MemoryVLA:让机器人拥有“记忆“的视觉-语言-动作模型
导读
机器人操作任务往往需要依赖历史信息才能做出正确决策,比如在按钮操作中,按下前后的视觉状态几乎相同,机器人很难判断是否已经完成了操作。然而,当前主流的视觉-语言-动作(VLA)模型如OpenVLA、π0等都只关注当前观察,忽略了时序依赖关系,在长时域任务上表现不佳。清华大学联合多家机构的研究团队受认知科学中人类双记忆系统启发,提出了MemoryVLA框架(2025.8),通过感知-认知记忆库(PCMB)同时建模低级视觉细节和高级语义信息,实现了机器人操作中的时序建模。在150+仿真和真实世界任务上,MemoryVLA显著超越了现有最先进方法,特别是在长时域任务上取得了+26%的性能提升。
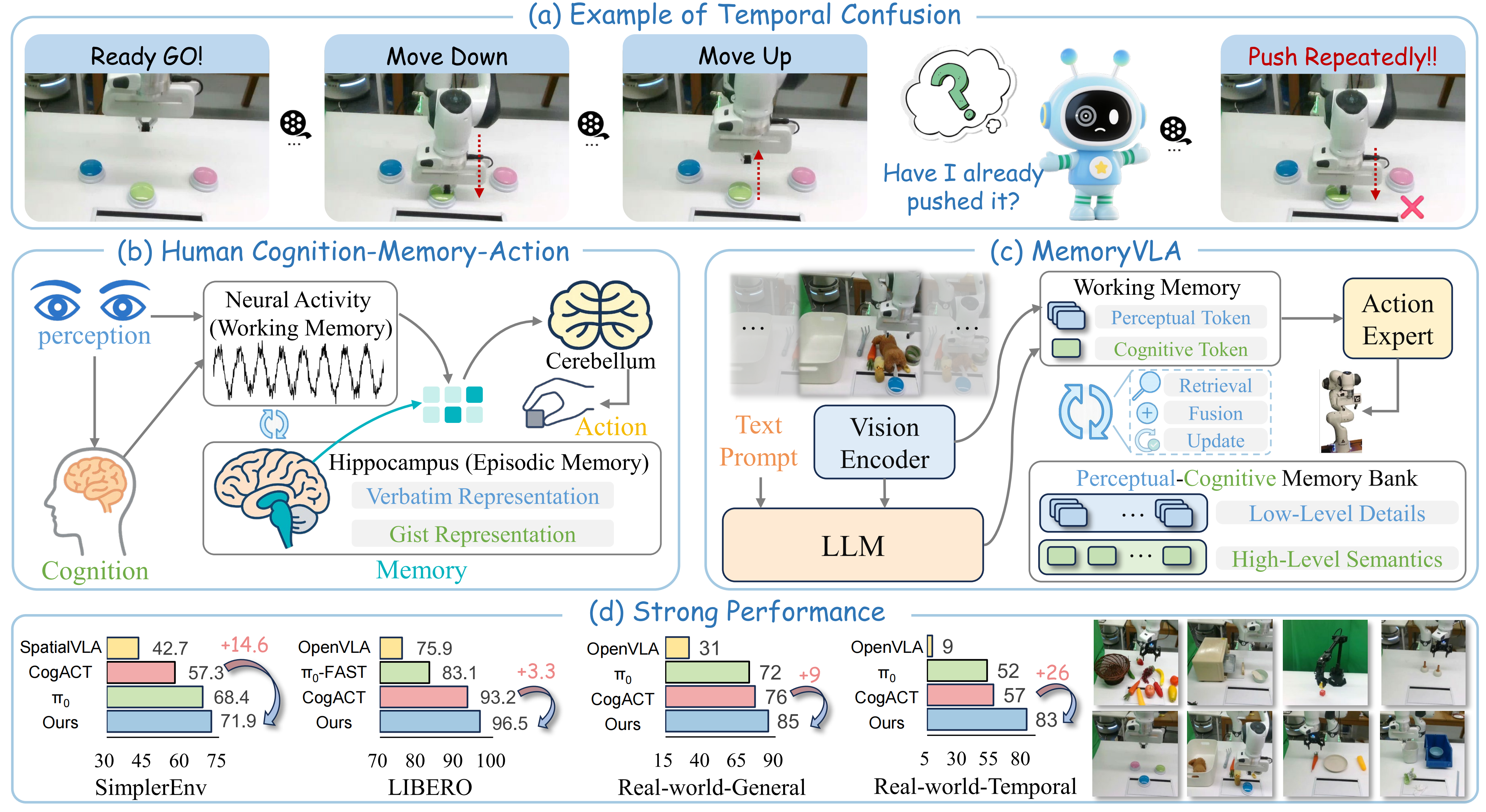
一、引言:机器人为什么需要"记忆"?
