【完整源码+数据集+部署教程】鸡粪病害检测系统源码和数据集:改进yolo11-bifpn-SDI
背景意义
在现代农业生产中,鸡粪作为一种重要的有机肥料,广泛应用于土壤改良和作物生长。然而,鸡粪在储存和施用过程中,常常受到各种病害的影响,这不仅影响其肥料效果,还可能对环境和人类健康造成潜在威胁。因此,及时、准确地检测鸡粪中的病害,对于保障农业生产的安全性和可持续性具有重要意义。
近年来,随着计算机视觉技术的迅猛发展,基于深度学习的目标检测方法在农业病害检测中展现出了巨大的潜力。YOLO(You Only Look Once)系列模型因其高效的实时检测能力和较高的准确率,成为了研究者们关注的焦点。特别是YOLOv11的改进版本,通过引入更为先进的特征提取和处理机制,能够在复杂背景下更好地识别和分类不同类型的病害。这为鸡粪病害的自动检测提供了新的技术手段。
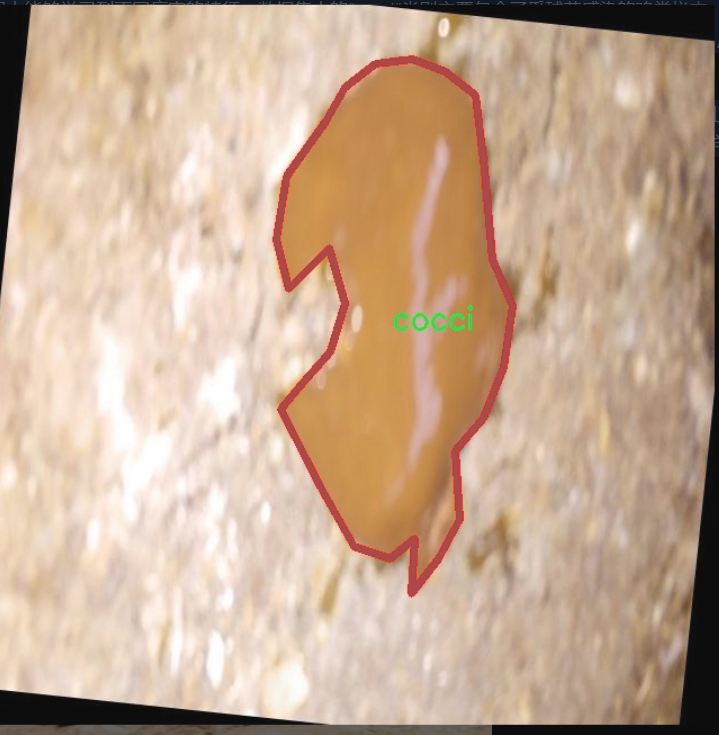
本研究旨在基于改进的YOLOv11模型,构建一个高效的鸡粪病害检测系统。该系统将利用一个包含5000张图像的数据集,涵盖了三种主要类别:健康的鸡粪、受球菌感染的鸡粪(cocci)和受沙门氏菌感染的鸡粪(salmo)。通过对这些图像的深度学习训练,系统将能够自动识别和分类鸡粪中的病害,极大地提高检测效率,降低人工成本。
此外,研究还将探讨数据集的构建与增强技术对模型性能的影响。通过随机旋转和图像预处理等方法,进一步提升模型的鲁棒性和适应性。这不仅为鸡粪病害的检测提供了可靠的技术支持,也为其他农业病害的监测和管理提供了借鉴,推动农业智能化的发展。因此,本研究具有重要的理论价值和实际应用意义。
图片效果
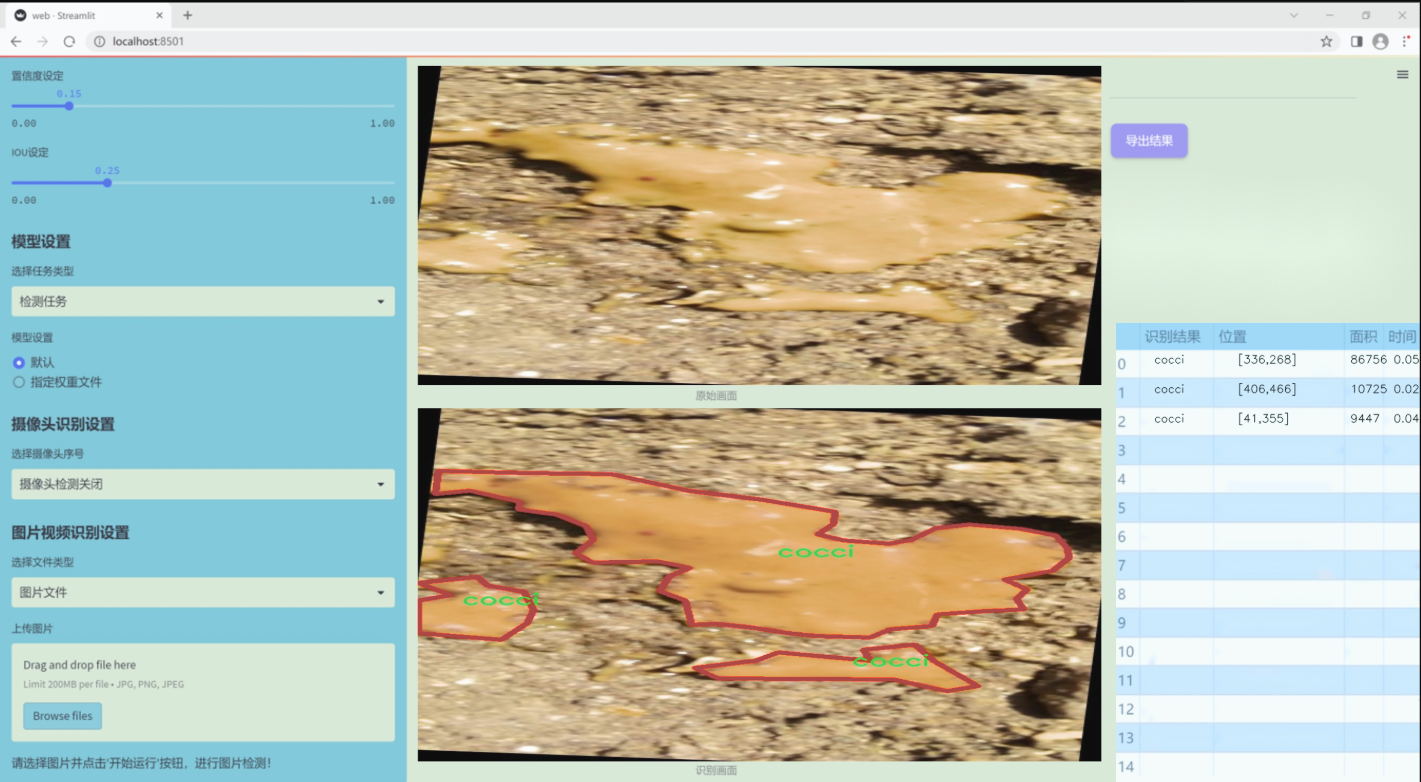
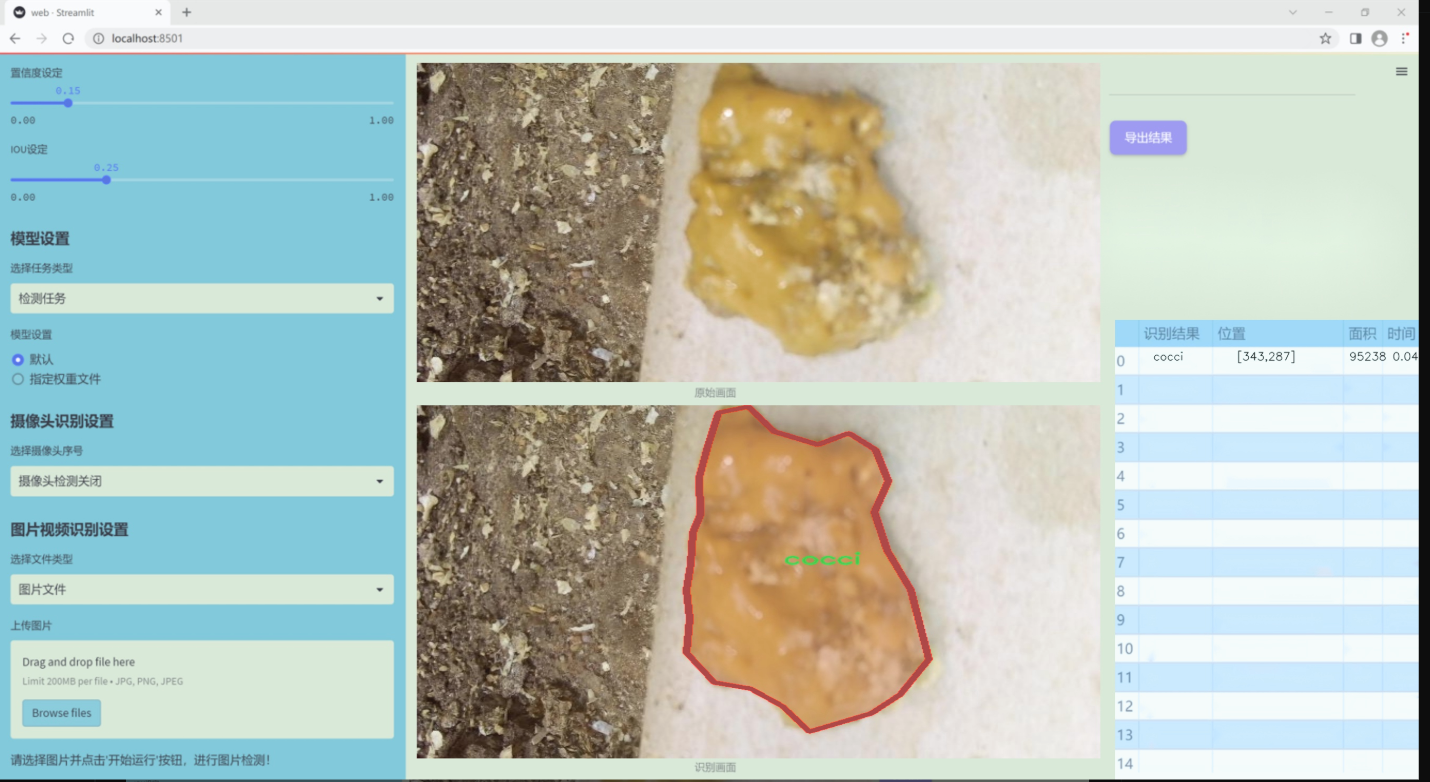
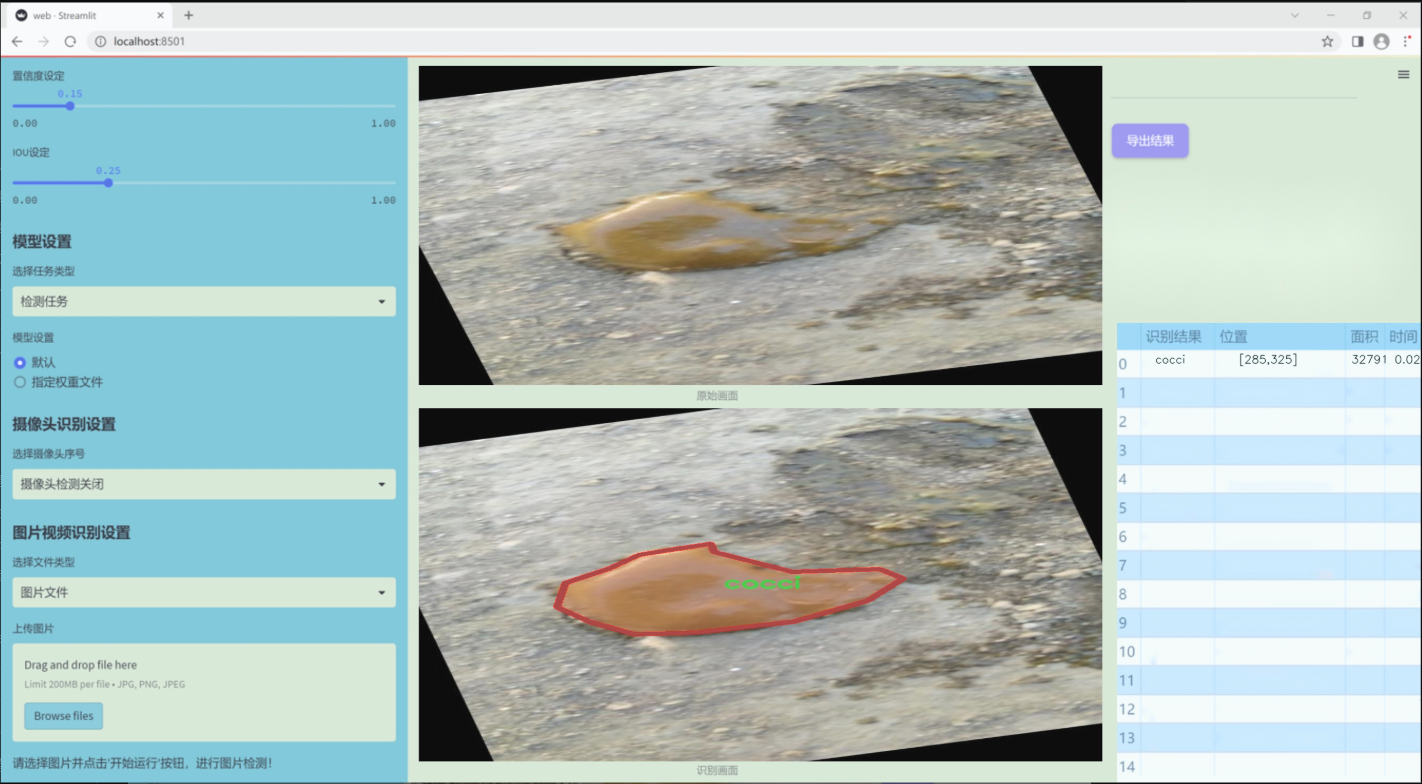
数据集信息
本项目数据集信息介绍
本项目所使用的数据集旨在支持改进YOLOv11的鸡粪病害检测系统,专注于对鸡粪中可能出现的病害进行精准识别与分类。数据集的主题为“CHICKEN MANURE YOLO”,其设计目的是为了解决在养殖业中常见的鸡粪病害问题,从而提高养殖效率和鸡只健康水平。该数据集包含三种主要类别,分别为“cocci”(球菌感染)、“healthy”(健康状态)和“salmo”(沙门氏菌感染)。这三类的划分不仅有助于快速识别病害,还能为养殖者提供有效的预防和处理建议。
在数据集的构建过程中,研究团队收集了大量真实场景下的鸡粪样本,确保数据的多样性和代表性。每一类样本均经过精心标注,确保模型在训练过程中能够学习到不同病害的特征。数据集中的“cocci”类别主要包含了受球菌感染的鸡粪样本,这类样本通常表现出特定的颜色和质地变化;而“salmo”类别则集中于沙门氏菌感染的样本,具有明显的病变特征;最后,“healthy”类别则代表健康状态下的鸡粪,作为对比样本,帮助模型更好地理解正常与异常之间的差异。
通过使用这一数据集,改进后的YOLOv11模型将能够在实际应用中快速、准确地识别出鸡粪中的病害类型,从而为养殖业提供更为高效的管理方案。这不仅有助于降低疾病传播的风险,还能提升整体养殖效益,促进可持续发展。数据集的多样性和丰富性为模型的训练提供了坚实的基础,使其在实际应用中具备良好的泛化能力和适应性。



核心代码
以下是代码中最核心的部分,并附上详细的中文注释:
import torch
import torch.nn as nn
from einops import rearrange
class LayerNorm2d(nn.Module):
“”"
2D层归一化类
“”"
def init(self, normalized_shape, eps=1e-6, elementwise_affine=True):
