字符串和内存函数(2)
#define _CRT_SECURE_NO_WARNINGS
#include<stdio.h>
#include<string.h>
#include<assert.h>
#include<stdlib.h>
1.10 strerror
char* strerror(int errnum);
返回错误码,所对应的错误信息。
/* strerror example : error list */
#include <stdio.h>
#include <string.h>
#include <errno.h>//必须包含的头文件
int main()
{
FILE* pFile;
pFile = fopen("unexist.ent", "r");
if (pFile == NULL)
printf("Error opening file unexist.ent: %s\n", strerror(errno));
//errno: Last error number
return 0;
}
字符转换:
int tolower(int c);
int toupper(int c);
/* isupper example */
#include <stdio.h>
#include <ctype.h>
int main()
{
int i = 0;
char str[] = "Test String.\n";
char c;
while (str[i])
{
c = str[i];
if (isupper(c))
c = tolower(c);
putchar(c);
i++;
}
return 0;
}
C语言的库函数,在运行时若发生错误,就会将错误码存在一个变量中,这个变量就是 errno。
其中,错误码通常都是数字,如:1 2 3 4 5 等等
由于其无法直观的被理解,则我们就需要将这些错误码翻译成我们能直接看懂的错误信息。
那么,这一步骤应该如何实现呢?
这里我们就要用到这样一个函数了:
strerror
char* strerror(int errnum);
get points to error message string
函数头文件为:<string.h>
因为每一个错误码都对应着一个错误信息,而函数 strerror :只要给它传递一个 int 类型的数字,它就能返回其所对应的错误信息的起始地址(错误码对应的错误信息字符串的首地址),返回类型为 char* 。
如以下代码所示:
#include<stdio.h>
#include<string.h>
int main()
{
printf("%s\n", strerror(0));//No error
printf("%s\n", strerror(1));//Operation not permitted 操作被拒绝
printf("%s\n", strerror(2));//No such file or directory 没有这样的文件或文件夹
printf("%s\n", strerror(3));//No such process 没有这个进程
printf("%s\n", strerror(4));//Interrupted function call 函数调用被中断
printf("%s\n", strerror(5));//Input / output error 输入/输出错误
printf("%s\n", strerror(6));//No such device or address 设备不存在或地址无效
return 0;
}
在这段代码中,strerror函数分别返回了错误码 0,1,2,3,4,5,6 代表的错误信息的 字符串 的 首地址。
在实际工程中,这些错误码我们是并不知道的(这里仅是用0,1,2,3,4,5,6举例)。
这个函数函数应该怎么用呢?
正如前文所言,strerror 函数也会在运行过程中发生错误时,就会将错误码存在一个变量中,这个变量就是 errno。
接下来我们将通过以下代码来展开讲解:
#include<stdio.h>
#include<string.h>
//补充
//fopen
//FILE * fopen(const char* filename,const char* mode);
// 文件名 打开方式
//如果打开文件成功,就返回一个有效指针;
//如果打开文件失败,就返回一个NULL指针。
//头文件为:<stdio.h>
int main()
{
//打开文件
FILE* pf = fopen("text.txt", "r");//text.txt 文件名,r 打开方式
//注意:如果没有指定路径的话,系统就会默认为当前工程的路径底下。
if (pf == NULL)
{
printf("打开文件失败\n");
return 1;
}
//读文件
//关闭文件
fclose(pf);
return 0;
}
//这里打印结果只能显示"打开文件失败",但这里又是为什么打印结果是"打开文件失败"呢?
//是访问权限不够呢?还是文件不存在呢?还是其他方面的原因?