想象一下这样的场景:你正在厨房做饭,需要按下微波炉的启动按钮。当你按下按钮后,按钮的外观几乎没有变化,但你知道自己已经按过了,因为你的大脑记住了刚才的动作。然而,对于机器人来说,如果它只能"看到"当前的画面,就很难判断按钮是否已经被按下。
这就是机器人操作任务中的一个核心问题:非马尔可夫性质。简单来说,就是仅凭当前的观察信息,机器人无法做出最优的决策,它需要"记住"之前发生了什么。
目前主流的视觉-语言-动作(VLA)模型,如OpenVLA[1]和π0[2],都存在一个共同的局限:它们只关注当前时刻的观察,完全忽略了历史信息。这就像是让一个失忆症患者去完成复杂的任务序列,自然会遇到困难。
为了解决这个问题,清华大学自动化系、Dexmal、MEGVII等机构的研究团队从认知科学中汲取灵感,提出了MemoryVLA框架。这个框架模拟人类的双记忆系统,让机器人也拥有"工作记忆"和"长期记忆",从而能够更好地处理需要时序依赖的复杂操作任务。
二、认知科学启发:人类是如何处理复杂任务的?
在深入了解MemoryVLA的技术细节之前,我们先来看看人类大脑是如何处理复杂操作任务的。认知科学研究表明,人类依赖一个精妙的双记忆系统:
2.1 工作记忆:短期的"缓存"
工作记忆就像计算机的内存,负责临时存储当前正在处理的信息,为即时决策提供短期记忆支持。。当你在做饭时,工作记忆会保持对当前步骤的关注,比如"我正在切洋葱"或"锅里的水快开了"。这种记忆通过大脑皮层的神经活动来维持,容量有限但响应迅速。在未经复述的条件下,大部分资讯在短期记忆中保持的时间很短, 通常在5-20秒,最长不超过1分钟。
2.2 情景记忆:长期的"硬盘"
情景记忆则像硬盘一样,由海马体支持,负责存储过去的经历和经验。它以两种形式保存信息:
- 逐字表征:保存精确的细节,比如"5分钟前我把盐放在了左边的柜子里"
- 要点表征:提取抽象的语义,比如"做这道菜需要先炒香料"
2.3 记忆的协同工作
在执行复杂任务时,工作记忆会从情景记忆中检索相关的历史信息,将其与当前的感知信息整合,然后指导具体的动作执行。同时,新的经历也会被整合到情景记忆中,为未来的决策提供参考。
这种双记忆系统让人类能够灵活应对各种复杂的操作任务,即使在视觉信息不足的情况下,也能依靠记忆做出正确的判断。
三、MemoryVLA框架:机器人的"认知-记忆-动作"系统
受人类双记忆系统启发,研究团队设计了MemoryVLA框架,这是一个端到端的"认知-记忆-动作"系统,专门用于处理需要时序依赖的机器人操作任务。
3.1 整体架构概览
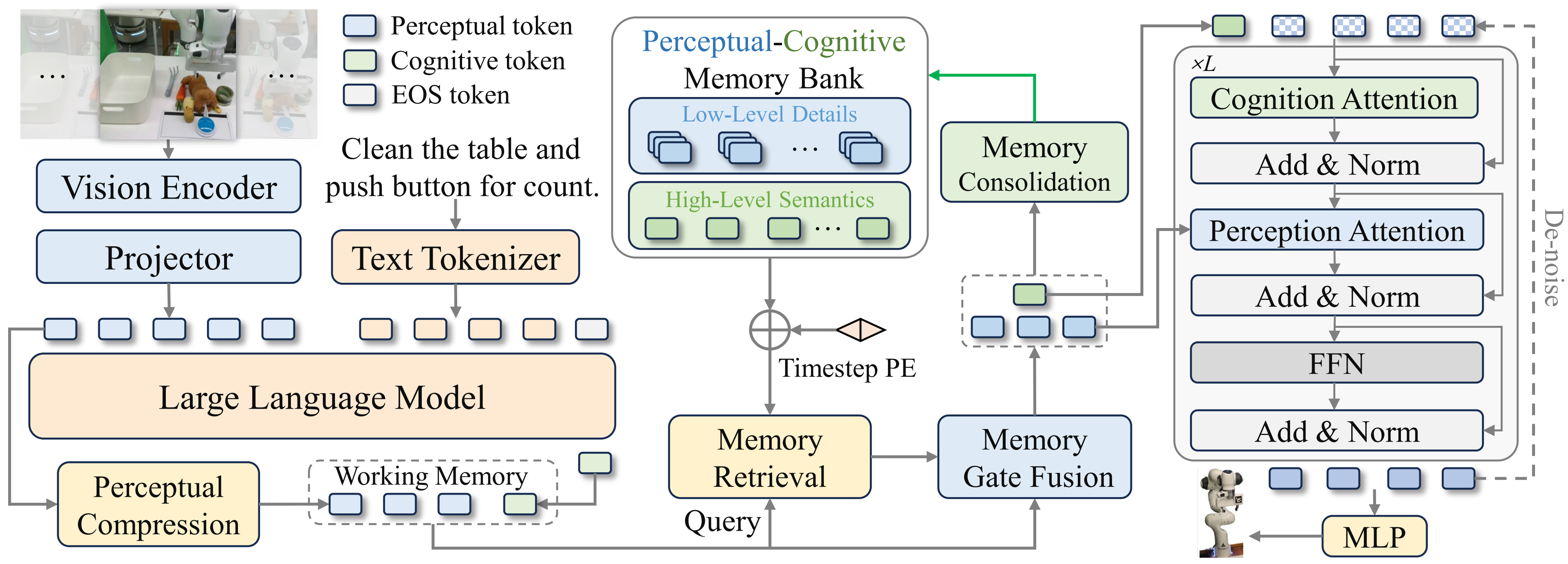