super().init()
# 初始化LayerNorm
self.norm = nn.LayerNorm(normalized_shape, eps, elementwise_affine)
def forward(self, x):# 输入x的形状为 (B, C, H, W),需要调整为 (B, H, W, C) 进行归一化x = rearrange(x, 'b c h w -> b h w c').contiguous()x = self.norm(x) # 进行归一化# 再次调整回 (B, C, H, W)x = rearrange(x, 'b h w c -> b c h w').contiguous()return x
class CrossScan(torch.autograd.Function):
“”"
跨扫描操作
“”"
@staticmethod
def forward(ctx, x: torch.Tensor):
B, C, H, W = x.shape
ctx.shape = (B, C, H, W)
xs = x.new_empty((B, 4, C, H * W)) # 创建一个新的张量用于存储结果
xs[:, 0] = x.flatten(2, 3) # 将x展平
xs[:, 1] = x.transpose(dim0=2, dim1=3).flatten(2, 3) # 转置并展平
xs[:, 2:4] = torch.flip(xs[:, 0:2], dims=[-1]) # 翻转前两个维度
return xs
@staticmethod
def backward(ctx, ys: torch.Tensor):B, C, H, W = ctx.shapeL = H * W# 反向传播时的计算ys = ys[:, 0:2] + ys[:, 2:4].flip(dims=[-1]).view(B, 2, -1, L)y = ys[:, 0] + ys[:, 1].view(B, -1, W, H).transpose(dim0=2, dim1=3).contiguous().view(B, -1, L)return y.view(B, -1, H, W)
class SelectiveScanCore(torch.autograd.Function):
“”"
选择性扫描核心操作
“”"
@staticmethod
@torch.cuda.amp.custom_fwd
def forward(ctx, u, delta, A, B, C, D=None, delta_bias=None, delta_softplus=False, nrows=1, backnrows=1,
oflex=True):
# 确保输入张量是连续的
if u.stride(-1) != 1:
u = u.contiguous()
if delta.stride(-1) != 1:
delta = delta.contiguous()
if D is not None and D.stride(-1) != 1:
D = D.contiguous()
if B.stride(-1) != 1:
B = B.contiguous()
if C.stride(-1) != 1:
C = C.contiguous()
if B.dim() == 3:
B = B.unsqueeze(dim=1) # 扩展维度
ctx.squeeze_B = True
if C.dim() == 3:
C = C.unsqueeze(dim=1) # 扩展维度
ctx.squeeze_C = True
