多智能体框架(下)
多智能体,MAS测评榜单:GAIA。
上篇参考Multi-Agent多智能体系统。
JoyAgent
JoyAgent-JDGenie,京东开源(5.3k Star,866 Fork),基于Java语言,首个高完成度轻量化通用多智能体产品,作为完整的端到端智能体系统,无需二次开发即可直接使用,支持多种任务处理,如生成报告、分析数据等。具备多智能体设计模式、跨任务记忆和工具进化机制等创新技术。
原理
- 多智能体设计模式:支持多层级的规划和思考。层级包括work和task。能够更好地应对复杂多变的任务场景,提升系统的灵活性和适应性。
- 跨任务记忆:能够记住之前处理过的相似任务的信息和经验,在处理新的相似任务时更加高效和准确。这一机制显著提高了系统的任务处理效率,减少重复工作。
- 工具进化机制:基于已有工具迭代生成新工具,自动拆解已有工具为原子工具,并结合LLM自动组合成新工具。减少工具错误生成,提高开发效率。
- 高并发DAG执行引擎:系统支持高并发的有向无环图(DAG)执行引擎,优化任务调度和资源分配,确保系统在高负载下仍能高效运行。
- 上下文管理:管理多个智能体之间的上下文信息,确保智能体之间的协同工作流畅高效。
- 全链路流式输出:系统支持全链路的流式输出,确保任务处理过程中的实时反馈和动态调整。
功能
- 开箱即用的任务处理:能够直接处理用户输入的复杂任务,如生成报告、分析数据等,无需二次开发。用户只需输入任务描述,系统即可自动完成任务处理并输出结果。
- 通用性强的框架设计:该系统支持用挂载子智能体或工具快速扩展功能,适应不同应用场景。开发者可以根据需求灵活添加或替换子智能体和工具,满足多样化的业务需求。
- 多智能体协同工作:多个子智能体协同完成复杂任务,提升效率。
- 多文件交付样式:支持网页版、PPT、Markdown等多种文件交付格式。用户可根据自己的使用习惯选择合适的输出格式。
- 工具进化机制:基于已有工具迭代生成新工具,自动拆解和重组原子工具,减少错误工具生成,提高开发效率。
- 跨任务记忆:记住相似任务信息,在处理新任务时更加高效准确。
安装
git clone https://github.com/jd-opensource/joyagent-jdgenie.git
docker build -t genie:latest .
docker run -d -p 3000:3000 -p 8080:8080 -p 1601:1601 -e OPENAI_BASE_URL="" -e OPENAI_API_KEY="" --name genie-app genie:latest
# 方法2
pip install uv
cd genie-tool
uv sync
source .venv/bin/activate
sh check_dep_port.sh
sh Genie_start.sh
二次开发
- 添加自定义工具:
- 在
genie-backend/src/main/resources/application.yml中添加MCP服务地址; - 实现
BaseTool接口,声明工具的名称、描述、参数和调用方法; - 在
com.jd.genie.controller.GenieController#buildToolCollection中添加自定义工具。
- 在
- 添加自定义子智能体:
- 实现
BaseTool接口,声明子智能体的名称、描述、参数和调用方法; - 在
com.jd.genie.controller.GenieController#buildToolCollection中添加自定义子智能体。
- 实现
对比LangGraph
| 维度 | JoyAgent-JDGenie | LangGraph |
|---|---|---|
| 一句话定位 | 端到端、产品级的多智能体应用,前后端都有,开箱即用 | 面向开发者的多智能体框架/库,自由构建认知架构 |
| 技术栈 | Java+Spring Boot+Python工具引擎 | Python,异步优先 |
| 核心架构 | 内置计划-执行(Plan-Executor)等多种模式,先规划再执行 | 基于有向图状态机,编排每个节点的动作和流程 |
| 开发体验 | 上手快,对Java工程师极度友好,深度定制需要跨语言 | 极其灵活,需要懂状态机和异步编程,对新手有门槛 |
