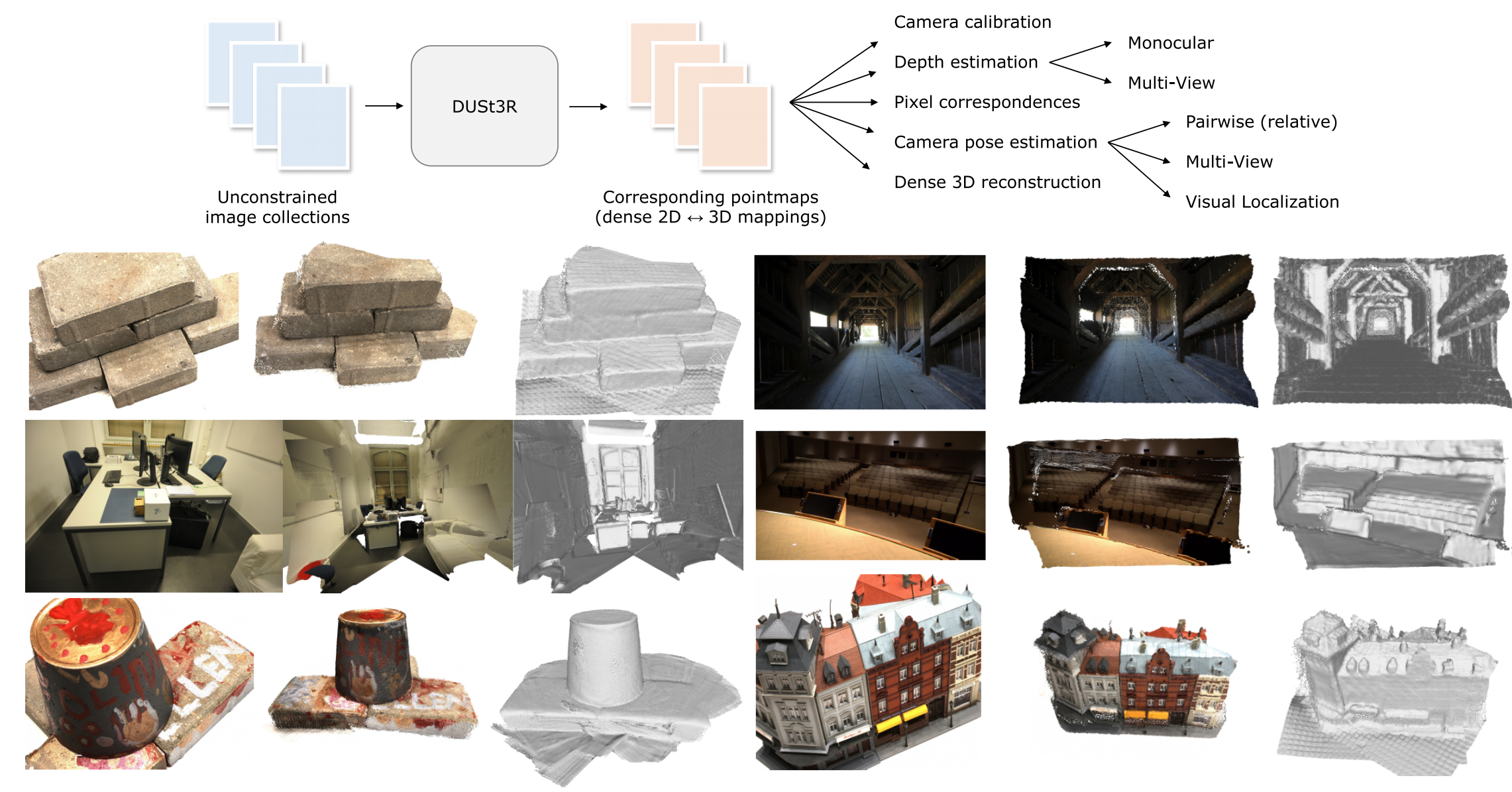
论文介绍:“DUSt3R”,让 3D 视觉从“繁琐”走向“直观”
DUSt3R:让 3D 视觉从“繁琐”走向“直观”

想象一下,你有一组用手机随意拍摄的照片,没有校准,也没有任何关于相机位置的记录。如果想用它们来重建一个 3D 模型,传统的计算机视觉方法会让你头疼不已。你需要先校准每张照片的相机参数,然后进行复杂的特征点匹配,再通过三角测量和捆集调整(Bundle Adjustment)等一系列繁琐的几何计算,才能最终得到一个勉强可用的 3D 模型。
而 DUSt3R 的出现,就像是为这个复杂流程按下了“快进键”。这篇名为《DUSt3R: Geometric 3D Vision Made Easy》的论文提出了一种颠覆性的新方法:它将整个 3D 重建过程,转化为一个直接的深度学习回归任务。 你只需要把照片丢给它,它就能直接给你一个完整的、彩色的 3D 点云,并且还能告诉你相机是怎么移动的。
核心思想:从“反推”到“直达”
DUSt3R 的核心思想在于点图(Pointmap)。你可以将点图看作是 RGB 图像的一种特殊“孪生兄弟”。对于 RGB 图像上的每一个像素,点图都存储着它在三维空间中的对应坐标 (X, Y, Z)。
传统的 3D 重建是一个复杂的“反向工程”。它依赖于已知的相机参数,通过几何投影关系来从 2D 像素反推 3D 坐标。而 DUSt3R 则反其道而行之,它用一个强大的 Transformer 模型,直接从海量的训练数据中“学习”这种 2D 到 3D 的映射关系。
正如论文摘要所述:
“Our method DUSt3R outputs a set of corresponding pointmaps (dense 2D 3D mappings), from which we can straightforwardly recover a variety of geometric quantities normally difficult to estimate all at once, such as the camera parameters, pixel correspondences, depthmaps, and fully-consistent 3D reconstruction.”’
