Zookeeper分布式锁原理
核心基础
在理解原理前,先回顾三个 ZooKeeper 的核心特性:
- 临时节点(Ephemeral Nodes):创建该节点的客户端会话(Session)一旦失效(如断开连接),那么这个节点会被自动删除。这保证了即使客户端崩溃,锁也能被自动释放,避免了死锁。
- 顺序节点(Sequential Nodes):创建节点时,ZooKeeper 会自动在节点名称后附加一个单调递增的序列号(如
lock-0000000001)。这保证了所有节点的创建顺序是全局唯一的。 - Watcher 机制:客户端可以在某个节点上设置监听(Watcher)。当该节点被删除、修改等事件发生时,ZooKeeper 会通知所有设置了 Watcher 的客户端。这是实现客户端间高效协调和通知的关键。
分布式锁的实现流程(以排他锁为例)
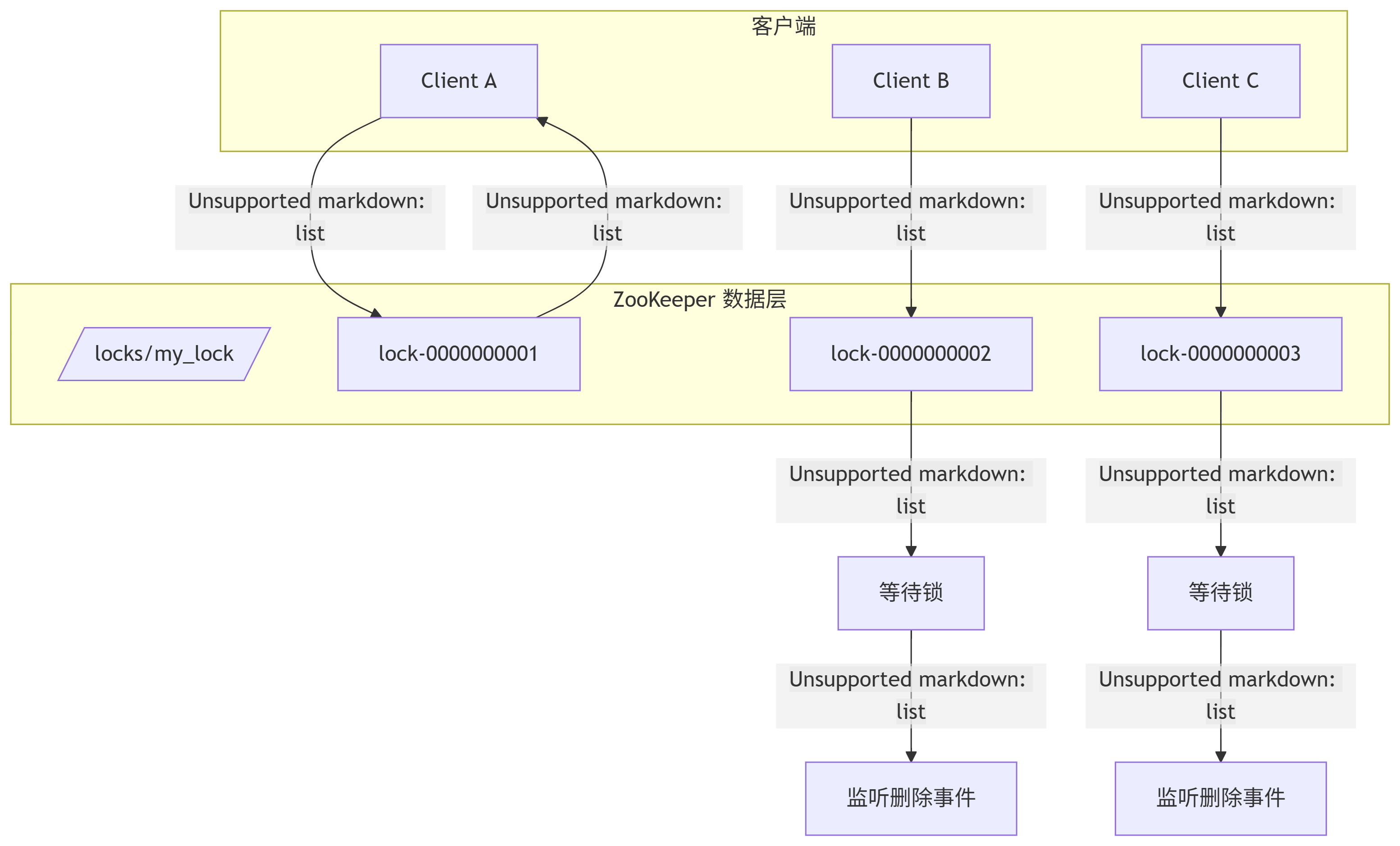
假设我们有一个锁的根节点 /locks/my_lock。
1. 获取锁(Acquire Lock)
-
步骤一:创建临时顺序节点
所有想要获取锁的客户端,都会在/locks/my_lock下创建一个临时顺序节点,例如:- Client A 创建了
/locks/my_lock/lock-0000000001 - Client B 创建了
/locks/my_lock/lock-0000000002 - Client C 创建了
/locks/my_lock/lock-0000000003
- Client A 创建了
-
步骤二:检查自己是否是最小节点
每个客户端都会获取/locks/my_lock下的所有子节点,并按序列号排序。- 对于 Client A:它发现自己的节点
lock-0000000001是序列号最小的节点。那么它就成功获得了锁,可以执行自己的业务逻辑。 - 对于 Client B:它发现自己的节点
lock-0000000002不是最小的,前面还有lock-0000000001。这意味着锁正被 Client A 持有。 - 对于 Client C:同样,它发现自己不是最小的,锁不可用。
- 对于 Client A:它发现自己的节点
-
步骤三:监听前一个节点(等待锁)
Client B 和 Client C 不会不停地轮询询问“轮到我了吗?”。而是采用更高效的方式:- Client B:它会向它前面的那个节点(即
lock-0000000001)设置一个 Watcher 监听。 - Client C:它会向它前面的那个节点(即
lock-0000000002)设置一个 Watcher 监听。
这样,每个客户端都只监听它前面的节点,形成一个等待队列。
- Client B:它会向它前面的那个节点(即
整个过程如下图所示,它清晰地展示了客户端如何通过创建节点、排序和监听来形成一个有序的等待队列:
2. 释放锁(Release Lock)
-
情况一:正常释放
Client A 完成业务逻辑后,主动删除它创建的那个临时节点lock-0000000001。 -
情况二:异常释放