RGB观测图像与语言指令通过一个70亿参数的视觉语言模型(VLM)编码为感知令牌与认知令牌,形成短期工作记忆。工作记忆通过查询感知-认知记忆库(PCMB)检索相关的历史上下文信息(包括高层语义特征与底层视觉细节),将其与当前令牌自适应融合,并通过合并最相似邻接条目的方式增强PCMB的存储。经记忆增强的令牌随后作为条件输入扩散变换器,用于预测未来的动作序列。
MemoryVLA的整体架构可以分为三个核心模块:
- 视觉-语言认知模块:负责理解当前的观察和指令
- 感知-认知记忆模块:负责存储和检索历史信息
- 记忆条件动作专家:负责基于记忆信息生成动作序列
让我们用一个生活化的例子来理解这个架构。假设机器人需要完成"清理桌子并按下计数按钮"这个任务:
- 认知模块就像机器人的"眼睛和大脑",它看到桌子上有杂物,理解了"清理桌子"的指令
- 记忆模块就像机器人的"记忆库",它记住了之前清理了哪些物品,按钮按了几次
- 动作专家就像机器人的"手",它根据当前观察和历史记忆,决定下一步应该做什么
3.2 问题建模
在技术层面,MemoryVLA将机器人操作建模为一个序列决策过程。给定当前的RGB图像 I∈RH×W×3I \in \mathbb{R}^{H \times W \times 3}I∈RH×W×3 和语言指令 LLL,模型需要输出一个动作序列:
A=(a1,a2,...,aT)=π(I,L)A = (a_1, a_2, ..., a_T) = \pi(I, L)A=(a1,a2,...,aT)=π(I,L)
其中每个动作 at=[Δx,Δy,Δz,Δθx,Δθy,Δθz,g]Ta_t = [\Delta x, \Delta y, \Delta z, \Delta \theta_x, \Delta \theta_y, \Delta \theta_z, g]^Tat=[Δx,Δy,Δz,Δθx,Δθy,Δθz,g]T 包含了相对位移、相对旋转(欧拉角)和夹爪状态。
这个建模方式的关键在于,策略 π\piπ 不仅依赖当前的观察,还会利用历史信息来做决策,从而解决了传统VLA模型的马尔可夫假设局限。
四、技术深度解析:三大核心模块
4.1 模块一:视觉-语言认知模块
这个模块相当于机器人的"感知和理解"系统,负责将原始的视觉和语言信息转换为机器人能够理解的表征。该模块基于7B参数的Prismatic VLM构建,它在大规模异构机器人数据集Open-X Embodiment上进行了预训练。
双编码器视觉处理
为了充分提取视觉信息,MemoryVLA采用了并行的双编码器架构:
- DINOv2:专门用于提取丰富的视觉特征,擅长捕捉物体的几何和空间关系
- SigLIP:专门用于视觉-语言对齐,能够理解视觉内容与语言描述的对应关系
这就像给机器人配备了两种不同的"眼睛":一种专门看形状和位置,另一种专门理解语义含义。两种视觉特征被拼接后,通过一个感知压缩模块(基于SE-bottleneck设计)压缩为256个感知token,这些token包含了丰富的低级视觉细节。
语言理解与认知提取
与此同时,原始视觉特征还会通过线性投影进入语言嵌入空间,与分词后的指令一起输入到LLaMA-7B大语言模型中。这个过程的巧妙之处在于,大语言模型不仅理解了指令的含义,还结合了视觉信息,在句末(EOS)位置输出一个认知token。
这个认知token可以理解为机器人对当前情况的"高级理解",它不仅知道看到了什么,还知道应该做什么,以及这个动作在整个任务中的意义。
工作记忆的形成
感知token和认知token共同构成了机器人的工作记忆:
Mwk={p∈RNp×dp,c∈R1×dc}M_{wk} = \{p \in \mathbb{R}^{N_p \times d_p}, c \in \mathbb{R}^{1 \times d_c}\}Mwk={p∈RNp×dp,c∈R1×dc}
其中 ppp 代表256个感知token,ccc 代表1个认知token。这个工作记忆就像人类大脑皮层的神经活动,保持着对当前情况的即时感知和理解。
4.2 模块二:感知-认知记忆模块
这是MemoryVLA的核心创新,也是整个框架最复杂的部分。它模拟人类的海马体记忆系统,负责长期存储、检索和整合历史信息。
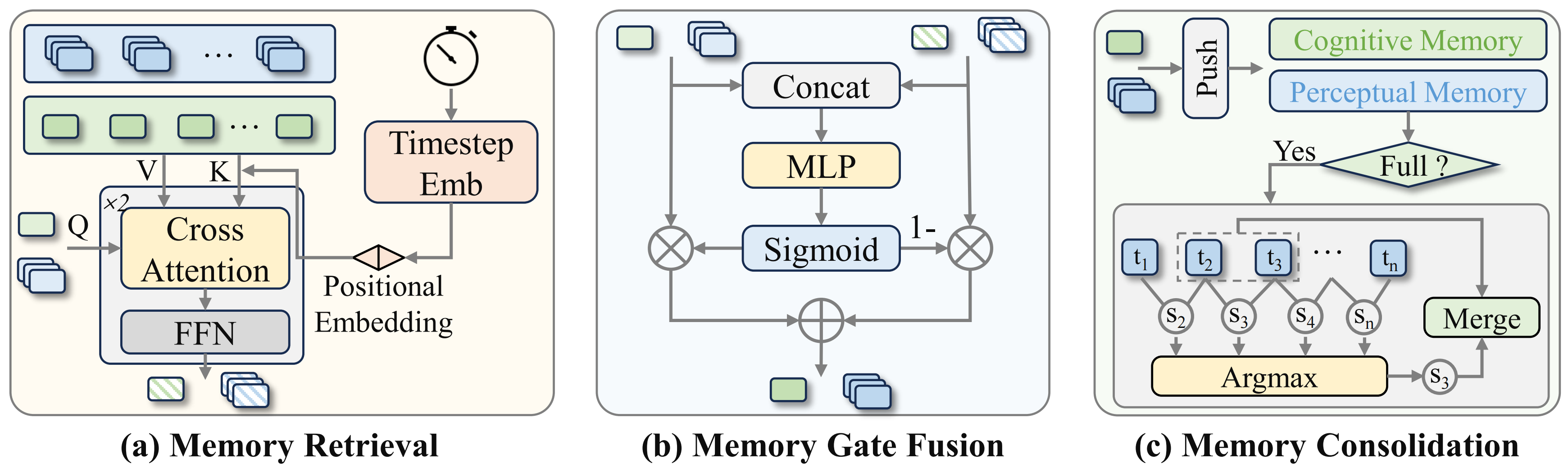
模块详情 (a) 检索机制:当前感知与认知标记通过带有时序位置编码的交叉注意力查询PCMB,以获取相关历史特征。(b) 门控融合:当前标记与检索到的标记通过门控机制进行自适应融合。© 整合机制:融合后的标记将更新至PCMB。当PCMB达到容量上限时,系统会计算相邻条目间的相似度,并合并最相似的特征对以保持存储紧凑性。
感知-认知记忆库(PCMB)
记忆库采用双流设计,分别存储两种类型的信息:
Mpcmb={mx∣x∈{per,cog}}M_{pcmb} = \{m^x | x \in \{per, cog\}\}Mpcmb={mx∣x∈{per,cog}}
- 感知记忆流:存储低级的视觉细节,比如物体的精确位置、颜色、纹理等
- 认知记忆流:存储高级的语义信息,比如任务的进展状态、动作的意图等
