正则表达式与grep文本过滤详解
文章目录
- 前言
- 一、正则表达式概述
- 1.1 定义
- 1.2 主要用途
- 1.3 Linux 中的正则表达式分类
- 1.3.1 基础正则表达式(BRE)
- 1.3.2 扩展正则表达式(ERE)
- 二、正则表达式的基本组成
- 2.1 普通字符
- 2.2 元字符
- 2.2.1 基本元字符
- 2.2.2 重复次数相关
- 2.2.3 扩展正则中的元字符(ERE)
- 2.2.4 `egrep`的用法
- 三、grep 工具的使用
- 3.1 常用选项
- 3.2 使用示例
- 四、正则表达式操作案例
- 4.1 查找特定字符
- 4.2 使用中括号集合
- 4.3 使用定位符
- 4.4 使用点与星号
- 4.5 使用次数限定符
- 五、基础正则与扩展正则对比表
- 总结
- 🎯 核心价值
- 📊 体系结构
- ⚡ 四大核心能力
- 🛠️ 实战应用
前言
你是否曾在成百上千行的日志文件中寻找某个关键错误信息,却像大海捞针一样无从下手?是否曾需要从杂乱的文本中快速提取电话号码、邮箱地址或特定格式的数据,却不得不手动逐行筛选?别担心,正则表达式正是为你解决这些问题而生的“文本处理瑞士军刀”。它就像是一套神奇的密码,掌握了它,你就能让计算机自动理解你想要的文本模式,无论是筛选日志、解析数据还是批量处理文档,都将变得轻松高效。本章将带你从零开始,解锁这项让无数程序员和系统管理员受益终身的强大技能。
一、正则表达式概述
1.1 定义
正则表达式(Regular Expression,常缩写为 regex/regexp/RE)是一种用于描述字符串模式的规则。它能够高效地进行检索、替换和过滤符合特定规则的字符串。
1.2 主要用途
- 系统日志筛选(如定位“登录失败”“服务启动失败”等关键信息)
- 配置文件解析与提取
- 文本查找与替换
- 脚本编程中的条件匹配与验证
