交我算使用保姆教程:在计算中心利用singularity容器训练深度学习模型
文章目录
- 准备工作
- 步骤
- 如何封装和使用容器
- 安装
- 创建 Singularity 容器
- 编写 def 文件
- 构建容器
- 查看构建容器的 python 版本
- 本地测试挂载数据集和代码
- 如何上传数据
- windows 系统
- Linux 系统
- 如何设置作业
- 任务脚本的结构
- 常用的 Slurm 参数
- 一份完整的 slurm 作业示例
- 如何在 debug 队列测试
- 如何提交作业
- 检查作业的状态
- 其它学习资源
准备工作
- 在交我办app上检索“交我算”,申请交我算主账号(有教职的才能申请主账号),然后让主账号申请子账号(都需要答题,可以重复提交,要100分才行)
- 开通账号之后获取账号和密码
步骤
- 准备作业,在本地调通,确定没有 bug
- 在本地封装环境为镜像,本地测试,镜像没有问题
- 将镜像、数据、代码全部上传(要通过数据节点上传,不然被封号)
- 在 debug 队列测试,确实可以运行
- ARM 作业在 ARM 的登录节点或计算节点提交;思源一号配备单独的登录节点,思源一号作业在思源一号的登录节点或计算节点提交;
需要注意的是:
- 上传 1T 以下的数据,用数据节点(节点名称一般包含 data 字样),不能在登录节点上上传(节点名称一般包含 login 字样);登录到数据节点上传数据(Windows 用 WinSCP 软件;linux 用 sftp);登录到登录节点提交任务(Windows用 Mobaxterm 软件模拟 terminal,linux 直接在 terminal 里面用 ssh)。上传 1T 以上的数据,直接用硬盘去网络中心拷。
- 登录到数据节点或者登录节点之后,都是直接进入自己的 home 目录下,如果
.sh或者.slurm文件在 home 目录下,那么你的工作目录就是 home 目录 - 登录到登录节点之后,就和本地使用 linux 一样的体验;但是不要在这里运行计算任务,而是包装成任务提交系统,让系统调度资源帮你运行
如何封装和使用容器
简单说,容器可以提供一个和本地相同的运行环境。在交我算上,没有root权限,很多东西安装不了,你可以把环境打包到容器里面,把容器上传到服务器,然后在容器里运行程序。
镜像和容器的关系:通过镜像生成容器
- 镜像:像预制好的房间设计图纸(包含家具、电路等)。
- 容器:根据图纸实际建造的房间实例,可快速复制多个相同的房间。
实际上我感觉这俩词混用也问题不大(?可以吗)
Docker 是最简单的容器技术,但是不足够用,这里得用 Singularity(因为我们没有 root 权限,Docker 默认是以 root 用户运行的)
Singularity 使用 .sif(Singularity Image Format)文件作为容器镜像
安装
注意版本,可以自己去官网找一个版本
# 下载 Singularity
wget https://github.com/sylabs/singularity/releases/download/v3.9.0/singularity-ce-3.9.0.tar.gz# 解压
tar -xzf singularity-ce-3.9.0.tar.gz# 进入解压后的目录
cd singularity-ce-3.9.0# 编译和安装
./mconfig
make -C builddir
sudo make -C builddir install
创建 Singularity 容器
首先,要编辑 .def 文件,这个文件表明你希望如何打包容器。然后,使用 singularity build container.sif container.def 命令从 Singularity 定义文件(.def 文件)或 Docker 镜像创建 Singularity 镜像。因为我们要用 pytorch 还有 cuda,官方有提供已经打包了 cuda 和 torch 的 docker 容器,我们直接在该基础上打包。
singularity 容器一旦打包完成,就不可以再修改了,如果代码要小改一下,就得重新打包,非常不方便。还有数据集,非常大,不能直接打包到容器里。所以我们在容器里只打包运行程序需要的包,也就是只打包环境,然后在运行的过程中,再通过参数说明我们的代码和数据集的位置(这种方式叫做“挂载”)
编写 def 文件
一份 .def 文件示例如下:
Bootstrap: docker
From: swr.cn-north-4.myhuaweicloud.com/ddn-k8s/docker.io/pytorch/pytorch:2.3.1-cuda11.8-cudnn8-runtime%post# 使用 Conda 安装 mpi4pyconda install -y mpi4py# 安装其他依赖pip install --no-cache-dir \tensorboard \transformers \accelerate>=0.26.0 \decord \tqdm \safetensors%environmentexport PATH=/usr/local/bin:$PATHexport LD_LIBRARY_PATH=/usr/lib/x86_64-linux-gnu/openmpi/lib:$LD_LIBRARY_PATH%runscript# 默认运行命令(可选)echo "Singularity 镜像已启动!"