每个流最多可以存储L个条目,当容量满了之后会通过智能的整合机制来管理存储空间。
记忆检索:智能的历史信息查找
当机器人需要做决策时,当前的工作记忆会作为"查询",从记忆库中检索相关的历史信息。这个过程使用了带时序位置编码的交叉注意力机制:
# 伪代码示例:记忆检索过程
def memory_retrieval(current_tokens, memory_bank, timesteps):# 为每个记忆条目添加时序位置编码K = [memory + timestep_encoding(t) for memory, t in zip(memory_bank, timesteps)]V = memory_bank# 通过交叉注意力检索相关信息attention_weights = softmax(current_tokens @ K.T / sqrt(d_model))retrieved_info = attention_weights @ Vreturn retrieved_info
这个机制的巧妙之处在于,它不是简单地检索最近的记忆,而是根据当前情况的相关性来检索。比如,当机器人看到按钮时,它会自动检索之前与按钮相关的操作记忆,而不是无关的清理动作。
门控融合:自适应的信息整合
检索到历史信息后,系统需要决定如何将其与当前信息结合。MemoryVLA使用了一个学习的门控机制:
gx=σ(MLP(concat[x,Hx]))g^x = \sigma(MLP(concat[x, H^x]))gx=σ(MLP(concat[x,Hx]))
x~=gx⊙Hx+(1−gx)⊙x\tilde{x} = g^x \odot H^x + (1-g^x) \odot xx~=gx⊙Hx+(1−gx)⊙x
这个门控机制就像一个智能的"调音师",它会根据具体情况决定历史信息和当前信息的权重。当历史信息很重要时(比如需要记住之前按了几次按钮),门控会更多地依赖检索到的记忆;当当前信息更关键时(比如需要精确定位新出现的物体),门控会更多地关注当前观察。
记忆整合:智能的存储管理
随着任务的进行,记忆库会不断积累新的信息。当存储空间不足时,系统会自动进行记忆整合:
- 计算相似度:在每个记忆流内,计算相邻条目之间的余弦相似度
- 选择合并对象:找到最相似的相邻条目对
- 执行合并:将两个相似的记忆条目平均合并为一个
这个过程模拟了人类记忆的整合机制,保留最重要的信息,同时减少冗余。
4.3 模块三:记忆条件动作专家
有了丰富的记忆信息后,最后一步就是生成具体的动作序列。MemoryVLA采用了基于扩散模型的动作生成方法。
为什么选择扩散模型?