(“我们的方法DUSt3R输出一组对应的点图(密集的2D到3D映射),从中我们可以直接恢复各种几何量,例如相机参数、像素对应关系、深度图和完全一致的3D重建,而这些通常很难一次性全部估计出来。”)
这个过程就像是:
- 传统的厨师:拿到食谱(相机参数),根据一步步的指示(几何计算)来烹饪。
- DUSt3R:就像一个经验丰富、天赋异禀的大厨,它通过尝遍了各种美食(训练数据),已经完全掌握了烹饪的精髓,根本不需要看食谱,就能直接做出色香味俱全的菜肴(3D 点图)。
技术实现:从点图到点云的旅程
那么,DUSt3R 是如何将多张照片整合为一个完整 3D 模型的呢?它采用了“先局部,后全局”的策略:
- 分帧预测:模型会为输入的每一张 RGB 图像都独立地预测出一张 3D 点图。这些点图就像是不同视角下,场景的 3D“快照”。
- 全局对齐:这是 DUSt3R 最巧妙的一步。它不再依赖于 2D 图像的重投影误差,而是直接在 3D 空间中进行优化。通过一个创新的优化过程,它将这些独立的 3D 点图对齐到同一个公共坐标系下。这就像是把多个 3D“拼图”块拼接在一起,最终得到一个统一、完整的 3D 点云。
论文中也明确提到了这一点:
“We propose an optimization procedure for globally aligning the pointmaps in multi-view 3D reconstruction. Unlike traditional Bundle Adjustment, this process does not minimize 2D reprojection errors, but instead directly minimizes 3D projection errors.”
