AI Engine Kernel and Graph Programming--知识分享9
流数据API
数据流图内核对无限长的类型值序列的数据流进行操作。这些数据流可以被分成单独的块,这些块由内核处理。内核消耗输入数据块并产生输出数据块。内核还可以以逐个样本的方式访问数据流。这两种情况下的数据访问API将在本章中介绍。注:本章中描述的数据移动API适用于矢量和标量、有符号和无符号数据。但是,请注意,AI引擎架构仅支持8位数据类型aie::vector<uint8,16>、aie::vector<uint8,32>、aie::vector <uint8,64>、aie::vector <uint8,128>的无符号整数向量运算。但对于标量算术,支持所有标准的C无符号整数数据类型unsigned char(uint8),unsigned short(uint16),unsigned int(uint32),unsigned long long(uint64)。
数据存取机制
基于流的访问
对于基于流的访问模型,内核接收类型化数据的输入流或输出流作为参数。对这些流的每次访问是同步的,即,如果数据在流中不可用,则读取暂停;如果流不能接受新数据,则写入暂停。AI引擎支持两个id=0或1的32位输入流端口和两个id=0或1的32位输出流端口。此ID作为参数提供给流对象构造函数。AI引擎编译器在内核的参数列表中从左到右自动分配输入和输出流端口ID。映射到同一AI引擎的多个内核不允许共享流端口,除非流是分组交换的(参见显式分组交换)。
public:
input_plio din;
output_plio dout;
adf::kernel k0,k1;
...
connect <stream> (din.out[0], k1.in[0]);
connect <stream> (k1.out[0], k2.in[0]);
connect <stream> (k2.out[0], dout.in[0]);在一个AI引擎的累加器寄存器和物理上相邻的核之间还有一个直接的流通信通道,称为级联。级联流在AI引擎阵列内以蛇形线性方式从AI引擎处理器连接到处理器。
connect <cascade> (k1.out[1], k2.in[1]);流数据结构由AI引擎编译器从数据流图连接自动推断,并在实现图控件的包装器代码中自动声明。内核函数只对作为参数传递给它们的流数据结构的指针进行操作。在数据流图或内核程序中不需要声明这些流数据结构。
用于多速率处理的流连接
如果没有用户规范,多速率分析在涉及流和分组流连接时不是一件容易的事情。使用约束指定内核将从输入流或pktstream输入中读取多少样本,以及内核将向流或pktstream输出中写入多少样本,如下所示:
// constraint to specify samples per iteration for stream/pktstream ports
to support multirate connections
constraint<uint32_t> samples_per_iteration(adf::port<adf::input>& p);
constraint<uint32_t> samples_per_iteration(adf::port<adf::output>& p);constraint关键字需要样本数据类型作为模板值,函数samples_per_iteration应用于内核的输入或输出。相关流可以连接到缓冲区的另一个流。
注意:多速率分析过程仅计算指定了adf::samples_per_iteration(>0)的stream/pktstream端口的速率。
内核的流操作
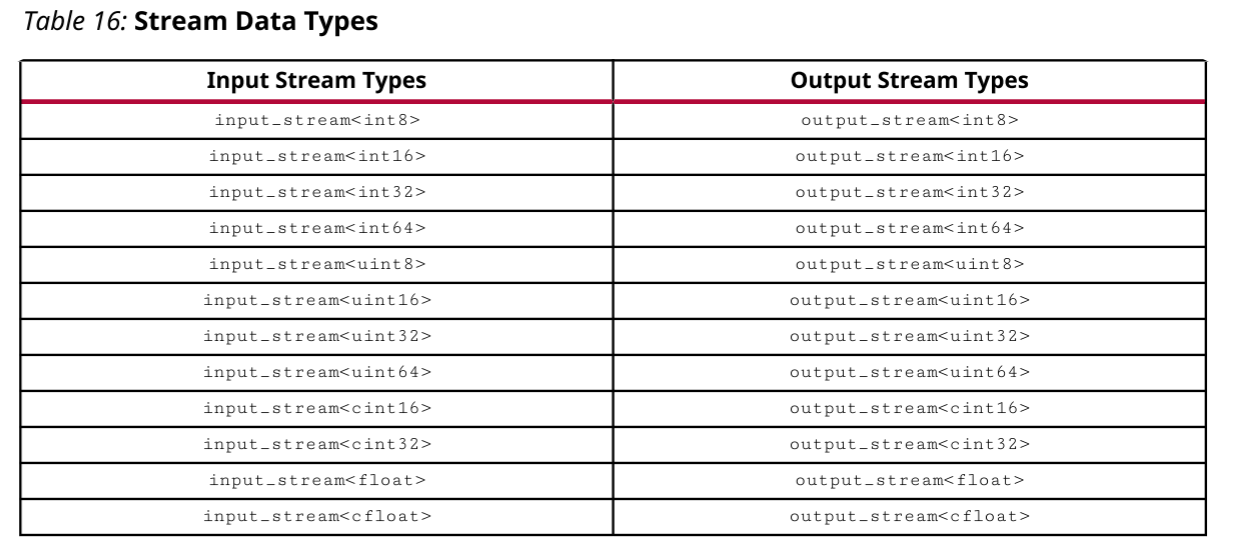
流数据类型
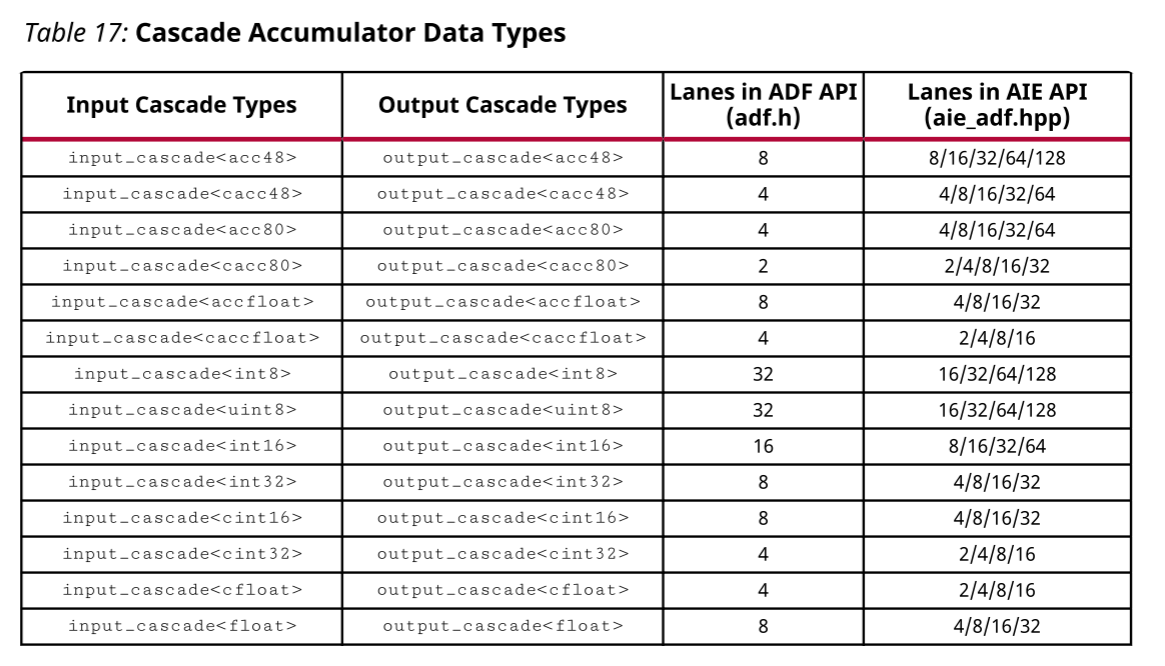
表中的每种数据类型都可以作为标量或向量组从AI引擎中读取或写入。但是,基于AI引擎到可编程逻辑接口端口或通过流交换机网络支持的总线数据宽度,对有效分组有某些限制。AI引擎内核的有效组合是总计高达32位或128位的向量束。累加器数据类型仅用于指定相邻AI引擎之间的级联流连接。其有效分组基于两个处理器之间的384位宽级联通道。
输入和输出级联数据类型可以在AI Engine API或ADF API的上下文中使用。AMD建议使用AI引擎API,因为它支持更大范围的通道。要使用AI引擎API,请<aie_adf.hpp>在内核源代码中包含#include。
ADF API支持有限数量的通道。要使用ADF API,请<adf.h>在内核源代码中包含#include。ADF API用于使用内部调用进行高级内核编程。
