Flink 系列之二十八- Flink SQL - 水位线和窗口
之前做过数据平台,对于实时数据采集,使用了Flink。现在想想,在数据开发平台中,Flink的身影几乎无处不在,由于之前是边用边学,总体有点混乱,借此空隙,整理一下Flink的内容,算是一个知识积累,同时也分享给大家。
注意:由于框架不同版本改造会有些使用的不同,因此本次系列中使用基本框架是 Flink-1.19.x,Flink支持多种语言,这里的所有代码都是使用java,JDK版本使用的是19。
代码参考:https://github.com/forever1986/flink-study.git
目录
- 1 水位线
- 1.1 水位线 watermark
- 1.2 处理时间的水位线
- 1.2 事件时间的水位线
- 2 窗口
- 2.1 滚动窗口
- 2.1.1 说明
- 2.1.2 示例演示
- 2.2 滑动窗口
- 2.2.1 说明
- 2.2.2 示例演示
- 2.3 会话窗口
- 2.3.1 说明
- 2.3.2 示例演示
- 2.4 累积窗口
- 2.4.1 说明
- 2.4.2 示例演示
- 3 迟到数据策略
前面讲解了关于通过FlinkSQL实现中间算子的语法,本该继续讲解FlinkSQL相关的其它中间算子,但是后面的中间算子可能会涉及到水位线和窗口2个概念,因此这一章先讲解跟流有关的两个概念,这两个概念在Data Stream API中的《系列之十五 - 高级概念 - 窗口》和《系列之十七 - 高级概念 - 事件时间和水位线》讲过,这里主要演示在FlinkSQL中如何定义水位线和窗口。
1 水位线
在《系列之十七 - 高级概念 - 事件时间和水位线》中讲过 处理时间 和 事件时间 ,通过这些时间可以将其定义为 水位线(watermarks) 。 水位线(watermarks) 也是一个数据,也在Flink流中传输,让Flink可以通过它来定义窗口、启动检查点等功能。在FlinkSQL中,也有相应的语法来操作:
1.1 水位线 watermark
关于水位线的概念,这里就不多累述。如果不太记得的朋友,可以去先看看Data Stream API 的《系列之十七 - 高级概念 - 事件时间和水位线》。这里简单说明一下FlinkSQL中定义水位线watermark的语法:
WATERMARK FOR column_name AS column_name - INTERVAL '数字' 时间单位(SECOND/MINUTE/HOUR)
说明:
- 1)其中column_name 就是指定哪个字段为水位线,必须是TIMESTAMP 列和 TIMESTAMP_LTZ 类型
- 2)AS:后面可以设置延迟时间,也就是之前说的处理乱序数据时,可以设置一定延迟
1.2 处理时间的水位线
处理时间(Processing Time):处理时间是指执行相应操作的机器的系统时间。简单来说,就数据到达Flink处理数据所在机器的系统时间。在FlinkSQL 中,定义处理时间语法如下:
CREATE TABLE user_actions (user_name STRING,data STRING,user_action_time AS PROCTIME(),WATERMARK FOR user_action_time AS user_action_time - INTERVAL '5' SECOND
) WITH (...
);
示例演示
示例说明,定义一个自动生成的log表,其ts字段为处理时间
1)定义log表:
CREATE TABLE log(id INT,cpu DOUBLE,ts AS PROCTIME()
) WITH ('connector' = 'datagen','rows-per-second'='1','fields.id.kind'='random','fields.id.min'='1','fields.id.max'='5','fields.cpu.kind'='random','fields.cpu.min'='1','fields.cpu.max'='100'
);
DESC log;

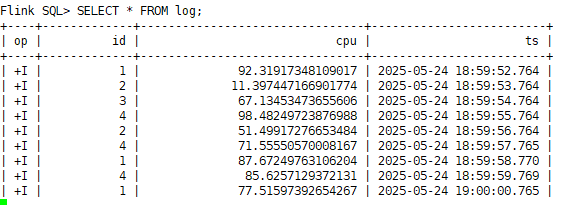
说明:在extras列中可以看到ts有一个标签为PROCTIME标识
2)查询表:
SET sql-client.execution.result-mode=TABLEAU;
SELECT * FROM log;
1.2 事件时间的水位线
事件时间(Event time):事件时间是每个单独事件在其产生设备上发生的时间。这个时间通常在数据进入Flink之前就嵌入到数据记录中,并且可以从每条数据记录中提取事件时间戳。简单来说,就是时间戳是在数据的某个字段,可以自定义选择某个字段作为事件时间。在FlinkSQL 中,定义处理时间语法如下:
CREATE TABLE user_actions (user_name STRING,data STRING,user_action_time TIMESTAMP(3),WATERMARK FOR user_action_time AS user_action_time - INTERVAL '5' SECOND
) WITH (...