(“我们提出了一个优化程序,用于在多视角3D重建中全局对齐点图。与传统的捆集调整(Bundle Adjustment)不同,该过程不是最小化2D重投影误差,而是直接最小化3D投影误差。”)
在这个过程中,DUSt3R 还会将原始 RGB 图像的颜色信息映射到 3D 点上,因此最终输出的点云是彩色的,这对于视觉化和下游应用至关重要。
DUSt3R 的训练过程与损失函数
DUSt3R 的训练是一个全监督过程,它需要大量的真实三维数据来指导模型学习如何将 2D 图像转化为 3D 坐标。这个过程可以概括为以下三个关键部分。
1.训练数据的构造
DUSt3R 的训练数据对由以下三部分组成:
-
一组多视角的 2D 图像:这些是来自不同角度拍摄的同一场景的 RGB 图片。
-
真值点云(Ground Truth Point Cloud):这是通过高精度的三维扫描仪(如 LiDAR)或结构光设备获取的场景真实三维数据,作为模型的“标准答案”。
-
相机内外参:尽管 DUSt3R 在推理时不需要这些参数,但在训练时,它们是必不可少的。这些参数用于将真值点云投影到每一张 2D 图像上,从而为每个像素计算出其对应的真值 3D 坐标。
2. 损失函数的设计
DUSt3R 的损失函数旨在最小化模型预测结果与真值之间的差异。它由三个主要的组成部分构成:
-
3D 回归损失(3D Regression Loss):这是最核心的损失。它直接衡量模型预测的 3D 点图与真值点图之间的欧几里得距离。这个损失鼓励模型预测的 3D 坐标尽可能地接近真实值。作者使用的是加权 L1 损失,以更好地处理训练中的异常值。
-
点图对齐损失(Pointmap Alignment Loss):在多视角训练中,这个损失确保模型为不同视角生成的点图能够互相正确对齐。它通过最小化不同点图上对应点之间的 3D 距离,来强制模型学习几何一致性。
-
置信度损失(Confidence Loss):模型不仅预测 3D 坐标,还会为每个像素输出一个置信度,表示预测的可靠程度。这个损失鼓励模型在预测准确的区域给出高置信度,而在预测不准确的区域给出低置信度,从而让模型学会自我评估。
关键问答
问:DUSt3R 的核心思想是什么?它与传统三维重建方法有何不同?
答: DUSt3R 的核心思想是将三维重建任务从一个复杂的几何问题,转化为一个直接的深度学习回归任务。
传统方法: 依赖于显式的几何学原理,需要预先获取相机参数(如内参和外参),然后通过特征匹配、三角测量和捆集调整等繁琐步骤来从 2D 图像反推 3D 坐标。
DUSt3R: 绕过了这些传统步骤,直接训练一个基于 Transformer 的神经网络模型。该模型接收 2D 图像作为输入,直接预测出点图(Pointmap),即 2D 像素与 3D 坐标的密集映射。这种端到端的方法极大地简化了整个流程。
问:DUSt3R 输出的“点图”是什么?它和深度图或点云有什么区别?
答: 点图是一种全新的数据表示,它将每个 2D 像素与一个 3D 空间中的坐标直接关联起来。
与深度图的区别: 深度图只表示像素到相机的距离,是一种二维表示,且依赖于相机内参。而点图则直接包含 3D 坐标,是一种更丰富、更基础的表示,可以从中推导出深度信息。
与点云的区别: 点云是离散的三维点集合,通常没有与原始 2D 像素的直接对应关系。而点图则是一种结构化的表示,它保持了原始图像的网格结构,并且每一个点都对应一个唯一的 2D 像素,因此可以轻松地添加颜色信息。
问:DUSt3R 是如何处理多张图像的?
答: 整个流程可以分为以下几个关键步骤:
-
分帧前向传播(Per-Frame Forward Pass): DUSt3R 的核心模型是基于Transformer的,它采用一种双分支的“孪生”(Siamese)架构,可以同时处理两张或多张图像。在实际操作中,它会为每一张输入的 2D 图像都进行一次前向传播,直接预测出该图像对应的 3D 点图。这个过程是并行的,这意味着所有图像的 3D 点图可以同时被计算出来,大大提高了效率。
-
两两对齐(Pairwise Alignment): 在得到所有独立的点图后,模型会计算每两张点图之间的相对位姿(relative pose)。这篇论文提到,这个过程是通过一个优化程序,在 3D 空间中找到最佳的旋转和平移,使得两张点图能够尽可能地对齐。
-
全局对齐(Global Alignment): 这是最关键的一步。当图像数量超过两张时,仅仅依赖两两对齐是不够的,因为误差会累积。DUSt3R 提出了一种全局优化方法,它将所有图像和它们之间的两两对齐关系构建成一个图,然后通过一个优化算法,调整所有相机在同一个全局坐标系下的绝对位姿,使得所有点图能够共同地、一致地对齐。
简单来说,DUSt3R 的处理流程是:先为每一张图独立地生成 3D 点图,然后通过两两对齐获取相对关系,最后通过一个全局优化过程,将所有点图整合到同一个 3D 空间中。 这种分步策略既保证了效率(并行计算),又确保了最终结果的全局一致性。
问:为什么 DUSt3R 可以无需相机参数?它又是如何恢复相机参数的?