前两行:
Bootstrap: docker这行指定了 Singularity 使用 docker 作为构建容器的引导方式。Singularity 支持多种引导方式(如 library、shub、localimage 等),这里选择 docker 表示 Singularity 会从 Docker 镜像构建容器。From: swr.cn-north-4.myhuaweicloud.com/ddn-k8s/docker.io/pytorch/pytorch:2.3.1-cuda11.8-cudnn8-runtime这行指定了 Singularity 使用的 Docker 镜像的来源。查找 torch 和 cuda docker(国内镜像):https://docker.aityp.com/r/docker.io/pytorch/pytorch
这个基础容器有说法;库里有 pytorch:2.3.1-cuda11.8-cudnn8-runtime 还有这种 pytorch:2.2.1-cuda11.8-cudnn8-devel ,除了版本区别以外,这两种的区别在于一个是 runtime 一个是 devel,runtime 这个文件比 devel 小很多。runtime 表示这是一个运行时镜像,通常用于部署和运行 PyTorch 应用,而不是用于开发。devel 表示这是一个开发镜像,通常包含了构建和开发 PyTorch 应用所需的工具和库。runtime 包含 cuda 运行需要的库,但是 nvcc 命令是不起用的,有些情况代码可以运行,有些情况会说找不到 cuda,就老实换成 devel 版本吧
在 Singularity 定义文件(.def 文件)中,% 用于表示不同的区块(sections),每个区块定义了容器构建过程中的不同部分。以下是一些常见的区块及其作用:
%help提供容器的帮助信息,用户在运行容器时可以通过singularity help <容器名>查看此信息。%labels用于为容器添加元数据(metadata),例如版本号、作者信息等。%files用于将主机上的文件或目录复制到容器中。例如:
%files
/path/on/host/file.txt /path/in/container/file.txt
但是在示例的文件没有用这个区块,因为数据集太大了,打包进去不方便;代码可能还需要修改,不要直接打包进去,而是通过挂载的方式,可以修改。
有一些包,需要联网下载,但是无法访问,可以先下载到本地,然后在 %files 段中把这个文件挂载到容器里,然后在 %post 段读取这个文件并安装。
%environment用于设置容器的环境变量,这些变量会在容器运行时生效。例如:
%environment
export PATH=/usr/local/cuda/bin:$PATH
%post这个命令就是在构建容器的时候会执行的命令(注意区分,不是在运行容器,而是在构建容器);这里一般写上需要在容器里安装的包。在这个示例中,安装 mpy4pi 用的是 conda 而不是 pip,因为 pip 装不上总是报错,没办法了,只能用 conda。torch不用写了,docker里面有。%runscript定义容器运行时默认执行的命令。当用户直接运行容器时,会执行此区块中的命令。如果把代码打包进容器了,那在这里写上运行代码的命令,到时候直接运行容器,就会执行代码了。
构建容器
写好 .def 文件之后,在terminal执行命令:sudo singularity build my_container.sif my_container.def 然后等待,完成之后会打印:
...
INFO: Adding environment to container
INFO: Adding runscript
INFO: Creating SIF file...
