Flink 系列之二十六 - Flink SQL - 中间算子:普通聚合
之前做过数据平台,对于实时数据采集,使用了Flink。现在想想,在数据开发平台中,Flink的身影几乎无处不在,由于之前是边用边学,总体有点混乱,借此空隙,整理一下Flink的内容,算是一个知识积累,同时也分享给大家。
注意:由于框架不同版本改造会有些使用的不同,因此本次系列中使用基本框架是 Flink-1.19.x,Flink支持多种语言,这里的所有代码都是使用java,JDK版本使用的是19。
代码参考:https://github.com/forever1986/flink-study.git
目录
- 1 分组
- 1.1 group by
- 1.2 grouping sets
- 1.2.1 grouping sets示例
- 1.2.2 ROLLUP
- 1.2.3 CUBE
- 2 聚合类算子
- 2.1 count/min/max/sum/avg
上一章讲了源算子和输出算子,接下来学习如何使用FlinkSQL实现中间算子。在《系列之八 - Data Stream API的中间算子:转换和聚合》中讲了转换和聚合算子。转换算子相对于FlinkSQL来说比较简单,Map无非就是通过Select语句将数据进行转换后插入到新的表;Fliter在SQL中就是where的条件过滤;FlatMap则比较复杂,可能还是需要通过编程方式自定义函数。因此转换算子就不单独介绍,在后续的示例中或多或少都会看到这些简单操作的影子。这一章着重讲一下FlinkSQL中普通的聚合算子。
1 分组
在《系列之八 - Data Stream API的中间算子:转换和聚合》中讲到 Data Stream API的聚合时,提到需要先keyBy,keyBy就是分组,相当于标准SQL的group by。这里对FlinkSQL中的group by做一下简单演示和介绍。
1.1 group by
group by就是一个分组,解析到Data Stream API就是keyBy。这里直接使用一个示例来说明。
示例说明:假设是一个来自服务器cpu的日志,日志格式是“服务器id,cpu,时间”,使用DataGen作为源算子生成的;将通过服务器id对数据进行groupby分组,并输出id和cpu平均值
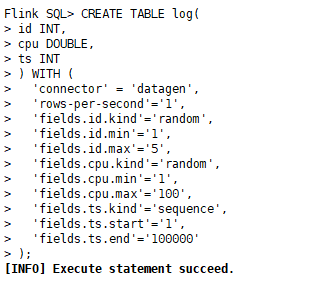
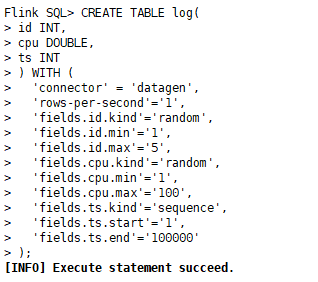
1)创建源算子表log:基于DataGen连接器,创建log表
CREATE TABLE log(id INT,cpu DOUBLE,ts INT
) WITH ('connector' = 'datagen','rows-per-second'='1','fields.id.kind'='random','fields.id.min'='1','fields.id.max'='5','fields.cpu.kind'='random','fields.cpu.min'='1','fields.cpu.max'='100','fields.ts.kind'='sequence','fields.ts.start'='1','fields.ts.end'='100000'
);
2)创建输出算子表avg_log:基于print连接器,创建avg_log表