);
示例演示
1)定义log表:
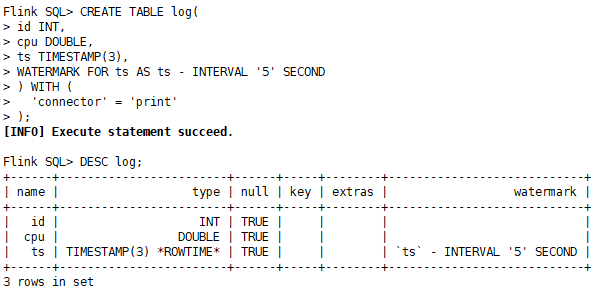
CREATE TABLE log(id INT,cpu DOUBLE,ts TIMESTAMP(3),WATERMARK FOR ts AS ts - INTERVAL '5' SECOND
) WITH ('connector' = 'print'
);
DESC log;
2)往log表插入数据:(注意:print是输出算子,无法使用select)
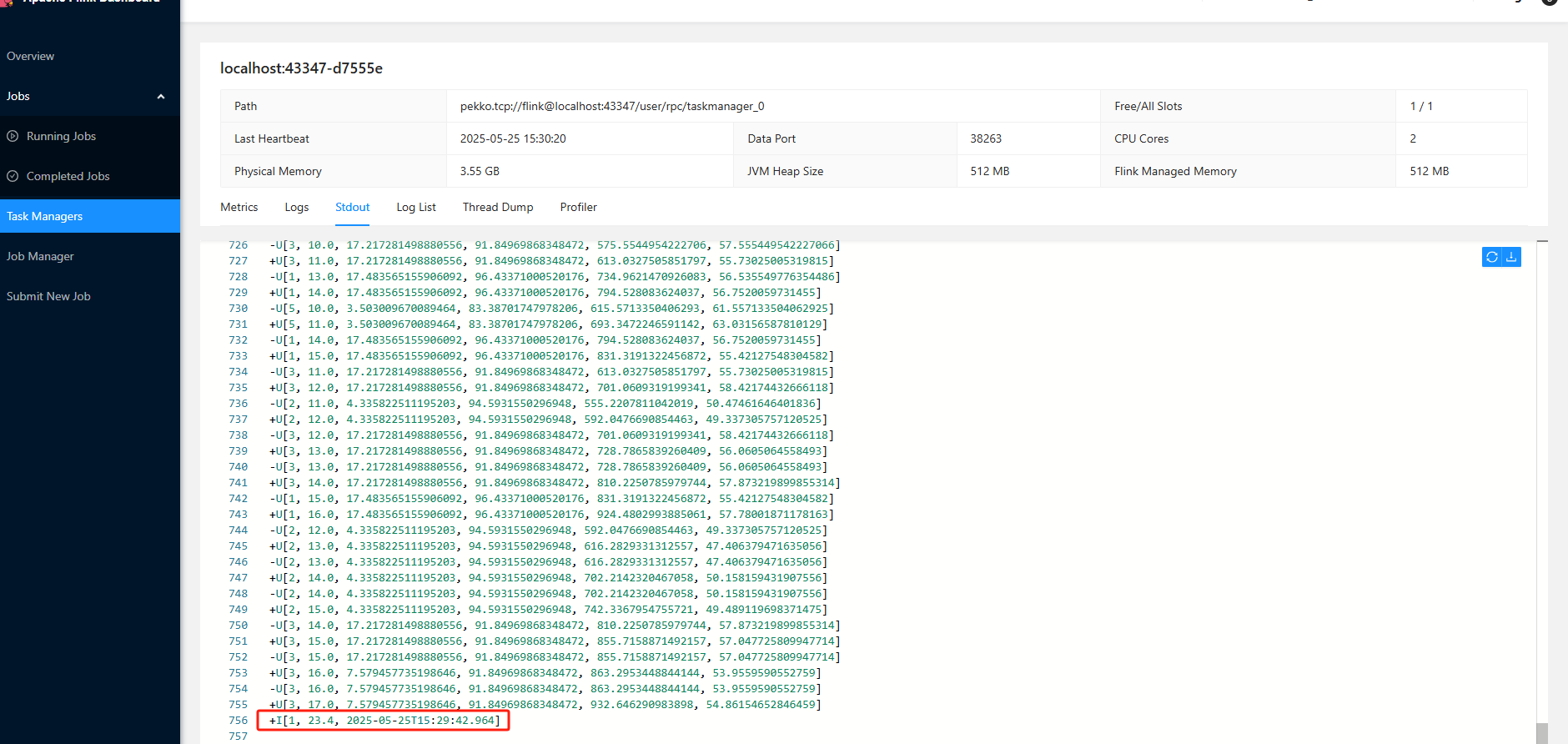
insert into log values(1,23.4,CURRENT_TIMESTAMP );

2 窗口
在前面《系列之十五 - 高级概念 - 窗口》中讲过窗口相关概念,其分类包括时间和计数,以及滚动、滑动和会话窗口等,这里就不累述这些概念。虽然《系列之二十七 - Flink SQL - 中间算子:OVER聚合》也能实现窗口功能,但是要实现滚动、滑动和会话窗口,FlinkSQL还是提供另外和Data Stream API 对应的语法。
注意:
1)在FlinkSQL中只提供时间类型的窗口,不支持计数类型的窗口
2)关于keyBy,对应的是FlinkSQL的group by(在《系列之二十六 - Flink SQL - 中间算子:普通聚合》中讲过),在FlinkSQL中就是加不加group by的问题,下面示例都是演示group by
2)Flink从1.13版本开始就提倡使用TVF方式的开窗替换Window Aggregation,因此本示例都是基于TVF方式演示。如果要了解Window Aggregation,其参考《官方文档》
2.1 滚动窗口
2.1.1 说明
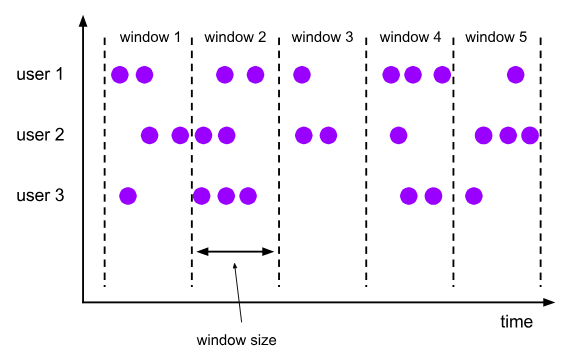
滚动窗口:将数据按照时间或者计数方式划分为不重叠的窗口。每个窗口都有固定时间或者计数。
语法如下:
FROM TABLE(TUMBLE(TABLE data, DESCRIPTOR(timecol), size [, offset ])
) GROUP BY column_list;
- data: 是一个表参数,可以是与 Time 属性列的任何关系。
- timecol: 是一个列描述符,指示应将数据的哪些时间属性列映射到滚动窗口。
- size: 是指定窗口宽度的持续时间。
- offset: 是一个可选参数,用于指定窗口 start 将移动的偏移量。
2.1.2 示例演示
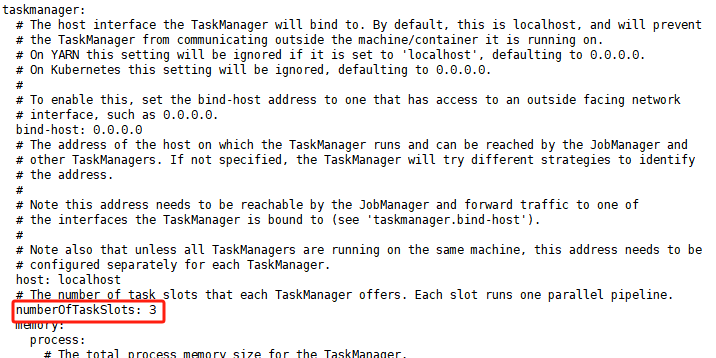
示例说明:以下窗口的实例,都是使用kafka来模拟数据进出。创建一个log的topic,然后使用一个sql-client客户端往log的topic中插入数据,使用另外一个sql-client客户端监听log的topic中数据。注意如果是单机版本的Flink,记得将taskmanager的numberOfTaskSlots改为大于1,这样可以同时跑多个任务
1)在kafka中创建topic:在kafka中创建log-tumble的topic
/opt/kafka/kafka_2.12-3.7.2/bin/./kafka-topics.sh --create \--bootstrap-server 172.18.4.10:9092 \--replication-factor 1 \--partitions 1 \--topic log-tumble

2)第一个sql-client客户端:在flink的客户端创建log_out:将使用kafka的连接器,创建log_out表,并同时使用滚动窗口监听数据;(注意在flink的lib中引入kafka的connector)
CREATE TABLE log_out (`id` STRING,`cpu` DOUBLE,`ts` TIMESTAMP(3),WATERMARK FOR ts AS ts - INTERVAL '2' SECOND