| 调试工具 | 自带WebUI,交互直观。调试主要靠日志 | 可集成LangSmith,每一步思考路径都可视化,调试神器 |
| 部署运维 | 主打本地化、私有化部署,数据不出内网,满足大企业安全合规要求 | 部警方式灵活,可用LangServe打包成API,或用官方平台托管 |
| 生态社区 | 京东开源,国内社区关注度高,生态相对封闭,刚起步 | 背靠LangChain庞大社区,工具,教程,插件多到用不完,生态成熟 |
调度模型
JoyAgent:内置两种经典模式
- ReAct:不断进行
感知-思考-行动的循环,会自己决定是调用工具查资料,还是直接给出答案,直到任务完成。灵活,适合开放式的探索任务。 - Plan-Executor:引入规划Agent负责全局规划,把一个复杂任务拆解成一个个小任务,再把这些小任务分发给不同的执行Agent去完成。分工清晰,能确保复杂任务有条不紊地进行。
LangGraph:不预设模式,核心是状态机/有向图,支持自定义Agent的决策流程。每一个操作都是图上的节点,而流程方向就是边。支持组装为各种模式:
- ReAct:工具选择Router+自循环;
- Plan-Executor:可设计一个嵌套子图的结构。如让两个Agent节点来回传递消息,模拟对话或辩论。
小结:JoyAgent提供验证有效的主流模式,方便快速上手;LangGraph则提供自由,但对架构设计能力要求更高。
并发与异步
JoyAgent:天生高并发,自带DAG(有向无环图)执行引擎,能自动把规划好的任务里没有依赖关系的分支并行执行。通过SSE实现全链路流式输出,能实时看到任务的中间进展。
LangGraph:异步优先,基于asyncio,天然支持非阻塞操作。
大坑预警 ❗️ 很多人以为用了LangGraph就能自动并行,其实不是。默认情况下,它还是会按图的顺序执行。 你必须显式地设计分支节点,才能让多个任务真正并行起来。 可实现非常细粒度的并发控制,比如同时调用多个外部API,然后在下游节点汇总结果。
小结:JoyAgent的并发依赖于底层框架,对开发者透明;LangGraph则需要明确地在图中设计并行流程,更灵活但也更考验人。
工具集成与协作
JoyAgent:自带豪华工具箱,即插即用。预置代码解释器、深度搜索、文件操作等多种常用工具,报告生成Agent、PPT生成Agent等智能体。扩展新工具也很方便:简单的,写个Python脚本放进tools/目录注册一下就行;复杂的,在Java后端实现一个BaseTool接口即可。
LangGraph:万物皆可为工具,生态就是力量。优势是背靠LangChain庞大的工具生态,100多种工具(搜索、计算、数据库、爬虫…)开箱即用。集成能力极强,任何REST API、Python函数,甚至一个OpenAPI规范,都能被轻松包装成一个工具节点。
在多智能体协作上,JoyAgent更偏向集中的经理-工人模式,而LangGraph可构建复杂网络,如对等Agent对话、市场竞价分配任务等(需要编码实现)。
小结:JoyAgent的工具体系只能满足常见需求;LangGraph则能把任何外部服务都整合进你的Agent系统。
数据流与记忆
Agent在执行多步任务时,如何记住上下文和传递信息至关重要。
JoyAgent:隐式的中央上下文管理。内部维护一个共享的内存/工作记忆,包含用户请求、任务列表、中间结果等。整个任务流程中,所有Agent都从记忆模块读取信息并更新结果。跨任务级别的记忆,能保存相似任务的解决方案,下次遇到时可参考。
LangGraph:显式的分布式状态管理。开发者需要明确定义一个State结构(通常是Python字典),列出Agent需要追踪的所有变量。整个流程就是对这个State对象不断进行读写和转换的过程。透明可控,每一步的数据变化都一清二楚。引入Checkpoint机制,可以将Agent的中间状态持久化到数据库,即使系统重启也能恢复。这对于构建需要长期运行的学习型Agent来说,是核弹级的功能。
小结:JoyAgent的记忆管理是中央数据库;LangGraph的记忆管理则需要你亲手设计,但提供完全的控制权和更强的持久化能力。
真实场景大比拼
文档理解与报告生成
- JoyAgent:非常擅长,有专门的报告生成智能体。
- LangGraph:更通用。可用于轻松构建各种RAG流程,对接PDF、数据库、网页等知识源,从合同分析到论文总结都能做。
流程自动化(RPA)
- JoyAgent:任务执行强,通过配置不同的persona(人格)和工具组合来实现。