CREATE TABLE avg_log(id INT,avg_cpu DOUBLE
) WITH (
'connector' = 'print'
);

3)执行聚合avg操作:通过insert语句,结合group by和avg函数,实现将log表数据插入到avg_log表
insert into avg_log select id,avg(cpu) from log group by id;

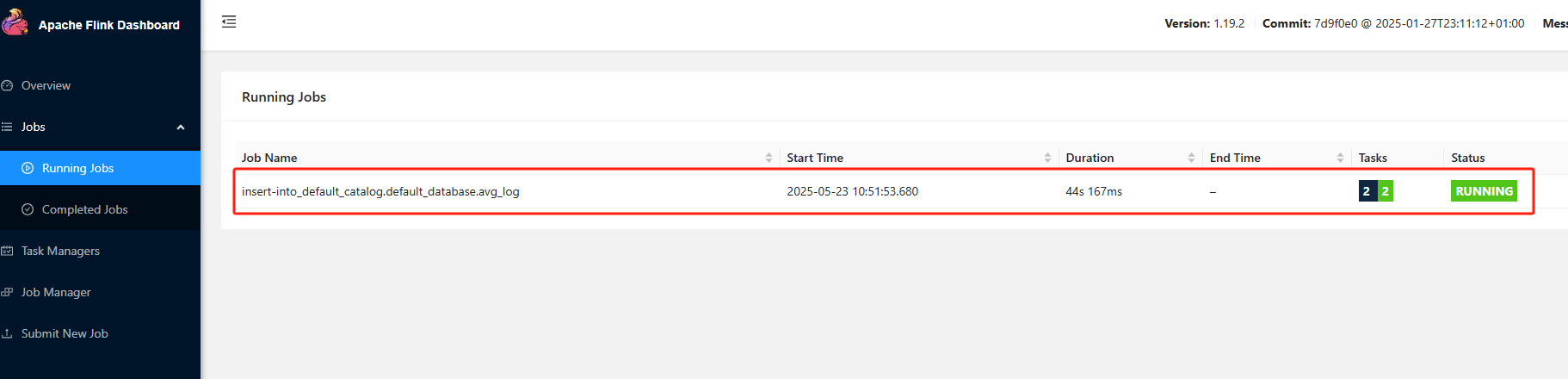
4)查看结果:上面可以看到执行insert操作,则生成一个job任务。这里可以通过web-ui控制台查看执行结果
在Runing Jobs可以看到对应的运行中任务
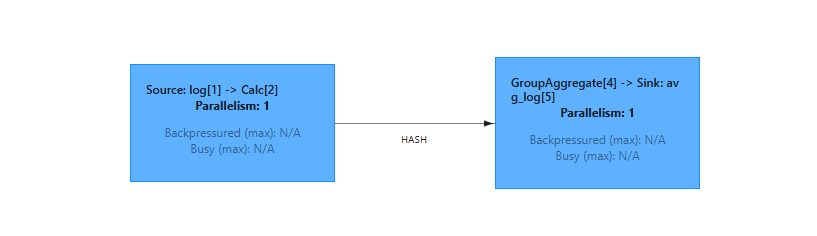
在Job的详情页可以看到其数据流程图
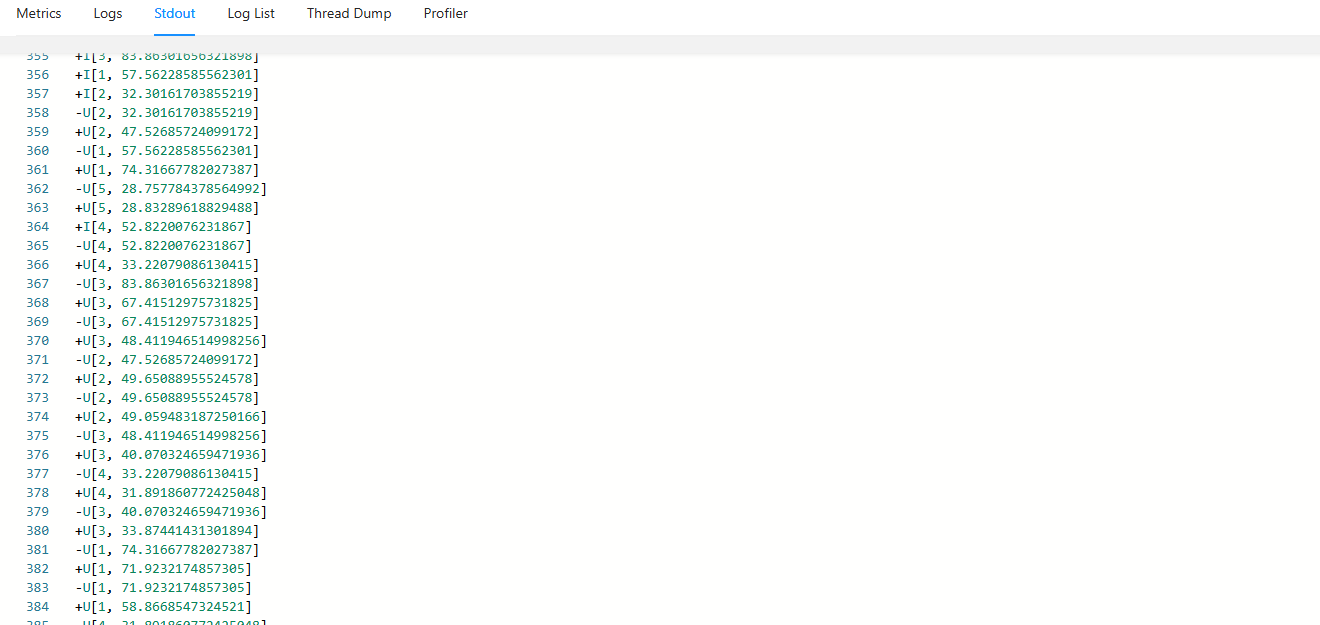
在Task Managers中的Stdout可以看到print连接器的输出结果
1.2 grouping sets
上面演示了简单的groupby使用,Flink经常被用做数仓的工具之一,那么支持OLAP的多维分析是必不可少的。因此在FlinkSQL中,提供了一种 grouping sets的便捷用法。在多维分析中,经常需要对不同维度进行聚合,而且这个维度可以随意组合,这在传统方式中可能需要写不同SQL来实现,而FlinkSQL提供了grouping sets允许在单个查询中实现多维度组合的分组统计,相较于传统方案,性能更优。这么说可能有点难理解,下面以官方示例来做演示。
1.2.1 grouping sets示例
示例说明:有一张表,有3个字段,分别是供应商id、产品id、产品等级。在实际应用中,可能需要查询同一个供应商相同产品等级的产品数量,同一个供应商所有产品的数量,所有供应商提供的产品总数等等
1)grouping sets语句:
SET sql-client.execution.result-mode=TABLEAU; SELECT supplier_id, rating, COUNT(*) AS total
FROM (VALUES('supplier1', 'product1', 4),('supplier1', 'product2', 3),('supplier2', 'product3', 3),('supplier2', 'product4', 4))
AS Products(supplier_id, product_id, rating)
GROUP BY GROUPING SETS ((supplier_id, rating), (supplier_id), ());
2)查看结果:
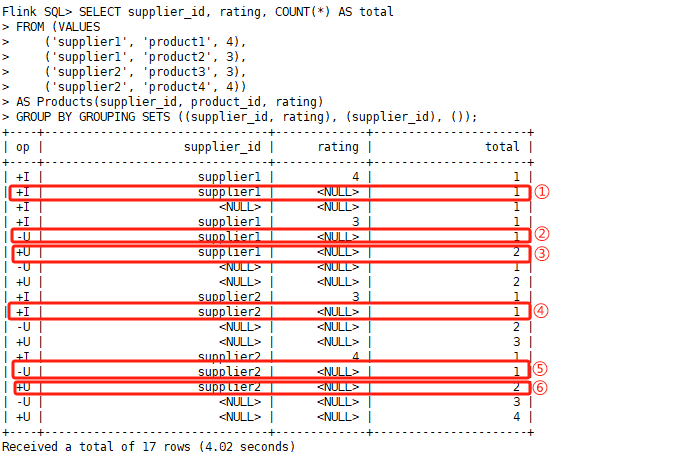
说明:原表中有四条数据,分别由2个供应商,4种产品,可以看到SQL中三种group by组合都会输出,并且没有被groupby的字段显示未NULL。这里以(supplier_id)为例子来说明,只group by字段supplier_id,说明是统计每个供应商供应产品的数量
1)当第一条数据 (‘supplier1’, ‘product1’, 4) ,结果显示supplier1供应商供应的产品总量是1,如图中①
