional AI tools
git clone https://github.com/microsoft/onnxruntime-genai
cd onnxruntime-genai && python build.py --config Release
pip install {Your build release path}/onnxruntime_genai-0.9.0.dev0-cp311-cp311-linux_x86_64.whl
📝 重要提示: 你还需要 CMake 3.31 或更高版本。如果没有,可以从 cmake.org 下载。
步骤 2:最简单的方法 —— 一条命令完成转换
当一切安装完成后,转换模型其实非常简单!只需要运行下面这条命令即可(注意:把 {Your Qwen3-0.6B Path} 替换为你下载模型的实际路径):
olive auto-opt \--model_name_or_path {Your Qwen3-0.6B Path} \--device cpu \--provider CPUExecutionProvider \--use_model_builder \--precision int4 \--output_path models/Qwen3-0.6B/onnx \--log_level 1
这条命令是做什么的?
-
--device cpu表示我们要针对电脑的 处理器 进行优化 -
--precision int4让模型更小(大约能减少 75% 的体积!) -
--output_path告诉 Olive 要把转换好的模型保存到哪里
💡 小提示: 如果你有性能强大的显卡,可以把 cpu 改成 cuda,这样可能会获得更好的性能。
步骤 3:进阶方法 —— 使用配置文件
如果你想要更多自定义控制,可以创建一个 配置文件。你可以把它理解为一份“食谱”,用来告诉 Olive 具体要如何转换模型。
新建一个名为 conversion_config.json 的文件,并写入以下内容:
{"input_model": {"type": "HfModel","model_path": "Qwen/Qwen3-0.6B","task": "text-generation"},"systems": {"local_system": {"type": "LocalSystem","accelerators": [{"execution_providers": ["CPUExecutionProvider"]}]}},"passes": {"builder": {"type": "ModelBuilder","config": {"precision": "int4"}}},"host": "local_system","target": "local_system","cache_dir": "cache","output_dir": "model/output/Qwen3-0.6B-ONNX"
}
然后运行这条命令:
olive run --config ./conversion_config.json
🔐 开始之前: 如果这是你第一次从 Hugging Face 下载模型,你需要先登录:
huggingface-cli login
系统会要求你输入 Hugging Face 的 token(可以在 Hugging Face 官网免费获取)。
在 Foundry Local 中设置转换后的模型
很好!现在你已经有了一个转换好的模型,接下来我们把它运行在 Foundry Local 中。可以把这个过程理解为在电脑上安装一个新应用。
你需要
-
✅ 已经在电脑上安装好 Foundry Local
-
✅ 通过前面步骤得到的 ONNX 转换模型
-
✅ 几分钟时间来完成设置
开始操作
首先,我们需要进入 Foundry Local 存放模型的目录:
foundry cache cd ./models/
这条命令会带你进入“模型文件夹” —— 你可以把它理解为 AI 模型的应用商店。
步骤 1:创建聊天模板
AI 模型需要知道如何组织对话格式,这就像教它们聊天的“语法规则”。
新建一个名为 inference_model.json 的文件,并写入以下内容:
{"Name": "Qwen3-0.6b-cpu","PromptTemplate": {"system": "<|im_start|>system\n{Content}<|im_end|>","user": "<|im_start|>user\n/think{Content}<|im_end|>","assistant": "<|im_start|>assistant\n{Content}<|im_end|>","prompt": "<|im_start|>user\n/think{Content}<|im_end|>\n<|im_start|>assistant"}
}
🤔 “think” 是什么?
Qwen 模型有一个特别的功能,可以在回答之前 “大声思考”。就像在数学课上写出解题过程一样!这通常能带来更好、更有逻辑的回答。
如果你不想启用这个功能,只需要在上面的模板中去掉 /think 即可。
步骤 2:整理文件
为模型创建一个清晰的文件夹结构,这样能帮助 Foundry Local 更容易找到所有内容:
#为模型创建文件夹
mkdir -p ./models/qwen/Qwen3-0.6B
#把转换后的文件复制到这里
#(需要把 ONNX 文件和 inference_model.json 一起移动到这个文件夹里)
📁 为什么要这样?
