FastVLM:高效视觉编码助力视觉语言模型突破高分辨率效率瓶颈
想要掌握如何将大模型的力量发挥到极致吗?叶梓老师带您深入了解 Llama Factory —— 一款革命性的大模型微调工具。
1小时实战课程,您将学习到如何轻松上手并有效利用 Llama Factory 来微调您的模型,以发挥其最大潜力。
CSDN教学平台录播地址:https://edu.csdn.net/course/detail/39987
视频号(直播分享):sphuYAMr0pGTk27 抖音号:44185842659
现有视觉语言模型(VLMs)在提升输入图像分辨率以优化文本密集型图像理解任务性能时,面临视觉编码器效率低下的核心问题:主流视觉编码器(如 ViTs)在高分辨率下会产生大量 tokens,导致编码延迟显著增加,同时过多 tokens 还会延长大模型的预填充时间,最终使得模型的首 token 生成时间(TTFT)大幅上升,难以平衡分辨率、延迟与精度三者关系。为解决这一问题,Apple 团队提出 FastVLM 模型,其核心创新在于引入新型混合视觉编码器 FastViTHD,通过优化视觉编码流程与 token 生成机制,在无需额外 token 修剪操作的前提下,仅通过缩放输入图像即可实现分辨率、延迟与精度的最优权衡。
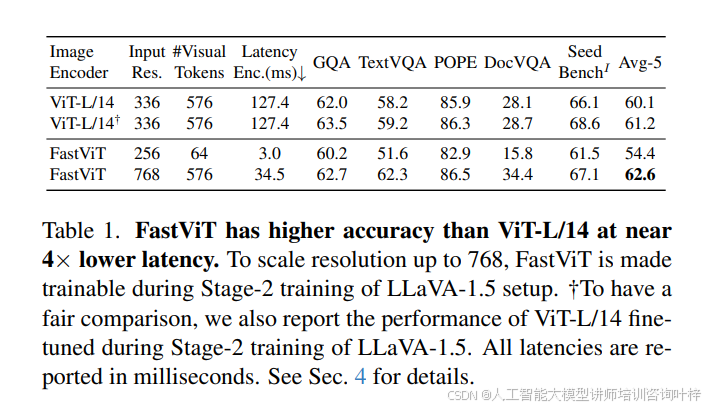
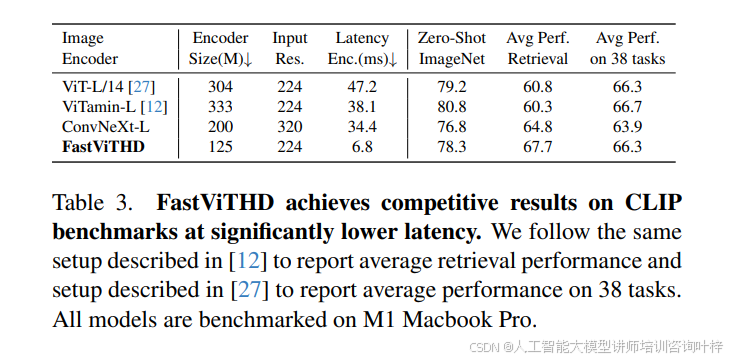
