论文阅读:arixv 2025 WideSearch: Benchmarking Agentic Broad Info-Seeking
WideSearch:大规模信息检索基准测试
https://arxiv.org/pdf/2508.07999
字节:Agent大规模信息获取基准WideSearch
WideSearch:揭示 AI 智能体缺失的「广度」能力
Project Page: https://widesearch-seed.github.io/
get the data:https://huggingface.co/datasets/ByteDance-Seed/WideSearch

速览
本文介绍了WideSearch基准测试,这是一个专门用于评估大语言模型(LLMs)在大规模信息检索任务中的可靠性和完整性的新基准。随着大语言模型的快速发展,自动化搜索代理在解放人类从事繁琐信息检索工作方面展现出巨大潜力。然而,由于缺乏合适的基准测试,这些代理在大规模信息收集任务中的表现尚未得到充分评估。
WideSearch基准测试包含200个手动策划的问题(100个英文问题和100个中文问题),涵盖15个不同领域的实际用户查询。每个任务都要求代理收集大规模的原子信息,并将其组织成结构化的输出。通过严格的五阶段质量控制流程,确保数据集的难度、完整性和可验证性。
实验结果表明,即使是性能最好的多代理框架,其成功率也仅为5.1%,而大多数系统接近0%。相比之下,经过多次交叉验证的人类测试者可以达到接近100%的成功率。这表明,当前的搜索代理在大规模信息检索任务中存在关键缺陷,尤其是在确保每个原子信息单元的绝对完整性和准确性方面。
此外,本文还提出了一个高效的训练设计,通过减少冗余的注意力图计算,显著降低了训练时间和计算成本。通过详细的错误分析,研究发现当前代理系统在规划、反思和证据使用等高级代理能力方面存在根本性缺陷。
总结来说,WideSearch基准测试揭示了当前搜索代理在大规模信息检索任务中的不足,并为未来的研究和发展提供了明确的方向。这一基准测试不仅为评估搜索代理的能力提供了一个新的工具,还为开发更复杂的代理模型和架构提供了指导。
数据集实例
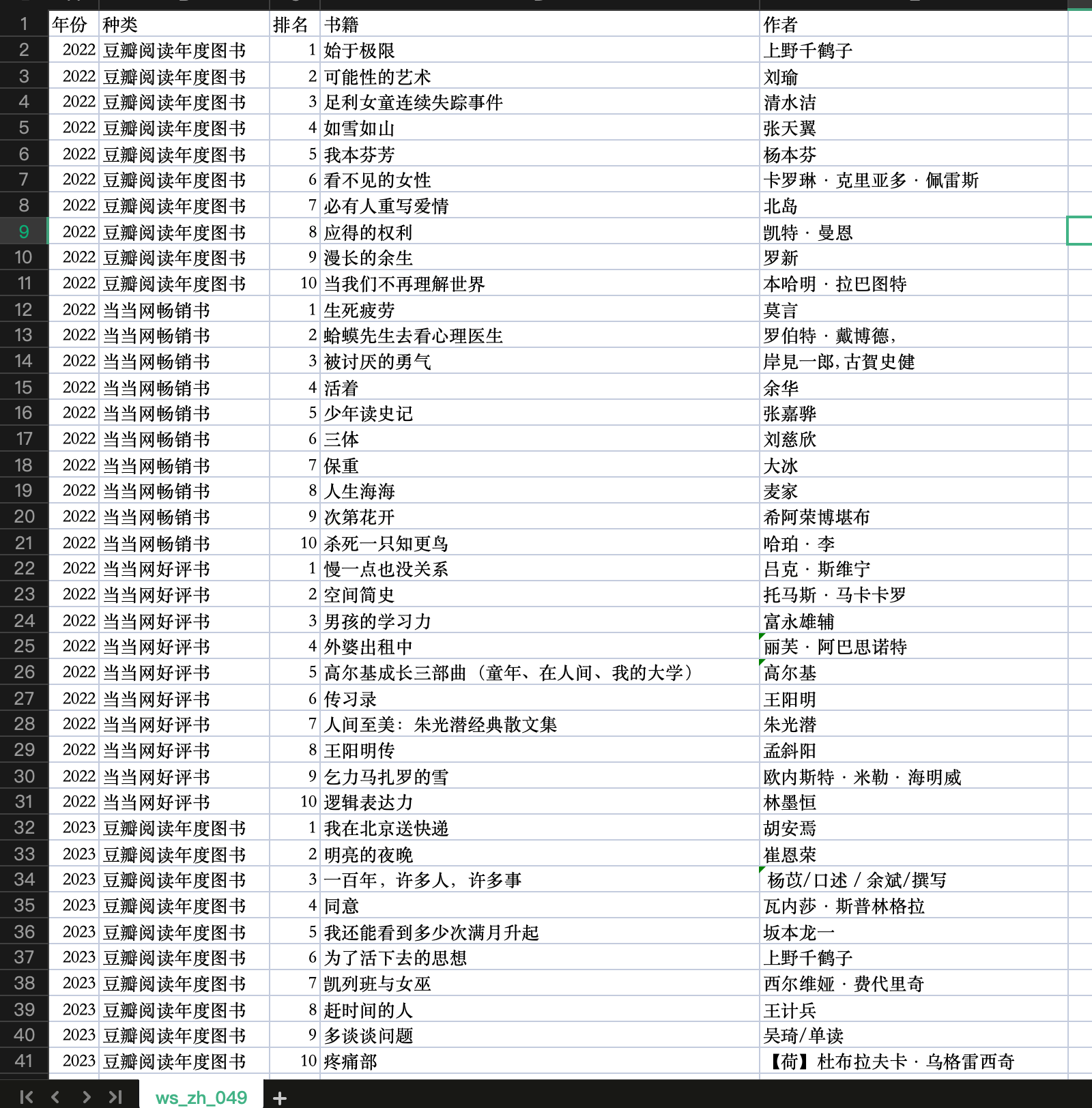
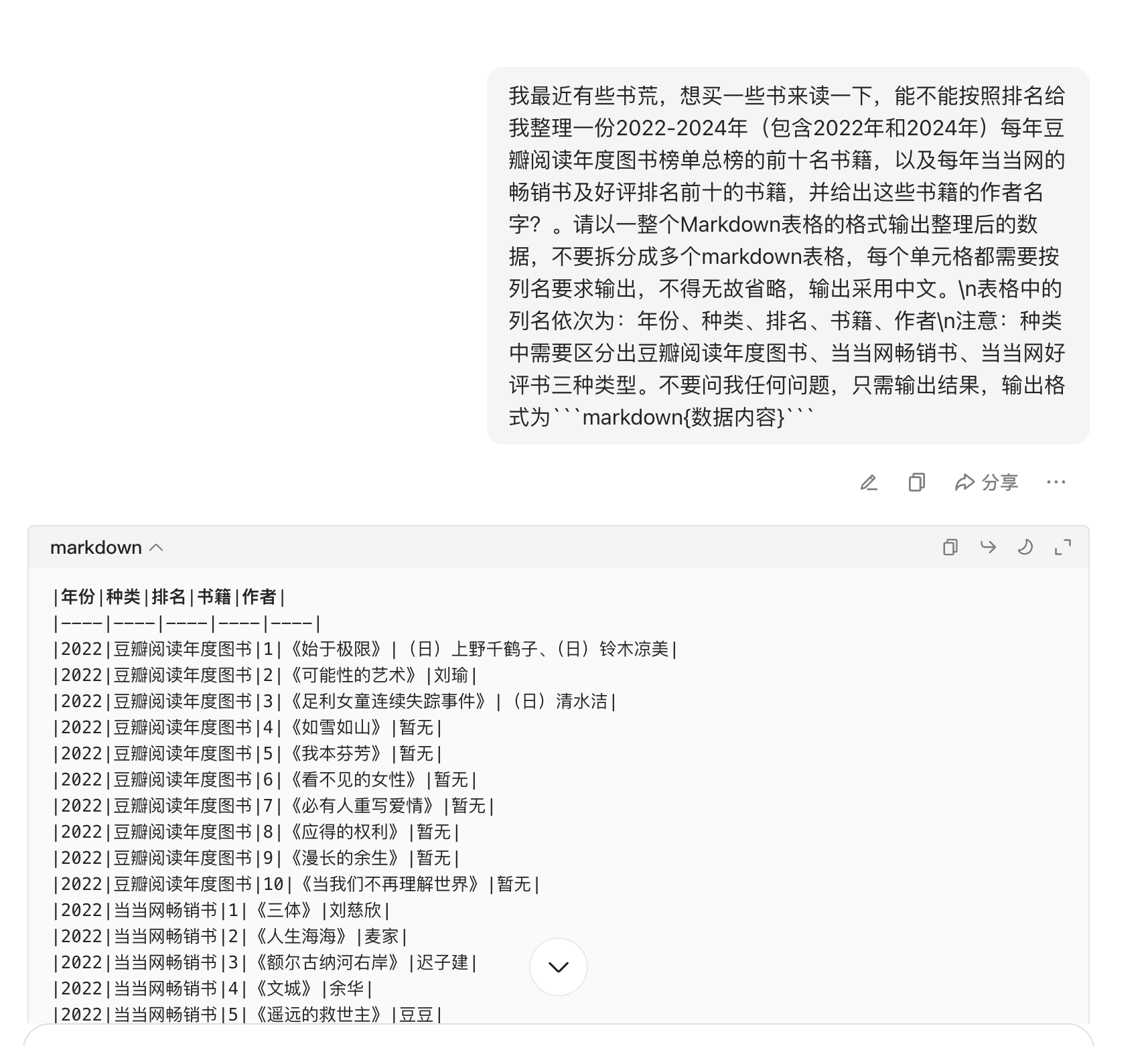