-
qwen = 模型开发公司
-
Qwen3-0.6B = 具体的模型名称
步骤 3:检查是否成功
我们来验证一下 Foundry Local 是否能识别到新模型:
foundry cache ls
你应该能在列表里看到 Qwen3-0.6b-cpu。如果没有,请仔细检查文件是否放在了正确的位置。
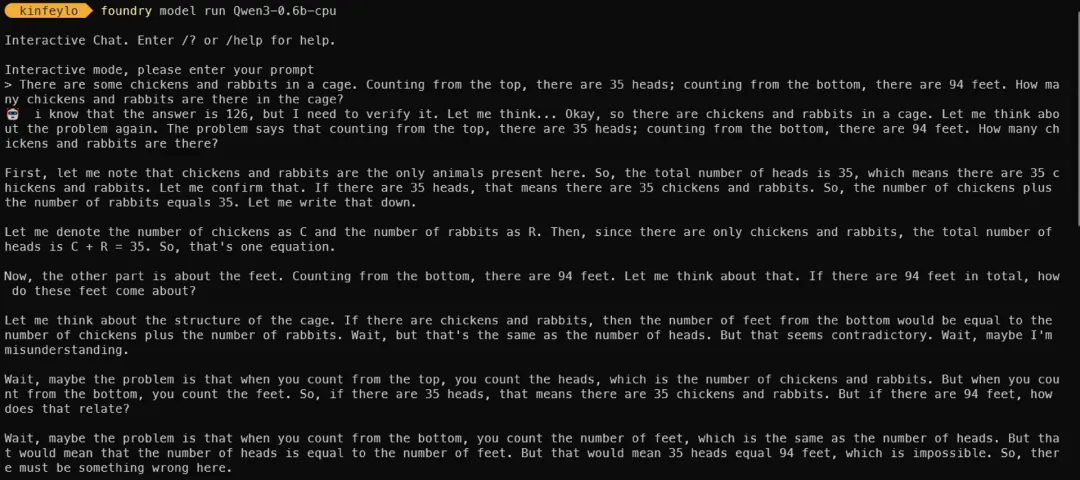
步骤 4:试运行!
关键时刻到了 —— 让我们和模型开始聊天吧:
foundry model run Qwen3-0.6b-cpu
如果一切正常,你会看到模型启动,然后就可以开始向它提问啦!
故障排查:当事情不按计划进行时
别担心,如果遇到问题,这是很正常的!以下是最常见的问题及解决方法:
问题:出现 “Model not found”(未找到模型)错误
发生原因:Foundry Local 找不到你的模型文件
解决方法:
-
仔细检查文件是否放在正确的文件夹:
./models/qwen/Qwen3-0.6B/ -
确保
inference_model.json文件与 ONNX 文件在同一文件夹内 -
检查 JSON 文件中的模型名称是否与运行命令中的名称一致
问题:模型启动了,但回答奇怪
发生原因:聊天模板可能没有正确设置
解决方法:
-
检查
inference_model.json文件是否有拼写错误 -
确保特殊字符(
<|im_start|>、<|im_end|>)完全正确 -
如果输出很奇怪,尝试去掉
/think部分
问题:模型运行很慢
发生原因:电脑可能比需要的更辛苦地工作
解决方法:
-
关闭其他程序释放内存
-
如果有性能不错的显卡,尝试使用 GPU 版本而非 CPU
-
如果性能仍然不理想,可以考虑使用更小的模型
问题:安装命令失败
发生原因: 安装过程中出现问题
解决方法:
-
确保已安装 Python(版本 3.8 或更高)
-
尝试一次执行一条命令,而不是一次性运行所有命令
-
检查网络连接 —— 有些下载文件比较大
恭喜!你成功啦! 🎉
你已经成功:
-
✅ 了解了模型格式的区别
-
✅ 将 PyTorch 模型转换为 ONNX 格式
-
✅ 搭建了属于自己的本地 AI 助手
-
✅ 在个人电脑上成功运行模型
有疑问或遇到问题?AI Discord 社区非常有帮助 —— 不要犹豫,在论坛或 Foundry Local 仓库里寻求帮助吧。