INFO: Build complete: my_container.sif
查看构建容器的 python 版本
singularity exec my_container.sif python --version
本地测试挂载数据集和代码
你可以把容器理解为一个独立的文件系统,存放逻辑和linux系统是一致的。假设你的数据集在本地存放的地址是 /home/you/datasets/my_dataset ,你可以把数据集挂载到容器的任何位置,例如我想挂载到容器的 /datasets/my_dataset 地址下,那么,容器里的 code 访问数据集的时候都是通过 /datasets/my_dataset 去访问的。所以在代码里面,你要把数据集地址修改为 /datasets/my_dataset ,不然程序访问不到,就会报错。
把代码里的地址改好,然后准备在本地测试容器是否可以正常使用。假设你本地运行代码使用的命令是这样:
torchrun --nnodes=1 --nproc_per_node=2 --master_port=29500;
那么你要让程序在容器里运行,你需要这样(其中 /code/train.py 是代码文件挂载到容器中的地址):
singularity exec vidAidImage.sif torchrun --nnodes=1 --nproc_per_node=2 --master_port=29500 /code/train.py
但是这样还是会报错,因为你忘记挂载代码和数据集地址了。当然,我这里还用到了预训练参数,所以预训练参数的文件地址也要挂载的(代码里读取的地址也要一起修改为挂载后的地址)
挂载的方法是:--bind 原地址:挂载地址 (原地址就是实际存放在运行程序的电脑里的地址,如果是在本地测试容器是否能用,那就是文件在你的电脑里的地址;如果是在交我算上运行,那就是文件在交我算上放的位置)
例如,我要挂载下面三个地址:
| 本地地址 | 想要挂载的地址 |
|---|---|
/media/gao/hardD1/eye_help_data/singularity/code | /code |
/media/gao/hardD1/pretrained_checkpoint | /pretrained |
/media/gao/hardD1/datasets/videoHelpDatasets/dataset-use | /datasets |
运行程序的命令是:
singularity exec --bind /media/gao/hardD1/eye_help_data/singularity/code:/code,/media/gao/hardD1/pretrained_checkpoint:/pretrained,/media/gao/hardD1/datasets/videoHelpDatasets/dataset-use:/datasets vidAidImage.sif torchrun --nnodes=1 --nproc_per_node=2 --master_port=29500 /code/train.py
但是,这样还是会报错。因为程序要用到 GPU,容器识别不到驱动。这时候只需要加上参数 --nv 就可以了,所以最后可以执行的命令就是:
singularity exec --nv --bind /media/gao/hardD1/eye_help_data/singularity/code:/code,/media/gao/hardD1/pretrained_checkpoint:/pretrained,/media/gao/hardD1/datasets/videoHelpDatasets/dataset-use:/datasets vidAidImage.sif torchrun --nnodes=1 --nproc_per_node=2 --master_port=29500 /code/train.py
另外,如果在代码中有相对路径,那可能也会报错,没有办法读到正确的地址。这时候你需要设置一下当前的工作目录,把代码变成这样:
singularity exec --nv --bind /media/gao/hardD1/eye_help_data/singularity/code:/code,/media/gao/hardD1/pretrained_checkpoint:/pretrained,/media/gao/hardD1/datasets/videoHelpDatasets/dataset-use:/datasets vidAidImage.sif bash -c "cd /code && torchrun --nnodes=1 --nproc_per_node=2 --master_port=29500 /code/train.py"
如果本地运行没有错误,就可以把文件都传到交我算上,在 debug 队列里测试一下,也没有问题的话就可以跑起来了。
如何上传数据
登录节点是可以访问到文件存储系统的,但是,不要在登录节点上传大量数据,会被封号的,请通过数据节点传输。(区分“登录”行为和“登录节点”这个节点)
首先要弄清数据应该上传到哪里,π2.0/AI/ARM集群及思源一号集群使用两个独立的存储系统。如果要用 A100 显卡,那是在思源一号集群,得登录到思源一号的传输节点传输。传输节点地址如下:
- 思源一号传输节点地址为
sydata.hpc.sjtu.edu.cn - π 2.0/AI/ARM 集群传输节点地址为
data.hpc.sjtu.edu.cn
windows 系统
下载 WinSCP 应用程序,在登陆会话框中,文件协议选择 SFTP;主机名称填写:sydata.hpc.sjtu.edu.cn
(这个是数据节点,登陆这个节点上传数据是允许的,不会被封号)
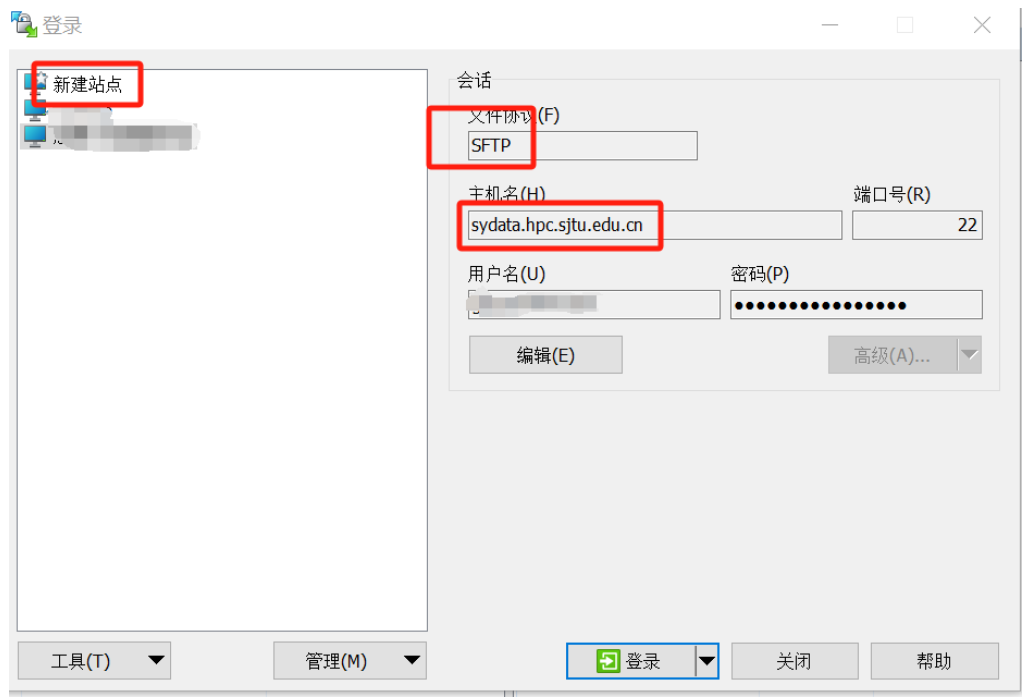
登陆之后自动进去你账号下的 home 目录,这里是你的地盘,可以任意操作(新建文件夹、上传数据)
Linux 系统
一般已经安装了,检查是否安装 sftp:
sftp -V
如果没安装,安装命令(Ubuntu):
sudo apt-get install openssh-server openssh-client
- 登陆:
sftp username@remote_name
username 是账号名,remote_name这里就是 sydata.hpc.sjtu.edu.cn;回车之后会让输入密码 - 上传文件
put local_file remote_file - 下载文件
get remote_file local_file
如何设置作业
代码写好后,在本地运行,只需要一行 python train.py 即可,但是如果直接在登录节点上运行这一行,是不可以的。
你必须要写一个“作业”,说明你需要多少资源、要运行哪个程序,然后把这个“作业”提交,Slurm 作业调度系统会根据目前系统硬件资源的繁忙情况,给你分配资源之后帮你运行。
作业其实就是一个 .sh 脚本;用代码 sbatch my_job.sh 提交任务;在交我算的文档里给的示例是 sbatch my_job.slurm 这个只是文件命名的区别,无所谓用哪一种,关键是文件内容正确即可。
任务脚本的结构
- Shebang 行
就是第一行,指定脚本使用的解释器(通常是 Bash)
#!/bin/bash
-
Slurm 参数(以
#SBATCH开头)
这些参数用于指定作业的资源需求和运行方式。常用的参数介绍见后文。 -
加载模块(可选)
在计算中心,通常需要加载一些软件模块以使用特定工具或库。但是我们在容器里运行,一般要什么容器里都有,所以这个可以不填。 -
设置环境变量(可选)
定义一些环境变量,方便脚本中使用。例如:
export DATA_DIR="/path/to/data"
export OUTPUT_DIR="/path/to/output"
- 运行命令
这是脚本的核心部分,指定需要执行的命令。例如:
python train.py --data_dir $DATA_DIR --output_dir $OUTPUT_DIR
常用的 Slurm 参数
- 作业基本信息
#SBATCH --job-name=my_job # 作业名称
#SBATCH --output=output_%j.out # 标准输出文件(%j 会被替换为作业ID)
#SBATCH --error=error_%j.err # 标准错误文件
标准输出文件是什么内容?
- 代码里的 print、命令行的输出、还有 slurm 调度的时候的一些信息,会输出到“标准输出文件”。
标准输出文件会存放在哪里?