FastVLM 的设计围绕视觉编码器与大模型的协同优化展开。在视觉编码器层面,团队首先探索了 FastViT 混合架构在 VLM 中的应用,发现其凭借卷积组件的原生分辨率缩放能力与 Transformer 块的高质量 token 生成特性,展现出显著优势。如 表 1 所示,当 FastViT 输入分辨率缩放至 768×768 时,能生成与 ViT-L/14(336×336 分辨率)相同数量的视觉 tokens,但在 TextVQA、DocVQA 等文本密集型基准测试中性能更优,且编码速度更快 —— latency 仅为 34.5ms,远低于 ViT-L/14 的 127.4ms,同时参数规模仅为 ViT-L/14 的 1/8.7。为进一步提升高分辨率场景下的效率,团队对 FastViT 进行架构优化,提出 FastViTHD:通过增加额外下采样阶段,使自注意力层在 32 倍下采样的张量上运行(而非现有模型的 16 倍),最终生成的 tokens 数量比 FastViT 减少 4 倍,比 ViT-L/14(336 分辨率)减少 16 倍。表 3 数据显示,FastViTHD 虽参数规模仅 125M(为 ViT-L/14 的 1/2.4),但在 38 项多模态零样本任务中平均性能与 ViT-L/14 持平,且编码 latency 仅 6.8ms,是 ViT-L/14 的 1/6.9,同时在检索任务上的平均性能还优于混合架构 ViTamin-L。