) WITH ('connector' = 'kafka','topic' = 'log-tumble','properties.bootstrap.servers' = '172.18.4.10:9092','properties.group.id' = 'testGroup','scan.startup.mode' = 'earliest-offset','sink.partitioner' = 'fixed','format' = 'json'
);
SET sql-client.execution.result-mode=TABLEAU;
SELECT window_start, window_end, max(cpu) AS max_cpu, count(cpu) AS numFROM TABLE(TUMBLE(TABLE log_out, DESCRIPTOR(ts), INTERVAL '5' SECOND))GROUP BY window_start, window_end;
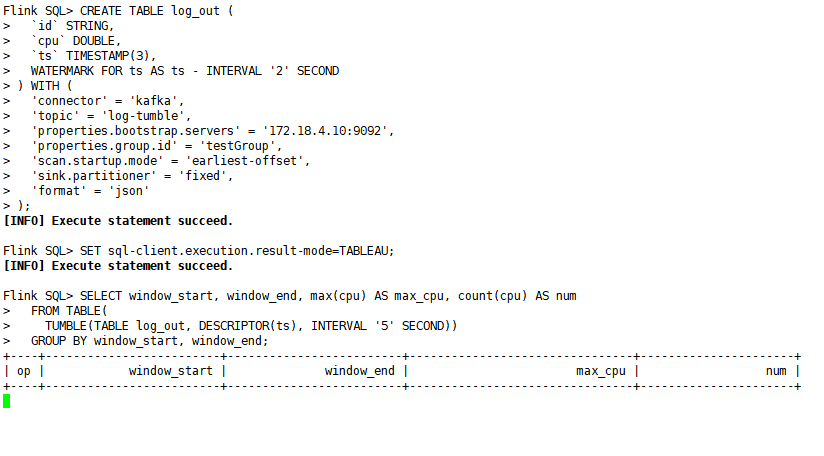
注意:这里使用水位线延迟2秒是支持数据水位线乱序
3)第二个sql-client客户端:在flink的客户端创建log_in:启动第二个sql-client窗口,创建log_in表,并插入数据
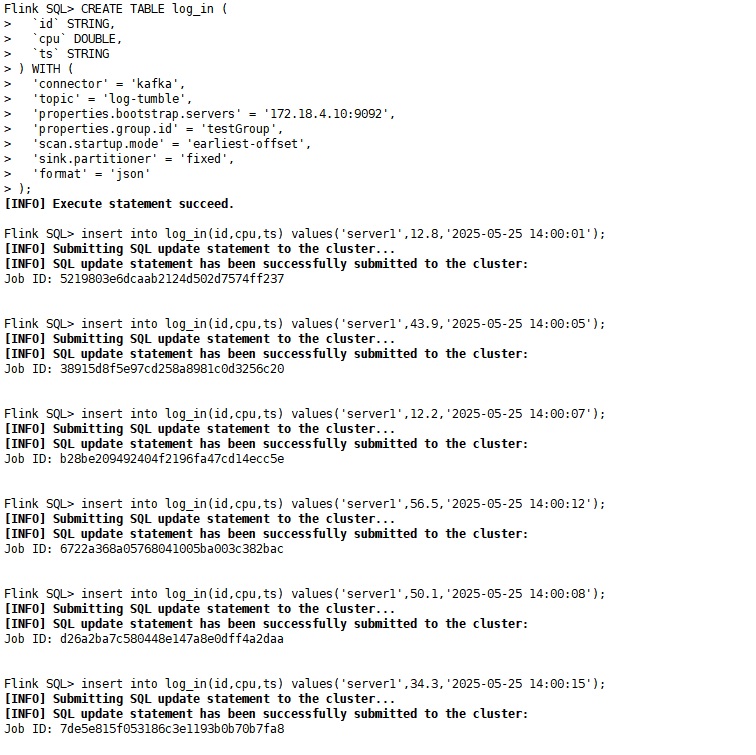
CREATE TABLE log_in (`id` STRING,`cpu` DOUBLE,`ts` STRING
) WITH ('connector' = 'kafka','topic' = 'log-tumble','properties.bootstrap.servers' = '172.18.4.10:9092','properties.group.id' = 'testGroup','scan.startup.mode' = 'earliest-offset','sink.partitioner' = 'fixed','format' = 'json'
);
insert into log_in(id,cpu,ts) values('server1',12.8,'2025-05-25 14:00:01');
insert into log_in(id,cpu,ts) values('server1',43.9,'2025-05-25 14:00:05');
insert into log_in(id,cpu,ts) values('server1',12.2,'2025-05-25 14:00:07');
insert into log_in(id,cpu,ts) values('server1',56.5,'2025-05-25 14:00:12');
insert into log_in(id,cpu,ts) values('server1',50.1,'2025-05-25 14:00:08');
insert into log_in(id,cpu,ts) values('server1',34.3,'2025-05-25 14:00:15');
4)在第一个sql-client客户端中查看结果:
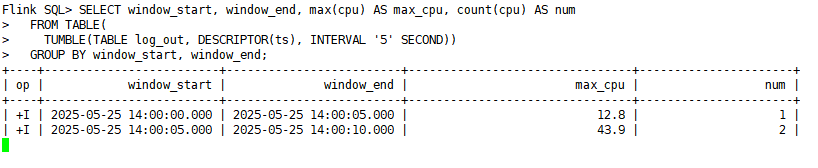
说明:
- 1)在 [0-5) 秒的窗口,只有1条数据,就是第1条,num=1,max_cpu=12.8(而且这个输出是你在输入第3条数据,也就是7秒的数据之后才输出的,因为watermark延迟2秒)
- 2)在 [5-10) 秒的窗口,有2条数据,也就是5秒和7秒,num=2,max_cpu=43.9(而且这个输出是你在输入第4条数据,也就是12秒的数据之后才输出的,因为watermark延迟2秒)
- 3)由于数据中最大的时间是15秒,而watermark延迟2秒,因此 [10-15) 秒的窗口还没有输出,同时有一条8秒的迟到数据也被丢弃了
