【Hot100】回溯
系列文章目录
、
提示:写完文章后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
- 系列文章目录
- 方法论
- Hot100 的回溯题
- 46. 全排列
- (1)解析
- (2)代码
- 78. 子集
- (1)解析
- (2)代码
- 17. 电话号码的字母组合
- 39. 组合总和
- 22. 括号生成
- 79. 单词搜索
- 131. 分割回文串
- (1)解析
- (2)代码
- 51. N 皇后
- (1)解析
- (2)代码
方法论
抽象地说,解决一个回溯问题,实际上就是遍历一棵决策树的过程,树的每个叶子节点存放着一个合法答案。你把整棵树遍历一遍,把叶子节点上的答案都收集起来,就能得到所有的合法答案。
站在回溯树的一个节点上,你只需要思考 3 个问题:
1、 路径:也就是已经做出的选择。
2、选择列表:也就是你当前可以做的选择。
3、 结束条件:也就是到达决策树底层,无法再做选择的条件。
result = []
def backtrack(路径, 选择列表):if 满足结束条件:result.add(路径)returnfor 选择 in 选择列表:做选择backtrack(路径, 选择列表)撤销选择
其核心就是 for 循环里面的递归,在递归调用之前「做选择」,在递归调用之后「撤销选择」, 特别简单。
Hot100 的回溯题
46. 全排列
「全排列」给定一个不含重复数字的数组 nums ,返回其所有可能的全排列 。你可以按任意顺序返回答案。
示例 1:
输入:nums = [1,2,3]
输出:[[1,2,3],[1,3,2],[2,1,3],[2,3,1],[3,1,2],[3,2,1]]
示例 2:
输入:nums = [0,1]
输出:[[0,1],[1,0]]
示例 3:
输入:nums = [1]
输出:[[1]]
(1)解析
我们都知道 n 个不重复的数,全排列共有 n! 个。那么我们是怎么穷举全排列的呢?比方说给三个数 [1,2,3],一般是这样:先固定第一位为 1,然后第二位可以是 2,那么第三位只能是 3;然后可以把第二位变成 3,第三位就只能是 2 了;然后就只能变化第一位,变成 2,然后再穷举后两位……
其实这就是回溯算法,我们无师自通就会用,并且我们可以画出如下这棵回溯树:

这棵树称为回溯算法的 「决策树」
为啥说这是决策树呢,因为你在每个节点上其实都在做决策。比如说你站在下图的红色节点上:

你现在就在做决策,可以选择 1 那条树枝,也可以选择 3 那条树枝。
对于回溯法,还有几个相关的概念:
- 「路径」,[2] 就是走过的路径,记录你已经做过的选择;
- 「选择列表」,[1,3] 就是选择列表,表示你当前可以做出的选择;
- 「结束条件」 就是遍历到树的底层叶子节点,这里也就是选择列表为空的时候。
如果明白了这几个名词,可以把 「路径」 和 「选择」 列表作为决策树上每个节点的属性,比如下图列出了几个蓝色节点的属性:

可以定义一个 backtrack 函数,让其像一个指针在这棵树上游走,同时正确维护每个节点的属性,每当走到树的底层叶子节点,其「路径」就是一个全排列。
再进一步,如何遍历一棵树?各种搜索问题其实都是树的遍历问题,而多叉树的遍历框架就是这样:
void traverse(TreeNode* root) {for (TreeNode* child : root->childern) {// 前序位置需要的操作traverse(child);// 后序位置需要的操作}
}
所谓的前序遍历和后序遍历,他们只是两个很有用的时间点。前序遍历的代码在进入某一个节点之前的那个时间点执行,后序遍历代码在离开某个节点之后的那个时间点执行。
现在,就可以较好地理解回溯算法的这段核心框架了:
result = [] #保存所有路径
def backtrack(路径, 选择列表):if 满足结束条件:result.add(路径)returnfor 选择 in 选择列表:# 做选择将该选择从选择列表移除路径.add(选择)backtrack(路径, 选择列表)# 撤销选择路径.remove(选择)将该选择再加入选择列表
我们 只要在递归之前做出选择,在递归之后撤销刚才的选择,就能正确得到每个节点的选择列表和路径。
(2)代码
class Solution {vector<vector<int>> res;