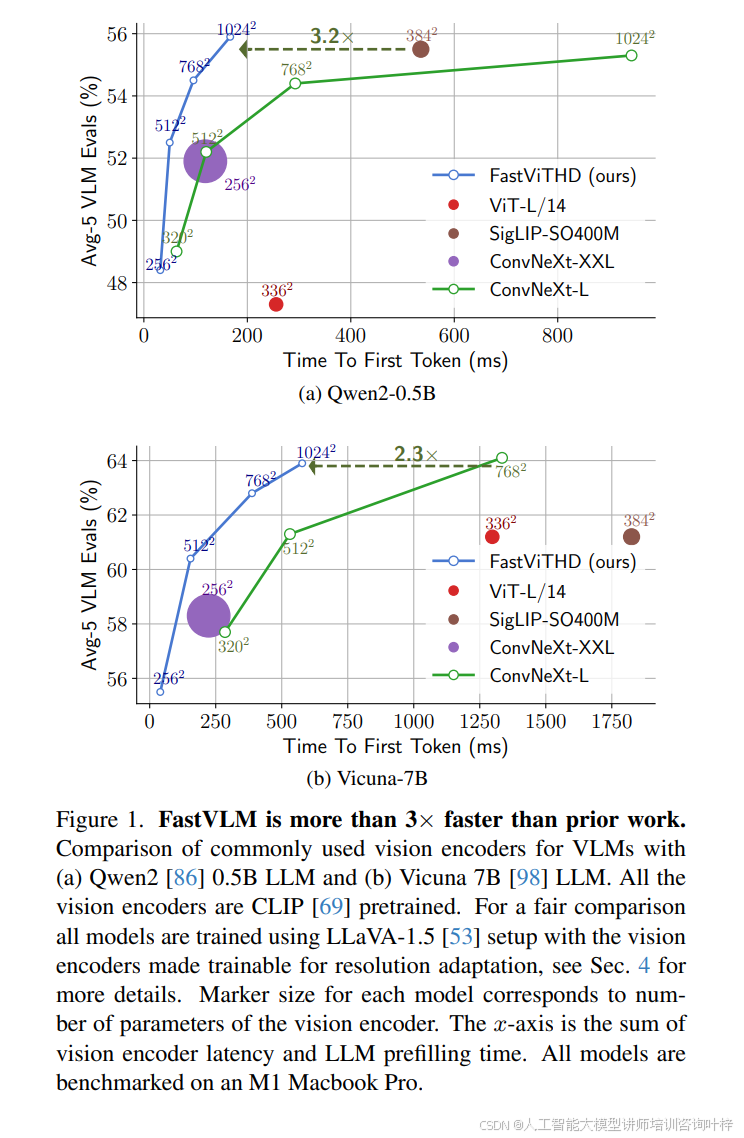
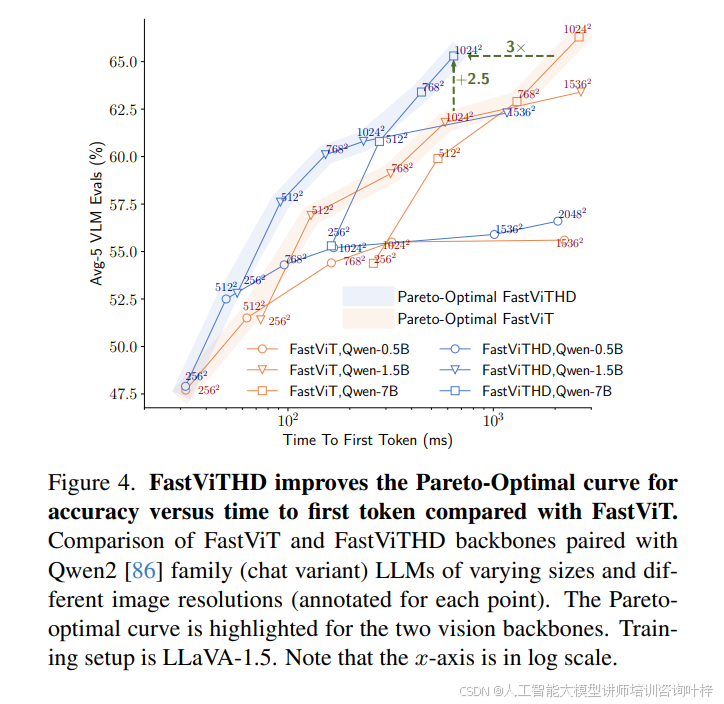
在模型性能与效率的平衡验证中,图 1 通过对比 FastViTHD 与 ViT-L/14、SigLIP-SO400M 等主流视觉编码器在不同大模型(Qwen2-0.5B、Vicuna-7B)下的表现,直观展现了 FastVLM 的优势:在 Qwen2-0.5B 大模型搭配下,FastViTHD 对应的 Avg-5 VLM 评估分数达 62%,而 TTFT 仅约 400ms,是 ViT-L/14(TTFT 约 800ms,分数 52%)的 1/2,同时参数规模更小(标记尺寸对应参数数量,FastViTHD 标记显著小于 ViT-L/14)。图 4 则进一步通过帕累托最优曲线对比 FastViTHD 与 FastViT 的性能 - 延迟关系:在相同 TTFT 预算下,FastViTHD 对应的 Avg-5 分数比 FastViT 高 2.5 个百分点以上;若目标性能一致,FastViTHD 可实现最高 3 倍的 TTFT 加速,且这一优势在不同分辨率与大模型规模组合下均稳定存在。
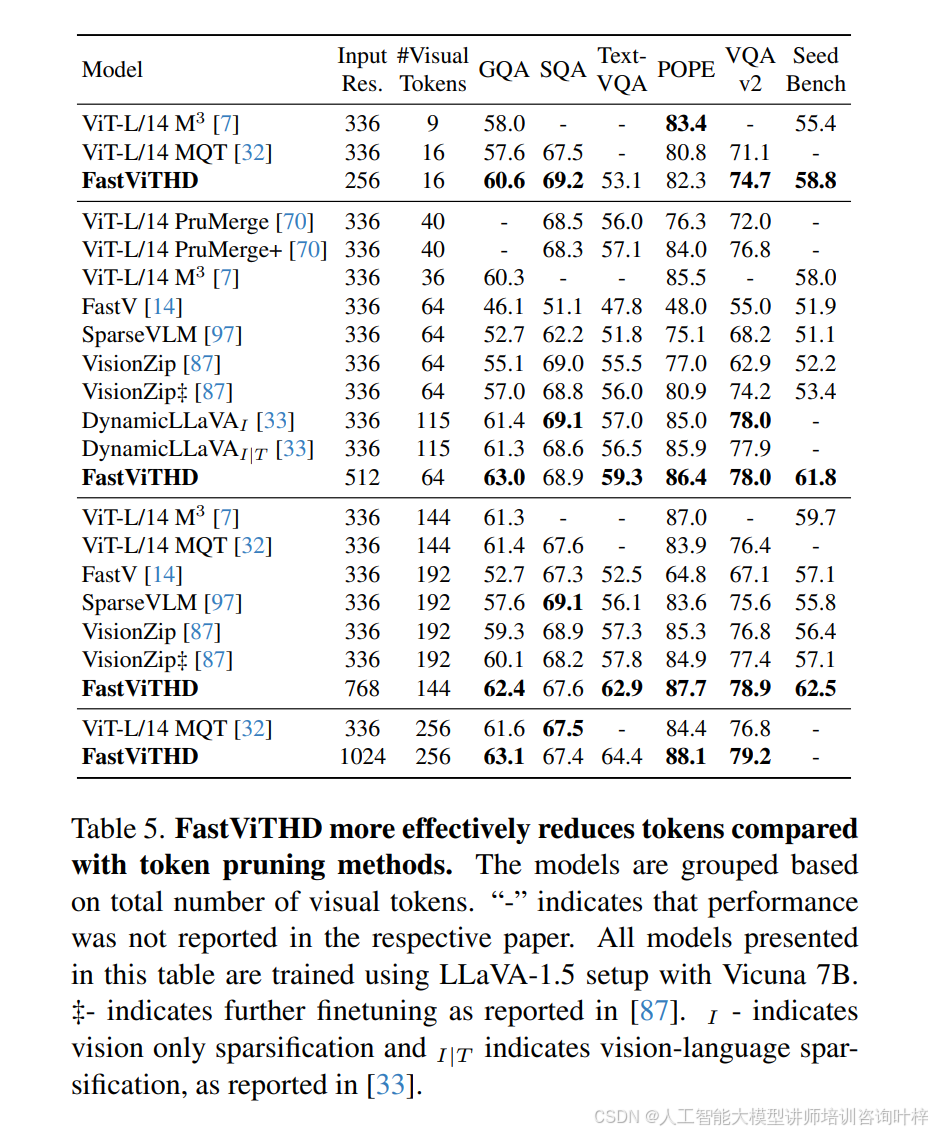
