vggt代码详解
参考VGGT|基于视觉几何的 Transformer 网络 代码详解_vggt 源代码-CSDN博客
VGGT:Visual Geometry Grounded Transformer&&代码逐行解析(一)-CSDN博客
VGGT[CVPR 2025 BEST PAPER] 论文 + 代码 最详细解析 新手小白友好型 - double-M的文章 - 知乎
https://zhuanlan.zhihu.com/p/1922807676762567215
CVPR 2025|VGGT|基于视觉几何的 Transformer 网络-CSDN博客
一、Block类
标题成员变量(你构造的结构)
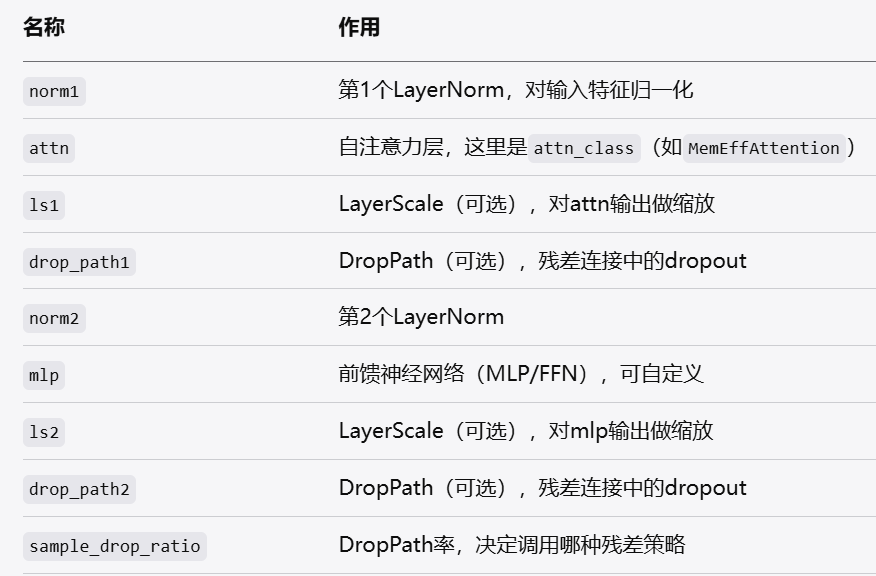
Block的forward流程
def attn_residual_func(x, pos=None):return self.ls1(self.attn(self.norm1(x), pos=pos))
def ffn_residual_func(x):return self.ls2(self.mlp(self.norm2(x)))def attn_residual_func
归一化 -> 自注意力 -> LayerScale
def ffn_residual_func(x):
归一化 -> MLP -> LayerScale
if self.training and self.sample_drop_ratio > 0.1:
# 训练时大DropPath率,使用stochastic depth残差
x = drop_add_residual_stochastic_depth(
x, pos=pos, residual_func=attn_residual_func, sample_drop_ratio=self.sample_drop_ratio
