LangChain: Memory
核心概念:什么是 Memory?
在 LangChain 的语境中,Memory 指的是链(Chain)或智能体(Agent)在多次交互之间“记住”信息的能力。
对于人类来说,对话是连续的。如果我问你“法国的首都是什么?”,你回答“巴黎”。如果我接着问“它以什么闻名?”,你很清楚“它”指的是巴黎,并能给出回答。但对于一个没有记忆的 AI 模型来说,每次交互都是独立的。第二个问题“它以什么闻名?”会因为缺乏上下文而变得毫无意义。
Memory 就是为了解决这个问题而存在的。它让 AI 应用(如聊天机器人)能够拥有短期或长期的记忆,从而进行连贯的、多轮的对话。
Memory 的核心作用与流程
Memory 在 LangChain 应用中扮演着“上下文管理器”的角色,其工作流程可以概括为以下几步:
flowchart TDA[用户输入新问题] --> B[Memory 系统读取历史记录]B --> C[将历史记录 + 新问题组合成完整上下文]C --> D[大语言模型<br>基于完整上下文生成回答]D --> E[Memory 系统将本次交互存入历史记录]E --> F[返回回答给用户]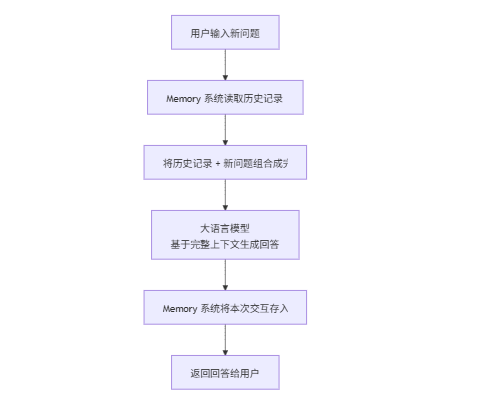
这个过程循环往复,使得对话能够基于之前的所有内容连贯地进行下去。
LangChain 中常见的 Memory 类型
LangChain 提供了多种 Memory 类,适用于不同的场景和复杂度:
1. 基础 Memory
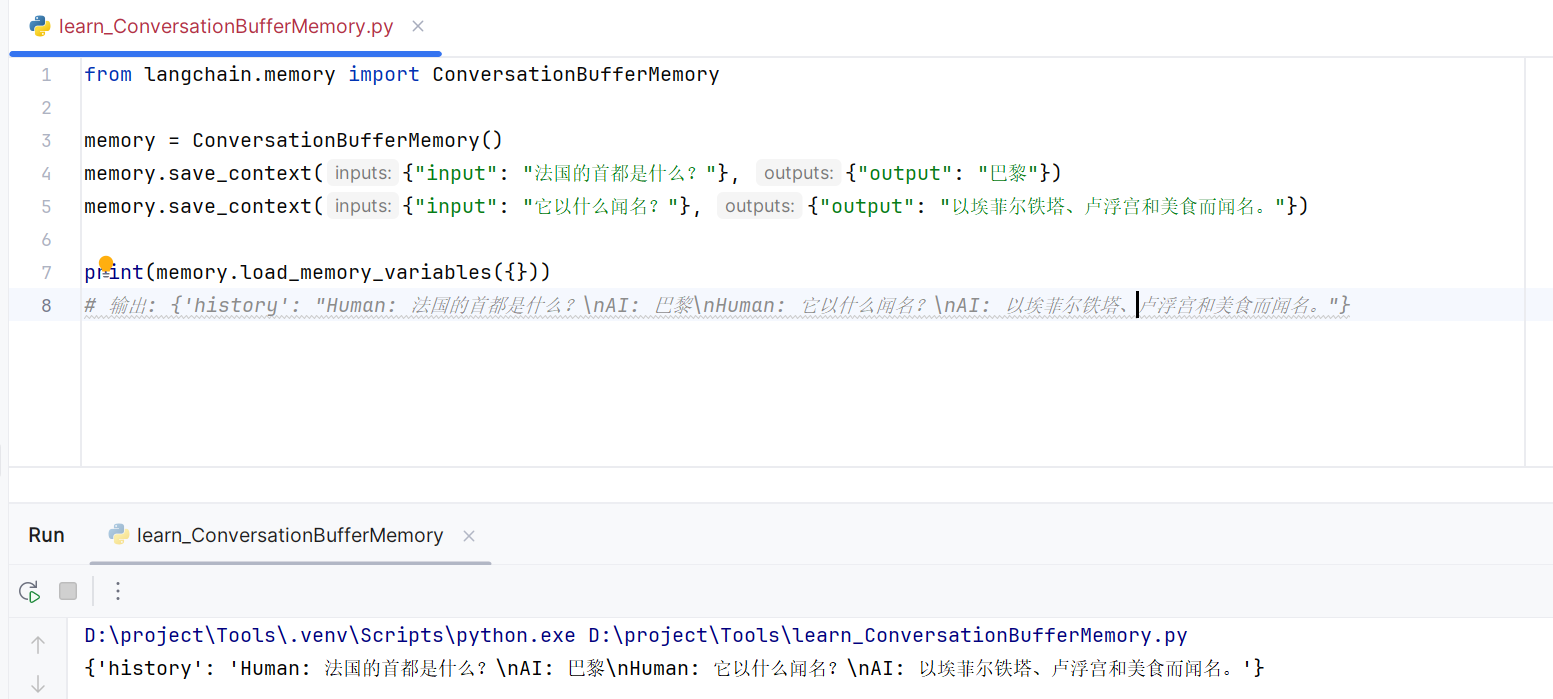
- ConversationBufferMemory
- 工作原理:像聊天记录一样,简单地、完整地保存所有对话历史。
- 优点:简单,信息完整。
- 缺点:对话很长时,消耗的 Token 会非常多,可能超出模型上下文限制。
- 代码示例:
from langchain.memory import ConversationBufferMemorymemory = ConversationBufferMemory() memory.save_context({"input": "法国的首都是什么?"}, {"output": "巴黎"}) memory.save_context({"input": "它以什么闻名?"}, {"output": "以埃菲尔铁塔、卢浮宫和美食而闻名。"})print(memory.load_memory_variables({})) # 输出: {'history': "Human: 法国的首都是什么?\nAI: 巴黎\nHuman: 它以什么闻名?\nAI: 以埃菲尔铁塔、卢浮宫和美食而闻名。"}
2. 优化型 Memory(更常用)
ConversationBufferWindowMemory
- 工作原理:只保留最近
k轮对话。像一个固定大小的滑动窗口,只记住最新的几次交流,更老的则被遗忘。 - 优点:有效控制 Token 消耗,避免上下文过长。
- 缺点:会遗忘窗口之外的对话历史。
- 适用场景:短期对话,关注最近上下文。
- 工作原理:只保留最近
ConversationSummaryMemory
- 工作原理:不保存原始对话,而是每次交互后都让 LLM 生成一个对当前对话的摘要,并只保存这个摘要。
- 优点:极大节省 Token,能记住非常长的对话的“精髓”。
- 缺点:摘要可能丢失细节;需要多次调用 LLM,成本稍高。
- 适用场景:长对话、需要记住核心信息的场景(如客户支持摘要)。
3. 高级 Memory
ConversationEntityMemory
- 工作原理:使用 LLM 识别并记住对话中提到的实体(如人、地点、事物)及其详细信息。它会为每个实体创建一个独立的记忆。
- 优点:记忆结构化,查询特定实体的信息非常高效。
- 示例:记住“Alice 的狗叫 Buddy”,然后当你问“Alice 的宠物叫什么?”时,它能准确回答。
ConversationKGMemory (Knowledge Graph Memory)
- 工作原理:将对话内容用知识图谱(三元组:主体-关系-客体)的形式存储。
- 优点:擅长捕捉和推理实体间的关系。
- 示例:将“Alice 的狗叫 Buddy”存储为
(Alice, has pet, Buddy)。
如何在链(Chain)中使用 Memory?