public:// 主函数,输入一组不重复的数字,返回它们的全排列vector<vector<int>> permute(vector<int>& nums) {list<int> track; // 记录「路径」vector<bool> used(nums.size(), false); // 「路径」中的元素会被标记为 true,避免重复使用backtrack(nums, track, used);return res;}private:// 路径:记录在 track 中// 选择列表:nums 中不存在于 track 的那些元素(used[i] 为 false)// 结束条件:nums 中的元素全都在 track 中出现void backtrack(vector<int>& nums, list<int>& track, vector<bool>& used) {// 触发结束条件if (track.size() == nums.size()) {res.push_back(track); return;}for (int i = 0; i < nums.size(); i++) {// 排除不合法的选择if (used[i]) // nums[i] 已经在 track 中,跳过continue;// 做选择track.push_back(nums[i]);used[i] = true;// 进入下一层决策树backtrack(nums, track, used);// 取消选择track.pop_back();used[i] = false;}}
};
这里稍微做了些变通,没有显式记录「选择列表」,而是通过 used 数组排除已经存在 track 中的元素,从而推导出当前的选择列表:

至此,我们就通过全排列问题详解了回溯算法的底层原理。当然,这个算法解决全排列不是最高效的,你可能看到有的解法连 used 数组都不使用,通过交换元素达到目的。但是那种解法稍微难理解一些,我会在
球盒模型:回溯算法两种穷举视角 中介绍。
但是必须说明的是,不管怎么优化,都符合回溯框架,而且 时间复杂度都不可能低于 O(N!),因为穷举整棵决策树是无法避免的,你最后肯定要穷举出 N! 种全排列结果。
这也是回溯算法的一个特点,不像动态规划存在重叠子问题可以优化,回溯算法就是纯暴力穷举,复杂度一般都很高。
78. 子集
78. 子集:给你一个整数数组 nums ,数组中的元素互不相同 。返回该数组所有可能的子集(幂集)。
解集 不能 包含重复的子集。你可以按 任意顺序 返回解集。
示例 1:
输入:nums = [1,2,3]
输出:[[],[1],[2],[1,2],[3],[1,3],[2,3],[1,2,3]]
示例 2:
输入:nums = [0]
输出:[[],[0]]
(1)解析

首先,生成元素个数为 0 的子集,即空集 [],为了方便表示,我称之为 S_0。
然后,在 S_0 的基础上生成元素个数为 1 的所有子集,我称为 S_1:[1]、[2]、[3]。
接下来,我们可以在 S_1 的基础上推导出 S_2,即元素个数为 2 的所有子集:[1, 2]、[1, 3]、[2, 3]
为什么集合 [2] 只需要添加 3,而不添加前面的 1 呢?因为集合中的元素不用考虑顺序,[1,2,3] 中 2 后面只有 3,如果你添加了前面的 1,那么 [2,1] 会和之前已经生成的子集 [1,2] 重复。
换句话说,我们可以 通过保证元素之间的相对顺序不变来防止出现重复的子集。
接着,我们可以通过 S_2 推出 S_3,实际上 S_3 中只有一个集合 [1,2,3],它是通过 [1,2] 推出的。整个推导过程就是上面一棵树。
如果把根节点作为第 0 层,将每个节点和根节点之间树枝上的元素作为该节点的值,那么第 n 层的所有节点就是大小为 n 的所有子集。 比如大小为 2 的子集就是这一层节点的值:

(2)代码
class Solution {
private:vector<vector<int>> res;vector<int> track;
public:// 主函数vector<vector<int>> subsets(vector<int>& nums) {backtrack(nums, 0);return res;}// 回溯算法核心函数,遍历子集问题的回溯树void backtrack(vector<int>& nums, int start) {// 前序位置,每个节点的值都是一个子集res.push_back(track);// 回溯算法标准框架for (int i = start; i < nums.size(); i++) {// 做选择track.push_back(nums[i]);// 通过 start 参数控制树枝的遍历,避免产生重复的子集backtrack(nums, i + 1);// 撤销选择track.pop_back();}}
};
【总结】
下面我们比较一下全排列和子集 插入一个结果的时机。void backtrack(vector<int>& nums, list<int>& track, vector<bool>& used) {// 触发结束条件if (track.size() == nums.size()) {res.push_back(track); return;}for(...)...}void backtrack(vector<int>& nums, int start) {// 前序位置,每个节点的值都是一个子集res.push_back(track);for (...) }造成差异的原因是,全排列的回溯树中,叶子节点才是可以添加的结果;而子集中每一个节点都是可以添加的结果。重点在于回溯树。
17. 电话号码的字母组合
17. 电话号码的字母组合:给定一个仅包含数字 2-9 的字符串,返回所有它能表示的字母组合。答案可以按 任意顺序 返回。