)
x = drop_add_residual_stochastic_depth(
x, residual_func=ffn_residual_func, sample_drop_ratio=self.sample_drop_ratio
)
elif self.training and self.sample_drop_ratio > 0.0:
# 训练时小DropPath率,普通DropPath残差
x = x + self.drop_path1(attn_residual_func(x, pos=pos))
x = x + self.drop_path1(ffn_residual_func(x)) # FIXME: drop_path2
else:
# 推理阶段(或无DropPath),正常残差
x = x + attn_residual_func(x, pos=pos)
x = x + ffn_residual_func(x)
训练时用DropPath或StochasticDepth随机丢弃部分残差分支(以增强正则化)
推理时只做普通残差
每个Block的工作流程(结构图)
A[输入x] --> L1[LayerNorm1]
L1 --> ATN[MemEffAttention/自定义Attention]
ATN --> LS1[LayerScale1]
LS1 --> DP1[DropPath1]
DP1 --> R1[残差加法1]
R1 --> L2[LayerNorm2]
L2 --> MLP[MLP/FFN]
MLP --> LS2[LayerScale2]
LS2 --> DP2[DropPath2]
DP2 --> R2[残差加法2]
R2 --> Out[输出x]
forward主逻辑就是:归一化->注意力->LayerScale->DropPath->残差->归一化->MLP->LayerScale->DropPath->残差