- 如果你按照上面那么写,也就是相对路径,那么当前工作文件夹就是这个
.sh或者.slurm文件所在的位置;如果写绝对路径,那就会放在绝对路径的位置
- 资源需求
#SBATCH --ntasks=1 # 任务数量
#SBATCH --cpus-per-task=4 # 每个任务使用的 CPU 核心数
#SBATCH --gres=gpu:2 # 使用的 GPU 数量
#SBATCH --mem=32G # 内存需求
#SBATCH --time=01:00:00 # 任务最长运行时间(格式:HH:MM:SS)
- 分区和约束
#SBATCH --partition=? # 分区名称(根据计算中心的配置填写)
partition 参数这样填:
| 队列 | 参数 |
|---|---|
| 思源一号cpu | 64c512g |
| 思源一号gpu | a100 |
| ARM 节点 | arm128c256g |
| debuga100队列 | debuga100 |
| dgx2队列 | dgx2 |
- 其他选项
#SBATCH --mail-type=END,FAIL # 任务结束时发送邮件
#SBATCH --mail-user=your_email@example.com # 接收邮件的邮箱
一份完整的 slurm 作业示例
#!/bin/bash
#SBATCH --job-name=videoLLaMA2_finetune # 作业名称
#SBATCH --output=outputs/videoLLaMA2/finetune_%j.out # 标准输出文件
#SBATCH --error=outputs/videoLLaMA2/finetune_%j.err # 标准错误文件
#SBATCH --ntasks=1 # 任务数量
#SBATCH --cpus-per-task=16 # 每个任务使用的CPU核心数
#SBATCH --gres=gpu:4 # 使用的GPU数量
#SBATCH --time=2-00:00:00 # 任务最长运行时间(2天)
#SBATCH --partition=a100 # 分区名称(思源1号)
#SBATCH --mem=128G # 内存需求# 加载必要的模块(根据计算中心的配置填写)
module load singularity# 定义变量
SIF_FILE="/dssg/home/xx/xx/containers/torch2_2.sif" # Singularity容器路径;我用的是思源一号,所以这个存储系统是在 /dssg 下面的,用的不是思源一号,就不是这个目录
CODE_DIR="/dssg/home/xx/xx/code/VideoLLaMA2" # 代码目录
PRETRAINED_DIR="/dssg/home/xxg/xx/pretrained" # 预训练模型目录
OUTPUT_DIR="/dssg/home/xx/xx/outputs/videoLLaMA2" # 输出目录
DATASET_DIR="/dssg/home/xx/xx/datasets" # 数据集目录# 执行命令
