昇腾算力加持,深度思考模型Colossal-R1上线魔乐社区
潞晨团队正式开源了Colossal-R1-7B与Colossal-R1-14B——两款在昇腾上,使用潞晨自研的分布式强化学习框架Colossal-RL,完成强化微调全流程的深度思考模型,现已上线魔乐社区,面向开发者与研究者免费开放。
🔗开源地址
https://modelers.cn/models/HPC_AI_TECH/Colossal-R1-7B
https://modelers.cn/models/HPC_AI_TECH/Colossal-R1-14B
01
模型介绍
Colossal-R1-7B与Colossal-R1-14B均基于DeepSeek-R1-Distill-Qwen系列模型进行微调,训练过程中潞晨团队全面采用自研的Colossal-RL分布式强化学习框架,并率先支持GRPO、DAPO等前沿算法。在数据方面,团队开发人员从 big_math、orz_math、Skywork、DAPO等开源资源中严格筛选,最终精选约12,000条高质量 prompt,确保了数据的难度与多样性。整个训练流程完全在昇腾算力上完成,并通过双重对齐方式保证了与NV版本的一致性,充分验证了国产芯片在深度思考模型训练中的强大潜力。
02
技术亮点
全流程国产芯片适配
从推理框架、强化学习(RL)到最终模型落地,整个训练流程完全基于昇腾算力实现。这标志着深度思考类大模型在国产芯片生态中实现了完整复现与优化。
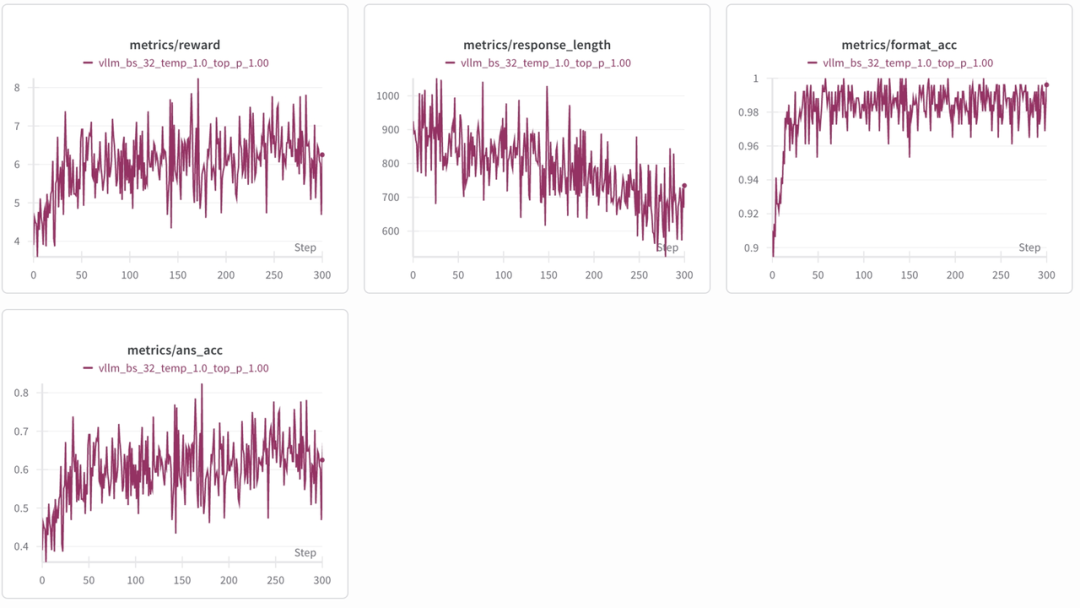
昇腾A2训练表现图
RL as a Pipeline:更高效的强化学习范式
在Colossal-RL框架中,潞晨团队引入了训推分离的流水线式设计(RL as a Pipeline)。这一范式让训练在第一个mini-batch就绪的瞬间即可启动,而无需等待完整的batch,从而显著加快迭代效率。同时,采用了异步one-step behind策略,使训练与推理在时间上实现最大程度的交叠(overlap),有效减少了算力空转,大幅提升整体吞吐率。
这种流水线模式不仅解决了“推理速度慢、训练等待久”的瓶颈,还能够根据推理与训练的耗时灵活调整资源分配,实现更加均衡的算力利用。在实际运行中,RL as a Pipeline带来的效率提升让模型能够以更快的速度收敛,并在相同算力条件下释放更强的性能潜力,为大模型的深度思考与复杂推理任务提供了坚实的技术保障。
模型表现显著提升
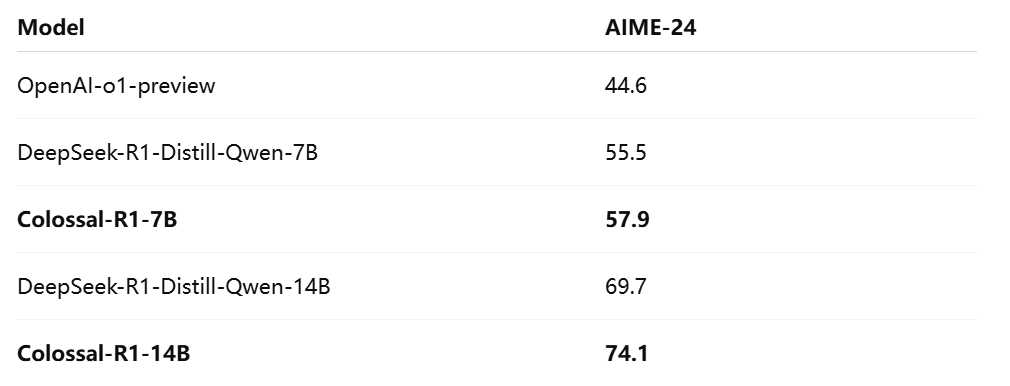
在AIME-24与Math-500数据集上的评测中,Colossal-R1-7B与Colossal-R1-14B的表现均已超越OpenAI-o1-preview,展现出强大的数学与逻辑推理能力。同时,在Alignment阶段,模型的reward指标实现了快速而稳定的收敛,进一步验证了训练体系的可靠性与高效性。这些成果不仅证明了Colossal-R1的领先性能,也让我们对其在未来更多数学推理与复杂逻辑任务中的应用充满信心。
03
开源与致谢
在模型开发过程中,潞晨团队也得到昇腾计算产品线的支持,汲取了Fuyao-ray、vLLM-Ascend、MindSpeed团队的开源贡献与建议。正是这些力量共同推动了Colossal-R1的诞生。目前,Colossal-R1-7B与Colossal-R1-14B已上传至魔乐社区,并附带详细的微调方案和技术说明,供社区开发者复现、研究与应用。
欢迎大家访问魔乐社区,下载体验Colossal-R1!我们期待与更多开发者一同探索深度思考模型在国产算力生态中的无限可能。