for blk in self.blocks:if self.training:x = checkpoint(blk, x, use_reentrant=self.use_reentrant)else:x = blk(x)block就是 Transformer 中的“层”,包含自注意力+MLP等结构for blk in self.blocks:是让输入的tokens依次通过每一层Transformer Block,每一层都更新token特征,共创建24个Block-
如果训练时用
checkpoint包裹,则是为了节省显存(梯度反向传播时再重新计算中间激活值)。
二、机器学习相关
1.浅层深层特征融合
- 浅层特征:提供零散的拼图碎片(靠近输入层,细节清晰,但不知道拼出来是什么)。
- 深层特征:提供拼图完成图(靠近输出层,语义,知道最终是“城堡”,但碎片模糊)。
- 特征融合:
把完成图(深层)当作指导,将碎片(浅层)按图拼合——既知道目标(语义),又保留碎片细节(位置精准)。
| 特征类型 | 提取位置 | 信息类型 | 分辨率 | 感受野 | 典型用途 |
|---|---|---|---|---|---|
| 浅层特征 | 网络前几层 | 细节(边缘、纹理) | 高 | 小 | 小目标检测、细节恢复 |
| 深层特征 | 网络后几层 | 语义(物体类别) | 低 | 大 | 物体分类、场景理解 |
深层特征上采样(放大),浅层特征下采样(缩小),最后每层分辨率一致
2.卷积
参考【深度学习笔记】卷积的输入输出的通道、维度或尺寸变化过程_卷积核个数与输入输出通道数关系-CSDN博客
nn.Conv2d(conv2_in_channels, head_features_2, kernel_size=3, stride=1, padding=1),
conv2_in_channels:输入特征图的通道数(即上一层的输出通道数)。-
head_features_2:输出通道数(由out_channels参数指定)。 -
kernel_size=3:使用3×3卷积核 - stride=1:步长为1
padding=1:边缘填充1圈像素
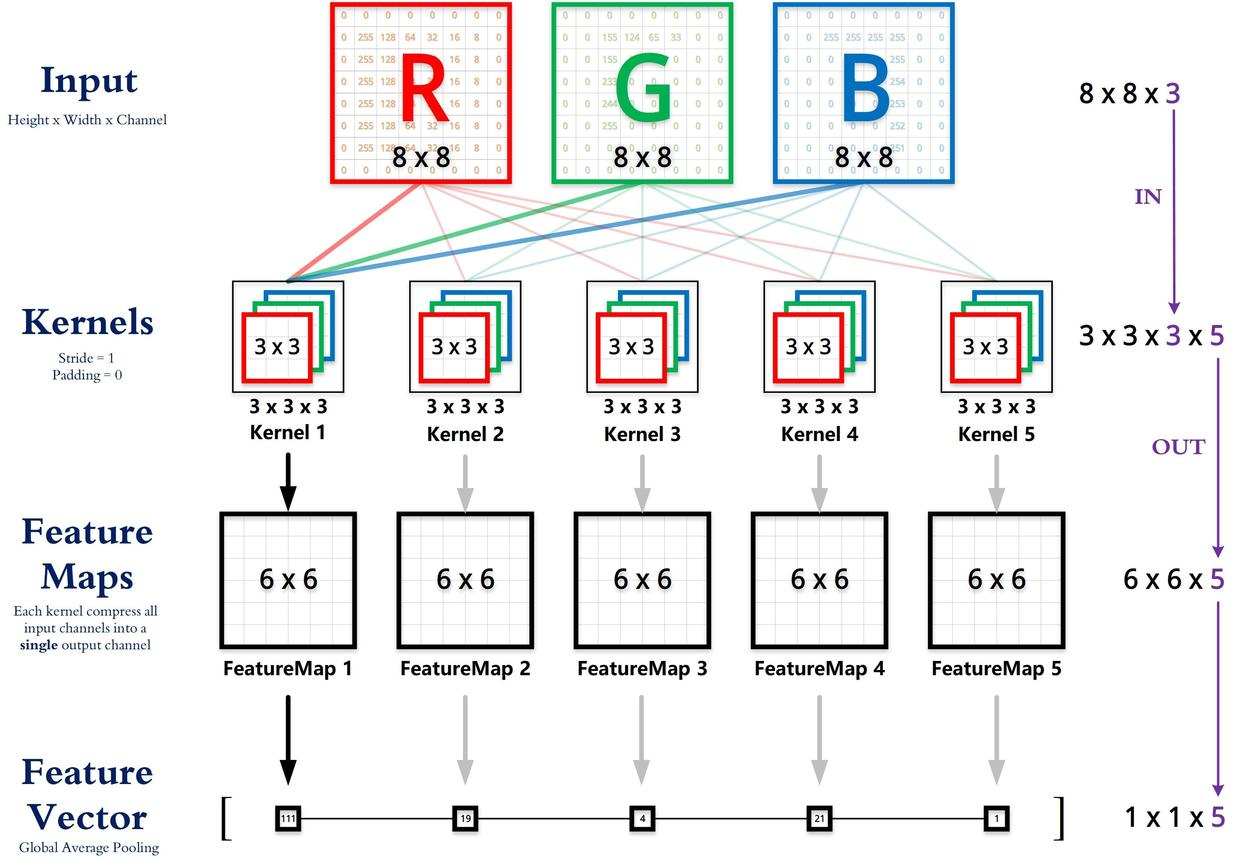
卷积核的输入通道数(in depth)由输入矩阵的通道数所决定。
输出矩阵的通道数(out depth)由卷积核的输出通道数所决定。
输出矩阵的高度和宽度由下面的公式计算,没有考虑Bias 参数。
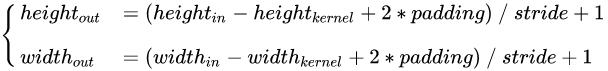
除法部分有小数向下取整
1 x 1 卷积就是将输入矩阵的通道数量缩减后输出(512 降为 32),并保持它在宽度和高度维度上的尺寸(227 x 227)。
- 原理是什么?卷积核的个数决定了输出的特征图的个数,也就是特征图的通道数,或者说是卷积后的输出的通道数,因此可以使用远小于原来的输入特征图通道数个1×1卷积核来压缩通道数。

反卷积
三、demo.gradio.py
流程
1. 系统初始化
- 加载VGGT模型权重
- 初始化CUDA设备支持
2. 用户数据上传处理
handle_uploads() → update_gallery_on_upload()- 用户上传视频或图片
- 视频按1帧/秒提取关键帧
- 创建唯一目录存储处理文件
- 显示预览图库
3. 3D重建核心流程
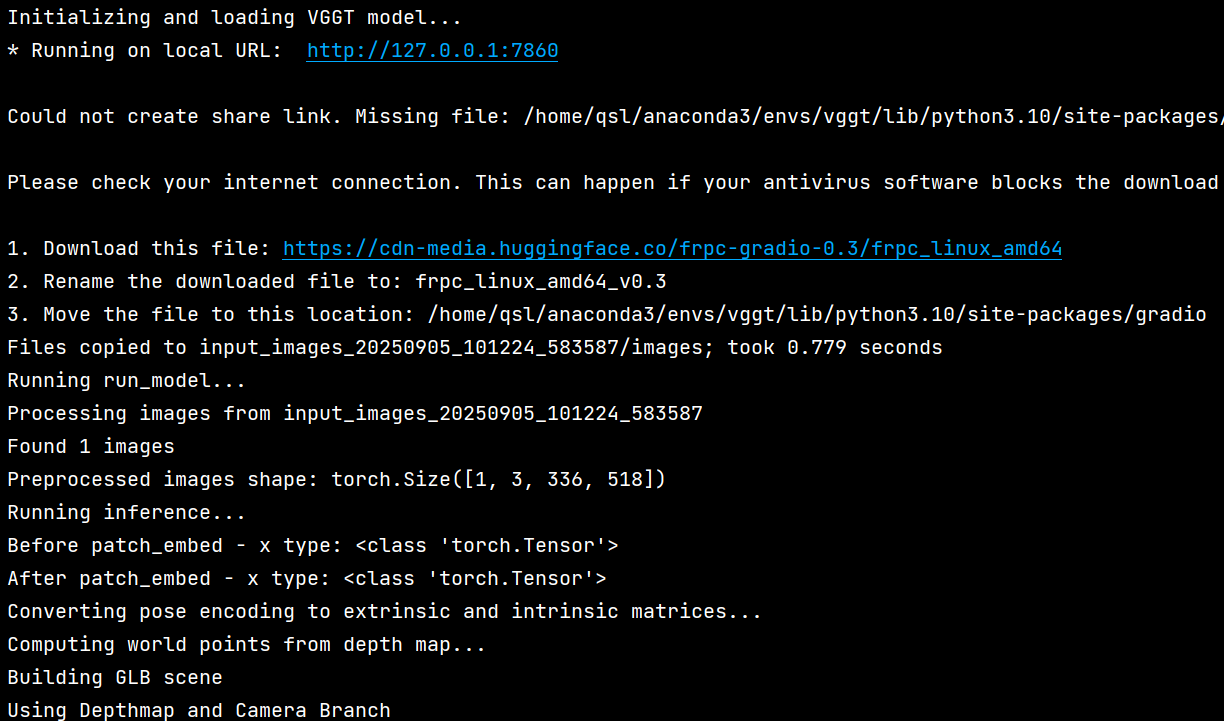
submit_btn.click() → gradio_demo() → run_model() 3.1 图像预处理
- 读取目标目录中的所有图像
- 使用 [load_and_preprocess_images()] 统一处理为518×518尺寸
- 转换为PyTorch张量格式
3.2 模型推理
- 运行VGGT模型进行推理
- 输出包括:
- [pose_enc]: 相机姿态编码(9维)
- [depth]: 深度图
- world_point: 3D点云
- 等其他预测结果
3.3 坐标变换处理
- 使用 [pose_encoding_to_extri_intri()]将姿态编码转换为外参和内参矩阵
- 使用 [unproject_depth_map_to_point_map()]从深度图生成3D世界坐标
3.4 3D可视化生成
- 保存预测结果为 `.npz` 文件
- 使用 [predictions_to_glb()] 将预测结果转换为GLB格式3D模型
- 在Gradio界面中显示3D模型
4. 交互式可视化调整
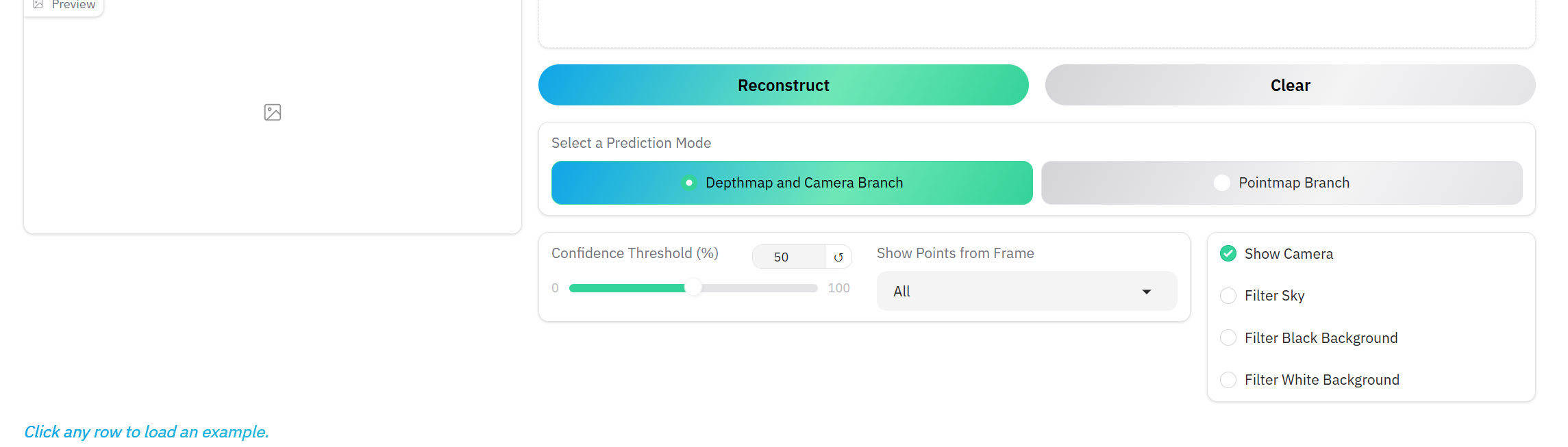
update_visualization()- 置信度阈值过滤
- 帧选择过滤
- 相机位置显示控制
- 天空/背景点过滤
- 预测模式选择
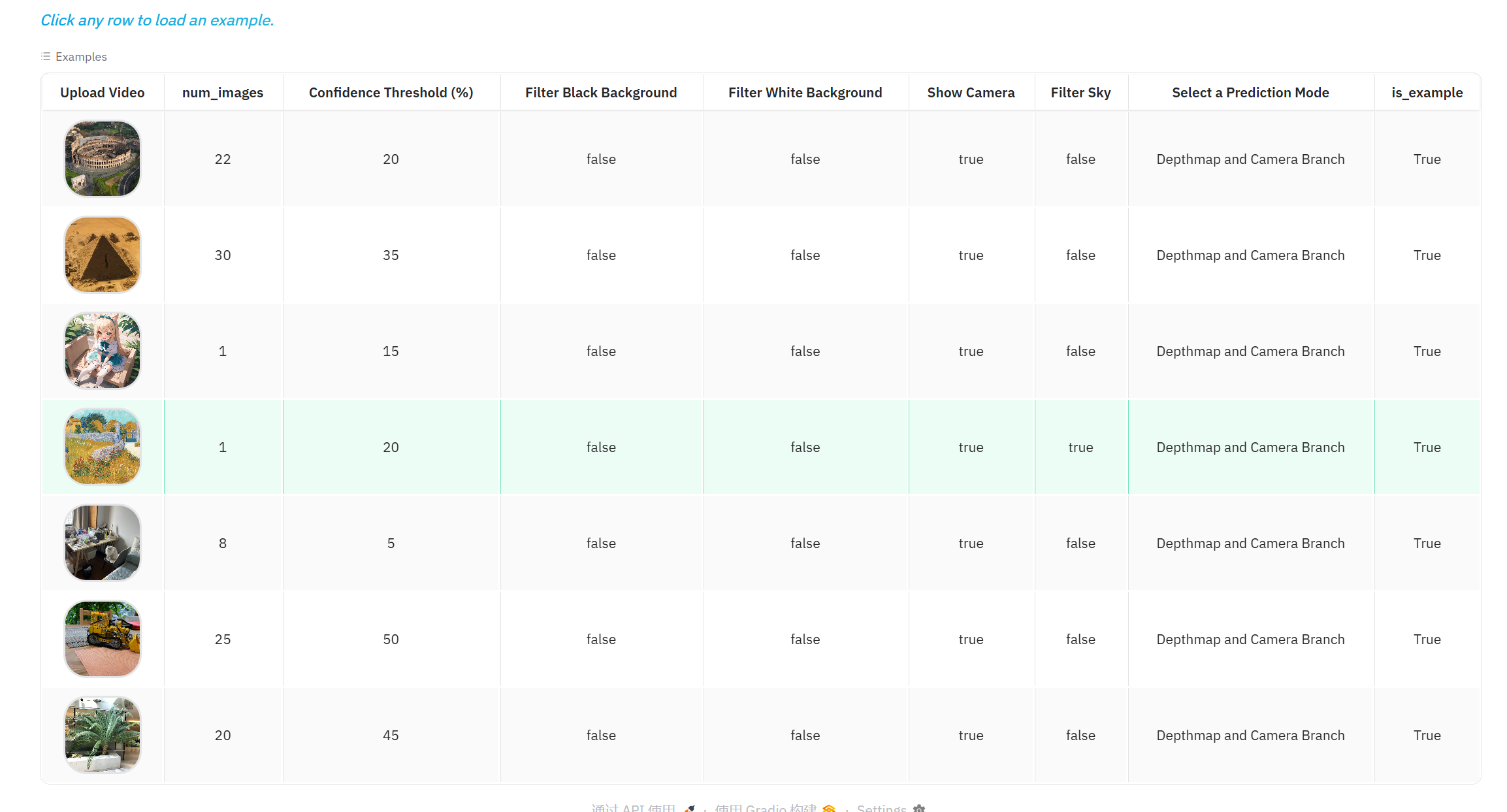
5. 示例数据处理
- 提供预设示例视频
- 一键加载和处理示例数据
整个流程实现了从2D图像到3D点云的完整重建和可视化,用户可以通过界面交互调整重建结果的显示效果。
1.is_example
只有当 is_example 为 "False" 时,才允许进行实时参数调整和可视化更新
加载示例数据时设置为true,自己上传文件时没有设置,保持之前的值
点击“重建”后将 is_example 设置为 "False"
2.运行结果

3.vggt
其关键组件和输出包括:
- Aggregator(特征聚合器):这是VGGT的核心。它使用DINOv2模型从输入图像中提取图像块(Patch Tokens),并为每张图像添加一个相机标记(Camera Token)和几个注册标记(Register Tokens)。然后,通过交替注意力机制(Alternating-Attention)(帧内注意力和全局注意力)处理这些标记,生成丰富的特征表示。
- 预测头(Heads):Aggregator产生的特征会被送到不同的预测头进行特定任务的预测:
- Camera Head:从特征中预测每一帧图像的相机参数。其输出是一个9维的姿态编码(
pose_enc),参数化了相机的旋转(四元数)、平移向量和焦距/视场角信息。该头部采用迭代细化的方式,逐步提升预测精度。 - DPT Head:用于生成密集预测图,例如深度图(
depth) 和点图(Point Map)。它基于DPT(Dense Prediction Transformer)结构,将特征转换为密集的输出。 - Track Head:用于实现点跟踪功能。
- Camera Head:从特征中预测每一帧图像的相机参数。其输出是一个9维的姿态编码(
- 姿态编码 (
pose_enc) 被解码为具体的相机外参矩阵 (extrinsic) 和相机内参矩阵 (intrinsic)。外参矩阵描述了相机在世界坐标系中的位置和朝向,内参矩阵描述了相机内部的成像参数。 - 利用深度图、相机外参和内参,通过反投影将图像中的每个像素点转换到 3D 世界坐标系中,生成点云(世界坐标)
四、由利用深度图、外参和内参计算世界坐标
unproject_depth_map_to_point_map(depth_map, extrinsic, intrinsic)
此函数利用深度图、相机外参和内参,通过反投影计算图像中每个像素点在3D世界坐标系中的位置。
- 原理:对于深度图中的每个像素点
(u, v),其深度值为 Z_c。利用相机内参矩阵可以将其反向投影到相机坐标系下的3D点(X_c, Y_c, Z_c)。再通过相机外参矩阵(逆变换)将其转换到世界坐标系,得到最终的3D点(X_w, Y_w, Z_w)。