Text2SQL与DataAgent技术深度对比与实践指南
在数据驱动决策的时代,如何让非技术人员也能轻松获取数据洞察?Text2SQL和DataAgent两大技术路线各有千秋,本文带你深入剖析它们的技术原理、优劣势对比及实际应用场景,助你在企业数据智能化转型中做出明智选择。
一、引言:数据民主化的两条进化路径
当今企业数字化转型的浪潮中,数据分析能力已成为核心竞争力。然而,传统的数据分析方式存在明显痛点:
技术门槛高:SQL编写需要专业知识,非技术人员难以直接获取数据洞察
分析周期长:从提需求到数据团队交付结果,往往需要数天甚至数周
资源瓶颈:数据团队成为企业数据分析的唯一通道,造成严重资源短缺
为解决这些问题,基于大语言模型(LLM)的两种技术路线应运而生:Text2SQL和DataAgent。它们代表了数据民主化的两种不同思路:
Text2SQL:专注于将自然语言转换为SQL查询语句,让用户通过对话方式直接获取数据
DataAgent:构建完整的数据分析助手,不仅能生成SQL,还能进行数据可视化和洞察解读
这两种技术路线看似相似,实则各有侧重,适用于不同的应用场景。本文将从技术原理、架构设计、优劣势对比和实际应用案例等多个维度,为读者提供全面的技术解析和选型参考。
二、技术原理:从自然语言到数据洞察的转化之路
2.1 Text2SQL技术原理与流程
Text2SQL(文本到SQL)技术的核心是将自然语言转换为结构化查询语言(SQL),其基本流程包括:
自然语言理解:解析用户输入,提取实体(如表名、字段名)、操作意图(如查询、统计)及条件(如时间、数值范围)
语义解析:将自然语言映射为逻辑形式(如抽象语法树),并结合数据库模式(Schema)理解表间关系
SQL生成:生成符合语法和数据库约束的SQL语句,涉及模板填充或序列生成模型(如Transformer)
随着技术发展,Text2SQL经历了三个主要阶段:
早期阶段(1960s-2010s):基于规则和模板,如LUNAR系统用于阿波罗任务的地质分析
AI驱动阶段(2010s后):引入统计机器翻译和神经网络,提升复杂查询处理能力
大模型时代(2020s后):基于LLM(如Codex、SQLCoder)实现高精度生成
2.2 DataAgent技术架构与原理
DataAgent作为一种更全面的数据分析助手,其技术架构更为复杂,通常包含三个核心维度:
数据源维度:
结构化数据:关系型数据库(MySQL、Oracle等)、电子表格、JSON/XML等
半结构化数据:Log文件、Markdown等
非结构化数据:图像、视频、PDF文档等
大模型维度:
自然语言转API:将用户问题转化为API调用
自然语言转SQL:生成数据库查询语句
自然语言转代码:生成完整的数据分析代码
应用与可视化维度:
数据可视化:自动选择合适的图表类型展示数据
洞察解读:对分析结果进行自然语言解释
交互式探索:支持用户进一步提问和分析
在实现方式上,DataAgent可分为侵入式和非侵入式两种架构:
侵入式架构:LLM直接连接数据库,获取schema和comment来理解表结构
非侵入式架构:通过中间层隔离LLM与数据库,保护数据安全的同时提供分析能力
三、技术实现:从理论到实践的关键环节
3.1 Text2SQL的技术实现路径
3.1.1 主流数据集与评估基准
Text2SQL技术的发展离不开高质量数据集的支持,目前主流的评估数据集包括:
Spider:大规模跨域数据集,包含200个数据库、8655个问题,专注于复杂SQL查询(多表连接、聚合操作等)
WikiSQL:基于Wikipedia表格构建,包含25,000+表格和80,000+问题-SQL对,但查询相对简单
UNITE:整合18个公开数据集的统一基准测试框架
SParC和CoSQL:专注于多轮对话式Text2SQL场景
ATIS:航空旅行领域的早期数据集
这些数据集可按照查询复杂度、领域特定性和交互模式(单轮vs对话式)等维度进行分类。
3.1.2 模型选择与优化策略
Text2SQL的模型实现主要有三种技术路线:
Seq2Seq模型:早期方案,将问题编码为向量,再解码为SQL
Transformer架构:利用自注意力机制处理长距离依赖,提升复杂查询生成能力
基于BERT的模型:利用预训练语言模型增强语义理解,提高跨域泛化能力
在大模型时代,主流的Text2SQL实现方案包括:
SQLCoder:专门针对SQL生成任务微调的模型,在Spider等基准上表现优异
DB-GPT-Hub:结合RAG技术的端到端Text2SQL框架,支持多种数据库方言
3.1.3 Tool-SQL:解决数据库不匹配问题的新思路
传统Text2SQL面临的一个关键挑战是生成的SQL与实际数据库不匹配,主要表现为:
条件不匹配:如选择错误的表、字段或生成不匹配的条件值
更严格约束的不匹配:如不符合外键关系或数据类型限制
Tool-SQL框架通过引入两个专用工具解决这些问题:
数据库检索器:当SQL条件与数据库不匹配时,检索相似的数据库单元作为参考
错误检测器:识别SQL中的错误并提供修复建议
3.1.4 实战示例:最小可用的Text2SQL服务(含基础校验)
下面给出一个轻量示例:给模型提供数据库Schema与用户问题,生成SQL后做基础语法与字段校验,再执行并返回结果。
# pip install openai sqlalchemy sqlparse pymysql
from typing import List, Dict
import re
import sqlparse
from sqlalchemy import create_engine, text# 1) 准备数据库连接(示例:MySQL)
ENGINE = create_engine("mysql+pymysql://user:password@host:3306/dbname?charset=utf8mb4",pool_pre_ping=True,
)# 2) 提取数据库Schema(也可离线维护成文本)
def get_schema(engine) -> str:with engine.connect() as conn:rows = conn.execute(text("""SELECT TABLE_NAME, COLUMN_NAME, DATA_TYPEFROM INFORMATION_SCHEMA.COLUMNSWHERE TABLE_SCHEMA = DATABASE()ORDER BY TABLE_NAME, ORDINAL_POSITION""")).fetchall()schema_lines = {}for t, c, d in rows:schema_lines.setdefault(t, []).append(f" - {c} {d}")return "\n".join([f"Table {t}:\n" + "\n".join(cols) for t, cols in schema_lines.items()])SCHEMA_TEXT = get_schema(ENGINE)# 3) 调用大模型生成SQL(以OpenAI兼容接口为例,替换成你的SDK与模型)
def llm_generate_sql(question: str, schema: str) -> str:system = ("你是SQL助手。基于提供的数据库Schema生成ANSI SQL或目标方言SQL。""只输出SQL,置于```sql```代码块中。")user = f"Schema:\n{schema}\n\n问题: {question}\n请生成SQL。"# 伪代码:替换为实际SDK调用# resp = openai.chat.completions.create(model="gpt-4o-mini", messages=[# {"role":"system","content":system},# {"role":"user","content":user}# ])# content = resp.choices[0].message.contentcontent = """
```sql
SELECT dept, COUNT(*) AS cnt
FROM employees
GROUP BY dept
ORDER BY cnt DESC
LIMIT 10;
""".strip()
m = re.search(r"sql\n([\s\S]*?)", content) sql = m.group(1).strip() if m else content return sql
4) 基础校验:
- 语法格式化/解析(sqlparse)
- 只允许白名单动词(SELECT/WITH)
- 校验表/字段是否存在(从SCHEMA_TEXT解析或预构建集合)