1.3 Linux 中的正则表达式分类
| 类型 | 名称 | 特点 | 需转义字符 | 常用工具 |
|---|---|---|---|---|
| BRE | 基础正则表达式 | 功能有限,传统语法 | \{n\}, \+, \?, \(\), | | grep, sed |
| ERE | 扩展正则表达式 | 功能强大,语法简洁 | 无需转义 | grep -E, egrep, awk |
1.3.1 基础正则表达式(BRE)
- 语法较为传统,功能相对有限
- 量词如
{}需转义为\{n,m\} +、?、()等符号也需要转义- 常用工具:
grep、sed
1.3.2 扩展正则表达式(ERE)
- 功能更强大,语法更简洁
+、?、()、{}、|等符号无需转义- 常用工具:
egrep(或grep -E)、awk
二、正则表达式的基本组成
2.1 普通字符
包括字母、数字、标点符号等,匹配其本身。
2.2 元字符
2.2.1 基本元字符
.:匹配任意单个字符(除换行符\r\n)[]:匹配字符集合中的一个字符,如[abc]、[a-z]、[0-9A-Z][^]:匹配不在集合中的任意一个字符,如[^a-z]表示非小写字母^:匹配行首$:匹配行尾\:转义符,用于取消元字符的特殊含义
2.2.2 重复次数相关
*:匹配前一个字符 0 次或多次\+:匹配前一个字符至少 1 次(BRE 中需转义)\{n\}:匹配前一个字符恰好 n 次\{n,m\}:匹配前一个字符 n 到 m 次\{n,\}:匹配前一个字符至少 n 次
2.2.3 扩展正则中的元字符(ERE)
+:匹配前一个字符至少 1 次(无需转义)?:匹配前一个字符 0 次或 1 次|:表示“或”关系,匹配多个模式之一():用于分组,可对一组字符进行重复或选择()+:匹配重复的组
2.2.4 egrep的用法
