DASK shuffle任务图分析
代码
if __name__ == '__main__':import dask.dataframe as ddimport pandas as pdimport numpy as npfrom dask.distributed import Client, LocalCluster# 创建本地 DASK 集群,2 个 worker,每个 worker 有 2 个线程cluster = LocalCluster(n_workers=2, threads_per_worker=2, memory_limit='2GB')client = Client(cluster)## # 打印集群信息print("DASK 集群信息:")print(client)print(cluster.dashboard_link)# 创建一个数据集,有 10 个分区n = 1000000 # 100万行数据df = pd.DataFrame({'id': np.random.randint(1, 10, n), # 随机 id 列'name': np.random.randint(1, 10, n), # 随机 id 列'value': np.random.rand(n) # 随机值列})# 将数据转换为 DASK DataFrame,划分成 10 个分区ddf = dd.from_pandas(df, npartitions=10)ddf = ddf.set_index('id',npartitions=2)# 打印一下有哪些TASK# 打印任务字典(显示所有task)print("任务图 keys:")ddf = ddf.groupby(['id', 'name']).value.mean()print(list(ddf.__dask_graph__().keys()))# 可视化为 PNG 文件ddf.visualize(filename="tasks.png")res = ddf.compute()print(res)# 关闭集群client.close()cluster.close()
[('truediv-1502847c4b84b6da0b23cb8ccb449e88', 0), ('assign-46695e4562789d0bbca8d8f885706151', 0), ('assign-46695e4562789d0bbca8d8f885706151', 1), ('assign-46695e4562789d0bbca8d8f885706151', 2), ('assign-46695e4562789d0bbca8d8f885706151', 3), ('assign-46695e4562789d0bbca8d8f885706151', 4), ('assign-46695e4562789d0bbca8d8f885706151', 5), ('assign-46695e4562789d0bbca8d8f885706151', 6), ('assign-46695e4562789d0bbca8d8f885706151', 7), ('assign-46695e4562789d0bbca8d8f885706151', 8), ('assign-46695e4562789d0bbca8d8f885706151', 9), ('from_pandas-292edf5f1c896094139efa30e5a92fd7', 0), ('from_pandas-292edf5f1c896094139efa30e5a92fd7', 1), ('from_pandas-292edf5f1c896094139efa30e5a92fd7', 2), ('from_pandas-292edf5f1c896094139efa30e5a92fd7', 3), ('from_pandas-292edf5f1c896094139efa30e5a92fd7', 4), ('from_pandas-292edf5f1c896094139efa30e5a92fd7', 5), ('from_pandas-292edf5f1c896094139efa30e5a92fd7', 6), ('from_pandas-292edf5f1c896094139efa30e5a92fd7', 7), ('from_pandas-292edf5f1c896094139efa30e5a92fd7', 8), ('from_pandas-292edf5f1c896094139efa30e5a92fd7', 