大语言模型的局限性与RAG基本框架和工作流实例
大语言模型的局限性与RAG基本框架和工作流实例
Restrictions of LLMs and Use Cases of RAG Fundamental Framework & Workflow
By Jackson@ML
1. 大语言模型的局限性
大语言模型(Large Language Model, LLMs) 在获取准确的判断和最新的知识方面存在一定的局限性。如果仅依赖大语言模型,那么得出的结果,可能不尽如人意,甚至可能有错误比较离奇的现象。
1) 幻觉
幻觉(Hallucination) 的产生形成了貌似正确但实际存在错误的输出结果。幻觉的问题,出自大语言模型过分自信地生成了不正确的响应。
举个例子,来让大语言模型做个判断即可。
示例,肉夹馍是陕西省的民间美食,用腊汁肉夹到白吉馍中间,人吃人爱。但LLM(使用DeepSeek R1)仍然生成了一个虚构的、具有很强误导性的补全。
提示词:
What is Rou Jia Mo? Does it taste well? (肉夹馍是什么?它的味道如何?)
答案(节选,出现幻觉):

很显然,“肉夹馍”介绍不充分,同时,配料表的原料(比如酱油(浅色与深色的),绍兴酒)都不是陕西肉夹馍所必须的,且腊汁肉制作配料多达二十多种,也未列出。
尤其是对“馍”的介绍,过于简单,无法体现肉夹馍的香醇可口、外酥内柔的美味。
2) 知识截断
Knowledge Cutoff(知识截断),是指大语言模型反悔的答案与最新最真实的数据不符。由于基础模型(Foundation Model, FM) 在预训练时都有一个知识截断的日期,因此,模型的知识仅限于模型预训练或微调时的数据。
同样做两个试验对比一下。
示例一,利用DeepSeek R1来提问前几天发生的欧国联足球锦标赛决赛:
提示词:
“谁赢得了2025年欧国联足球锦标赛冠军?冠亚军争夺战比分是多少?”
回答:

此项赛事发生在3天前(比赛时间是北京时间2025年6月9日凌晨2:45),而笔者撰稿时,现在时间则是北京时间2025年6月11日23:00。
DeepSeek在这两天多时间内,已经输入和学习了很多关于本届欧国联足球锦标赛的数据,因此提供信息较为准确。
示例二,对于第三届全国翻译技术大赛第六场培训的问答
提示词:
“2025年6月11日,第三届全国翻译技术大赛举行培训,请问培训主题是什么?由谁主讲?”
回答:
“服务器繁忙,请稍后再试。“
反复利用提示词问了几遍,回答都是一样的答案。看来,DeepSeek未能获取任何相关知识,只能给出默认答案 “服务器繁忙,请稍后再试” 。
可以看到,示例二发生在笔者写本文的一小时前,因此,大语言模型不可能这么快地得到训练,从而具备知识。这时候,就出现了 “知识截断” 。
2. RAG
1)基本概念
Retrieval Augmented Generation(增强检索生成,RAG) 本身并不是一门纯粹的技术。
但是,RAG可以将基于大语言模型的应用程序链接到外部数据源和应用程序,一方面克服知识的局限性,另一方面,也会对大语言模型的输出进行矫正和完善。
如果希望大语言模型能访问它在预训练和微调过程中 “学到” 的“记忆“之外的数据,就可以使用RAG来满足。
由于这些数据并没有包含在原始训练数据中,比如:公司内部的私有数据。通过允许模型访问额外信息(或特定信息),而无须持续进行全部数据的微调。
2) RAG基本框架
RAG为大语言模型提供了外部知识源(或知识库)的访问能力,可将这些知识以上下文形式,嵌入原始提示词中以增强提示,并将这些信息一并发送给大语言模型。
RAG知识增强基本框架如下图所示。
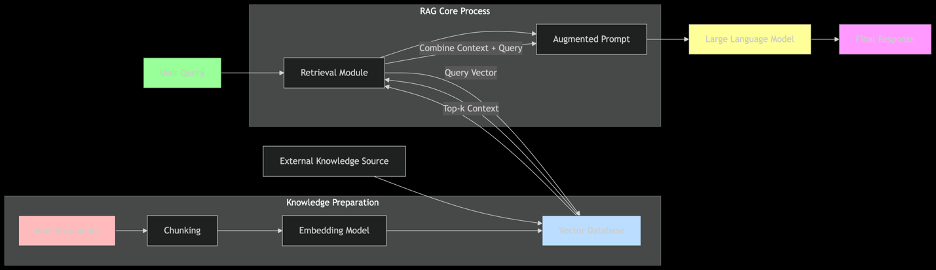
除了该框架外,RAG运行时参考流程如下图。

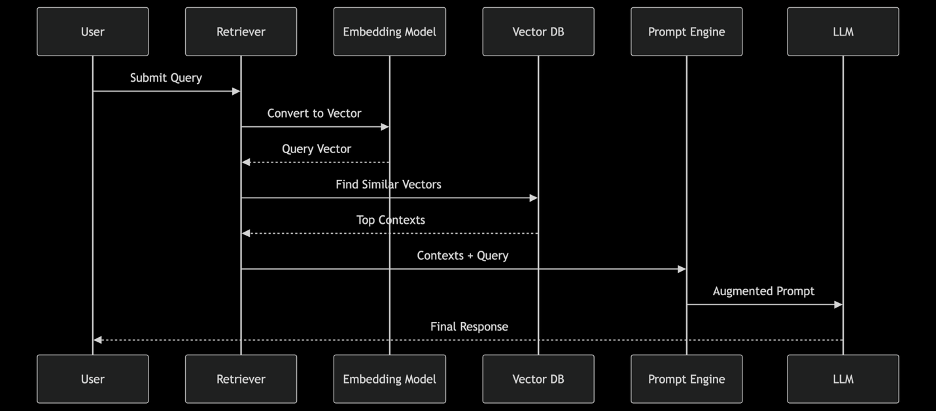
3)RAG工作流程
关键查询参考流程如下图:
4) 提示工程要求
在RAG优化的工作流中,提示工程(Prompt Engineering)有以下关键组件:
- 1) 系统说明(仅使用上下文回答)
- 2) 上下文分隔符标记
- 3) 显式问题格式
- 4) 访幻觉保护措施
在RAG实现检索增强后,如果想要实现基于上下文推理的应用程序,还需要进一步探索的丰富组件,并且,按照项目开发和测试流程,才能最终完成该应用程序。
AI技术好文陆续推出,敬请关注、收藏和点赞👍。
您的认可,我的动力! 😃