给出数字到字母的映射如下(与电话按键相同)。注意 1 不对应任何字母。
示例 1:
输入:digits = “23”
输出:[“ad”,“ae”,“af”,“bd”,“be”,“bf”,“cd”,“ce”,“cf”]
示例 2:
输入:digits = “”
输出:[]
示例 3:
输入:digits = “2”
输出:[“a”,“b”,“c”]
class Solution {
public:vector<string> res;string track;vector<string> strMap = {"", "", "abc", "def", "ghi", "jkl", "mno", "pqrs", "tuv", "wxyz"};vector<string> letterCombinations(string digits) {if(digits.empty()) return res;backtrack(digits, 0);return res;}void backtrack(string digits, int index){if(track.size() == digits.size()){res.push_back(track);return;}string str = strMap[digits[index] - '0']; // 获取数字对应的字符串for(int i = 0; i < str.size(); i++){track.push_back(str[i]);backtrack(digits, index+1); // 利用index,递归遍历 digitstrack.pop_back();} }
};
39. 组合总和
给你一个 无重复元素的整数数组 candidates 和一个目标整数 target ,找出 candidates 中可以使数字和为目标数 target 的 所有不同组合 ,并以列表形式返回。你可以按 任意顺序 返回这些组合。
candidates 中的 同一个 数字可以无限制重复被选取 。如果至少一个数字的被选数量不同,则两种组合是不同的。
对于给定的输入,保证和为 target 的不同组合数少于 150 个。
示例 1:
输入:candidates = [2,3,6,7], target = 7
输出:[[2,2,3],[7]] 解释: 2 和 3
可以形成一组候选,2 + 2 + 3 = 7 。
注意 2 可以使用多次。7 也是一个候选, 7 = 7 。仅有这两种组合。
示例 2:
输入: candidates = [2,3,5], target = 8
输出: [[2,2,2,2],[2,3,3],[3,5]]
示例 3:
输入: candidates = [2], target = 1
输出: []
class Solution {
public:vector<vector<int>> res;vector<int> track;vector<vector<int>> combinationSum(vector<int>& candidates, int target) {backtrack(candidates, target, 0);return res;}void backtrack(vector<int>& candidates, int target, int start){if(target == 0){res.push_back(track);return;}if(target < 0) return;for(int i = start; i < candidates.size(); i++){track.push_back(candidates[i]);target -= candidates[i];backtrack(candidates, target, i); // 让下一次递归,下标从i开始,防止重复track.pop_back();target += candidates[i];}}
};
22. 括号生成
22. 括号生成:数字 n 代表生成括号的对数,请你设计一个函数,用于能够生成所有可能的并且 有效的 括号组合。
示例 1:
输入:n = 3
输出:[“((()))”,“(()())”,“(())()”,“()(())”,“()()()”]
示例 2:
输入:n = 1
输出:[“()”]
class Solution {
public:vector<string> res;string track;char chs[2] = {'(', ')'};vector<string> generateParenthesis(int n) {backtrack(n, 0, 0);return res;}void backtrack(int n, int l, int r){if(r > l || r > n || l > n)return;if(track.size() == n*2){res.push_back(track);return;}for(int i = 0; i < 2; ++i){track.push_back(chs[i]);chs[i] == '('? l++ : r++;backtrack(n, l, r);track.pop_back();chs[i] == '('? l-- : r--;}}
