SemiSAM+:在基础模型时代重新思考半监督医学图像分割|文献速递-深度学习人工智能医疗图像
Title
题目
SemiSAM+: Rethinking semi-supervised medical image segmentation in theera of foundation models
SemiSAM+:在基础模型时代重新思考半监督医学图像分割
01
文献速递介绍
医学图像分割相关研究内容翻译 医学图像分割旨在从医学图像中勾勒出特定的解剖结构和病变区域,是众多图像引导治疗技术中的核心组成部分。精准的分割结果能够提供器官与肿瘤的关键体积及形态信息,为多种临床应用提供支持,例如疾病进展监测、治疗方案制定以及治疗过程引导等(Antonelli 等,2022;Lalande 等,2022;Ma 等,2022;Zhang 等,2024b)。 尽管深度学习在医学图像分割领域已取得显著成效,但训练过程对大规模带标注数据集的依赖仍是一大瓶颈,在医学领域尤为突出——专家标注不仅成本高昂,且耗时耗力(Tajbakhsh 等,2020;Shi 等,2024)。获取大规模标注医学数据集的难度源于多方面因素:首先,医学图像标注需临床专业人员具备领域专长,导致标注过程成本高、资源消耗大;其次,计算机断层扫描(CT)、磁共振成像(MRI)等常用医学成像模态生成的是三维体数据,需逐切片标注,相较于二维图像标注,人工工作量大幅增加;此外,医疗机构间的数据共享限制进一步降低了标注数据集的可获取性(DuMont Schütte 等,2021)。 为缓解人工标注的负担,研究人员在开发“标注高效型”深度学习医学图像分割方法上投入了大量精力(Cheplygina 等,2019;Zhang 等,2021;Zhao 等,2023)。在实际场景中,未标注数据往往较为充足,因此半监督学习(SSL)通过将有限带标注数据与易获取的未标注数据高效结合,成为一种极具吸引力的解决方案与前沿研究方向(Jiao 等,2023)。不同于早期通过迭代方式生成伪标签并更新分割模型的思路(Lee 等,2013),近年来半监督医学图像分割的研究重点在于将未标注数据通过无监督正则化融入训练过程,例如在不同数据扰动下(Yu 等,2019;Zhang 等,2023)或不同模型间(Luo 等,2022;Song 和 Wang,2024)强制保持预测一致性。总体而言,这些研究多围绕“以模型为中心”的半监督学习改进展开,核心是设计新型策略生成无监督监督信号,以更高效地挖掘未标注图像中蕴含的“暗知识”。然而,这些半监督方法应用于新分割任务时,仍需标注一小部分数据才能达到可接受的性能;在标注数据极度有限的场景下,难以取得理想效果。 计算机视觉领域基础模型的兴起——以任意分割模型(SAM)(Kirillov 等,2023)及后续的 SAM 2(Ravi 等,2025)为代表——已在各类自然图像与视频分割任务中展现出卓越的零样本分割能力(Li 等,2023;Yang 等,2023)。尽管近期研究表明,由于自然图像与医学图像存在差异,SAM 直接应用于医学图像分割时性能有限(Zhang 等,2024a;Zhang 和 Shen,2024),但借助基础模型的知识库,它仍为解决标注稀缺问题提供了新机遇:在人工标注图像稀缺时,可作为可靠的伪标签生成器指导分割任务。 作为利用类 SAM 可提示基础模型解决半监督医学图像分割问题的初步尝试,我们此前的研究工作 SemiSAM(Zhang 等,2024c)旨在挖掘 SAM 的潜力,通过新增一个监督分支实现一致性正则化;已有多项研究(Ali 等,2024)对该方法进行了实现与扩展,验证了其有效性。如图 1 所示,现有“以模型为中心”的半监督学习改进思路,核心是设计新型正则化策略,以更高效地利用未标注数据进行训练。在标注数据占比为 10% 或 20% 等常规半监督设置下,这些方法能实现可观的性能提升;但在仅含 1 张或几张标注图像的“标注极度稀缺”场景中,却难以达到理想效果。可能的原因在于:极度有限的监督信号无法让模型学习到足够的判别性信息,导致预测结果不确定性高,且挖掘未标注数据价值的空间受限。为此,我们摒弃这一范式,转而利用基础模型的预训练知识指导学习过程,尤其在标注极度有限的场景下,该思路能带来显著性能提升。 本文提出SemiSAM+——一种由基础模型驱动的半监督学习框架,旨在利用有限标注数据高效完成医学图像分割任务。SemiSAM+ 包含两个核心组件:一是可训练的“任务专用分割模型”(作为专用模型),用于处理下游分割任务;二是一个或多个“可提示基础模型”(作为通用模型),这类模型经大规模数据集预训练,具备零样本泛化能力。参考现有半监督学习框架的设计逻辑,专用模型的更新同时依赖两部分损失:基于标注数据的有监督损失,以及基于未标注数据的无监督正则化损失。 在 SemiSAM+ 中,采用“专用-通用模型协同学习”机制,并引入额外的“置信度感知正则化”,以高效利用通用模型的监督信号,避免在标注极度有限的情况下,通用模型对专用模型的学习过程产生误导。训练阶段,可训练的专用模型生成位置提示,与冻结的通用模型交互以获取伪标签;随后,通用模型的输出为专用模型提供信息丰富且高效的监督信号,进而反哺专用模型,提升其自动分割效果与提示生成质量。 作为初步版本(Zhang 等,2024c)的扩展,SemiSAM+ 在方法层面进行了大量改进,并通过广泛实验验证了其“即插即用”的高效性——可集成多个通用模型实现知识融合,也可适配任意专用模型以进一步提升特定任务的性能。此外,本文还补充了更全面的文献综述、对相关工作的深入探讨,以及针对不同模态、不同分割目标任务的更广泛实验。我们期望此项研究能为“标注高效型”医学图像分割的后续深入研究提供助力,最终推动可临床应用的医疗技术发展。 本文的研究贡献可总结如下: 1. 提出一种由基础模型驱动的半监督学习框架,用于利用有限标注数据高效完成医学图像分割任务。通过“专用-通用模型协同学习”机制,借助通用基础模型的预训练知识,促进专用半监督学习模型的训练。 2. 该框架具备“即插即用”的高效性:可集成多个通用模型实现知识融合,也可适配任意专用模型,进一步提升特定任务的性能。 3. 框架应用时无额外计算开销:推理阶段仅需轻量级专用模型,无需调用通用基础模型(见图 3)。 4. 针对不同模态的多种医学图像分割任务开展了广泛且全面的实验,验证了该框架在适配不同专用模型与通用模型时的鲁棒性和泛化性。
Abatract
摘要
Deep learning-based medical image segmentation typically requires large amount of labeled data for training,making it less applicable in clinical settings due to high annotation cost. Semi-supervised learning (SSL) hasemerged as an appealing strategy due to its less dependence on acquiring abundant annotations from expertscompared to fully supervised methods. Beyond existing model-centric advancements of SSL by designing novelregularization strategies, we anticipate a paradigmatic shift due to the emergence of promptable segmentationfoundation models with universal segmentation capabilities using positional prompts represented by SegmentAnything Model (SAM). In this paper, we present SemiSAM+, a foundation model-driven SSL frameworkto efficiently learn from limited labeled data for medical image segmentation. SemiSAM+ consists of oneor