【Doris入门】Doris表模型完全指南:明细、聚合、主键模型的选择与优化技巧
目录
引言
1 Doris数据模型基础概念
1.1 什么是数据模型?
1.2 Doris数据模型概述
1.3 Key列与Value列
2 三种数据模型详解
2.1 Duplicate Key Model(明细模型)
2.1.1 模型简介
2.1.2 工作原理
2.1.3 适用场景
2.1.4 建表示例:
2.2 Aggregate Key Model(聚合模型)
2.2.1 模型简介
2.2.2 聚合类型详解
2.2.3 工作原理
2.2.4 聚合示例
2.2.5 建表示例
2.3 Unique Key Model(主键模型)
2.3.1 模型简介
2.3.2 实现方式
2.3.3 工作原理
2.3.4 与Aggregate模型的关系
2.3.5 建表示例
3 数据模型对比与选择
3.1 三种模型能力对比
3.2 数据模型选择决策流程
3.3 典型应用场景示例
3.3.1 电商系统数据建模
3.3.2 数据仓库分层建模
4 数据模型内部机制
4.1 数据存储结构
4.2 数据模型与存储的关系
4.3 ROLLUP与数据模型
5 实践建议与性能优化
5.1 数据模型选择实践建议
5.2 性能优化建议
5.2.1 Duplicate模型优化
5.2.2 Aggregate模型优化
5.2.3 Unique模型优化
6 总结
引言
Apache Doris作为一款现代化的MPP架构分析型数据库,凭借其高性能、易用性和实时分析能力,在数据仓库和BI分析领域获得了广泛应用。对于Doris初学者来说,理解其数据表模型是掌握Doris的关键第一步。
1 Doris数据模型基础概念
1.1 什么是数据模型?
在数据库领域,数据模型是定义数据如何存储、组织和访问的框架。它决定了数据的逻辑结构、操作约束以及数据之间的关系。对于Doris这样的分析型数据库而言,数据模型直接影响着查询性能、存储效率和数据处理能力。
数据模型的核心作用:
- 定义数据的存储方式
- 确定数据的组织结构
- 影响查询性能和效率
- 决定数据处理的能力和限制