def is_safe_sql(sql: str) -> bool: parsed = sqlparse.parse(sql) if not parsed: return False upper = sql.upper() if not (upper.startswith("SELECT") or upper.startswith("WITH")): return False forbidden = ["DELETE ", "UPDATE ", "INSERT ", "DROP ", "ALTER ", "TRUNCATE "] if any(tok in upper for tok in forbidden): return False return True
可选:从SCHEMA_TEXT中抽取表与字段集合做进一步校验
def extract_tables_and_columns(schema_text: str) -> Dict[str, List[str]]: tables: Dict[str, List[str]] = {} current = None for line in schema_text.splitlines(): line = line.strip() if line.startswith("Table ") and line.endswith(":"): current = line[len("Table "):-1] tables[current] = [] elif line.startswith("- ") or line.startswith("• ") or line.startswith("-") or line.startswith("•"): # 宽松解析 "- col dtype" col = line.lstrip("-• ").split()[0] if current: tables[current].append(col) elif line.startswith("- ") is False and line.startswith(" - "): col = line.strip().lstrip("- ").split()[0] if current: tables[current].append(col) return tables
TABLES = extract_tables_and_columns(SCHEMA_TEXT)
def validate_columns(sql: str, tables: Dict[str, List[str]]) -> bool:
轻量校验:表名出现但字段未知时发出警告(生产可用AST更精确)
upper = sql.upper() known_tables = set(t.upper() for t in tables)
粗略匹配 FROM/JOIN 后面的标识(忽略别名复杂情况)
from_like = re.findall(r"(?:FROM|JOIN)\s+([a-zA-Z0-9_.]+)", upper) missing_tables = [t for t in from_like if t not in known_tables] return len(missing_tables) == 0
def run_sql(sql: str): with ENGINE.connect() as conn: rows = conn.execute(text(sql)).fetchall() return rows
def answer(question: str): sql = llm_generate_sql(question, SCHEMA_TEXT) if not is_safe_sql(sql) or not validate_columns(sql, TABLES): return {"error": "SQL校验未通过", "sql": sql} try: rows = run_sql(sql) return {"sql": sql, "rows": [dict(r._mapping) for r in rows]} except Exception as e: return {"error": str(e), "sql": sql}