//单从这段代码来看我们无从得知。
因此,这里就要用到前面所提及的 strerror 函数。
故,我们需要进行如下修改:
#include<stdio.h>//printf、fopen、fclose 头文件
#include<string.h>//strerror、perror 头文件
#include<errno.h>//errno 头文件
int main()
{
//打开文件
FILE* pf = fopen("text.txt", "r");
if (pf == NULL)
{
printf("%s\n", strerror(errno));
//通过 错误码 通过 strerror 函数 将 具体错误信息 打印出来
//错误码 则是 来自 errno
//要使用 errno 这个全局变量,要记得包含其头文件 <errno.h>
return 1;
}
//读文件
//关闭文件
fclose(pf);
return 0;
}
拓展
perror
打印错误信息
void perror(const char* str);
头文件为:<string.h>
应用
#include<stdio.h>
int main()
{
FILE* pf = fopen("text.txt", "r");
if (pf == NULL)
{
perror("fopen");
return 1;
}
fclose(pf);
return 0;
}
总结:
perror 是直接打印错误信息,在打印错误信息之前,会先打印自定义的信息。如下图所示:
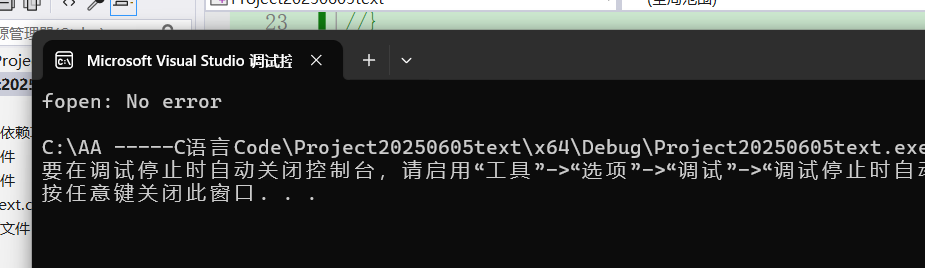

我们也可以认为:perror = printf + strerror
字符分类函数
① islower
int islower(int c);
头文件:<ctype.h>
判断字符是否是小写字母 a~z Check if character is lowercase letter.
如果是小写字母,函数则返回一个非0数字;
如果不是小写字母,函数则返回 0。
#include<stdio.h>
#include<ctype.h>
int main()
{
int ret = islower('a');
printf("%d\n", ret);
return 0;
}
② isdigit
int isdigit(int c);
头文件:<ctype.h>
判断字符是否是十进制数字字符 0~9 Check if character is decimal digit.
如果是数字字符,函数则返回一个非0数字;
如果不是数字字符,函数则返回 0。
#include<stdio.h>
#include<ctype.h>
int main()
{
int ret = isdigit('3');
printf("%d\n", ret);
return 0;
}
③isupper
int isupper(int c);
头文件:<ctype.h>
判断字符是否是大写字母A~Z
如果是大写字母,函数则返回一个非0数字;
如果不是大写字母,函数则返回 0。
/* isupper example */
#include <stdio.h>
#include <ctype.h>
int main()
{
int i = 0;
char str[] = "Test String.\n";
char c;
while (str[i])
{
c = str[i];
if (isupper(c))
c = tolower(c);
putchar(c);
i++;
}
return 0;
}
字符转换
只针对字母
tolower(int c);//大写字母转小写
toupper(int c);//小写字母转大写
//传字符或ASCII码值都可以(传字符就是传的对应的ASCII码值)
头文件为:<ctype.h>
应用
tolower
int main()
{
printf("%c\n", tolower('S'));
return 0;
}
toupper
int main()
{
printf("%c\n", toupper('a'));
return 0;
}
功能展示:
将字符串完全转换成大写 / 小写
Chen Xianglin PKU
方法一 :
int main()
{
char arr[] = "Chen Xianglin PKU";
int i = 0;
while (arr[i])
{
if (isupper(arr[i]))
{
printf("%c", tolower(arr[i]));
//注意:这里并没有改掉arr[]内的元素,只是在将是arr[]内的大写字母转换成对应的
// 小写字母,并将其返回来。
//同理,toupper 函数 也无法修改字符串内容。
}
else
{
printf("%c", arr[i]);
}
i++;
}
return 0;
}
方法二:
int main()
{
char arr[] = "Chen Xianglin PKU";
int i = 0;
while (arr[i])
{
if (isupper(arr[i]))
{
arr[i] = tolower(arr[i]);
}