2.2 滑动窗口
2.2.1 说明
滑动窗口也称为跳跃窗口。
滑动窗口:将数据按照设定的时间或者计数+步长的方式划分窗口,每个窗口都有固定时间或者计数,但是窗口跟窗口之间存在一定重叠数据。
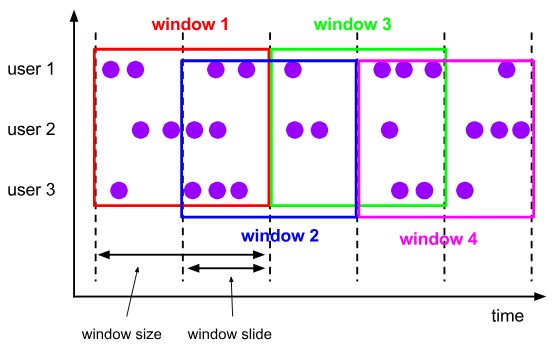
语法如下:
FROM TABLE(HOP(TABLE data, DESCRIPTOR(timecol), slide, size [, offset ])
) GROUP BY column_list;
- data: 是一个表参数,可以是与 Time 属性列的任何关系。
- timecol: 是一个列描述符,指示应将数据的哪些 Time Attributes 列映射到跳跃窗口。
- slide:是一个持续时间,用于指定顺序跳跃窗口开始之间的持续时间。也就是步长。
- size: 是指定跳跃窗口宽度的持续时间。也就是窗口大小。注意:窗口大小size必须是slide步长的整倍数
- offset: 是一个可选参数,用于指定窗口 start 将移动的偏移量。
2.2.2 示例演示
示例说明:以下窗口的实例,都是使用kafka来模拟数据进出。创建一个log的topic,然后使用一个sql-client客户端往log的topic中插入数据,使用另外一个sql-client客户端监听log的topic中数据。注意如果是单机版本的Flink,记得将taskmanager的numberOfTaskSlots改为大于1,这样可以同时跑多个任务
1)在kafka中创建topic:在kafka中创建log-hop的topic
/opt/kafka/kafka_2.12-3.7.2/bin/./kafka-topics.sh --create \--bootstrap-server 172.18.4.10:9092 \--replication-factor 1 \--partitions 1 \--topic log-hop

2)第一个sql-client客户端:在flink的客户端创建log_out:将使用kafka的连接器,创建log_out表,并同时使用滚动窗口监听数据;(注意在flink的lib中引入kafka的connector)
CREATE TABLE log_out (`id` STRING,`cpu` DOUBLE,`ts` TIMESTAMP(3),WATERMARK FOR ts AS ts - INTERVAL '2' SECOND
) WITH ('connector' = 'kafka','topic' = 'log-hop','properties.bootstrap.servers' = '172.18.4.10:9092','properties.group.id' = 'testGroup','scan.startup.mode' = 'earliest-offset','sink.partitioner' = 'fixed','format' = 'json'
);
SET sql-client.execution.result-mode=TABLEAU;
SELECT window_start, window_end, max(cpu) AS max_cpu, count(cpu) AS numFROM TABLE(HOP(TABLE log_out, DESCRIPTOR(ts), INTERVAL '2' SECOND, INTERVAL '4' SECOND))GROUP BY window_start, window_end;
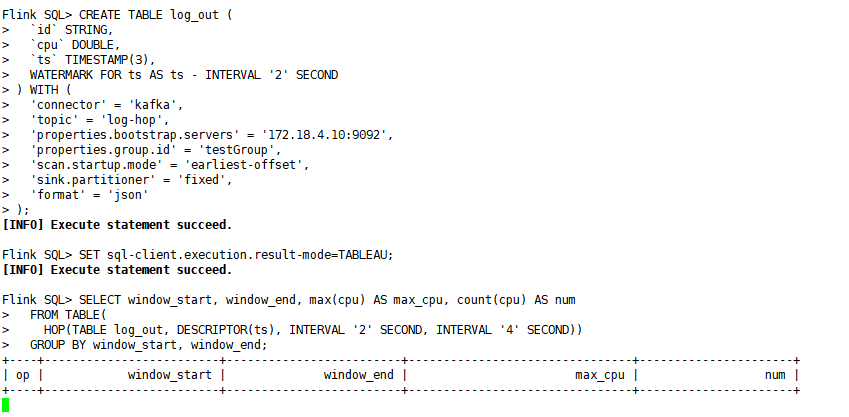
注意:这里watermark延迟2秒钟。滑动窗口长度是4秒,步长为2秒
3)第二个sql-client客户端:在flink的客户端创建log_in:启动第二个sql-client窗口,创建log_in表,并插入数据
CREATE TABLE log_in (`id` STRING,`cpu` DOUBLE,`ts` STRING