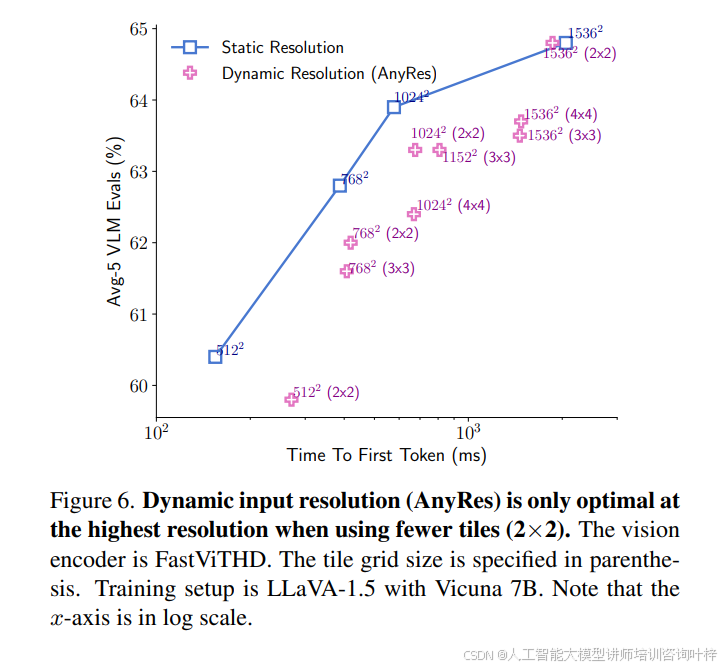 FastVLM 在静态与动态分辨率策略的选择上也有明确结论。图 6 显示,当输入分辨率未达到极端值(如 1536×1536)时,直接将模型输入分辨率设置为目标分辨率的静态策略,比 AnyRes 动态分块策略(如 768×768 拆分为 2×2、3×3 块)更优 —— 相同 TTFT 下静态策略的 Avg-5 分数更高,仅在 1536×1536 分辨率且分块数量较少(2×2)时,动态策略才展现出一定竞争力,这主要源于极端分辨率下的内存带宽限制。此外,表 5 对比 FastViTHD 与现有 token 修剪方法(如 ViT-L/14 M³、VisionZip)发现,FastViTHD 无需复杂的 token 修剪机制,仅通过降低输入分辨率(如 256×256)即可生成低至 16 个的视觉 tokens,且在 GQA(60.6)、TextVQA(53.1)等基准测试中分数高于多数修剪方法(如 ViT-L/14 M³ 16 个 tokens 时 GQA 仅 58.0),验证了其架构设计的高效性。
FastVLM 在静态与动态分辨率策略的选择上也有明确结论。图 6 显示,当输入分辨率未达到极端值(如 1536×1536)时,直接将模型输入分辨率设置为目标分辨率的静态策略,比 AnyRes 动态分块策略(如 768×768 拆分为 2×2、3×3 块)更优 —— 相同 TTFT 下静态策略的 Avg-5 分数更高,仅在 1536×1536 分辨率且分块数量较少(2×2)时,动态策略才展现出一定竞争力,这主要源于极端分辨率下的内存带宽限制。