# 进行选择性扫描的前向计算out, x, *rest = selective_scan_cuda_core.fwd(u, delta, A, B, C, D, delta_bias, delta_softplus, 1)ctx.save_for_backward(u, delta, A, B, C, D, delta_bias, x) # 保存用于反向传播的张量return out@staticmethod
@torch.cuda.amp.custom_bwd
def backward(ctx, dout, *args):u, delta, A, B, C, D, delta_bias, x = ctx.saved_tensorsif dout.stride(-1) != 1:dout = dout.contiguous()# 进行选择性扫描的反向计算du, ddelta, dA, dB, dC, dD, ddelta_bias, *rest = selective_scan_cuda_core.bwd(u, delta, A, B, C, D, delta_bias, dout, x, ctx.delta_softplus, 1)return (du, ddelta, dA, dB, dC, dD, ddelta_bias, None, None, None, None)
def cross_selective_scan(
x: torch.Tensor = None,
x_proj_weight: torch.Tensor = None,
x_proj_bias: torch.Tensor = None,
dt_projs_weight: torch.Tensor = None,
dt_projs_bias: torch.Tensor = None,
A_logs: torch.Tensor = None,
Ds: torch.Tensor = None,
out_norm: torch.nn.Module = None,
out_norm_shape=“v0”,
nrows=-1,
backnrows=-1,
delta_softplus=True,
to_dtype=True,
force_fp32=False,
ssoflex=True,
SelectiveScan=None,
scan_mode_type=‘default’
):
“”"
跨选择性扫描操作
“”"
B, D, H, W = x.shape
D, N = A_logs.shape
K, D, R = dt_projs_weight.shape
L = H * W
# 定义选择性扫描的内部函数
def selective_scan(u, delta, A, B, C, D=None, delta_bias=None, delta_softplus=True):return SelectiveScan.apply(u, delta, A, B, C, D, delta_bias, delta_softplus, nrows, backnrows, ssoflex)xs = CrossScan.apply(x) # 应用跨扫描操作# 进行权重投影
x_dbl = torch.einsum("b k d l, k c d -> b k c l", xs, x_proj_weight)
if x_proj_bias is not None:x_dbl = x_dbl + x_proj_bias.view(1, K, -1, 1)# 拆分投影结果
dts, Bs, Cs = torch.split(x_dbl, [R, N, N], dim=2)
dts = torch.einsum("b k r l, k d r -> b k d l", dts, dt_projs_weight)
xs = xs.view(B, -1, L)