printf("%c", arr[i]);
i++;
}
return 0;
}
总结:
①字符分类函数
函数 如果他的参数符合下列条件就返回真
iscntrl 任何控制字符
isspace 空白字符:空格‘ ’,换页‘\f’,换行'\n',回车‘\r’,制表符'\t'或者垂直制表符'\v'
isdigit 十进制数字 0~9
isxdigit 十六进制数字,包括所有十进制数字,小写字母a~f,大写字母A~F
islower 小写字母a~z
isupper 大写字母A~Z
isalpha 字母a~z或A~Z
isalnum 字母或者数字,a~z, A~Z, 0~9
ispunct 标点符号,任何不属于数字或者字母的图形字符(可打印)
isgraph 任何图形字符
isprint 任何可打印字符,包括图形字符和空白字符
②字符转换函数
int tolower(int c);
int toupper(int c);
③两类函数的头文件皆为:<ctype.h>。
④两类函数都是针对字符的。
针对内存
Memcpy
Memmove
Memcmp
Memset
1.11 memcpy
void* memcpy(void* destination, const void* source, size_t num);
//void*:不知道拷贝类型、返回类型是什么,因此用 void*。
//num:拷贝字节数。
函数memcpy从source的位置开始向后复制num个字节的数据到destination的内存位置。
这个函数在遇到 '\0' 的时候并不会停下来。
如果source和destination有任何的重叠,复制的结果都是未定义的。
由此可知,其与strcpy的用法有所差异:
strcpy —— 仅用于字符串拷贝
memcpy —— 可用于多种类型的数据拷贝
/* memcpy example */
#include <stdio.h>
#include <string.h>
struct {
char name[40];
int age;
} person, person_copy;
int main()
{
char myname[] = "Pierre de Fermat";
/* using memcpy to copy string: */
memcpy(person.name, myname, strlen(myname) + 1);
person.age = 46;
/* using memcpy to copy structure: */
memcpy(&person_copy, &person, sizeof(person));
printf("person_copy: %s, %d \n", person_copy.name, person_copy.age);
return 0;
}
示例:
#include<stdio.h>
#include<string.h>
int main()
{
int arr1[] = { 0,1,2,3,4,5,6,7,8,9 };
int arr2[10] = { 0 };
memcpy(arr2, arr1, 20);//20/sizeof(int)=5
for (int i = 0; i < 10; i++)
{
printf("%d ", arr2[i]);
}printf("\n");
//0 1 2 3 4 0 0 0 0 0
memcpy(arr2, &arr1[3], 20);
for (int i = 0; i < 10; i++)
{
printf("%d ", arr2[i]);
}printf("\n");
//3 4 5 6 7 0 0 0 0 0
memcpy(arr2, arr1 + 3, 20);
//arr1+3:数组名=数组首元素地址,arr1+3=数组内下标为3的元素的地址:&arr[3]
for (int i = 0; i < 10; i++)
{
printf("%d ", arr2[i]);
}printf("\n");
//3 4 5 6 7 0 0 0 0 0
memcpy(arr2, arr1 + 3, 17);
//07 00 00 00 —— 只拷贝了 前面三个元素 和 07
//07 和 原 arr2 数组中的对应元素的 后三个字节相结合,组成新的 7。
for (int i = 0; i < 10; i++)
{
printf("%d ", arr2[i]);
}printf("\n");
//3 4 5 6 7 0 0 0 0 0
return 0;
}
memcpy的模拟实现——my_memcpy
方法一:
#include<stdio.h>
#include<assert.h>
void* my_memcpy(void* dest, const void* src, size_t num)
{
assert(dest && src);
void* ret = dest;
assert(ret);
while (num--)
//num 初始为 20,num-- 返回 20(判断为真),然后 num 立即变为 19
{
*(char*)dest = *(char*)src;
//dest 仍是 void* 类型、src仍是 const void* 类型
