TactileNet 利用 AI 生成触觉图形填补视障人士无障碍鸿沟
全球约 4300 万视障人士依赖触觉图形获取视觉信息,但传统制作方法耗时费力,难以满足需求。本文提出TactileNet,首个全面的数据集和基于 AI 的框架,结合文本到图像的稳定扩散(SD)模型、低秩适应(LoRA)和DreamBooth技术,实现高保真、合规的触觉图形生成。通过专家评估,生成图形对触觉标准的准确率达 92.86%,与自然图像的姿势和特征对齐率达 100%。该框架展示出了可扩展性,数据集包含 66 类共 1029 张触觉图像,生成阶段可输出 32,000 张图像(筛选后7050张高质量样本),支持提示编辑定制细节(如添加/删除特征)。该框架显著加速无障碍设计流程,为教育等领域提供可扩展的 AI 解决方案,展现技术赋能社会公益的潜力。https://arxiv.org/abs/2504.04722触觉图形通过纹理表面传递视觉信息,是视障人士教育和日常生活的重要工具,但其传统制作依赖手工设计和电子浮雕设备,流程繁琐且成本高昂,难以满足海量需求。现有技术如图形设计软件和电子浮雕机虽提升效率,但仍受限于人工干预和专业知识门槛。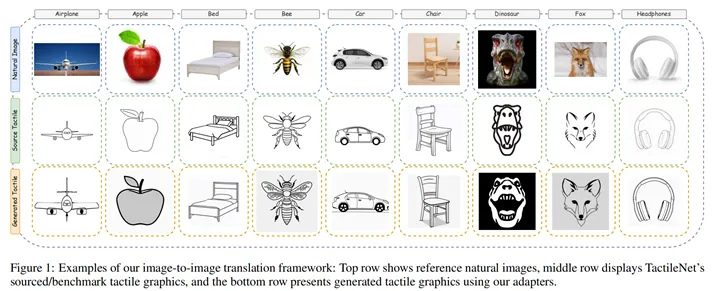
AI 驱动的自动化方案虽有潜力,但缺乏高质量数据集和针对性模型,导致生成的触觉图形在合规性和细节精度上表现不足。TactileNet 旨在解决上述问题,通过构建专用数据集并结合 SD 模型、LoRA 和 DreamBooth 技术,实现从文本或自然图像到触觉图形的高效生成。核心创新包括:TactileNet 数据集、轻量化微调框架、专家验证评估。这篇论文按照如下几个模块进行了进一步介绍。文章概述了管理TactileNet数据集和适应稳定扩散(SD)模型来生成触觉图形。1.相关工作触觉图形的当前方法与局限:传统触觉图形制作依赖设计师手动绘制或使用专业软件(如CorelDRAW、TactileView),再通过电子浮雕机(如 IndexBraille、ViewPlus)输出,这类方法耗时耗力,且难以处理复杂图像(如动物纹理、机械结构)。近年研究尝试通过图像复杂度评估和半自动转换工具提升效率,但仍需大量人工校准,无法实现规模化生产。此外,现有数据集规模小、类别少,限制了 AI 模型的泛化能力。文章概述了管理TactileNet数据集和适应稳定扩散(SD)模型来生成触觉图形。2.生成触觉图形去噪扩散概率模型(DDPM):通过前向扩散(添加噪声)和反向去噪(重建数据)生成高保真图像。TactileNet 利用 DDPM 的反向过程,结合文本提示引导生成符合触觉特征的图形。文本到图像 SD 模型:基于 DDPM 扩展,通过文本编码器将用户提示转化为语义向量,指导扩散模型生成对应图像。这一创新应用不仅将噪声转化为结构化的图像,还整合了语言元素以确保生成的视觉内容准确反映所描述的情景。微调SD模型:文章框架采用了两种方法—低秩适应(LoRA)和Dreambooth。在推理过程中,系统支持文本到图像和图像到图像的生成,这种灵活性确保了实际应用的实用性,弥合了触觉设计的不同模态之间的差异。低秩适应(LoRA):在微调阶段仅更新模型中低秩矩阵参数(而非全量参数),减少计算成本。这与完整模型重新训练相比需要较少的计算资源,同时保持高精度。