Linux ARM64 内核/用户虚拟空间地址映射
文章目录
- 前言
- 一、内核虚拟空间地址映射
- 1.1 AArch64 Linux memory layout
- 1.2 内核线性映射
- MMU硬件翻译
- 1.3 内核页表映射
- 二、用户空间虚拟空间地址映射
- 2.1 PGD
- 2.2 PUD
- 2.3 PMD
- 2.4 PTE
前言
关于Linux x86_64的内核/用户虚拟空间地址映射请参考:Linux 物理内存映射
本文Linux内核版本:6.12.0
一、内核虚拟空间地址映射
1.1 AArch64 Linux memory layout
// linux/v6.12/source/Documentation/arch/arm64/memory.rstAArch64 Linux memory layout with 4KB pages + 4 levels (48-bit)::Start End Size Use-----------------------------------------------------------------------0000000000000000 0000ffffffffffff 256TB userffff000000000000 ffff7fffffffffff 128TB kernel logical memory map[ffff600000000000 ffff7fffffffffff] 32TB [kasan shadow region]ffff800000000000 ffff80007fffffff 2GB modulesffff800080000000 fffffbffefffffff 124TB vmallocfffffbfff0000000 fffffbfffdffffff 224MB fixed mappings (top down)fffffbfffe000000 fffffbfffe7fffff 8MB [guard region]fffffbfffe800000 fffffbffff7fffff 16MB PCI I/O spacefffffbffff800000 fffffbffffffffff 8MB [guard region]fffffc0000000000 fffffdffffffffff 2TB vmemmapfffffe0000000000 ffffffffffffffff 2TB [guard region]
//v6.12/source/arch/arm64/include/asm/memory.h// 基于CONFIG_ARM64_VA_BITS(通常为48)
#define VA_BITS 48
#define PAGE_OFFSET (-(1UL << 48)) // = 0xffff000000000000
#define MODULES_VADDR (_PAGE_END(VA_BITS_MIN))
#define MODULES_END (MODULES_VADDR + SZ_2G)
#define KIMAGE_VADDR MODULES_END // 内核镜像起始地址