如果 Client A 在持有锁期间进程崩溃或网络断开,由于它创建的是临时节点,ZooKeeper 会自动检测到会话失效,并自动删除lock-0000000001。
3. 唤醒下一个等待者(Notify Next)
- 当
lock-0000000001被删除(无论是主动还是被动)时,ZooKeeper 会通知所有监听了这个节点的客户端。也就是 Client B 会收到一个通知。 - Client B 被唤醒后,它会重复“步骤二”:再次获取
/locks/my_lock下的所有子节点。- 此时子节点是
[lock-0000000002, lock-0000000003] - Client B 发现自己的节点
lock-0000000002现在是最小的了!于是它成功获得了锁。
- 此时子节点是
- 同理,当 Client B 释放锁,删除
lock-0000000002后,Client C 会被唤醒,进而获得锁。
这种设计的精妙之处
-
避免羊群效应(Herd Effect):
传统的做法是所有客户端都监听同一个锁节点,释放时所有客户端都被唤醒并同时争抢,给 ZooKeeper 和服务端带来巨大压力。而只监听前一个节点的方式,每次锁释放都只精确地唤醒一个客户端(队列中的下一个),压力非常小。 -
天然的公平锁(Fair Lock):
由于节点顺序是全局唯一的,并且严格按照顺序唤醒,所以每个客户端获取锁的顺序就是它们创建节点的顺序,实现了先来后到的公平性。 -
自动防死锁(Deadlock-Free):
得益于临时节点的特性,任何客户端持有的锁都会在会话结束时自动释放,无需担心因为客户端宕机而导致的锁永久死锁问题。 -
可重入性(Reentrancy)(需要客户端实现):
如果同一个客户端线程想再次获取锁,可以在客户端内存中记录一个计数器(count)。检查锁的持有者时,不仅要看节点序列号,还要看节点名称中是否包含自己的客户端ID。如果是自己持有的,就直接增加计数器并返回成功,而无需再创建节点。
总结:ZooKeeper 分布式锁的核心步骤
| 步骤 | 操作 | 说明 |
|---|---|---|
| 1. 争抢 | 所有客户端在锁目录下创建临时顺序节点。 | 宣告自己的排队资格。 |
| 2. 判断 | 获取锁目录下所有子节点,判断自己是否是序号最小的节点。 | 是则成功获锁;否则继续。 |
| 3. 等待 | 如果不是最小,则监听自己前面那个节点的删除事件。 | 避免羊群效应,高效等待。 |
| 4. 释放 | 业务处理完,主动删除自己创建的那个节点。 | 正常释放锁。 |
| 5. 唤醒 | 节点被删除,ZooKeeper 通知下一个监听它的客户端。 | 下一个客户端被唤醒,回到步骤2。 |
在实际开发中,我们通常不直接使用 ZooKeeper 的原生 API 来实现锁,而是使用更高级的封装库,例如 Apache Curator。Curator 提供了一个成熟、稳健的分布式锁实现(InterProcessMutex),直接开箱即用,避免了手动处理各种极端情况(例如连接丢失、重试等)。但理解其底层原理对于诊断问题和设计系统至关重要。