pytorch 中前向传播和后向传播的自定义函数
系列文章目录
文章目录
- 系列文章目录
- 一、torch.autograd.function
- 代码实例
在开始正文之前,请各位姥爷动动手指,给小店增加一点访问量吧,点击小店,同时希望我的文章对你的学习有所帮助。本文也很简单,主要讲解pytorch的前向传播张量计算,和后向传播获取梯度计算。
一、torch.autograd.function
每一个原始的自动求导运算实际上是两个对 Tensor 操作的函数
- forward 函数计算输入Tensor,一些列操作后得到输出Tensor
- backward 接收输出 Tensor ,获取某个标量的梯度,并且计算输入Tensor相对于相同标量的梯度值。
使用 apply 执行相应的运算
代码实例
这个实例实现了重写line的功能,在以后的深度学习和构建扔工神经网络中常常使用。对 line 类重构,两个方法 forward 和 backward 都是静态的。实现的功能就是把三个张量运算: w * x + b.代码中在 return 中体现。
- forward 传递的 ctx 用于保存上下文的管理器,调用
ctx.save_for_backward(变量名)可以存储变量,调用ctx.saved_tensors可以把对应的张量取出来。 - grad_output 是上一层的梯度,返回回来应该遵循链式法则。
- 导数计算:把 y 看做是因变量(编程中省略这个变量,具体体现 w * x + b),w, x, b 都看做是自变量。使用高数中的求导公式,大家就知道乘的系数是什么了。
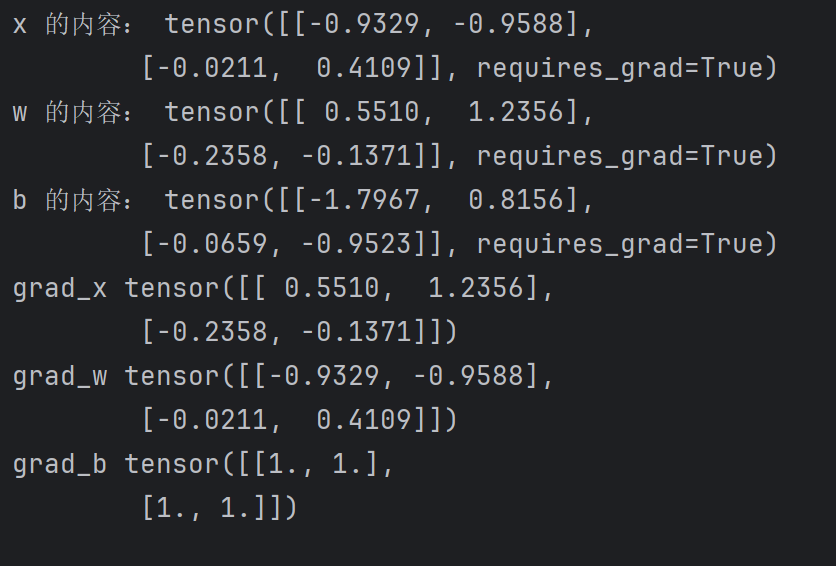
import torchclass line(torch.autograd.Function):@staticmethoddef forward(ctx,w,x,b):# 第一个参数是管理器,对变量进行存储# y = w*x+bctx.save_for_backward(w,x,b)# 定义前向运算return w*x+b@staticmethoddef backward(ctx, grad_output):# 上下文管理器,第二个参数是上一级梯度,表达了一个链式法则# 我们计算梯度,需要乘上一级梯度w,x,b = ctx.saved_tensors# dy/dw = xgrad_w = grad_output * x# dy/dx = wgrad_x = grad_output * w# dy/db = 1grad_b = grad_output * 1return grad_w,grad_x,grad_bw = torch.randn(2,2,requires_grad=True)
x = torch.randn(2,2,requires_grad=True)
b = torch.randn(2,2,requires_grad=True)# 调用重写的line函数
out = line.apply(w,x,b)
out.backward(torch.ones(2,2))print("x 的内容:",x)
print("w 的内容:",w)
print("b 的内容:",b)
print("grad_x",x.grad)
print("grad_w",w.grad)
print("grad_b",b.grad)