- LangGraph:灵活编排判断和循环,非常适合构建逻辑分支明确的业务流程,如采购审批流。
跨系统复杂任务
- JoyAgent:能拆分出多个子任务,并行交给不同的工具完成再整合。擅长跨域任务整合。
- LangGraph:自由度更高。可让两个跨系统任务并行,互相通信,动态决定执行顺序。代价是需要处理数据格式转换、错误处理等细节。
LangGraph4j
GitHub,820 Star,120 Fork。LangGraph的Java版移植,旨在为Java开发者提供一种更加直观和易于使用的方式来构建复杂的智能体交互图,支持开发者构建有状态多智能体应用,并能够与LLMs无缝集成。
特点
- 流程管理:提供强大的流程控制能力,允许开发者定义包含循环、条件分支和并行执行等复杂逻辑的工作流,灵活地处理各种业务需求,并确保流程的高效性和准确性。
- 状态管理:支持状态对象贯穿整个图的执行过程,提供对流程状态的精细控制。每个节点执行前后都会创建检查点,这些检查点不仅保存当前的状态信息,还包括版本号和回溯关系等重要数据。这意味着即使在长时间运行或可能中断的应用场景下,也可以轻松恢复到之前的状态,增强应用的健壮性和用户体验。
- 模块化设计:采用模块化设计,即每个节点专注于完成单一职责,好处是简化开发流程,提高代码复用性,并降低维护成本。模块之间的耦合度较低,更容易进行扩展和优化。促进团队协作,不同成员可以独立负责不同的模块,最后再整合成完整的系统。
- 人机协作:支持Human-in-Loop(人在环路)模式,这使得在关键决策点上将控制权交还给用户成为可能,非常适合那些既需要自动化又离不开人类判断力的任务,实现人与机器的有效协同工作。
- 可视化工具:提供PlantUML和Mermaid支持,使得图形化展示和编辑图结构成为可能。
- IDE:与Spring Boot、Jetty和Quarkus等流行框架无缝集成,简化开发流程。
概念
- 状态图:StateGraph,一种数据结构,其生命周期存在于整个LangGraph过程中,所有节点的执行过程和结构都可以被记录到状态图中;而且每个节点也都可以随时访问状态图中的数据,来获取其当时的执行过程和结果;
- 节点:Node,就是一个个的智能体或功能函数;用来执行具体任务;
- 边:Edge,如果说节点是一个函数,那么边就相当于判断逻辑中的分支,边决定当前节点执行完毕之后,下一个执行的节点;当然,还有一种边叫做条件边,意思就是可以根据条件判断来动态决定应该执行哪个节点;
- 检查点:State,存档点。程序在状态图中进行流转,每一次进入新节点前,都会存档一次,后续用户再来访问此Agent时,就会读取存档。也是用这种能力,实现的人机交互、时光回溯。本质都是往前找检查点的版本号就行。检查点和状态图的区别是:状态图只是一个属性,在运行阶段可以读取的部分数据。而检查点是存储当前节点的所有信息,包括状态图,也有检查点版本号,回溯关系之类的信息。
引入依赖:implementation 'org.bsc.langgraph4j:langgraph4j-core:1.5.14'
AgentUniverse
AgentUniverse是蚂蚁集团开源(GitHub,1.6k Star,246 Fork)的MAS框架,实现分层的记忆管理系统,支持短期和长期记忆,支持多种存储后端(内存、向量、关系数据库)。
短期记忆基于Langchain ConversationTokenBufferMemory实现,主要限制是对token限制进行截断且不进行压缩。核心Token管控机制实现如下:
def prune(self, memories: List[Message]) -> List[Message]:tokens = get_memory_tokens(new_memories, agent_llm_name)if tokens <= self.max_tokens:return new_memories# 超出限制时,从头部开始移除早期记忆while tokens > self.max_tokens:pruned_memory = new_memories.pop(0) # FIFO策略tokens = get_memory_tokens(new_memories, agent_llm_name)
记忆构建过程:
def build_memory(self):# 1. 丢弃系统消息for message in self.messages:if message.type.lower() == ChatMessageEnum.SYSTEM.value:self.messages.remove(message)# 2. 成对生成Human-AI对话for i in range(0, len(self.messages), 2):inputs, outputs = self.generate_chat_messages(self.messages[i], self.messages[i + 1])self.save_context(inputs, outputs)
长期记忆实现比较简单,基于压缩提示词实现
逐步总结所提供对话内容,压缩记忆信息。
基于先前的记忆概要,返回新的记忆概要,必须使用中文回答。
先前的记忆概要为:
{summary}
新一轮对话:
{new_lines}
要求:
生成的新的概要,总体字数不超过{max_tokens}个字符。
Langroid
CMU和威斯康星大学推出的开源轻量级多智能体框架,核心思想:Agent+Task+消息传递。每个Agent可装备LLM、向量数据库和工具函数,然后通过Task来管理和编排它们之间的交互。
GitHub,3.6k Star,341 Fork。
类似框架:CrewAI、AutoGen、LangChain。
Agent作为一等公民,Task负责编排,消息传递机制很清晰。支持hierarchical task delegation,复杂的多智能体系统也能轻松搭建。
示例:
import langroid as lrllm_cfg = lr.language_models.OpenAIGPTConfig(chat_model="gpt-4"
)
agent = lr.ChatAgent(lr.ChatAgentConfig(llm=llm_cfg))
task = lr.Task(agent, name="助手", system_message="你是一个有用的助手")
task.run("你好")
技术亮点
- 工具调用支持:支持OpenAI的Function Calling,ToolMessage机制,兼容任何LLM。用Pydantic定义工具接口,类型安全又简洁。
- 向量数据库集成:支持Qdrant、Chroma、LanceDB等主流向量库。
- LLM支持:OpenAI,本地模型、Ollama、oobabooga等各种服务,基本上所有兼容OpenAI API的模型都能用。
- 缓存机制:支持Redis缓存LLM响应,开发调试时能节省不少API费用。
实例:文档信息提取场景,可设置两个Agent:
- LeaseExtractor:负责生成问题和整理结果
- DocAgent:负责从文档中检索答案
通过消息传递协作,LeaseExtractor提出问题,DocAgent从向量数据库中检索相关信息回答,最后LeaseExtractor用Function Call输出结构化结果。
需要文档解析功能就装doc-chat扩展,数据库功能装db扩展。
LiteFlow
GitHub,5.3k Star,866 Fork。
节点类型:
- IntentionClassifyNode:意图识别节点,通过IntentionClassifyAgent分析用户输入,起到路由作用,分类结果分为获取新闻列表、获取新闻内容和其他(日常闲聊)。
- ParamAnalyseNode:参数提取节点,借助ParamAnalyseAgent分析用户输入,提取查找新闻列表的关键参数。
- GetHotNewsListNode:获取新闻标题列表节点,依据参数执行服务调用,获取新闻对象列表,并通过SSE推送新闻列表信息。
- GetHotNewsContentNode:获取新闻内容节点,借助HotNewsContentAgent分析用户输入,从多轮对话上下文变量中获取新闻信息,调用MCP服务工具查找新闻内容并总结,同时异步推送新闻原内容。
- NormalChatNode:普通聊天节点,借助NormalChatAgent基于大模型知识储备回答用户问题。
- OutputNode:输出节点,借助UniOutputAgent将文字输出内容转述为固定格式。
智能体编排的核心在于变量管理;根据变量生命周期,本文将变量分为三种类型:
- 单轮对话级别:通过LiteFlow上下文变量解决,借助