9), ('getitem-42a8626272687008192d13242be46ea5', 0), ('getitem-42a8626272687008192d13242be46ea5', 1), ('getitem-42a8626272687008192d13242be46ea5', 2), ('getitem-42a8626272687008192d13242be46ea5', 3), ('getitem-42a8626272687008192d13242be46ea5', 4), ('getitem-42a8626272687008192d13242be46ea5', 5), ('getitem-42a8626272687008192d13242be46ea5', 6), ('getitem-42a8626272687008192d13242be46ea5', 7), ('getitem-42a8626272687008192d13242be46ea5', 8), ('getitem-42a8626272687008192d13242be46ea5', 9), ('set_partitions_pre-d1909e5fcd92e4d40b4ed6e5b4fb8e1a', 0), ('set_partitions_pre-d1909e5fcd92e4d40b4ed6e5b4fb8e1a', 1), ('set_partitions_pre-d1909e5fcd92e4d40b4ed6e5b4fb8e1a', 2), ('set_partitions_pre-d1909e5fcd92e4d40b4ed6e5b4fb8e1a', 3), ('set_partitions_pre-d1909e5fcd92e4d40b4ed6e5b4fb8e1a', 4), ('set_partitions_pre-d1909e5fcd92e4d40b4ed6e5b4fb8e1a', 5), ('set_partitions_pre-d1909e5fcd92e4d40b4ed6e5b4fb8e1a', 6), ('set_partitions_pre-d1909e5fcd92e4d40b4ed6e5b4fb8e1a', 7), ('set_partitions_pre-d1909e5fcd92e4d40b4ed6e5b4fb8e1a', 8), ('set_partitions_pre-d1909e5fcd92e4d40b4ed6e5b4fb8e1a', 9), ('shuffle-transfer-5ec1743e8c69cd98bd74251ef02ee1c9', 0), ('shuffle-transfer-5ec1743e8c69cd98bd74251ef02ee1c9', 1), ('shuffle-transfer-5ec1743e8c69cd98bd74251ef02ee1c9', 2), ('shuffle-transfer-5ec1743e8c69cd98bd74251ef02ee1c9', 3), ('shuffle-transfer-5ec1743e8c69cd98bd74251ef02ee1c9', 4), ('shuffle-transfer-5ec1743e8c69cd98bd74251ef02ee1c9', 5), ('shuffle-transfer-5ec1743e8c69cd98bd74251ef02ee1c9', 6), ('shuffle-transfer-5ec1743e8c69cd98bd74251ef02ee1c9', 7), ('shuffle-transfer-5ec1743e8c69cd98bd74251ef02ee1c9', 8), ('shuffle-transfer-5ec1743e8c69cd98bd74251ef02ee1c9', 9), 'shuffle-barrier-5ec1743e8c69cd98bd74251ef02ee1c9', ('shuffle_p2p-ce4b51bcbab77135418119cb01a9f71b', 0), ('shuffle_p2p-ce4b51bcbab77135418119cb01a9f71b', 1), ('set_index_post_scalar-3d008d63bb18c6a07bd73da70821558b', 0), ('set_index_post_scalar-3d008d63bb18c6a07bd73da70821558b', 1), ('sort_index-b226b11a5a1b20f1c81a9a7b00496a3b', 0), ('sort_index-b226b11a5a1b20f1c81a9a7b00496a3b', 1), ('getitem-e1167abf27eafa5da409b0b25fd69fd9', 0), ('getitem-e1167abf27eafa5da409b0b25fd69fd9', 1), ('series-groupby-sum-chunk-956bd669c8e6be6eaf801a0307088e95-16e47b9a3c24592c32d8520f8cef07bb', 0), ('series-groupby-sum-chunk-956bd669c8e6be6eaf801a0307088e95-16e47b9a3c24592c32d8520f8cef07bb', 1), ('series-groupby-sum-agg-956bd669c8e6be6eaf801a0307088e95', 0), ('series-groupby-count-chunk-b774409088eb85656d28c76f1282a225-d8f60f2d2cc7ba705647746be49e2ae8', 0), ('series-groupby-count-chunk-b774409088eb85656d28c76f1282a225-d8f60f2d2cc7ba705647746be49e2ae8', 1), ('series-groupby-count-agg-b774409088eb85656d28c76f1282a225', 0)]
任务图
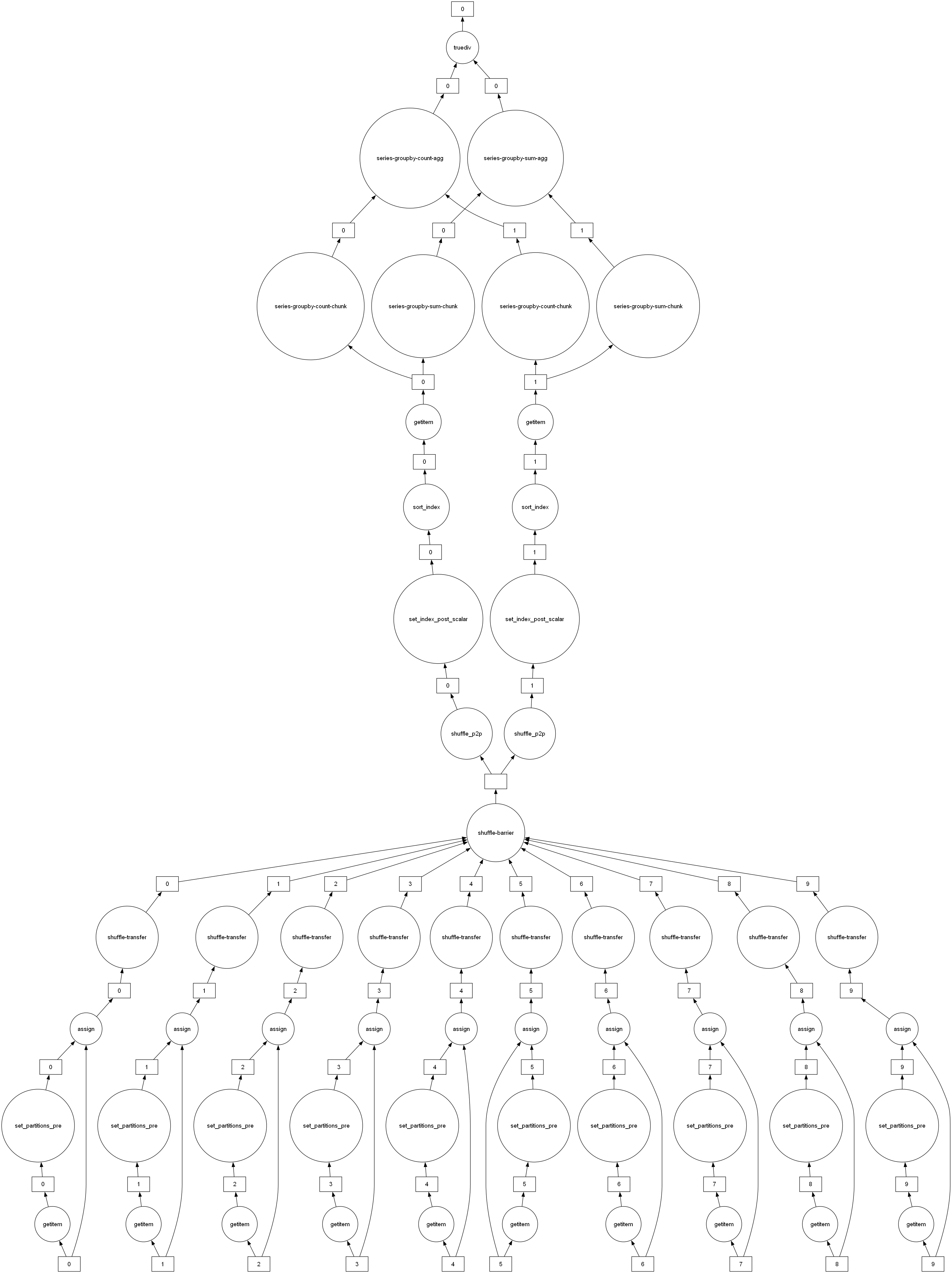
任务图分析
数据来源
('from_pandas-xxxx', i)
→ 每个分区都是从原始pandas.DataFrame切出来的。
你有 10 个分区,所以出现了from_pandas-..., 0..9。
列选择
('getitem-xxxx', i)
→ Dask 在 dataframe 上做了df['value']这样的列选择操作,对每个分区独立执行。
重新分区 / 设置索引
('assign-xxxx', i)
→ 分区内部做数据重排,配合 set_index。('set_partitions_pre-xxxx', i)
→set_index时需要先扫描分区数据,推断分区边界。('shuffle-transfer-xxxx', i)/'shuffle-barrier-xxxx'/('shuffle_p2p-xxxx', i)
→ 真正的数据 shuffle 阶段,把不同分区的行根据id分发到目标分区。('set_index_post_scalar-xxxx', i)
→ shuffle 之后每个 worker 得到的数据分区,再次处理,形成新 index。('sort_index-xxxx', i)
→ 对分区内的数据按照新 index 排序,保证id有序。
GroupBy + 聚合
('series-groupby-sum-chunk-xxxx', i)
→ 在每个分区上先局部做sum。('series-groupby-sum-agg-xxxx', 0)
→ 再把各分区的sum合并。('series-groupby-count-chunk-xxxx', i)
→ 在每个分区统计count。('series-groupby-count-agg-xxxx', 0)
→ 合并所有分区的count。('truediv-xxxx', 0)
→ 最后执行sum / count,得到mean()。
set_index shuffle分析
set_partitions_pre
dask.dataframe.shuffle.set_partitions_pre
根据目标分区数量计算出division,判断出每个分区中每一行需要分配到哪个新分区并新增成一个列
shuffle_transfer
分区发货
distributed.shuffle._shuffle.shuffle_transfer
distributed.shuffle._core.ShuffleRun.add_partition
distributed.shuffle._core.ShuffleRun._shard_partition
distributed.shuffle._shuffle.DataFrameShuffleRun._shard_partition
已经知道每个新的分区应该在哪个WORKER上了,并且每个分区内每行数据需要分配到哪个新分区上,根据要发往的WORKER分片打包数据。放入缓冲区
shuffle-barrier
确认所有货物发出
P2PShuffle._layer() 创建任务图
↓
P2PBarrierTask 创建barrier任务
↓
p2p_barrier() 函数执行
distributed.distributed.shuffle._core.p2p_barrier
↓
ShuffleWorkerPlugin.barrier()
↓
ShuffleRun.barrier()
distributed.shuffle._core.ShuffleRun.barrier
↓
scheduler.shuffle_barrier() 调度器协调
distributed.shuffle._scheduler_plugin.ShuffleSchedulerPlugin.barrier
检查run_id一致性/如果不一致,重启shuffle/否则广播"输入完成"消息给所有参与的worker
shuffle_p2p
分区收货 & 合并
set_index shuffle分析V2020.12.0
dask 2020.12.0
distributed 2021.1.1
if __name__ == '__main__':import dask.dataframe as ddimport pandas as pdimport numpy as npfrom dask.distributed import Client, LocalCluster# 创建本地 DASK 集群,2 个 worker,每个 worker 有 2 个线程cluster = LocalCluster(n_workers=2, threads_per_worker=1, memory_limit='2GB')client = Client(cluster)## # 打印集群信息print("DASK 集群信息:")print(client)print(cluster.dashboard_link)# 创建一个数据集,有 10 个分区n = 1000000 # 100万行数据df = pd.DataFrame({'id': np.random.randint(1, 10, n), # 随机 id 列'name': np.random.randint(1, 10, n), # 随机 id 列'value': np.random.rand(n) # 随机值列})# 将数据转换为 DASK DataFrame,划分成 10 个分区ddf = dd.from_pandas(df, npartitions=5)ddf = ddf.set_index('id',npartitions=2).reset_index(drop=False)# 打印一下有哪些TASK# 打印任务字典(显示所有task)print("任务图 keys:")ddf = ddf.groupby(['id', 'name']).value.sum()# print(list(ddf.__dask_graph__().keys()))# 可视化为 PNG 文件ddf.visualize(filename="tasks.png")res = ddf.compute()print(res)# 关闭集群client.close()cluster.close()import pandas as pd
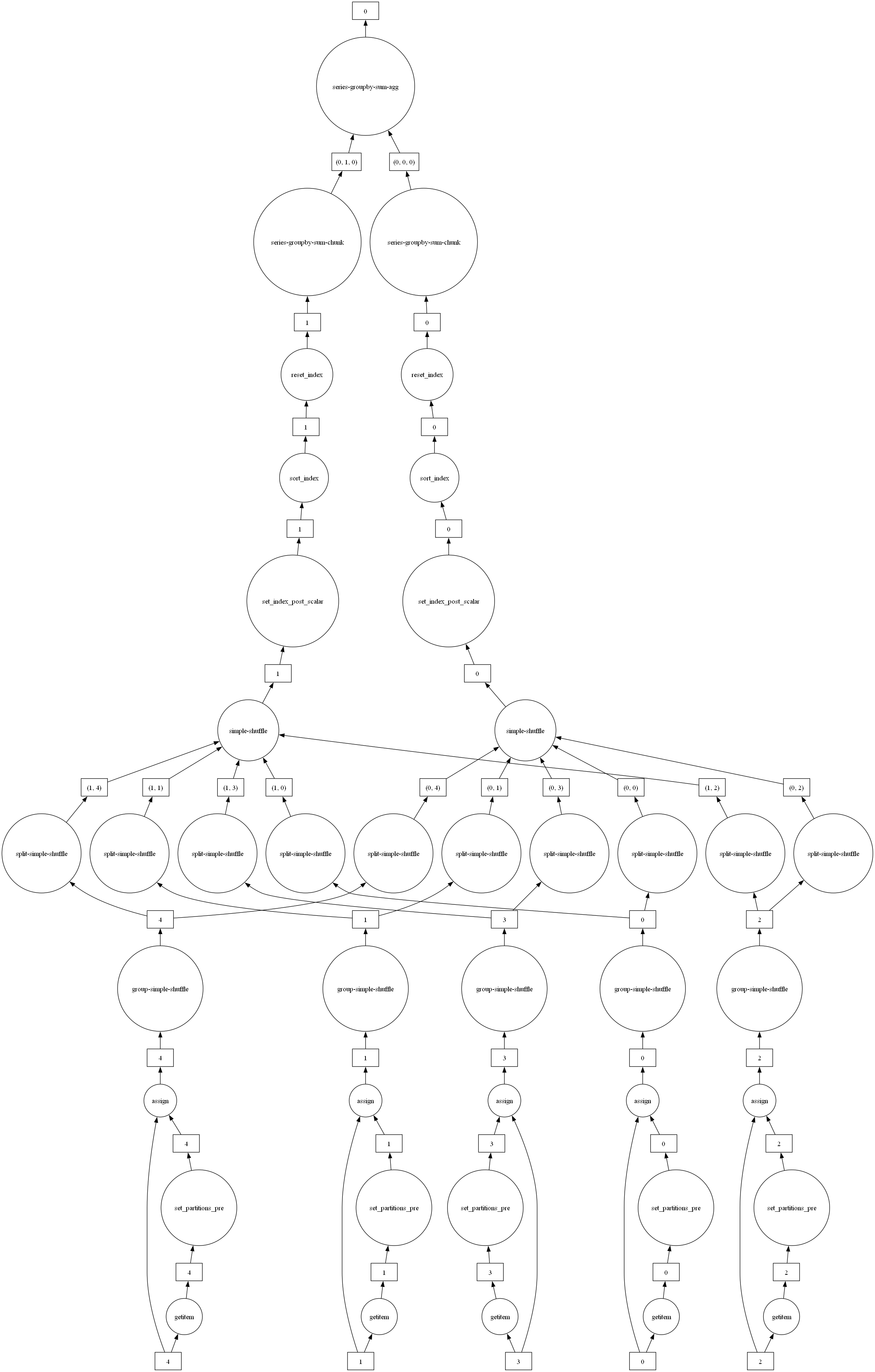
老版本还没有shuffle p2p,直接走的simple shuffle
getitem获取输入数据到各个分区
set_partitions_pre根据指定为INDEX的列进行HASH,确定每一行应该被分到新的哪个分区
assign将目标分区作为一个新的列添加到DF中
group-simple-shuffle同一个源分区内的数据根据目标分区分好组
spilt-simple-shuffle在目标WORKER内拉取应该要的源分区的数据
group-shuffle在目标WORKER上合并拉取到的小块合并成新分区
set-index-post-scalar到了目标分区的数据需要将指定INDEX列设置成pandas dataframe的index
sort-index每个分区内部的数据根据索引列排序,是为了和division更好的对齐,并且方便其他loc merge等操作
series-groupby-sum-chunk各个分区类分组求和
series-groupby-sum-agg汇总各个分区的结果,再次分组求和得到最终结果
compute分析
part1
df.compute()
⬇
results = schedule(dsk, keys, **kwargs)
⬇