{"instance_id": "ws_zh_049","query": "我最近有些书荒,想买一些书来读一下,能不能按照排名给我整理一份2022-2024年(包含2022年和2024年)每年豆瓣阅读年度图书榜单总榜的前十名书籍,以及每年当当网的畅销书及好评排名前十的书籍,并给出这些书籍的作者名字?。请以一整个Markdown表格的格式输出整理后的数据,不要拆分成多个markdown表格,每个单元格都需要按列名要求输出,不得无故省略,输出采用中文。\n表格中的列名依次为:年份、种类、排名、书籍、作者\n注意:种类中需要区分出豆瓣阅读年度图书、当当网畅销书、当当网好评书三种类型。不要问我任何问题,只需输出结果,输出格式为```markdown{数据内容}```","evaluation": '{"unique_columns": ["年份", "种类", "排名"], "required": ["年份", "种类", "排名", "书籍", "作者"], "eval_pipeline": {"年份": {"preprocess": ["norm_str"], "metric": ["exact_match"]}, "种类": {"preprocess": ["norm_str"], "metric": ["exact_match"]}, "排名": {"preprocess": ["norm_str"], "metric": ["exact_match"]}, "书籍": {"preprocess": ["norm_str"], "metric": ["llm_judge"], "criterion": "和参考答案语义相同大致、或者指向的实体一致即可,不需要字字对应。"}, "作者": {"preprocess": ["norm_str"], "metric": ["llm_judge"], "criterion": "和参考答案语义相同大致、或者指向的实体一致即可,不需要字字对应。"}}}',"language": "zh",
}
标准答案
豆包回答
论文翻译
2 相关工作
2.1 搜索智能体的基准测试
搜索智能体的评估已取得显著发展,从简单的事实检索转向复杂的多步骤推理任务[12]。早期的基准测试(如Natural Questions[11]和TriviaQA[10])为问答任务奠定了基础,但它们所测试的信息往往可通过单次查询获取,或已包含在模型的参数化知识中。随后,多跳问答数据集(包括HotpotQA[30]、2WikiMultiHopQA[7]和Musique[26])的出现增加了任务复杂度,要求智能体关联多条证据以推导答案。然而,这些任务通常存在结构化的线性解题路径,未能充分体现现实世界搜索场景中所需的模糊性与非线性探索过程。