) WITH ('connector' = 'kafka','topic' = 'log-hop','properties.bootstrap.servers' = '172.18.4.10:9092','properties.group.id' = 'testGroup','scan.startup.mode' = 'earliest-offset','sink.partitioner' = 'fixed','format' = 'json'
);
insert into log_in(id,cpu,ts) values('server1',12.8,'2025-05-25 14:00:02');
insert into log_in(id,cpu,ts) values('server1',43.9,'2025-05-25 14:00:01');
insert into log_in(id,cpu,ts) values('server1',12.2,'2025-05-25 14:00:04');
insert into log_in(id,cpu,ts) values('server1',56.5,'2025-05-25 14:00:06');
insert into log_in(id,cpu,ts) values('server1',50.1,'2025-05-25 14:00:07');
insert into log_in(id,cpu,ts) values('server1',34.3,'2025-05-25 14:00:08');
4)在第一个sql-client客户端中查看结果:
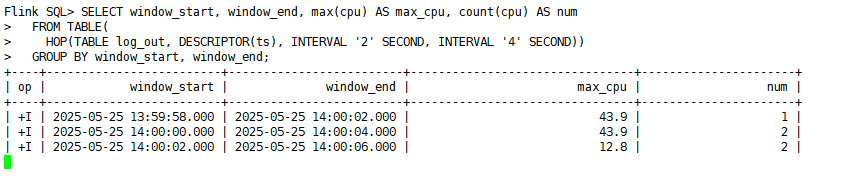
说明:
- 1)在 [58-2) 秒的窗口,只有1条数据,就是第2条数据,num=1,max_cpu=43.9(而且这个输出是你在输入第3条数据,也就是4秒的数据之后才输出的,因为watermark延迟2秒)
- 2)在 [0-4) 秒的窗口,有2条数据,也就是1秒和2秒,num=2,max_cpu=43.9(而且这个输出是你在输入第4条数据,也就是6秒的数据之后才输出的,因为watermark延迟2秒)
- 3)在 [2-6) 秒的窗口,有2条数据,也就是2秒和4秒,num=2,max_cpu=12.8(而且这个输出是你在输入第6条数据,也就是8秒的数据之后才输出的,因为watermark延迟2秒)
2.3 会话窗口
2.3.1 说明
会话窗口:将数据按照规定多少时间内没有其它数据再进来,那么之前进来的数据归为一个窗口。每个窗口都没有固定时间,窗口与窗口之间数据不重复。
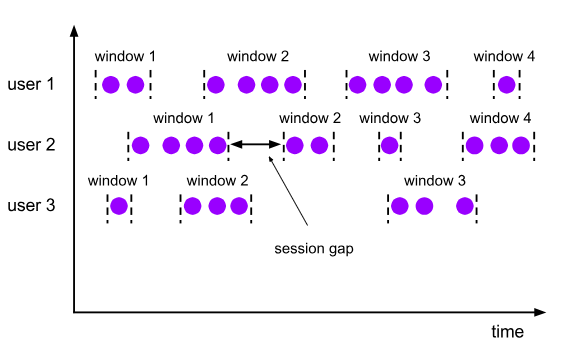
语法如下:
TABLE(SESSION(TABLE data [PARTITION BY(keycols, ...)], DESCRIPTOR(timecol), gap)
) GROUP BY window_start, window_end;
- data: 是一个表参数,可以是与 Time 属性列的任何关系。
- keycols:是一个列描述符,指示在会话窗口之前应该使用哪些列对数据进行分区。
- timecol:是一个列描述符,指示应将数据的哪些 Time Attributes 列映射到会话窗口。
- gap:是将两个事件视为同一会话窗口的一部分的最大时间间隔(以时间戳为单位)。
2.3.2 示例演示
示例说明:以下窗口的实例,都是使用kafka来模拟数据进出。创建一个log的topic,然后使用一个sql-client客户端往log的topic中插入数据,使用另外一个sql-client客户端监听log的topic中数据。注意如果是单机版本的Flink,记得将taskmanager的numberOfTaskSlots改为大于1,这样可以同时跑多个任务
1)在kafka中创建topic:在kafka中创建log-session的topic