if name == "main": print(answer("近一年各部门员工数量排名前十?"))
该示例聚焦于“最小可用”:提供Schema、生成SQL、做白名单校验与基本字段核对,适合作为原型验证的起点。#### 3.1.5 实战示例:Tool-SQL校正循环(检索器+错误检测器)下面是“数据库检索器 + 错误检测器”的最小循环伪代码,展示如何在不匹配时自动检索相似列并让LLM自我修正。```python
from difflib import get_close_matchesclass DatabaseRetriever:def __init__(self, tables):self.tables = tables # {table: [cols]}def similar_columns(self, col: str, k: int = 3):all_cols = {f"{t}.{c}": (t, c) for t, cols in self.tables.items() for c in cols}hits = get_close_matches(col, [c.split(".")[-1] for c in all_cols], n=k, cutoff=0.6)# 返回候选(表.列)result = []for h in hits:for fq, (t, c) in all_cols.items():if c == h:result.append(fq)return resultclass SqlErrorDetector:def find_unknown_columns(self, sql: str, tables) -> list[str]:# 简化:正则提取 a.b 形式的列,检查是否存在pairs = re.findall(r"([a-zA-Z_][a-zA-Z0-9_]*)\.([a-zA-Z_][a-zA-Z0-9_]*)", sql)unknown = []for t, c in pairs:if t not in tables or c not in tables.get(t, []):unknown.append(f"{t}.{c}")return unknowndef tool_sql_loop(question: str, schema: str, tables):retriever = DatabaseRetriever(tables)detector = SqlErrorDetector()sql = llm_generate_sql(question, schema)for _ in range(2): # 最多两轮自我修复bad_cols = detector.find_unknown_columns(sql, tables)if not bad_cols:breaksuggestions = {col: retriever.similar_columns(col.split(".")[-1]) for col in bad_cols}# 让LLM基于建议修正SQLrepair_prompt = (f"原SQL:\n{sql}\n这些列不存在:{bad_cols}\n"f"候选列建议:{suggestions}\n""请输出修正后的SQL,仍置于```sql```代码块中")sql = llm_generate_sql(repair_prompt, schema)return sql
3.2 DataAgent的实现架构与关键技术
DataAgent作为更完整的数据分析助手,其实现涉及多个技术模块的协同工作:
3.2.1 数据源接入与处理
DataAgent需要处理多种类型的数据源:
结构化数据处理:支持主流关系型数据库、电子表格等,需要在加载时对数据进行说明帮助LLM理解
半结构化数据处理:如Log文件解析、Markdown内容提取等
非结构化数据处理:通过OCR、PDF加载器等技术提取文本信息
3.2.2 大模型应用技术
DataAgent利用大模型实现三种核心能力:
自然语言转API:将用户问题转化为系统API调用
自然语言转SQL:生成数据库查询语句
自然语言转代码:生成完整的数据分析代码(如Python、R等)
3.2.3 可视化与交互设计
DataAgent的一大特色是自动化的数据可视化能力:
智能图表推荐:根据数据特征和分析目的自动选择合适的图表类型
交互式探索:支持用户通过自然语言调整可视化参数