机器人的动作空间是连续的、多模态的。比如,抓取一个杯子可能有多种合理的方式,传统的回归方法往往只能输出一种"平均"的动作,而扩散模型能够捕捉这种多样性。
扩散Transformer(DiT)架构
MemoryVLA使用了扩散Transformer架构,通过10步DDIM去噪过程生成16步的未来动作序列。整个过程可以理解为:
- 初始化:从随机噪声开始
- 条件注入:在每个去噪步骤中,注入记忆增强的表征
- 双重注意力:
- 认知注意力层:利用高级语义信息指导动作规划
- 感知注意力层:利用细粒度视觉信息精确控制动作
- 逐步去噪:通过多步迭代,逐渐从噪声中"雕刻"出精确的动作序列
训练目标
模型使用均方误差(MSE)损失进行训练:
L=Et,ϵ[∥ϵ−ϵθ(xt,t,c~,p~)∥2]\mathcal{L} = \mathbb{E}_{t,\epsilon} \left[ \|\epsilon - \epsilon_\theta(x_t, t, \tilde{c}, \tilde{p})\|^2 \right]L=Et,ϵ[∥ϵ−ϵθ(xt,t,c~,p~)∥2]
其中 ϵ\epsilonϵ 是真实噪声,ϵθ\epsilon_\thetaϵθ 是模型预测的噪声,c~\tilde{c}c~ 和 p~\tilde{p}p~ 是记忆增强的认知和感知表征。
五、实验验证:全方位的性能评估
为了验证MemoryVLA的有效性,研究团队进行了大规模的实验评估,涵盖仿真和真实世界环境,总共测试了150+任务和500+变体。
5.1 仿真环境评估
SimplerEnv基准测试
SimplerEnv是一个标准的机器人操作仿真基准,包含Bridge和Fractal两个子集:
Bridge子集结果:
- MemoryVLA:71.9%成功率
- CogACT(之前最佳):57.3%成功率
- 提升幅度:+14.6%
这个提升是相当显著的。在具体任务上,MemoryVLA在"勺子放毛巾"和"胡萝卜放盘子"任务上都达到了75%的成功率,而在"茄子放篮子"任务上更是达到了100%的完美表现。
Fractal子集结果:
- MemoryVLA:72.7%成功率
- CogACT:68.1%成功率
- 提升幅度:+4.6%
特别值得注意的是,在需要更多时序推理的"开关抽屉"任务上,MemoryVLA的提升更加明显,在视觉匹配设置下达到了84.7%的成功率,比CogACT提升了12.9%。
LIBERO基准测试
LIBERO是另一个重要的机器人操作基准,包含5个不同的任务套件:
| 任务套件 | MemoryVLA | CogACT | 提升幅度 |
|---|---|---|---|
| Spatial | 98.4% | 97.2% | +1.2% |
| Object | 98.4% | 98.0% | +0.4% |
| Goal | 96.4% | 90.2% | +6.2% |
| Long | 93.4% | 88.8% | +4.6% |
| LIBERO-90 | 95.6% | 92.1% | +3.5% |
| 平均 | 96.5% | 93.2% | +3.3% |
值得注意的是,MemoryVLA在所有子任务上都取得了提升,特别是在Goal和Long任务上提升更为明显,这些任务通常需要更多的长期规划和记忆。
5.2 真实世界评估
仿真结果虽然重要,但真实世界的表现才是检验技术实用性的金标准。研究团队在Franka和WidowX两种机器人上进行了真实世界测试。
通用操作任务
在6个通用操作任务上的结果:
| 任务 | MemoryVLA | CogACT | π0 |
|---|---|---|---|