multiple promptable foundation models as generalist models, and a trainable task-specific segmentationmodel as specialist model. For a given new segmentation task, the training is based on the specialist–generalistcollaborative learning procedure, where the trainable specialist model delivers positional prompts to interactwith the frozen generalist models to acquire pseudo-labels, and then the generalist model output provides thespecialist model with informative and efficient supervision which benefits the automatic segmentation andprompt generation in turn. Extensive experiments on three public datasets and one in-house clinical datasetdemonstrate that SemiSAM+ achieves significant performance improvement, especially under extremely limitedannotation scenarios, and shows strong efficiency as a plug-and-play strategy that can be easily adapted todifferent specialist and generalist models.
基于深度学习的医学图像分割翻译 基于深度学习的医学图像分割通常需要大量带标注数据用于训练,由于标注成本高昂,其在临床场景中的适用性受限。半监督学习(SSL)因相较于全监督方法对专家标注数据的依赖度更低,已成为一种极具吸引力的解决方案。 目前,半监督学习的现有研究多围绕“以模型为中心”展开,通过设计新型正则化策略实现性能提升;而随着具备通用分割能力的“可提示分割基础模型”(如基于位置提示的任意分割模型SAM)的出现,我们认为该领域正迎来范式转变。本文提出SemiSAM+——一种由基础模型驱动的半监督学习框架,旨在利用有限标注数据高效完成医学图像分割任务。 SemiSAM+包含一个或多个“可提示基础模型”(作为通用模型),以及一个可训练的“任务专用分割模型”(作为专用模型)。针对特定新分割任务,训练过程基于“专用-通用模型协同学习”机制:可训练的专用模型生成位置提示,与冻结的通用模型交互以获取伪标签;随后通用模型的输出为专用模型提供信息丰富且高效的监督信号,反过来助力专用模型优化自动分割效果与提示生成质量。 在三个公开数据集及一个内部临床数据集上开展的大量实验表明:SemiSAM+实现了显著的性能提升,尤其在标注数据极度有限的场景下表现突出;同时,该框架具备“即插即用”的高效性,可轻松适配不同的专用模型与通用模型。
Method
方法
3.1. Preliminaries
Semi-supervised learning aims to utilize unlabeled data in conjunction with labeled data to train higher-performing segmentation modelswith limited annotations. Given a dataset for training, we annotate asmall subset with 𝑀cases as 𝐿 = {𝑥𝑖 𝑙 , 𝑦𝑖}𝑀 𝑖=1 based on the availablebudget, while the remaining unlabeled set with 𝑁unlabeled casesas 𝑈 = {𝑥𝑖 𝑢 } 𝑁 𝑖=1, where 𝑥𝑙 and 𝑥𝑢denote the labeled and unlabeledinput images, and 𝑦 denotes the corresponding ground truth of labeleddata. Generally, 𝐿 is a relatively small subset of the entire dataset, which means 𝑀 ≪ 𝑁. For semi-supervised segmentation settings,we aim at building a data-efficient deep learning model to learn withthe combination of densely labeled data 𝐿 and unlabeled data *𝑈* fortraining and to make the performance comparable to an optimal modeltrained over fully labeled dataset.Different from generating pseudo-labels and updating the segmentation model in an iterative manner, recent progress in semi-supervisedmedical image segmentation has been focused on incorporating unlabeled data into the training procedure with unsupervised regularization. Generally, the model is optimized based on the combinationof supervised segmentation loss 𝑠𝑢𝑝(𝜃; 𝐿) and unsupervised regularization loss *𝑢𝑛𝑠𝑢𝑝*(𝜃; 𝑈 ). Recent model-centric advancements havebeen focused on designing novel strategies for calculating unsupervised regularization loss to seek more efficient utilization of unlabeledimages.An overview of the proposed SemiSAM+ framework is illustratedin Fig. 4. SemiSAM+ consists of a trainable task-specific segmentation model as specialist model for downstream segmentation task(Section 3.2), and one or multiple promptable foundation models asgeneralist models** pre-trained on large-scale datasets with zero-shotgeneralization ability (Section 3.3). Building upon existing specialistSSL frameworks, SemiSAM+ utilizes an additional confidence-awareregularization for effective utilization of generalist model’s supervision to avoid possible misguidance and assist in annotation-efficientlearning of specialist model (Section 3.4).