/opt/kafka/kafka_2.12-3.7.2/bin/./kafka-topics.sh --create \--bootstrap-server 172.18.4.10:9092 \--replication-factor 1 \--partitions 1 \--topic log-session

2)第一个sql-client客户端:在flink的客户端创建log_out:将使用kafka的连接器,创建log_out表,并同时使用滚动窗口监听数据;(注意在flink的lib中引入kafka的connector)
CREATE TABLE log_out (`id` STRING,`cpu` DOUBLE,`ts` TIMESTAMP(3),WATERMARK FOR ts AS ts - INTERVAL '2' SECOND
) WITH ('connector' = 'kafka','topic' = 'log-session','properties.bootstrap.servers' = '172.18.4.10:9092','properties.group.id' = 'testGroup','scan.startup.mode' = 'earliest-offset','sink.partitioner' = 'fixed','format' = 'json'
);
SET sql-client.execution.result-mode=TABLEAU;
SELECT window_start, window_end, max(cpu) AS max_cpu, count(cpu) AS numFROM TABLE(SESSION(TABLE log_out PARTITION BY id, DESCRIPTOR(ts), INTERVAL '5' SECOND))GROUP BY window_start, window_end;
注意:这里watermark延迟2秒钟。会话窗口间隔为5秒
3)第二个sql-client客户端:在flink的客户端创建log_in:启动第二个sql-client窗口,创建log_in表,并插入数据
CREATE TABLE log_in (`id` STRING,`cpu` DOUBLE,`ts` STRING
) WITH ('connector' = 'kafka','topic' = 'log-session','properties.bootstrap.servers' = '172.18.4.10:9092','properties.group.id' = 'testGroup','scan.startup.mode' = 'earliest-offset','sink.partitioner' = 'fixed','format' = 'json'
);insert into log_in(id,cpu,ts) values('server1',12.8,'2025-05-25 14:00:01');
insert into log_in(id,cpu,ts) values('server1',43.9,'2025-05-25 14:00:03');
insert into log_in(id,cpu,ts) values('server1',12.2,'2025-05-25 14:00:02');
insert into log_in(id,cpu,ts) values('server1',56.5,'2025-05-25 14:00:08');
insert into log_in(id,cpu,ts) values('server1',50.1,'2025-05-25 14:00:15');
4)在第一个sql-client客户端中查看结果:
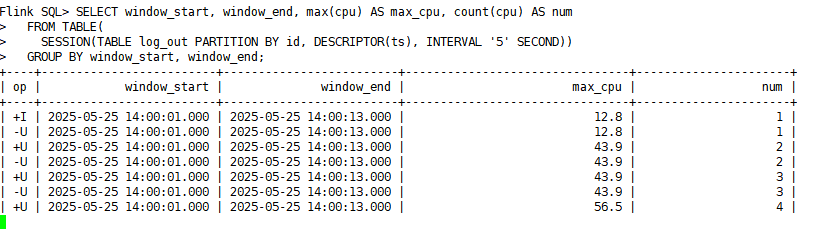
说明:
- 1)在 输入前4条的的时候,会话窗口都没有输出任何结果。虽然第4条输入8秒,与watermark的差有5秒,但是由于watermark延迟2秒,因此8秒相当于6秒,没有输出数据。