#define VMEMMAP_END (-UL(SZ_1G)) // = 0xfffffc0000000000?
#define VMEMMAP_START (VMEMMAP_END - VMEMMAP_SIZE)
#define PCI_IO_START (VMEMMAP_END + SZ_8M)
#define PCI_IO_END (PCI_IO_START + PCI_IO_SIZE)
#define FIXADDR_TOP (-UL(SZ_8M)) // = 0xffffffffffff800000
宏定义与地址计算
VA_BITS = 48: 虚拟地址宽度为 48 位。
PAGE_OFFSET = _PAGE_OFFSET(VA_BITS) = -(1 << 48) = 0xffff000000000000: 线性映射的起始虚拟地址。计算方式:-(2^48) 在 64 位有符号数中表示为 0xffff000000000000。
MODULES_VADDR = _PAGE_END(VA_BITS_MIN): 内核模块的起始地址,通常在 PAGE_OFFSET 附近。
MODULES_VSIZE = 2GB: 内核模块区域大小。
KIMAGE_VADDR = MODULES_END: 内核镜像的起始虚拟地址,通常紧跟在模块区域之后。
如下图所示:
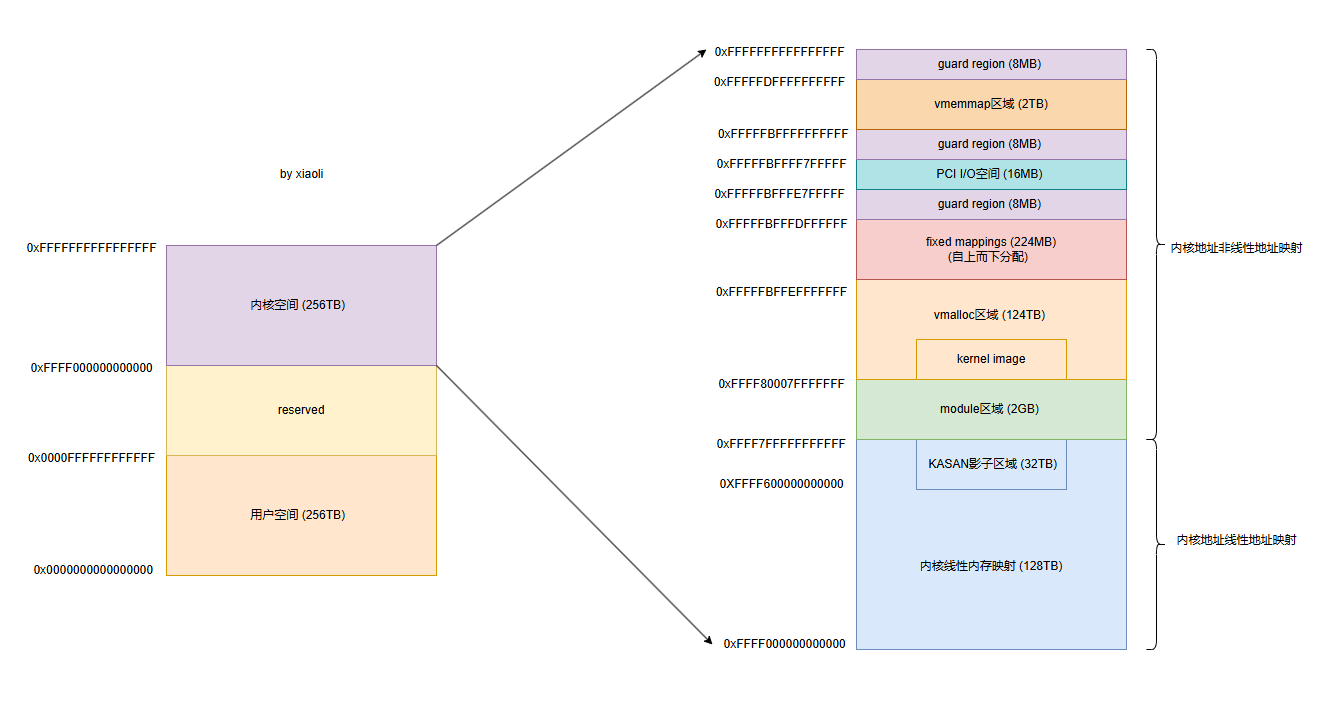
区域详细说明:
用户空间:低256TB,用于用户进程。
内核逻辑内存映射:线性映射区域,物理内存直接映射。
KASAN影子区域:KASAN 工具的影子内存,每个字节影子内存对应 8 字节主内存,用于检测内核内存错误。
模块区域:内核模块加载区域
vmalloc区域:动态内核虚拟内存分配。vmalloc(), ioremap() 分配的内存,虚拟地址连续但物理页不连续。对于ARM64,内核镜像也在这个区域。
固定映射区域:用于特殊用途的固定映射
PCI I/O空间:PCI设备I/O内存映射
vmemmap区域:稀疏内存模型的结构体映射,存放 struct page 数组的虚拟地址空间,用于管理物理内存页。
保护区域:防止越界访问的保护页面
1.2 内核线性映射
内核虚拟空间地址会建立两个映射:线性映射和页表映射
(1)线性映射:比如在ARM64的Linux内核中,存在一个直接的线性映射区域,通常称为"direct mapping"或"linear mapping",即上面的 kernel logical memory map。
线性映射是指内核虚拟地址空间中的一个连续区域,直接、一对一地映射到物理内存的连续区域。
内核在初始化时(paging_init阶段):就创建内核空间的映射(所有进程共享同一份内核页表,内核代码和数据在所有上下文中都位于相同的虚拟地址)。 在软件层面(内核), 当内核需要知道它访问的一个内核空间页面Px的物理地址时, 它只要知道第一页P0的物理地址即可, 然后加上Px相距P0的偏移, 即可快速知道Px的物理地址(线性映射的优势),而不需要走页表翻译这种类似哈希表的方式去计算( 当内核去访问该页时, 硬件层面仍然走的是MMU翻译的全过程)。