Memory 通常与 ConversationChain 或 LLMChain 结合使用。
完整示例:创建一个带记忆的聊天机器人
from langchain_openai import OpenAI
from langchain.chains import ConversationChain
from langchain.memory import ConversationBufferMemory# 1. 初始化大语言模型
llm = OpenAI(model_name="gpt-3.5-turbo-instruct", temperature=0) # 2. 初始化 Memory
memory = ConversationBufferMemory()# 3. 创建带有 Memory 的链
conversation = ConversationChain(llm=llm,memory=memory,verbose=True # 打印详细日志,方便查看内存如何使用
)# 4. 进行多轮对话
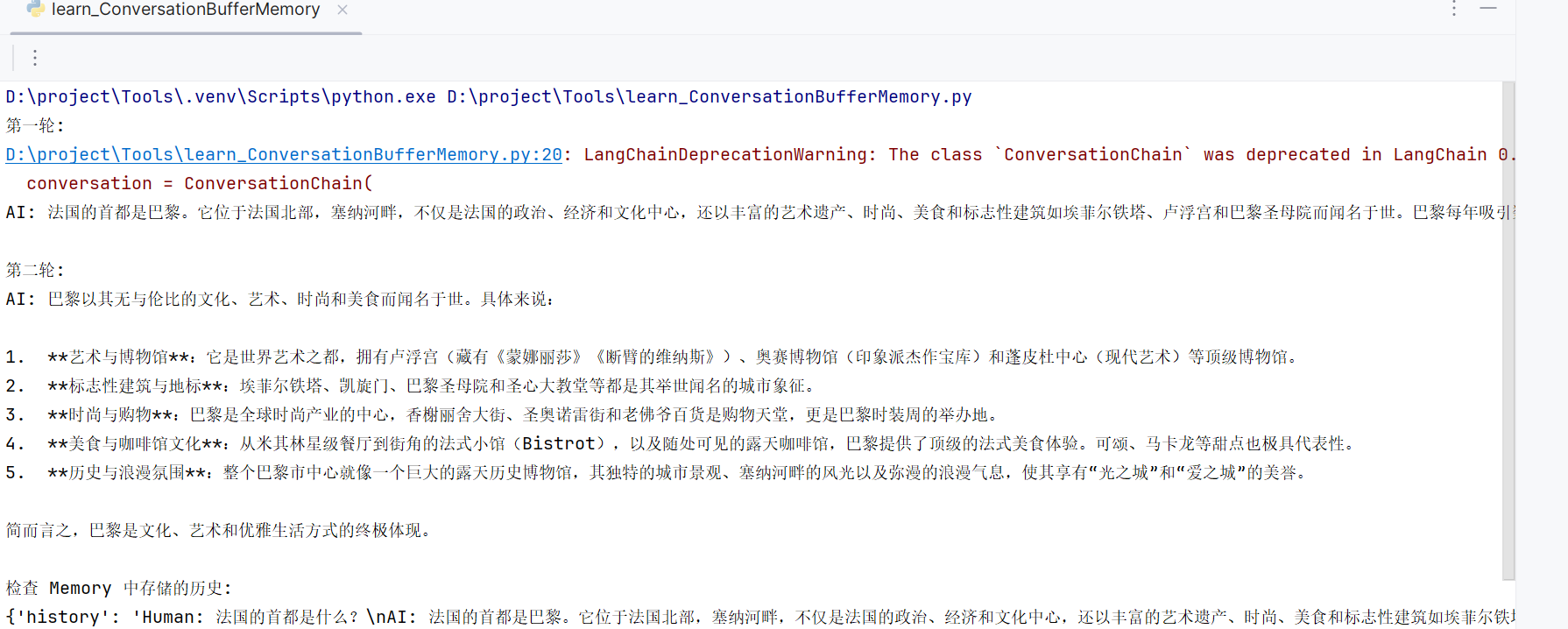
print("第一轮:")
result1 = conversation.predict(input="法国的首都是什么?")
print(f"AI: {result1}")print("\n第二轮:")
result2 = conversation.predict(input="它以什么闻名?") # AI 知道“它”指巴黎
print(f"AI: {result2}")print("\n检查 Memory 中存储的历史:")
print(memory.load_memory_variables({}))输出可能如下:
第一轮:
> Entering new ConversationChain chain...
Prompt: The following is a friendly conversation between a human and an AI. The AI is talkative and provides lots of specific details from its context. If the AI does not know the answer to a question, it truthfully says it does not know.Current conversation:Human: 法国的首都是什么?
AI: 巴黎Human: 它以什么闻名?
AI: 巴黎以其标志性的埃菲尔铁塔、世界闻名的卢浮宫博物馆和美味的法式美食而闻名。Current conversation:
...
总结与最佳实践
| 特性 | 说明 |
|---|---|
| 核心价值 | 使AI应用能够进行连贯的多轮对话,是构建聊天机器人和交互式代理的基石。 |
| 关键选择 | 根据你的场景选择正确的 Memory 类型: • 简单对话/Demo: ConversationBufferMemory• 大多数生产环境: ConversationBufferWindowMemory• 长对话/摘要: ConversationSummaryMemory• 复杂结构化信息: ConversationEntityMemory |
| 注意事项 | • Token 消耗:记忆内容会占用宝贵的上下文窗口,需合理管理。 • 状态管理:在无状态服务(如Web服务器)中使用时,需要将内存内容(如 memory.chat_memory.messages)序列化(存入数据库或Session)并在下次请求时重新加载。 |
总而言之,LangChain 的 Memory 系统提供了一个强大而灵活的抽象层,让你可以轻松地为LLM应用赋予“记忆”能力,从而构建出真正智能和连贯的交互体验。