- 2)当输入第5条的时候,会话窗口输出结果,由于第5条的时间是15秒,watermark=13秒,与8秒相差大于等于5秒,因此输出。输出结果是一个回撤流的显示结果,把前四条的数据去了最终max_cpu=56.5
2.4 累积窗口
2.4.1 说明
累积窗口:这个窗口之前在Data Stream API 中没有,这个窗口有点像OVER函数。它的作用是固定的窗口间隔内,每个一定累积步长则触发的窗口输出。比如设置1个小时的窗口长度,累积步长是5分钟,那么每隔5分钟就会输出从0-5、0-10、0-15…的累积数据。
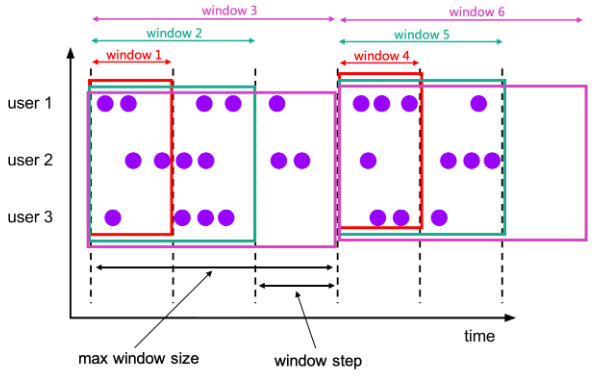
这种窗口在老版本写法中,一般通过参数来设置,但是由于VTF不支持以下参数,因此提供累积窗口:
- set ‘table.exec.emit.allow-lateness’ = ‘true’;
- set ‘table.exec.emit.early-fire.delay’ = ‘5000’;
语法如下:
TABLE(CUMULATE(TABLE data, DESCRIPTOR(timecol), step, size)
) GROUP BY window_start, window_end;
- data: 是一个表参数,可以是与 Time 属性列的任何关系。
- timecol:是一个列描述符,指示应将数据的哪些时间属性列映射到累积窗口。
- step:是一个持续时间,也叫累积步长,用于指定在顺序累积窗口结束之间增加的窗口大小。
- size: 是指定累积窗口的最大宽度的持续时间。 注意:累积窗口的最大宽度size必须是累积步长step的整倍数
- offset: 是一个可选参数,用于指定窗口 start 将移动的偏移量。
2.4.2 示例演示
示例说明:以下窗口的实例,都是使用kafka来模拟数据进出。创建一个log的topic,然后使用一个sql-client客户端往log的topic中插入数据,使用另外一个sql-client客户端监听log的topic中数据。注意如果是单机版本的Flink,记得将taskmanager的numberOfTaskSlots改为大于1,这样可以同时跑多个任务
1)在kafka中创建topic:在kafka中创建log-cumulate的topic
/opt/kafka/kafka_2.12-3.7.2/bin/./kafka-topics.sh --create \--bootstrap-server 172.18.4.10:9092 \--replication-factor 1 \--partitions 1 \--topic log-cumulate

2)第一个sql-client客户端:在flink的客户端创建log_out:将使用kafka的连接器,创建log_out表,并同时使用滚动窗口监听数据;(注意在flink的lib中引入kafka的connector)
CREATE TABLE log_out (`id` STRING,`cpu` DOUBLE,`ts` TIMESTAMP(3),WATERMARK FOR ts AS ts - INTERVAL '2' SECOND
) WITH ('connector' = 'kafka','topic' = 'log-cumulate','properties.bootstrap.servers' = '172.18.4.10:9092','properties.group.id' = 'testGroup','scan.startup.mode' = 'earliest-offset','sink.partitioner' = 'fixed','format' = 'json'
);
SET sql-client.execution.result-mode=TABLEAU;
