GPU集群扩展:Ray Serve与Celery的技术选型与应用场景分析
当你需要处理大规模并行任务,特别是涉及GPU集群的场景时,Ray Serve和Celery是两个主要选择。但它们的设计理念完全不同:
Celery是分布式任务队列,把任务推到broker,worker拉取执行。它的核心是扇出扇入(fan-out/fan-in),特别适合大批量离线处理。Ray Serve是模型服务平台,基于Ray集群,专门为低延迟、高并发的在线推理设计,天生支持GPU资源调度。
这两者最大的分水岭在GPU扩展能力上。如果你的工作负载主要是GPU密集型的推理服务,Ray Serve的资源感知调度会让你省很多心。如果是CPU密集的批处理任务,Celery的成熟生态可能更实用。
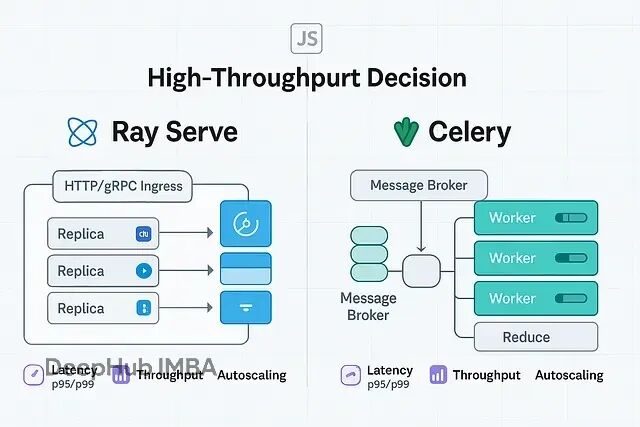
扩展任务 vs 扩展副本
Celery的核心是分布式任务队列。你往Redis或RabbitMQ里扔任务,worker进程拉取执行,结果存到backend。并发控制很明确,扇出扇入的优先级最高(groups、chains、chords)。整个架构围绕工作流和后台作业设计。
Ray Serve是基于Ray的模型服务层。你声明deployments(Python函数或类),Serve负责扩展replicas、路由请求、跨集群分配CPU/GPU资源。它的思路是把低延迟服务做到集群规模。
Celery扩展的是任务,Ray Serve扩展的是副本。前者适合批处理,后者适合在线服务。
快速选型参考
高QPS在线推理(HTTP/gRPC),混合GPU/CPU工作负载 → Ray Serve。自动扩展副本,资源感知调度,原生ASGI支持。
大规模离线批处理需要结果聚合 → Celery。成熟的任务语义,简单的扇出扇入,worker pool管理直接。
Web应用偶尔有重计算任务 → 两者结合。FastAPI/Serve处理交互路由,Celery处理后台突发任务。
已有严格的broker工作流 → Celery。无缝接入现有Redis/RabbitMQ基础设施。
多节点服务有严格p95/p99延迟要求 → Ray Serve。背压感知路由和副本自动扩展。
如果你的需求是p95/p99延迟,Serve的请求路由和自动扩展能让用户感知的队列保持很短。你扩展的是副本而不是进程,每个副本可以申请GPU而不需要自己写调度逻辑。
如果你追求的是跨数百万独立任务的总完成量,Celery的broker模型简单粗暴但有效。把任务列表丢进队列,让worker 处理,然后用chord做结果归约。
代码实例对比
Ray Serve的自动扩展HTTP部署:
from ray import serve
from starlette.requests import Request
import numpy as np @serve.deployment(ray_actor_options={"num_cpus": 1})
@serve.ingress # exposes ASGI-compatible handlers
class Scorer: async def __call__(self, request: Request): body = await request.json() x = float(body.get("x", 0)) # pretend model math return {"score": float(np.tanh(x))} app = Scorer.bind()
定义一次deployment,Serve就会在压力上升时启动多个副本,把它们分配到可用的节点/GPU上,并做好流量路由。你的延迟SLO会指导选择的自动扩展策略。
Celery的大规模扇出和弦:
from celery import Celery, group, chord app = Celery( "proj", broker="redis://localhost/0", backend="redis://localhost/1",
) @app.task
def score(n: int) -> int: # CPU-light mock; replace with real work return n * n @app.task
def summarize(results): return {"count": len(results), "sum": sum(results)} def run_batch(ns): # fan-out -> fan-in jobs = group(score.s(n) for n in ns) result = chord(jobs)(summarize.s()) return result.get(timeout=600)
每个worker进程从队列拉取任务,
--concurrency
控制本地并行度。groups和chords让大批量处理变得可理解,不需要自己实现归约器。
GPU资源感知
Serve理解资源。如果deployment申请
num_gpus=1
和
num_cpus=0.5
,Ray会精确调度副本到对应硬件。实际效果是你可以高密度打包GPU节点,保持高利用率而不需要手动管理设备ID。
Celery是资源无关的。这是优势也是负担。你可以跑GPU任务,但需要自己管理——每设备队列、路由键、精心规划容量避免超订。
GPU扩展场景下,两者的运维复杂度差异巨大。Ray Serve基本是开箱即用,Celery需要大量定制化工作。
真实场景案例
Celery的运维优势很明显:worker pool管理简单直接,重试和退避机制稳定,扇出扇入不需要外部orchestrator。但broker调优很关键(visibility timeout、acks-late、持久性配置),结果backend容易膨胀需要及时清理,崩溃时的重复执行问题需要精确的ack处理。
Serve的运维体验更现代:原生HTTP/gRPC入口减少中间件,副本自动扩展基于实际请求压力,backpressure在deployment边界可见便于延迟分析。代价是你要掌握整个Ray runtime——集群生命周期、可观测性、调度机制都有学习成本。对纯离线批处理来说可能过重。
下面介绍三个比较有代表性的案例:
夜间(空闲)特征提取,3000万记录因为简单Celery胜出。3000万ID推到Redis队列,200个worker跑spot实例,chord聚合计数。吞吐量线性扩展,失败通过重试和幂等任务控制。
文本embedding API,p99要求150ms以内Serve胜出。单deployment每副本申请
num_gpus=1
。负载上升时Serve添加副本并分配到GPU节点。延迟稳定因为请求队列从不积压超过每副本几个in-flight请求。
通用Web应用有突发重任务两者并用。FastAPI/Serve处理同步endpoints,重计算任务(PDF渲染、数据压缩)交给Celery,这样交互路径不会阻塞。你可以混用他们两个
总结
技术选型没有银弹,关键在于理解工作负载的本质特征。Ray Serve的核心价值在于服务化思维——自动扩展副本、资源感知调度、背压控制,这些特性让它在低延迟、高并发的GPU推理场景中表现出色。而Celery的任务队列模型经过多年验证,在大规模批处理和结果聚合方面几乎无可替代。
选择的关键在于识别瓶颈所在。如果你的应用需要严格的延迟SLA和动态扩展能力特别是涉及GPU资源调度时,Ray Serve的现代化架构会让运维变得轻松。如果你面对的是海量离线数据处理需要可靠的扇出扇入机制,Celery的成熟生态和简单直接的并发模型更适合。
在实际项目中,两者并非互斥选择。许多团队采用混合架构:用Ray Serve处理用户交互路径上的实时推理,用Celery处理后台的数据处理和模型训练任务。这种组合既保证了前端响应性能,又充分利用了后端批处理的资源效率。
https://avoid.overfit.cn/post/bd6296f2d7eb4ca69af3bc9b00914594