【LLM的后训练之对齐人类篇】SFT、RLHF(RM+PPO)、DPO task09
Task09:第四章 大语言模型
(这是笔者自己的happy-llm学习记录,仅供参考,愿 LLM 越来越好❤)接上篇task08的第一阶段:预训练,之后的二三阶段:SFT和RLHF\DPO

LLM二阶段:SFT—— Alignment对齐阶段1
SFT概要
SFT=Supervised Fine Tuning=有监督微调
为什么要SFT?
- 表面原因:因为光pretrain出来的LLM很牛,但不会说话,无法接下游任务,就是很难大程度压榨他的能力,所以需要SFT进行微调。
- 本质原因:pretrain的模型用的是
CLM任务,模型有的是预测下一个token,所以不好和用户指令适配。
SFT要干什么?
这个阶段训练的是模型“遵循通用指令的能力”(指令微调)
- 表面上看:理解并可以回复好user的chat时各种各样的指令。多轮对话能力也是在这里实现的
- 实际上:就是继续进行CLM训练,但是要求对指令 理解+回复
- 简单预测下一token❌,预测input + output✔️
SFT的微调数据(指令数据集)
微调数据的内容是什么样的?
- 要包括大量类别的
用户指令 + 对应回复
1.简易版:
{"instruction":"将下列文本翻译成英文:",(用户指令,让模型做的事情的描述)"input":"今天天气真好",(执行改指令的补充输入,没用的话可以空着)"output":"Today is a nice day!"(模型应该给的回复)
}
2.LLaMA用的指令数据集的数据格式:
他把instruction和input合成content了,是为了让模型学到和预训练不一样的范式
Instruction:\n{{content}}\n\n### Response:\n
Instruction:\n将下列文本翻译成英文:今天天气真好\n\n### Response:\n3.开源AIpaca指令数据集的格式:
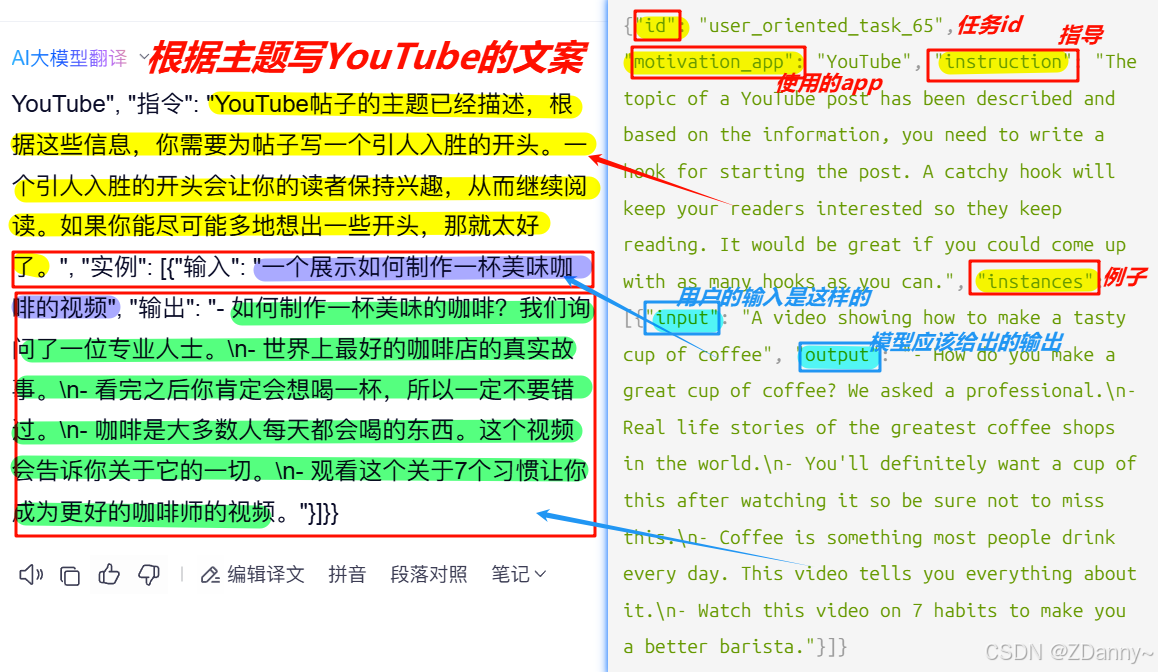
指令数据集有什么难点?
- 问答类别
覆盖范围越大越好,但是高质量的数据集难获取,有监督,人工检查标注。开源出来的少 不同任务类别数据的配比也很重要

