Scikit-learn Python机器学习 - 特征预处理 - 归一化 (Normalization):MinMaxScaler
锋哥原创的Scikit-learn Python机器学习视频教程:
2026版 Scikit-learn Python机器学习 视频教程(无废话版) 玩命更新中~_哔哩哔哩_bilibili
课程介绍

本课程主要讲解基于Scikit-learn的Python机器学习知识,包括机器学习概述,特征工程(数据集,特征抽取,特征预处理,特征降维等),分类算法(K-临近算法,朴素贝叶斯算法,决策树等),回归与聚类算法(线性回归,欠拟合,逻辑回归与二分类,K-means算法)等。
Scikit-learn Python机器学习 - 特征预处理 - 归一化 (Normalization):MinMaxScaler
不同特征可能有不同的量纲和范围(如身高、体重、年龄),归一化使各特征在相同尺度上进行比较,避免某些特征因数值较大而主导模型。
我们将特征缩放至一个特定的范围(默认是 [0, 1])。
归一化(Normalization)公式,也称为最小-最大归一化(Min-Max Normalization)
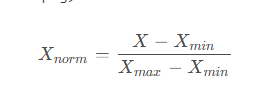
公式含义 这个公式将原始数据 X 从其原始范围转换到 [ 0,1] 的范围内。
公式各部分解释

工作原理

特点

应用场景 归一化在机器学习和数据挖掘中非常常用,特别是:
-
特征缩放,使不同量纲的特征可比较
-
梯度下降算法中加速收敛
-
神经网络中防止梯度消失或爆炸
-
图像处理中的像素值标准化
在Scikit-learn中,使用MinMaxScaler进行归一化操作。在初始化 MinMaxScaler 对象时,最重要的参数是:
-
feature_range: tuple(min, max), 默认=(0, 1)-
作用:指定你想要将数据缩放到的目标范围。
-
示例:如果想缩放到 [-1, 1],则设置
feature_range=(-1, 1)。
-
我们看一个示例:
import numpy as np
import pandas as pd
from sklearn.impute import SimpleImputer
from sklearn.preprocessing import MinMaxScaler
# 创建示例数据,包含不同类型的问题
data = {'age': [25, 30, np.nan, 45, 60, 30, 15], # 数值,含缺失值'salary': [50000, 54000, 60000, np.nan, 100000, 40000, 20000], # 数值,尺度大,含缺失值'country': ['USA', 'UK', 'China', 'USA', 'India', 'China', 'UK'], # 分类型'gender': ['M', 'F', 'F', 'M', 'M', 'F', 'F'] # 分类型
}
df = pd.DataFrame(data)
print("原始数据:")
print(df)
# 策略通常为 mean(均值), median(中位数), most_frequent(众数), constant(固定值)
imputer = SimpleImputer(strategy='mean')
# 我们只对数值列进行填充
numeric_features = ['age', 'salary']
df_numeric = df[numeric_features]
# fit 计算用于填充的值(这里是均值),transform 应用填充
imputer.fit(df_numeric)
df[numeric_features] = imputer.transform(df_numeric)
print("\n处理缺失值后:")
print(df)
minmax_scaler = MinMaxScaler()
df_numeric = df[['age', 'salary']]
# 根据数据训练生成模型
minmax_scaler.fit(df_numeric)
# 根据模型训练数据
df_normalized = minmax_scaler.transform(df_numeric)
print("\n归一化后的数值特征(范围[0,1]):")
print(df_normalized)运行结果:
归一化后的数值特征(范围[0,1]):
[[0.22222222 0.375 ][0.33333333 0.425 ][0.42592593 0.5 ][0.66666667 0.425 ][1. 1. ][0.33333333 0.25 ][0. 0. ]]