1.2 Doris数据模型概述
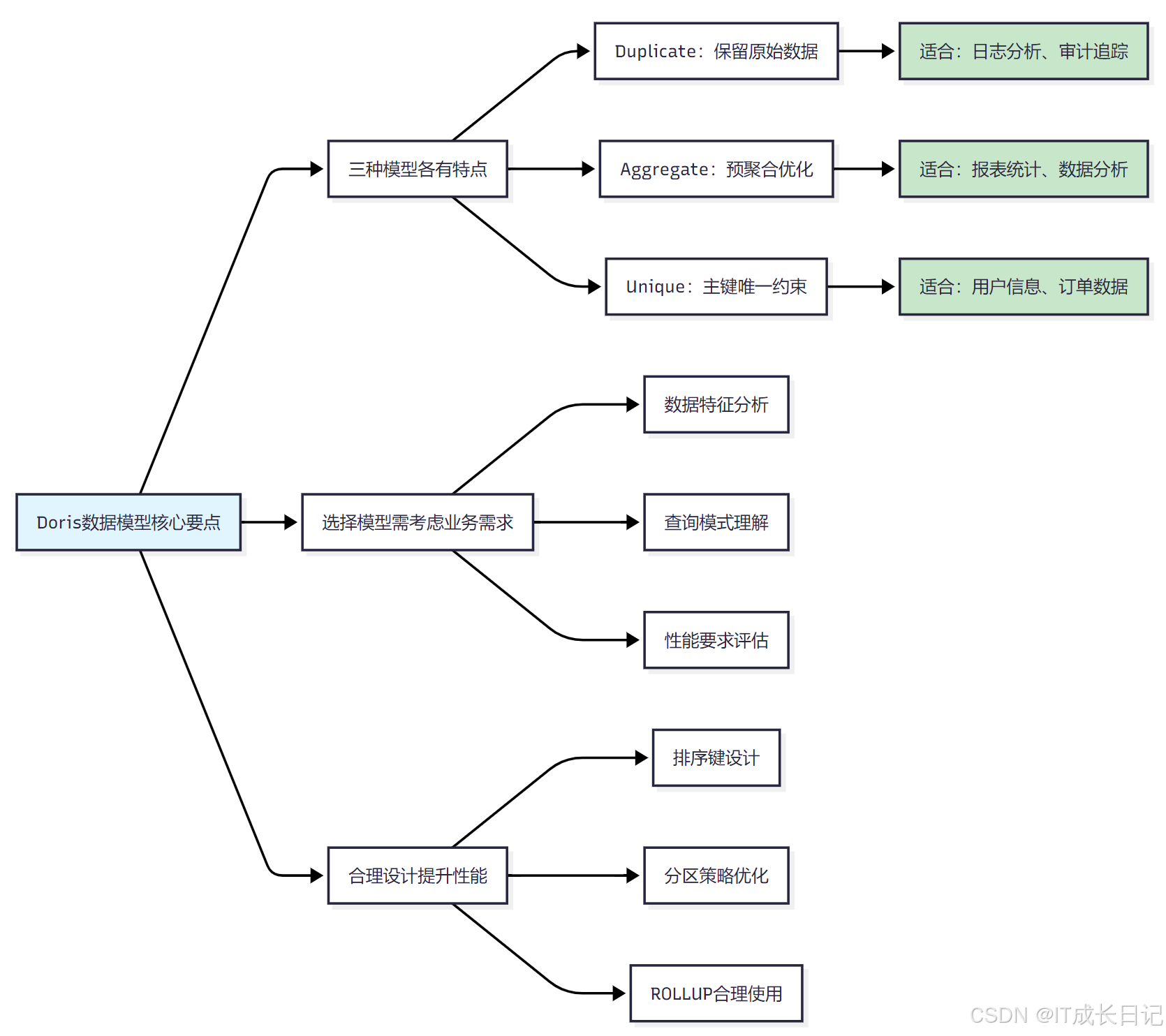
- Doris提供了三种核心数据模型,每种模型都有其特定的适用场景和优势:
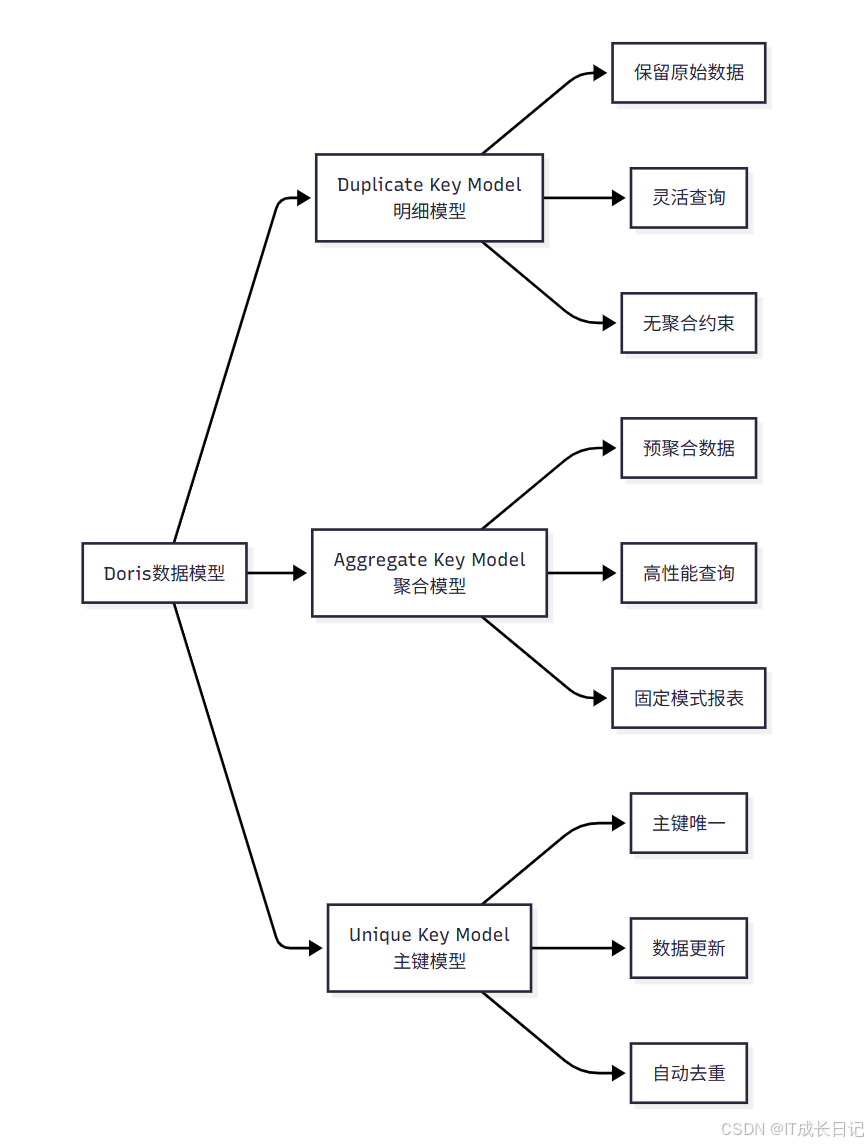
Doris三种数据模型的分类关系和核心特点:
- Duplicate模型:专注于保留原始数据,提供最大的查询灵活性
- Aggregate模型:通过预聚合提升查询性能,适合固定模式的报表查询
- Unique模型:保证主键唯一性,支持数据更新和自动去重
1.3 Key列与Value列
在Doris的数据模型中,列被分为Key列和Value列两大类:
- Key列:也称为维度列,用于数据的分组、排序和去重
- Value列:也称为指标列,用于存储需要聚合或计算的数值
- Key列与Value列的关系:
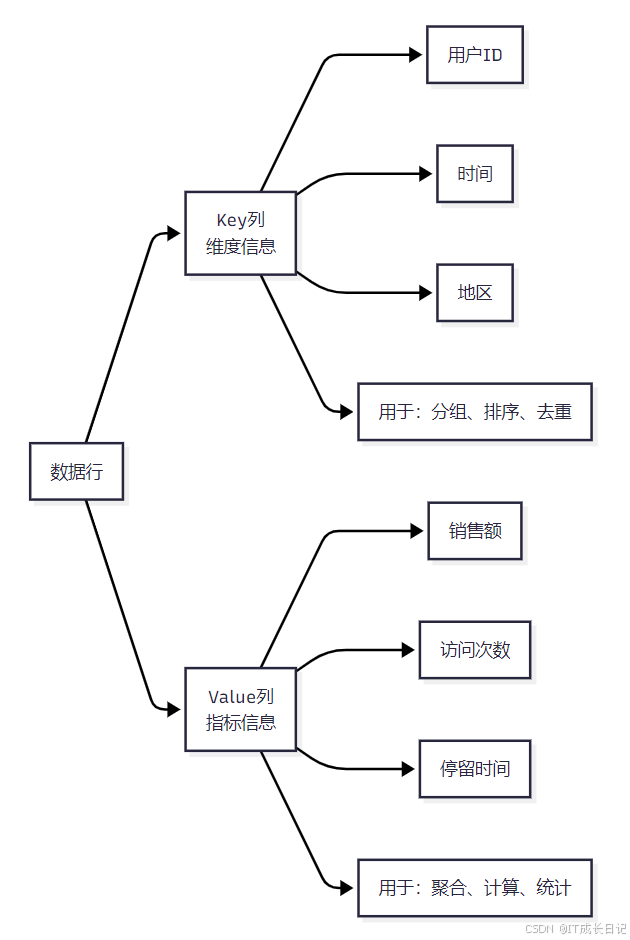
- Key列:包含业务维度信息,如用户ID、时间、地区等,用于数据的组织和管理
- Value列:包含业务指标信息,如销售额、访问次数等,用于数据分析和计算
- 两者的分工明确,Key列负责数据的组织,Value列负责数据的计算
2 三种数据模型详解
2.1 Duplicate Key Model(明细模型)
2.1.1 模型简介
Duplicate模型是Doris的默认数据模型,也是最简单的模型。它的核心特点是完全保留原始数据,不会对数据进行任何聚合或去重处理。无论数据是否重复,都会原样存储。
核心特征:
- 保留所有原始数据,不做任何处理
- 支持任意维度的灵活查询
- 适合需要详细分析的场景
2.1.2 工作原理
- Duplicate模型的工作流程:
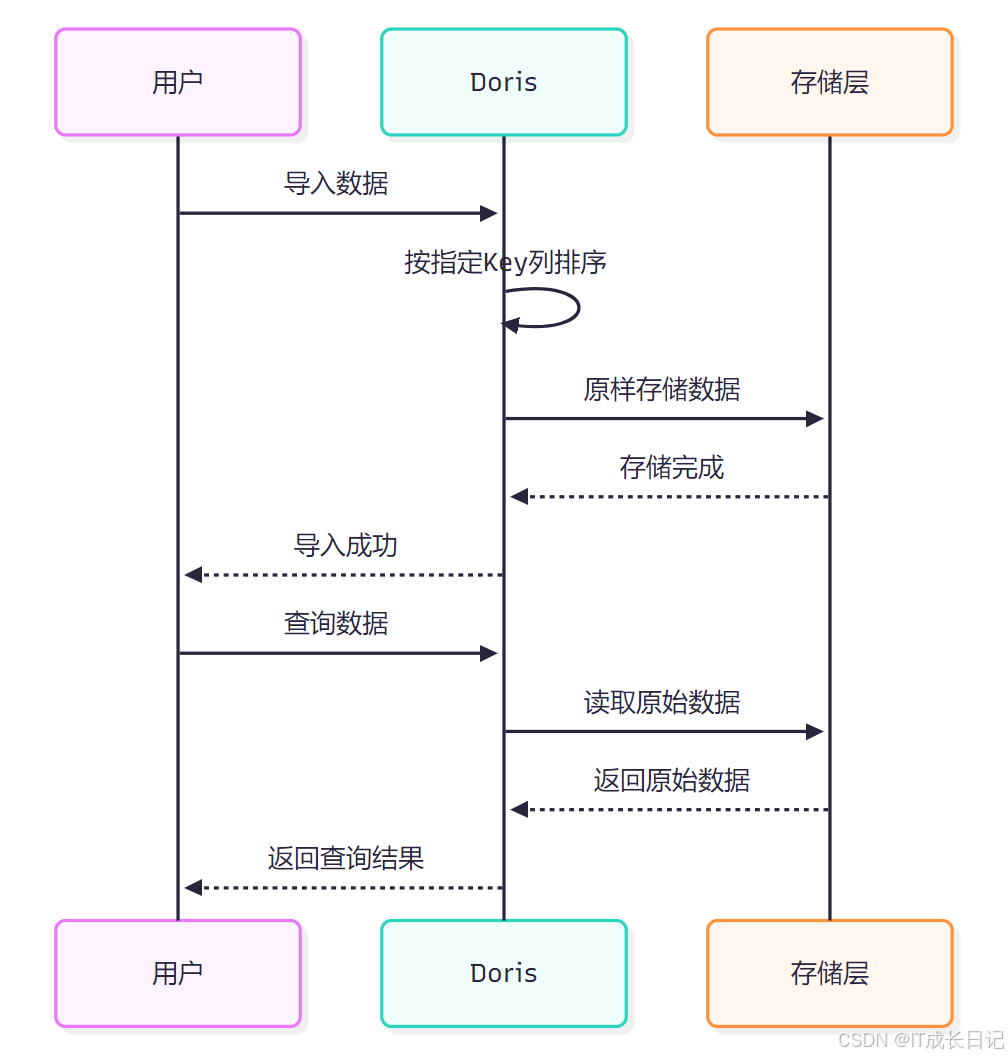
- 数据导入阶段:用户将数据导入Doris,系统按照指定的Key列对数据进行排序,但不会进行任何聚合或去重处理
- 数据存储阶段:数据被原样存储在存储层,完全保留原始格式
- 数据查询阶段:查询时直接返回原始数据,不进行任何额外处理