此外,表 5 对比 FastViTHD 与现有 token 修剪方法(如 ViT-L/14 M³、VisionZip)发现,FastViTHD 无需复杂的 token 修剪机制,仅通过降低输入分辨率(如 256×256)即可生成低至 16 个的视觉 tokens,且在 GQA(60.6)、TextVQA(53.1)等基准测试中分数高于多数修剪方法(如 ViT-L/14 M³ 16 个 tokens 时 GQA 仅 58.0),验证了其架构设计的高效性。
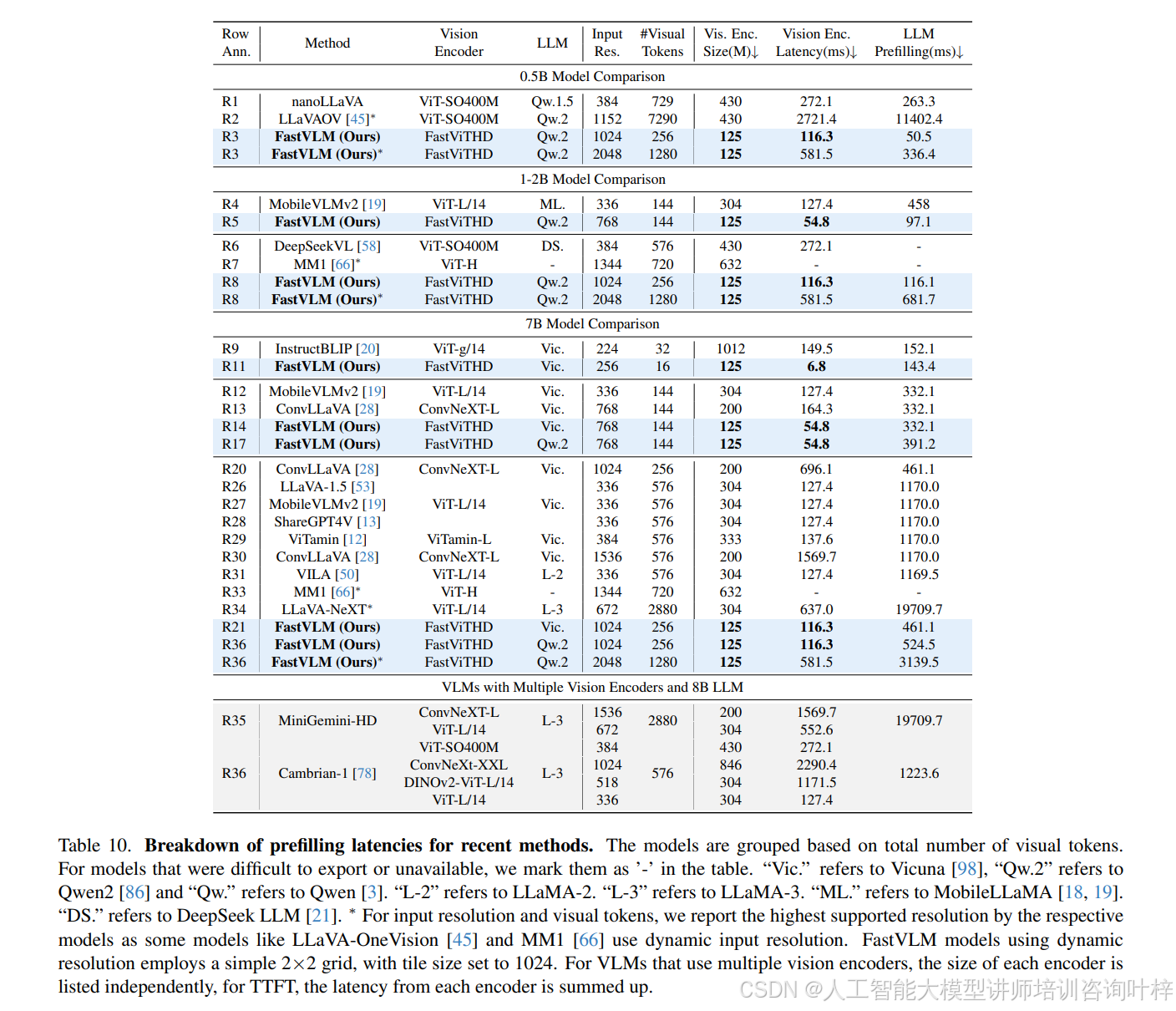
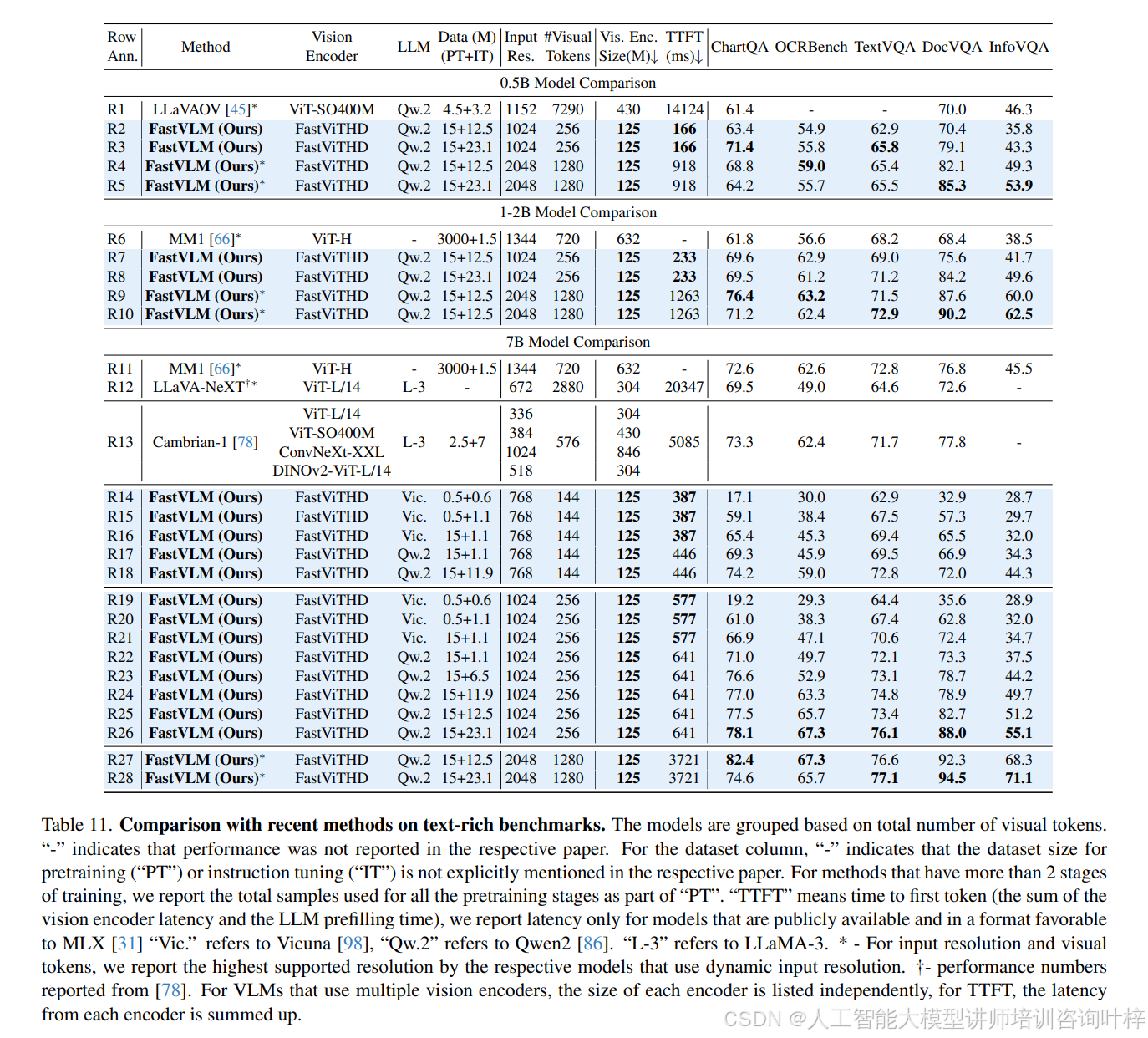
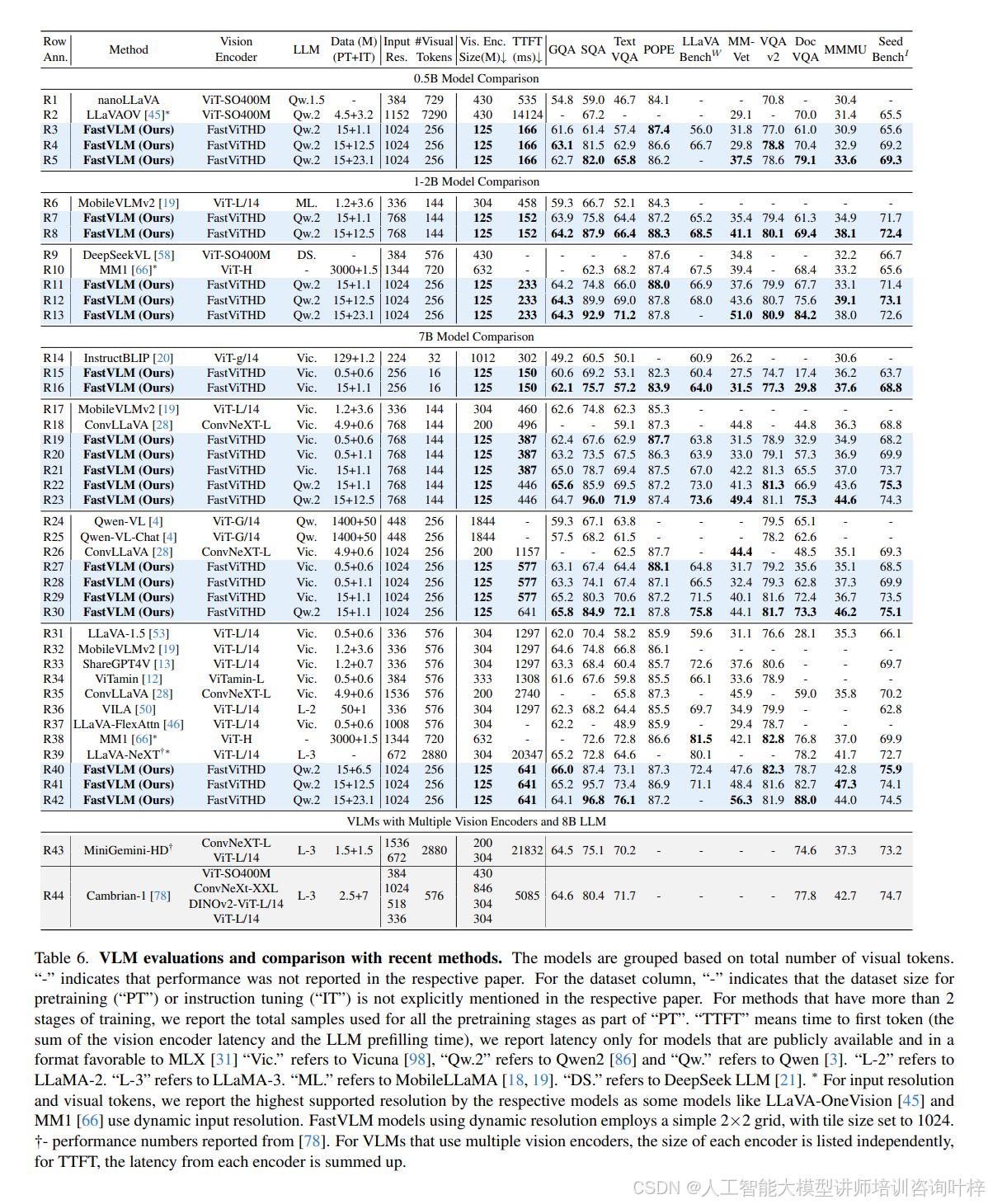 在与现有主流 VLM 的对比中,FastVLM 展现出显著的性能 - 效率优势。表 6 显示,与 LLaVA-OneVision(使用相同 0.5B Qwen2 大模型,1152×1152 分辨率)相比,FastVLM(1024×1024 分辨率)在 SeedBench、MMMU、DocVQA 等关键基准测试中性能更优(如 SeedBench I 达 69.2,LLaVA-OneVision 为 65.5),同时 TTFT 仅 166ms,是前者(14124ms)的 1/85,视觉编码器参数规模也仅为前者(SigLIP-SO400M,430M)的 1/3.4。