虽然硬件 MMU 仍然会进行翻译,但这种固定的线性关系使得地址转换在软件层面变得极其简单和快速。
转换公式通常是:虚拟地址 = 物理地址 + 固定的偏移量
__virt_to_phys:内核空间虚拟空间地址到物理地址的线性转换。
/** Check whether an arbitrary address is within the linear map, which* lives in the [PAGE_OFFSET, PAGE_END) interval at the bottom of the* kernel's TTBR1 address range.*/
#define __is_lm_address(addr) (((u64)(addr) - PAGE_OFFSET) < (PAGE_END - PAGE_OFFSET))#define __lm_to_phys(addr) (((addr) - PAGE_OFFSET) + PHYS_OFFSET)
#define __kimg_to_phys(addr) ((addr) - kimage_voffset)#define __virt_to_phys_nodebug(x) ({ \phys_addr_t __x = (phys_addr_t)(__tag_reset(x)); \__is_lm_address(__x) ? __lm_to_phys(__x) : __kimg_to_phys(__x); \
})#define __virt_to_phys(x) __virt_to_phys_nodebug(x)
__phys_to_virt:物理地址到内核空间虚拟空间地址的线性转换。
#define __phys_to_virt(x) ((unsigned long)((x) - PHYS_OFFSET) | PAGE_OFFSET)
线性映射在paging_init之前就建立了,paging_init建立内核页表映射,将物理内存映射到虚拟地址空间。
MMU硬件翻译
软件层面(内核开发者视角):
内核代码使用 __pa()/__virt_to_phys 和 __va() /__phys_to_virt宏进行地址转换。
这些宏是纯计算,不访问任何硬件或数据结构。
速度极快,等效于 phys_addr = virt_addr - PAGE_OFFSET + PHYS_OFFSET。
这就是线性映射带来的巨大便利。
硬件层面(CPU MMU 视角):
当 CPU 执行一条访问内核虚拟地址的指令时,MMU 必须完整地遍历页表。
流程:PGD -> PUD -> PMD -> (PTE) -> 物理地址。
即使是 2MB 大页映射,MMU 也会在 PMD 级别找到映射并停止遍历。
TLB(Translation Lookaside Buffer) 会缓存这些翻译结果,后续访问可以直接从 TLB 获取物理地址,无需再次遍历页表。
连续映射(PTE_CONT)的作用就是让 TLB 能将多个 PTE 项视为一个单元,提高 TLB 的有效容量。
为什么需要硬件翻译?