 阅读和推进输入流
阅读和推进输入流
AI引擎操作
以下操作从给定的输入流中读取数据,并在AI引擎上推进该流。由于AI引擎上有两个输入流端口,因此AI引擎编译器自动进行物理端口分配,并作为流数据结构的一部分进行传输。流中的数据值可以一次读取一个,也可以作为向量读取。在后一种情况下,除非所有值都存在,否则流操作将停止。数据分组基于基础的单周期、32位流操作或4周期、128位宽流操作。级联连接并行读取所有累加器值。
//Scalar operations
//#include<aie_adf.hpp> or #include<adf.h>
int32 readincr(input_stream<int32> *w);
uint32 readincr(input_stream<uint32> *w);
cint16 readincr(input_stream<cint16> *w);
float readincr(input_stream<float> *w);
cfloat readincr(input_stream<cfloat> *w);
//AIE API Operations to read vector data which supports more vector lanes
//#include<aie_adf.hpp>
aie::vector<int8,16> readincr_v<16>(input_stream<int8> *w);
aie::vector<uint8,16> readincr_v<16>(input_stream<uint8> *w);
aie::vector<int16,8> readincr_v<8>(input_stream<int16> *w);
aie::vector<cint16,4> readincr_v<4>(input_stream<cint16> *w);
aie::vector<int32,4> readincr_v<4>(input_stream<int32> *w);
aie::vector<cint32,2> readincr_v<2>(input_stream<cint32> *w);
aie::vector<float,4> readincr_v<4>(input_stream<float> *w);
template<typename T,int N>
aie::accum<T,N> readincr_v<N>(input_cascade<T> *w);
template<typename T,int N>
aie::vector<T,N> readincr_v<N>(input_cascade<T> *w);
//ADF API Operations to read vector data which supports limited vector lanes
//#include<adf.h>
v8acc48 readincr_v8(input_cascade<acc48>* str);
v4acc80 readincr_v4(input_cascade<acc80>* str);
v8accfloat readincr_v8(input_cascade<accfloat>* str);
v4cacc48 readincr_v4(input_cascade<cacc48>* str);
v2cacc80 readincr_v2(input_cascade<cacc80>* str);
v4caccfloat readincr_v4(input_cascade<caccfloat>* str);
v32int8 readincr_v32(input_cascade<int8>* str);
v32uint8 readincr_v32(input_cascade<uint8>* str);
v16int16 readincr_v16(input_cascade<int16>* str);
v8cint16 readincr_v8(input_cascade<cint16>* str);
v8int32 readincr_v8(input_cascade<int32>* str);
v4cint32 readincr_v4(input_cascade<cint32>* str);
v8float readincr_v8(input_cascade<float>* str);
v4cfloat readincr_v4(input_cascade<cfloat>* str);注意:为了指示流的结束,readincr API可以与TLAST参数一起使用,如下所示。