与 ConvLLaVA(Vicuna-7B 大模型,768×768 分辨率)相比,FastVLM 在 TextVQA(67.5 vs 59.1)、DocVQA(57.3 vs 44.8)上分数更高,TTFT 却从 496ms 降至 387ms,参数规模从 200M 缩减至 125M。即使面对多视觉编码器模型(如 Cambrian-1,使用 ViT-L/14、ConvNeXt-XXL 等多个编码器),FastVLM 单编码器设计仍更高效 ——表 10 显示 Cambrian-1 的 TTFT 约 5085ms,而 FastVLM(1024×1024 分辨率,Qwen2-7B 大模型)仅 641ms,是前者的 1/7.9,同时 表 11 中文本密集型任务(如 DocVQA 82.7 vs 77.8)性能更优。
在与现有主流 VLM 的对比中,FastVLM 展现出显著的性能 - 效率优势。表 6 显示,与 LLaVA-OneVision(使用相同 0.5B Qwen2 大模型,1152×1152 分辨率)相比,FastVLM(1024×1024 分辨率)在 SeedBench、MMMU、DocVQA 等关键基准测试中性能更优(如 SeedBench I 达 69.2,LLaVA-OneVision 为 65.5),同时 TTFT 仅 166ms,是前者(14124ms)的 1/85,视觉编码器参数规模也仅为前者(SigLIP-SO400M,430M)的 1/3.4。