3.1 预备知识 半监督学习旨在结合带标注数据与未标注数据,以有限的标注信息训练性能更优的分割模型。给定用于训练的数据集$\mathcal{D}$,在现有标注预算下,我们选取其中包含$M$个样本的子集进行标注,记为带标注数据集$\mathcal{D}_L = \{x_i^l, y_i\}_{i=1}^M$;剩余含$N$个样本的未标注部分记为未标注数据集$\mathcal{D}_U = \{x_i^u\}_{i=1}^N$。其中,$x^l$和$x^u$分别表示带标注输入图像与未标注输入图像,$y$表示带标注数据对应的真实标签(ground truth)。通常,带标注数据集$\mathcal{D}_L$在整个数据集$\mathcal{D}$中占比极小,即满足$M \ll N$($M$远小于$N$)。在半监督分割任务设置中,我们的目标是构建“数据高效型”深度学习模型:通过融合密集标注的$\mathcal{D}_L$与未标注的$\mathcal{D}_U$进行训练,使模型性能接近在全标注数据集上训练的最优模型。 不同于早期通过迭代方式生成伪标签并更新分割模型的思路,近年来半监督医学图像分割的研究重点在于:通过无监督正则化(unsupervised regularization)将未标注数据融入训练过程。通常,模型的优化目标由两部分损失结合构成:一是基于带标注数据的有监督分割损失$\mathcal{L}_{sup}(\theta; \mathcal{D}_L)$,二是基于未标注数据的无监督正则化损失$\mathcal{L}_{unsup}(\theta; \mathcal{D}_U)$($\theta$表示模型参数)。近期“以模型为中心”的半监督学习改进工作,核心聚焦于设计新型无监督正则化损失计算策略,以更高效地挖掘未标注图像的价值。 本文提出的SemiSAM+框架整体架构如图4所示。该框架包含两个核心组件: 1. 专用模型(Specialist Model):一种可训练的任务专用分割模型,用于处理下游具体分割任务(详见3.2节); 2. 通用模型(Generalist Model):一个或多个“可提示基础模型”,这类模型经大规模数据集预训练,具备零样本泛化能力(详见3.3节)。 在现有“专用模型半监督学习框架”的基础上,SemiSAM+新增了“置信度感知正则化(confidence-aware regularization)”机制:一方面可高效利用通用模型的监督信号,避免其对专用模型的学习过程产生误导;另一方面能助力专用模型实现“标注高效型”学习(详见3.4节)。 (术语说明:1. “ground truth”译为“真实标签”,指人工标注的、用于衡量模型预测准确性的标准参考数据;2. “zero-shot generalization ability”译为“零样本泛化能力”,指模型无需针对新任务进行训练,仅通过少量提示即可适配新任务的能力;3. 公式中$\mathcal{D}_L$、$\mathcal{D}_U$等符号为数据集标准表示方式,保留原符号以确保学术严谨性。)
Conclusion
结论
Although deep learning-based automatic medical image segmentation has shown remarkable performance in many tasks, it faces alimitation in clinical application as it requires a large amount of annotated data for training. Semi-supervised learning focus on learning froma small amount of labeled data and large amount of unlabeled data,which has shown the potential to deal with this challenge. However,these approaches still require a small subset of high-quality annotateddata, struggling to achieve satisfactory outcomes when faced with extremely limited labeling budgets. One possible reason is that the modelcannot learn sufficient discriminative information with extremely limited supervision. As a result, the predictions exhibit high uncertaintyand the improvement of exploiting unlabeled data is limited. Withthe introduction of segmentation foundation models represented bythe Segment Anything Model (SAM) (Kirillov et al., 2023), whichhave shown zero-shot segmentation capabilities for various new segmentation tasks with positional prompts. Despite recent work (Zhanget al., 2024a) revealing that SAM’s unsatisfying performance for directapplication to medical image segmentation tasks, it still offers newpossibilities serving as a reliable pseudo-label generator to guide thelearning procedure.To this end, we propose SemiSAM+, a foundation model-drivenannotation-efficient learning framework to efficiently learn from limited labeled data for medical image segmentation. In contrast withexisting model-centric semi-supervised methods for medical image segmentation, SemiSAM+ represents a new paradigm which focuses onutilizing pre-trained knowledge of generalist foundation models toassist in trainable specialist SSL model in a collaborative learning manner. Extensive experimental results show that adapting SemiSAM+ cansignificantly improve the performance especially in extremely limitedannotation scenarios with only one or a few labeled data. Anotheradvantage of SemiSAM+ is that it is a plug-and-play strategy that canbe easily adapted to new trainable specialist models and generalistfoundation models for more specific designs of different tasks. Whilesegmentation models trained with a small amount of annotations maynot yet meet the required accuracy and reliability for direct clinicaldeployment, SemiSAM+ can serve as an efficient tool to accelerate thehuman-in-the-loop annotation procedure for subsequent data, therebyalleviating the heavy burden on radiologists as shown in our analysis.Due to the promptable manner of generalist foundation models, ourexperiments mainly focus on single-target segmentation. Nevertheless,we validate the expansibility of SemiSAM+ to multi-target segmentation as the specialist model can be easily adapted to multi-targetsegmentation by changing the output class channels, and the generalistmodel can be adapted by prompting each target with correspondingclass-level feedback. However, the correlation between different classesfor prompting is neglected. Another limitation of current work is thatthe nature of point prompts hinders the application of the method intochallenging non-compact targets with irregular shape. Despite the integration of mask prompts alleviating the limitations of point prompts tosome extent, we aim to exploit more flexible prompt types of generalistmodels like scribble prompts (Wong et al., 2025) and semantic textprompts (Du et al., 2023) to further extend the usability in the future.We anticipate this work will act as catalysts to promote future indepth research in annotation-efficient medical image segmentation inthe era of foundation models, ultimately benefiting clinical applicablehealthcare practices.