};
79. 单词搜索
给定一个 m x n 二维字符网格 board 和一个字符串单词 word 。如果 word 存在于网格中,返回 true ;否则,返回 false 。
单词必须按照字母顺序,通过相邻的单元格内的字母构成,其中“相邻”单元格是那些水平相邻或垂直相邻的单元格。同一个单元格内的字母不允许被重复使用。
示例1:
输入:board = [[‘A’,‘B’,‘C’,‘E’],[‘S’,‘F’,‘C’,‘S’],[‘A’,‘D’,‘E’,‘E’]], word = “ABCCED”
输出:true

示例2:
输入:board = [[‘A’,‘B’,‘C’,‘E’],[‘S’,‘F’,‘C’,‘S’],[‘A’,‘D’,‘E’,‘E’]], word = “SEE”
输出:true
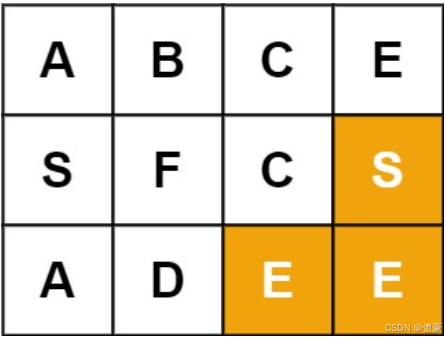
示例3:
输入:board = [[‘A’,‘B’,‘C’,‘E’],[‘S’,‘F’,‘C’,‘S’],[‘A’,‘D’,‘E’,‘E’]], word = “ABCB”
输出:false
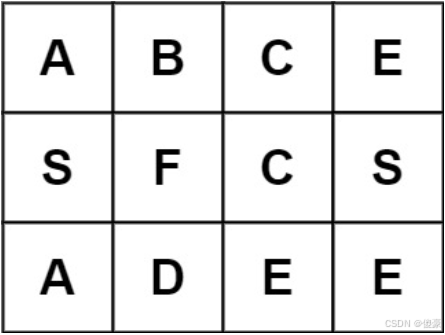
class Solution {
public:int dirs[4][2] = {{1, 0}, {-1, 0}, {0, 1}, {0, -1}};bool exist(vector<vector<char>>& board, string word) {// 剪枝1:统计 board 中各字符数量unordered_map<char, int> count;for (auto& row : board)for (char c : row)count[c]++;// 检查 word 中每个字符是否足够for (char c : word) {if (--count[c] < 0) {return false;}}// 剪枝2:如果 word 太长,直接 false(可选)if (word.empty()) return false;// 每一个字母都可以作为起点for(int i = 0; i < board.size(); i++){for(int j = 0; j < board[0].size(); ++j){if(backtrack(board, word, i, j, 0)) // 找到一个可行解,就可以返回,避免不必要的递归return true;} }return false;}bool backtrack(vector<vector<char>>& board, string& word, int i, int j, int k){// 边界检查 or 已访问 or 字符不匹配(中包含已访问的情况)if(i<0 || j<0 || i>=board.size() || j>=board[0].size() || k>word.size() || board[i][j] != word[k]) return false;if (k == word.size() - 1) {return true;}board[i][j] = '#'; // 访问过设为特殊字符,后续递归回出现字符不匹配,避免重复访问// 可以往四个方向递归for(auto dir : dirs){if(backtrack(board, word, i+dir[0], j+dir[1], k+1))return true;}board[i][j] = word[k];return false;}
};
131. 分割回文串
131. 分割回文串:给你一个字符串 s,请你将 s 分割成一些 子串,使每个子串都是 回文串 。返回 s 所有可能的分割方案。
示例 1:
输入:s = “aab”
输出:[[“a”,“a”,“b”],[“aa”,“b”]]
示例 2:
输入:s = “a”
输出:[[“a”]]
(1)解析
该题主要有两个难点:1、怎么判断回文;2、怎么回溯。整体思路分为两大步骤:
- 预处理:用动态规划(DP)快速判断任意子串 s[i…j] 是否为回文
- 搜索:用 DFS(回溯)枚举所有合法的回文分割方案
1、动态规划
使用二维数组 vector<vector<int>> f; 来记录字符串的回文情况,f[i][j] 表示 s[i..j] 是否为回文串(true 表示是)。
一开始,先初始化 f 数组全为true。初始化为 true 是为了后续 DP 递推方便,并且长度为 1 的子串(i == j)一定是回文。
状态转移:一个子串是回文,当且仅当:首尾字符相同:s[i] == s[j]并且中间部分也是回文:f[i+1][j-1] 为 true。核心代码如下:
for (int i = n - 1; i >= 0; --i) {for (int j = i + 1; j < n; ++j) {f[i][j] = (s[i] == s[j]) && f[i + 1][j - 1];}
}
为什么 i 要从 n-1 往 0 遍历?