与 ConvLLaVA(Vicuna-7B 大模型,768×768 分辨率)相比,FastVLM 在 TextVQA(67.5 vs 59.1)、DocVQA(57.3 vs 44.8)上分数更高,TTFT 却从 496ms 降至 387ms,参数规模从 200M 缩减至 125M。即使面对多视觉编码器模型(如 Cambrian-1,使用 ViT-L/14、ConvNeXt-XXL 等多个编码器),FastVLM 单编码器设计仍更高效 ——表 10 显示 Cambrian-1 的 TTFT 约 5085ms,而 FastVLM(1024×1024 分辨率,Qwen2-7B 大模型)仅 641ms,是前者的 1/7.9,同时 表 11 中文本密集型任务(如 DocVQA 82.7 vs 77.8)性能更优。
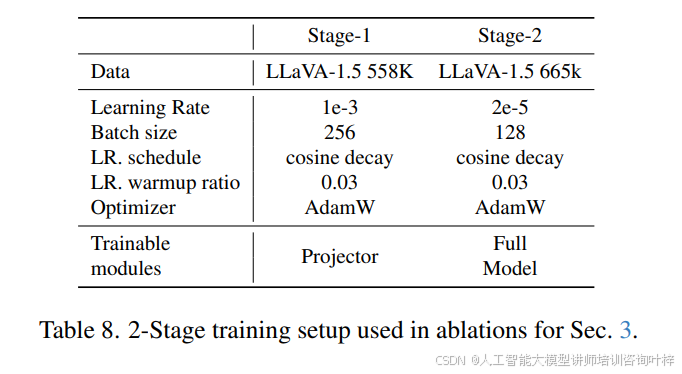
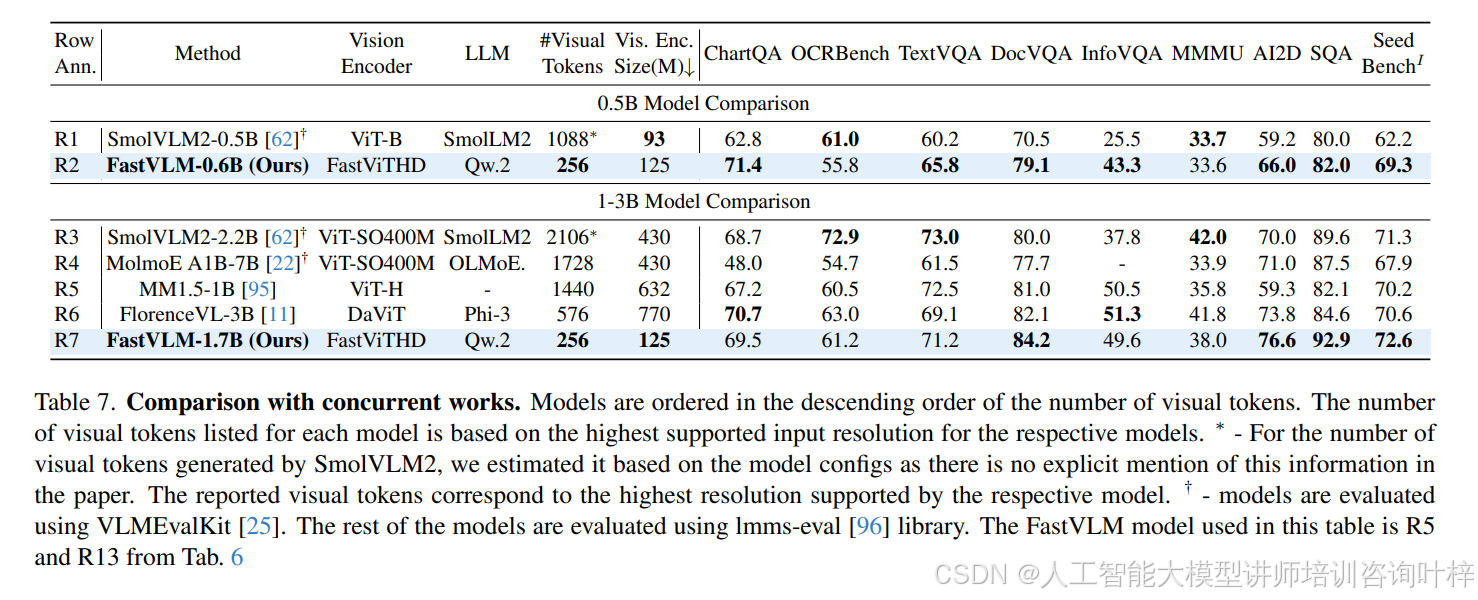
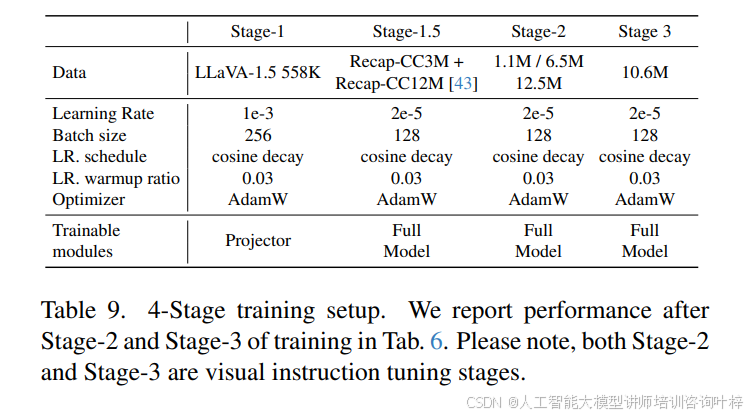 FastVLM 的训练流程采用多阶段优化策略,表 8 与 表 9 详细列出了 2 阶段与 4 阶段训练的参数设置:2 阶段训练中,Stage-1 仅训练投影层(学习率 1e-3,batch size 256),Stage-2 微调全模型(学习率 