基于深度学习的医学图像自动分割相关研究进展与本文方法阐述 尽管基于深度学习的医学图像自动分割在诸多任务中已展现出卓越性能,但其在临床应用中仍面临一项局限:模型训练需依赖大量标注数据。半监督学习专注于从少量带标注数据与大量未标注数据中学习,为应对这一挑战提供了潜力。然而,这类方法仍需一小部分高质量标注数据,在标注预算极度有限的场景下,难以取得理想效果。其中一个可能的原因是:在监督信号极度有限的情况下,模型无法学习到足够的判别性信息,导致预测结果存在较高不确定性,且对未标注数据的利用效果提升受限。 随着以“任意分割模型(SAM)”(Kirillov 等人,2023)为代表的分割基础模型问世,此类模型借助位置提示(positional prompts),已在多种新分割任务中展现出零样本分割能力。尽管近期有研究(Zhang 等人,2024a)指出,SAM直接应用于医学图像分割任务时性能欠佳,但其仍为医学图像分割领域提供了新可能——可作为可靠的伪标签生成器,为模型学习过程提供指导。 为此,本文提出一种基础模型驱动的标注高效型学习框架 SemiSAM+,旨在从有限标注数据中高效学习,以实现医学图像分割。与现有面向医学图像分割的“以模型为中心”的半监督方法不同,SemiSAM+代表了一种新范式:通过协同学习的方式,利用通用基础模型(generalist foundation model)的预训练知识,辅助可训练的专用半监督学习模型(specialist SSL model)。大量实验结果表明,SemiSAM+能显著提升模型性能,尤其在标注数据极度有限(仅含1个或少数几个带标注样本)的场景下效果突出。此外,SemiSAM+还具备“即插即用”的优势:可轻松适配新的可训练专用模型与通用基础模型,为不同任务的特定设计提供便利。 尽管仅用少量标注数据训练的分割模型,其精度与可靠性可能尚不足以直接用于临床部署,但如本文分析所示,SemiSAM+可作为一种高效工具,加速后续数据的“人机协同标注”流程,进而减轻放射科医师的繁重标注负担。 由于通用基础模型采用“可提示”的工作方式,本文实验主要聚焦于单目标分割任务。不过,我们已验证SemiSAM+向多目标分割任务扩展的可行性:对于专用模型,只需调整输出类别通道数,即可轻松适配多目标分割;对于通用模型,可通过为每个目标提供对应类别级反馈(class-level feedback)作为提示,实现多目标分割适配。但目前的方法仍存在不足:未考虑不同类别在提示过程中的关联性。 当前研究的另一项局限在于:点提示(point prompts)的特性限制了该方法在“形状不规则、非紧凑目标”这类挑战性任务中的应用。尽管掩码提示(mask prompts)的融入在一定程度上缓解了点提示的局限,但未来研究中,我们计划探索通用模型更灵活的提示类型,如涂鸦提示(scribble prompts)(Wong 等人,2025)与语义文本提示(semantic text prompts)(Du 等人,2023),以进一步拓展方法的适用范围。 我们期望本研究能起到推动作用,促进基础模型时代下“标注高效型医学图像分割”领域的深入研究,最终为可临床应用的医疗实践提供助力。
Figure
图
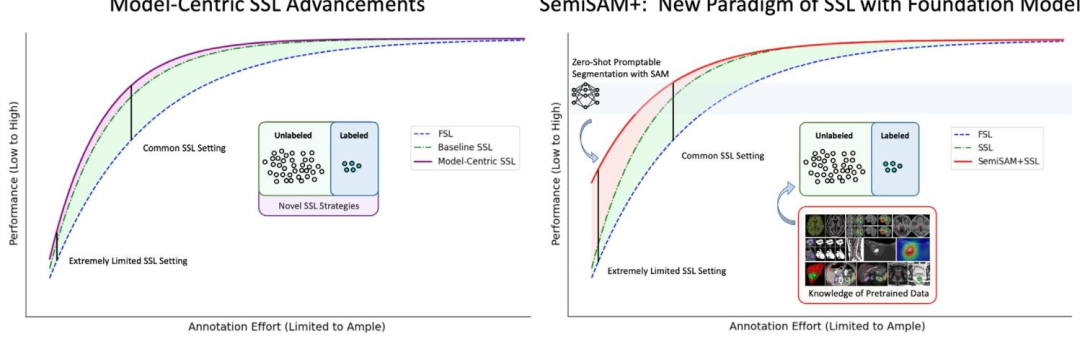
Fig. 1. Semi-supervised learning (SSL) aims to utilize unlabeled data in conjunction with limited amount of labeled data to improve the performance of fully supervised learning(FSL) using only labeled data (from blue to green). Existing model-centric SSL advancements aims to exploit more efficient utilization of unlabeled data for better performance(from green to purple). With positional prompting, the foundation model achieves acceptable zero-shot segmentation performance (in celeste). In this work, SemiSAM+ representsa new paradigm to exploit pre-trained knowledge of foundation model to assist in SSL (from green to red).