egrep 是 Unix/Linux 系统中的一个文本搜索工具,属于 GNU grep 的扩展版本(grep -E 的别名)。它支持扩展正则表达式(Extended Regular Expressions, ERE),比基础正则表达式(BRE)提供更灵活的语法,例如直接使用 +、?、| 等元字符而无需转义。
基本量词语法
egrep和awk使用{n}、{n,}、{n,m}进行匹配时,{}前无需加转义符\- 示例:
egrep -E -n 'wo{2}d' demo # 匹配"wood" egrep -E -n 'wo{2,3}d' demo # 匹配"wood"或"woood"
常用量词操作符
-
+重复一个或多个前导字符- 示例:
egrep -n 'wo+d' demo匹配"wood"、“woood”、"woooooood"等字符串
- 示例:
-
?零个或一个前导字符- 示例:
egrep -n 'bes?t' demo匹配"bet"和"best"
- 示例:
-
|或操作(匹配多个模式)- 示例:
egrep -n 'of|is|on' demo匹配"of"、“if"或"on”
- 示例:
-
()分组匹配- 示例:
egrep -n 't(a|e)st' demo
匹配"tast"和"test",利用分组将共有的"t"和"st"提取,仅将差异部分"a|e"放入组内
- 示例:
-
()+重复分组匹配- 示例:
egrep -n 'A(xyz)+C' demo
匹配以"A"开头、"C"结尾,中间包含一个或多个"xyz"的字符串
- 示例:
三、grep 工具的使用
3.1 常用选项
| 选项 | 功能说明 | 使用示例 |
|---|---|---|
-E | 启用扩展正则表达式 | grep -E 'wo{2}d' file |
-c | 统计匹配行数 | grep -c root /etc/passwd |
