人工智能-python-深度学习-批量标准化与模型保存加载详解
文章目录
- 批量标准化与模型保存加载详解
- 1. 批量标准化(Batch Normalization, BN)
- 1.1 训练阶段的批量标准化流程
- 1.2 测试阶段的批量标准化
- 1.3 批量标准化的作用
- 1.4 PyTorch 中的函数说明
- 1.5 代码实现示例
- 2. 模型的保存与加载
- 2.1 标准网络模型构建
- 2.2 序列化模型对象
- 2.3 保存模型参数(推荐 ✅)
- 3. 结果导向总结
批量标准化与模型保存加载详解
1. 批量标准化(Batch Normalization, BN)
批量标准化(Batch Normalization)是一种广泛使用的神经网络正则化技术,核心思想是对每一层的输入进行标准化, 然后进行缩放和平移,旨在加速训练,提高模型的稳定性和泛化能力。批量标准化通常在全连接层或卷积层之后,激活函数之前应用
核心思想:
Batch Normalization(BN)通过对每一批(batch)数据的每个特征通道进行标准化,解决内部协变量偏移(Internal Covariate Shift)问题,从而:
- 加速网络训练
- 允许使用更大的学习率
- 减少对初始化的依赖
- 提供轻微的正则化效果
批量标准化的基本思路是在每一层的输入上执行标准化操作,并学习两个可训练的参数:缩放因子 γ\gammaγ 和偏移量 β\betaβ。
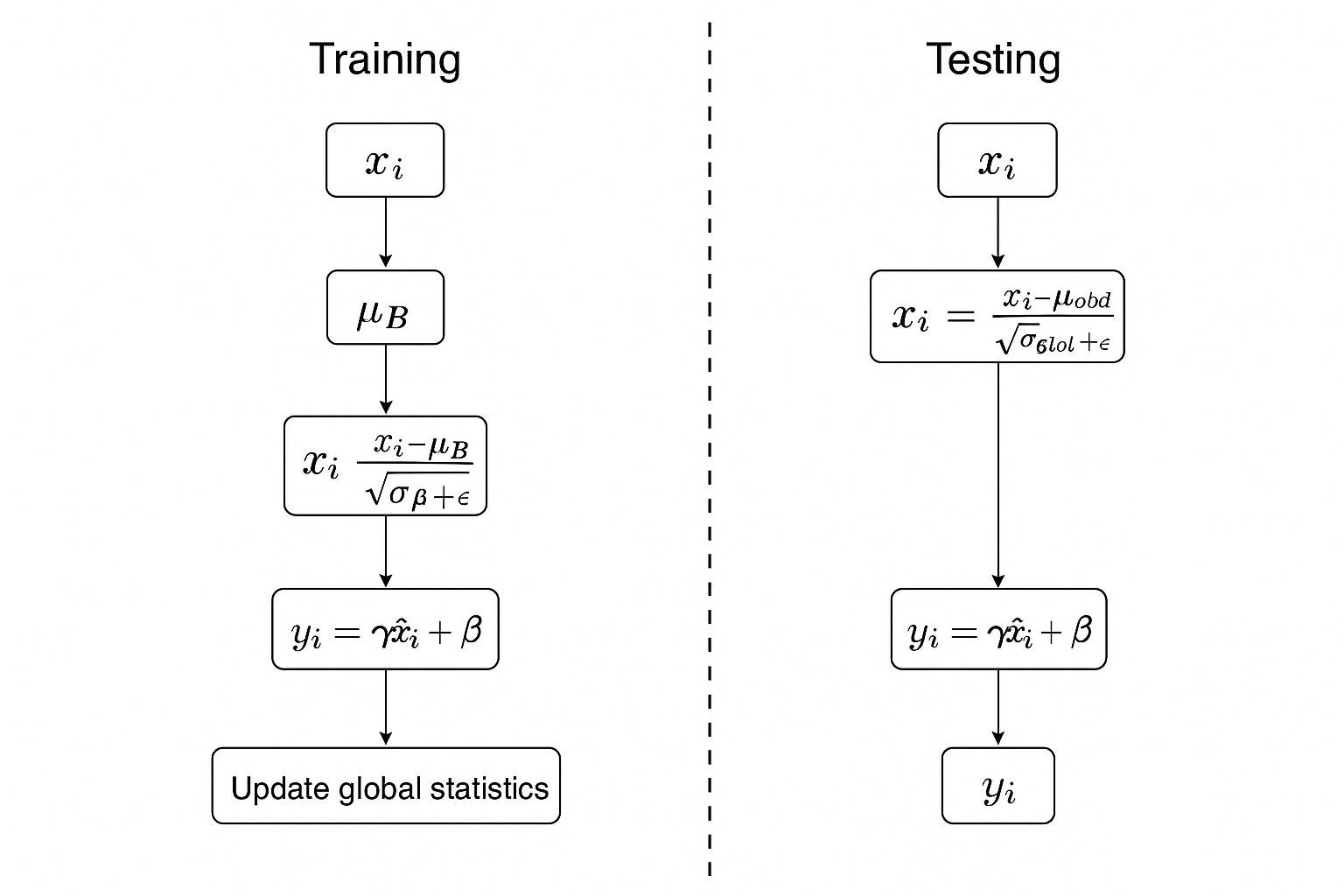
在深度学习中,批量标准化(Batch Normalization)在训练阶段和测试阶段的行为是不同的。在测试阶段,由于没有 mini-batch 数据,无法直接计算当前 batch 的均值和方差,因此需要使用训练阶段计算的全局统计量(均值和方差)来进行标准化。
1.1 训练阶段的批量标准化流程
在训练过程中,BN 的核心思想是让每一层的输入分布保持稳定,避免“内部协变量偏移(Internal Covariate Shift)”。流程如下:
-
计算均值和方差
对 mini-batch 内的每个特征维度计算:μB=1m∑i=1mxi,σB2=1m∑i=1m(xi−μB)2\mu_B = \frac{1}{m}\sum_{i=1}^m x_i,\quad \sigma_B^2 = \frac{1}{m}\sum_{i=1}^m (x_i - \mu_B)^2 μB=m1i=1∑mxi,σB2=m1i=1∑m(xi−μB)2
-
标准化
对输入数据进行归一化,使其均值为 0,方差为 1:x^i=xi−μBσB2+ϵ\hat{x}_i = \frac{x_i - \mu_B}{\sqrt{\sigma_B^2 + \epsilon}} x^i=σB2+ϵxi−μB
-
缩放和平移
引入可学习参数 γ,β\gamma, \betaγ,β,恢复网络表达能力:yi=γx^i+βy_i = \gamma \hat{x}_i + \beta yi=γx^i+β
-
更新全局统计量
维护一个 滑动平均的全局均值与方差,用于测试阶段。
1.2 测试阶段的批量标准化
在测试阶段,没有 mini-batch 的均值和方差,因此采用训练过程中累计的 全局均值和方差 来进行标准化:
x^i=xi−μglobalσglobal2+ϵ\hat{x}_i = \frac{x_i - \mu_{global}}{\sqrt{\sigma_{global}^2 + \epsilon}} x^i=σglobal2+ϵxi−μglobal
1.3 批量标准化的作用
- ✅ 缓解梯度消失/爆炸问题:让激活值保持在合理范围,梯度传播更稳定。
- ✅ 加速训练收敛:输入分布更稳定,学习率可以更大。
- ✅ 减少过拟合:带来轻微的正则化效果(类似 Dropout 的扰动)。
1.4 PyTorch 中的函数说明
PyTorch 提供了多种 BN 层:
nn.BatchNorm1d(num_features):用于全连接层或 1D 数据(如序列)。nn.BatchNorm2d(num_features):用于图像卷积层。nn.BatchNorm3d(num_features):用于 3D 卷积数据(如视频)。
常用参数:
num_features: 特征数量(通常等于通道数)。eps: 防止除 0 的极小值,默认1e-5。momentum: 控制滑动平均更新速度。affine: 是否有可学习参数 γ,β\gamma, \betaγ,β。
1.5 代码实现示例
import torch
import torch.nn as nnclass Net(nn.Module):def __init__(self):super(Net, self).__init__()self.layer1 = nn.Sequential(nn.Conv2d(3, 16, kernel_size=3, stride=1, padding=1),nn.BatchNorm2d(16), # 批量标准化nn.ReLU())self.fc = nn.Linear(16*32*32, 10)def forward(self, x):out = self.layer1(x)out = out.view(out.size(0), -1)out = self.fc(out)return outnet = Net()
print(net)
2. 模型的保存与加载
2.1 标准网络模型构建
一般构建好一个 nn.Module 网络结构(如上例中的 Net)。
2.2 序列化模型对象
-
保存整个模型对象(包含结构和参数):
torch.save(net, "model.pth")加载时:
model = torch.load("model.pth") model.eval()
⚠️ 缺点:跨环境加载可能会失败(因为依赖代码定义)。
2.3 保存模型参数(推荐 ✅)
只保存参数字典 state_dict,更灵活:
# 保存模型参数
torch.save(net.state_dict(), "model_params.pth")# 加载模型参数
model = Net()
model.load_state_dict(torch.load("model_params.pth"))
model.eval()
3. 结果导向总结
-
批量标准化(BN) 解决了梯度不稳定、收敛慢、过拟合等问题,是现代深度网络的标配。
-
模型保存与加载 是工程落地的关键步骤:
- 保存整个模型适合快速实验;
- 保存参数字典更适合跨环境部署和迁移学习。