2)当第二条数据 (‘supplier1’, ‘product2’, 3),结果显示supplier1供应商供应的产品总量是2,这是一个回撤流,因此图中执行②和③
3)当第三条数据 (‘supplier2’, ‘product3’, 3) ,结果显示supplier2供应商供应的产品总量是1,如图中④
4)当第四条数据 (‘supplier2’, ‘product4’, 4),结果显示supplier2供应商供应的产品总量是2,这是一个回撤流,因此图中执行⑤和⑥
这样就做到一步即可将所有可能得groupby都输出来
1.2.2 ROLLUP
ROLLUP是用于指定常见类型的分组集的简写表示法。它表示给定的表达式列表和列表的所有前缀,包括空列表。简单来说就是grouping sets的分组是每一个groupby都要写出来,比如上面1.2.1中的示例写了3种groupby方式是有规则,就是层次递减的方式;而ROLLUP就可以实现简写方式,上面的SQL可以简写为如下:
SELECT supplier_id, rating, COUNT(*)
FROM (VALUES('supplier1', 'product1', 4),('supplier1', 'product2', 3),('supplier2', 'product3', 3),('supplier2', 'product4', 4))
AS Products(supplier_id, product_id, rating)
GROUP BY ROLLUP (supplier_id, rating)
说明:上面SQL只写了一个(supplier_id, rating)分组,但是它会从(supplier_id, rating)开始,一个个减少右边字段,直到最后为空。因此效果和GROUPING SETS ((supplier_id, rating), (supplier_id), ())是一致的。
1.2.3 CUBE
CUBE是另外一种用于指定常见类型的分组集的简写表示法。它表示给定的列表及其所有可能的子集 - 幂集。也就是如果你写如下SQL:
SELECT supplier_id, rating, product_id, COUNT(*)
FROM (VALUES('supplier1', 'product1', 4),('supplier1', 'product2', 3),('supplier2', 'product3', 3),('supplier2', 'product4', 4))
AS Products(supplier_id, product_id, rating)
GROUP BY CUBE (supplier_id, rating, product_id)
它相当于将supplier_id, rating, product_id所有的组合都作为groupby,相当于如下使用grouping sets的写入:
SELECT supplier_id, rating, product_id, COUNT(*)
FROM (VALUES('supplier1', 'product1', 4),('supplier1', 'product2', 3),('supplier2', 'product3', 3),('supplier2', 'product4', 4))
AS Products(supplier_id, product_id, rating)