2.1.3 适用场景
Duplicate模型特别适合以下场景:
- 日志分析:需要保留所有原始日志,用于详细的问题排查和分析
- 审计追踪:必须完整记录所有操作历史,不能丢失任何细节
- 原始数据存储:作为数据仓库的ODS层,存储原始业务数据
- 灵活分析:需要进行各种Ad-hoc查询,不受预聚合限制
2.1.4 建表示例:
CREATE TABLE IF NOT EXISTS test_db.ods_log_tmp
(`timestamp` DATETIME NOT NULL COMMENT "日志时间",`user_id` BIGINT COMMENT "用户ID",`action` VARCHAR(50) COMMENT "用户操作",`page` VARCHAR(100) COMMENT "访问页面",`duration` INT COMMENT "停留时长"
)
DUPLICATE KEY(`timestamp`, `user_id`)
DISTRIBUTED BY HASH(`user_id`) BUCKETS 10
PROPERTIES ("replication_num" = "1"
);2.2 Aggregate Key Model(聚合模型)
2.2.1 模型简介
Aggregate模型是Doris最具特色的数据模型,它支持在数据导入时进行预聚合处理。对于Key列相同的行,Value列会按照指定的聚合方式进行自动计算,从而减少存储空间并提升查询性能。
核心特征:
- 支持多种聚合方式(SUM、MAX、MIN、REPLACE等)
- 预聚合减少数据量,提升查询性能
- 适合固定模式的报表查询
2.2.2 聚合类型详解
- Aggregate模型支持多种聚合类型,每种类型都有其特定的用途:
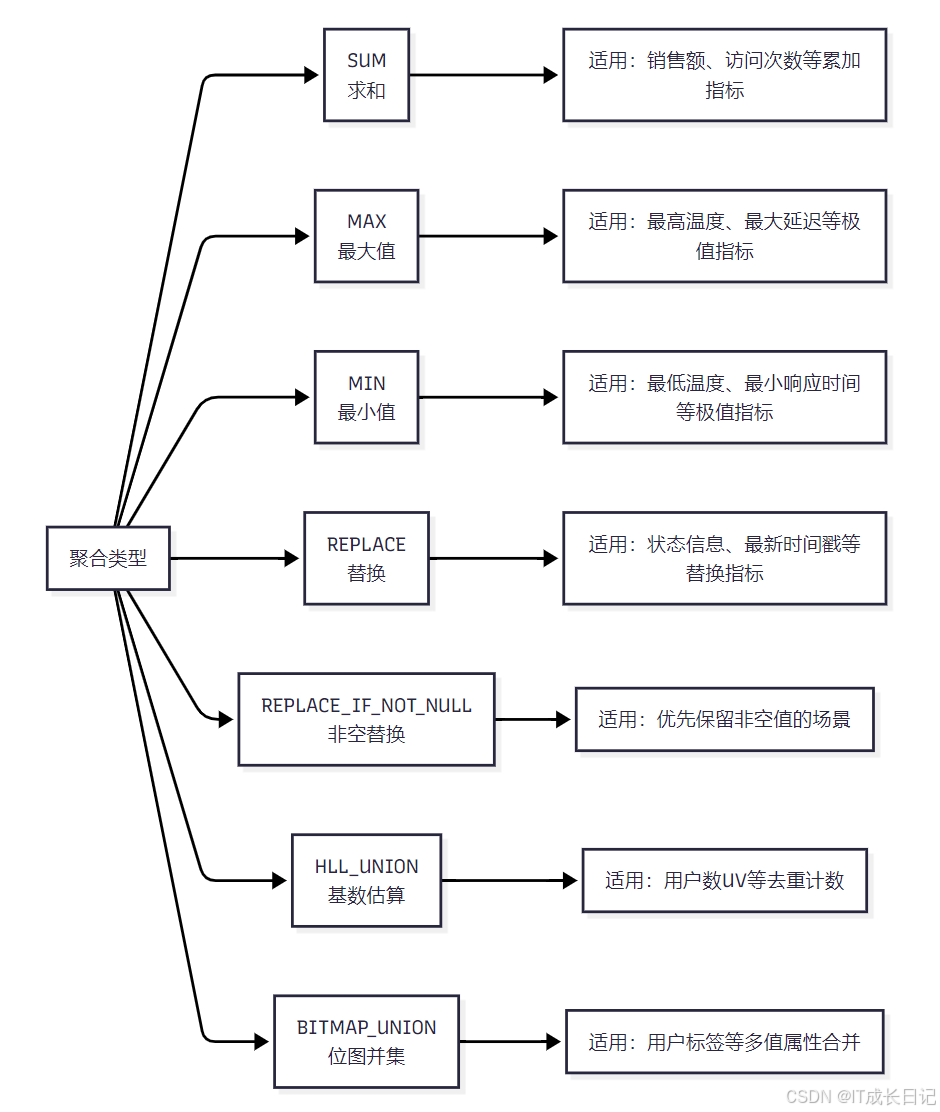
- SUM:用于需要累加的指标,如销售额、访问次数
- MAX/MIN:用于需要获取极值的指标,如最高/最低温度
- REPLACE:用于需要保留最新值的指标,如状态信息