洞察解读:自动生成对可视化结果的文字解释
3.2.4 实战示例:端到端DataAgent原型(SQL→DataFrame→图表→洞察)
此示例串起完整链路:从问题到SQL,再到数据可视化与自动解读,适合做PoC。
# pip install pandas matplotlib sqlalchemy pymysql
import io
import base64
import pandas as pd
import matplotlib.pyplot as plt
from sqlalchemy import create_engine, textENGINE = create_engine("mysql+pymysql://user:password@host:3306/dbname?charset=utf8mb4")def fetch_df(sql: str) -> pd.DataFrame:with ENGINE.connect() as conn:return pd.read_sql(text(sql), conn)def choose_chart(df: pd.DataFrame) -> str:# 极简规则:if len(df.columns) >= 2 and pd.api.types.is_numeric_dtype(df[df.columns[1]]):return "bar" if df.shape[0] < 30 else "line"return "table"def render_chart(df: pd.DataFrame, chart: str) -> str:if chart == "table":return df.head(20).to_markdown(index=False)x, y = df.columns[:2]plt.figure(figsize=(6, 3))if chart == "bar":plt.bar(df[x].astype(str), df[y])else:plt.plot(df[x], df[y], marker="o")plt.xticks(rotation=30, ha="right")plt.tight_layout()buf = io.BytesIO()plt.savefig(buf, format="png", dpi=150)plt.close()return base64.b64encode(buf.getvalue()).decode()def explain_insight(question: str, df: pd.DataFrame) -> str:# 生产中可用LLM归纳,这里简化为描述性统计desc = df.describe(include="all").to_dict()return f"基于问题‘{question}’,样本量={len(df)}。数值字段统计={list(desc.keys())[:3]}等。"def data_agent_answer(question: str, schema: str) -> dict:sql = llm_generate_sql(question, schema)df = fetch_df(sql)chart = choose_chart(df)payload = render_chart(df, chart)insight = explain_insight(question, df)return {"sql": sql,"chart_type": chart,"chart_payload": payload, # 若为table则是Markdown,否则是PNG的base64"insight": insight,}# 示例
if __name__ == "__main__":resp = data_agent_answer("过去12个月每月活跃用户趋势?", SCHEMA_TEXT)print({k: (v[:80] + "...") if k == "chart_payload" and isinstance(v, str) else v for k, v in resp.items()})
可将chart_payload直接渲染为图片或在前端转为<img src="data:image/png;base64,...">展示;若为table则渲染为Markdown表格。