因为 f[i][j] 依赖 f[i+1][j-1](左下角),所以必须 从下往上、从左往右 填表。
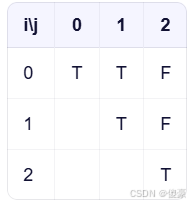
✅举例:s = “aab”
- f[0][1] = (s[0] == s[1]) && f[1][0] → 但 i > j 时我们默认 f[i][j] 为 true(逻辑上空串是回文)
- 实际上当 j == i+1 时,f[i+1][j-1] 就是 f[i+1][i],即 i > j,我们视作 true(边界条件)。
所以 “aa” 是回文 ✅
“aab”:s[0] == s[2]? 否 → f[0][2] = false
2、DFS
核心代码:
void dfs(const string& s, int i) {if (i == n) {ret.push_back(ans);return;}for (int j = i; j < n; ++j) {if (f[i][j]) { // s[i..j] 是回文,可以作为一段ans.push_back(s.substr(i, j - i + 1)); // 加入当前回文段dfs(s, j + 1); // 从 j+1 继续分割ans.pop_back(); // 回溯:撤销选择}}
}
📌 DFS 逻辑:
- 当前从位置 i 开始尝试所有可能的结束位置 j
- 如果 s[i…j] 是回文(查 f[i][j]),就把它作为一个片段加入 ans
- 然后递归处理剩下的部分 s[j+1…]
- 回溯时 pop_back(),尝试其他分割方式
(2)代码
class Solution {
private:vector<vector<int>> f; // f[i][j] 表示 s[i..j] 是否为回文串(true 表示是)vector<vector<string>> ret; // 最终结果:存储所有分割方案vector<string> ans; // 当前正在构造的一个分割方案int n; // 字符串长度public:void dfs(const string& s, int i) {if (i == n) {ret.push_back(ans);return;}for (int j = i; j < n; ++j) {if (f[i][j]) { // s[i..j] 是回文,可以作为一段ans.push_back(s.substr(i, j - i + 1)); // 加入当前回文段dfs(s, j + 1); // 从 j+1 继续分割ans.pop_back();}}}vector<vector<string>> partition(string s) {n = s.size();f.assign(n, vector<int>(n, true)); // 初始化 f 数组,因为长度为 1 的子串(i == j)一定是回文。// 动态规划,判断所有子串是否为回文for (int i = n - 1; i >= 0; --i) {for (int j = i + 1; j < n; ++j) {f[i][j] = (s[i] == s[j]) && f[i + 1][j - 1]; // f[i][j]:表示子串 s[i] 到 s[j] 是否为回文。}}dfs(s, 0);return ret;}
};
51. N 皇后
51. N 皇后:按照国际象棋的规则,皇后可以攻击与之处在同一行或同一列或同一斜线上的棋子。
n 皇后问题 研究的是如何将 n 个皇后放置在 n×n 的棋盘上,并且使皇后彼此之间不能相互攻击。
给你一个整数 n ,返回所有不同的 n 皇后问题的解决方案。
每一种解法包含一个不同的 n 皇后问题 的棋子放置方案,该方案中 'Q' 和 '.' 分别代表了皇后和空位。
(1)解析
对于 N 皇后问题,我们知道每行必然有且只有一个皇后,所以如果我们决定在 board[i] 这一行的某一列放置皇后,那么接下来就不用管 board[i] 这一行了,应该考虑 board[i+1] 这一行的皇后要放在哪里。所以 N 皇后问题的穷举对象是棋盘中的行,每一行都持有一个皇后,可以选择把皇后放在该行的任意一列。
首先再某一行放置皇后的时候,需要判断位置是否合法,需要检查列和斜对角线上是否有皇后造成冲突。该判断函数命名为isValid,函数内容如下:
// 是否可以在 board[row][col] 放置皇后?
bool isValid(const std::vector<std::string>& board, int row, int col) {int n = board.size();// 检查列是否有皇后互相冲突for (int i = 0; i < row; i++) {if (board[i][col] == 'Q')return false;}// 检查右上方是否有皇后互相冲突for (int i = row - 1, j = col + 1; i >= 0 && j < n; i--, j++) {if (board[i][j] == 'Q')return false;}// 检查左上方是否有皇后互相冲突for (int i = row - 1, j = col - 1; i >= 0 && j >= 0; i--, j--) {if (board[i][j] == 'Q')return false;}return true;
}
(2)代码
class Solution {
public:vector<vector<string>> res;vector<vector<string>> solveNQueens(int n) {vector<string> board(n, string(n, '.'));backtrack(board, n, 0);return res;}void backtrack(vector<string>& board, int n, int row){if(row == n){res.push_back(board);return;}// 遍历所有列for(int j = 0; j < n; ++j){// 排除掉不合法选择if(isValid(board, row, j)){board[row][j] = 'Q';backtrack(board, n, row+1); // 递归下一行board[row][j] = '.';}}}bool isValid(vector<string>& board, int row, int col){int n = board.size(); // 行数、列数都为n// 检查列是否有皇后互相冲突for(int i = 0; i < row; ++i){if(board[i][col] == 'Q')return false;}// 检查左上方for(int i = row - 1, j = col-1; i >= 0 && j >= 0; --i,--j){if(board[i][j] == 'Q')return false;}// 检查右上方for(int i = row - 1, j = col+1; i >= 0 && j < n; --i,++j){if(board[i][j] == 'Q')return false;}return true;}
};