//错误代码:
//①
//dest++, src++;
//错误原因:
//注意前面 (char*) 强制类型转换只进行了一次
//②
//(char*)dest++,(char*)src++;
//错误原因:
//①如在这段代码中:int* dest=&p;(char*)dest++;
// C语言中,dest是不是只强制类型转换了一次。
// 且在++之后,dest跳过了4个字节,然后对++前的dest进行强制类型转换,
// 而++后的dest仍然是int*类型的。
//②将 dest++ 返回的原始值(指针)转换为 char* 类型。
//③转换仅发生一次,且仅作用于 dest++ 的返回值(原始地址值)。
//④由于 ++ 与 (char*) 的优先级都属于第二优先级,结合方式 为 从右到左。
//⑤执行顺序是:先执行 dest++,再对递增前的原始值进行强制类型转换。
//⑥ dest 在 强转 前为 void* 类型,因此 ++ 不合法。
dest = (char*)dest + 1, src = (char*)src + 1;
//dest仍是void* 类型、src仍是 const void* 类型
}
return ret;
//注意:
//函数返回类型是 void* ,不是 void 类型。
}
int main()
{
int arr1[] = { 0,1,2,3,4,5,6,7,8,9 };
int arr2[10] = { 0 };
my_memcpy(arr2, arr1 + 3, 20);
for (size_t i = 0; i < sizeof(arr2) / sizeof(arr2[i]); i++)
{
printf("%d ", arr2[i]);
}//3 4 5 6 7 0 0 0 0 0
return 0;
}
拓展:
分析以下这两段代码是否正确:
①
void my_memcpy(void* dest, const void* src, size_t num)
{
assert(dest && src);
*(char*)dest = *(char*)src;
dest = (char*)dest + 1, src = (char*)src + 1;
}
②
void my_memcpy(int* dest, const int* src, size_t num)
{
assert(dest && src);
*(char*)dest = *(char*)src;
dest = (char*)dest + 1, src = (char*)src + 1;
}
分析:
第一段代码:使用 void* 参数
void my_memcpy(void* dest, const void* src, size_t num) {
assert(dest && src);
*(char*)dest = *(char*)src;
dest = (char*)dest + 1; // ✅ 合法
src = (char*)src + 1; // ✅ 合法
}
正确性分析:
1. 拷贝操作:✅ 正确
拷贝1字节数据(语法正确)
2. 指针移动:
o dest = (char*)dest + 1:✅ 合法
void* 可以接受任何指针类型的赋值(包括 char* )
o src = (char*)src + 1:✅ 合法
const void* 可以接受 char* 赋值(C标准允许)
3. 类型安全性:✅ 安全
所有类型转换和赋值都符合C标准
4. 问题:
o 缺少循环,只能拷贝1字节(功能不完整)
o 参数是值传递,修改不会影响调用者的指针
第二段代码:使用 int* 参数
void my_memcpy(int* dest, const int* src, size_t num) {
assert(dest && src);
*(char*)dest = *(char*)src; // ✅ 正确
dest = (char*)dest + 1; // ❌ 错误
src = (char*)src + 1; // ❌ 错误
}
正确性分析:
1. 拷贝操作:✅ 正确
拷贝1字节数据(语法正确)
2. 指针移动:
o dest = (char*)dest + 1:❌ 编译错误
右边是 char* 类型
左边是 int* 类型
不能将 char* 赋给 int* (类型不兼容)
o src = (char*)src + 1:❌ 编译错误
右边是 char* 类型
左边是 const int* 类型
类型不兼容 + const 限定符问题
3. 类型安全性:❌ 危险
o 试图将字节指针赋给整型指针
o 可能导致未定义行为(内存对齐问题)
关键对比:
特性 void* 版本 int* 版本
编译结果 ✅ 成功编译 ❌ 编译失败(类型错误)
dest 移动 ✅ 合法(void * 接受任何指针) ❌ 错误(char * → int* )
src 移动 ✅ 合法 ❌ 错误(char * → const int* )
类型安全性 ✅ 安全 ❌ 危险
参数通用性 ✅ 高(接受任意指针) ❌ 低(仅接受 int 指针)
标准符合性 ✅ 完全符合 C 标准 ❌ 违反类型规则
为什么第二段代码错误?