- REPLACE_IF_NOT_NULL:用于优先保留非空值的场景
- HLL_UNION:用于去重计数,如统计用户数UV
- BITMAP_UNION:用于多值属性的合并,如用户标签
2.2.3 工作原理
- Aggregate模型的聚合过程可以分为三个阶段:
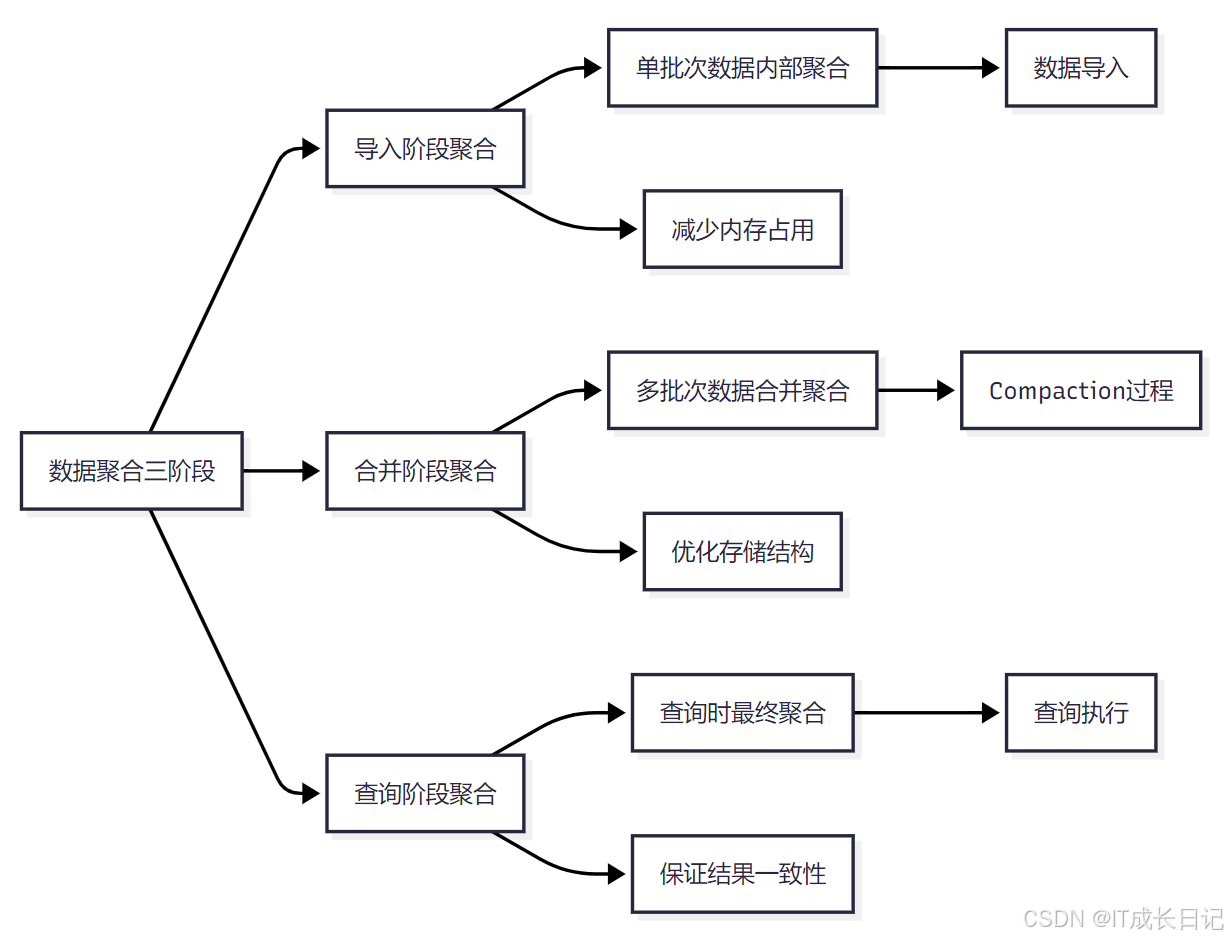
- 导入阶段聚合:数据导入时,在单个批次内部进行聚合,减少内存占用
- 合并阶段聚合:在后台Compaction过程中,将多个批次的数据进行合并聚合,优化存储结构
- 查询阶段聚合:查询时对尚未完全聚合的数据进行最终聚合,保证查询结果的一致性
2.2.4 聚合示例
- 原始数据:
| user_id | date | city | cost | visit_time |
| 10001 | 2025-07-01 | 北京 | 100 | 10 |
| 10001 | 2025-07-01 | 北京 | 200 | 15 |
| 10002 | 2025-07-01 | 上海 | 150 | 20 |
- 聚合后数据:
| user_id | date | city | cost(SUM) | visit_time(MAX) |
| 1001 | 2025-07-01 | 北京 | 300 | 15 |
| 1002 | 2025-07-01 | 上海 | 150 | 20 |
聚合过程说明:
- user_id=1001的两行数据被聚合为一行
- cost列使用SUM聚合:100 + 200 = 300
- visit_time列使用MAX聚合:max(10, 15) = 15
2.2.5 建表示例
CREATE TABLE IF NOT EXISTS test_db.ads_user_behavior_tmp
(`user_id` BIGINT NOT NULL COMMENT "用户ID",`date` DATE NOT NULL COMMENT "日期",`city` VARCHAR(20) COMMENT "城市",`cost` BIGINT SUM DEFAULT "0" COMMENT "消费金额",`visit_time` INT MAX DEFAULT "0" COMMENT "访问时长"