-i | 忽略大小写 | grep -i "the" file |
-o | 只输出匹配内容 | grep -o '[0-9]\+' file |
-v | 反向匹配(排除) | grep -v root /etc/passwd |
-n | 显示行号 | grep -n pattern file |
--color=auto | 高亮显示匹配内容 | grep --color=auto pattern file |
3.2 使用示例
grep -c root /etc/passwd # 统计包含 root 的行数
grep -i "the" web.sh # 忽略大小写匹配 the
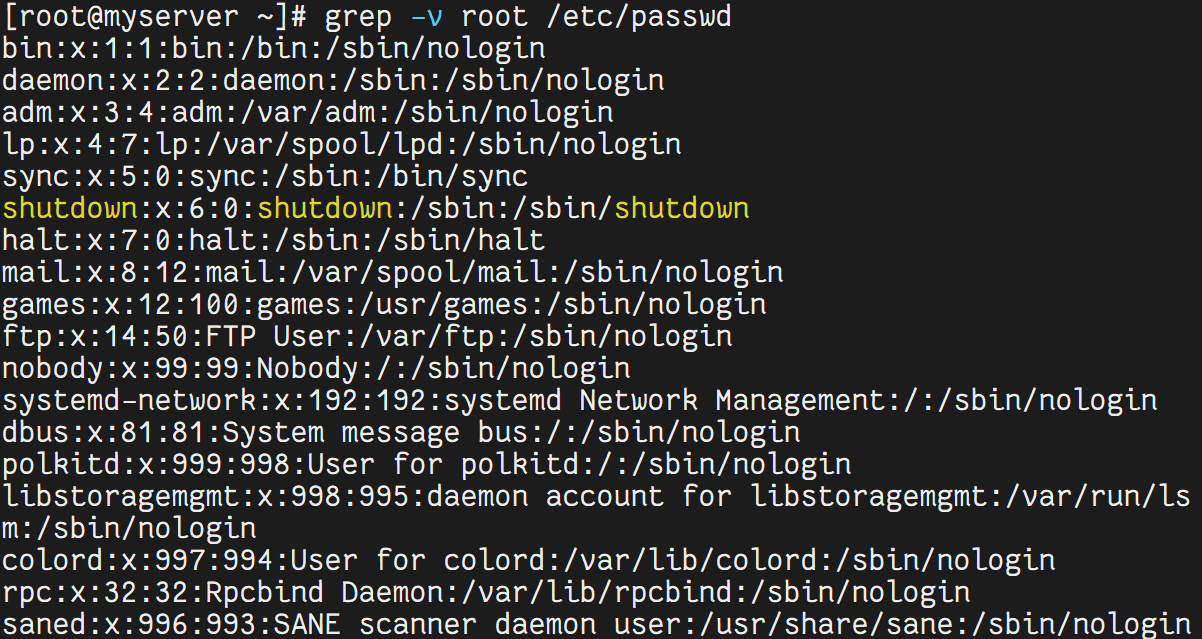
grep -v root /etc/passwd # 输出不包含 root 的行
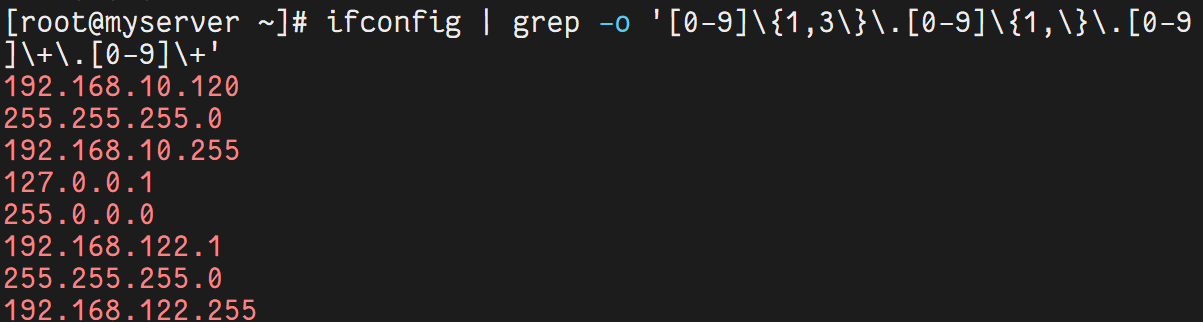
ipconfig | grep -o '[0-9]\+\.[0-9]\+\.[0-9]\+\.[0-9]\+' | head -1 # 提取 IP 地址
-c

-i

-v
-o
四、正则表达式操作案例
| 元字符 | 功能说明 | 示例 | 匹配结果 |
|---|---|---|---|
. | 匹配任意单个字符(除\r\n) | w..d | wood, word, w00d |
[ ] | 匹配字符集合中的任意一个字符 | sh[io]rt | shirt, short |
[^ ] | 匹配不在集合中的任意一个字符 | [^w]oo | foo, boo(排除woo) |
^ | 匹配行首位置 | ^the | 以the开头的行 |
$ | 匹配行尾位置 | \.$ | 以.结尾的行 |
\ | 转义特殊字符 | a\.b | a.b(而不是ajb等) |
4.1 查找特定字符