GROUP BY GROUPING SET (( supplier_id, product_id, rating ),( supplier_id, product_id ),( supplier_id, rating ),( supplier_id ),( product_id, rating ),( product_id ),( rating ),( )
)
2 聚合类算子
2.1 count/min/max/sum/avg
在FlinkSQL中的聚合函数跟关系型数据库的聚合函数基本一致。这里和 Data Strem API 的聚合有一小点不同,Data Strem API 的聚合后的那条数据会保留没有被聚合的字段,而FlinkSQL在写没有聚合字段在Select中则会报错。因此FlinkSQL就不存在minBy、maxBy的聚合函数。
示例说明:假设是一个来自服务器cpu的日志,日志格式是“服务器id,cpu,时间”,使用DataGen作为源算子生成的;将通过服务器id对数据进行groupby分组,并输出id和cpu平均值
1)创建源算子表log:基于DataGen连接器,创建log表
CREATE TABLE log(id INT,cpu DOUBLE,ts INT
) WITH ('connector' = 'datagen','rows-per-second'='1','fields.id.kind'='random','fields.id.min'='1','fields.id.max'='5','fields.cpu.kind'='random','fields.cpu.min'='1','fields.cpu.max'='100','fields.ts.kind'='sequence','fields.ts.start'='1','fields.ts.end'='100000'
);
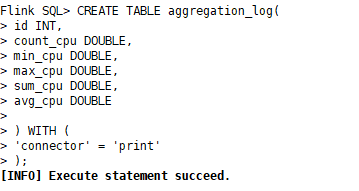
2)创建输出算子表aggregation _log:基于print连接器,创建avg_log表
CREATE TABLE aggregation_log(id INT,count_cpu DOUBLE,min_cpu DOUBLE,max_cpu DOUBLE,sum_cpu DOUBLE,avg_cpu DOUBLE) WITH (
'connector' = 'print'
);
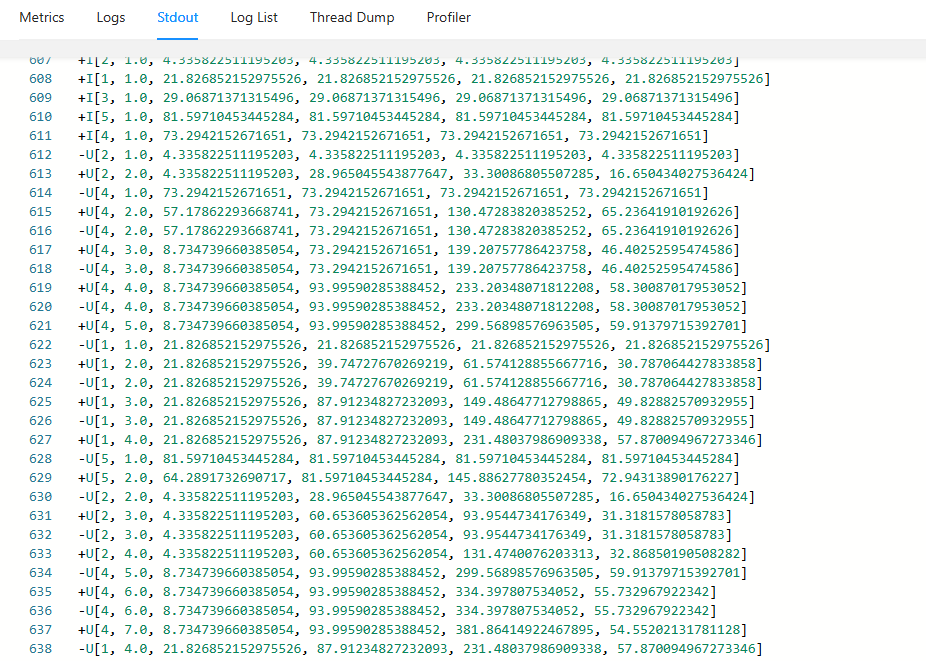
3)执行聚合操作:通过insert语句,结合group by和聚合函数,实现将log表数据插入到aggregation_log表
insert into aggregation_log select id,count(cpu),min(cpu),max(cpu),sum(cpu),avg(cpu) from log group by id;

4)查看结果:上面可以看到执行insert操作,则生成一个job任务。这里可以通过web-ui控制台查看执行结果
结语:本章先讲解group by的功能,再基于group by的简单聚合函数进行演示说明。接下来一章还是讲聚合函数。但是是FlinkSQL特有的一个OVER函数,也成为“开窗函数”,虽然还没有讲到FlinkSQL如何设置窗口,但是OVER函数并不会与窗口冲突,它更像是SQL特有的窗口语法。