)
AGGREGATE KEY(`user_id`, `date`, `city`)
DISTRIBUTED BY HASH(`user_id`) BUCKETS 10
PROPERTIES ("replication_num" = "1"
);2.3 Unique Key Model(主键模型)
2.3.1 模型简介
Unique模型专门用于处理需要主键唯一性约束的场景。它保证对于相同的Key值,只保留最新写入的数据,自动实现数据去重和更新功能。
核心特征:
- 保证主键唯一性
- 自动保留最新数据
- 支持数据更新操作
- 本质是Aggregate模型的特例
2.3.2 实现方式
- Unique模型提供了两种实现方式,各有优劣:
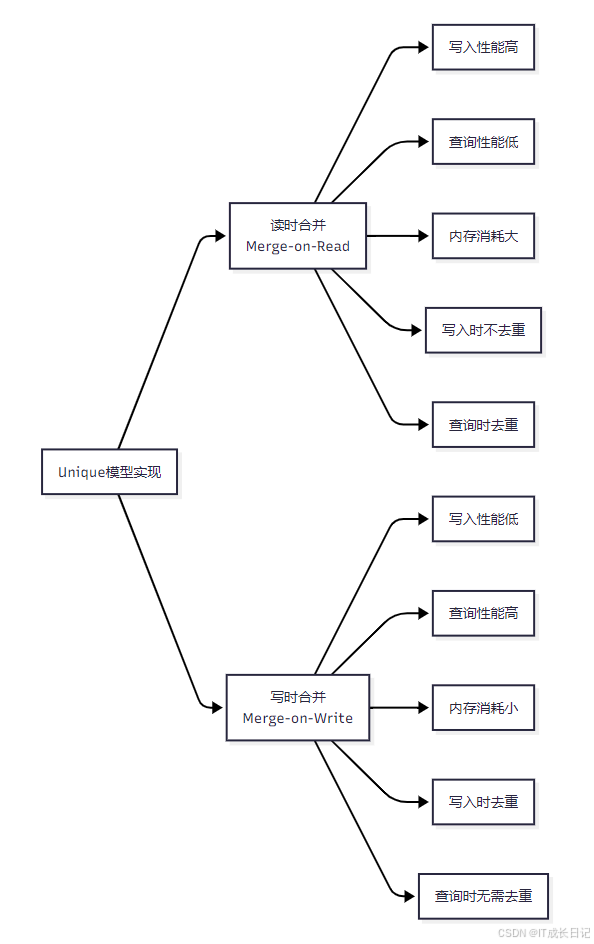
- 读时合并:写入时性能高,但查询时性能低,适合写入密集型场景
- 写时合并:写入时性能稍低,但查询时性能高,适合查询密集型场景
- 从Doris 2.1版本开始,写时合并成为默认实现方式
2.3.3 工作原理
- Unique模型的数据更新流程:
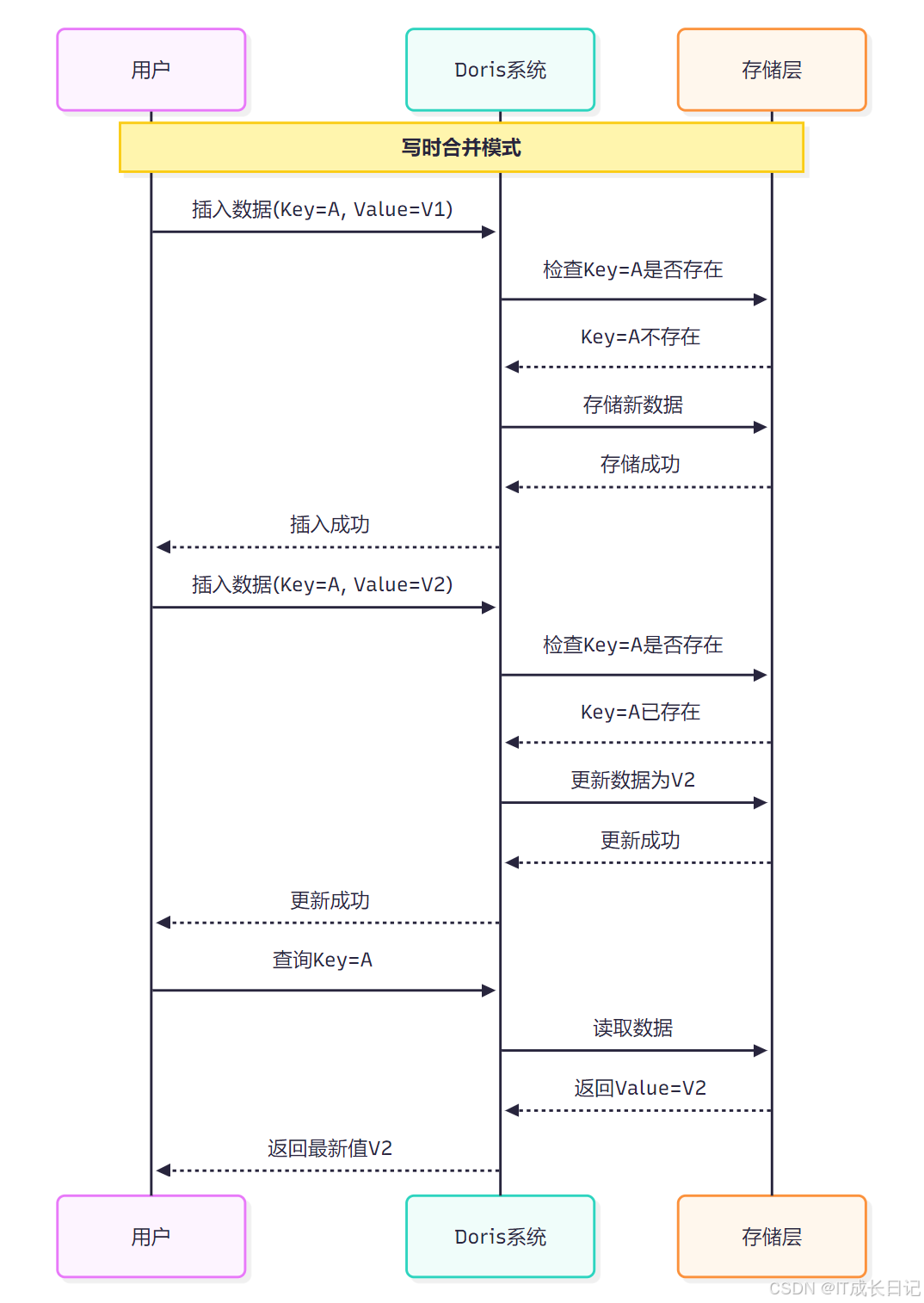
- 首次插入:当插入一个不存在的Key时,直接存储新数据
- 重复插入:当插入已存在的Key时,自动更新为最新值
- 数据查询:查询时直接返回该Key对应的最新值,无需额外处理
2.3.4 与Aggregate模型的关系
- Unique模型本质上是Aggregate模型的一种特例,所有非Key列都使用REPLACE聚合方式:
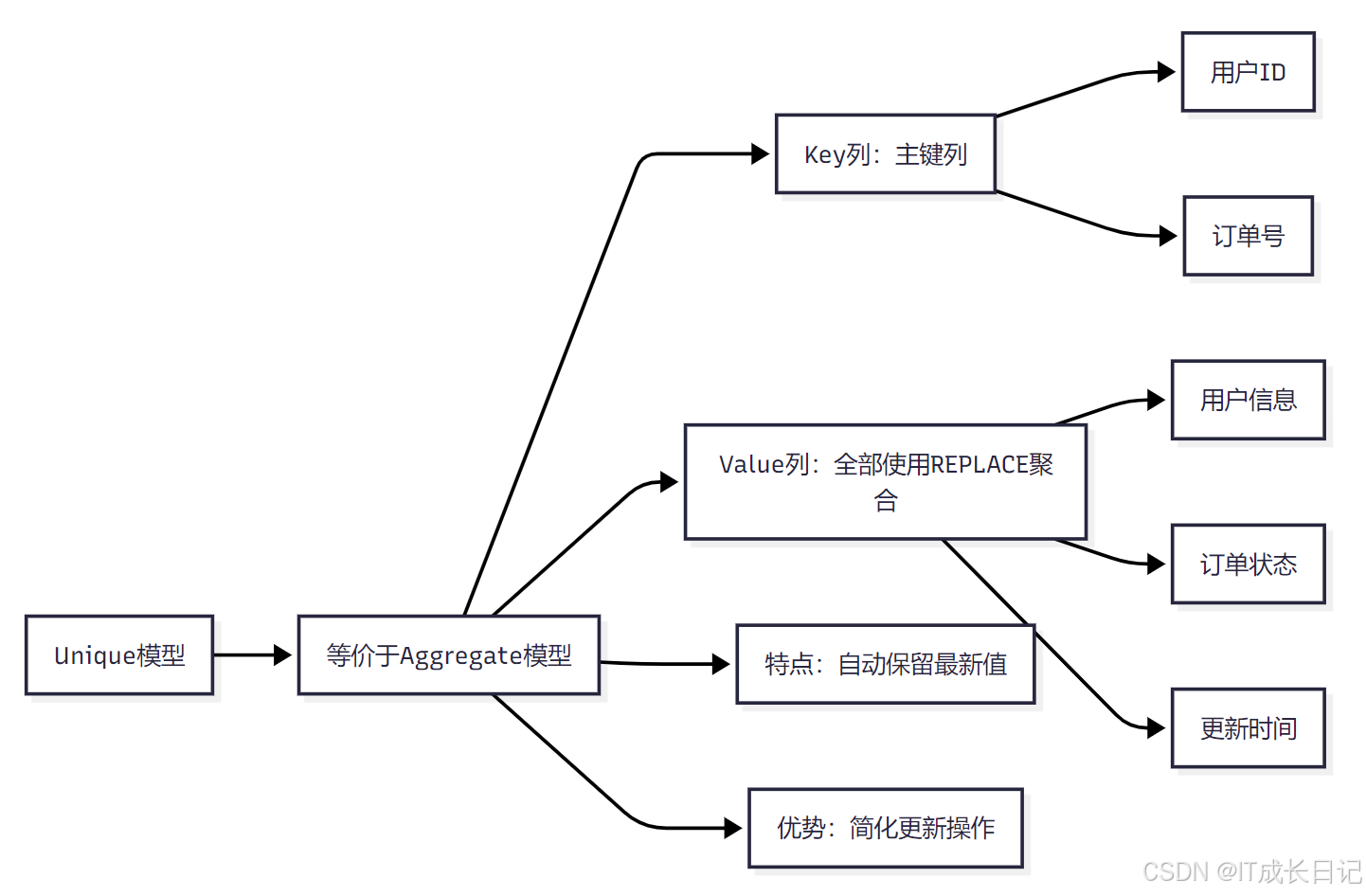
- Unique模型可以看作是所有Value列都使用REPLACE聚合的Aggregate模型
- 这种设计使得Unique模型能够自动保留最新值,简化数据更新操作
- 特别适合需要主键约束和数据更新的业务场景
2.3.5 建表示例