singularity exec --nv --bind ${CODE_DIR}:/code/VideoLLaMA2,${PRETRAINED_DIR}:/pretrained,${OUTPUT_DIR}:/output/videoLLaMA2,${DATASET_DIR}:/datasets ${SIF_FILE} bash -c "cd /dssg/home/xx/xx/code/VideoLLaMA2 && /dssg/home/xx/xx/code/VideoLLaMA2/my_finetune.sh 1 4"
如何在 debug 队列测试
提交 debug A100 队列作业使用思源一号登录节点 sylogin.hpc.sjtu.edu.cn
登录方法:在终端运行 ssh 命令,ssh username@登录节点地址 回车之后会让输入密码。
debuga100队列是调试用的队列 ,目前只提供1节点,因此只能投递单节点作业。调试节点将4块a100物理卡虚拟成 4*7=28 块gpu卡,每卡拥有5G独立显存;节点CPU资源依然为64核,请在作业参数中合理指定gpu与cpu的配比。
投放到此队列的作业 运行时间最长为20分钟 ,超时后会被终止。
测试的时候,数据集用一个很小的,让它快速走完一个流程,保证 checkpoint 是可以保存的,以免跑了很久发现参数没有存下来……
测试的时候,与正式版的需要修改:
- 队列名称:
partition=debuga100 - 时间,不能超过 20min,不然会报错;它不是超过 20min 自动停,而是你设置的时候就不能超过 20min
- 资源,按理来说可以申请不超过这个队列的资源;但是这种情况系统直接给 cancel 了;我测试只申请
cpus-per-task=1; gres=gpu:1; mem=4G可以继续往下运行;不过一般这个体量跑不了模型,只能看报错是 run out of memory 然后就直接提交正式任务了
提交任务:sbatch my_task.sh
提交任务之后系统会返回给你一串字符,例如:Submitted batch job 111111
你要看这个任务的状态,使用命令:scontrol show job 111111
这个命令系统会给你返回如下信息,例如:
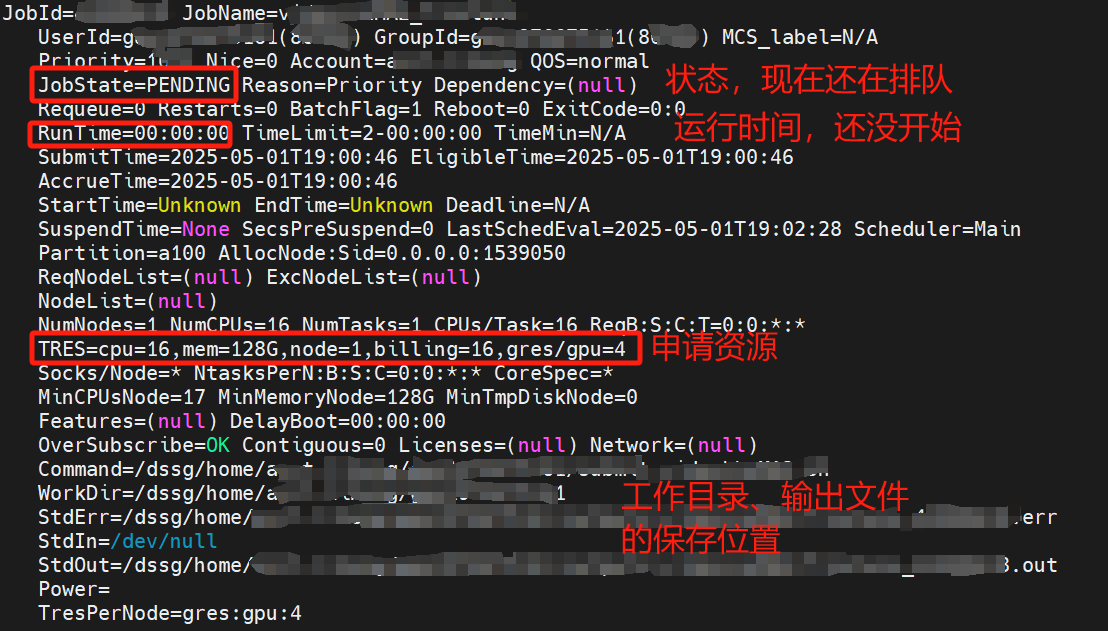
如何提交作业
- 提交a100队列作业请使用 思源一号登录节点。
- 提交dgx2队列作业请使用 π 2.0 集群登录节点。
登录方法:在终端运行 ssh 命令,ssh username@登录节点地址 回车之后会让输入密码。
检查作业的状态
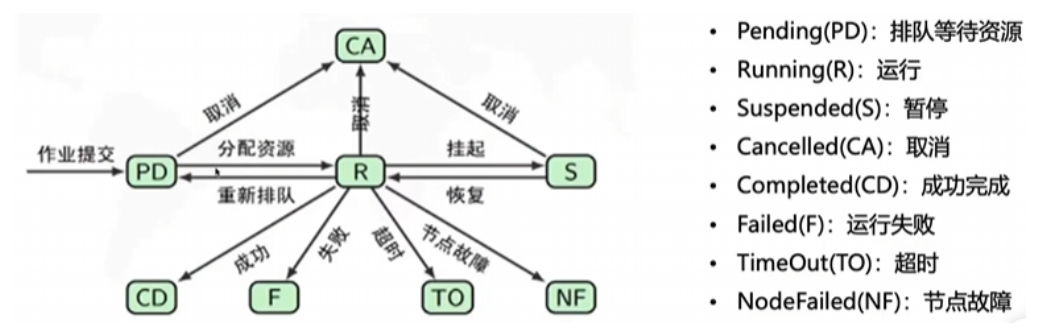
查看自己账号下的作业:squeue -u your_username

作业状态包括R(正在运行),PD(正在排队),CG(即将完成),CD(已完成)。
查看作业的详细信息:scontrol show job 作业id
常用命令:

其它学习资源
b站官方视频
官方使用手册