1. 类型系统冲突:
C语言禁止在不同类型指针间直接赋值(除了 void* 的特定情况)
2. 内存对齐风险:
int* dest = ...;
dest = (char*)dest + 1; // 现在 dest 可能指向未对齐地址
o 访问未对齐的 int* 指针在某些架构上会导致崩溃(如ARM)
o 属于未定义行为
3. const 正确性破坏:
o 将非const的 char* 赋给 const int* 违反类型限定规则
o 在第一段代码中,无论是const void* 还是void * ,都是可以接收任意类型的指针的
方法二:
#include<stdio.h>
#include<assert.h>
void* my_memcpy(void* dest, const void* src, size_t num)
{
assert(dest && src);
void* ret = dest;
assert(ret);
while (num--)
{
*(char*)dest = *(char*)src;
++(char*)dest, ++(char*)src;
//对比(char*)dest++,(char*)src++;,其正确的原因:
//①执行顺序是:先执行 ++dest,再对递增后的值进行强制类型转换。
//②在表达式 ++(char*)dest; 中,++ 操作的是 (char*)dest 的返回值(临时结果),
// 而不是直接操作 dest 变量本身。
}
return ret;
}
int main()
{
int arr1[] = { 0,1,2,3,4,5,6,7,8,9 };
int arr2[10] = { 0 };
my_memcpy(arr2, arr1 + 3, 20);
for (size_t i = 0; i < sizeof(arr2) / sizeof(arr2[i]); i++)
{
printf("%d ", arr2[i]);
}//3 4 5 6 7 0 0 0 0 0
return 0;
}
思考:
如果要将 arr1[] 中的前五个元素——0 1 2 3 4,拷贝到第四个元素到第八个元素这一段,用表达式:my_memcpy(arr1 + 3, arr1, 20); 可以实现吗?为什么?
示例:
#include<stdio.h>
#include<assert.h>
void* my_memcpy(void* dest, const void* src, size_t num)
{
assert(dest && src);
void* ret = dest;
assert(ret);
while (num--)
{
*(char*)dest = *(char*)src;
++(char*)dest, ++(char*)src;
}
return ret;
}
void test()
{
int arr1[] = { 0,1,2,3,4,5,6,7,8,9 };
my_memcpy(arr1 + 3, arr1, 20);
for (size_t i = 0; i < sizeof(arr1) / sizeof(arr1[i]); i++)
{
printf("%d ", arr1[i]);
}
}
int main()
{
test();
return 0;
}
//打印结果为:
//0 1 2 0 1 2 0 1 8 9
回答:
由上可知,用该表达式无法实现。其原因如下:
因为 arr1[0]~arr1[4] 与 arr1[3]~arr1[7] 两段有重叠部分——arr1[3], arr1[4],
因此,当 arr1[0]、arr1[1] 在赋值给 arr1[3]、arr1[4] 后,两段中的 arr1[3]、arr1[4] 的值均被改变,
3、4 被改成 0、1,也因此在后续的拷贝过程中拷贝的是已经被拷贝过的内容,因此该表达式无法实现。
思考:
既然有重叠的两部分,那又应该如何拷贝呢?
这就要引出我们接下来要学习的函数——memmove了。
1.12 memmove
实现重叠字符串拷贝
void* memmove(void* destination, const void* source, size_t num);
和memcpy的差别就是memmove函数处理的源内存块和目标内存块是可以重叠的。
如果源空间和目标空间出现重叠,就得使用memmove函数处理。
/* memmove example */
#include <stdio.h>
#include <string.h>
int main()
{
char str[] = "memmove can be very useful......";
memmove(str + 20, str + 15, 11);
puts(str);
return 0;
}
示例:
#include<stdio.h>
#include<string.h>
void test()
{
int arr[] = { 0,1,2,3,4,5,6,7,8,9 };
memmove(arr + 3, arr, 20);
for (size_t i = 0; i < sizeof(arr) / sizeof(arr[0]); i++)
{
printf("%d ", arr[i]);
}
}
int main()
{
test();
return 0;
}
memmove 的模拟实现 —— my_memmove
#include<stdio.h>
#include<assert.h>
void* my_memmove(void* dest, const void* src, size_t num)
{
void* ret = dest;
assert(dest && src);
//判断 dest 与 src 的位置
//如果 dest 在 src 的右侧,则 从右往左 拷贝;
//如果 dest 在 src 的左侧,则 从左往右 拷贝。
if (dest < src)
{
// 从左往右 拷贝
while (num--)
{
*(char*)dest = *(char*)src;
++(char*)dest, ++(char*)src;
}
}
else
{
// 从右往左 拷贝
while (num--)
//以第一次循环为例:
//num 初始为 20,num-- 返回 20(判断为真),然后 num 立即变为 19
{
*((char*)dest + num) = *((char*)src + num);
//这里的 dest 和 src 加的 num 都是 19
}
}
return ret;