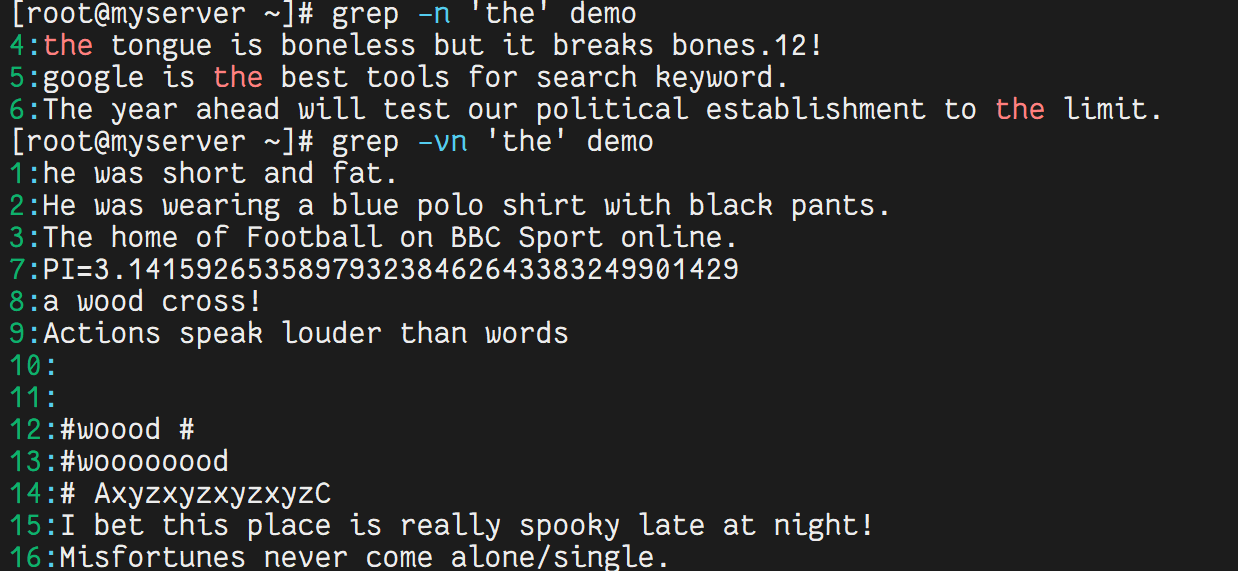
grep -n 'the' demo # 查找包含 the 的行
grep -vn 'the' demo # 查找不包含 the 的行
4.2 使用中括号集合
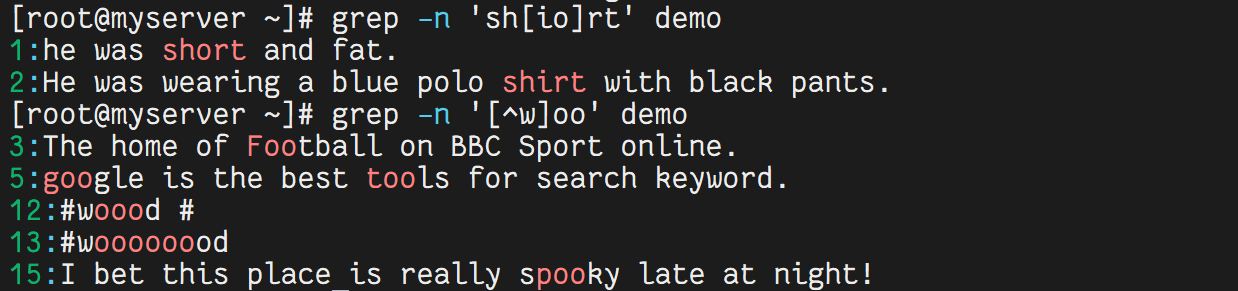
grep -n 'sh[io]rt' demo # 匹配 shirt 或 short
grep -n '[^w]oo' demo # 匹配开头不是 w 且包含 oo 的行
4.3 使用定位符
grep -n '^the' demo # 匹配以 the 开头的行
grep -n '\.$' demo # 匹配以 . 结尾的行
grep -n '^$' demo # 匹配空行
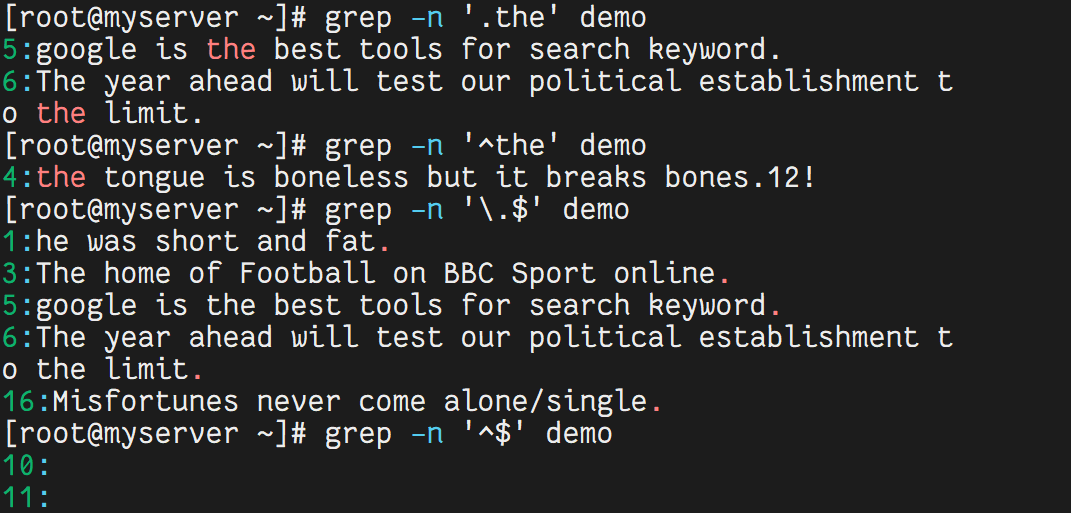
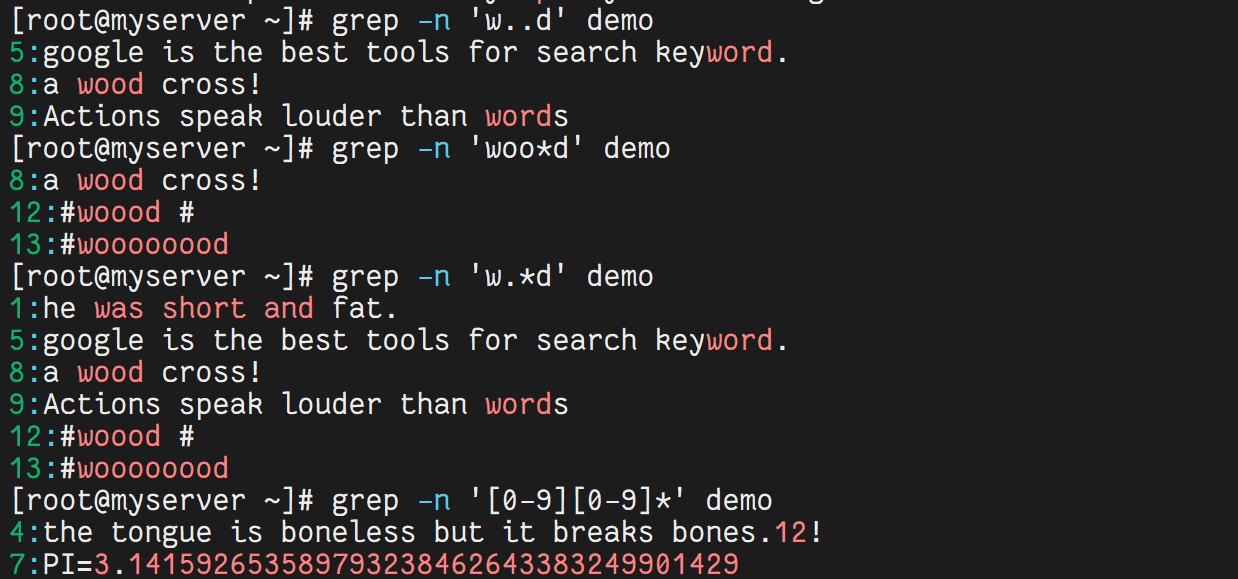
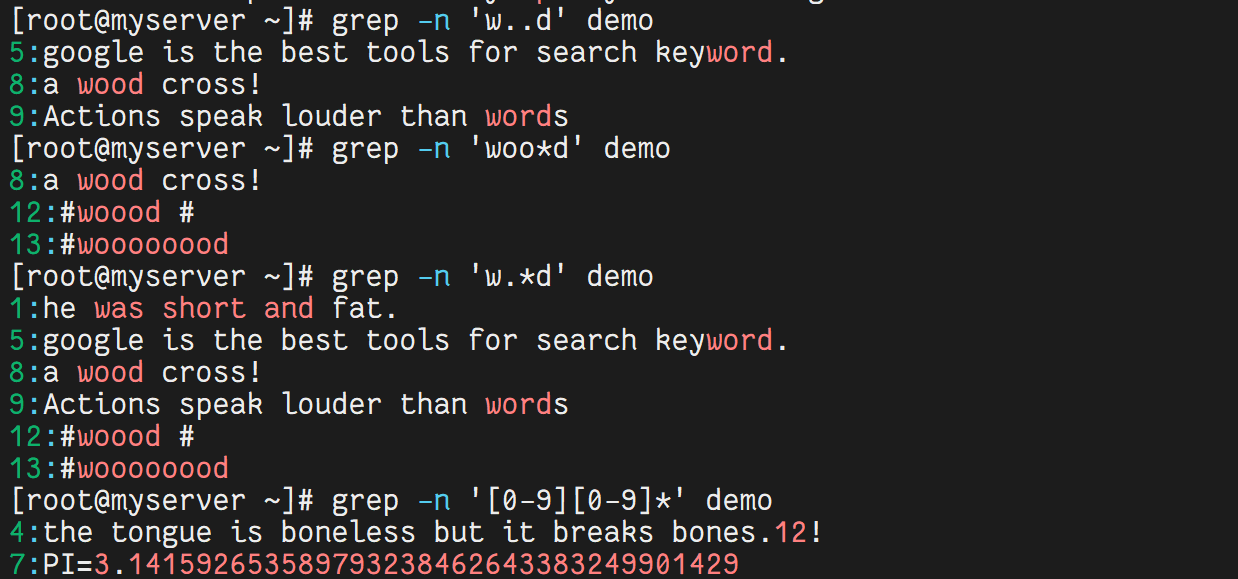
4.4 使用点与星号
grep -n 'w..d' demo # 匹配 w 开头、d 结尾,中间两个任意字符
grep -n 'woo*d' demo # 匹配 w 开头、d 结尾,中间有 0 个或多个 o
grep -n 'w.*d' demo # 匹配 w 开头、d 结尾,中间任意多个字符
grep -n '[0-9][0-9]*' demo # 匹配任意数字
4.5 使用次数限定符
grep -n 'o\{2\}' demo # 匹配两个连续的 o
grep -n 'wo\{2,5\}d' demo # 匹配 w 开头、d 结尾,中间 2~5 个 o
grep -n 'wo\{2,\}d' demo # 匹配 w 开头、d 结尾,中间至少 2 个 o