dts = dts.contiguous().view(B, -1, L)# HiPPO矩阵
As = -torch.exp(A_logs.to(torch.float)) # 计算A
Bs = Bs.contiguous()
Cs = Cs.contiguous()
Ds = Ds.to(torch.float) # 转换为浮点型
delta_bias = dt_projs_bias.view(-1).to(torch.float)# 进行选择性扫描
ys: torch.Tensor = selective_scan(xs, dts, As, Bs, Cs, Ds, delta_bias, delta_softplus
).view(B, K, -1, H, W)# 进行合并操作
y: torch.Tensor = CrossMerge.apply(ys)# 进行输出归一化
if out_norm_shape in ["v1"]:y = out_norm(y.view(B, -1, H, W)).permute(0, 2, 3, 1)
else:y = y.transpose(dim0=1, dim1=2).contiguous()y = out_norm(y).view(B, H, W, -1)return (y.to(x.dtype) if to_dtype else y)
class SS2D(nn.Module):
“”"
SS2D模块
“”"
def init(self, d_model=96, d_state=16, ssm_ratio=2.0, ssm_rank_ratio=2.0, dt_rank=“auto”, act_layer=nn.SiLU, dropout=0.0, bias=False, forward_type=“v2”, **kwargs):
super().init()
d_expand = int(ssm_ratio * d_model) # 扩展维度
d_inner = int(min(ssm_rank_ratio, ssm_ratio) * d_model) if ssm_rank_ratio > 0 else d_expand
self.dt_rank = math.ceil(d_model / 16) if dt_rank == “auto” else dt_rank
self.d_state = math.ceil(d_model / 6) if d_state == “auto” else d_state # 20240109
self.K = 4
# 输入投影self.in_proj = nn.Conv2d(d_model, d_expand, kernel_size=1, stride=1, groups=1, bias=bias)self.act: nn.Module = nn.GELU()# 输出投影self.out_proj = nn.Conv2d(d_expand, d_model, kernel_size=1, stride=1, bias=bias)self.dropout = nn.Dropout(dropout) if dropout > 0. else nn.Identity()# 初始化参数self.Ds = nn.Parameter(torch.ones((self.K * d_inner)))self.A_logs = nn.Parameter(torch.zeros((self.K * d_inner, self.d_state))) # A == -A_logs.exp() < 0self.dt_projs_weight = nn.Parameter(torch.randn((self.K, d_inner, self.dt_rank)))self.dt_projs_bias = nn.Parameter(torch.randn((self.K, d_inner)))def forward_corev2(self, x: torch.Tensor, channel_first=False, SelectiveScan=SelectiveScanCore, cross_selective_scan=cross_selective_scan, force_fp32=None):if not channel_first:x = x.permute(0, 3, 1, 2).contiguous() # 调整维度x = cross_selective_scan(x, self.x_proj_weight, None, self.dt_projs_weight, self.dt_projs_bias,self.A_logs, self.Ds,out_norm=getattr(self, "out_norm", None),out_norm_shape=getattr(self, "out_norm_shape", "v0"),delta_softplus=True, force_fp32=force_fp32,SelectiveScan=SelectiveScan, ssoflex=self.training,)return xdef forward(self, x: torch.Tensor, **kwargs):x = self.in_proj(x) # 输入投影x = self.act(x) # 激活函数y = self.forward_core(x) # 核心前向计算out = self.dropout(self.out_proj(y)) # 输出投影和dropoutreturn out
代码核心部分说明:
LayerNorm2d: 实现了2D层归一化,用于处理图像数据的归一化。
CrossScan: 实现了跨扫描操作,能够对输入张量进行多维度的展平和翻转。
SelectiveScanCore: 选择性扫描的核心操作,负责前向和反向传播的计算。
cross_selective_scan: 实现了跨选择性扫描的功能,结合了输入的多个参数进行复杂的计算。
SS2D: 主要模块,包含输入投影、输出投影、以及核心的选择性扫描逻辑。
以上代码是实现深度学习模型中的一些重要操作,主要用于图像处理和特征提取。
这个程序文件 mamba_yolo.py 是一个实现 YOLO(You Only Look Once)目标检测模型的 PyTorch 代码。代码中定义了多个类和函数,主要用于构建神经网络的不同模块和操作。以下是对代码的详细说明:
首先,代码导入了必要的库,包括 PyTorch、数学运算、类型提示等。接着,定义了一些辅助函数和类,例如 LayerNorm2d,它实现了二维层归一化,适用于图像数据。该类在前向传播中将输入张量的维度重新排列,以便进行归一化处理。
接下来,定义了 autopad 函数,用于根据卷积核的大小自动计算填充,以保持输出形状与输入形状相同。
然后,代码中实现了几个重要的自定义操作,包括 CrossScan 和 CrossMerge。CrossScan 类用于对输入张量进行交叉扫描,生成不同方向的特征图;而 CrossMerge 类则用于将这些特征图合并。
SelectiveScanCore 类实现了选择性扫描的核心功能,通过自定义的前向和反向传播方法,支持在 GPU 上高效计算。cross_selective_scan 函数则是对选择性扫描的封装,提供了多种参数选项,以便在不同的情况下使用。
接下来,定义了 SS2D 类,这是一个重要的模块,结合了选择性扫描和卷积操作。该类的构造函数中定义了输入和输出的投影层、卷积层以及其他参数,允许在训练过程中进行灵活的调整。