图1 半监督学习(SSL)相关方法性能对比 半监督学习(SSL)旨在结合有限带标注数据与未标注数据,提升仅使用带标注数据的全监督学习(FSL)的性能(对应图中从蓝色到绿色的提升)。现有“以模型为中心”的半监督学习改进思路,核心是更高效地利用未标注数据以进一步优化性能(对应图中从绿色到紫色的提升)。借助位置提示,基础模型可实现具有可接受度的零样本分割性能(对应图中的天蓝色部分)。本研究提出的SemiSAM+代表了一种新范式——通过利用基础模型的预训练知识辅助半监督学习,实现性能提升(对应图中从绿色到红色的提升)。
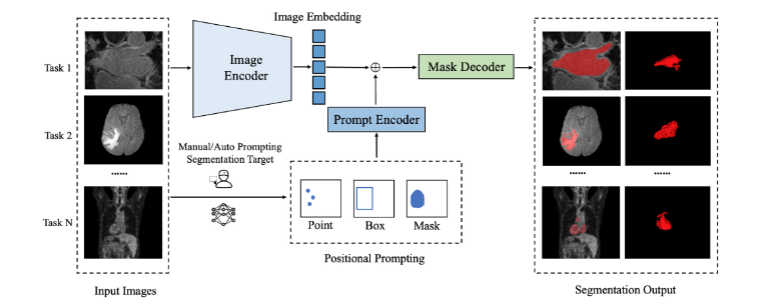
Fig. 2. An overview of segmentation foundation model represented by Segment Anything Model (SAM), which adopts an image encoder to extract image embeddings, a promptencoder to integrate user interactions via different prompt modes, and a mask decoder to predict segmentation masks by fusing image embeddings and prompt embeddings. Forany given dataset, the model can segment any target out of the image based on the positional prompting, which demonstrate universal segmentation capability to any new tasks.
图2 以任意分割模型(SAM)为代表的分割基础模型整体架构 该图展示了以任意分割模型(SAM)为代表的分割基础模型的核心架构,其主要由三部分组成: 1. 图像编码器(Image Encoder):负责提取输入图像的特征嵌入(Image Embeddings),将图像转化为计算机可理解的高维特征表示; 2. 提示编码器(Prompt Encoder):通过多种提示模式(如点、框、掩码等)整合用户交互信息,生成对应的提示嵌入(Prompt Embeddings),实现模型与用户需求的精准匹配; 3. 掩码解码器(Mask Decoder):将图像编码器输出的图像嵌入与提示编码器输出的提示嵌入进行融合,最终预测出目标区域的分割掩码(Segmentation Masks)。 对于任意给定的数据集,该模型可基于位置提示(如指定目标区域的坐标点或边界框)从图像中分割出任意目标,体现出对各类新分割任务的通用分割能力。
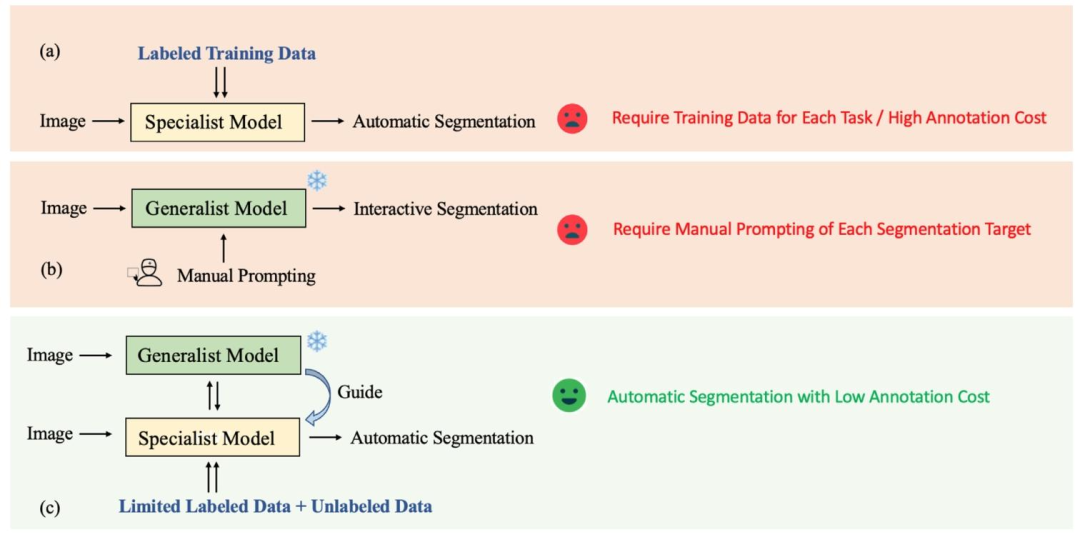
Fig. 3. Comparison of existing methods with our proposed method. (a) Specialist model for training-based task-specific automatic segmentation. (b) Generalist model for universalpromptable interactive segmentation. (c) SemiSAM+: specialist–generalist collaborative learning for annotation-efficient automatic segmentation