即使有线性映射,硬件翻译仍然必不可少,因为:
权限检查:MMU 需要检查当前访问(读/写/执行)是否符合 PTE/PMD 项中设置的权限(PTE_RDONLY, PTE_PXN, PTE_UXN 等)。
缓存策略:MMU 需要根据页表项中的缓存属性(如 Normal, Device, Write-Through, Write-Back)来决定如何与 CPU 缓存交互。
访问位(Accessed Flag)和脏位(Dirty Flag):MMU 在访问页面时会自动设置 PTE_AF 和 PTE_DIRTY,用于内存管理和页面回收。
1.3 内核页表映射
硬件必要性:CPU 在执行指令时,MMU 仍然必须完整地进行页表遍历和权限检查。
当 CPU 执行一条访问内核虚拟地址的指令时,MMU 必须完整地遍历页表。因此还需要基于MMU建立页表映射。
PGD (Page Global Directory) → P4D (Page 4th Directory) → PUD (Page Upper Directory) → PMD (Page Middle Directory) → PTE (Page Table Entry)
在ARM64架构中,P4D通常等同于PGD(只有3级或4级页表,没有真正的5级页表)。
虽然大部分内核空间采用线性映射,但有些区域例外:
vmalloc区域:动态分配的虚拟内存,不是线性映射
固定映射:用于临时映射的特殊区域
设备内存:通过ioremap映射的设备寄存器
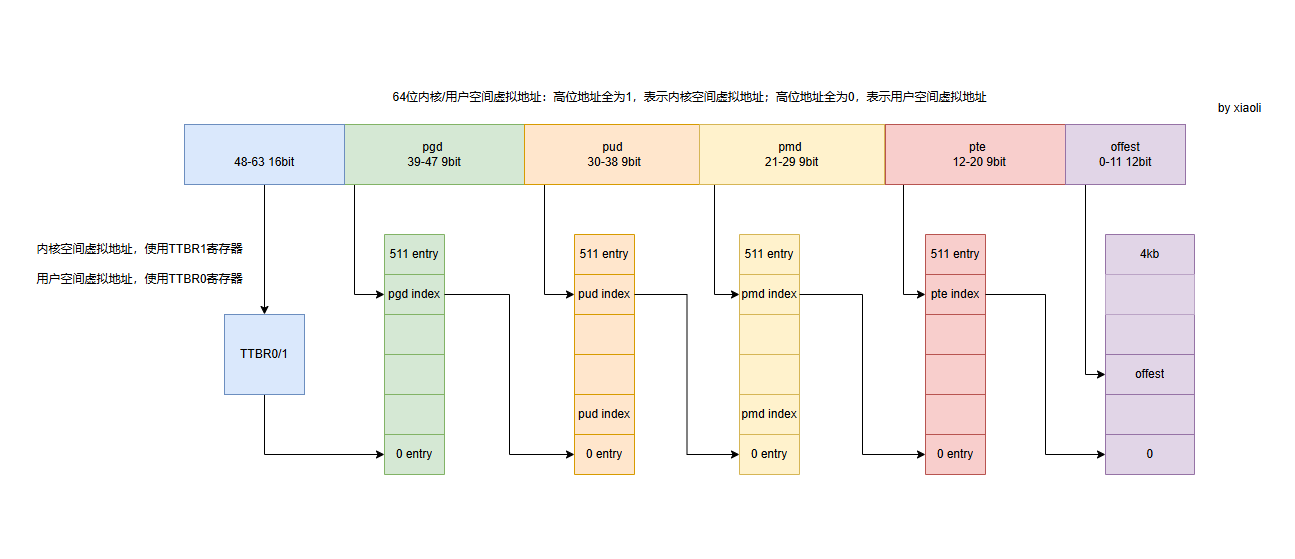
二、用户空间虚拟空间地址映射
用户空间虚拟空间地址只会建立页表映射。
页表映射:
PGD (Page Global Directory) → P4D (Page 4th Directory) → PUD (Page Upper Directory) → PMD (Page Middle Directory) → PTE (Page Table Entry)
在ARM64架构中,P4D通常等同于PGD(只有3级或4级页表,没有真正的5级页表)。
我们已 AArch64 Linux 在 4KB 页 + 4级页表 + 48位虚拟地址 模式为例:
配置(ARM64_VA_BITS_48,ARM64_4K_PAGE, PGTABLE_LEVELS=4)
ARM64_VA_BITS:
config ARM64_VA_BITSintdefault 36 if ARM64_VA_BITS_36default 39 if ARM64_VA_BITS_39default 42 if ARM64_VA_BITS_42default 47 if ARM64_VA_BITS_47default 48 if ARM64_VA_BITS_48default 52 if ARM64_VA_BITS_52
default 48 if ARM64_VA_BITS_48
PGTABLE_LEVELS:
config PGTABLE_LEVELSintdefault 2 if ARM64_16K_PAGES && ARM64_VA_BITS_36default 2 if ARM64_64K_PAGES && ARM64_VA_BITS_42default 3 if ARM64_64K_PAGES && (ARM64_VA_BITS_48 || ARM64_VA_BITS_52)default 3 if ARM64_4K_PAGES && ARM64_VA_BITS_39default 3 if ARM64_16K_PAGES && ARM64_VA_BITS_47default 4 if ARM64_16K_PAGES && (ARM64_VA_BITS_48 || ARM64_VA_BITS_52)default 4 if !ARM64_64K_PAGES && ARM64_VA_BITS_48default 5 if ARM64_4K_PAGES && ARM64_VA_BITS_52
