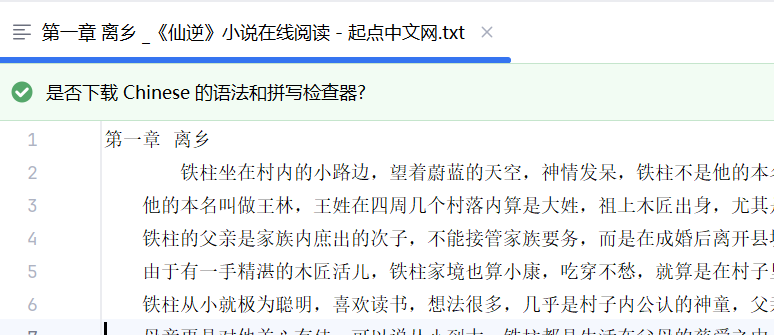
简单爬一个小说页面 HTML 的title和内容
1、请求接口-->url、头部,get获取
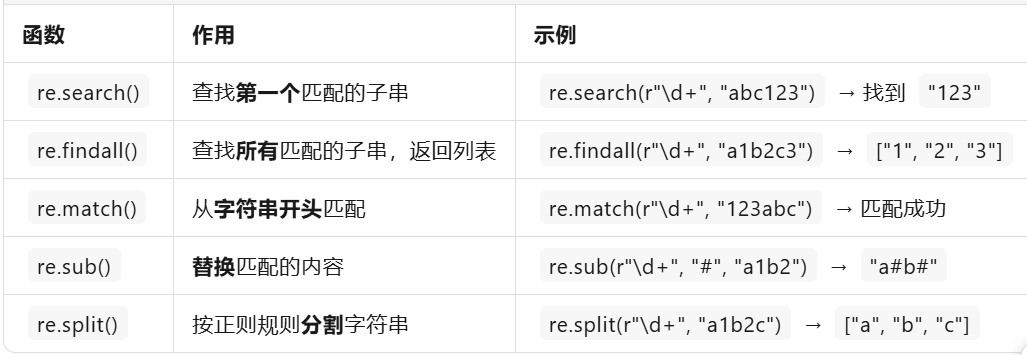
2、re.search(r"<title>(.*?)</title>").group(1)
(.*?)去匹配 网页标签内 的内容
group(1),捕获(.*?)的内容
r"<title>(.*?)</title>" r'<title id="123">(.*?)</title>'
如果标签内存在双引号,则r要使用单引号
re库 正则表达式模块
3、content.repalce('<p>', '\n', html)
提取出来的内容存在标签,可以使用replace()方法,将标签内容替换成想要的效果
4、
将内容写入到txt文件中

import re
import requests# 请求,获取text
def get_res(url, header):return requests.get(url, headers=header).text# 获取数据
def get_data(html):'''从html中提取数据:param html: HTML数据:return: 标题 内容'''title = re.search(r"<title>(.*?)</title>", html).group(1)# 需要转义[1.35] ---> \[1.35\]page = re.search(r'<h1 class="title text-1.3em text-s-gray-900 leading-\[1.35\] font-medium break-all wrap-word inline-block r-font-black-medium" data-v-f233f990>(.*?)</h1>', html).group(1)# print(title)# print(page)content = re.search(r'<main id="c-23808826" data-type="cjk" class="content mt-1.5em text-s-gray-900 leading-\[1.8\] relative z-0 r-font-black" data-v-f233f990>(.*?)</main>', html).group(1)# 将</p>替换换行处理,<p>替换空格处理content = content.replace('</p>', '\n').replace('<p>', '')# print(content)return title, page, content# 保存到txt文件
def save_txt(title, page, content):with open(f"{title}.txt", 'w', encoding = "UTF-8") as f:f.write(page + '\n')f.write(content)# 主方法
def main():# 请求参数url = "https://www.qidian.com/chapter/1264634/23808826/"header = {"Cookie" : "supportwebp=true; newstatisticUUID=1756714163_2142352094; _csrfToken=NVS3WyVwWW5ttGLBkag2uKm0QXG2N2sSu5vZMIIW; fu=1203733242; Hm_lvt_f00f67093ce2f38f215010b699629083=1756714109; HMACCOUNT=9EDCE41745AC7FA6; supportWebp=true; abPolicy=0; traffic_utm_referer=https%3A%2F%2Fwww.baidu.com%2Flink; traffic_search_engine=; se_ref=; Hm_lpvt_f00f67093ce2f38f215010b699629083=1756715830; w_tsfp=ltvuV0MF2utBvS0Q7KzulU6mFT0ncjs4h0wpEaR0f5thQLErU5mA14F7u8PzNXHW58xnvd7DsZoyJTLYCJI3dwNHR83CIYAX3wvGxolwiolGARQ0Q5+PWlFMJLx9uGEVf3hCNxS00jA8eIUd379yilkMsyN1zap3TO14fstJ019E6KDQmI5uDW3HlFWQRzaLbjcMcuqPr6g18L5a5T3c5FutfVl9Bu5E2BTAhC4dDn4k5BC7IO9eMhutI86pSqA=","user-agent" : "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/139.0.0.0 Safari/537.36","upgrade-insecure-requests" : "1"}# 发送请求获取响应html = get_res(url, header)# print(html)# 获取数据title, page, content = get_data(html)# 存放数据并输出save_txt(title, page, content)if __name__ == '__main__':main()