}
void test()
{
int arr[] = { 0,1,2,3,4,5,6,7,8,9 };
my_memmove(arr + 3, arr, 20);
for (size_t i = 0; i < sizeof(arr) / sizeof(arr[0]); i++)
{
printf("%d ", arr[i]);
}
}
int main()
{
test();
return 0;
}
注意:
在 VS 编译器中,memcpy 也能对重叠字符串进行拷贝。
1.13 memcmp
int memcmp(const void* ptr1,
const void* ptr2,
size_t num);
比较从ptr1和ptr2指针开始的num个字节
返回值如下:
Return Value
Returns an integral value indicating the relationship between the content of the memory blocks :
| return value | indicates |
| < 0 | the first byte that does not match in both memory blocks has a lower value in ptr1 than in ptr2(ifevaluated agunsigned char values) |
| = 0 | the contents of both memory blocks are equal |
| > 0 | the first byte that does not match in both memory blocks has a greater value in ptr1 than in ptr2(ifevaluated as unsiqned char values) |
/* memcmp example */
#include <stdio.h>
#include <string.h>
int main()
{
char buffer1[] = "DWgaOtP12df0";
char buffer2[] = "DWGAOTP12DF0";
int n;
n = memcmp(buffer1, buffer2, sizeof(buffer1));
if (n > 0) printf("'%s' is greater than '%s'.\n", buffer1, buffer2);
else if (n < 0) printf("'%s' is less than '%s'.\n", buffer1, buffer2);
else printf("'%s' is the same as '%s'.\n", buffer1, buffer2);
return 0;
}
示例:
#include<stdio.h>
#include<string.h>
int main()
{
int arr1[] = { 1,2,3 };
int arr2[] = { 1,2,4 };
int ret = memcmp(arr1, arr2, 8);
printf("%d\n", ret);//0
ret = memcmp(arr1, arr2, 9);
printf("%d\n", ret);//-1
int arr3[] = { 1,2,2 };
ret = memcmp(arr1, arr3, 9);
printf("%d\n", ret);//1
return 0;
}
1.14 memset
void* memset(void* ptr, int value, size_t num);
Fill block of memory :
Sets the first num bytes of the block of memory pointed by ptr to the specified value(interpreted as an unsigned char).
内存设置函数:以字节为单位来设置内存中的数据。
Parameters :
| ptr | Pointer to the block of memory to fill. |
| value | Value to be set.The value is passed as an int, but the function fills the block of memory using the unsigned char.conversion of this value. |
| num | Number of bytes to be set to the value.size_t is an unsigned integral type. |
用法:
以字符串 "Welcome to PKU,Christophe." 为例,是否能将其中的前14个全为'P',后面内容不变的字符串?
#include<stdio.h>
#include<string.h>
int main()
{
char arr[] = "Welcome to PKU,Christophe.";
//错误代码:memset(arr, "PKU", 14);
memset(arr, 'P', 14);
printf("%s\n", arr);
memset(arr+15, 'C', 10);
printf("%s\n", arr);
return 0;
}
思考:
以数组 arr[10] = { 0 }; 为例,可否利用 memset 函数,得出表达式 memset(arr, 1, 40); 将数组元素都改为 1 呢?为什么?
#include<stdio.h>
#include<string.h>
int main()
{
int arr[10] = { 0 };
memset(arr, 1, 40);
for (int i = 0; i < 10; i++)
{
printf("%d ", arr[i]);
}
return 0;
}
①回答:
经代码检验可知,该表达式并不能实现我们想要的结果。
②回答:
经代码调试可知,十六进制下,该表达式实际上是使 arr[i] 4个字节的每个字节都由 00 变为 01,因此最终 arr[i] 的结果实际上为:0x01010101
因此,这里就进一步验证了 memset 函数是以字节为单位进行内存数据的设置的。同时,也因此,其第二个参数不宜过大 ( - 255n≤ value ≤ 255n,n为非0整数,当 n != -1 || n != 1时,会发生阶段,因此value不宜过大)。