default 4 if !ARM64_64K_PAGES && ARM64_VA_BITS_48
2.1 PGD
// v6.12/source/arch/arm64/include/asm/pgtable-hwdef.h#define PTDESC_ORDER 3/* Number of VA bits resolved by a single translation table level */
#define PTDESC_TABLE_SHIFT (PAGE_SHIFT - PTDESC_ORDER)#define ARM64_HW_PGTABLE_LEVEL_SHIFT(n) (PTDESC_TABLE_SHIFT * (4 - (n)) + PTDESC_ORDER)/** PGDIR_SHIFT determines the size a top-level page table entry can map* (depending on the configuration, this level can be -1, 0, 1 or 2).*/
#define PGDIR_SHIFT ARM64_HW_PGTABLE_LEVEL_SHIFT(4 - CONFIG_PGTABLE_LEVELS)
#define PGDIR_SIZE (_AC(1, UL) << PGDIR_SHIFT)
#define PGDIR_MASK (~(PGDIR_SIZE-1))
#define PTRS_PER_PGD (1 << (VA_BITS - PGDIR_SHIFT))
PGDIR_SHIFT:
CONFIG_PGTABLE_LEVELS = 4PGDIR_SHIFT = ARM64_HW_PGTABLE_LEVEL_SHIFT(4 - 4) = ARM64_HW_PGTABLE_LEVEL_SHIFT(0)。ARM64_HW_PGTABLE_LEVEL_SHIFT(0) = (12 - 3) * (4 - 0 ) + 3) = 39。PGDIR_SHIFT = 39。
PGDIR_SIZE:
#define PGDIR_SIZE (_AC(1, UL) << PGDIR_SHIFT) = 2 << 39 = 512GB
PGDIR_MASK:
#define PGDIR_MASK (~(PGDIR_SIZE-1)) PGDIR_SIZE-1 = 0x0000007FFFFFFFFF
PGDIR_MASK = ~0x0000007FFFFFFFFF = 0xFFFF800000000000
PTRS_PER_PGD:
#define PTRS_PER_PGD (1 << (VA_BITS - PGDIR_SHIFT))
PTRS_PER_PGD = 1 << (48 -39) = 512
这些值表明:
每个顶级页表项(PGD)可以映射 512GB 的地址空间
页全局目录(PGD)有 512 个表项
虚拟地址的高 9 位(48-39=9)用于索引 PGD
掩码用于将地址对齐到 512GB 边界
2.2 PUD
#if CONFIG_PGTABLE_LEVELS > 3CONFIG_PGTABLE_LEVELS = 4#define PTDESC_ORDER 3/* Number of VA bits resolved by a single translation table level */
#define PTDESC_TABLE_SHIFT (PAGE_SHIFT - PTDESC_ORDER)#define ARM64_HW_PGTABLE_LEVEL_SHIFT(n) (PTDESC_TABLE_SHIFT * (4 - (n)) + PTDESC_ORDER)#define PUD_SHIFT ARM64_HW_PGTABLE_LEVEL_SHIFT(1)
#define PUD_SIZE (_AC(1, UL) << PUD_SHIFT)
#define PUD_MASK (~(PUD_SIZE-1))
#define PTRS_PER_PUD (1 << PTDESC_TABLE_SHIFT)