SFT数据集规模?
一般,
单个任务 —— 500~1000条
多种任务泛化能力好 —— 数B(十亿) token
一些获取数据的方法?
用chatGPT生成指令数据集:一些种子prompt ——>chatGPT ——> 生成更多指令 ——> 生成对应回复(如开源指令数据集AIpaca)
训练模型的多轮对话能力
模型的多轮对话能力完全来自于 SFT 阶段,
训练数据怎么做?
将训练数据构造成多轮对话格式,让模型能够利用之前的知识来生成回答。
ps:这里的[MASK] 并不是“遮盖”,而是表示模型在训练时不计算这些部分的损失
1.直接将最后一次模型回复作为输出,前面所有历史对话作为输入,直接拟合最后一次回复(丢失大量中间信息)
input=<prompt_1><completion_1><prompt_2><completion_2><prompt_3><completion_3>output=[MASK][MASK][MASK][MASK][MASK]<completion_3_>2.和上面的差不多。只是分开了。(有大量重复计算)
input_1 = <prompt_1><completion_1>output_1 = [MASK]<completion_1_>input_2 = <prompt_1><completion_1><prompt_2><completion_2>output_2 = [MASK][MASK][MASK]<completion_2_>input_3=<prompt_1><completion_1><prompt_2><completion_2><prompt_3><completion_3>output_3=[MASK][MASK][MASK][MASK][MASK]<completion_3_>3.直接要求模型预测每一轮对话的输出。(最合理)
input=<prompt_1><completion_1><prompt_2><completion_2><prompt_3><completion_3>output=[MASK]<completion_1_>[MASK]<completion_2_>[MASK]<completion_3_>LLM三阶段:RLHF —— Alignment对齐阶段2
= Reinforcement Learning from Human Feedback = 人类反馈强化学习
是chatGPT比GPT-3的核心突破,也是为什么chatGPT能够让大众和他好好对话——和人类对齐
> SFT:让LLM和人类的指令对齐 ——指令遵循能力
> RLHF:让LLM和人类价值观对齐 ——回答 安全无害有用
> > 强化学习 vs 监督学习 ( < 机器学习)
> 强化:就是不断调整直到能在这个**环境**中获得最大**奖励**。
> 监督:就是规范行为
LLM后训练阶段中的RLHF是什么样的?
让人类标注员给模型的回答打分(奖励) – > 模型不断调整自己的回复来获得高分(进化强化了)
how RLHF?
分成两步:训练RM + PPO训练
what is RM?
Reward Model = 奖励模型
怎么训RM?
学会按照偏好排序 + 选出来后怎么映射到分数。(原因:分数尺度不一样,我觉得好给9分,他觉得好只给6分)
- 训练数据:
模型对齐chosen的回答

- 初始模型:
小参数的LLM(OpenAI是175BLLM + 6B RM)
可以是SFT后的LLM、基于偏好训的LLM
怎么用RM(操作)?
使用PPO算法进行强化学习,(最大化奖励分数,所以要不断的更新更新调整)
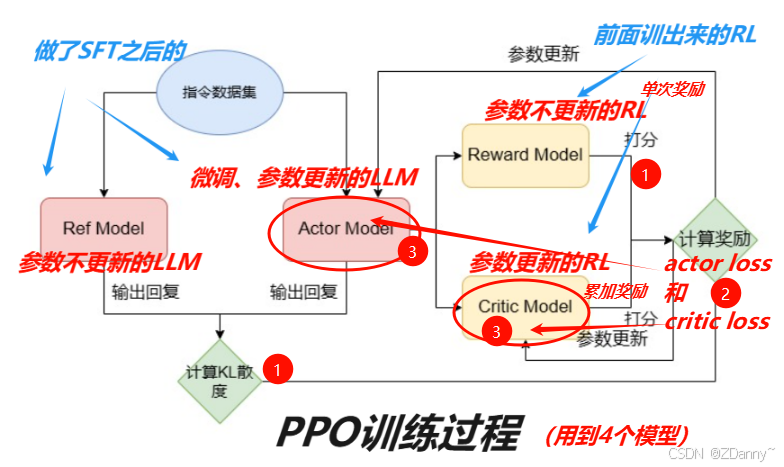 (ps:右上↗蓝字是RM不是RL,打错了)
(ps:右上↗蓝字是RM不是RL,打错了)
什么是PPO算法?
- Proximal Policy Optimization = 近端策略优化算法
- 经典的RL强化学习算法,目前最适合RLHF的
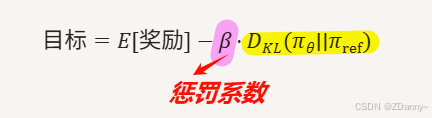
KL散度是什么?作用是什么?
广义,衡量两个概率分布之间差异的指标
RLHF中,评估actor模型和ref模型之间输出差异的指标

当作惩罚项/正则化项,防止actor太偏离ref,限制模型复杂度。防止模型疯了,丢之前的pretrain和SFT能力
RM的能力(阐述)?
是人类偏好的抽象,
RM的任务(RL中):对LLM的回复(input)进行打分(output)
本质是文本分类模型,隐藏层输出✔️,分类层输出❌
RM的难点和挑战?
- 偏好排序如何转成分数?
模型结构的最后加上线性层做映射 - PPO训练过程显存占用大
| 模型配置 | 总显存占用 | 卡 | 单卡显存占用 |
|---|---|---|---|
| 4个都是7B | ≈240G | 4×"GPT-3" (A100 80G) | ≈60G |
- 训练复杂,门槛高
LLM三阶段:DPO ——RLHF平替
- = Direct Preference Optimization = 直接偏好优化
- 监督学习的思路,
- 直接学人类偏好(偏好数据出发),不用先训练奖励函数(RM)然后更新参数
核心思路:
- DPO的RM:不用显式训,而是直接通过
偏好data构造的损失函数 - 再将损失值反向传播更新参数。只用到2个LLM
RLHF vs DPO