图3 现有方法与本文所提方法对比 (a)用于基于训练的任务专用自动分割的专用模型;(b)用于通用可提示交互式分割的通用模型;(c)SemiSAM+:面向标注高效型自动分割的专用-通用模型协同学习。
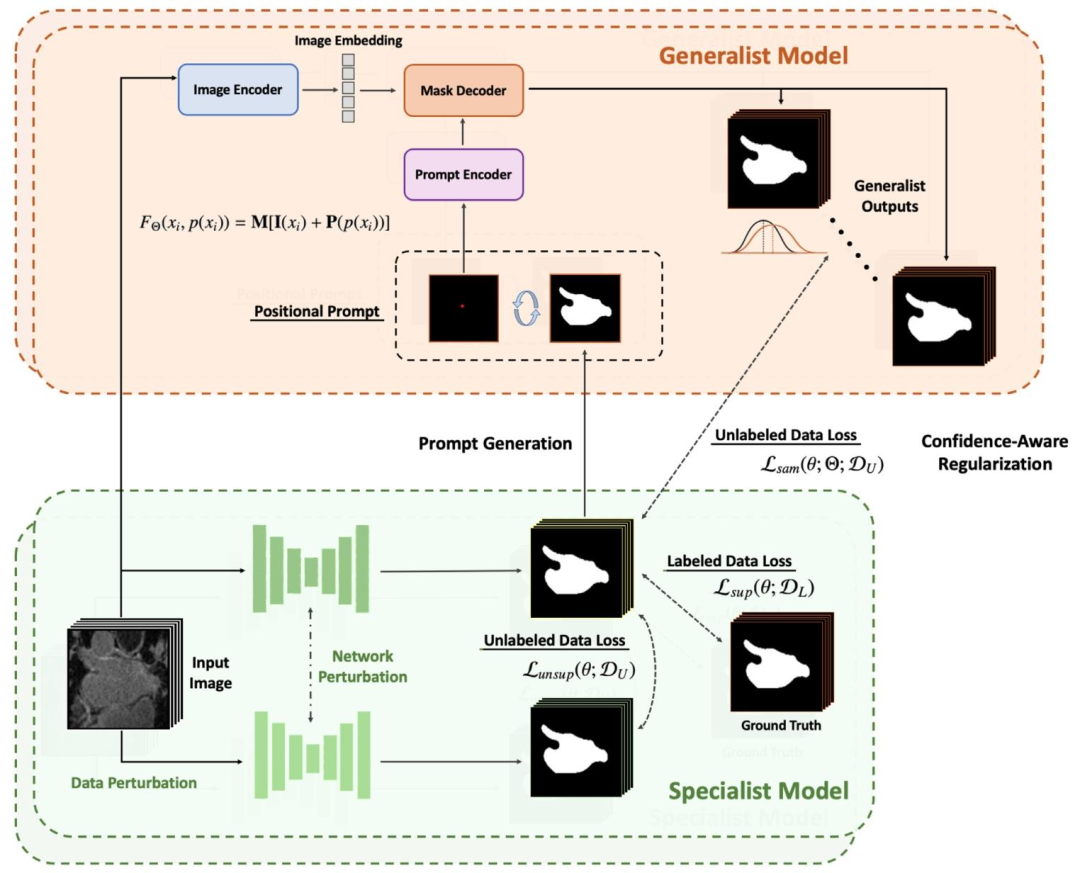
Fig. 4. Overview of the proposed foundation model-driven annotation-efficient learning framework SemiSAM+. Specifically, SemiSAM+ consists of a trainable task-specificsegmentation model as specialist model for downstream segmentation task and one or multiple promptable foundation models as generalist models pre-trained on large-scaledatasets with zero-shot generalization ability. In SemiSAM+, an additional confidence-aware regularization is adapted for effective utilization of generalist model’s supervision toavoid possible misguidance when encountering extremely limited annotation.
图 4 本文提出的基础模型驱动型标注高效学习框架 SemiSAM + 整体架构
具体而言,SemiSAM + 包含两个核心组件:一是可训练的任务专用分割模型(作为专用模型),用于处理下游分割任务;二是一个或多个可提示基础模型(作为通用模型),这类模型经大规模数据集预训练,具备零样本泛化能力。在 SemiSAM + 中,还引入了额外的置信度感知正则化机制,目的是高效利用通用模型的监督信号,避免在标注数据极度有限的情况下,通用模型对专用模型的学习过程产生可能的误导。
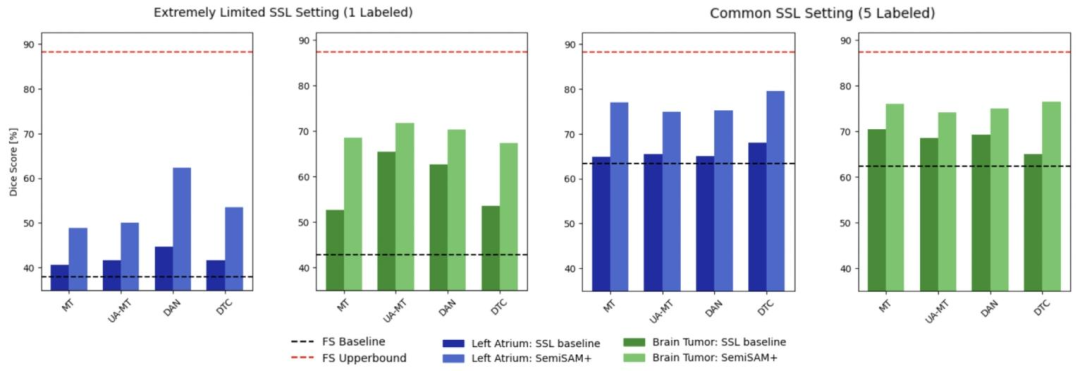
Fig. 5. Comparison of Dice performance of adapting SemiSAM+ to different SSL specialist models for left atrium segmentation and brain tumor segmentation under different SSLsettings.
图5 不同半监督学习(SSL)设置下,将SemiSAM+适配于不同SSL专用模型时,在左心房分割与脑肿瘤分割任务中的Dice性能对比
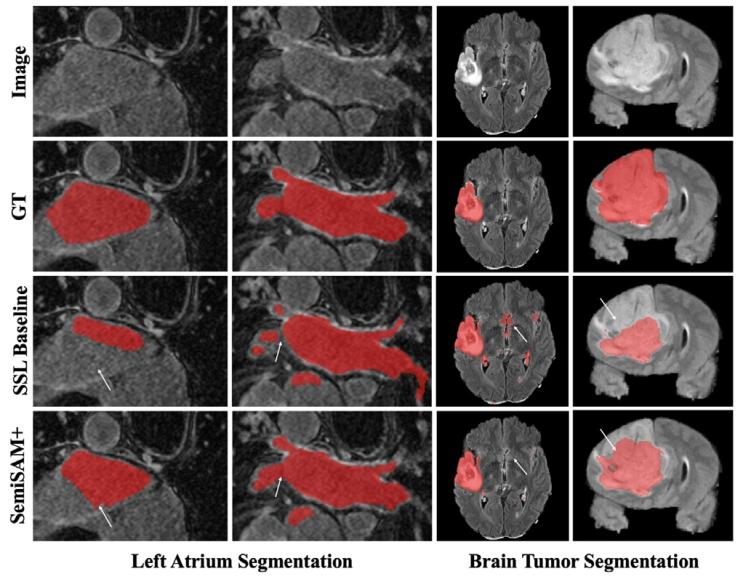
Fig. 6. Visual comparison of segmentation results of SSL baseline (MT) and SemiSAM+(MT/SAM-Med3D) on left atrium segmentation and brain tumor segmentation.
图 6 半监督学习(SSL)基准模型(MT)与 SemiSAM+(MT/SAM-Med3D)在左心房分割和脑肿瘤分割任务上的分割结果可视化对比
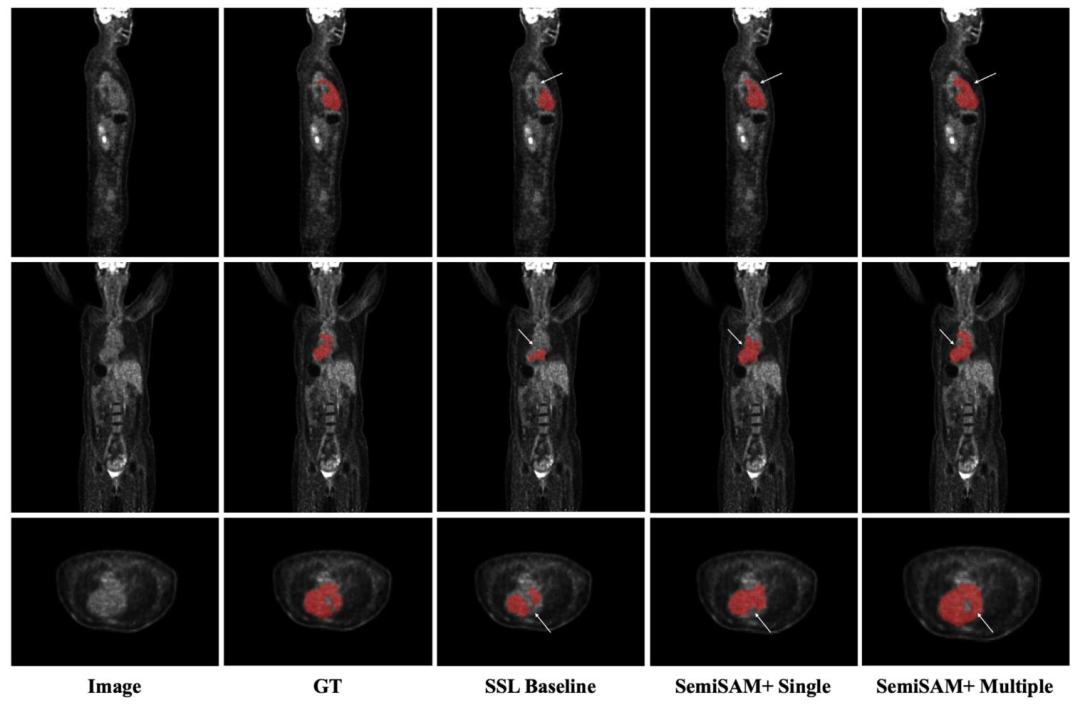
Fig. 7. Visual comparison of segmentation results of SSL baseline (MT) and SemiSAM+ using single generalist model (SAM-Med3D) and multiple generalist models (SAM-Med3Dand SegAnyPET) on whole heart segmentation from PET images
图7 半监督学习(SSL)基准模型(MT)与SemiSAM+(分别使用单一通用模型SAM-Med3D、多通用模型SAM-Med3D与SegAnyPET)在PET图像全心分割任务上的分割结果可视化对比
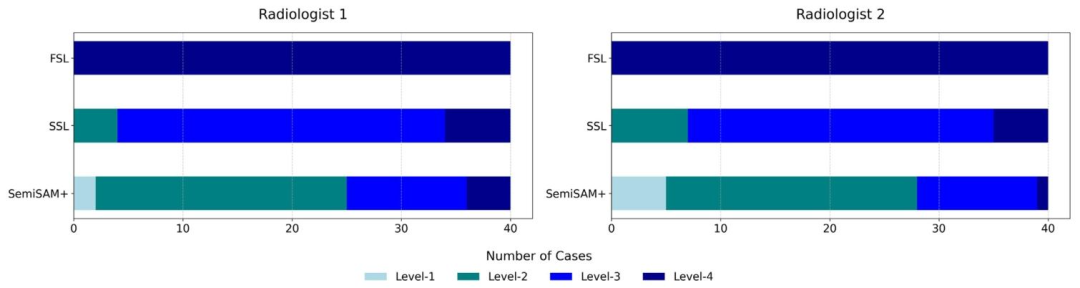
Fig. 8. Distribution of rating scores of two radiologists for manual evaluation of model-generated PET segmentation results, including Level-1 (no revision needed), Level-2 (minorrevision within 10 min), Level-3 (major revision with 10-30 min) and Level-4 (rejection and should be annotate from scratch).
图8 两名放射科医师对模型生成的PET分割结果进行人工评估的评分分布 评分等级包括:1级(无需修改)、2级(轻微修改,耗时不超过10分钟)、3级(重大修改,耗时10-30分钟)、4级(判定无效,需重新标注)。
Table
表
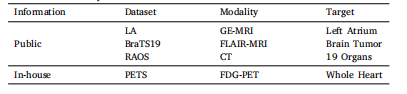
Table 1Information summary of datasets used in our work
表1 本研究中所用数据集的信息汇总
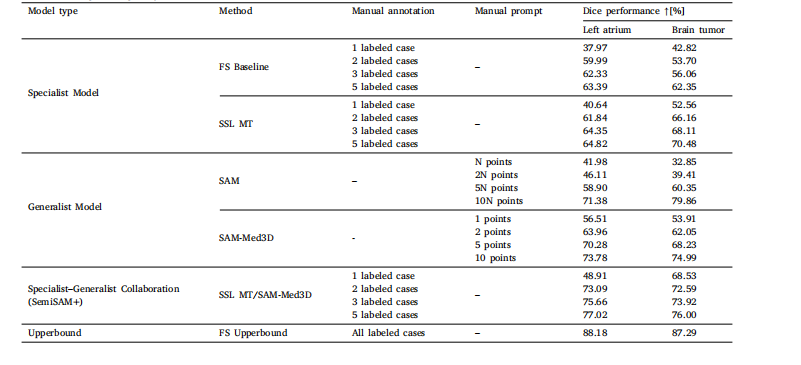
Table 2Comparison of segmentation performance with generalist models and specialist models on different segmentation datasets. Specifically, N denotes the count ofslices containing the target object.