PUD_SHIFT:
#define PUD_SHIFT ARM64_HW_PGTABLE_LEVEL_SHIFT(1)PUD_SHIFT = ARM64_HW_PGTABLE_LEVEL_SHIFT(1) = (12 - 3) * (4 - 1) + 3) = 30。
PUD_SIZE:
#define PUD_SIZE (_AC(1, UL) << PUD_SHIFT)PUD_SIZE = 1 << 30 = 1GB
PUD_MASK:
#define PUD_MASK (~(PUD_SIZE-1))PUD_SIZE-1 = 0x3FFFFFFF
PUD_MASK = ~0x3FFFFFFF = 0xFFFFFFFFFFC00000(64位系统中)
PTRS_PER_PUD:
#define PTRS_PER_PUD (1 << PTDESC_TABLE_SHIFT)PTRS_PER_PUD = 1 << 9 = 512
这些值表明:
每个PUD(Page Upper Directory)表项可以映射 1GB 的地址空间
每个PUD表有512个表项
虚拟地址的30-38位(9位)用于索引PUD
2.3 PMD
/** PMD_SHIFT determines the size a level 2 page table entry can map.*/
#if CONFIG_PGTABLE_LEVELS > 2CONFIG_PGTABLE_LEVELS = 4#define PTDESC_ORDER 3/* Number of VA bits resolved by a single translation table level */
#define PTDESC_TABLE_SHIFT (PAGE_SHIFT - PTDESC_ORDER)#define ARM64_HW_PGTABLE_LEVEL_SHIFT(n) (PTDESC_TABLE_SHIFT * (4 - (n)) + PTDESC_ORDER)#define PMD_SHIFT ARM64_HW_PGTABLE_LEVEL_SHIFT(2)
#define PMD_SIZE (_AC(1, UL) << PMD_SHIFT)
#define PMD_MASK (~(PMD_SIZE-1))
#define PTRS_PER_PMD (1 << PTDESC_TABLE_SHIFT)
#endif
PMD_SHIFTL:
PMD_SHIFT = ARM64_HW_PGTABLE_LEVEL_SHIFT(2) = (12 - 3) * (4 - 2) + 3) = 21。
PMD_SIZE:
#define PMD_SIZE (_AC(1, UL) << PMD_SHIFT)PMD_SIZE = 1 << 21 = 2^21 = 2MB
PMD_MASK:
#define PMD_MASK (~(PMD_SIZE-1))PMD_SIZE-1 = 0x1FFFFF
PMD_MASK = ~0x1FFFFF = 0xFFFFFFFFFFE00000(64位系统中)
PTRS_PER_PMD:
#define PTRS_PER_PMD (1 << PTDESC_TABLE_SHIFT)
PTRS_PER_PMD = 1 << 9 = 512
这些值表明:
每个PMD(Page Middle Directory)表项可以映射 2MB 的地址空间
每个PMD表有512个表项
虚拟地址的21-29位(9位)用于索引PMD
2.4 PTE
每个PTE(Page Table Entry)表项映射一个4KB的物理页
每个PTE表有512个表项
虚拟地址的12-20位(9位)用于索引PTE
页内偏移使用低12位(0-11位)
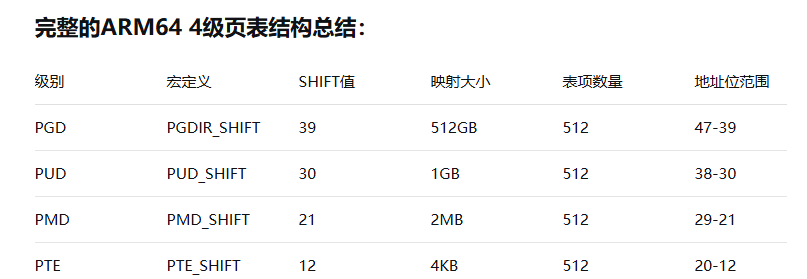
这种设计实现了48位虚拟地址到物理地址的转换,每个页表级别使用9位索引,总共4×9=36位用于页表索引,加上12位页内偏移,正好构成48位虚拟地址空间。
如下图所示: