Qwen3-30B-A3B 模型解析
模型介绍
Qwen3-30B-A3B 是阿里巴巴通义千问团队推出的 Qwen3 系列中的一款旗舰级专家混合(Mixture-of-Experts, MoE)大语言模型。它代表了当前开源模型在架构创新与性能表现上的最新高度,旨在为复杂推理、高效对话及智能代理任务提供一个强大而高效的基石。
-
双模式无缝切换(核心突破):
Qwen3-30B-A3B 独特地内嵌了“思考模式”和“非思考模式”的智能切换能力。- 思考模式(Think Mode):在此模式下,模型会进行更深思熟虑的链式推理,尤其擅长解决复杂的数学问题、代码生成与调试、以及需要多步逻辑推理的任务,性能超越前代专门化的推理模型。
- 非思考模式(Non-Think Mode):在此模式下,模型响应迅速流畅,专注于提供高效、自然的通用对话体验,在创意写作、多轮闲聊和指令遵循方面表现卓越。
-
卓越的人类偏好对齐:
经过精心设计的后训练(Post-training),模型在人类偏好对齐方面表现突出。它能够生成更自然、富有创造力且贴合用户意图的文本,在角色扮演、创意写作和沉浸式对话中提供出色的用户体验。 -
强大的智能代理(Agent)能力:
无论是思考模式还是非思考模式,模型都展现出顶尖的工具调用与任务规划能力。它能精准地理解用户指令,自主选择并调用外部工具(如API、计算器、搜索引擎),完成复杂的、多步骤的自动化任务,在开源智能体领域达到了领先水平。 -
全面的多语言支持:
模型在100多种语言和方言上进行了深度优化,不仅具备优秀的理解和生成能力,更在跨语言翻译和多语言指令遵循方面表现强劲,真正服务于全球化的应用场景。
模型性能
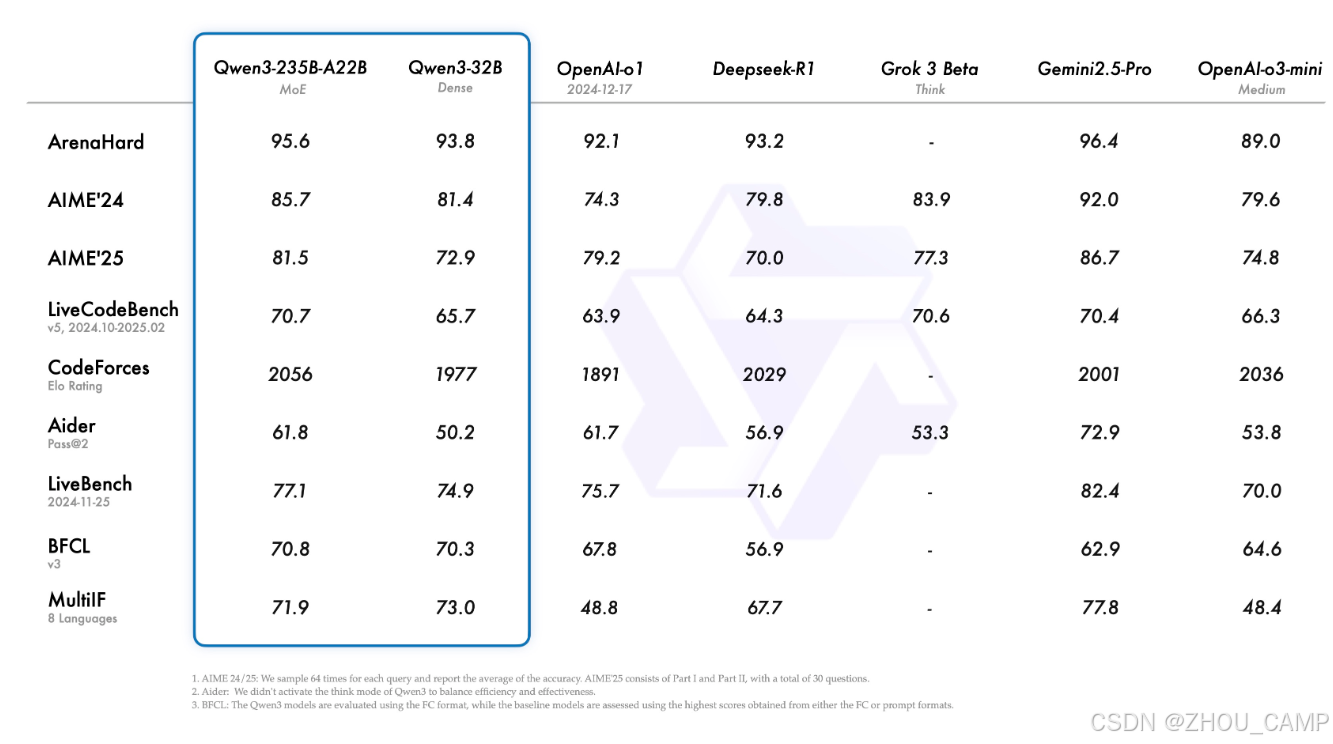
模型加载
from modelscope import AutoModelForCausalLM, AutoTokenizermodel_name = "Qwen/Qwen3-30B-A3B"# load the tokenizer and the model
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name,torch_dtype="auto",device_map="auto"
)/home/six/Zhou/test_source/gpt-oss-unsloth/.venv/lib/python3.12/site-packages/tqdm/auto.py:21: TqdmWarning: IProgress not found. Please update jupyter and ipywidgets. See https://ipywidgets.readthedocs.io/en/stable/user_install.htmlfrom .autonotebook import tqdm as notebook_tqdmDownloading Model from https://www.modelscope.cn to directory: /home/six/.cache/modelscope/hub/models/Qwen/Qwen3-30B-A3B
Downloading Model from https://www.modelscope.cn to directory: /home/six/.cache/modelscope/hub/models/Qwen/Qwen3-30B-A3BLoading checkpoint shards: 100%|██████████| 16/16 [00:51<00:00, 3.24s/it]
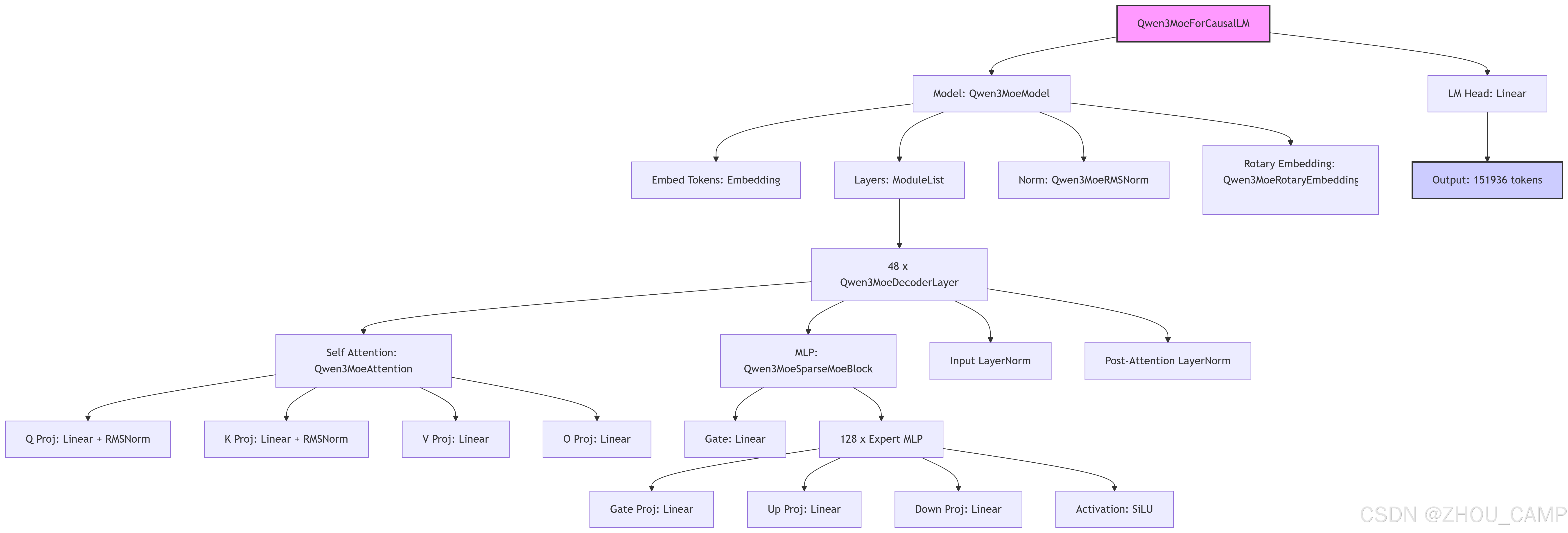
模型结构
model
Qwen3MoeForCausalLM((model): Qwen3MoeModel((embed_tokens): Embedding(151936, 2048)(layers): ModuleList((0-47): 48 x Qwen3MoeDecoderLayer((self_attn): Qwen3MoeAttention((q_proj): Linear(in_features=2048, out_features=4096, bias=False)(k_proj): Linear(in_features=2048, out_features=512, bias=False)(v_proj): Linear(in_features=2048, out_features=512, bias=False)(o_proj): Linear(in_features=4096, out_features=2048, bias=False)(q_norm): Qwen3MoeRMSNorm((128,), eps=1e-06)(k_norm): Qwen3MoeRMSNorm((128,), eps=1e-06))(mlp): Qwen3MoeSparseMoeBlock((gate): Linear(in_features=2048, out_features=128, bias=False)(experts): ModuleList((0-127): 128 x Qwen3MoeMLP((gate_proj): Linear(in_features=2048, out_features=768, bias=False)(up_proj): Linear(in_features=2048, out_features=768, bias=False)(down_proj): Linear(in_features=768, out_features=2048, bias=False)(act_fn): SiLU())))(input_layernorm): Qwen3MoeRMSNorm((2048,), eps=1e-06)(post_attention_layernorm): Qwen3MoeRMSNorm((2048,), eps=1e-06)))(norm): Qwen3MoeRMSNorm((2048,), eps=1e-06)(rotary_emb): Qwen3MoeRotaryEmbedding())(lm_head): Linear(in_features=2048, out_features=151936, bias=False)
)
模型配置
model.config
Qwen3MoeConfig {"architectures": ["Qwen3MoeForCausalLM"],"attention_bias": false,"attention_dropout": 0.0,"bos_token_id": 151643,"decoder_sparse_step": 1,"eos_token_id": 151645,"head_dim": 128,"hidden_act": "silu","hidden_size": 2048,"initializer_range": 0.02,"intermediate_size": 6144,"max_position_embeddings": 40960,"max_window_layers": 48,"mlp_only_layers": [],"model_type": "qwen3_moe","moe_intermediate_size": 768,"norm_topk_prob": true,"num_attention_heads": 32,"num_experts": 128,"num_experts_per_tok": 8,"num_hidden_layers": 48,"num_key_value_heads": 4,"output_router_logits": false,"rms_norm_eps": 1e-06,"rope_scaling": null,"rope_theta": 1000000.0,"router_aux_loss_coef": 0.001,"sliding_window": null,"tie_word_embeddings": false,"torch_dtype": "bfloat16","transformers_version": "4.55.2","use_cache": true,"use_sliding_window": false,"vocab_size": 151936
}
模型使用
# prepare the model input
prompt = "Give me a short introduction to large language model."
messages = [{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(messages,tokenize=False,add_generation_prompt=True,enable_thinking=True # Switches between thinking and non-thinking modes. Default is True.
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)# conduct text completion
generated_ids = model.generate(**model_inputs,max_new_tokens=32768
)
output_ids = generated_ids[0][len(model_inputs.input_ids[0]):].tolist() # parsing thinking content
try:# rindex finding 151668 (</think>)index = len(output_ids) - output_ids[::-1].index(151668)
except ValueError:index = 0thinking_content = tokenizer.decode(output_ids[:index], skip_special_tokens=True).strip("\n")
content = tokenizer.decode(output_ids[index:], skip_special_tokens=True).strip("\n")print("thinking content:", thinking_content)
print("content:", content)
thinking content: <think>
Okay, the user is asking for a short introduction to large language models. Let me start by defining what they are. I should mention that they're AI systems trained on vast amounts of text data. Then, I need to explain their purpose, like generating human-like text and understanding language.I should highlight key features such as their size, with billions of parameters, and how they use deep learning, maybe mention transformers. It's important to note their applications—like chatbots, content creation, and data analysis. Also, touch on their capabilities like multilingual support and reasoning. But I shouldn't forget to mention the challenges, like computational costs and potential biases. Keep it concise but informative. Let me structure that into a few paragraphs without getting too technical. Make sure it's easy to understand for someone who might not be familiar with AI terms.
</think>
content: A **large language model (LLM)** is an advanced artificial intelligence system designed to understand, generate, and interact with human language. Trained on vast amounts of text data from the internet, books, and other sources, these models learn patterns, grammar, and context to produce coherent responses, answer questions, write essays, code, or even engage in conversations. Powered by deep learning architectures like transformers, LLMs can handle complex tasks such as translation, summarization, and reasoning. Their scale—often involving billions of parameters—enables them to capture nuanced linguistic structures and adapt to diverse topics. While they excel at mimicking human-like text, they lack true understanding and rely on statistical patterns. LLMs are widely used in applications like virtual assistants, content creation, and customer service, but they also raise ethical and technical challenges, such as bias, misinformation, and computational costs.