答: DUSt3R 之所以无需相机参数,是因为它将三维重建视为一个回归任务,而不是一个几何计算问题。模型直接从数据中学习 2D 到 3D 的映射,而不需要任何先验的几何约束。
在得到 2D 像素与 3D 点的映射后,它可以反向推导出相机参数。这个过程是利用了基础的几何原理:只要有了 2D 像素及其对应的 3D 坐标,就可以通过一个优化问题来求解出能够解释这种映射关系的相机内参(焦距、主点)和外参(旋转、平移)。
问:DUSt3R 的重建精度如何?与 NeRF 和 3D Gaussian Splatting (3DGS) 相比呢?
答: DUSt3R 在多项三维重建任务上达到了**最先进(SoTA)**的水平。但其精度与 NeRF 和 3DGS 的侧重点不同:
-
DUSt3R: 重建结果是显式的、可编辑的点云。它的优点是结果直观,可用于三维测量和编辑,几何精度高。
-
NeRF 和 3DGS: 这两种方法属于神经渲染。它们重建的是隐式或显式的场景表示,旨在生成逼真、高质量的新视角图像。在渲染质量和视觉逼真度上,它们通常优于 DUSt3R,但在直接提供可编辑的几何模型方面则各有优劣。
问:DUSt3R 有什么缺点?如何处理动态场景?
答: DUSt3R 的主要缺点包括:
-
训练成本高: 基于 Transformer 架构和全监督训练,需要大量的计算资源和高质量的标注数据。
-
泛化能力: 在未见过的复杂场景或极端条件下,其泛化能力可能受限。
-
无法处理动态场景: DUSt3R 假设场景是静态的。如果场景中存在移动物体,传统的几何对应关系会被破坏,导致重建失败。要处理动态场景,需要从根本上改变建模方式,将时间作为一个关键维度。相关方法包括:1) 动态神经渲染(如动态 NeRF):学习场景在不同时间的形变,从而重建一个 4D(三维空间+时间)模型。2) 多传感器融合:结合深度相机、IMU 等传感器来提供额外的运动约束。这些方法与 DUSt3R 的静态重建原理完全不同。
颠覆性的优势与应用场景
DUSt3R 的创新不仅在于技术本身,更在于它带来的巨大实用价值。
1. 恢复相机参数
由于模型直接预测了 2D 像素与 3D 点的对应关系,因此所有传统的几何量,包括相机内外参(intrinsic and extrinsic camera parameters)和像素对应关系(pixel correspondences),都可以从最终生成的点图中轻松反向推导出来。这意味着 DUSt3R 可以像一个“万能标定工具”一样,自动从普通照片中恢复出精确的相机参数,而无需任何昂贵的校准设备。
2. 具体业务应用
基于这种强大的能力,DUSt3R 在多个领域都有广阔的应用前景:
- 虚拟现实(VR)与增强现实(AR):它可以快速从普通照片中重建出 3D 场景,为 VR/AR 应用提供逼真的数字内容,例如创建虚拟旅游或 AR 游戏。
- 机器人与无人机导航:通过实时处理图像,DUSt3R 可以为机器人或无人机提供其所在环境的 3D 地图,帮助它们进行自主导航和避障。
- 文化遗产数字化:DUSt3R 能够从历史照片或文物照片中,自动创建高精度的 3D 模型,用于永久保存、研究和虚拟展示。
- 室内设计与房地产:它可以快速重建房间的 3D 模型,帮助设计师进行虚拟布局,或者为客户提供沉浸式的房产参观体验。
论文也自信地给出了结论:
“DUSt3R achieves new state-of-the-art results on monocular and multi-view depth benchmarks as well as multi-view camera pose estimation.”
(“DUSt3R在单目和多视角深度基准测试以及多视角相机姿态估计上取得了新的最先进(SoTA)成果。”)
总而言之,DUSt3R 就像是 3D 视觉领域的一场技术革命。它用一种优雅而强大的方式,重新定义了从 2D 到 3D 的路径,为我们提供了一个更简单、更高效、更强大的解决方案。