分享一种常被忽略的芯片死锁
1. 前言
芯片研发中对死锁二字谈之色变,很多死锁要依靠正向分析去发现,simulation的大量回归也不一定好撞见,更别提如果无效simulation在瞎跑。有些公司使用formal去发现死锁,但formal随着深度的增加,证明难度指数增长,而且死锁一般需要很深的深度才能发现。本文分享一种经常会被错过的死锁模型,只要在我们激励中增强一些特性,依靠simulation来发现它们也不是什么难事的。
2. 模型介绍
如图1为该死锁模型,看起来是不是很简单,参与者就两个:master和slave。Master发起request需要slave做一些事情,slave反馈回response告知master这件事做的怎么样了。但就是这样简单的通信场景没有配合好就暗含死锁风险。
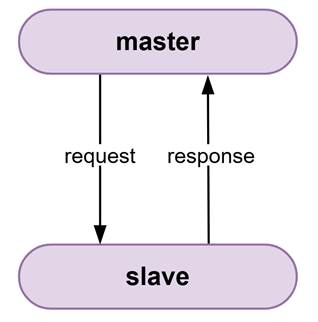
图1 死锁模型
为什么这个模型会死锁呢?比如master和slave都比较拧巴,master一定要让slave做某件事,它才会继续接下来的执行操作,但slave一直不做这件事,它们两个一直这样杠着是不是就死循环了?
识别到这个死锁存在的可能后,解决就很简单了,既然两个人都是倔驴,就至少劝说其中一个不要当倔驴了,退一步海阔天空,好好过日子。下面有两个例子来说明如何解决,一个是master不当倔驴(AXI master写数据),另一个是slave不当倔驴(slave ECC屏蔽)。
3. AXI master写数据
这个例子中,master是AXI master,slave是下游memory,如图2所示。AXI master内部有一个状态机FSM,它控制这AXI写数据的过程。当AXI master往下游发起AW/W后,下游返回response error话,那么这个状态机会跳转到重新发送的状态。如果下游slave memory出现问题,出现always fault region,则会一直返回response error,AXI master的状态机就会反复循环跳转,无法结束,这就导致AXI master出现卡壳。
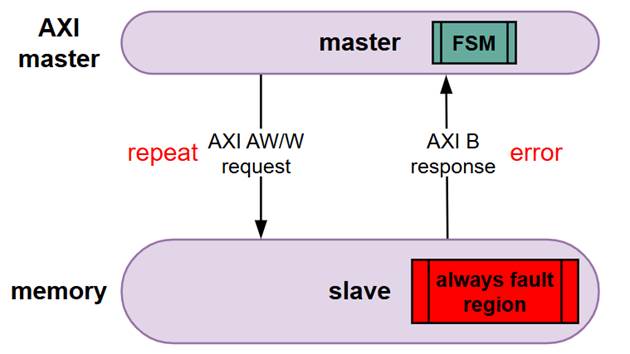
图2 AXI 写数据
由于下游slave返回的response情况比较多,要解这个问题,就需要AXI master自己主动放弃一定要发送这笔AXI 写数据的执念,比如转换为上报一个imprecise fault之类,表示该笔写数据出现问题。
4. Slave ECC屏蔽
这个例子中,master的CPU core,slave是cache系统,假设cache是四路组相联。Master发出cacheable load指令往slave里找数据,如果cache的某个way发生ECC错误,那么Master会重新发起load指令去重读数据,也就是replay。在这种情况下,如果cache RAM的某set/way发生了永久性损坏,那么访问该RAM的set/way会一直上报ECC错误,然后master也无脑的一直replay,就出现了死锁现象。
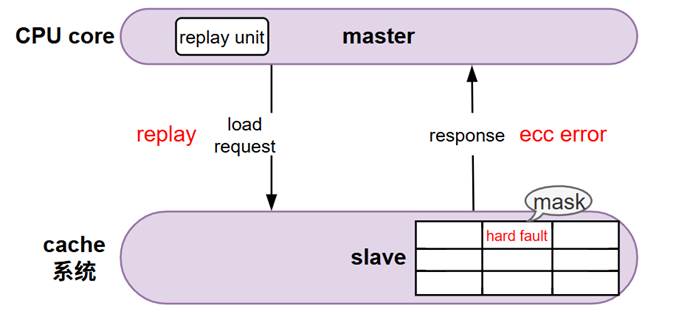
图3 Slave ECC屏蔽
这个问题的解法是靠cache系统来屏蔽掉有ECC错误的set/way,这样master下次replay时就不会遇到ECC,终究还是要有一方做出妥协。
5. 激励增强
基于以上的分析,在激励实现中,对于slave stimulus,一定要实现always fault regions,也就是master如果访问到该区间,slave一定返回response error。对于master stimulus中,也可以针对slave返回的某种响应一定做replay。