RGBlock 和 LSBlock 类实现了不同的网络块,分别用于特征提取和信息融合。XSSBlock 和 VSSBlock_YOLO 类则是更复杂的模块,结合了多个前面定义的组件,形成了 YOLO 模型的基本结构。
SimpleStem 类实现了模型的初始卷积层,负责将输入图像转换为特征图。VisionClueMerge 类则用于在不同分辨率的特征图之间进行合并,增强模型的表达能力。
整体来看,这个文件实现了一个高度模块化的 YOLO 模型,允许用户根据需求进行定制和扩展。每个模块都经过精心设计,以实现高效的特征提取和目标检测功能。通过使用选择性扫描和其他先进的技术,模型能够在处理复杂场景时保持高效性和准确性。
10.4 mobilenetv4.py
以下是保留的核心代码部分,并附上详细的中文注释:
import torch
import torch.nn as nn
定义一个函数,用于确保所有层的通道数是8的倍数
def make_divisible(value: float, divisor: int, min_value: Optional[float] = None, round_down_protect: bool = True) -> int:
“”"
确保通道数是divisor的倍数
Args:
value: 原始值
divisor: 需要检查的除数
min_value: 最小值阈值
round_down_protect: 是否允许向下取整超过10%
Returns:
调整后的值,确保是int类型并且是divisor的倍数
“”"
if min_value is None:
min_value = divisor
new_value = max(min_value, int(value + divisor / 2) // divisor * divisor)
if round_down_protect and new_value < 0.9 * value:
new_value += divisor
return int(new_value)
定义一个2D卷积层的构建函数
def conv_2d(inp, oup, kernel_size=3, stride=1, groups=1, bias=False, norm=True, act=True):
“”"
构建一个2D卷积层,包含卷积、批归一化和激活函数
Args:
inp: 输入通道数
oup: 输出通道数
kernel_size: 卷积核大小
stride: 步幅
groups: 分组卷积的组数
bias: 是否使用偏置
norm: 是否使用批归一化
act: 是否使用激活函数
Returns:
nn.Sequential: 包含卷积、批归一化和激活函数的序列
“”"
conv = nn.Sequential()
padding = (kernel_size - 1) // 2
conv.add_module(‘conv’, nn.Conv2d(inp, oup, kernel_size, stride, padding, bias=bias, groups=groups))
if norm:
conv.add_module(‘BatchNorm2d’, nn.BatchNorm2d(oup))
if act:
conv.add_module(‘Activation’, nn.ReLU6())
return conv
定义反向残差块
class InvertedResidual(nn.Module):
def init(self, inp, oup, stride, expand_ratio, act=False):
“”"
初始化反向残差块
Args:
inp: 输入通道数
oup: 输出通道数
stride: 步幅
expand_ratio: 扩展比例
act: 是否使用激活函数
“”"