CREATE TABLE IF NOT EXISTS test_db.dwd_user_info_tmp
(`user_id` BIGINT NOT NULL COMMENT "用户ID",`username` VARCHAR(50) NOT NULL COMMENT "用户名",`city` VARCHAR(20) COMMENT "城市",`age` INT COMMENT "年龄",`register_time` DATETIME COMMENT "注册时间"
)
UNIQUE KEY(`user_id`, `username`)
DISTRIBUTED BY HASH(`user_id`) BUCKETS 10
PROPERTIES("replication_num"="1"
);3 数据模型对比与选择
3.1 三种模型能力对比
| 能力特性 | Duplicate模型 | Aggregate模型 | Unique模型 |
| 数据去重 | 不支持 | 按Key聚合 | 按Key唯一 |
| 明细查询 | 支持 | 不支持 | 支持 |
| 聚合查询 | 性能一般 | 性能优秀 | 性能一般 |
| 数据更新 | 不支持 | 不支持 | 支持 |
| count(*)性能 | 优秀 | 较差 | 较差 |
| 存储空间 | 较高 | 较低 | 中等 |
| 写入性能 | 优秀 | 良好 | 良好 |
| 查询灵活性 | 最高 | 受限 | 中等 |
3.2 数据模型选择决策流程
- 选择合适的数据模型是Doris应用成功的关键:
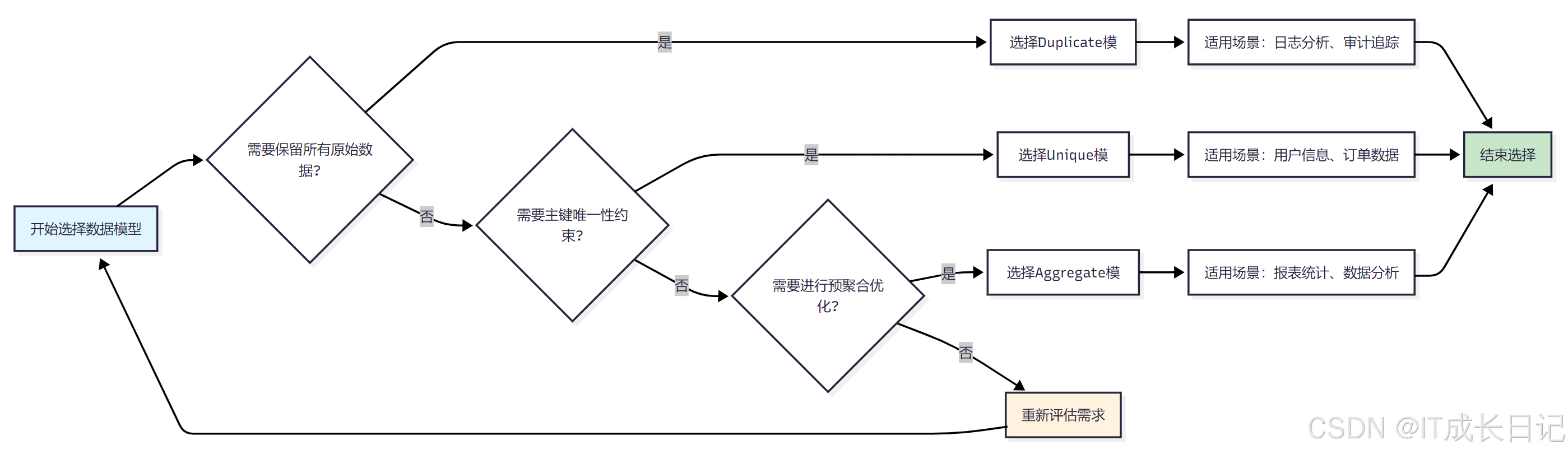
- 第一步:判断是否需要保留所有原始数据,如果是则选择Duplicate模型
- 第二步:如果不需要保留原始数据,判断是否需要主键唯一性约束,如果是则选择Unique模型
- 第三步:如果不需要主键约束,判断是否需要预聚合优化,如果是则选择Aggregate模型
- 循环评估:如果都不符合,需要重新评估业务需求
3.3 典型应用场景示例
3.3.1 电商系统数据建模