2e-5,batch size 128);4 阶段训练则新增 Stage-1.5(分辨率适应预训练,使用 15M 样本)与 Stage-3(高质量指令微调,如 MammothVL 数据集),进一步提升模型在高分辨率与复杂任务上的性能。表 7 显示,随着训练数据规模扩大(如指令微调数据从 1.1M 增至 23.1M),FastVLM 在 ChartQA(71.4)、InfoVQA(43.3)等任务上的分数持续提升,验证了其数据扩展性。
FastVLM 的训练流程采用多阶段优化策略,表 8 与 表 9 详细列出了 2 阶段与 4 阶段训练的参数设置:2 阶段训练中,Stage-1 仅训练投影层(学习率 1e-3,batch size 256),Stage-2 微调全模型(学习率 2e-5,batch size 128);4 阶段训练则新增 Stage-1.5(分辨率适应预训练,使用 15M 样本)与 Stage-3(高质量指令微调,如 MammothVL 数据集),进一步提升模型在高分辨率与复杂任务上的性能。表 7 显示,随着训练数据规模扩大(如指令微调数据从 1.1M 增至 23.1M),FastVLM 在 ChartQA(71.4)、InfoVQA(43.3)等任务上的分数持续提升,验证了其数据扩展性。
https://www.arxiv.org/pdf/2412.13303
https://github.com/apple/ml-fastvlm