五、基础正则与扩展正则对比表
| 量词 | 功能说明 | BRE语法 | ERE语法 | 示例 |
|---|---|---|---|---|
* | 匹配0次或多次 | * | * | wo*d(wd, wod, wood) |
+ | 匹配1次或多次 | \+ | + | wo\+d(wod, wood) |
? | 匹配0次或1次 | \? | ? | bes?t(bet, best) |
{n} | 匹配恰好n次 | \{n\} | {n} | o\{2\}(oo) |
{n,} | 匹配至少n次 | \{n,\} | {n,} | o\{2,\}(oo, ooo, …) |
{n,m} | 匹配n到m次 | \{n,m\} | {n,m} | o\{2,5\}(oo, ooo, oooo, ooooo) |
总结
🎯 核心价值
正则表达式是文本处理的瑞士军刀,通过模式匹配实现高效检索、替换和过滤,极大提升数据处理效率。
📊 体系结构
两大体系并行:
- BRE(基础正则):传统严谨,需转义特殊字符
- ERE(扩展正则):现代简洁,直接使用元字符
⚡ 四大核心能力
- 精准定位 - 用
^$锁定行首行尾 - 字符控制 - 用
[ ][^ ]精确字符范围 - 数量调控 - 用
*+?{}控制出现次数 - 逻辑组合 - 用
|()实现复杂逻辑匹配
🛠️ 实战应用
和grep 、awk、sed等结合使用,可以处理99%的文档
- 日志分析:快速定位错误信息
grep -n "error" logfile - 数据提取:匹配特定格式
grep -o '[0-9]\{3\}-[0-9]\{2\}-[0-9]\{4\}' - 文本清洗:过滤空行
grep -v '^$' file - 模式验证:检查格式合法性
grep -E '^[A-Za-z0-9]+@[A-Za-z0-9]+\.[a-z]{2,}$'