distributed.client.Client.get
Client._graph_to_futures会在这里将DSK发送给scheduler
distributed.client.Client._send_to_scheduler
Client.gather然后在这等待计算结果返回
part2
发送给scheduler的具体内容
self._send_to_scheduler(
{
"op": "update-graph-hlg",
"hlg": dsk,
"keys": list(map(stringify, keys)),
"restrictions": restrictions or {},
"loose_restrictions": loose_restrictions,
"priority": priority,
"user_priority": user_priority,
"resources": resources,
"submitting_task": getattr(thread_state, "key", None),
"retries": retries,
"fifo_timeout": fifo_timeout,
"actors": actors,
}
)
part3
scheduler收到后处理
distributed.distributed.scheduler.Scheduler.update_graph_hlg
收到的TASK放入Scheduler的self.tasks,
此时stattus是released ,封装成了TaskState
ts = self.new_task(k, tasks.get(k), "released"),
self.transitions(recommendations)状态转成waiting
distributed.distributed.scheduler.Scheduler.transition在这发现状态在这个字典内self._transitions,那么就调用字典内定义的函数("waiting", "processing"): self.transition_waiting_processing,
distributed.distributed.scheduler.Scheduler.send_task_to_worker发送给worker计算
msg: dict = {
"op": "compute-task",
"key": ts._key,
"priority": ts._priority,
"duration": duration,
}
part4
worker收到了来自Scheduler封装好的msg
- 入口就是 worker 的流式消息路由里把 "compute-task" 绑定到 `add_task`。scheduler 发过来的任务消息会走这里:
```640:677:distributed/distributed/worker.py
stream_handlers = {
"close": self.close,
"compute-task": self.add_task,
"release-task": partial(self.release_key, report=False),
"delete-data": self.delete_data,
"steal-request": self.steal_request,
}
```
- 这个路由在 `Worker.__init__` 里注册到通信服务,随后 `add_task` 解析并入队执行(登记依赖、拉取数据或转 ready):
```1431:1516:distributed/distributed/worker.py
def add_task(
self,
key,
function=None,
args=None,
kwargs=None,
task=no_value,
who_has=None,
nbytes=None,
priority=None,
duration=None,
resource_restrictions=None,
actor=False,
**kwargs2,
):
...
if ts.waiting_for_data:
self.data_needed.append(ts.key)
else:
self.transition(ts, "ready")
```
worker正式执行函数
distributed.distributed.worker.Worker.execute
distributed.distributed.worker.apply_function