super(InvertedResidual, self).init()
self.stride = stride
assert stride in [1, 2] # 步幅只能是1或2
hidden_dim = int(round(inp * expand_ratio)) # 计算隐藏层的通道数
self.block = nn.Sequential()
if expand_ratio != 1:
self.block.add_module(‘exp_1x1’, conv_2d(inp, hidden_dim, kernel_size=1, stride=1)) # 扩展卷积
self.block.add_module(‘conv_3x3’, conv_2d(hidden_dim, hidden_dim, kernel_size=3, stride=stride, groups=hidden_dim)) # 深度卷积
self.block.add_module(‘red_1x1’, conv_2d(hidden_dim, oup, kernel_size=1, stride=1, act=act)) # 投影卷积
self.use_res_connect = self.stride == 1 and inp == oup # 判断是否使用残差连接
def forward(self, x):if self.use_res_connect:return x + self.block(x) # 使用残差连接else:return self.block(x)
定义MobileNetV4模型
class MobileNetV4(nn.Module):
def init(self, model):
“”"
初始化MobileNetV4模型
Args:
model: 模型类型
“”"
super().init()
self.model = model
# 根据模型类型构建各个层
self.conv0 = build_blocks(self.spec[‘conv0’])
self.layer1 = build_blocks(self.spec[‘layer1’])
self.layer2 = build_blocks(self.spec[‘layer2’])
self.layer3 = build_blocks(self.spec[‘layer3’])
self.layer4 = build_blocks(self.spec[‘layer4’])
self.layer5 = build_blocks(self.spec[‘layer5’])
self.features = nn.ModuleList([self.conv0, self.layer1, self.layer2, self.layer3, self.layer4, self.layer5])
def forward(self, x):"""前向传播Args:x: 输入数据Returns:features: 特征列表"""input_size = x.size(2)scale = [4, 8, 16, 32]features = [None, None, None, None]for f in self.features:x = f(x)if input_size // x.size(2) in scale:features[scale.index(input_size // x.size(2))] = xreturn features
定义不同类型的MobileNetV4模型的构建函数
def MobileNetV4ConvSmall():
return MobileNetV4(‘MobileNetV4ConvSmall’)
def MobileNetV4ConvMedium():