SELECT window_start, window_end, max(cpu) AS max_cpu, count(cpu) AS numFROM TABLE(CUMULATE(TABLE log_out, DESCRIPTOR(ts), INTERVAL '2' SECOND, INTERVAL '6' SECOND))GROUP BY window_start, window_end;
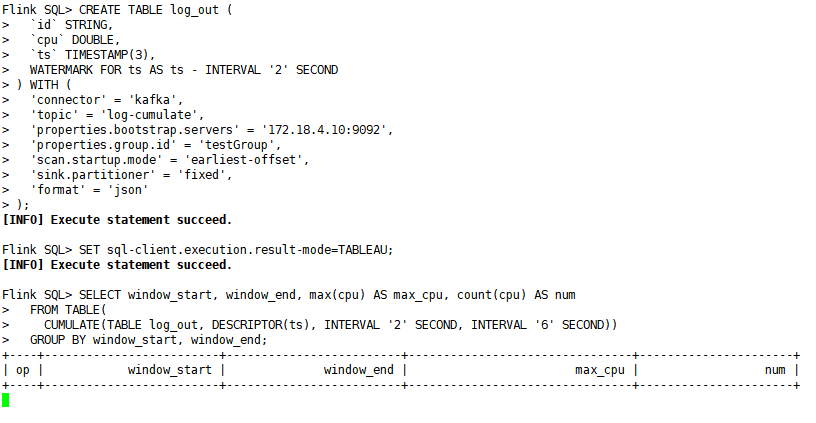
注意:这里watermark延迟2秒钟。乐基窗口长度6秒,累积步长2秒
3)第二个sql-client客户端:在flink的客户端创建log_in:启动第二个sql-client窗口,创建log_in表,并插入数据
CREATE TABLE log_in (`id` STRING,`cpu` DOUBLE,`ts` STRING
) WITH ('connector' = 'kafka','topic' = 'log-cumulate','properties.bootstrap.servers' = '172.18.4.10:9092','properties.group.id' = 'testGroup','scan.startup.mode' = 'earliest-offset','sink.partitioner' = 'fixed','format' = 'json'
);
insert into log_in(id,cpu,ts) values('server1',12.8,'2025-05-25 14:00:02');
insert into log_in(id,cpu,ts) values('server1',43.9,'2025-05-25 14:00:01');
insert into log_in(id,cpu,ts) values('server1',12.2,'2025-05-25 14:00:03');
insert into log_in(id,cpu,ts) values('server1',56.5,'2025-05-25 14:00:04');
insert into log_in(id,cpu,ts) values('server1',50.1,'2025-05-25 14:00:06');
insert into log_in(id,cpu,ts) values('server1',34.3,'2025-05-25 14:00:08');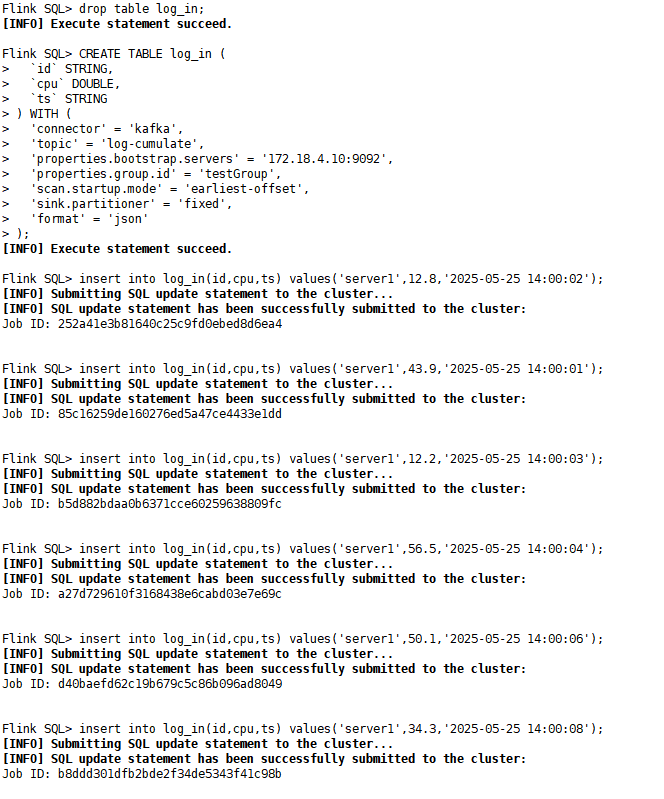
4)在第一个sql-client客户端中查看结果:
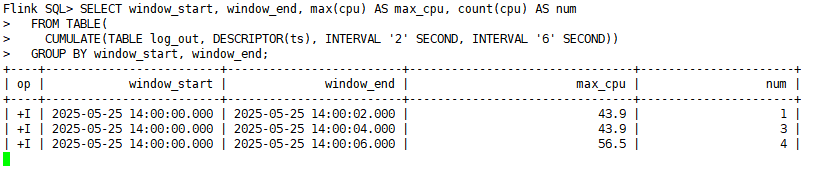
说明:
- 1)在 输入前3条的的时候,累积窗口都没有输出任何结果。因为watermark延迟2秒,因此3秒相当于1秒,没有输出数据。
- 2)当输入第4条的时候,累积窗口输出结果,由于第4条的时间是4秒,watermark延迟2秒,相当于现在的watermark=2秒,因此输出[0,2) 的数据
- 3)当输入第5条的时候,累积窗口输出结果,由于第5条的时间是6秒,watermark延迟2秒,相当于现在的watermark=4秒,因此输出[0,4) 的数据
- 4)当输入第6条的时候,累积窗口输出结果,由于第6条的时间是8秒,watermark延迟2秒,相当于现在的watermark=6秒,因此输出[0,6) 的数据
3 迟到数据策略
在《系列之十八 - 高级概念 - 水位线传递和策略》中提到对于迟到的数据,可以通过3种方式最终让迟到数据得到处理
- 水位线延迟时间
- 迟到时间
- 侧输出流
但是很遗憾,除了水位线延迟时间之外,FlinkSQL并未直接提供窗口延迟关闭以及侧输出流。
结语:本章主要讲解了FlinkSQL中如何定义水位线和窗口,同时还比较了FlinkSQL与Data Stream API中的一些区别。下一章讲会将结合上一章的Top-N和Deduplication讲一下在窗口模式下的语法。