| 插入圆环 | 87% | 80% | 67% |
| 鸡蛋放锅 | 80% | 67% | 73% |
| 鸡蛋放烤箱 | 80% | 60% | 73% |
| 叠杯子 | 93% | 93% | 87% |
| 叠积木 | 87% | 80% | 53% |
| 拾取水果 | 84% | 76% | 80% |
| 平均 | 85% | 76% | 72% |
长时域时序任务
这是MemoryVLA最能体现优势的测试场景,因为这些任务严重依赖历史信息:
| 任务 | MemoryVLA | CogACT | π0 |
|---|---|---|---|
| 顺序按按钮 | 58% | 15% | 25% |
| 更换食物 | 85% | 47% | 42% |
| 猜测位置 | 72% | 40% | 24% |
| 清理桌子计数 | 84% | 67% | 61% |
| 按顺序放置 | 100% | 90% | 82% |
| 清理餐桌 | 96% | 84% | 80% |
| 平均 | 83% | 57% | 52% |
在长时域任务上,MemoryVLA相比CogACT取得了惊人的+26%提升!这充分证明了记忆机制在处理复杂时序任务中的重要性。
5.3 消融实验:每个组件都很重要
为了理解MemoryVLA各个组件的贡献,研究团队进行了详细的消融实验:
记忆类型的影响
| 配置 | 成功率 |
|---|---|
| 仅认知记忆 | 63.5% |
| 仅感知记忆 | 65.2% |
| 感知+认知记忆 | 71.9% |
结果表明,双流记忆设计确实比单一记忆类型更有效,感知和认知信息的结合带来了显著的性能提升。
关键机制的贡献
| 移除的组件 | 成功率 | 性能下降 |
|---|---|---|
| 完整模型 | 71.9% | - |
| 无时序位置编码 | 69.8% | -2.1% |
| 无门控融合 | 68.5% | -3.4% |
| 无记忆整合 | 70.6% | -1.3% |
每个组件都对最终性能有贡献,其中门控融合机制的贡献最大,这说明自适应地整合历史和当前信息确实很重要。
记忆长度的影响
| 记忆长度 | 成功率 |
|---|---|
| L=5 | 69.8% |
| L=10 | 71.9% |
| L=15 | 72.3% |
随着记忆长度的增加,性能持续提升,但边际收益递减。L=10似乎是一个比较好的平衡点。
六、鲁棒性与泛化能力
除了基本的性能评估,研究团队还测试了MemoryVLA在各种分布外(Out-of-Distribution, OOD)条件下的鲁棒性,包括:
- 背景变化:从实验室环境到家庭、办公室环境
- 光照变化:明亮、昏暗等不同光照条件
- 干扰物:场景中出现训练时未见过的物体
- 遮挡:部分视野被遮挡的情况
- 物体变化:使用不同材质、颜色的物体
- 容器变化:使用不同形状、大小的容器
实验结果表明,MemoryVLA在这些挑战性条件下仍然保持了良好的性能,展现出了强大的泛化能力。这对于实际应用来说非常重要,因为真实世界的环境总是充满变化和不确定性。
七、技术创新点总结
MemoryVLA的主要技术创新可以总结为以下几个方面:
1. 认知科学启发的架构设计
该工作将认知科学中的双记忆系统理论系统性地引入VLA模型。通过模拟人类的工作记忆和情景记忆,MemoryVLA实现了更加自然和高效的时序建模。
2. 感知-认知双流记忆机制
传统的记忆机制往往只考虑单一类型的信息,而MemoryVLA创新性地设计了双流记忆架构,同时建模低级感知细节和高级认知语义,实现了更全面的历史信息保存。
3. 自适应记忆管理策略