NodeComponent的getContextBean方法获取上下文信息,作为节点间数据传递的通信总线。 - 多轮对话级别:实现方案包括继承
MessageChatMemoryAdvisor复写aroundCall方法、自管控ChatMemory或存入全局变量池(如Redis、内存缓存)。
public static void putVariableIntoMemoryWithReplace(String chatId, String key, String value) {if (!StringUtils.hasText(key) || !StringUtils.hasText(value)) {return;}ChatMemory chatMemory = getChatMemory(chatId);List<Message> messages = chatMemory.get(chatId, 50);if (!CollectionUtils.isEmpty(messages)) {List<Message> newMessages = new ArrayList<>();for (Message message : messages) {if (message instanceof SystemMessage systemMessage) {if (systemMessage.getText().contains(VARIABLE_PREFIX) && systemMessage.getText().contains(key)) {continue;} else {newMessages.add(message);}} else {newMessages.add(message);}}chatMemory.clear(chatId);chatMemory.add(chatId, newMessages);}chatMemory.add(chatId, new SystemMessage(String.format(MEMORY_VARIABLE, key, value)));
}
解读:
- 该方法用于将变量存入会话记忆中,以便在多轮对话中引用。
- 遍历对话消息,过滤掉包含特定前缀和键的系统消息,避免变量重复。
- 清空原有对话消息,添加过滤后的新消息,并注入新的系统消息(包含变量信息)。
- 全局级别:适用于用户名称、偏好等需持久记忆的信息。
public class GuavaCacheTools {static Cache<String, String> cache = CacheBuilder.newBuilder().maximumSize(100).build();public static void put(String chatId, String key, String value) {if (StringUtils.hasText(key) && StringUtils.hasText(value)) {cache.put(chatId + ":" + key, value);}}public static String get(String chatId, String key) {if (StringUtils.hasText(key) && StringUtils.hasText(chatId)) {return cache.getIfPresent(chatId + ":" + key);}return "";}
}
解读:
- 使用Guava CacheBuilder创建缓存,设置最大容量为100
示例Agent
public class HotNewsContentAgent {public static final String SYS_PROMPT = """你是一个获取热点新闻内容的助手,可以调用工具 getMainContentOfNews 获取新闻内容。获取新闻内容需传递新闻链接(newsUrl),该信息可从新闻列表中获取。新闻列表:{last_search_news_list}请根据用户提问判断对应新闻,若无法判断则返回“无法判断询问的是哪条内容”。