DreamBooth:利用少量样本对 SD 模型进行个性化微调,使模型学习特定类别的触觉特征。通过添加唯一标识符,模型可生成符合该类别结构的高质量图形。3.数据集创建数据采集:从多个专业图书馆库获取 1029 张高质量、专家设计的触觉图像,覆盖 66 个类别(如动物、交通工具、日常物品)。通过Pinterest等社交平台补充相似图像,经人工筛选确保符合触觉设计的标准。文本提示生成:使用 ChatGPT 结合 DALL-E,为每张图像生成标准化提示,遵循结构化模板。这些提示词会经过严格审查,以确保它们严格遵循预定义的模板并且在整个数据集中保持一致性和相关性。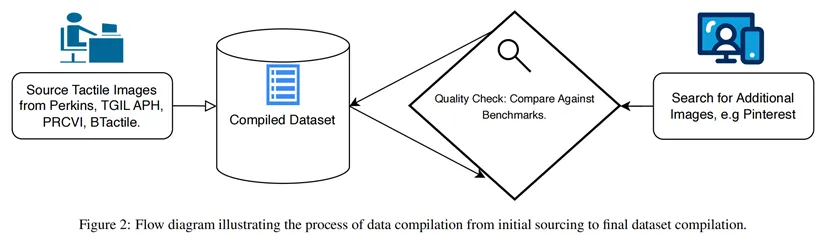
4.模型开发与图像生成类别特定微调:对每个类别单独训练 LoRA 和 DreamBooth 适配器,共生成 66 个模型。生成模式:a)文本到图像:仅使用特定类别的提示,模型输出符合描述的图形;b)图像到图像:结合自然图像和提示,生成适配触觉表现的图形。5.实验设置文章中概述了实验中使用的配置和环境设置,包含微调设置、优化和硬件配置参数以及图像生成配置(具体设置见论文原文)。6.评价方案文章提出了更符合触觉图形的独特需求的评估协议,该协议优先考虑由行业合作伙伴进行专家评估,确保生成的图形能够满足视障用户的实际需求。评估问题包括:特征对齐(Q1)准则合规(Q2)质量评级(Q3)开放反馈(Q4)
7.结果与讨论文章中做了图像到图像转换评估的结果分析如下:特征对齐:生成图形与自然图像的姿势和核心特征对齐率达100%,优于部分源库图形(如骆驼物种误配导致的 3.57% 错误);准则合规:生成图形合规率 92.86%,略低于源库图形(96.43%),主要差距在于复杂场景的线条简化(如椅子的 3D 透视过度);质量评级:28.57% 的生成图形需修改,主要因视觉复杂度高导致触觉可读性下降,而源库图形的 “拒绝” 率为 3.57%,多为数据集配对错误。文章中也做了文本到图像转换的结果分析如下表所示:这项研究标志着通过应用生成式人工智能在开发人工智能驱动的辅助工具取得了重大进展,有效地解决了对可扩展、高质量触觉图形的关键需求的问题。在以下三个方面有重要贡献:触觉网络(TactileNet)数据集、高效的微调和以人为中心的评估。TactileNet 通过专用数据集和轻量化微调框架,首次实现高效、合规的触觉图形生成,为视障人士获取视觉信息提供了可扩展的 AI 解决方案。实验表明,生成图形在特征对齐和准则合规上接近人工设计水平,提示编辑功能进一步提升了实用性。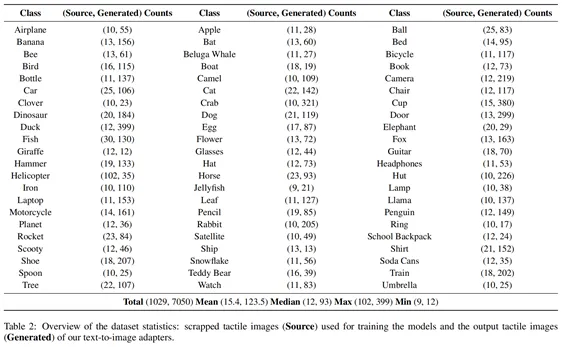
未来研究可聚焦复杂场景建模和跨模态整合,推动触觉图形生成技术从实验室走向实际应用,助力构建更包容的信息无障碍社会。参考文献:Khan A, Choubineh A, Shaaban M A, et al. TactileNet: Bridging the Accessibility Gap with AI-Generated Tactile Graphics for Individuals with Vision Impairment[J]. arXiv preprint arXiv:2504.04722, 2025.