通过检索、融合、整合三个核心操作,MemoryVLA实现了智能的记忆管理。特别是门控融合机制,能够根据具体情况自适应地平衡历史和当前信息的重要性。
4. 端到端的联合优化
与一些需要分阶段训练的方法不同,MemoryVLA实现了从感知到记忆再到动作的端到端联合优化,确保了各个组件之间的协调配合。
5. 扩散模型的创新应用
将扩散模型与记忆机制结合,通过双重注意力机制(认知注意力+感知注意力)实现了更精确的动作生成。
八、局限性与未来方向
尽管MemoryVLA取得了显著的成果,但仍然存在一些局限性和改进空间:
当前局限性
- 计算开销:记忆检索和融合机制增加了计算复杂度,特别是在长序列任务中
- 记忆容量:当前的记忆整合策略相对简单,可能会丢失一些重要的历史信息
- 多模态输入:目前主要依赖RGB图像,未来可以考虑整合深度、触觉等多模态信息
- 在线学习:当前模型主要基于离线训练,缺乏在线适应新环境的能力
未来研究方向
- 更高效的记忆机制:研究更加高效的记忆检索和整合算法,降低计算开销
- 层次化记忆结构:设计多层次的记忆架构,更好地建模不同时间尺度的依赖关系
- 多模态记忆融合:整合视觉、听觉、触觉等多种模态信息的记忆机制
- 持续学习能力:使机器人能够在执行任务的过程中不断学习和适应新环境
- 可解释性增强:提高记忆机制的可解释性,让人类能够理解机器人的决策过程
九、实际应用前景
MemoryVLA的技术突破为机器人在实际场景中的应用开辟了新的可能性:
家庭服务机器人
在家庭环境中,机器人需要记住家庭成员的偏好、物品的位置、日常作息等信息。MemoryVLA的记忆机制能够帮助机器人更好地适应家庭环境,提供个性化的服务。
工业自动化
在制造业中,许多装配任务需要严格的顺序控制和质量检查。MemoryVLA能够记住之前的操作步骤和检查结果,确保产品质量和生产效率。
医疗辅助
在医疗场景中,机器人需要记住患者的病史、治疗方案等信息,协助医护人员提供更好的医疗服务。
教育机器人
教育机器人需要记住学生的学习进度、知识掌握情况等,提供个性化的教学辅导。
结语
MemoryVLA代表了机器人操作技术的一个重要进步。通过引入认知科学的双记忆系统理论,它成功解决了传统VLA模型在时序建模方面的不足,在多个基准测试中取得了显著的性能提升。更重要的是,MemoryVLA符合当前机器人技术发展方向:不仅要让机器人能够感知和理解当前的环境,还要让它们能够"记住"过去的经历,并利用这些记忆来指导未来的行动。这种能力对于实现真正智能的机器人系统至关重要。随着技术的不断发展和完善,我们有理由相信,具备"记忆"能力的机器人将在更多的实际场景中发挥重要作用,为人类社会带来更大的价值。
参考文献
[1] Kim, D., et al. (2024). OpenVLA: An Open-Source Vision-Language-Action Model. arXiv preprint arXiv:2406.09246.
[2] Black, K., et al. (2024). Training a Helpful and Harmless Assistant with Reinforcement Learning from Human Feedback. arXiv preprint arXiv:2204.05862.
[3] Shi, H., et al. (2025). MemoryVLA: Perceptual-Cognitive Memory in Vision-Language-Action Models for Robotic Manipulation. 项目网站:https://shihao1895.github.io/MemoryVLA/