若找到对应新闻,调用工具获取内容并总结。""";private final ChatClient chatClient;public HotNewsContentAgent(ChatClient.Builder chatClientBuilder, ToolCallbackProvider tools) {this.chatClient = chatClientBuilder.defaultTools(tools).defaultOptions(DashScopeChatOptions.builder().withTopP(0.7).build()).build();}public Flux<ChatResponse> getHotNewsContent(String userInput, String chatId) {String list = getLastSearchNewsList(chatId);log.info("getHotNewsContent 最近一次查询处理的新闻列表为:{}", list);SystemPromptTemplate spt = new SystemPromptTemplate(SYS_PROMPT);Message system = spt.createMessage(Map.of("last_search_news_list", list));Message user = new UserMessage(userInput);Prompt prompt = new Prompt(List.of(system, user));return chatClient.prompt(prompt).advisors(new MessageChatMemoryAdvisor(ChatMemoryTools.getChatMemory(chatId))).stream().chatResponse();}private String getLastSearchNewsList(String chatId) {ChatMemory chatMemory = ChatMemoryTools.getChatMemory(chatId);return ChatMemoryTools.getVariableFromMemory(chatId, "lastSearchNewsList");}
}
解读:
- 定义系统提示词模板,包含新闻列表变量
{last_search_news_list},以便Agent获取上下文信息。 - 构造方法初始化ChatClient,设置默认工具和选项。
getHotNewsContent方法根据用户输入和会话ID获取新闻内容:- 从会话记忆中获取最近一次查询的新闻列表。
- 创建系统消息和用户消息,构建提示。
- 调用ChatClient发送提示,通过MessageChatMemoryAdvisor管理会话记忆。
- 返回聊天响应的Flux流。
Tinyflow
官网,GitHub,572 Star,Gitee
MiroFlow
GitHub,398 Star,31 Fork。
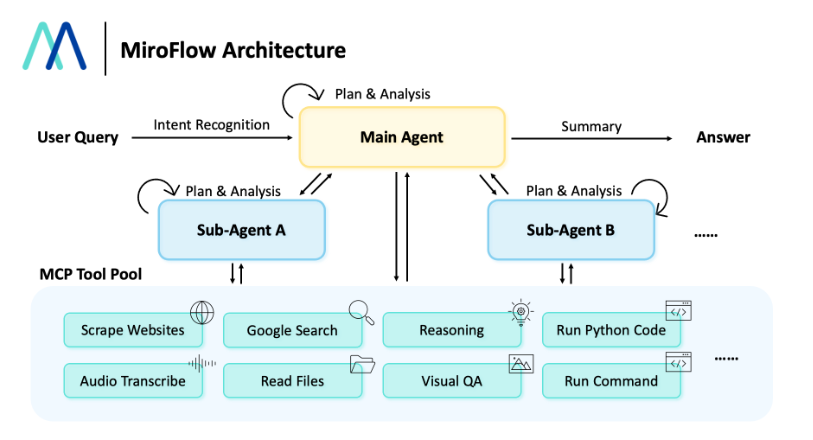
MiroFlow是一款经过实战检验的模块化AI智能体框架,旨在可靠地完成复杂的工具使用任务,并为MiroThinker等模型生成高质量的智能体轨迹数据。其主要功能包括持续实现领先(SOTA)且高度可复现的性能,具备高并发和强大的容错能力以高效扩展数据收集,内置用于可视化和调试智能体轨迹数据的可观测性及评估工具。通过意图识别、智能规划、将任务委派给专业子智能体以及通过MCP服务器访问多种工具等多阶段流程来处理用户查询。核心要点在于其卓越的性能表现、对可复现性的严格承诺、持续的社区共创以及从基准测试到生产环境的无缝过渡能力。
CoAgents
GitHub,224 Star。
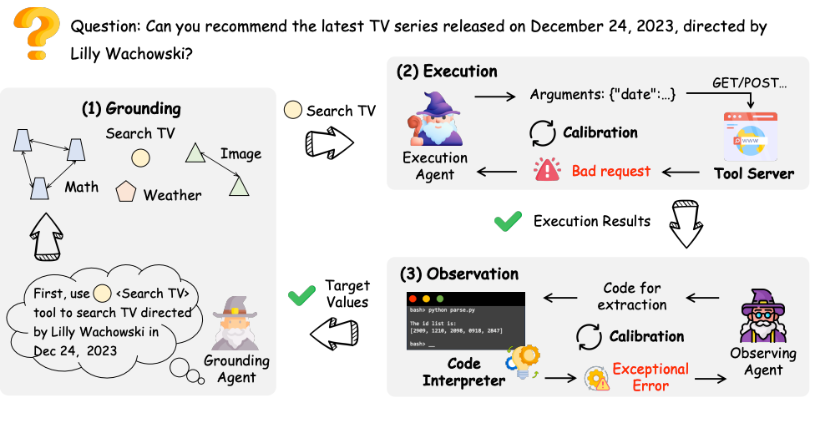 一个专注于合作与交互式代理的框架,其核心在于使代理能够通过协作学习和使用工具。通过定义接地代理生成工具使用指令、执行代理执行选定工具以及观察代理从执行结果中提取关键值等角色,实现多代理间的协同工作。其关键特性在于执行代理和观察代理能够根据工具环境的反馈进行迭代适应,从而提升工具使用的效率与准确性,该框架已通过与TMDB平台API的互动进行能力演示。
一个专注于合作与交互式代理的框架,其核心在于使代理能够通过协作学习和使用工具。通过定义接地代理生成工具使用指令、执行代理执行选定工具以及观察代理从执行结果中提取关键值等角色,实现多代理间的协同工作。其关键特性在于执行代理和观察代理能够根据工具环境的反馈进行迭代适应,从而提升工具使用的效率与准确性,该框架已通过与TMDB平台API的互动进行能力演示。