- 一个典型的电商系统通常需要处理多种类型的数据,不同类型的数据适合不同的数据模型:
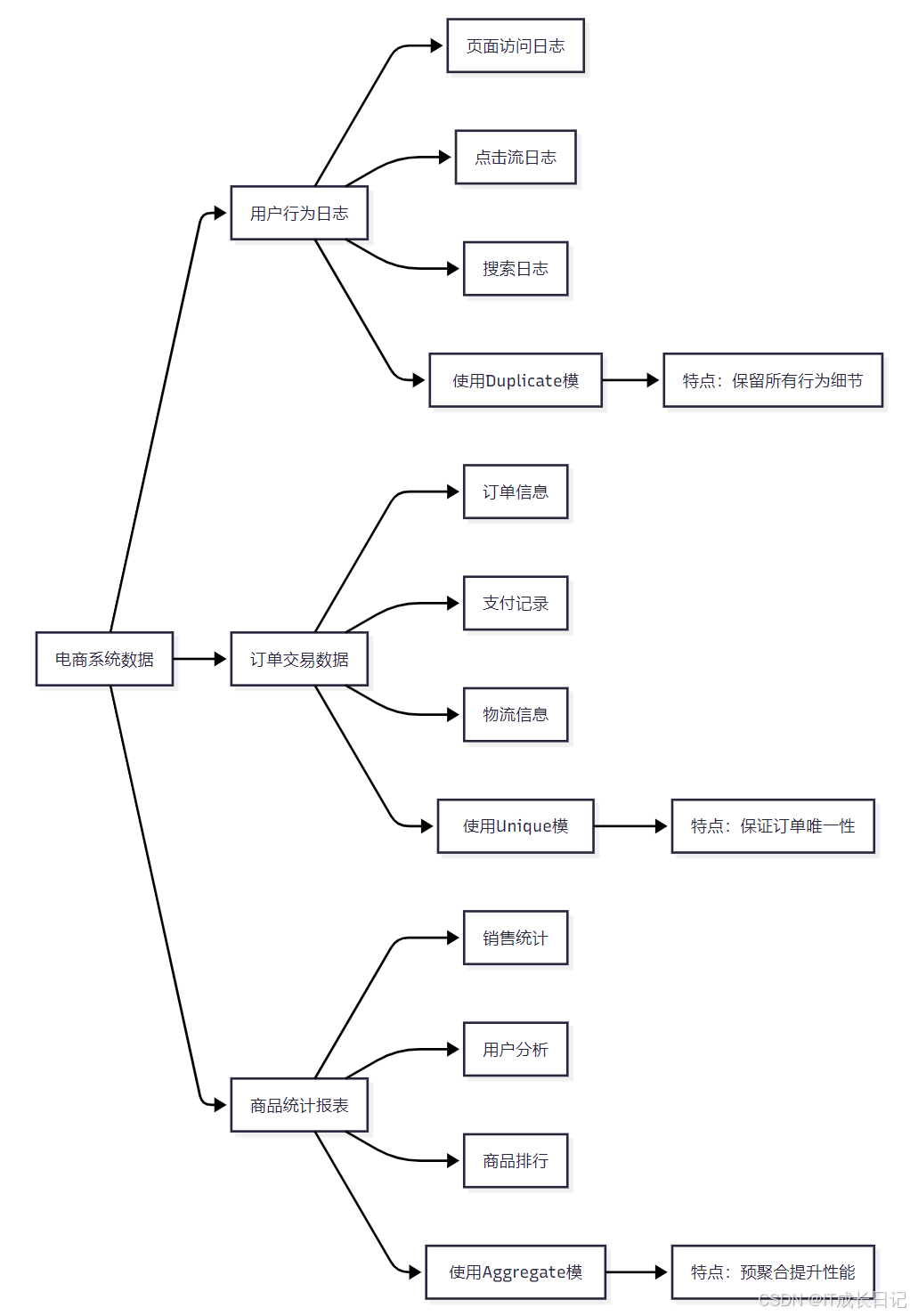
- 用户行为日志:使用Duplicate模型保留所有行为细节,用于用户行为分析
- 订单交易数据:使用Unique模型保证订单唯一性,支持订单状态更新
- 商品统计报表:使用Aggregate模型预聚合数据,提升报表查询性能
3.3.2 数据仓库分层建模
- 在数据仓库建设中,不同层次的数据适合使用不同的数据模型:
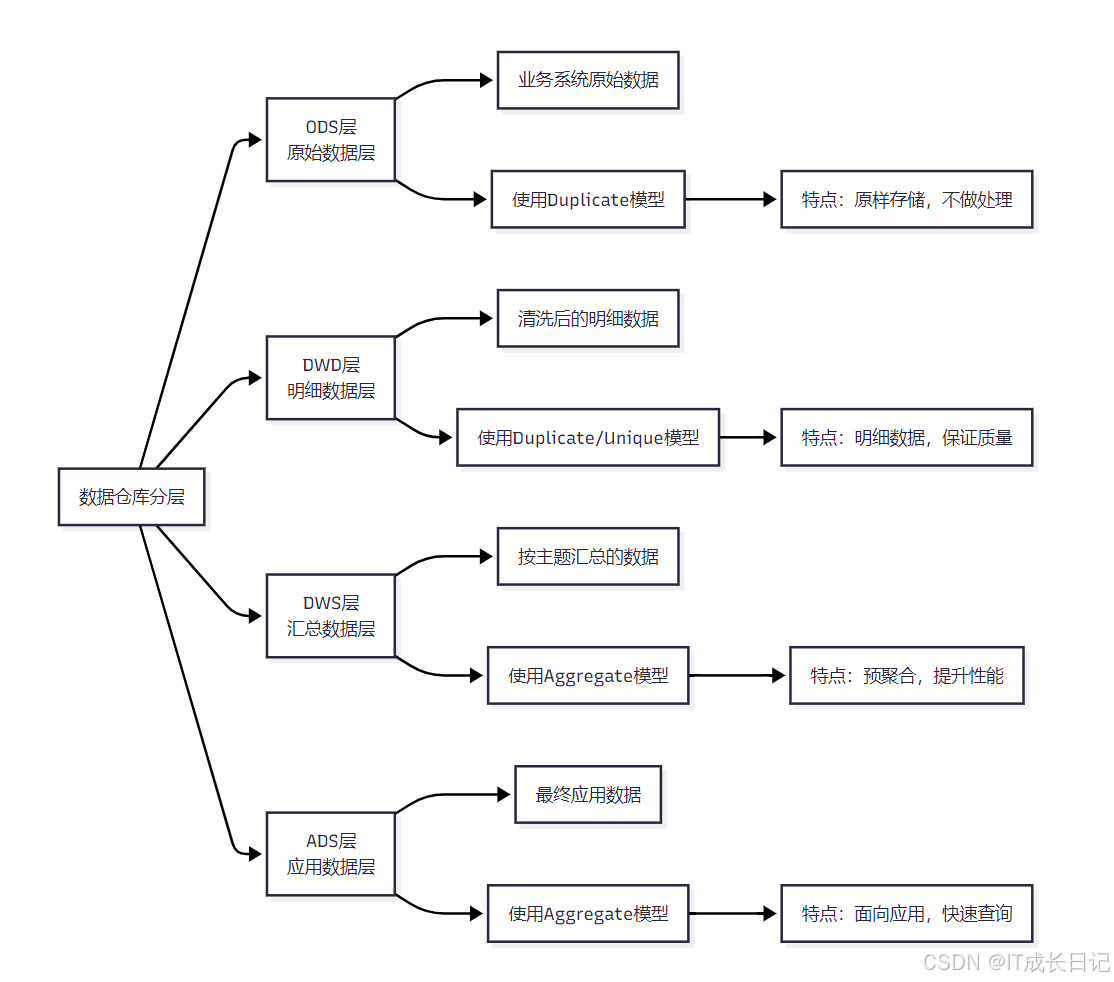
- ODS层:使用Duplicate模型原样存储业务系统数据
- DWD层:根据数据特点选择Duplicate或Unique模型,保证数据质量
- DWS层:使用Aggregate模型进行预聚合,提升查询性能
- ADS层:使用Aggregate模型提供面向应用的快速查询
4 数据模型内部机制
4.1 数据存储结构
- Doris采用列式存储,其数据存储结构对理解数据模型的工作原理很重要:
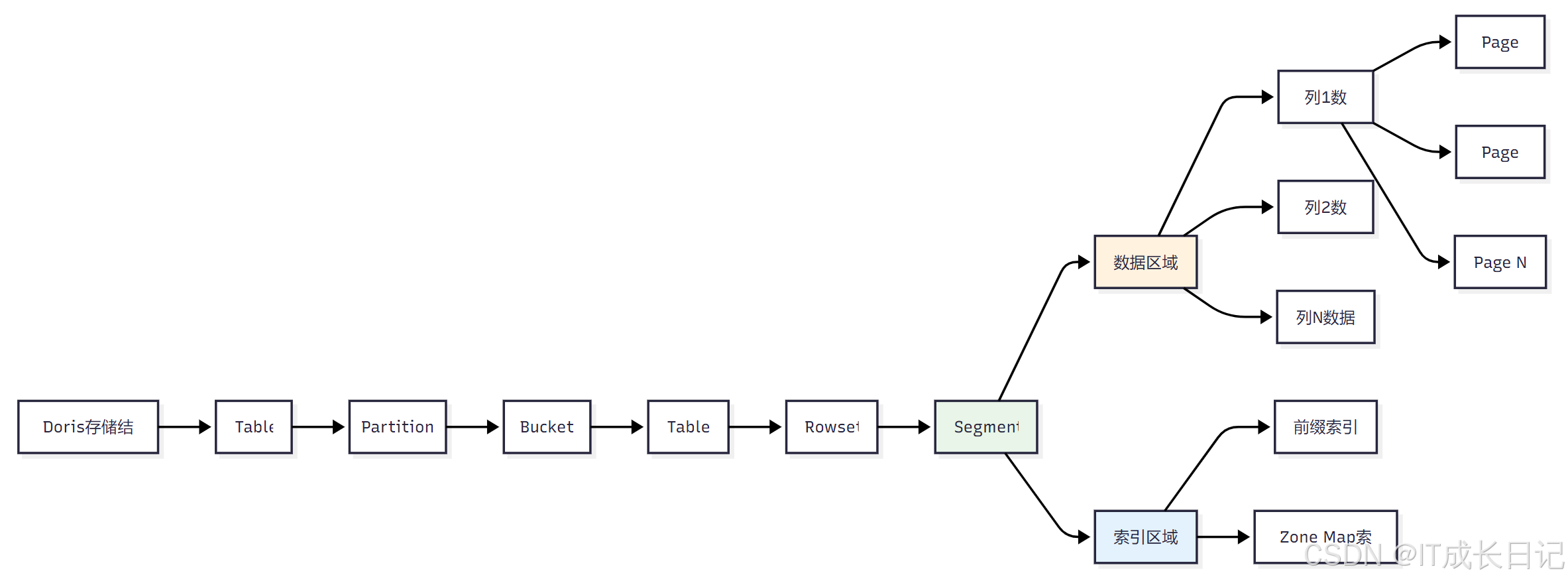
- Table到Tablet:逻辑表到物理存储单元的映射
- Rowset:一次导入的数据集合
- Segment:核心存储单元,包含数据和索引
- 数据区域:按列存储实际数据,分为多个Page
- 索引区域:包含前缀索引和Zone Map索引,加速查询
4.2 数据模型与存储的关系
- 不同的数据模型在存储层有不同的实现方式:
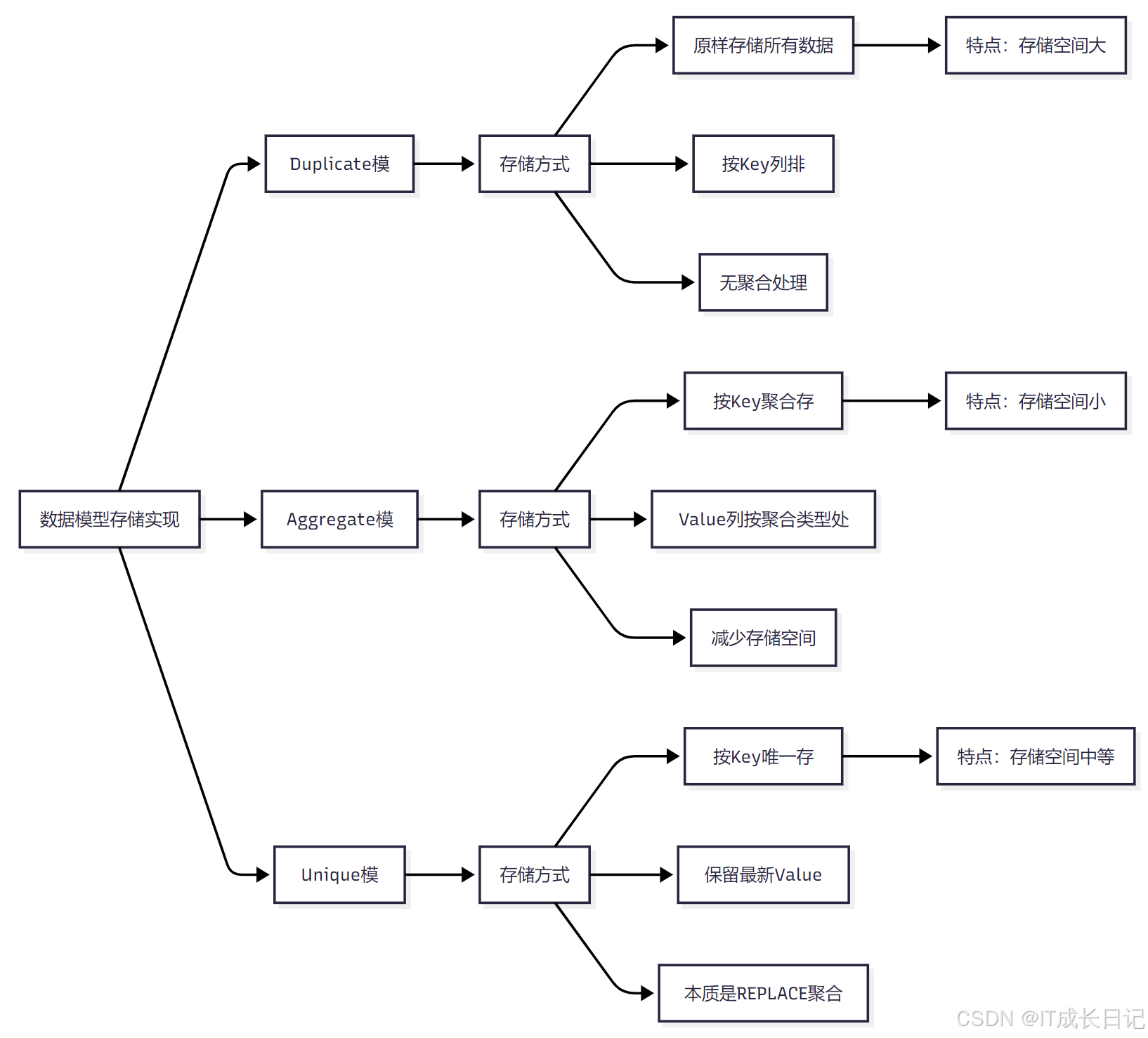
- Duplicate模型:原样存储所有数据,按Key列排序,不进行聚合处理
- Aggregate模型:按Key聚合存储,Value列按聚合类型处理,减少存储空间
- Unique模型:按Key唯一存储,保留最新Value值,本质是REPLACE聚合
4.3 ROLLUP与数据模型
- ROLLUP是Doris中的预聚合机制,与数据模型密切相关:
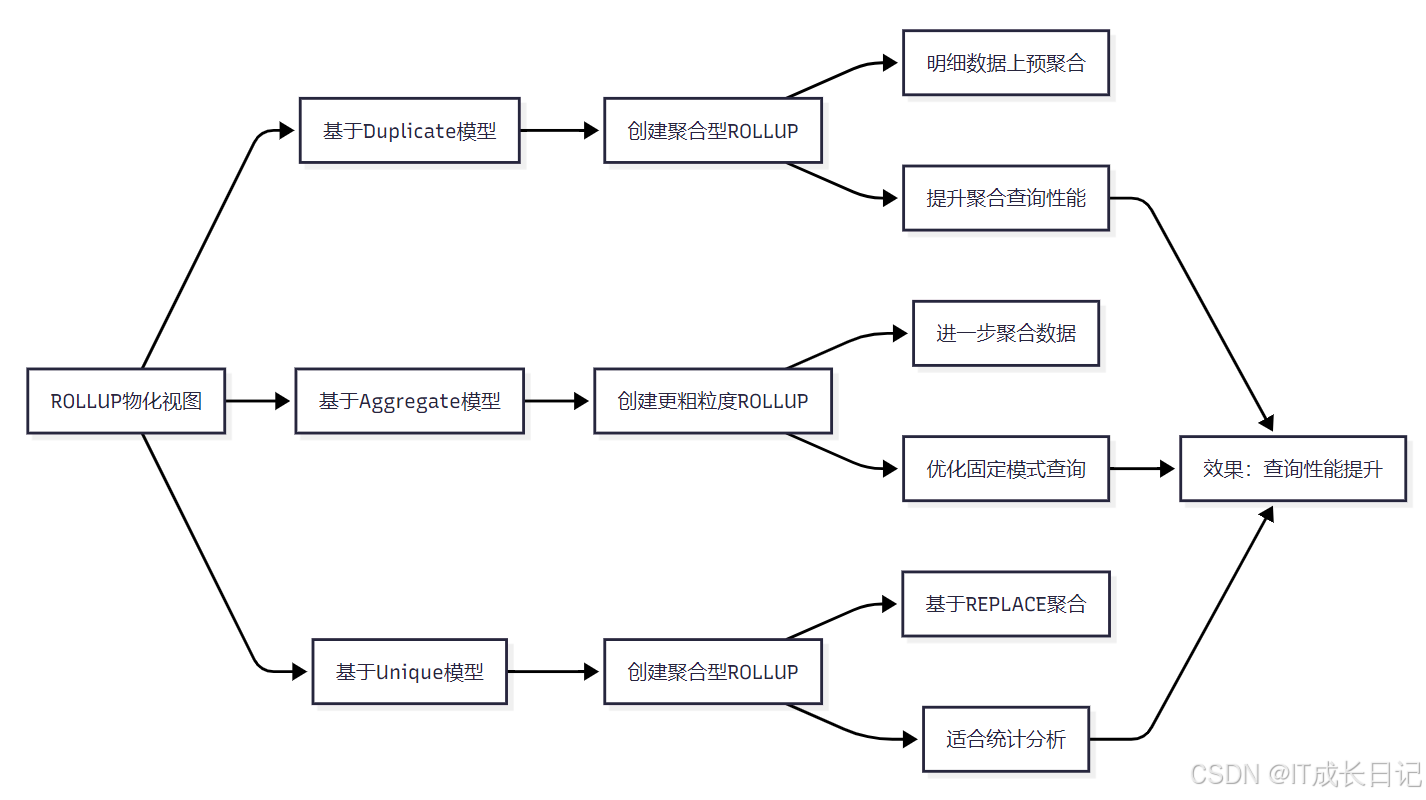
- 基于Duplicate模型:可以创建聚合型ROLLUP,在明细数据基础上进行预聚合
- 基于Aggregate模型:可以创建更粗粒度的ROLLUP,进一步优化查询性能
- 基于Unique模型:可以创建聚合型ROLLUP,基于REPLACE聚合进行统计分析
- 所有ROLLUP的共同目标是提升查询性能
5 实践建议与性能优化
5.1 数据模型选择实践建议
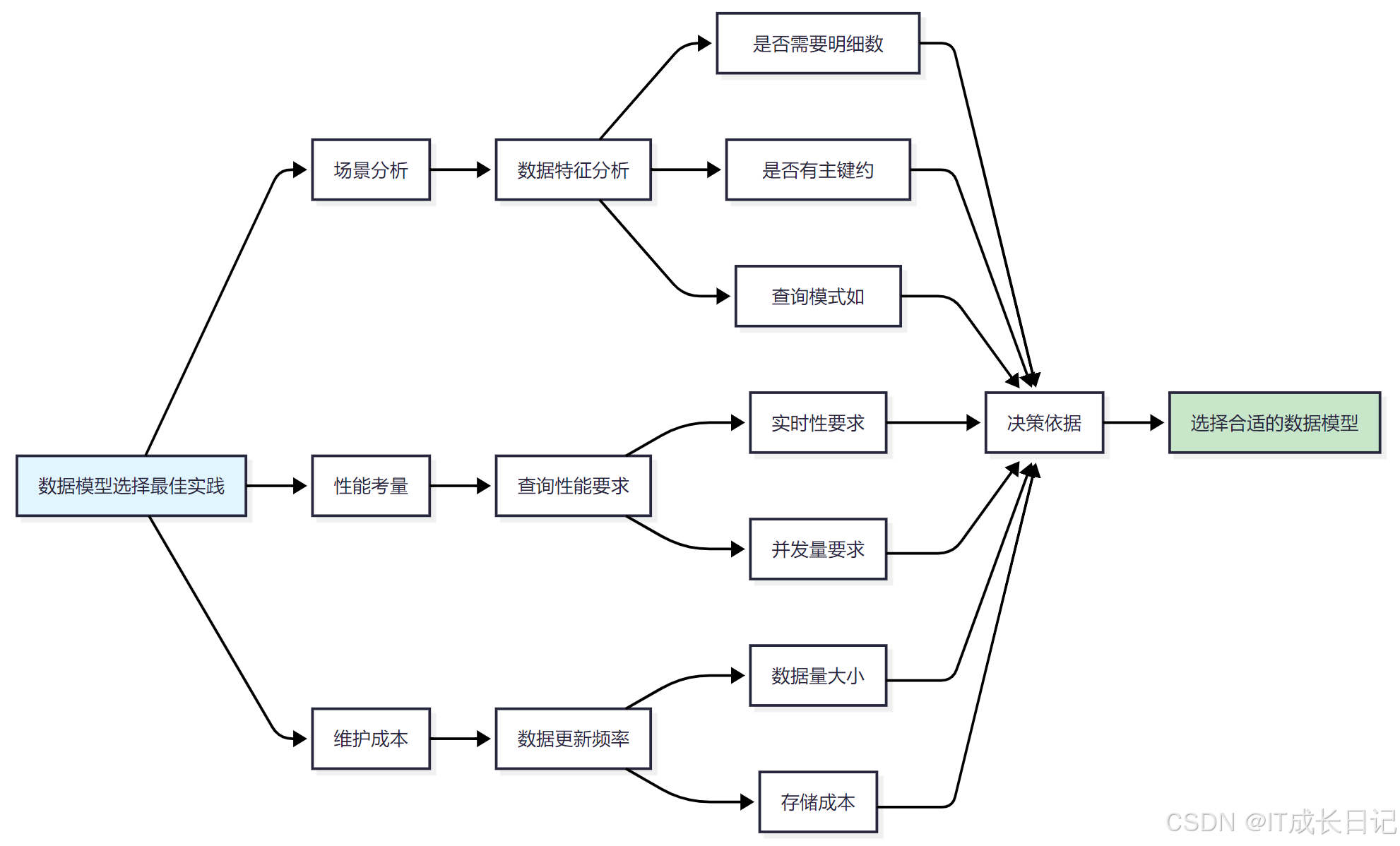
- 场景分析:分析数据特征,包括是否需要明细数据、是否有主键约束、查询模式等
- 性能考量:考虑查询性能要求,包括实时性、并发量等
- 维护成本:考虑数据更新频率、数据量大小、存储成本等
- 综合决策:基于以上因素选择最合适的数据模型
5.2 性能优化建议
5.2.1 Duplicate模型优化
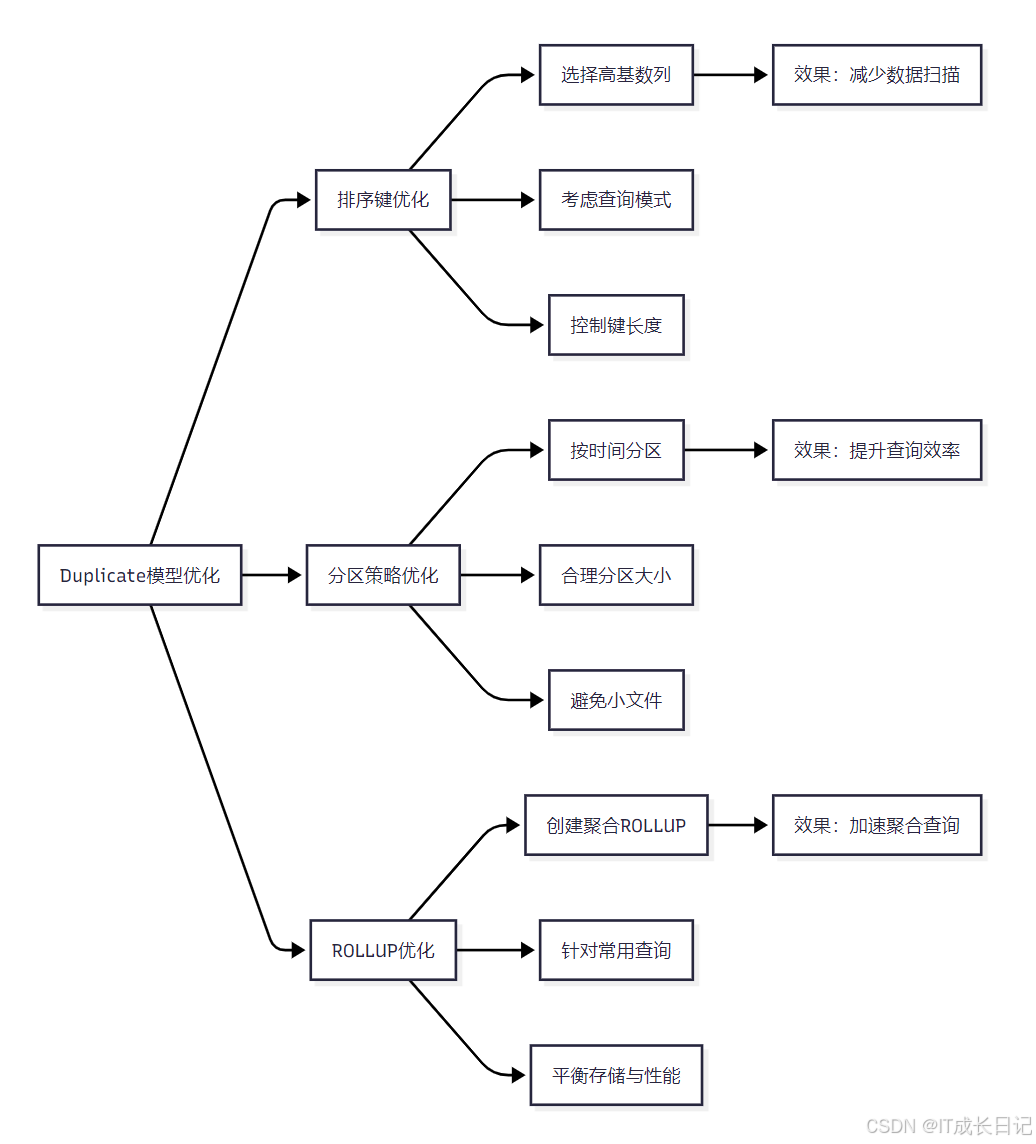
- 排序键优化:选择高基数列作为排序键前缀,考虑查询模式,控制排序键长度
- 分区策略优化:按时间分区,合理设置分区大小,避免产生过多小文件
- ROLLUP优化:针对常用查询创建聚合ROLLUP,平衡存储空间与查询性能
5.2.2 Aggregate模型优化
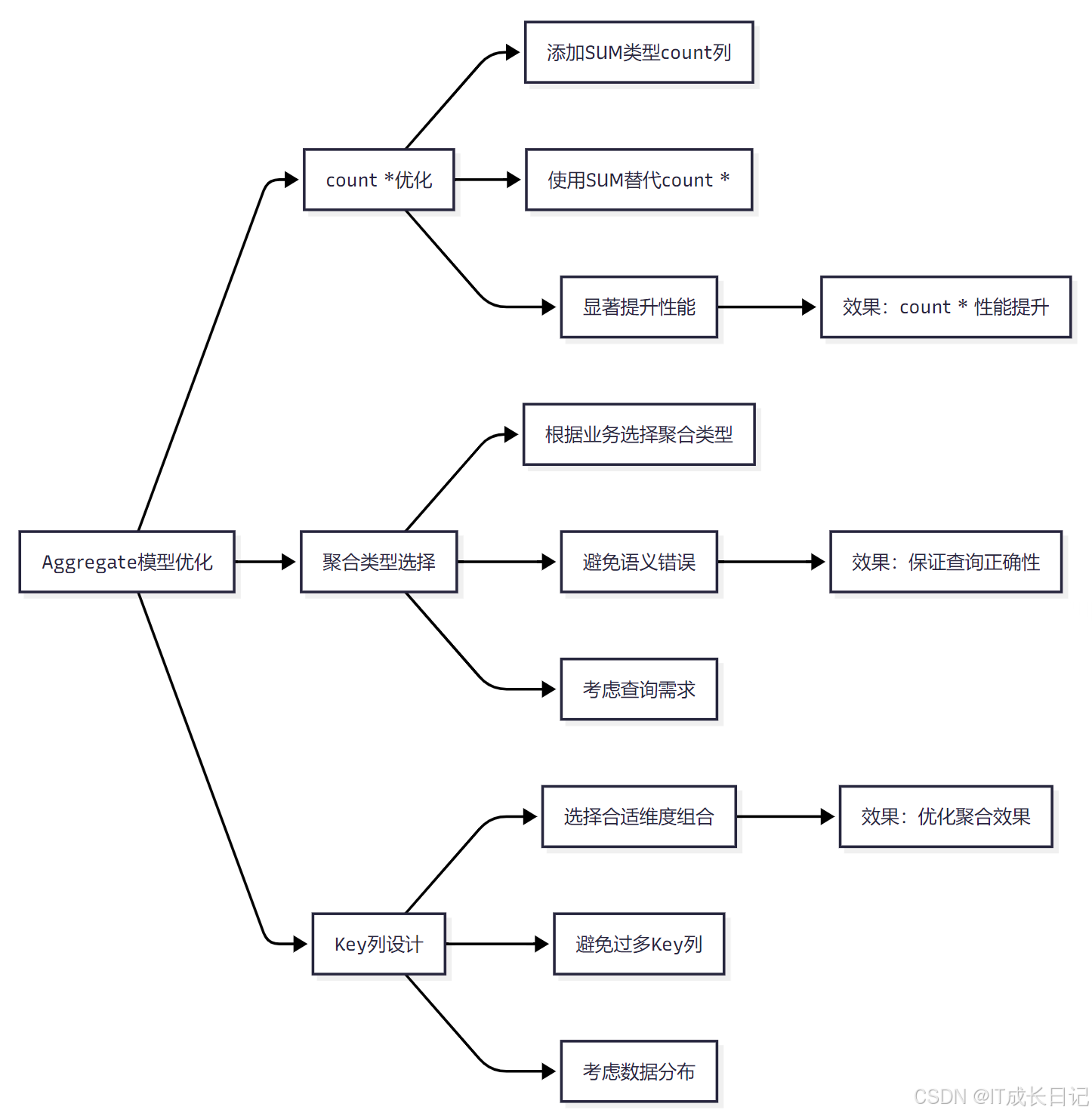
- count(*)优化:添加SUM类型的count列,使用SUM(count)替代count(*),显著提升性能
- 聚合类型选择:根据业务需求选择合适的聚合类型,避免语义错误,考虑查询需求
- Key列设计:选择合适的维度组合作为Key列,避免过多Key列,考虑数据分布情况
5.2.3 Unique模型优化
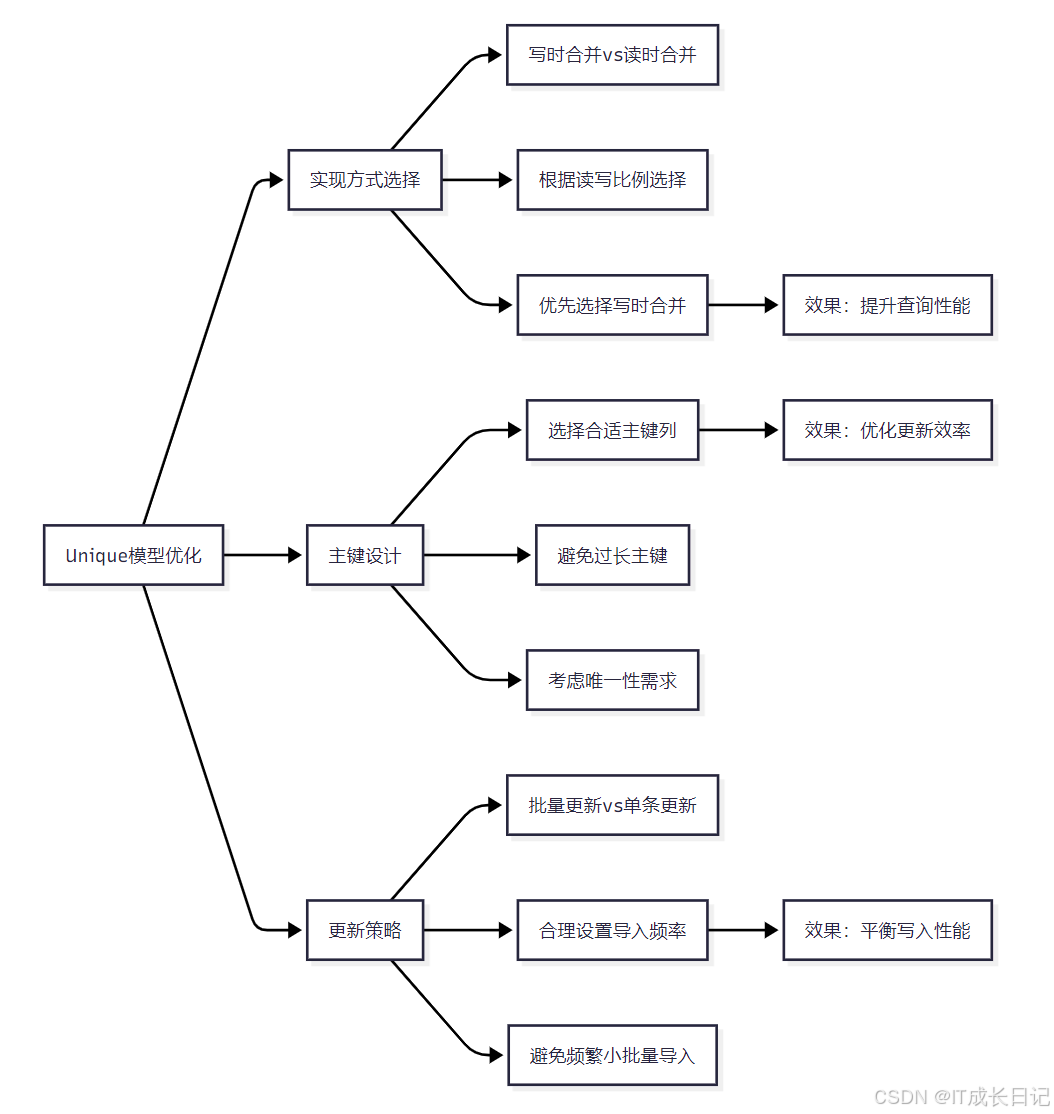
- 实现方式选择:根据读写比例选择写时合并或读时合并,优先选择写时合并
- 主键设计:选择合适的主键列,避免过长的主键,考虑唯一性需求
- 更新策略:优先使用批量更新,合理设置导入频率,避免频繁小批量导入
6 总结