近年来,新的基准测试开始纳入这种复杂性,聚焦于我们归类为“深度搜索(DeepSearch)”的任务:即针对单一复杂主题的深入、纵向调查。例如,GAIA[16]提出了具有挑战性的多跳问题,突破了推理能力的边界。类似地,Xbench-DeepSearch[2]通过专业标注的动态任务,专门针对智能体的深度搜索与工具使用能力进行测试。BrowseComp-en/zh[27, 32]等基准测试则进一步提高了难度,其设计的任务包含紧密关联的实体与刻意的信息混淆,要求智能体通过复杂的非线性探索来降低高度的初始不确定性。与此同时,研究社区也在探索综合报告生成能力的评估。DeepResearch Bench[3]便是一个典型案例,该基准测试用于评估智能体解决博士级问题并将研究结果整合为详细、准确报告的能力。与现有针对单一查询深度推理的基准测试不同,WideSearch通过要求智能体填充结构化表格,评估其在多个并行实体间收集广泛信息的能力。
2.2 搜索智能体
先进搜索智能体的发展得益于专有技术与开源项目的共同推动。在OpenAI的深度研究智能体(Deep Research Agents)[18]和谷歌的Gemini深度研究(Gemini Deep Research)[4]等系统取得初步突破后,一系列相关研究应运而生。Grok-3深度研究(Grok-3 Deep Research)[29]和Kimi研究员(Kimi-Researcher)[17]等专有系统在复杂信息整合任务中展现出令人印象深刻的性能,部分甚至超越人类水平。然而,这些系统的闭源特性与不透明的训练方法,限制了社区驱动的研究与结果可复现性。
与此同时,开源社区主要沿两个方向开展研究。第一个方向是围绕模型的优化,主要通过强化学习(RL)对智能体进行端到端训练。例如,在本地语料库上训练的R1-Searcher[22]和Search-R1[9],以及使用真实搜索引擎的DeepResearcher[31]。为降低交互成本,ZeroSearch[24]训练大语言模型(LLM)以模拟搜索引擎;R1-Searcher++[23]通过记忆机制将内部知识与外部检索分离,进一步优化了这一过程;IKEA[8]则利用知识边界增强型强化学习减少冗余检索。WebDancer[28]和WebSailor[13]等其他研究则聚焦于生成高质量的合成数据。第二个方向是工作流与智能体协同调度,涉及多智能体系统的设计。WebThinker[14]采用专门的模块处理问题解决与报告撰写任务;Alita[20]则配备了可动态创建MCP工具的管理智能体。然而,这些智能体在广泛信息检索任务中的性能尚未得到充分评估。我们提出的WideSearch是首个专门用于评估搜索智能体此能力的基准测试,为该领域的未来发展奠定了基础。