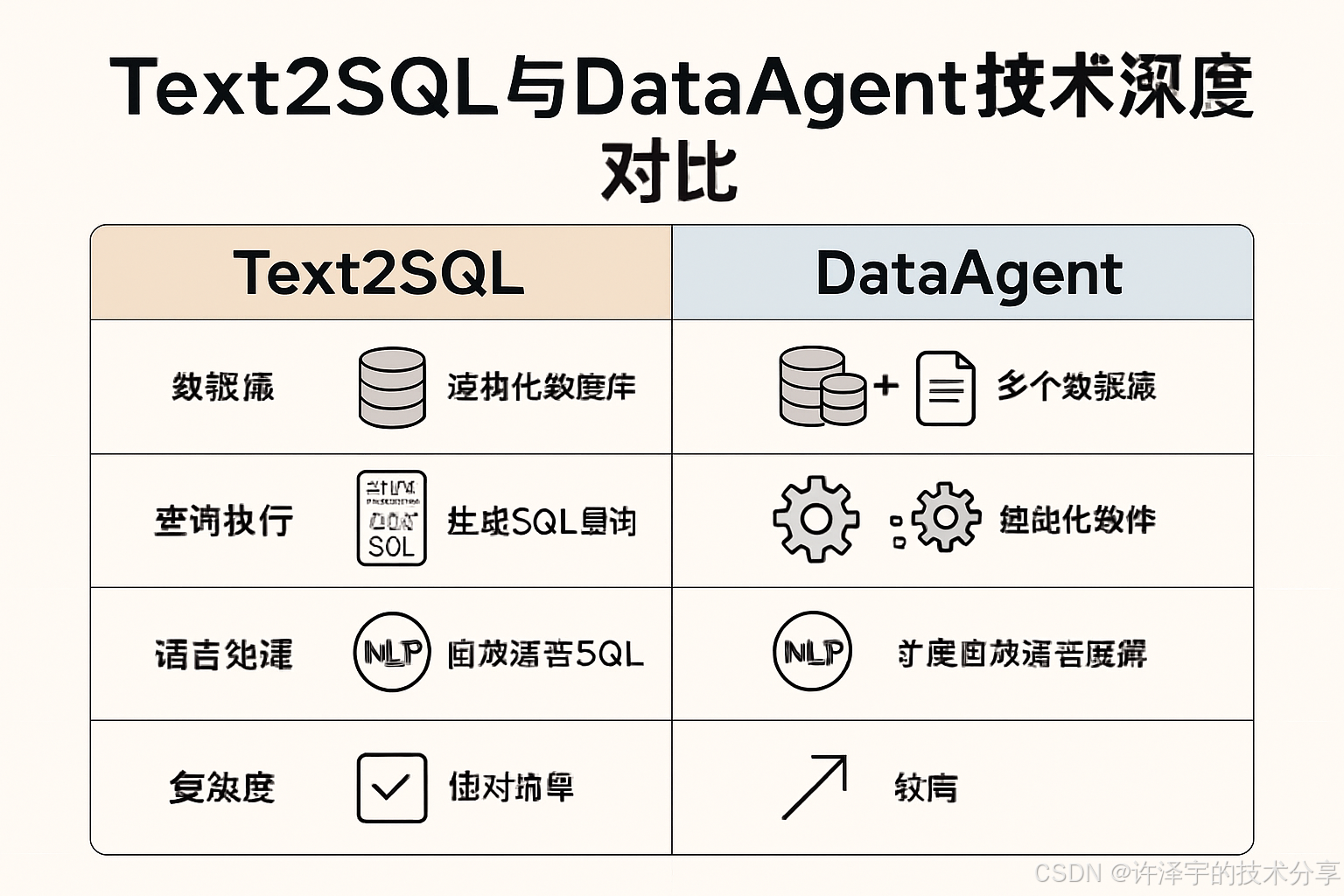
四、技术对比:Text2SQL与DataAgent的优劣势分析
4.1 技术能力对比
| 对比维度 | Text2SQL | DataAgent |
|---|---|---|
| 核心功能 | 自然语言转SQL | 完整数据分析流程 |
| 技术复杂度 | 中等 | 高 |
| 准确率上限 | 约80%(GPT-4) | 视具体实现而定 |
| 数据源支持 | 主要支持结构化数据 | 结构化+半结构化+非结构化 |
| 可视化能力 | 弱或无 | 强 |
| 部署难度 | 相对简单 | 复杂 |
| 资源消耗 | 中等 | 高 |
4.2 Text2SQL的优势与局限
优势:
专注性强:专注于SQL生成,在特定领域可以达到较高准确率
技术成熟:有大量开源模型和评估基准可供参考
部署灵活:可以轻量级集成到现有系统中
资源需求适中:相比完整的DataAgent,计算资源需求较低
局限:
准确率瓶颈:即使是GPT-4等先进模型,在复杂查询上准确率也难以突破80%
语义理解挑战:自然语言的歧义性导致查询意图理解困难
缺乏端到端体验:仅生成SQL,不提供可视化和解读能力
跨库兼容性问题:不同数据库方言间的转换仍有挑战
4.3 DataAgent的优势与挑战
优势:
全流程覆盖:从数据获取到可视化和洞察解读的完整体验
多模态支持:可处理结构化、半结构化和非结构化数据
交互体验优越:提供更自然的对话式数据探索体验
业务价值更高:直接输出可视化和洞察,降低理解门槛
挑战:
技术复杂度高:涉及多个技术模块的协同工作
资源需求大:需要更强大的计算资源支持
定制化程度高:需要针对特定业务场景进行深度定制
评估标准不统一:缺乏统一的评估基准和方法
五、应用案例:从理论到实践的落地之路
5.1 Text2SQL的典型应用场景
5.1.1 开发者工具与数据库客户端
案例:Chat2DB
Chat2DB是一款集成了Text2SQL能力的数据库客户端工具,主要面向开发者和数据分析师,提供以下功能:
自然语言转SQL查询
多种数据库方言支持
SQL优化建议
查询结果可视化
在实际应用中,Chat2DB通过多阶段生成策略和RAG检索增强方案,解决了复杂查询处理和跨库查询优化等难题,显著提升了开发效率。
5.1.2 垂直领域的Text2SQL优化
案例:MCS-SQL方法
MCS-SQL(Multiple-Choice Selection for SQL)是一种创新的Text2SQL优化方法,通过多提示架构和选择机制提升准确率:
在BIRD基准测试上达到65.5%的准确率
在Spider数据集上达到89.6%的准确率
这种方法特别适用于金融、医疗等对查询准确性要求极高的垂直领域。
5.2 DataAgent的企业级应用
5.2.1 企业BI场景的智能化转型
案例:有云数据分析助手
有云公司开发的数据分析助手是DataAgent在企业BI领域的典型应用:
非侵入式架构设计,保护数据隐私
支持多种数据源接入(MySQL、Oracle、Excel等)
自动化的数据可视化和洞察生成
在薪资分析场景中实现70%的效率提升
5.2.2 数据可视化Agent项目
数据可视化Agent项目结合了Text2SQL优化与数据可视化推理过程,实现了端到端的解决方案:
SQL生成任务优化
图表关系的业务建模
API参数的智能生成
这类项目特别适合需要频繁数据可视化的业务场景,如市场分析、运营监控等。
六、性能对比:准确率与效率的权衡
6.1 准确率对比
Text2SQL和DataAgent在准确率方面存在明显差异:
Text2SQL:
GPT-4在复杂查询上的准确率约为80%
MCS-SQL方法在BIRD基准上达到65.5%,Spider上达到89.6%
Defog的34B模型经过微调后可达到99%的准确率(特定场景)
DataAgent:
准确率评估更为复杂,需考虑SQL生成、可视化选择和洞察解读等多个环节
在企业实践中,有云数据分析助手报告的准确率约为85%
6.2 效率与资源消耗
在效率和资源消耗方面:
Text2SQL:
响应时间:通常在1-3秒内
资源消耗:中等,主要依赖于模型大小
部署成本:可本地部署或云端API调用
DataAgent:
响应时间:复杂查询可能需要5-10秒
资源消耗:高,需要更强大的计算资源