表2 不同分割数据集上通用模型与专用模型的分割性能对比 其中,N表示包含目标对象的切片数量。
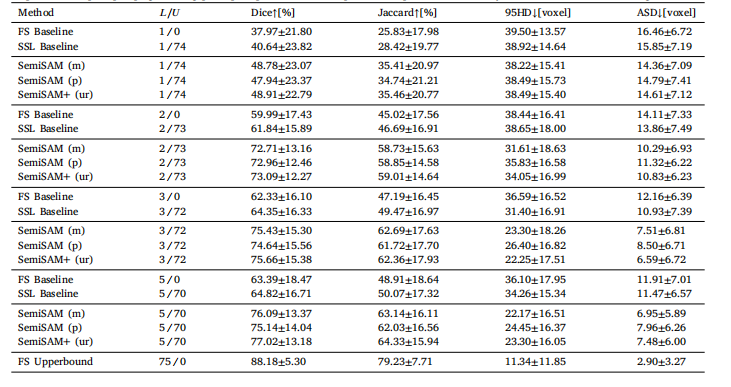
Table 3Ablation study of the proposed SemiSAM+ framework on the LA dataset with different prompting strategy. (m) directly utilizing specialistoutput as mask prompt. (p) generating point prompts based on the specialist output. (ur) uncertainty-rectified confidence-aware regularization.
表3 不同提示策略下,所提SemiSAM+框架在LA数据集上的消融实验结果 ((m)表示直接将专用模型输出作为掩码提示;(p)表示基于专用模型输出生成点提示;(ur)表示经不确定性修正的置信度感知正则化。)
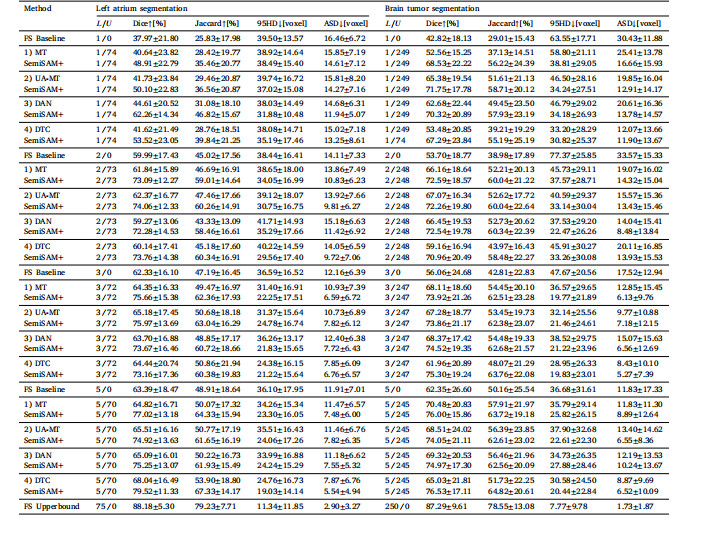
Table 4Evaluation of flexibility of adapting SemiSAM+ upon different specialist models on left atrium segmentation and brain tumor segmentation tasks under different annotation scenarios.All the models use the same 3D U-Net as the backbone
表4 不同标注场景下,在左心房分割与脑肿瘤分割任务中SemiSAM+适配不同专用模型的灵活性评估 所有模型均采用相同的3D U-Net作为骨干网络
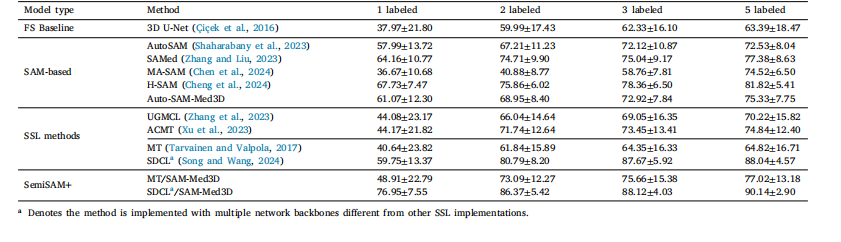
Table 5Comparison of Dice performance of SemiSAM+ with state-of-the-art semi-supervised and SAM-based fine-tuning methods on the LA dataset.
表5 SemiSAM+与当前最优的半监督学习方法及基于SAM的微调方法在LA数据集上的Dice性能对比

Table 6Comparison of Dice performance of adapting SemiSAM+ upon different single and multiple generalist models on the in-house PETS dataset
表 6 在内部 PETS 数据集上,SemiSAM + 适配不同单一通用模型与多通用模型时的 Dice 性能对比
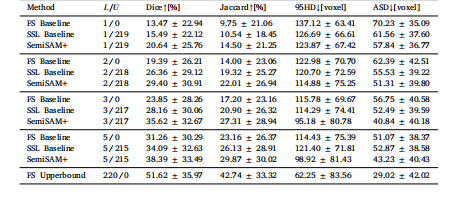
Table 7Comparison of Dice performance of adapting SemiSAM+ to multi-organ segmentationtask in challenging clinical scenarios on the RAOS dataset
表7 在RAOS数据集的挑战性临床场景下,SemiSAM+适配多器官分割任务的Dice性能对比