int32 readincr(input_stream<int32> *w, bool &tlast);写入和推进输出流
AI引擎操作
以下操作将数据写入给定的输出流,并在AI引擎上推进该流。由于AI引擎上有两个输出流端口,因此AI引擎编译器自动进行物理端口分配,并作为流数据结构的一部分进行传输。数据值可以一次写入一个输出流,也可以作为向量写入。在后一种情况下,直到所有值都被写入,流操作才会停止。数据分组基于基础的单周期、32位流操作或4周期、128位宽流操作。级联连接并行写入所有值。
//Scalar operations
//#include<aie_adf.hpp> or #include<adf.h>
void writeincr(output_stream<int32> *w, int32 v);
void writeincr(output_stream<int64> *w, int64 v);
void writeincr(output_stream<uint32> *w, uint32 v);
void writeincr(output_stream<cint16> *w, cint16 v);
void writeincr(output_stream<cint32> *w, cint32 v);
void writeincr(output_stream<float> *w, float v);
void writeincr(output_stream<cfloat> *w, cfloat v);
//AIE API Operations to read vector data which supports more vector lanes
//#include<aie_adf.hpp>
void writeincr(output_stream<int8> *w, aie::vector<int8,16> &v);
void writeincr(output_stream<uint8> *w, aie::vector<uint8,16> &v);
void writeincr(output_stream<int16> *w, aie::vector<int16,8> &v);
void writeincr(output_stream<cint16> *w, aie::vector<cint16,4> &v);
void writeincr(output_stream<int32> *w, aie::vector<int32,4> &v);
void writeincr(output_stream<cint32> *w, aie::vector<cint32,2> &v);
void writeincr(output_stream<float> *w, aie::vector<float,4> &v);
template<typename T,int N>
void writeincr(output_cascade<T> *w, aie::accum<T,N> &v);
template<typename T,int N>
void writeincr(output_cascade<T> *w, aie::vector<T,N> &v);
//ADF API Operations to read vector data which supports limited vector lanes
//#include<adf.h>
void writeincr(output_cascade<acc48>* str,v8acc48 value);
void writeincr(output_cascade<acc80>* str,v4acc80 value);
void writeincr(output_cascade<cacc48>* str,v4cacc48 value);
void writeincr(output_cascade<cacc80>* str,v2cacc80 value);
void writeincr(output_cascade<accfloat>* str,v8accfloat value);
void writeincr(output_cascade<caccfloat>* str,v4caccfloat value);
void writeincr(output_cascade<int8>* str,v32int8 value);
void writeincr(output_cascade<uint8>* str,v32uint8 value);
void writeincr(output_cascade<int16>* str,v16int16 value);
void writeincr(output_cascade<cint16>* str,v8cint16 value);
void writeincr(output_cascade<int32>* str,v8int32 value);
void writeincr(output_cascade<cint32>* str,v4cint32 value);
void writeincr(output_cascade<float>* str,v8float value);
void writeincr(output_cascade<cfloat>* str,v4cfloat value);注意:为了指示流的结束,writeincr API与TLAST参数一起使用,如下所示。
void writeincr(output_stream<int32> *w, int32 value, bool tlast);数据包流操作

提供了两种附加的流数据类型以表征由若干不同流的分组化交织组成的流数据。当程序中的独立数据流数量超过可用的硬件流通道或端口数量时,这些数据类型非常有用。此机制在Explicit Packet Switching中有更详细的描述。
数据包流阅读和写
数据分组由一个字(32位)分组报头组成,后面是一定数量的数据字,其中最后一个数据字具有用信号通知分组结束的TLAST字段。以下操作用于读取和推进输入数据包流以及写入和推进输出数据包流。
int32 readincr(input_pktstream *w);
int32 readincr(input_pktstream *w, bool &tlast);
void writeincr(output_pktstream *w, int32 value);
void writeincr(output_pktstream *w, int32 value, bool tlast);如果数据包大小不固定,带有TLAST参数的API有助于读取或写入数据包结束条件。如果分组报头字具有等于真的边带TLAST,则这发信号通知分组完成并且分组中没有更多的数据,也就是说,分组仅具有分组报头。
分组处理
数据包的第一个32位字必须始终是数据包报头,它对下表所示的几个位字段进行编码。

包ID由编译器根据路由要求分配。在图中,pktsplit输出索引或pktmerge输入索引可能与分配的数据包ID不同。例如,下图显示了pktsplit的编译结果:

从上面的图形视图中,pktsplit输出的索引首先显示,然后是相应的数据包ID。因此,在AI Engine内核中,应该通过getPacketid API查询数据包ID,以确保代码在不同的编译中有效。数据包类型可以是您要插入以标识数据包类型的任何3位模式。源行和源列表示数据包源自的AI引擎图块坐标。按照惯例,源自可编程逻辑(PL)的分组的源行和源列是-1,-1。您有责任在每个数据包的开头构造并发送适当的数据包报头。在接收端,需要在阅读数据之前接收和解码数据包报头。以下操作有助于在AI引擎内核中组装或拆卸数据包报头。
void writeHeader(output_pktstream *str, unsigned int pcktType, unsigned int ID);
void writeHeader(output_pktstream *str, unsigned int pcktType, unsigned int ID, bool tlast);
uint32 getPacketid(input_pktstream *w, int index);
uint32 getPacketid(output_pktstream *w, int index);writeHeader API允许用给定的packet ID和packet类型组装packet header,而packet ID应该在内核中用getPacketid API查询。源行和源列将使用执行此API的AI引擎图块的坐标自动插入。getPacketid API允许在输入或输出包流数据结构上查询编译器分配的包ID。索引参数指的是图规范中的拆分或合并分支边。下面的示例使用getPacketid API查询输出数据包流上的数据包ID。可以使用writeHeader API将该ID写入输出数据包流。
void aie_core1(...,output_pktstream *out){
//Get ID from output pktstream, index=0
uint32 ID=getPacketid(out,0);
//Generate header for output
writeHeader(out,pktType,ID);
......精彩文章,请关注订阅号:威视锐科技