部署成本:通常需要云端部署或高性能服务器
6.3 用户体验对比
从用户体验角度看:
Text2SQL:
适合技术用户,输出SQL需要一定解读能力
交互模式相对简单,主要是问答式
学习曲线较陡,需要了解数据库结构
DataAgent:
适合非技术用户,直接输出可视化和洞察
交互模式丰富,支持多轮对话和探索
学习曲线平缓,无需了解底层技术细节
七、未来趋势:技术融合与创新方向
7.1 技术融合趋势
Text2SQL和DataAgent技术正在向融合方向发展:
多模态输入支持:结合图像、音频等多模态输入,增强理解能力
混合架构设计:结合Text2SQL的精准性和DataAgent的全面性
领域知识增强:通过RAG技术注入领域知识,提升专业场景下的表现
自适应学习能力:根据用户反馈不断优化模型表现
7.2 创新应用方向
未来,Text2SQL和DataAgent将在以下方向展现更大价值:
垂直行业解决方案:针对金融、医疗、零售等特定行业的定制化解决方案
数据治理与安全:结合数据治理能力,确保数据安全和合规
自动化决策支持:从数据分析到决策建议的闭环系统
边缘计算部署:轻量级模型支持边缘设备上的实时数据分析
7.3 技术挑战与突破点
未来技术发展仍面临以下挑战:
准确率提升:特别是在复杂查询和跨域场景下
资源优化:降低模型大小和计算资源需求
隐私保护:在保护数据隐私的同时提供高质量分析
可解释性增强:提高模型决策的可解释性和透明度
八、选型建议:如何为企业选择合适的技术路线
8.1 企业需求分析框架
在选择Text2SQL还是DataAgent时,企业可参考以下分析框架:
用户画像分析:
技术背景:技术用户更适合Text2SQL,非技术用户更适合DataAgent
使用频率:高频使用场景更适合投入DataAgent
业务场景评估:
分析复杂度:简单查询适合Text2SQL,复杂分析适合DataAgent
可视化需求:有强可视化需求的场景更适合DataAgent
资源约束考量:
技术团队规模:小团队可能更适合轻量级的Text2SQL解决方案
预算限制:预算充足的情况下可考虑更全面的DataAgent
8.2 落地路径规划
无论选择哪种技术路线,企业都可以参考以下落地路径:
试点验证阶段:
选择特定业务场景进行小规模试点
收集用户反馈,评估技术效果
能力提升阶段:
针对试点反馈进行模型优化
扩展数据源和功能支持
规模化应用阶段:
推广至更多业务场景
建立长效运维和迭代机制
8.3 混合策略建议
对于大型企业,可考虑采用混合策略:
为技术团队部署Text2SQL工具,提升开发效率
为业务部门部署DataAgent,赋能自助分析
建立统一的知识库和模型优化机制,实现资源共享
九、总结与展望
9.1 技术选择的核心考量
Text2SQL和DataAgent各有优势,选择时需考虑以下核心因素:
用户需求:是否需要端到端的分析体验
技术成熟度:项目风险承受能力
资源投入:可投入的技术和资金资源
长期规划:技术路线与企业数字化战略的契合度
9.2 未来发展展望
随着大模型技术的不断进步,我们可以预见:
技术边界模糊化:Text2SQL和DataAgent的界限将越来越模糊
专业化与通用化并行:既有面向特定领域的专业解决方案,也有通用型平台
自主学习能力增强:系统将具备更强的自主学习和优化能力
生态系统形成:围绕数据智能将形成完整的技术和服务生态
9.3 结语
Text2SQL和DataAgent代表了数据民主化的两种技术路径,它们不是相互替代的关系,而是在不同场景下各有所长。企业在技术选型时,应从自身需求出发,选择最适合的解决方案,或采用混合策略充分发挥两种技术的优势。
随着技术的不断发展,我们有理由相信,数据分析的门槛将进一步降低,让每个人都能轻松获取数据洞察,真正实现数据的民主化。
互动环节
感谢您阅读本文!为了更好地交流和分享经验,我想邀请您参与以下讨论:
您所在的企业是否已经应用了Text2SQL或DataAgent技术?使用体验如何?
在实际应用中,您遇到了哪些技术难点或挑战?
您认为Text2SQL和DataAgent技术未来最有前景的应用场景是什么?
如果您正在考虑引入这些技术,最关心的问题是什么?
欢迎在评论区分享您的想法和经验,也可以提出您感兴趣的问题,我将尽力回复并参与讨论!
关于作者:资深数据科学家,专注于AI与数据分析领域,拥有多年企业级数据智能解决方案实施经验。欢迎关注获取更多数据科学与AI技术内容!