return MobileNetV4(‘MobileNetV4ConvMedium’)
def MobileNetV4ConvLarge():
return MobileNetV4(‘MobileNetV4ConvLarge’)
def MobileNetV4HybridMedium():
return MobileNetV4(‘MobileNetV4HybridMedium’)
def MobileNetV4HybridLarge():
return MobileNetV4(‘MobileNetV4HybridLarge’)
if name == ‘main’:
model = MobileNetV4ConvSmall() # 创建一个MobileNetV4ConvSmall模型
inputs = torch.randn((1, 3, 640, 640)) # 生成随机输入
res = model(inputs) # 前向传播
for i in res:
print(i.size()) # 打印输出特征的尺寸
代码说明
make_divisible: 确保通道数是8的倍数,避免不必要的计算。
conv_2d: 构建一个包含卷积、批归一化和激活函数的2D卷积层。
InvertedResidual: 定义反向残差块,使用深度卷积和1x1卷积进行特征提取。
MobileNetV4: 定义MobileNetV4模型,包含多个卷积层和反向残差块。
模型构建函数: 提供不同版本的MobileNetV4模型构建接口。
这个程序文件定义了一个名为 MobileNetV4 的深度学习模型,主要用于图像分类等计算机视觉任务。该模型是 MobileNet 系列的一部分,专注于在移动设备上实现高效的卷积神经网络(CNN)。以下是对代码的详细讲解。
首先,程序导入了必要的库,包括 torch 和 torch.nn,这些库是 PyTorch 深度学习框架的核心组件。接着,定义了一些模型的规格,包括不同大小的 MobileNetV4 变体(小型、中型、大型和混合型)。这些规格以字典的形式存储,描述了每个层的类型、数量和参数。
在 make_divisible 函数中,确保每个层的通道数是可被8整除的,这在某些硬件上可以提高性能。这个函数接收一个值和一个除数,计算出一个符合条件的整数值。
conv_2d 函数用于构建一个二维卷积层,包含卷积操作、批归一化和激活函数(ReLU6)。这个函数的灵活性在于可以选择是否包含归一化和激活。
InvertedResidual 类实现了倒残差块,这是 MobileNetV4 的核心构建块之一。它使用了深度可分离卷积,通过扩展和压缩通道数来提高模型的表达能力。
UniversalInvertedBottleneckBlock 类是另一个重要的构建块,允许更灵活的卷积结构,包括不同大小的卷积核和下采样选项。
build_blocks 函数根据层的规格构建相应的层,支持不同类型的卷积块(如 convbn、uib 和 fused_ib)。
MobileNetV4 类是模型的主要实现。它在初始化时根据传入的模型名称构建各个层,并将它们存储在一个模块列表中。forward 方法定义了模型的前向传播过程,返回不同尺度的特征图。
最后,文件中定义了一些工厂函数(如 MobileNetV4ConvSmall、MobileNetV4ConvMedium 等),用于创建不同变体的 MobileNetV4 模型。在 main 块中,创建了一个小型模型并对随机输入进行了前向传播,输出了每个特征图的尺寸。
总体来说,这个文件提供了一个灵活且高效的 MobileNetV4 实现,适用于各种计算机视觉任务。通过不同的模型规格,用户可以根据需求选择合适的模型,以在性能和效率之间取得平衡。
源码文件

源码获取
欢迎大家点赞、收藏、关注、评论啦 、查看👇🏻获取联系方式👇🏻